大模型新拐点:FlagOS+Engram 开启算存协同新时代
当前大语言模型的发展,正深陷 “计算模拟记忆” 的原生范式瓶颈。无论是 Dense 还是 MoE 架构的大模型,都无法摆脱知识与参数强绑定、算力与显存双膨胀、能力与容量耦合扩展的核心困境。DeepSeek 提出的 Engram 架构,通过显式可扩展记忆系统实现计算与存储的解耦,为大模型开辟了 “计算 + 记忆” 双稀疏扩展的全新方向。
本文首先介绍 Engram 的核心思想,然后阐述基于 FlagOS 系统软件栈中的训练插件完成的 Engram 架构全链路复现。在此基础上,重点展示 FlagOS 针对 Engram 进行的三大工程优化。实验量化结果表明,FlagOS 对 Engram 的优化在保持额外负载为零的前提下,使吞吐最高提升近 150%。
1什么是Engram?
Engram 由 DeepSeek 提出,其核心贡献在于引入了一个显式、可扩展的记忆系统,从根本上解耦了传统大模型中的计算与存储。具体而言,Engram 与 MoE 共同构建了一种“计算 + 记忆”的双稀疏架构:MoE 负责条件计算,Engram 负责条件记忆,通过高效的检索机制按需访问大规模记忆存储。这一设计使得计算与存储可以沿着两个正交维度各自稀疏化,将系统瓶颈从算力逐步转移至带宽与索引效率。知识不再被隐式压缩在模型参数中,而是被释放为独立的、可扩展的记忆单元,从而支持按需扩展、动态更新以及跨任务复用。最终,Engram 推动大模型从传统的“参数规模扩展”演进为“计算与记忆协同扩展”的全新范式。
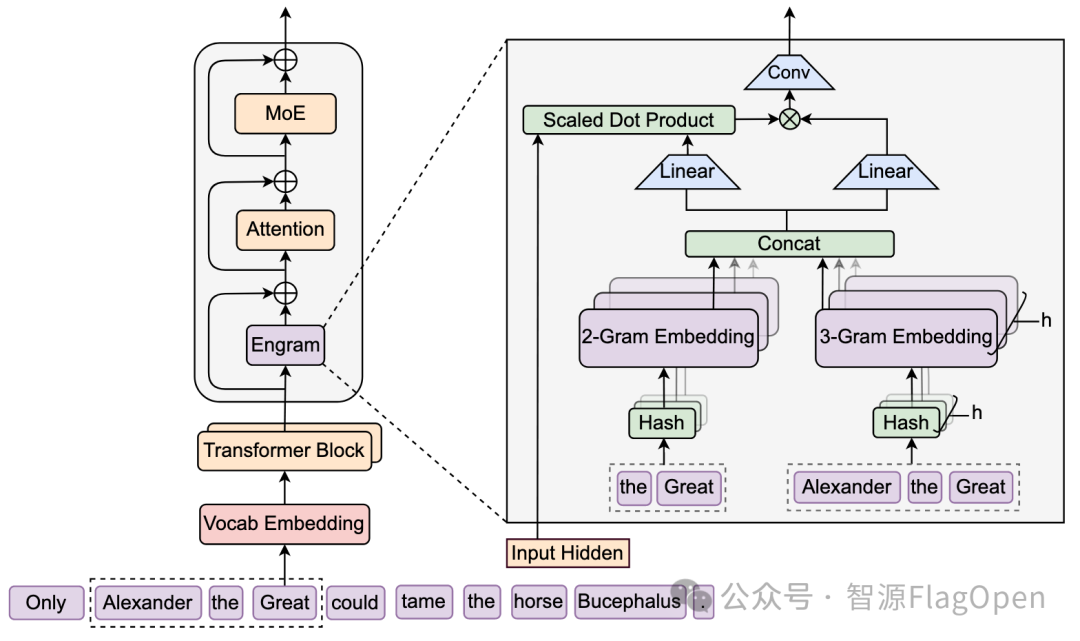
2FlagScale 的统一多芯片训推插件,提供 Engram 架构落地的基础底座
FlagOS 是一个面向多元 AI 硬件的统一系统软件平台,始终秉承开源开放的核心理念,为上层大模型与下层多样 AI 芯片之间提供高效、可扩展的连接与调度能力。其核心训推组件 FlagScale 具备统一多芯片插件体系、分布式训练深度优化、原生 MoE 全兼容与低侵入式扩展能力,为 Engram 算存解耦架构的落地提供了坚实底座。
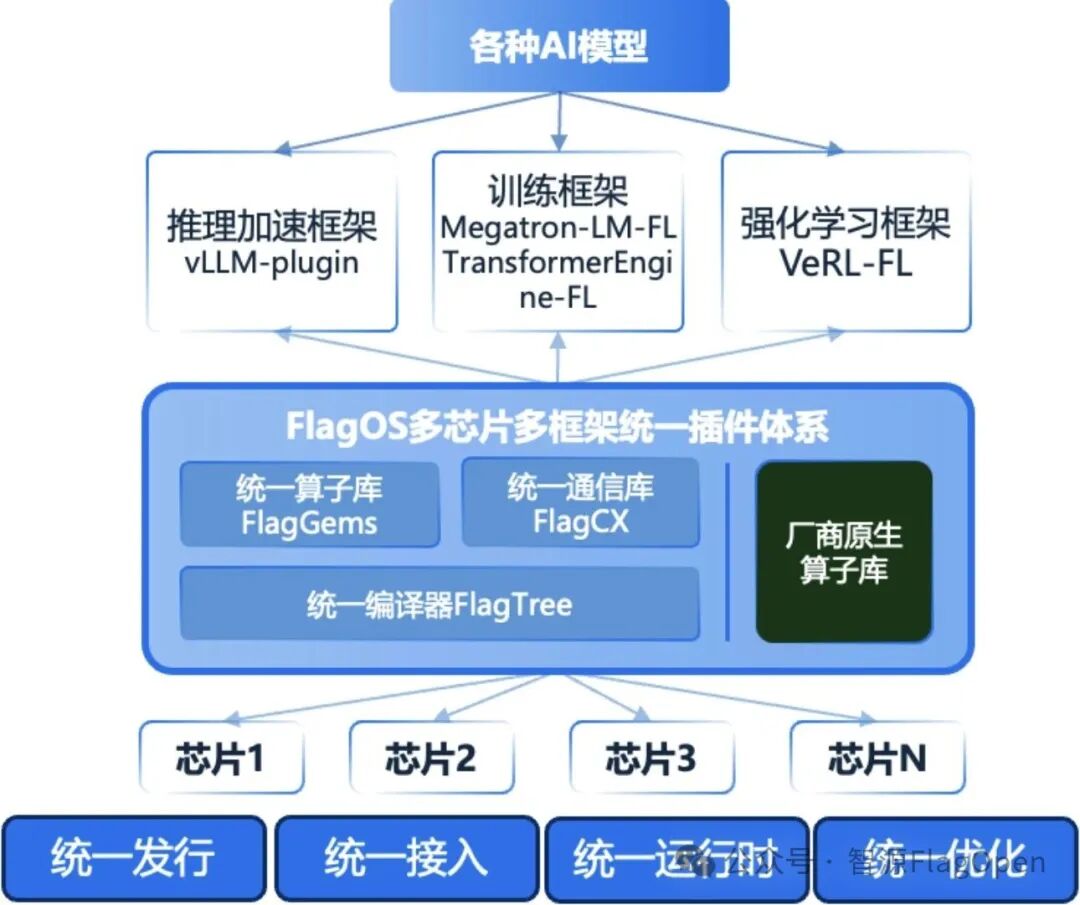
FlagScale统一多芯片插件体系
本次工作基于 FlagScale 组件,完成了 Engram 架构的增量式、非侵入式复现,核心目标是在不破坏原生deepseek-v3 主干结构的前提下,引入可按层灵活启用的 Engram 分支,让模型在指定层通过 n-gram 哈希索引完成记忆检索,并以残差方式融入主干计算。
