Docker
一、Docker基础
Docker与容器
Docker是基于Go语言实现的开源容器项目。它诞生于2013年年初,最初发起者是dotCloud公司。Docker自开源后受到业界广泛的关注和参与,目前已有80多个相关开源组件项目(包括Containerd、Moby、Swarm等),逐渐形成了围绕Docker容器的完整的生态体系。dotCloud公司也随之快速发展壮大,在2013年年底直接改名为Docker Inc,并专注于Docker相关技术和产品的开发,目前已经成为全球最大的Docker容器服务提供商。
为什么要用Docker?
- 更高效的利用系统资源
由于容器不需要进行硬件虚拟以及运行完整操作系统等额外开销,Docker 对系统资源的利用率更高。无论是应用执行速度、内存损耗或者文件存储速度,都要比传统虚拟机技术更高效。因此,相比虚拟机技术,一个相同配置的主机,往往可以运行更多数量的应用。
- 更快速的启动时间
传统的虚拟机技术启动应用服务往往需要数分钟,而 Docker 容器应用,由于直接运行于宿主内核,无需启动完整的操作系统,因此可以做到秒级、甚至毫秒级的启动时间。大大的节约了开发、测试、部署的时间。
- 一致的运行环境
开发过程中一个常见的问题是环境一致性问题。由于开发环境、测试环境、生产环境不一致,导致有些 bug 并未在开发过程中被发现。而 Docker 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现 「这段代码在我机器上没问题啊」 这类问题。
- 持续交付和部署
对开发和运维(DevOps)人员来说,最希望的就是一次创建或配置,可以在任意地方正常运行。
使用 Docker 可以通过定制应用镜像来实现持续集成、持续交付、部署。开发人员可以通过 Dockerfile 来进行镜像构建,并结合 持续集成(Continuous Integration) 系统进行集成测试,而运维人员则可以直接在生产环境中快速部署该镜像,甚至结合 持续部署(Continuous Delivery/Deployment) 系统进行自动部署。
而且使用 Dockerfile 使镜像构建透明化,不仅仅开发团队可以理解应用运行环境,也方便运维团队理解应用运行所需条件,帮助更好的生产环境中部署该镜像。
- 更轻松的迁移
由于 Docker 确保了执行环境的一致性,使得应用的迁移更加容易。Docker 可以在很多平台上运行,无论是物理机、虚拟机、公有云、私有云,甚至是笔记本,其运行结果是一致的。因此用户可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况。
- 更轻松的维护和扩展
Docker 使用的分层存储以及镜像的技术,使得应用重复部分的复用更为容易,也使得应用的维护更新更加简单,基于基础镜像进一步扩展镜像也变得非常简单。此外,Docker 团队同各个开源项目团队一起维护了一大批高质量的 官方镜像,既可以直接在生产环境使用,又可以作为基础进一步定制,大大的降低了应用服务的镜像制作成本。
容器与虚拟机的区别
容器和虚拟机具有相似的资源隔离和分配优势,但功能有所不同,因为容器虚拟化的是操作系统,而不是硬件,因此容器更容易移植,效率也更高。
容器虚拟化的是操作系统而不是硬件,容器之间是共享同一套操作系统资源的。虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统。因此容器的隔离级别会稍低一些。
传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主机的内核中,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便。
-
Docker 容器的启动可以在秒级实现,相比传统的虚拟机方式要快很多(分钟级)。 其次,容器对系统资源的利用率很高,一台主机上可以同时运行数百个 Docker 应用。
-
容器基本不消耗额外的系统资源,使系统的开销尽量小。
-
