【 LangChain v1.2 入门系列教程】【七】中间件——给 Agent 装上“外挂“
系列文章目录
【 LangChain v1.2 入门系列教程】【一】开篇入门 | 从零开始,跑通你的第一个 AI Agent
【 LangChain v1.2 入门系列教程】【二】消息类型与提示词工程
【 LangChain v1.2 入门系列教程】【三】工具(Tools)开发,让 Agent 连接外部世界
【 LangChain v1.2 入门系列教程】【四】结构化输出,让 Agent 返回可预测的结构
【 LangChain v1.2 入门系列教程】【五】记忆管理,让 Agent 记住对话
【 LangChain v1.2 入门系列教程】【六】流式输出, 让 Agent 告别“想好了再说”
【 LangChain v1.2 入门系列教程】【七】中间件——给 Agent 装上"外挂"
文章目录
前言
在 LangChain 智能体开发中,Agent 核心执行逻辑是固定闭环的,而中间件(Middleware)是实现 Agent 能力扩展、流程管控、安全兜底的核心方案。本文将继续介绍中间件核心概念、生命周期、使用方法以及内置中间件应用。
一、为什么需要中间件?
想象你正在开发一个 AI 客服 Agent。上线前,你需要解决一堆"周边问题":
- 用户输入里会不会泄露手机号、身份证号?
- 调用外部 API 失败了怎么办,要不要重试?
- 对话太长超出模型上下文了,怎么自动压缩?
- 每次调用都要记日志,难道在每个工具里写 print?
传统做法是把这些逻辑硬编码到 Agent 或工具内部——代码臃肿、耦合严重、复用困难。
LangChain v1.2 的中间件(Middleware) 提供了一个更优雅的方案:在 Agent 执行的全链路中插入自定义逻辑,实现无侵入式的功能扩展。就像给 Web 框架加中间件一样,你可以在不修改核心 Agent 代码的情况下,给它"外挂"各种能力。
二、Agent 完整执行生命周期
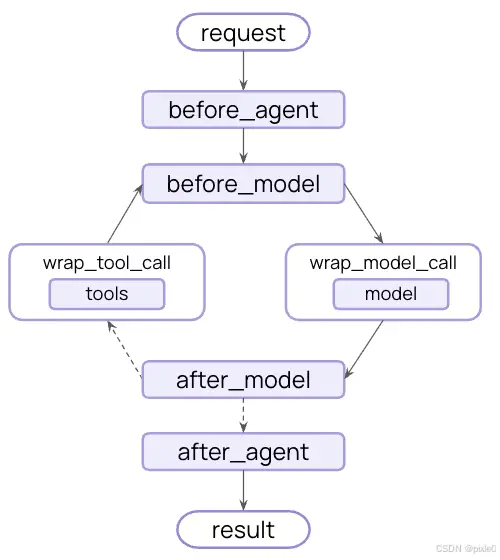
LangChain v1.2 重构了中间件生命周期,标准化了全链路钩子节点,完整执行顺序如下:
Agent启动 → 前置钩子(before_agent) → 模型调用前置(before_model) → 模型调用包装(wrap_model_call) → LLM 执行 → 模型响应后置(after_model) → 工具调用包装(wrap_tool_call) → 工具执行 → Agent结束后置(after_agent)
所有中间件逻辑均挂载在上述生命周期节点中,精准拦截任意执行环节。官方将钩子分为两大类,适配不同开发场景:
- 节点型钩子(before_* / after_*):顺序执行,适用于日志、校验、状态更新等同步逻辑
- 包装型钩子(wrap_*):像洋葱一样层层包裹,嵌套拦截,可控制执行次数、短路终止,适用于重试、缓存、降级等流程控制逻辑
| 钩子类型 | 执行时机 | 典型用途 |
|---|---|---|
before_agent |
Agent 开始执行前(每个请求触发一次) | 初始化、参数校验、权限检查 |
before_model |
每次调用模型前 | 修改 Prompt、动态选模型、日志 |
wrap_model_call |
包裹每次模型调用 | 重试、缓存、熔断、模型降级 |
wrap_tool_call |
包裹每次工具调用 | 工具重试、超时、监控 |
after_model |
每次模型返回后 | 结果加工、敏感信息过滤 |
after_agent |
Agent 执行结束后(每个请求触发一次) | 清理、最终日志、统计 |
例如:
@before_model
def log_before_model(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
#日志记录
print(f"即将调用模型,当前对话消息数:{len(state['messages'])}")
return None
三、如何注册中间件
注册中间件非常简单,你只需在 create_agent 函数的 middleware 参数中传入一个中间件列表即可。执行顺序就按列表顺序。LangChain v1.2 提供了一批生产级的内置中间件可以直接注册使用也可以通过钩子自定义中间件。均通过以下方式注册到 Agent,无额外配置:
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware #系统自带中间件(自动摘要总结)
#自定义中间件
@before_model
def log_before_model(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
#日志记录
print(f"即将调用模型,当前对话消息数:{len(state['messages'])}")
return None
# 注册多个中间件,按数组顺序生效
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[
# 多个中间件依次填写
SummarizationMiddleware(), #自动摘要总结中间件
log_before_model, #自定义中间件
A,
B,
....