3如何通过FlagOS训练插件复现Engram
围绕上述目标,我们从核心模块开发、主干网络集成、分布式状态兼容三个维度完成了全流程设计与实现,具体如下。
1.核心模块开发
首先扩展模型配置,新增 EngramConfig 参数组,用于定义 n-gram 范围、每个 gram 的 embedding/head 配置、启用 Engram 的层列表、哈希种子以及并行策略。在此基础上实现三个关键子模块:
-
NgramHashMapping:负责将输入 token 序列映射为 n-gram 哈希索引;
-
MultiHeadEmbedding:管理多头的记忆存储与并行查找;
-
Engram 模块:整合上述组件,完成记忆检索与残差输出。
2.主干网络集成
为避免侵入原生 DeepSeek-V3 主干,采用层层包裹的适配方式。
-
在 TransformerLayer 级别,实现 EngramTransformerLayer 。仅在配置指定的层执行 Engram 分支,计算结果以残差形式注入,然后再调用原始的 TransformerLayer 前向逻辑。
-
在 TransformerBlock 级别,实现 EngramTransformerBlock 。为每个 Engram 层传入对应层号的哈希输入,并在层循环中提前预取下一层所需的 embedding,同时兼容原有的重计算、量化与并行上下文。
-
在模型入口处构建 EngramModel,复用 GPTModel 的构造链路,将原始 block 替换为 EngramTransformerBlock,并通过 LazyHashInputIds 支持哈希结果的延迟访问,最终在前向传播中将哈希输入与 decoder 调用完整贯通。
-
新增 engram_builder,在模型构建时根据配置开关与层列表动态选择使用 Engram 层还是原始层,并自动适配 MoE / 非 MoE 不同路径。
3.状态保存与结构兼容
由于 Engram 层与普通层共存导致模型层结构不再同构,显式标记了 non_homogeneous_layers,确保分布式训练下的 checkpoint 键生成与加载过程能够正确处理这种异构结构,避免状态错位或丢失。
上述设计实现了对 Engram 架构的非侵入式增量支持,既保留了主干模型的所有原有能力,又为灵活启用记忆检索分支提供了干净的工程接口。
