彻底搞懂 Causal Forcing:实时交互式视频生成的因果蒸馏新范式
一、前言
2025 年以来,实时交互式视频生成成为 AIGC 领域最火热的方向之一:Google Genie 3 实现了可交互的 3D 世界建模,字节跳动 Motionstream 支持实时动作控制,腾讯 LiveAvatar 实现了毫秒级数字人生成。这些产品的核心技术底座,都是自回归(AR)视频扩散模型—— 它能逐帧流式输出,支持用户在生成过程中实时干预内容。
但长期以来,AR 视频扩散面临一个两难困境:
- 原生多步 AR 模型质量高,但速度慢,无法满足实时要求;
- 直接从双向模型蒸馏的少步 AR 模型速度快,但存在模糊、动态丢失、时序断裂等致命问题。
2026 年 2 月,清华大学朱军团队提出的 Causal Forcing 彻底打破了这个僵局。它从帧级单射性这一理论根源出发,重构了自回归扩散蒸馏的完整流程,在保持 17FPS 实时推理速度的同时,较此前 SOTA 的 Self Forcing 实现了 ** 动态度 + 19.3%、视觉奖励 + 8.7%、指令遵循 + 16.7%** 的跨越式提升,综合表现甚至超越了原始双向模型 Wan2.1。
本文将从理论本质 + 工程实现 + 落地实践三个维度,完整解析 Causal Forcing 的核心思想,帮你彻底搞懂这个视频生成领域的最新突破。
二、背景:双向→AR 蒸馏的百年孤独
2.1 为什么我们必须用 AR 架构?
传统双向视频扩散模型(如 Wan2.1、CogVideoX)采用全注意力机制,生成时必须一次性计算所有帧的注意力,这带来了三个无法解决的问题:
- 延迟爆炸:生成 81 帧视频需要 103 秒(单卡 H100),完全无法实时;
- 无法流式输出:必须等所有帧生成完才能展示给用户;
- 无交互能力:用户无法修改已生成的内容来影响后续生成。
而 AR 视频扩散模型采用因果注意力机制,严格保证第 i 帧只依赖前 i-1 帧,完美解决了上述问题:
- 生成一帧输出一帧,用户看到第一帧的时间仅需 0.05 秒;
- 支持实时交互:用户可以擦除、修改已生成的帧,模型会基于新的历史继续生成;
- 可无限生成长视频:理论上可以生成任意长度的视频,不会出现内存爆炸。
这就是为什么所有实时交互式视频生成产品,无一例外都采用 AR 架构。
2.2 前 SOTA Self Forcing 的致命缺陷
为了兼顾质量和速度,行业主流方案是将预训练好的高质量双向模型蒸馏为少步 AR 模型,其中最具代表性的就是 2025 年提出的 Self Forcing。它采用两阶段流程:
- ODE 初始化:用双向教师生成 PF-ODE 轨迹,训练 AR 学生直接从噪声回归干净帧;
- DMD 精调:用分布匹配蒸馏进一步提升生成质量。
但 Self Forcing 存在一个理论上的致命缺陷:它试图用一步同时完成两个完全独立的任务:
- 任务 1:架构转换(双向全注意力 → 因果单向注意力);
- 任务 2:速度蒸馏(多步扩散 → 少步 ODE 映射)。
这两个任务的约束条件是冲突的:双向教师的 PF-ODE 只满足视频级单射,而 AR 学生需要的是帧级单射。强行耦合的结果就是:同一个噪声帧对应多个干净帧,AR 学生只能学习条件期望,最终生成模糊、动态丢失的视频。