]
)
四、通过装饰器自定义中间件示例
4.1动态切换模型
生产级 Agent 必备能力:根据用户等级(普通用户、vip用户)或者根据对话复杂度、Token 长度、任务难度动态切换大/小模型,简单任务用轻量模型降本,复杂任务用高精度模型保效果,兼顾成本与体验。基于 wrap_model_call 包装钩子实现,可拦截并替换模型实例。
根据用户等级切换模型示例:
import os
from typing import Callable, NotRequired
from dotenv import load_dotenv
from langchain.agents import AgentState, create_agent
from langchain.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
load_dotenv()
# 自定义 Agent 状态,继承自基础 AgentState(已包含 messages 等字段)
class CustomStatus(AgentState):
# 扩展字段:用户等级,0 表示普通用户,1 表示 VIP 用户
# NotRequired 表示该字段是可选的,调用时可以不传
user_level: NotRequired[int]
# 轻量低成本模型(用于普通用户)
simple_llm = ChatOpenAI(
model="qwen2.5-7b-instruct",
base_url=os.getenv("AL_BASE_URL"),
api_key=os.getenv("AL_API_KEY"),
)
# 高精度复杂模型(用于 VIP 用户)
complex_llm = ChatOpenAI(
model="deepseek-chat",
base_url=os.getenv("DEEP_BASE_URL"),
api_key=os.getenv("DEEP_API_KEY"),
)
# 动态模型切换中间件
@wrap_model_call
def dynamic_model_selector(
request: ModelRequest, handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
# 获取用户等级
user_level = request.state.get("user_level", 0)
# 普通用户使用轻量低成本模型
if user_level == 0:
target_model = simple_llm
# vip用户使用高精度复杂模型
else:
target_model = complex_llm
return handler(request.override(model=target_model))#替换模型参数
agent = create_agent(
model=simple_llm, # 默认模型,会被中间件动态覆盖
state_schema=CustomStatus, #传入自定义状态模式,使 user_level 成为合法状态字段
middleware=[dynamic_model_selector] #注册中间件
)
response = agent.invoke({
"messages": [HumanMessage("你好,你是谁")],
"user_level": 1 #VIP 用户
})
print(response['messages'][-1].content)
@wrap_model_call 入参和返回值说明:
参数:
-
request:封装了本次模型调用的完整上下文(messages、system_message、tools、model、state 等)。
-
handler:一个可调用对象,执行后将返回模型的原始响应。你必须自己决定何时以及如何调用它(例如直接调用、重试调用、或跳过不调用)。
返回:
必须返回 ModelResponse(或 ExtendedModelResponse,用于同时更新状态)。
不能改变参数个数或名称,但可以通过装饰器的 state_schema 参数约束 request.state 的类型。
4.2 历史消息修剪
多轮交互的 Agent 场景,避免上下文无限膨胀,需要动态对历史消息进行修剪,只保留首条+最新n条
import os
from typing import Callable
from dotenv import load_dotenv
from langchain.agents import AgentState, create_agent
from langchain.messages import HumanMessage, RemoveMessage
from langchain_openai import ChatOpenAI
from langchain.agents.middleware import (
Runtime,
after_model,
before_model,
wrap_model_call,
ModelRequest,
ModelResponse,
)
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph.message import REMOVE_ALL_MESSAGES
load_dotenv()
llm = ChatOpenAI(
model="qwen2.5-7b-instruct",
base_url=os.getenv("AL_BASE_URL"),
api_key=os.getenv("AL_API_KEY"),
)
#修剪消息历史中间件
@before_model
def trim_messages(state: AgentState, runtime: Runtime) -> dict[str, any] | None:
"""
保留首条消息和最近10条消息,移除中间的冗余消息,使对话总长度控制在合理范围内。
"""
messages = state["messages"]
# 如果消息数量不超过 11 条,不需要修剪
if len(messages) < 11:
return None # 返回 None 表示不修改状态
else:
first_message = messages[0] # 始终保留第一条消息(可能是系统消息/用户初始信息)
recent_messages = messages[-10:] # 留最后 10 条
# 拼接新的消息列表
new_messages = [first_message] + recent_messages
return {