4基于 FlagScale 训练插件的 Engram 架构性能优化方案
基于 DeepSeek V3 基础架构,FlagOS 旗下 FlagScale 大模型训练框架针对 Engram 记忆增强模型的核心特性,在基础训练架构设施层面完成了三大核心工程优化,完整兼容 mHC(Manifold-Constrained Hyper-Connections)架构设计,实现了训练吞吐、显存效率、并行扩展性的全面突破,同时保障了大规模训练的稳定性。
4.1 核心工程优化方案
FlagScale 针对 Engram 的结构特性与训练痛点,落地了三项针对性的底层架构优化,具体如下。
-
专属并行维度解耦方案
如图 1 所示,针对 Engram Embedding 超大词表带来的并行适配难题,FlagScale 为 Engram Embedding 设计了独立的专属并行维度,实现与模型主干张量并行(TP)策略的完全解耦,避免超大词表对主干模型并行方式的干扰;同时采用 AlltoAll 通信算子替代传统 Allreduce 算子,大幅削减通信冗余,从底层解决了多卡并行场景下的通信瓶颈问题。
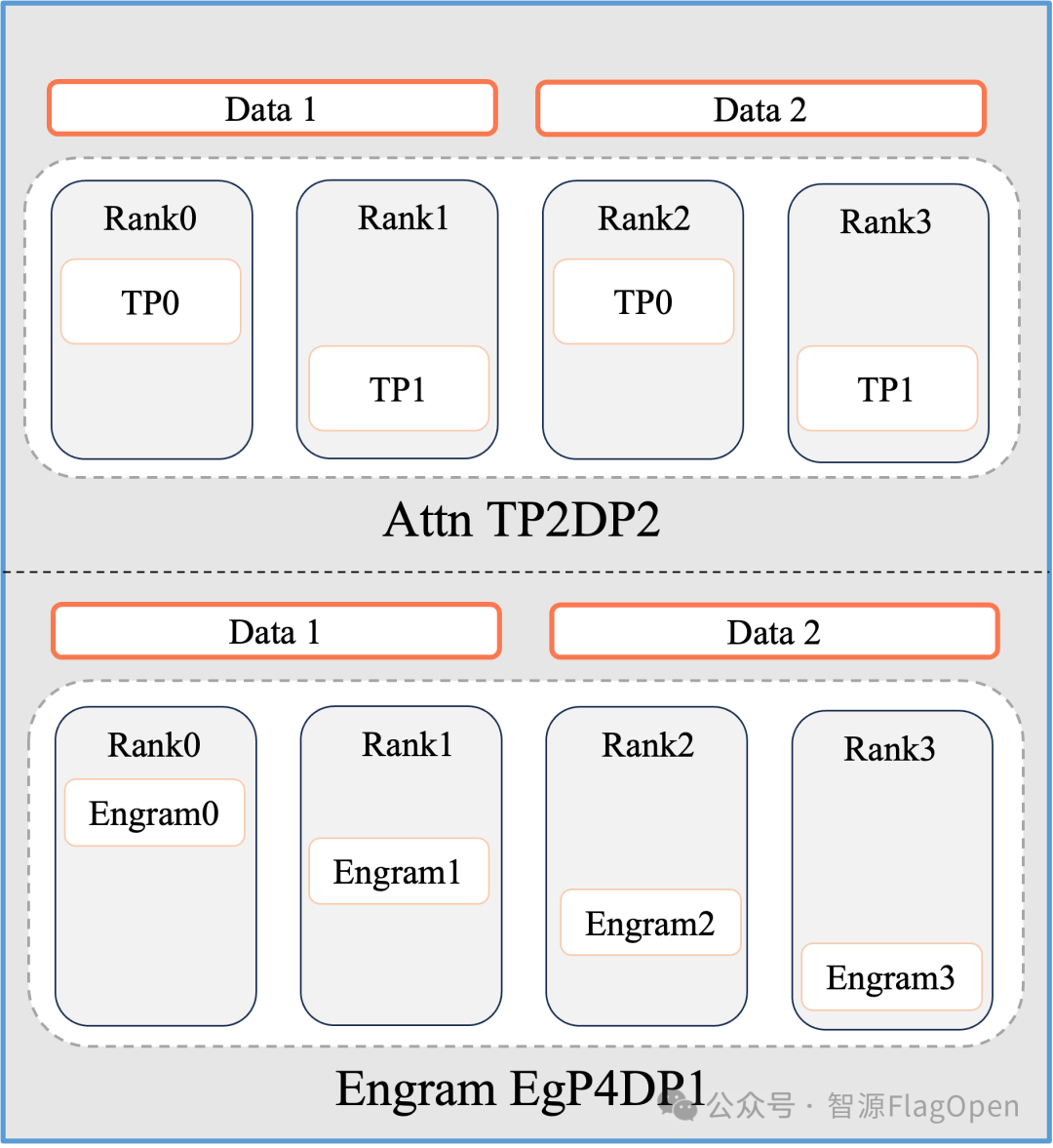
图1 engram 并行策略
2. 异步预取与计算重叠优化
依托 Engram 模块输入仅依赖 token_id、检索索引可在数据生成阶段提前确定的确定性特征,FlagScale 在包含 Engram 的前一层网络计算过程中,通过 CPU 异步预取后续所需的特征向量,实现 Hash 计算流程与模型主干计算的完全重叠,最终将 Engram 模块引入的端到端训练吞吐量损失控制在 3% 以内。
3.优化器状态分级卸载策略
针对 Engram embedding 参数量大、优化器状态占用显存量高,且仅分布在模型少量层的特性,FlagScale 采用精细化的分级卸载策略:仅将 Engram embedding 对应的优化器状态主动卸载至 CPU 内存完成参数更新,主干模型参数与优化器状态仍保留在 GPU 显存中。该方案带来的计算开销微乎其微,既有效解决了有限 GPU 卡量、长序列训练场景下的显存溢出(OOM)问题,也完全不影响骨干网络的核心计算效率。
4.2 关键实验验证结果