虚拟机技术依赖物理 CPU 和内存,属于硬件级别的(特别是桌面虚拟化);而 Docker 构建在操作系统上, 利用操作系统的系统隔离技术运行,甚至 Docker 可以在虚拟机中运行。
-
无需硬件支持,在大多数主流的 Linux/Unix 与 Windows 系统上都支持。
Docker三要素
- 镜像(Image): Docker运行容器所需要的环境(静态定义)
操作系统分为内核空间和用户空间。对于 Linux 而言,内核启动后,会挂载 root 文件系统为其提供用户空间支持。而 Docker 镜像(Image),就相当于是一个 root 文件系统。
Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。 镜像不包含任何动态数据,其内容在构建之后也不会被改变。
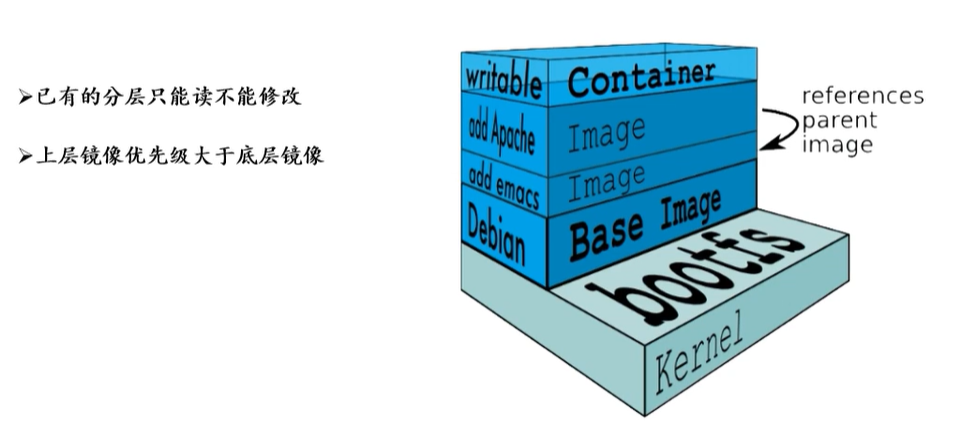
Docker 设计时,就充分利用 Union ****FS技术,将其设计为 分层存储的架构 。 镜像实际是由多层文件系统联合组成。
镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除。在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像。因此,在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉。
分层存储的特征还使得镜像的复用、定制变的更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。
- 容器(Container):Docker使用镜像运行出来的东西
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等 。
容器的实质是进程,但与直接在宿主机上执行的进程不同,容器进程运行于属于自己的独立的命名空间。前面讲过镜像使用的是分层存储,容器也是如此。
容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡。因此,任何保存于容器存储层的信息都会随容器删除而丢失。
按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据 ,容器存储层要保持无状态化。所有的文件写入操作,都应该使用数据卷(Volume)、或者绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此, 使用数据卷后,容器可以随意删除、重新 run ,数据却不会丢失。
- 仓库(Repository):集中存放镜像的地方
镜像构建完成后,可以很容易的在当前宿主机上运行,但是, 如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry就是这样的服务。
一个 Docker Registry中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。所以说:镜像仓库是Docker用来集中存放镜像文件的地方类似于我们常用的代码仓库。
通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本 。我们可以通过<仓库名>:<标签>的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。
这里补充一下Docker Registry 公开服务和私有 Docker Registry的概念:
Docker Registry 公开服务 是开放给用户使用、允许用户管理镜像的 Registry 服务。一般这类公开服务允许用户免费上传、下载公开的镜像,并可能提供收费服务供用户管理私有镜像。
最常使用的 Registry 公开服务是官方的 Docker Hub ,这也是默认的 Registry,并拥有大量的高质量的官方镜像,网址为:https://hub.docker.com/ 。在国内访问Docker Hub 可能会比较慢国内也有一些云服务商提供类似于 Docker Hub 的公开服务。比如 时速云镜像库、网易云镜像服务、DaoCloud 镜像市场、阿里云镜像库等。