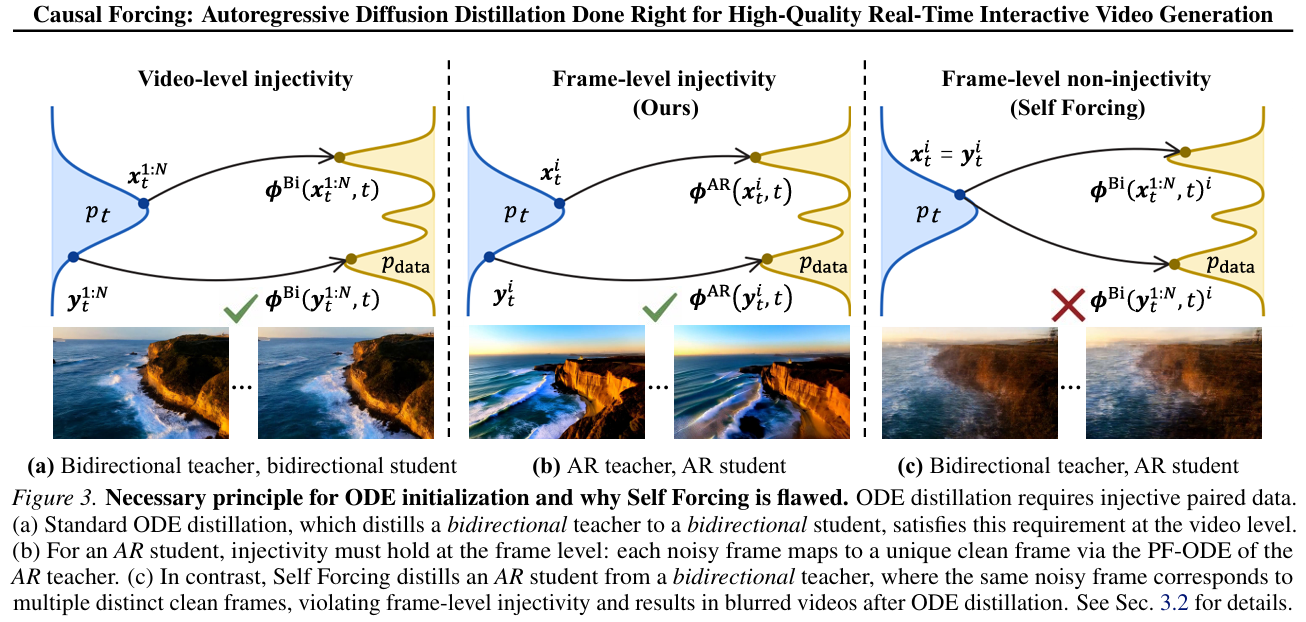
2.3 什么是帧级单射性?(论文核心理论)
单射性是数学中的一个基本概念:对于一个函数 f (x),如果 x1≠x2,则 f (x1)≠f (x2),那么 f 就是单射函数。
在扩散蒸馏中,单射性是 ODE 蒸馏有效的必要条件:
- 视频级单射:整条噪声视频 x_t^1:N 对应唯一的干净视频 x_0^1:N,双向教师满足这一点;
- 帧级单射:任意单个噪声帧 x_t^i 对应唯一的干净帧 x_0^i,只有 AR 教师满足这一点。
Self Forcing 用双向教师蒸馏 AR 学生,本质上是用一个只满足视频级单射的函数,去拟合一个需要帧级单射的函数,这在数学上是不可能的。这就是为什么无论怎么调参、怎么增加训练步数,Self Forcing 的生成质量始终无法追上双向模型。
三、核心概念扫盲:4 个 Forcing + 3 种蒸馏 全解析
3.1 四大 Forcing:从训练策略到蒸馏方案
很多人容易混淆这四个概念,我用一张表把它们的本质、适用场景和优缺点讲清楚:
| 方法 | 提出时间 | 类型 | 核心做法 | 解决的核心问题 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
| Teacher-Forcing(TF) | 2024 | AR 训练策略 | 训练时输入干净真实历史帧 | 消除 AR 模型的训练 - 推理分布不匹配 | 训练稳定、生成质量高 | 多步采样速度慢 |
| Diffusion-Forcing(DF) | 2024 | AR 训练策略 | 训练时输入带噪声的历史帧 | 让模型适应噪声前缀,支持长视频延续 | 适合长视频生成 | 训练 - 推理分布错位,生成易坍塌 |
| Self-Forcing(SF) | 2025 | 蒸馏方案 | 双向教师→ODE 初始化→DMD 精调 | 将慢双向模型蒸馏为快 AR 模型 | 速度快、实现简单 | 违反帧级单射,生成模糊、动态差 |
| Causal-Forcing(CF) | 2026 | 蒸馏方案 | TF 训练 AR 教师→因果 ODE→DMD 精调 | 弥合双向→AR 的架构鸿沟,满足帧级单射 | 质量高、速度快、动态强 | 训练流程稍复杂 |
🔴 关键误区纠正:Diffusion Forcing 不是完全没用,它在双向模型的长视频延续任务中表现很好,但在AR 模型的训练和蒸馏中,它会导致严重的分布错位,这是 Causal Forcing 论文中重点批判的一点。
3.2 三种蒸馏方式:各自的定位和分工
所有将多步扩散模型转为少步模型的方法,都可以归为这三类,它们不是竞争关系,而是互补关系:
-
ODE 蒸馏(概率流常微分方程蒸馏)
- 本质:直接拟合扩散模型的 PF-ODE 轨迹,学习 "噪声→干净帧" 的直接映射;
- 损失函数:MSE 回归损失;
- 核心要求:必须满足单射性,否则学出的是条件期望(模糊);
- 定位:蒸馏的初始化阶段,搭建基础的流映射。
-
一致性蒸馏(Consistency Distillation)