所有核心对比实验的主干模型为21B A4B(对齐 Engram Paper 官方模型规格),纯 MoE 基线模型为27B A4B,Engram embedding 大小扩展实验均基于 21B A4B 主干模型通过调整 Engram 参数量完成。实验可视化结果中,蓝色系为 FlagScale 优化后的结果,橙色系为优化前的基线结果;同一色系内不同数据代表不同训练配置下的吞吐表现,数值越高代表性能越优,所有结果均以相对加速比呈现。
-
算力效率翻倍:如图2所示,在 27B 模型的对比实验中,FlagScale 的两个并行解耦方案相比于传统Allreduce+张量并行(TP)中最好的baseline分别达到了其149.86%和144.67%的吞吐率;相比之下,传统的 Allreduce + 张量并行(TP)自身的各种配置差异较大,甚至出现大幅度掉速的情况。因此我们的并行解耦方案性能提升效果极其显著。
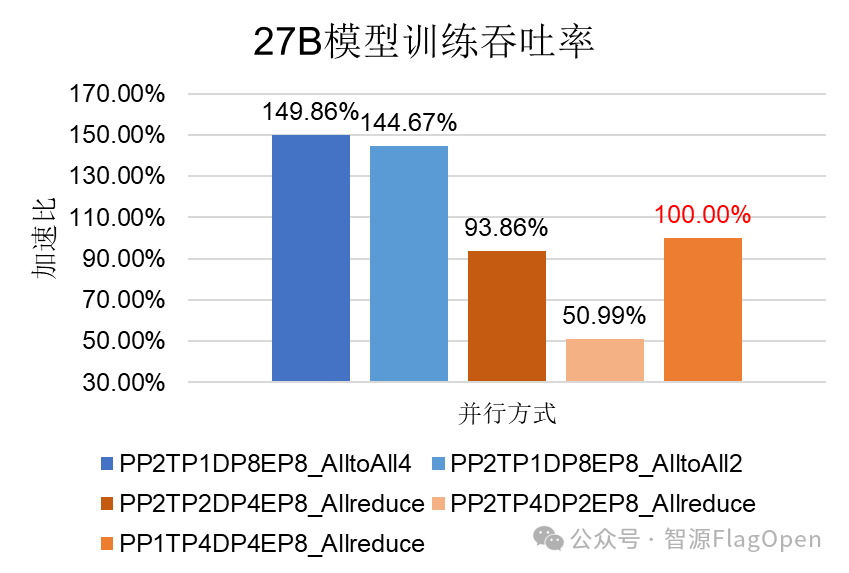
图2 并行解耦性能实验
-
额外负载“近乎零”:如图3实验显示,在 4k 到 16k 的不同序列长度下,Engram 模型的训练吞吐率与纯 MoE 模型几乎完全持平。这证明了 Engram 模块在提供强大记忆能力的同时,并不会给系统带来额外的计算负担。
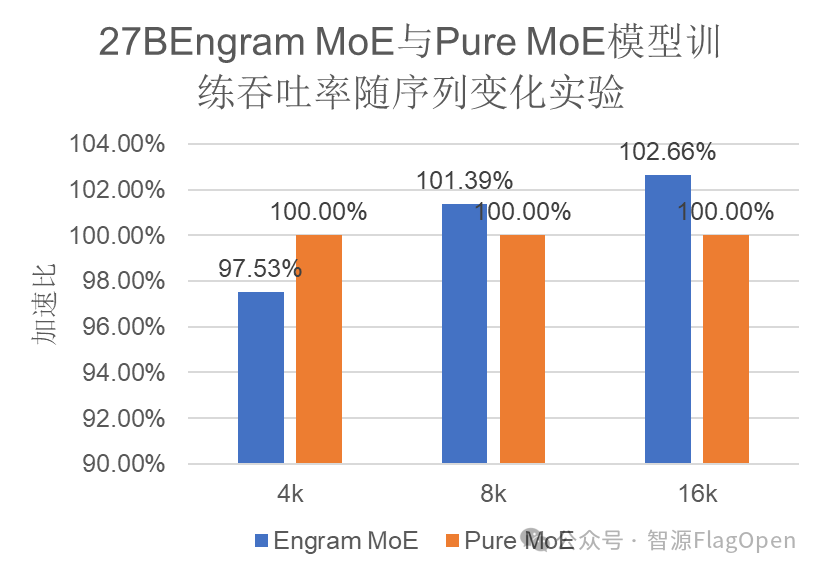
图3 Engram 与 纯MoE模型训练吞吐率
随序列长度变化的实验
-
最优参数区间划定:
如图4,通过扩展性实验发现,当 Engram 大小在模型主干参数量的一半以内时,性能表现最稳定,超过该阈值后性能快速劣化,划定了最优参数区间。
此外如图5,当专家参数占比降至 40% 并将冗余分配给 Engram 时,吞吐量达到峰值,优于原生纯MoE,是原生MoE模型训练吞吐率的104.16%,实现了“1+1>2”的正向收益。
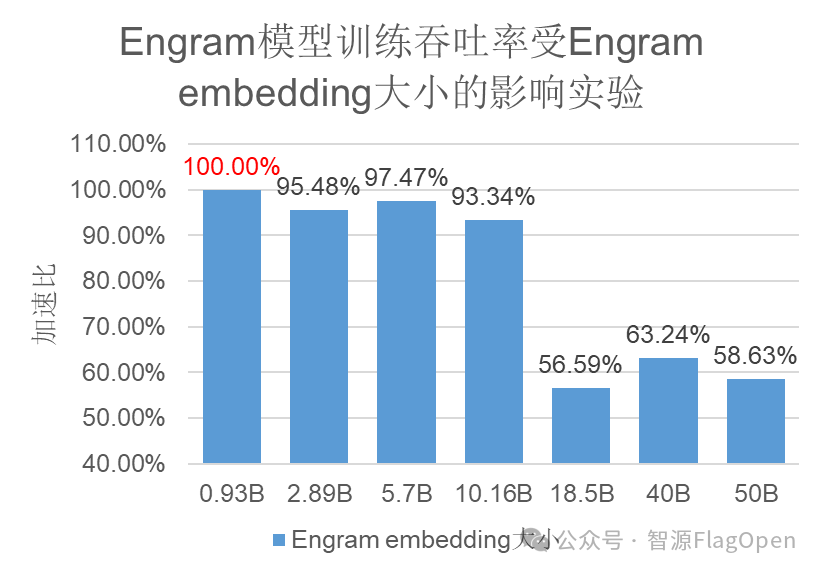
图4 Embedding大小扩展实验
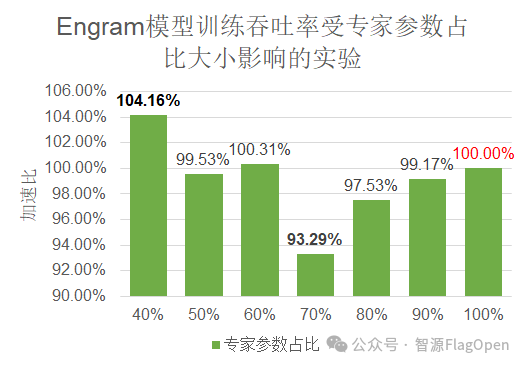
图5 训练吞吐率受专家占比影响的实验
5
开箱即用:
手把手教你在 FlagScale 上训练 Engram
FlagScale 训练插件针对 DeepSeek V3 架构完成了 Engram 模块的增量式训练适配,适配过程对模型主干训练逻辑无侵入,使用者无需关注 Engram 模块的底层实现细节,即可快速完成 Engram 增强模型的训练部署。
核心可配置参数
插件开放了全维度的 Engram 训练可配置参数,核心参数定义如下:
use_engram: bool = False # 决定是否启用Engram
engram_tokenizer_name_or_path: str | None = None # Engram的Tokenizer路径
engram_vocab_size: list[int] | None = None # Engram中每个n-gram的词表大小,列表参数。例如: [1131200, 1131200],代表Engram中包含2-gram和3-gram,词表大小都是1131200
max_ngram_size: int = 1 # Engram中最大的n-gram,比如3,即Engram中包含2-gram和3-gram,与engram_vocab_size对应
n_embed_per_ngram: int | None = None # Engram embedding的整体隐藏层维度
n_head_per_ngram: int = 1 # Engram 多头embedding的头数,n_embed_per_ngram = n_head_per_engram * embedding_size_per_head
engram_layer_ids: list[int] | None = None # Engram模块存在与模型的哪些层,列表参数,下标从0开始
engram_pad_id: int = 0 # Engram tokenizer的pad_id
engram_seed: int = 0 # 用于Engram Hash的随机数种子
engram_kernel_size: int = 1 # Engram中ShortConv的卷积核大小
engram_hc_mult: int = 1 # mHC维度,见 https://arxiv.org/pdf/2512.24880
engram_embedding_parallel_size: int | None = 1 # 为Engram embedding设计的独立并行维度,与传统词表并行的TP解耦,默认为1,仅在engram_embedding_parallel_method为allreduce时为None
engram_embedding_parallel_method: str = "alltoall" # Engram embedding的并行方式,alltoall代表并行解耦,allreduce代表使用传统词表并行(即TP)
