用PyTorch和Transformers提炼GPT
本教程将解释如何将GPT2提炼成更小的模型。整个管道包括:distilgpt2
- 建立一个稳定的训练环境。
- 加载教师()和学生()模型。
gpt2distilgpt2 - 如果需要,可以使用数据增强。
- 应用改进的预处理步骤。
- 实现标签平滑。
- 使用自定义蒸馏损失函数。
- 培训和评估精炼模型。
在整个教程中,你将看到如何利用教师输出(知识提炼)来训练学生模型,同时保留一些来自真实标签的直接监督(硬丢失)。该平衡配置为参数 。alpha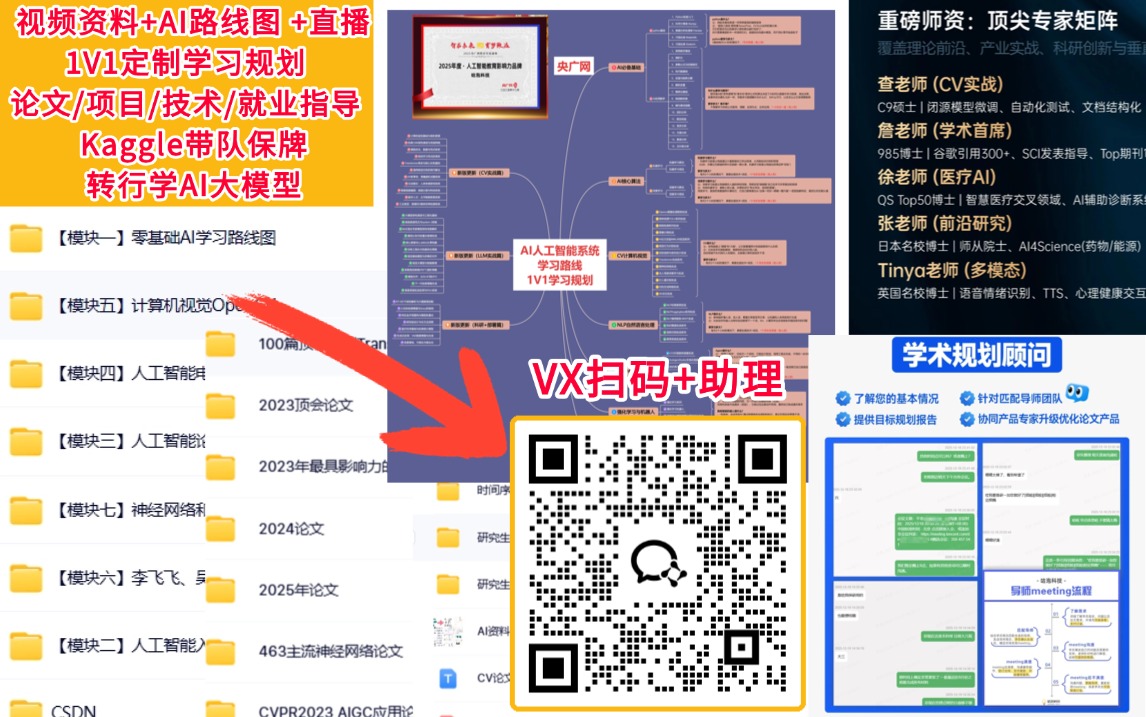
前提条件
PyTorch(用于构建和训练神经网络)
拥抱面部变换器(针对预训练变压器模型)
数据集(用于加载和处理数据集)
对Python和深度学习概念有基本熟悉
完整代码在文章末尾
pip install torch transformers datasets
关键步骤说明
1.设备设置
我们通过以下方式检测GPU是否可用:torch.cuda.is_available()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
这样可以确保模型在GPU上训练(如果有的话),否则就用CPU训练。
2.选择稳定基模型
我们定义了教师和学生的模式:
teacher_model_name = "gpt2"
student_model_name = "distilgpt2"
如果你愿意,可以随意切换到其他模型(比如GPT-Neo或GPT-J),只要它们符合因果语言建模架构。
3. FP32中的加载模型及调整掉落
我们将教师和学生都安排在FP32,以实现更稳定的训练。我们还提高学生模型的退出率,以减少过拟合:
teacher_model = AutoModelForCausalLM.from_pretrained(
teacher_model_name,
device_map="auto",
torch_dtype=torch.float32
).eval()
student_model = AutoModelForCausalLM.from_pretrained(
student_model_name,
device_map="auto",
torch_dtype=torch.float32
)
# Increase dropout
student_model.config.attn_pdrop = 0.1
...