"messages": [
RemoveMessage(
id=REMOVE_ALL_MESSAGES
), # 清除全部历史消息(使用内置删除标记)
*new_messages, # 展开保留的消息
],
}
#获取历史消息数量中间件
@wrap_model_call
def check_messages(
request: ModelRequest, handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
messages = request.state.get("messages", )
print(f"历史消息长度:{len(messages)}",'dynamic_model_selector')
return handler(request)
#短期记忆存储
checkpointer=InMemorySaver()
agent = create_agent(
system_prompt="你是一个智能助手,根据用户提问回答问题", #系统提示词
model=llm, # 模型
middleware=[trim_messages,check_messages], #注册中间件
checkpointer=checkpointer
)
while True:
answer=input('【提问】:请输入问题')
res=agent.invoke({
"messages":HumanMessage(answer),
},config={"configurable": {"thread_id": "1"}})
print(f"【回答】 :{res['messages'][-1].content}",end="\n",flush=True)
@before_model入参和返回值说明:
参数:
-
state:当前完整的 Agent 状态字典(默认包含 messages 等)。
-
runtime:当前运行时对象,可获取 config、thread_id 等信息。
返回:
-
返回 dict 会合并到 Agent 状态中(例如添加消息或跳转指令)。
-
返回 None 表示不修改状态。
4.3 动态提示词中间件
LangChain v1.2 专门提供了@dynamic_prompt专属中间件装饰器,是官方标准化的动态提示词实现方案,相比 before_model 手动替换提示词更简洁、更稳定、优先级更高。核心作用是:在 Agent 每次执行前动态生成、覆盖、更新系统提示词,彻底解决静态提示词固化、无法适配场景变化的痛点。
适用于多角色切换、场景自适应、对话阶段差异化、用户权限区分等生产场景,无需改动 Agent 核心逻辑,纯中间件无侵入实现。
import os
from typing import NotRequired
from dotenv import load_dotenv
from langchain.agents import AgentState, create_agent
from langchain_openai import ChatOpenAI
from langchain.agents.middleware import (
dynamic_prompt,
ModelRequest,
)
load_dotenv()
# 自定义 Agent 状态,继承自基础 AgentState(已包含 messages 等字段)
class CustomStatus(AgentState):
# 扩展字段:用户角色,admin 表示管理员,beginner 表示 普通用户 ,expert 表示专家用户
# NotRequired 表示该字段是可选的,调用时可以不传
user_role: NotRequired[str]
llm = ChatOpenAI(
model=os.getenv("MODEL_NAME"),
base_url=os.getenv("QWEN_BASE_URL"),
api_key=os.getenv("API_KEY"),
)
#动态提示词中间件
@dynamic_prompt
def user_role_prompt(request: ModelRequest) -> str:
"""根据用户角色动态生成系统提示词"""
# 从运行时上下文获取自定义角色参数,默认普通用户
user_role = request.state.get("user_role", "beginner")
base_prompt = "你是专业的LangChain v1.2智能体开发助手。"
# 角色差异化 Prompt
if user_role == "expert":
print("庄家")
return f"{base_prompt} 输出专业、详尽、带源码解析、带底层原理的技术回答。"
elif user_role == "beginner":
return f"{base_prompt} 语言通俗易懂,避免专业黑话,步骤清晰,新手友好。"
elif user_role == "admin":
return f"{base_prompt} 开启调试模式,输出完整日志、报错分析、优化方案。"
return base_prompt
agent = create_agent(
state_schema=CustomStatus,
model=llm, # 模型
middleware=[user_role_prompt], # 注册中间件
)
说明:
- 优先级:@dynamic_prompt > create_agent system_prompt > before_model 手动拼接。
五、框架自带中间件
5.1 上下文摘要中间件(SummarizationMiddleware)
解决长对话 Token 溢出问题,达到阈值自动压缩历史对话,保留最新上下文,适配多轮长对话场景。
from langchain.agents.middleware import SummarizationMiddleware
agent = create_agent(
model=llm, # 模型
checkpointer=checkpointer,
middleware=[
SummarizationMiddleware(
model=llm,
# 触发条件:token >= 4000 或消息数 >= 20 任一满足
trigger=[
("tokens", 4000),
("messages", 20),
] ,
keep=("messages",10), # 保留最近 10 条消息不摘要
)
], # 注册中间件
)
更多参数:
SummarizationMiddleware(
....