engram_offload_embedding_optimizer_states: bool = False # 是否将Engram embedding的优化器状态卸载到CPU的开关,开启则全部卸载到CPU,需配合Megatron-FL的optimizer_cpu_offload一起使用。如果不需要全部卸载,也可以不启用这个开关,使用Megatron-FL的optimizer_offload_fraction参数进行部分卸载配置与使用建议
快速开启训练
用户在训练Engram时,可以使用提供的模型配置文件,确定主干模型后,只需令use_engram=True,FlagScale将自动完成主干模型和Engram模块的创建。用户可根据上述参数配置Engram各部分模块的情况。
高效训练建议
使用者完成主干模型的并行维度(PP/TP/EP)配置后,推荐将 engram_embedding_parallel_method 设置为 "alltoall" 以启用并行解耦优化,再结合 GPU 显存情况设置 engram_embedding_parallel_size 参数;若需进一步降低 Engram 模块的显存占用,可开启 engram_offload_embedding_optimizer_states 开关。
FlagScale 为 Engram 27B 模型训练提供了完整的可落地配置方案,详细配置可参考官方示例:
https://github.com/flagos-ai/FlagScale/blob/main/examples/deepseek_v3/conf/train.yaml
6
开启大模型“算存协同扩展”新时代
通过为 Engram 设计独立的 embedding 并行方案,我们在系统层面实现了计算与记忆的有效解耦:记忆模块以专属并行维度进行扩展,并配合更高效的通信与调度策略,显著降低了冗余开销。并行解耦后的 Engram 模型不仅未引入明显性能负担,反而能够以极低的额外开销对齐甚至在部分场景下超越纯 MoE 模型的整体性能。同时,结合基于确定性检索路径的异步预取与计算重叠技术,我们进一步将 memory 访问延迟有效隐藏,使 Engram 对训练主路径的影响降至最低。实验数据表明:在 10B 级别 Embedding(约为主干网络一半参数量)规模下,训练吞吐率仅下降约 7%;而在更小规模配置下,吞吐损失稳定控制在 4% 以内,整体性能表现高度接近纯 MoE 上限。