4. 加载分词器
我们使用与教师模型相同的分词器以保持一致性:
tokenizer = AutoTokenizer.from_pretrained(teacher_model_name)
tokenizer.pad_token = tokenizer.eos_token
我们设置为 以确保所有序列的填充一致。pad_tokeneos_token
5. 数据增强
在这里,你可以选择性地加入文本增强技术(同义词替换、随机插入等)。目前,该函数返回的是原文。
6. 改进的数据预处理
我们进行最小限度的文本清理和标记化:
def tokenize_function(examples):
...
tokenized = tokenizer(
processed_texts,
truncation=True,
max_length=128,
padding="max_length",
return_tensors="pt"
)
...
我们会删除太短(少于10字符)的文本。这有助于避免用琐碎的例子进行训练。
7. 加载与拆分OpenWebText数据集
dataset = load_dataset("openwebtext")
dataset = dataset["train"].train_test_split(test_size=0.1)
数据集分为训练(90%)和测试(10%)。然后我们映射 以标记整个数据集。tokenize_function
8. DataLoader 配置
我们创建 PyTorch 数据加载器用于训练和测试,定义一个自定义方法将张量迁移到正确的设备:collate_fn
def collate_fn(batch):
...
train_loader = DataLoader(..., collate_fn=collate_fn)
9. 标签平滑
为减少预测过度自信,会实现自定义类。我们将典型的交叉熵损失替换为标签平滑:LabelSmoothingCrossEntropy
class LabelSmoothingCrossEntropy(nn.Module):
...
label_smoothing_loss_fn = LabelSmoothingCrossEntropy(smoothing=0.1)
10. 改进蒸馏损耗函数
该函数计算:distillation_loss
硬损失:通过标签平滑()计算。label_smoothing_loss_fn
软损失:教师与学生对数之间的Kullback-Leibler发散,按 。temperature
def distillation_loss(student_outputs, teacher_outputs, labels, temperature=3.0, alpha=0.7):
...
return alpha * hard_loss + (1 - alpha) * soft_loss
该参数在硬损失和软损失之间取得平衡。alpha
11. 训练环
我们定义为经历多个训练阶段:train_student
def train_student(student_model, teacher_model, train_loader, epochs=3, lr=3e-6, output_dir="distilled_model"):
...
每批批次:
1-教师模型生成logits。
2-学生模式生成logits。
3-我们计算蒸馏损失并进行反向传播。
12. 模型评估
我们通过以下方法从测试集中的教师和学生模型生成文本:
model.generate(...)
我们收集了一些样本来比较它们的输出。
13. 训练执行
这里,我们用所需的参数调用:train_student(...)
trained_model = train_student(
student_model,
teacher_model,
train_loader,
epochs=2,
lr=3e-6,
output_dir=output_model_dir
)
根据需要调整纪元或学习速度。
14. 拯救最终模型
我们保存了学生模型的最终州词典:
torch.save(trained_model.state_dict(), os.path.join(output_model_dir, "final_distilled_model.pt"))
15-16. 输出比较与保存
我们从教师和学生那里生成一些样本,并将其写成文本文件,以便直观地比较表现。
结论
你现在已经完成了一份逐步指南,教你如何将GPT模型(GPT2)提炼成一个更小的学生(DistilGPT2)。这种方法平衡了教师获取的知识(软标签)与原始的真实信息(硬标签),以打造出更紧凑且高效的模型。
欢迎修改:
数据增强逻辑。
蒸馏损失中的温度和α参数。
辍学率。
其他超参数(批次大小、学习率、历元等)。
多试试这些设置,找出性能和模型尺寸之间的最佳权衡。祝你蒸馏顺利!