- 本质:学习稳定的流映射,让模型从任意时间步的噪声出发,最终都收敛到同一个干净结果;
- 损失函数:相邻时间步输出的一致性损失;
- 核心优势:无需预生成和存储大规模 ODE 轨迹,节省存储和计算;
- 定位:ODE 蒸馏的替代方案,适合存储资源有限的场景。
-
分数蒸馏(Score Distillation)
- 本质:对齐学生模型的生成分布与真实数据分布;
- 典型实例:DMD(Distribution Matching Distillation);
- 核心作用:精调模型,提升视觉真实感、纹理细节和指令遵循能力;
- 定位:蒸馏的精调阶段,在合格的初始化基础上做优化。
🟢 论文核心结论:DMD 无法修复架构鸿沟。如果 ODE 初始化阶段违反了帧级单射性,无论怎么用 DMD 精调,都无法解决模糊和动态丢失的问题。这就是为什么 Self Forcing 即使加了 DMD,性能还是远不如 Causal Forcing。
四、Causal Forcing 核心原理:解耦是第一生产力
4.1 核心创新:解耦架构转换与速度蒸馏
Causal Forcing 的核心思想非常简单但极其有效:把 Self Forcing 中耦合的两个任务,拆成两个独立的阶段,每个阶段只解决一个问题。
| 阶段 | 解决的问题 | 具体做法 | 约束条件 |
|---|---|---|---|
| 阶段 1(新增) | 仅做架构转换 | 用 Teacher-Forcing 训练一个纯 AR 多步扩散教师 | 只要求架构是因果的,不要求少步 |
| 阶段 2 | 仅做速度蒸馏 | 用这个纯 AR 教师生成 PF-ODE 轨迹,做因果 ODE 蒸馏 | 只要求多步转少步,不做架构转换 |
| 阶段 3 | 仅做质量精调 | 用非对称 DMD 进一步提升生成质量 | 只优化分布,不改变架构 |
解耦之后,用于 ODE 蒸馏的教师本身就是 AR 架构,其 PF-ODE 天然满足帧级单射性,从根源上解决了 "一个噪声帧对应多个干净帧" 的问题。
4.2 三阶段完整 Pipeline(论文工程实现细节)
论文基于 Wan2.1-T2V-1.3B 基础模型,完整的训练流程如下:
阶段 1:Teacher-Forcing 训练 AR 多步教师
- 数据集:用双向模型 Wan2.1 生成 3K 个合成视频样本(基于 VidProM 数据集的提示词);
- 训练设置:batch size=64,学习率 = 2e-6,训练 2000 步;
- 输入格式:
[干净历史latent x0^i + 当前噪声latent xt^i],用因果注意力 mask 保证 xt^i 只能看到 x0^<i; - 核心优势:训练时用干净历史,推理时也用干净历史,完全消除了训练 - 推理分布不匹配。
阶段 2:因果 ODE 蒸馏
- 生成 ODE 轨迹数据集:用训练好的 AR 教师,为每个样本生成完整的 PF-ODE 轨迹,存储 4 个关键时间步(t=1, 0.9375, 0.8333, 0.625)的配对数据;
- 训练设置:batch size=64,学习率 = 2e-6,训练 1000 步;
- 损失函数:
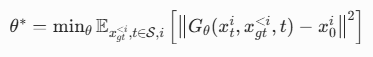
- 核心优势:AR 教师的 PF-ODE 天然满足帧级单射性,学生模型能精准学习真实的流映射,不会出现模糊。
阶段 3:非对称 DMD 精调
- 教师设置:S_real 用 Wan2.1-14B(大模型提供高质量分数),S_fake 用 Wan2.1-1.3B;
- 训练设置:batch size=64,学习率 = 2e-6,训练 750 步;
- 核心作用:对齐生成分布与真实数据分布,提升纹理细节、色彩还原和指令遵循能力。
📌 总训练步数:2000+1000+750=3750 步,和 Self Forcing 的训练预算完全相同,但性能提升巨大。
4.3 可选方案:因果一致性蒸馏
论文还提出了因果一致性蒸馏作为因果 ODE 蒸馏的替代方案,它不需要预生成 ODE 轨迹,适合存储资源有限的场景:
- 损失函数:
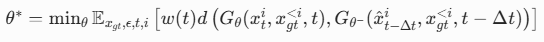
- 核心优势:零存储开销,总计算量比因果 ODE 蒸馏小 30%;
- 性能差异:最终 DMD 精调后的性能比因果 ODE 蒸馏低约 1%,几乎可以忽略不计。
五、关键问题深度解析(论文灵魂 + 工程实践)
5.1 什么是 ODE 轨迹?怎么生成?(附伪代码)
ODE 轨迹就是确定性采样器从高斯噪声走到干净帧过程中,所有时间步的中间含噪状态的集合。
它有两个核心特性:
- 确定性:同一个起点 x_T,永远走到同一个终点 x_0;
- 单射性:轨迹上任意一个中间点 x_t,唯一对应终点 x_0。
下面是生成 AR 教师 ODE 轨迹的极简 PyTorch 伪代码:
def generate_ode_trajectory(ar_teacher, clean_history, num_steps=50):
"""
生成AR教师的PF-ODE轨迹
Args:
ar_teacher: 训练好的AR多步扩散教师模型
clean_history: 干净历史帧latent [batch, 3*H*W]
num_steps: ODE求解步数
Returns:
trajectory: ODE轨迹,包含所有时间步的含噪帧 [num_steps+1, batch, 3*H*W]
"""
# 初始化高斯噪声(轨迹起点)
x = torch.randn_like(clean_history[:, :3*H*W])
trajectory = [x.clone()]
# 时间步从1到0
timesteps = torch.linspace(1, 0, num_steps+1)
for i in range(num_steps):
t = timesteps[i]
dt = timesteps[i+1] - t
# AR教师预测速度场
v = ar_teacher(x, clean_history, t)
# 欧拉法积分,得到下一个时间步的含噪帧
x = x + v * dt
trajectory.append(x.clone())
# trajectory[-1] 就是干净帧x0
return trajectory
5.2 为什么因果 ODE 需要预生成轨迹,因果一致性不需要?