除了使用公开服务外,用户还可以在本地搭建私有 Docker Registry 。Docker 官方提供了 Docker Registry 镜像,可以直接使用做为私有 Registry 服务。开源的 Docker Registry 镜像只提供了 Docker Registry API 的服务端实现,足以支持 docker 命令,不影响使用。但不包含图形界面,以及镜像维护、用户管理、访问控制等高级功能。
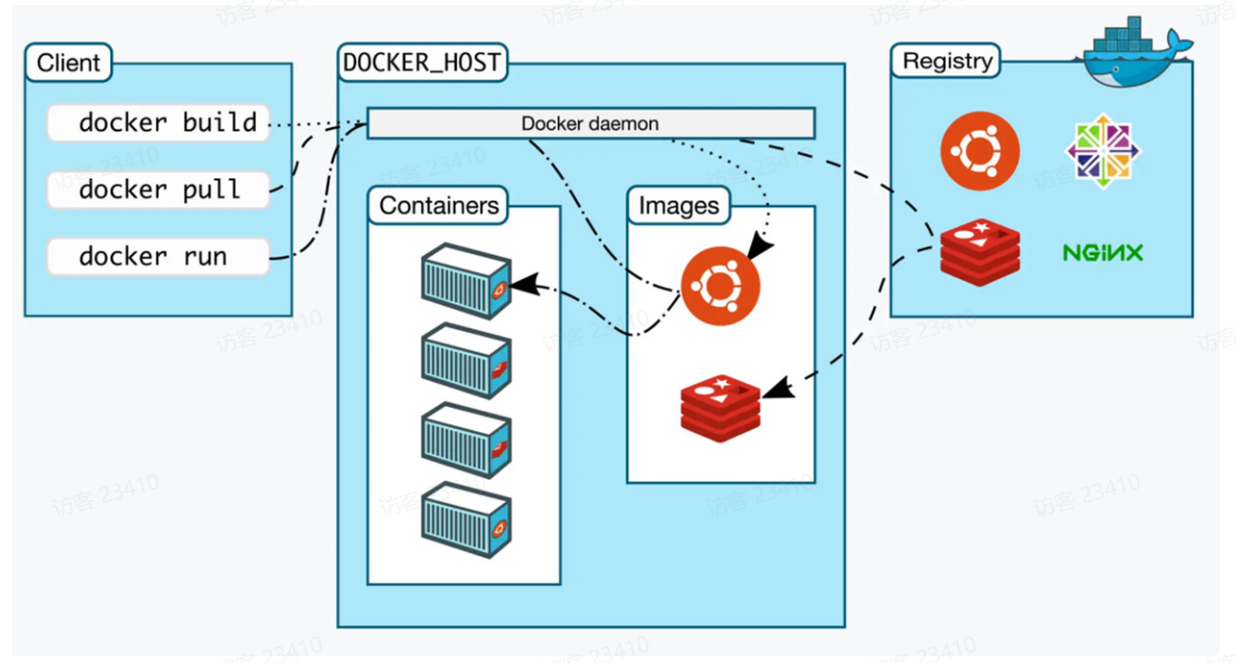
Docker架构
Docker 使用客户端-服务器 (C/S) 架构模式,即可使用远程 API 来管理服务端和创建容器。 Docker 容器需要通过 Docker 镜像来创建。
Docker C/S 架构逻辑图:
-
Docker 分为客户端与服务端, 客户端可以管理本地的服务端(默认), 也可以管理远程的服务端。
-
Docker 服务端在启动容器时需要从仓库获取启动镜像。
Docker版本介绍
Docker 从 1.13.x 版本开始,版本分为企业版 EE 和社区版 CE。
- Docker EE(企业版):Docker Enterprise Edition(EE)是基于Docker CE构建的高级版本,为企业级用户提供了更多的功能和支持。Docker EE提供了一整套企业级特性,如容器编排、高级网络、安全性增强、镜像管理、监控和日志等。此外,Docker EE还提供了商业支持和服务,如技术支持、培训和咨询等。
- Docker CE(社区版):Docker Community Edition(CE)是Docker的免费版本,提供了一组基本的容器化功能。它适用于个人使用和小型团队,具有快速部署和管理容器的能力。Docker CE包括Docker引擎、CLI工具、Compose、Swarm等常用组件,以及许可证允许用户自行修改和分发软件。
在系统中可以使用 docker version 查看版本信息。
Docker基本实现原理
基于内核以下三项技术实现Docker功能:
- 资源隔离(Namespace): 使用 NameSpace 隔离系统资源技术,通过隔离网络、PID 进程、系统信号 量、文件系统挂载、主机名与域名, 来实现在同一宿主系统中,运行不同的容器,而每个容器之间相互隔离, 运行互不干扰。
- 资源限额(CGroups): 使用系统的 Cgroups 系统资源配额功能, 限制资源包括: CPU、Memory、Blkio(块设备)、Network。
- 分层存储(Union FS):通过 Union FS 数据存储技术, 实现容器镜像的物理存储与新建容器存储。
二、Docker的安装
安装前准备
- 查看系统版本和内核版本
cat /etc/redhat-release
# 查看系统版本
uname -a
# 获取系统信息
- 关闭防火墙和SELinux
systemctl stop firewalld
# 关闭防火墙
systemctl disable firewalld
# 防火墙开机不自启
setenforce 0
# 关闭SELinux
getenforce
# 查看SELinux的状态
- 卸载旧版本的Docker
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
安装Docker
- 配置仓库
dnf install -y dnf-utils
# 安装dnf-utils
dnf config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 添加阿里云的docker仓库
- 安装
dnf -y install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# 安装最新版
dnf install docker-ce-3:27.5.1 docker-ce-cli-1:27.5.1 containerd.io docker-compose-plugin docker-buildx-plugin