以下是蒸馏工作流程的完整代码
你可以把它保存在一个名为(或你喜欢的名字)的文件里并运行。代码中的注释部分为中文,但每个部分代码块下方都有英文解释。
Distill_GPT.py
import os
import torch
import torch.nn as nn
import torch.optim as optim
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from torch.utils.data import DataLoader
# ======================
# 1. Set the device
# ======================
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ======================
# 2. Use stable base models
# ======================
teacher_model_name = "gpt2"
student_model_name = "distilgpt2"
# ======================
# 3. Load models in FP32 for stability and adjust dropout in the student model
# ======================
teacher_model = AutoModelForCausalLM.from_pretrained(
teacher_model_name,
device_map="auto",
torch_dtype=torch.float32
).eval()
student_model = AutoModelForCausalLM.from_pretrained(
student_model_name,
device_map="auto",
torch_dtype=torch.float32
)
# Increase regularization to reduce mode collapse risk
student_model.config.attn_pdrop = 0.1
student_model.config.embd_pdrop = 0.1
student_model.config.resid_pdrop = 0.1
student_model.train()
# ======================
# 4.Load tokenizer
# ======================
tokenizer = AutoTokenizer.from_pretrained(teacher_model_name)
tokenizer.pad_token = tokenizer.eos_token
# ======================
# 5. Data augmentation interface
# ======================
def data_augmentation(text: str) -> str:
# Currently returns the original text;
# you can add more complex augmentation logic here
return text
# ======================
# 6. Improved data preprocessing
# ======================
def tokenize_function(examples):
processed_texts = []
for text in examples["text"]:
# Data augmentation
text_aug = data_augmentation(text)
cleaned = text_aug.strip()
# Filter out very short texts
if len(cleaned) > 10:
processed_texts.append(cleaned)
# In case none of the texts remain
if not processed_texts:
processed_texts = ["[EMPTY]"] * len(examples["text"])
tokenized = tokenizer(
processed_texts,
truncation=True,
max_length=128,
padding="max_length",
return_tensors="pt"
)
return {key: value.tolist() for key, value in tokenized.items()}
# ======================
# 7. Load a larger dataset - openwebtext, then split into train/test
# ======================
dataset = load_dataset("openwebtext")
dataset = dataset["train"].train_test_split(test_size=0.1)
tokenized_datasets = dataset.map(
tokenize_function,
batched=True,
batch_size=8,
remove_columns=["text"],
load_from_cache_file=False,
keep_in_memory=True,
num_proc=4
)
# ======================
# 8. Configure the data loader
# ======================
def collate_fn(batch):
input_ids = torch.tensor([ex["input_ids"] for ex in batch], dtype=torch.long).to(device)
attention_mask = torch.tensor([ex["attention_mask"] for ex in batch], dtype=torch.long).to(device)
return {
"input_ids": input_ids,
"attention_mask": attention_mask
}
train_loader = DataLoader(
tokenized_datasets["train"],
batch_size=8,
shuffle=True,
collate_fn=collate_fn
)
test_loader = DataLoader(
tokenized_datasets["test"],
batch_size=1,
collate_fn=collate_fn
)
# ======================
# 9. Implementation of Label Smoothing
# ======================
class LabelSmoothingCrossEntropy(nn.Module):
def __init__(self, smoothing=0.1):
"""
:param smoothing: Smoothing factor, typically in [0, 1)
"""
super(LabelSmoothingCrossEntropy, self).__init__()
self.smoothing = smoothing
self.log_softmax = nn.LogSoftmax(dim=-1)
def forward(self, logits, target):
with torch.no_grad():
pad_mask = (target == -100)
target = target.clone()
target[pad_mask] = 0
log_probs = self.log_softmax(logits)
nll_loss = -log_probs.gather(dim=-1, index=target.unsqueeze(1)).squeeze(1)
smooth_loss = -log_probs.mean(dim=-1)
nll_loss[pad_mask] = 0.0
smooth_loss[pad_mask] = 0.0
loss = (1.0 - self.smoothing) * nll_loss + self.smoothing * smooth_loss
return loss.mean()
label_smoothing_loss_fn = LabelSmoothingCrossEntropy(smoothing=0.1)