- 因果 ODE 蒸馏:它的损失是 MSE 回归,需要固定的 x0 标签。如果不预生成轨迹,每次训练迭代都要跑一遍完整的 50 步 ODE 求解,计算量会爆炸(训练 1000 步就是 50000 步 ODE 计算)。预生成轨迹后,训练时直接从硬盘读取数据,不需要再跑教师模型,训练速度极快。
- 因果一致性蒸馏:它的损失是相邻时间步的一致性约束,不需要任何固定的 x0 标签。训练时只需要用教师模型跑一步 ODE,得到相邻的两个时间步,就可以计算损失。因此可以在线生成数据,不需要预生成和存储任何轨迹。
5.3 为什么双向模型的 "伪流式" 永远打不过 AR 的 "真流式"?
很多人会问:我让双向模型每次生成 3 帧的极短视频,生成完一个就输出一个,不就可以模拟流式生成了吗?
这确实是早期很多视频生成服务采用的 "伪流式" 方案,但它和 AR 的真流式有本质区别,存在 4 个致命缺陷:
| 维度 | 双向伪流式 | AR 真流式 |
|---|---|---|
| 延迟 | 总延迟随视频长度线性增加,生成 81 帧需要 2.7 秒 | 总延迟恒定,生成 81 帧需要 1.35 秒 |
| 首帧时间 | 0.1 秒(必须等第一个 3 帧生成完) | 0.05 秒(生成第一帧就输出) |
| 交互性 | 无,无法用历史帧影响未来生成 | 强,可实时修改历史帧 |
| 时序一致性 | 差,chunk 之间易出现人物 / 场景突变 | 好,天然上下文依赖 |
| KV Cache 复用 | 不能,每个 chunk 都是独立任务 | 能,复用所有历史计算 |
| 长视频扩展性 | 差,越长延迟越高 | 好,延迟不随长度增加 |
🔴 最核心的区别:双向模型无法复用任何历史计算结果。生成第 100 个 chunk 时,它的计算量和生成第 1 个 chunk 完全相同;而 AR 模型生成第 100 个 chunk 时,只需要计算 3 个新 token 的 Q,计算量几乎不变。
5.4 为什么不用 AR 模型直接训练少步模型,还要蒸馏?
这是一个非常好的问题。答案是:直接训练少步 AR 模型的质量远不如蒸馏。
原因有两个:
- 数据效率低:少步扩散模型的训练难度远高于多步模型,需要更多的数据和更长的训练时间;
- 知识迁移难:预训练双向模型已经学习了海量的视觉知识,蒸馏可以把这些知识高效地迁移到 AR 模型中,而直接训练 AR 模型需要从头学习所有知识。
Causal Forcing 的优势就在于:它既保留了蒸馏的知识迁移优势,又解决了双向→AR 蒸馏的架构鸿沟问题。
六、实验结果:全面碾压 SOTA
论文在 VBench 基准上进行了全面的评估,所有方法都在单卡 H100 上测试,推理设置为 4 步采样。
6.1 与所有基线模型的对比
| 模型 | 吞吐量(FPS) | 延迟(s) | 动态度 | VisionReward | 指令遵循 | 用户评分 |
|---|---|---|---|---|---|---|
| 双向模型 | ||||||
| Wan2.1-1.3B | 0.78 | 103 | 61 | 5.275 | 42 | 2.29 |
| LTX-1.9B | 8.98 | 13.5 | 46 | -6.218 | -38 | 6.40 |
| 原生 AR 模型 | ||||||
| NOVA | 0.88 | 4.1 | 46 | -7.381 | -16 | 8.41 |
| Pyramid Flow | 6.70 | 2.5 | 16 | 4.055 | -2 | 6.11 |
| 蒸馏 AR 模型 | ||||||
| CausVid | 17.0 | 0.69 | 62 | 5.741 | 12 | 4.27 |
| Self Forcing | 17.0 | 0.69 | 57 | 5.820 | 48 | 2.87 |
| Causal Forcing(Ours) | 17.0 | 0.69 | 68 | 6.326 | 56 | 1.64 |
核心结论:
- Causal Forcing 在保持和 Self Forcing 完全相同的推理速度(17FPS,0.69s 延迟)的同时,在所有指标上全面超越 Self Forcing;