# 安装27.5.1版本
dnf list docker-ce --showduplicates | sort -r
# 查看所有版本
systemctl enable --now docker
# 启动服务
dnf download --resolve docker-ce-3:27.5.1 docker-ce-cli-1:27.5.1 containerd.io docker-compose-plugin
# 下载安装包到当前目录下,下载时会同时下载依赖包
dnf localinstall *.rpm
# 安装,*.rpm连同依赖一起安装
docker version
# 查看docker版本
docker info
# 查看
三、容器的管理
docker 命令行参数
docker操作命令分为:管理命令与普通命令
1)管理命令:为区分每个项目的命令,如:镜像操作的命令以docker image开头;
2)普通命令:是在docker命令后面直接跟命令,如:删除镜像docker rmi;
3)管理命令相对于普通命令来说更清晰,更严瑾;
命令格式:
docker [-选项] 命令
常用命令:
run 镜像名:版本号:使用镜像创建并且运行一个新的容器;
exec:在正在运行的容器中执行命令;
如:查看容器的主机名:docker exec 容器ID hostname
如:进入到容器中:docker exec -it 容器ID bash
ps:查看所以容器;
build:使用docker文件创建一个镜像;
push:将一个镜像推送到远程仓库中;
images:查看所有镜像;
login:登录到远程仓库中;
logout:退出登录远程仓库;
search:搜索远程仓库中的相关镜像;
version:查看当前docker的版本;
info:查看当前docker的信息;
管理命令:
builder:管理构建;
compose:docker编排;
container:管理容器;
context:管理上下文;
image:管理镜像;
manifest:管理Docker镜像清单和清单列表;
network:管理网络连接;
plugin:管理插件;
system:管理docker;
trust:管理Docker镜像的信任;
volume:管理卷;
老式命令:
attach:将本地输入、输出、错误连接到当前正在运行的容器;
commit:根据容器的更改创建新镜像;
cp:在容器和本地之间相互复制文件;
create:创建一个新的容器;
diff:检查容器文件系统上文件或目录的更改;
events:从服务器获取实时事件;
export:将容器的文件系统导出为tar归档;
history:查看镜像的制作过程;
import:从tarball文件导入内容以创建文件系统镜像;
inspect:返回docker对象的低级信息;
kill:杀死正在运行的一个或多个容器;
load:从tar压缩包中读取镜像;
rename:重命名一个容器;
restart:重启一个容器;
rm:删除一个或多个容器,-f:强制删除;
rmi:删除一个或多个镜像;
save:从远程仓库中下载镜像;
start:开始运行一个或多个容器;
stats:查看容器的状态;
stop:停止一个正在运行的容器;
tag:使用现有的镜像创建一个新镜像,方便推送到远程仓库;
update:更新一个或多个容器的配置信息;
pull:从远程仓库拉取镜像到本地;
查看容器的IP地址
- 方法 1:在容器内部查看:
进入到容器中:docker exec -it 容器ID bash
查看IP:ip a
- 方法 2:使用
docker intercept查看:
docker inspect 容器名 | grep -i ipaddr
- 使用nsenter:
容器的生命周期
容器生命周期管理涉及容器启动、停止等功能,下面选取最常用的docker run命令和负责启动停止的docker start/stop/restart命令举例。
- 启动容器:
docker run [选项] IMAGE [命令] [参数...]