# ======================
# 10. Improved distillation loss function
# ======================
def distillation_loss(student_outputs, teacher_outputs, labels, temperature=3.0, alpha=0.7):
student_logits = student_outputs.logits
teacher_logits = teacher_outputs.logits.detach()
labels = labels.to(student_logits.device)
# Hard loss from label smoothing
hard_loss = label_smoothing_loss_fn(
student_logits.view(-1, student_logits.size(-1)),
labels.view(-1)
)
# Soft loss from teacher logits
soft_loss = nn.KLDivLoss(reduction='batchmean')(
nn.functional.log_softmax(student_logits / temperature, dim=-1),
nn.functional.softmax(teacher_logits / temperature, dim=-1)
) * (temperature ** 2)
return alpha * hard_loss + (1 - alpha) * soft_loss
# ======================
# 11. Enhanced training loop
# ======================
def train_student(student_model, teacher_model, train_loader, epochs=3, lr=3e-6, output_dir="distilled_model"):
optimizer = optim.AdamW(student_model.parameters(), lr=lr, weight_decay=0.01)
os.makedirs(output_dir, exist_ok=True)
for epoch in range(epochs):
student_model.train()
total_loss = 0.0
for batch_idx, batch in enumerate(train_loader):
inputs = batch["input_ids"]
attention_mask = batch["attention_mask"]
labels = inputs.clone()
labels[labels == tokenizer.pad_token_id] = -100
optimizer.zero_grad()
with torch.no_grad():
teacher_outputs = teacher_model(input_ids=inputs, attention_mask=attention_mask)
student_outputs = student_model(input_ids=inputs, attention_mask=attention_mask)
loss = distillation_loss(student_outputs, teacher_outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
# Print progress occasionally
if batch_idx % 100000 == 0 and batch_idx > 0:
print(f"Epoch {epoch+1} | Batch {batch_idx} | Average Loss: {total_loss / (batch_idx + 1):.4f}")
print(f"Epoch {epoch+1} Complete | Average Loss: {total_loss / len(train_loader):.4f}")
print("Training complete!")
return student_model
# ======================
# 12. Model evaluation
# ======================
def evaluate_model(model, test_loader, num_samples=3):
model.eval()
results = []
with torch.no_grad():
for i, batch in enumerate(test_loader):
if i >= num_samples:
break
inputs = batch["input_ids"]
attention_mask = batch["attention_mask"]
output = model.generate(
inputs,
attention_mask=attention_mask,
max_new_tokens=50,
pad_token_id=tokenizer.eos_token_id,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.9
)
decoded = tokenizer.decode(output[0], skip_special_tokens=True)
results.append(decoded)
return results
# ======================
# 13. Run the training
# ======================
output_model_dir = "distilled_model_output_OpenWeb"
trained_model = train_student(
student_model,
teacher_model,
train_loader,
epochs=2, # Adjust epochs as needed
lr=3e-6,
output_dir=output_model_dir
)
# ======================
# 14. Save the final model
# ======================
torch.save(trained_model.state_dict(), os.path.join(output_model_dir, "final_distilled_model.pt"))
# ======================
# 15. Comparison Evaluation
# ======================
print("\nTeacher Model Generation Samples:")
teacher_results = evaluate_model(teacher_model, test_loader)
print("\nStudent Model Generation Samples:")
student_results = evaluate_model(trained_model, test_loader)
# ======================
# 16. Save comparison results
# ======================
comparison_file_path = os.path.join(output_model_dir, "generation_comparison.txt")
with open(comparison_file_path, "w", encoding="utf-8") as f:
f.write("=== Teacher Model Generation ===\n")
f.write("\n".join(teacher_results))
f.write("\n\n=== Student Model Generation ===\n")
f.write("\n".join(student_results))
print(f"\nTraining and evaluation complete! Comparison saved to {comparison_file_path}")
print(f"Model files saved in {output_model_dir}")

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)