- Causal Forcing 的综合表现甚至超越了原始双向模型 Wan2.1-1.3B,实现了 "速度快 10 倍,质量更高" 的奇迹;
- 用户评分达到 1.64(越低越好),是所有模型中最好的,说明人类主观感受也认为 Causal Forcing 的生成质量最高。
6.2 关键消融实验
论文做了大量的消融实验,验证了各个模块的有效性:
-
Teacher Forcing vs Diffusion Forcing
方法 动态度 VisionReward 指令遵循 Diffusion Forcing 60 1.583 30 Teacher Forcing 50 3.343 32 结论:Teacher Forcing 的 VisionReward 提升了 111.2%,证明了它在 AR 训练中的优越性。 -
不同初始化方式对 DMD 的影响
初始化方式 动态度 VisionReward 指令遵循 Self Forcing ODE + DMD 24 3.330 38 AR 教师直接初始化 + DMD 66 5.863 48 因果 ODE 初始化 + DMD 68 6.326 56 结论:因果 ODE 初始化是最优的,证明了解耦架构转换和速度蒸馏的有效性。
七、工程落地建议
7.1 复现指南
基于论文的开源代码(https://thuml.github.io/CausalForcing.github.io/),你可以按照以下步骤复现 Causal Forcing:
- 下载预训练的 Wan2.1-T2V-1.3B 模型;
- 用 Wan2.1 生成 3K 个合成视频样本,构建数据集 D_Bi;
- 用 Teacher-Forcing 训练 AR 多步教师,2000 步;
- 用 AR 教师生成 ODE 轨迹数据集 D_Causal;
- 进行因果 ODE 蒸馏,1000 步;
- 进行非对称 DMD 精调,750 步;
- 用 4 步采样进行推理。
7.2 蒸馏方式选择建议
- 如果你的存储资源充足(有几十 GB 的空闲空间),优先选择因果 ODE 蒸馏,它的训练更稳定,最终质量略高;
- 如果你的存储资源有限,或者想加快训练速度,选择因果一致性蒸馏,它的性能损失可以忽略不计;
- 无论选择哪种初始化方式,都必须加上DMD 精调,它能显著提升视觉质量和指令遵循能力。
八、总结与展望
8.1 核心总结
Causal Forcing 的成功,本质上是理论指导实践的胜利。它没有引入任何复杂的新模块,只是通过解耦架构转换与速度蒸馏这一简单的思想,从根源上解决了自回归扩散蒸馏的核心难题。
它的核心贡献可以用三句话概括:
- 指出了双向→AR 蒸馏失败的根源:违反帧级单射性;
- 提出了 Causal Forcing 蒸馏框架:用 AR 教师做因果 ODE 蒸馏,满足帧级单射性;
- 实现了实时视频生成的质的飞跃:速度快 10 倍,质量超越双向模型。
8.2 未来展望
Causal Forcing 为实时交互式视频生成打开了新的大门,未来的研究方向包括:
- 更长视频生成:将 Causal Forcing 应用于分钟级甚至小时级的长视频生成;
- 3D 视频生成:将因果蒸馏思想扩展到 3D 视频扩散模型,实现实时可交互的 3D 世界建模;
- 端侧部署:进一步压缩模型大小,将 Causal Forcing 模型部署到手机等端侧设备上;
- 多模态交互:支持文本、图像、语音等多种模态的实时交互控制。
九、常见问题 FAQ
-
Causal Forcing 能不能用在图像生成上?不能。因为图像生成不需要自回归架构,双向模型已经足够快,不需要蒸馏为 AR 模型。Causal Forcing 是专门为视频生成设计的。
-
为什么论文用合成数据集训练 AR 教师,不用真实数据集?因为合成数据集的质量更高,而且可以和双向教师的分布完全对齐,蒸馏效果更好。用真实数据集训练 AR 教师也是可以的,但需要更多的数据和更长的训练时间。
-
Causal Forcing 的推理速度能不能进一步提升?可以。通过量化、剪枝、TensorRT 加速等技术。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 18
18 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)