Engram 架构代表了大模型向高效知识存储与调用迈出的关键一步,而基于 FlagOS 核心组件 FlagScale 的统一训练插件能力,进一步验证了这一架构在真实工程环境中的可行性与可扩展性。通过对并行策略、通信机制与执行路径的协同优化,我们不仅实现了 Engram 的高效落地,也为其在大规模生产环境中的应用提供了一套可复用、可推广的技术参考路径。
参考资料
[1] X. Cheng et al., “Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models,” Jan. 12, 2026, arXiv: arXiv:2601.07372. doi: 10.48550/arXiv.2601.07372.
[2] Xie, Zhenda, et al. "mhc: Manifold-constrained hyper-connections." arXiv preprint arXiv:2512.24880 (2025).
点击阅读原文,了解更多FlagScale
关于众智FlagOS社区
为解决不同 AI 芯片大规模落地应用,北京智源研究院联合众多科研机构、芯片企业、系统厂商、算法和软件相关单位等国内外机构共同发起并创立了众智 FlagOS 社区。成员单位包括北京智源研究院、中科院计算所、中科加禾、安谋科技、北京大学、北京师范大学、百度飞桨、硅基流动、寒武纪、海光信息、华为、基流科技、摩尔线程、沐曦股份、澎峰科技、清微智能、天数智芯、先进编译实验室、移动研究院、中国矿业大学(北京)等多家在 FlagOS 软件栈研发中做出卓越贡献的单位。
FlagOS 是一款专为异构 AI 芯片打造的开源、统一系统软件栈,支持 AI 模型一次开发即可无缝移植至各类硬件平台,大幅降低迁移与适配成本。它包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,致力于构建「模型-系统-芯片」三层贯通的开放技术生态,通过“一次开发跨芯迁移”释放硬件计算潜力,打破不同芯片软件栈之间生态隔离。
官网:https://flagos.io
GitHub 项目地址:https://github.com/flagos-ai
GitCode 项目地址:https://gitcode.com/flagos-ai
SkillHub: https://skillhub.flagos.io


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)