# 自定义摘要提示词(可选)
summary_prompt="""请对以下对话历史进行摘要,保留关键信息和决策点:
{messages}
摘要要求:
- 保留用户的核心需求和约束条件
- 保留已确认的事实和数据
- 去除闲聊和重复内容
- 用中文输出
摘要:""",
# 摘要长度限制(可选)
max_summary_tokens=600,
)
5.2工具重试 (ToolRetryMiddleware )
自动给失败的工具(如遇到网络超时)调用加指数退避重试
from langchain.agents.middleware import ToolRetryMiddleware
agent = create_agent(
model=llm,
tools=[api_tool, search_tool],
middleware=[
ToolRetryMiddleware(
max_retries=3, #最多重试3次
backoff_factor=2.0, #等待时间以2倍增长:1s, 2s, 4s
initial_delay=1.0, # 首次重试前等待1秒
tools=["search_tool"], # 只对 search_tool工具应用重试
retry_on=(ConnectionError, TimeoutError), # 只对这些异常重试
on_failure="return_message", # 重试耗尽后返回错误信息给模型,而不是抛异常
),
],
)
5.3 敏感信息脱敏中间件(PIIMiddleware)
自动检测手机号、邮箱、银行卡等隐私信息,支持脱敏、屏蔽、拦截、哈希四种处理策略,适配合规场景。
from langchain.agents.middleware import PIIMiddleware
agent = create_agent(
model=llm,
tools=[],
middleware=[
# 自动脱敏邮箱、手机号
PIIMiddleware("email", strategy="redact", apply_to_input=True),
PIIMiddleware("phone_number", strategy="mask", apply_to_input=True)
]
)
5.4 任务规划与跟踪能力中间件(TodoListMiddleware )
TodoListMiddleware 是一个为 LangChain Agent 提供待办事项列表(Todo List)管理功能的中间件。它的核心思路是为 Agent 添加一个专用的write_todos工具,引导 Agent 在接到复杂任务时,先进行规划。
适用场景
- 复杂多步骤任务(如代码重构、数据分析、旅行规划)
- 需要跨多个工具协调的长流程操作
- 需要向用户展示执行进度的场景
基础使用:
from langchain.agents import create_agent
from langchain.agents.middleware import TodoListMiddleware
agent = create_agent(
model=llm,
tools=[read_file, write_file, run_tests],
middleware=[TodoListMiddleware()],
)
自定义配置:
agent = create_agent(
model="gpt-4.1",
tools=[read_file, write_file, run_tests],
middleware=[
TodoListMiddleware(
system_prompt="请根据用户需求创建任务清单,按优先级执行并更新进度",
tool_description="write_todos:创建或更新任务清单,格式为:- [ ] 任务描述",
),
],
)
5.5 人机审核中间件(HumanInTheLoopMiddleware)
对于高危操作如“退款”、“发送邮件”、“操作数据库”等,我们希望在真正执行前得到人工确认、修改或拒绝。HumanInTheLoopMiddleware 会在匹配的工具调用时暂停 Agent,等待外部审批。
接下来演示一个从数据库删除用户和发送邮件敏感操作需要用户审批的完整示例:
import os
from dotenv import load_dotenv
from langchain.agents import create_agent
from langchain.messages import HumanMessage
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langchain.agents.middleware import (
HumanInTheLoopMiddleware,
)
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph.state import Command
load_dotenv()
llm = ChatOpenAI(
model=os.getenv("DEEP_MODEL_NAME"),
base_url=os.getenv("DEEP_BASE_URL"),
api_key=os.getenv("DEEP_API_KEY"),
)
@tool
def delete_user_data(condition: str) -> str:
"""删除用户数据"""
return f"工具执行成功,删除数据,条件={condition}"
@tool
def send_msg(email: str, subject: str, content: str) -> str:
"""发送邮件"""
return (
f"【实际发送结果】\n"