docker run命令是Docker的核心命令之一,所有选项的说明可以通过docker run --help 命令查看。
- 查看正在运行的容器:
docker ps
- 停止正在运行的容器:
docker stop [选项] 容器名或容器ID [多个容器...]
- 查看已经停止的容器:
docker ps -a
# -a:查看所有
- 启动已经停止的容器:
docker start [选项] 容器名或容器ID [多个容器...]
- 删除容器:
docker rm [选项] 容器名或容器ID [多个容器...]
# 删除已经停止的容器:
Remove one or more containers
# 删除已经退出的容器:
docker rm $(docker ps -a | awk '{print $1 }' | grep -v CONTAINER) -f
容器管理
# 查看容器应用的日志
docker logs -f
# 查看容器 资源利用率
docker stats
# 临时启动一个容器, 容器退出后 自动 删除容器
docker run -it --rm busybox sh
# 设置容器开机自动运行
docker run --restart always --name nginx-02 -d nginx:1.22.1
--restart always:开机自启
--name nginx-02:运行的容器名
-d nginx:1.22.1:使用的镜像名称和版本号
# 修改容器的运行参数:
# 1.修改 /etc/hosts 本地静态解析
docker run --add-host www.yangtao.com:192.168.23.23 -it busybox sh
# 2.修改容器中DNS 服务器
docker run --dns 223.5.5.5 -it busybox sh
# 注意:一旦容器成功运行之后就不能修改参数,需要在启动之前修改;
# 保存docker镜像为一个tar包
docker save nginx:1.29.1 -o nginx-1.29.1.tar
或
docker save nginx:1.29.1 > nginx-1.29.1.tar
# 读取保存的tar包为一个docker镜像
docker load -i nginx-1.29.1.tar
或
docker load < nginx-1.29.1.tar
四、仓库管理
五、镜像制作
镜像的特征
容器创建时需要指定镜像,每个镜像都有唯一的标识:Image ID,和容器的Container ID一样,默认128位,可以使用前12位缩略形式,也可以使用“仓库名:tag”两部分组合唯一标识,如果省略tag,默认使用最新版本标签(latest);
镜像的分层:Docker的镜像在制作时通过联合文件系统(UFS:union filesystem)将各层文件系统分开制作,各层文件系统互不影响,在运行时通过联合文件系统(UFS:union filesystem)将各层文件系统叠加在一起。使用docker history 镜像名:版本号可以查看镜像的分层。
- bootfs:用于系统引导的文件系统,包括
bootloader和kernel,容器启动之后会被卸载以节省内存空间; - rootfs:位于bootfs之上,表现为docker容器的根文件系统;
- 传统模式中,系统启动时,内核挂载rootfs时会首先将其挂载为“只读”模式,完整性自检完成后会将其重新挂载为读写模式;
- docker中,rootfs有内核挂载为“只读”模式,而后通过UFS技术挂载一个“可写”层(最上层)。
docker commit制作镜像
- 使用已有的镜像启动一个容器;
- 将启动的容器修改自己想要的状态;
- 退出容器;
