CLIP (Contrastive Language-Image Pre-training) 论文解读
·
- 论文标题:Learning Transferable Visual Models From Natural Language Supervision
- 论文链接:arXiv:2103.00020
- 发表单位: OpenAI (2021 ICML)
- 核心贡献:利用大规模互联网文本对作为监督信号,通过对比学习(Contrastive Learning)训练视觉和语言模型,使其具备极强的零样本(Zero-shot)迁移能力。
1. 研究背景与动机
传统的计算机视觉模型(如基于 ImageNet 训练的 ResNet)通常依赖于人工标注的、预定义的离散类别集合。这种范式存在几个显著的局限性:
- 数据标注成本高昂:需要大量人工清洗和标注的图片,难以扩展到更多、更细粒度的类别。
- 泛化能力差:在面对未见过的数据分布(如手绘草图、对抗样本、不同风格的图片)时,模型性能会急剧下降。
- 任务灵活性差:模型被严格限制在训练时预定义的类别内,无法像人类一样通过阅读文本描述来理解新概念。
为了解决这些问题,OpenAI 提出了 CLIP,其核心理念是:直接利用互联网上随处可见的海量“图像-文本对”(Image-Text pairs)作为自然语言监督信号来训练模型,从而打破固定类别标签的限制。
2. 核心方法论 (Methodology)
CLIP 的核心思想是对比学习(Contrastive Learning),它的目标是将图像和文本映射到同一个多模态共享的特征表示空间中。
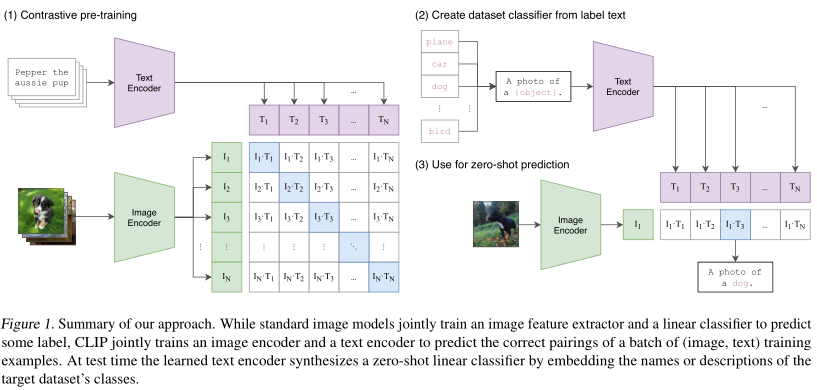
2.1 模型架构
CLIP 由两个相互独立的编码器(Encoder)组成:
- Text Encoder(文本编码器):使用基于 Transformer 的模型(类似于 GPT 架构)来提取文本序列的特征向量。
- Image Encoder(图像编码器):作者尝试了两种经典的视觉架构:修改版的 ResNet(如 ResNet-50)和 Vision Transformer (ViT)。最终表现最好的是基于 ViT 的变体。
2.2 对比学习预训练 (Contrastive Pre-training)
与传统的预测具体单词或生成文本的任务不同,CLIP 采用了一个代理任务,即图像-文本配对预测。
- 在训练时,给定一个批次(Batch)内包含的 N N N 个图像-文本对。
- 模型会计算 N × N N \times N N×N 个可能的图像-文本组合的余弦相似度(Cosine Similarity)。
- 优化目标:
- 最大化对角线上 N N N 个正样本(真实的图像-匹配文本)的相似度。
- 最小化非对角线上 N 2 − N N^2 - N N2−N 个负样本(不匹配的图像-文本组合)的相似度。
- 使用对称的交叉熵损失函数(Symmetric Cross-Entropy Loss)对文本和图像编码器进行联合优化。
这种高度并行的对比学习方法计算效率极高,使得在大规模数据集上训练成为可能。

2.3 数据集构建 (WIT)
为了支持预训练,OpenAI 构建了一个包含 4 亿(400 million)图像-文本对的数据集,称为 WIT (WebImageText),提供了涵盖海量视觉概念的丰富监督信号。这种极大规模的、未经过度人工清洗但覆盖面极广的数据集是 CLIP 成功的重要基石。
3. Zero-Shot 推理机制
CLIP 最令人瞩目的亮点在于其极其强大的 Zero-Shot(零样本)能力。在没有对特定任务进行任何微调(Fine-tuning)的情况下,CLIP 如何进行图像分类?
- 构建标签候选集:给定测试集的所有可能类别名称(例如 “dog”, “cat”, “car”)。
- Prompt Engineering(提示工程):由于 CLIP 在训练时看到的是完整的句子而非单个单词,直接输入 “dog” 效果不佳。因此,作者使用提示模板将标签构造成句子,例如 “A photo of a {label}.”。
- 提取文本特征:将所有构造好的文本输入 Text Encoder,得到一组文本特征向量。
- 提取图像特征:将待分类的图像输入 Image Encoder,得到图像特征向量。
- 计算相似度:计算图像特征向量与所有文本特征向量的余弦相似度。
- 输出预测:相似度最高的那段文本所对应的标签,即为模型的分类预测结果。
4. 实验结果与发现
- 强大的 Zero-Shot 性能:CLIP 在完全没有使用 ImageNet 训练集微调的情况下,在 ImageNet 上的 Zero-Shot 准确率达到了惊人的水平,甚至与完全监督学习训练出的 ResNet-50 相当。在涵盖丰富任务的其余 20 多个数据集中,CLIP 也表现出了极强的竞争力。
- 卓越的鲁棒性 (Robustness):传统模型在面对数据分布偏移(如 ImageNet-V2, ImageNet-R 艺术画, ImageNet-Sketch 草图)时性能往往“断崖式”下跌。而 CLIP 凭借文本监督带来的丰富语义特征,表现出了极强的泛化能力和零样本迁移能力。
- Prompt 的重要性:实验表明,给类别名称加上适当的上下文提示(如 “A photo of a”, “A sketch of a”)能显著提升模型的分类准确率。
5. 总结与深远影响
CLIP 是多模态和通用人工智能(AGI)领域的里程碑式工作。它深刻地证明了以下几点:
- 自然语言是一种极其强大的监督信号。它比离散的数字或类别标签(如 0, 1, 2)蕴含着更丰富、更密集的语义信息,能够极大地提升视觉模型的表征能力。
- 多模态对比学习 + 大规模数据 = 强泛化能力。这种范式颠覆了传统的计算机视觉训练模式,开启了“视觉基础大模型”的时代。
- 催生了新一代生成式 AI:CLIP 不仅本身具备强大的检索和分类能力,它还成为了后续众多突破性文生图(Text-to-Image)模型(如 DALL-E 2, Stable Diffusion, Midjourney)的关键组件,用于对齐文本和图像语义,指导高质量图像的生成。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)