f"收件人: {email}\n"
f"主题: {subject}\n"
f"实际发送内容: {content}\n"
f"状态: 发送成功"
)
checkpointer = InMemorySaver()
agent = create_agent(
model=llm, # 模型
tools=[delete_user_data, send_msg],
checkpointer=checkpointer,
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={#设置需要审核的工具
"delete_user_data": {"allowed_decisions": ["approve", "reject"]},
"send_msg": {"allowed_decisions": ["approve", "edit", "reject"]},
}
)
],
)
config = {"configurable": {"thread_id": "1"}}
result = agent.invoke(
{
"messages": [
HumanMessage(
"删除创建于2025年的用户数据,并发送邮件给132@qq.com,主题:hello,内容:很高兴认识你"
)
]
},
config=config,
version="v2",
)
# 判断是否有中断
is_interrupted = bool(hasattr(result, "interrupts") and result.interrupts)
if is_interrupted:
interrupt_value = result.interrupts[0].value
decisions = [] # 审批意见
# 原审批数据
action_requests = interrupt_value["action_requests"]
# 遍历需要审批的工具
for i, item in enumerate(interrupt_value["review_configs"]):
# 模拟用户选择审批意见
review_input = input(
f"工具名称:{item['action_name']},请输入审批意见({','.join(item['allowed_decisions'])})"
)
# 发送邮件审核为人工编辑
if review_input == "edit" and item["action_name"] == "send_msg":
# 修改邮件内容
new_msg_content = input("请输入修改后邮件内容:")
decisions.append(
{
"type": review_input,
"edited_action": {
"name": item["action_name"],
"args": {
**action_requests[i]["args"], # 保留原来邮件地址和主题
"content": new_msg_content,
},
},
}
)
else:
decisions.append({"type": review_input})
# 提交审批意见
response = agent.invoke(
Command(resume={
"decisions": decisions
}),
config=config,
version="v2"
)
print(response.value["messages"][-1].content, "contentvalue")
运行效果:
说明:
(1) 通过interrupt_on注册需要审批的工具
# 创建带有 Human-in-the-Loop 中断审批的 Agent
agent = create_agent(
model=llm, # 大语言模型实例
tools=[delete_user_data, send_msg], # 提供给 Agent 的工具列表
checkpointer=checkpointer, # 用于状态的持久化(支持中断恢复)
middleware=[
HumanInTheLoopMiddleware(
# 定义哪些工具调用需要暂停等待人类审批
interrupt_on={
"delete_user_data": {
"allowed_decisions": [
"approve", # 批准执行
"reject" # 拒绝执行
]
},
"send_msg": {
"allowed_decisions": [
"approve", # 批准原样执行
"edit", # 修改参数后执行
"reject" # 拒绝执行
]
}
}
)
],
)
人工决策说明:
- approve(通过):允许工具正常执行
- edit(编辑):人工修改工具调用参数后重新执行
- reject(拒绝):终止当前高危操作,返回拒绝提示
(2) interrupts 的判断
是否含待审批类型的工具判断方法:
result = agent.invoke(
{
"messages": [
HumanMessage(
"删除创建于2025年的用户数据,并发送邮件给132@qq.com,主题:hello,内容:很高兴认识你"
)
]
},
config=config,
version="v2",#必须使用v2版本
)
result对象有个interrupts属性 是个元组类型,
| 值 | 含义 | 布尔判断 |
|---|---|---|
() 空元组 |
没有中断 | False |
| 非空元组(包含中断信息) | 有中断发生 | True |
该示例运行后打印的“interrupts ”数据如下所示:
interrupts = ( # ← 外层:元组
Interrupt( # ← Interrupt 对象实例(第1个,也是唯一一个)