docker commit 容器ID 新镜像名;
使用Dockerfile创建镜像
Dockerfile基本结构
Dockerfile是一种文本格式的配置文件,我们可以使用Dockerfile来快速构建自定义的镜像,Dockerfile是由一行一行的命令语句组成的,并且支持以“#”开头的注释行。一般来说,Dockerfile的主体分为四部分:
- 基础镜像信息;
base image,建议使用官方提供的镜像; - 维护者信息;
- 镜像操作指令;
- 容器启动时执行的指令;
示例:
# 基础镜像
FROM rockylinux:9
# 维护者信息
LABEL authors="1565627677@qq.com"
# 添加yum仓库,nginx.repo文件需要与Dockerfile在同一目录下
COPY nginx.repo /etc/yum.repos.d/nginx.repo
# 安装nginx
RUN yum -y install nginx && yum clean all
# 使用&&连接的两条命令会被放在镜像的同一层,不同的层之间是不能修改数据的
RUN echo "daemon off;" >> /etc/nginx/nginx.conf
# 启动nginx的命令
CMD /usr/sbin/nginx
我们使用 FROM 指令指明所基于的镜像名称,接下来一般是使用 LABEL 指令说明维护者信息。后面则是镜像操作指令,例如 RUN 指令将对镜像执行跟随的命令。每运行一条 RUN 指令,镜像添加新的一层,并提交。最后是 CMD 指令,来指定运行容器时的操作命令。
Dockerfile文件中的指令说明
Dockerfile中的指令一般格式为INSTRUCTION arguments,包括“配置指令”(配置镜像信息)和“操作指令”(具体执行操作):
| 指令(大写) | 说明 |
|---|---|
| FROM | 指定所创建镜像的基础镜像 |
| ARG | 定义创建镜像过程中使用的变量 |
| LABEL | 为生成的镜像添加元素数据标签信息 |
| EXPOSE | 声明镜像内服务监听的端口 |
| ENV | 指定环境变量 |
| ENTRYPOINT | 指定镜像的默认入口命令 |
| VOLUME | 创建一个数据卷挂载点 |
| USER | 指定运行容器时的用户名和UID |
| WORKDIR | 配置工作目录 |
| ONBUILD | 创建子镜像时指定自动执行的操作指令 |
| STOPSIGNAL | 指定退出的信号值 |
| HEALTHCHECH | 配置所启动容器如何进行健康检查 |
| SHELL | 指令默认shell类型 |
| RUN | 运行指定命令 |
| CMD | 启动容器时默认使用的命令 |
| ADD | 添加内容到镜像 |
| COPY | 复制内容到镜像 |
指令详解
- FROM
作用:指定所创建镜像的基础镜像。
格式:FROM <image> [AS <name>] 或 FROM <image>:<tag> [AS <name>] 或 FROM <image>@<digest> [AS <name>]
注意:任何一个Dockerfile中的第一条指令必须为FROM指令。
举例:
# Base image
FROM rockylinux:9
# Maintainer
LABEL authors="1565627677@qq.com"
# Install tools
RUN yum -y install telnet lrzsz iproute && yum clean all
CMD ["/bin/bash"]
# 1.创建镜像
docker build -t rockytools:9 -f Dockerfile .