value={ # ← 中断携带的核心数据(字典)
'action_requests': [ # ← 待审批的工具调用请求列表
{
# ========== 第1个待审批工具:删除用户数据 ==========
'name': 'delete_user_data', # ← 工具名称
'args': { # ← 工具参数
'condition': 'created_year=2025' # ← 删除条件:2025年创建的数据
},
'description': ( # ← 审批描述文本(供人工阅读)
"Tool execution requires approval\n\n" # ← 提示需要审批
"Tool: delete_user_data\n" # ← 工具名
"Args: {'condition': 'created_year=2025'}" # ← 参数详情
)
},
{
# ========== 第2个待审批工具:发送邮件 ==========
'name': 'send_msg', # ← 工具名称
'args': { # ← 工具参数
'email': '132@qq.com', # ← 收件人邮箱
'subject': 'hello', # ← 邮件主题
'content': '很高兴认识你' # ← 邮件内容
},
'description': ( # ← 审批描述文本
"Tool execution requires approval\n\n"
"Tool: send_msg\n"
"Args: {'email': '132@qq.com', 'subject': 'hello', 'content': '很高兴认识你'}"
)
}
],
'review_configs': [ # ← 审批配置规则列表(与 action_requests 一一对应)
{
# ========== delete_user_data 的审批规则 ==========
'action_name': 'delete_user_data', # ← 对应哪个工具
'allowed_decisions': ['approve', 'edit', 'reject'] # ← 允许的操作:批准/编辑/拒绝
},
{
# ========== send_msg 的审批规则 ==========
'action_name': 'send_msg', # ← 对应哪个工具
'allowed_decisions': ['approve', 'edit', 'reject'] # ← 允许的操作:批准/编辑/拒绝
}
]
},
id='e068bfb543d4d1fce115c244487b53d3' # ← 此 Interrupt 的唯一标识符(UUID)
), # ← Interrupt 对象结束,注意元组的逗号
) # ← interrupts 元组结束
(3) 通过遍历interrupts [0].value[“review_configs”]获取所有需要审批的工具以及审批操作配置
interrupt_value = result.interrupts[0].value
decisions = [] # 审批意见
# 原审批数据
action_requests = interrupt_value["action_requests"]
# 遍历需要审批的工具
for i, item in enumerate(interrupt_value["review_configs"]):
# 模拟用户选择审批意见
review_input = input(
f"工具名称:{item['action_name']},请输入审批意见({','.join(item['allowed_decisions'])})"
)
(4)审批结果通过Command提交
# ========== 批量提交多个工具的审批决策 ==========
from langgraph.graph.state import Command
decision_command = Command(
resume={
"decisions": [
# 第1个工具:delete_user_data → 批准
{"type": "approve"},
# 第2个工具:send_msg → 编辑参数
{
"type": "edit",
"edited_action": { # ← 编辑数据
"name": "send_msg", # ← 工具名称(必需)
"args": { # ← 新参数(完整或部分)
"email": "132@qq.com",
"subject": "hello",
"content": "我叫小明,你好" # ← 修改后的内容
}
}
},
# 第3个工具(如果有)→ 拒绝
# {
# "type": "reject",
# "feedback": "禁止执行此操作"
# },
]
}
)
# 提交审批,恢复执行
response = agent.invoke(
decision_command,
config=config,
version="v2"
)
更多官方内置中间件和参数可以查看官方文档https://docs.langchain.com/oss/python/langchain/middleware/built-in
总结
LangChain v1.2 的中间件体系为 Agent 开发带来了函数式编程般的优雅与模块化能力。通过清晰地划分出 请求前、响应后和工具环绕 三种钩子,你可以像搭积木一样,将日志、安全、重试等关注点干净地分离到独立的中间件中。从使用官方内置的强大中间件,到编写完全自定义的逻辑,这套体系极大地提升了 Agent 应用的灵活性、健壮性和安全性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)