# 2.运行镜像
docker run -it rockytools:9 /bin/bash
# 3.验证:
telnet www.baidu.com 80 或 ip a
- ARG和ENV
定义创建镜像过程中使用的变量/环境变量。
格式:ARG <name>[=<default value>]
`ENV <key>=<value> ...`
注意:在执行 docker build 时,可以通过 --build-arg [=] 来为变量赋值。当镜像编译成功后,ARG 指定的变量将不再存在(ENV 指定的变量将在镜像中保留)。
举例:
# Base image
FROM rockylinux:9
# Maintainer
LABEL authors="1565627677@qq.com"
# 自定义变量/环境变量
ARG VERSION=1.26.0
ENV NGINX_VERSION=1.26.1
# 定义监听端口
EXPOSE 80
# 指定工作目录
WORKDIR /data
# Add nginx yum repo
COPY nginx.repo /etc/yum.repos.d/nginx.repo
# Install nginx
# $变量名引用自定义的变量
RUN yum -y install nginx-1:$VERSION-1.el9.ngx.x86_64 && yum clean all
#RUN yum -y install nginx-1:$NGINX_VERSION-1.el9.ngx.x86_64 && yum clean all
RUN echo "daemon off;" >> /etc/nginx/nginx.conf
# Start nginx daemon
CMD ["/usr/sbin/nginx"]
docker build -t nginx:1.26.1 --build-arg VERSION=1.26.1 .
# ARG 的变量可以在 docker build 的过程中使用 --build-arg 参数修改变量的值。
docker run -it nginx:1.26.1 /bin/bash
# 查看nginx的版本
nginx -V
:::info
ARG和ENV的区别:
ARG定义的是变量,变量可以通过运行容器时使用--build-arg选项指定变量的值,而ENV定义的是环境变量,不能通过启动时的选项指定值;
ARG定义的变量启动完容器之后就会失效,之后就不能使用了,而使用ENV定义的变量是环境变量,启动完容器之后会存放在容器中,后续可以继续使用。
:::
- LABEL
作用:可以为生成的镜像添加元数据标签信息。
格式:LABEL <key>=<value> <key>=<value> <key>=<value> ...
举例:
LABEL version="1.0.0-rc3"
LABEL author="chijinjing@xinxianghf.com" date="2023-01-01"
LABEL description="This text illustrates \
that label-values can span multiple lines."
# Base image
FROM rockylinux:9
# Maintainer
LABEL authors="1565627677@qq.com"
# 自定义标签
LABEL date="2026-01-04"
LABEL description="This is a demo image that based on Rockylinux9."
CMD /bin/bash
# 构建镜像
docker build -t nginx-label:v1 .
# 使用inspect就可以看到自定义标签的内容
docker inspect nginx-label:v1
- EXPOSE
作用:声明镜像内服务监听的端口;
格式:EXPOSE <port> [<port>/<protocol>...]
举例:
EXPOSE 80 443
这个指令只能起到声明作用,并不会自动完成端口映射。
- ENTRYPOINT和CMD
作用:
ENTRYPOINT:指定镜像的默认入口命令。
CMD:指定启动容器时默认执行的命令。
格式:
ENTRYPOINT:支持两种格式:
第一种:ENTRYPOINT ["executable", "param1", "param2"]:使用exec执行;建议使用这种方式;
第二种:ENTRYPOINT command param1 param2:在shell终端执行。
CMD:支持三种格式:
第一种:CMD ["executable", "param1", "param2"]:相当于执行 executable param1 param2,推荐方式;
第二种:CMD command param1 param2:在默认的 Shell 中执行,提供给需要交互的应用;
第三种:CMD ["param1", "param2"]:提供给 ENTRYPOINT 的默认参数。
注意:
每个Dockerfile中只能有一个ENTRYPOINT,当指定多个时,只有最后一个生效;
每个Dockerfile只能有一条CMD命令。如果指定了多条命令,只有最后一条会被执行。
:::info
exec执行和在shell中执行的区别:
直接执行(exec):
直接调用二进制程序;
不经过shell解析(即不通过sh -c);
环境变量、工作目录等都保持当前进程的上下文;
通常由系统服务管理器(如:systemd)或脚本直接启动。
通过shell执行:
先启动一个shell进程(/bin/sh),再让这个shell执行启动命令;
或多出一层进程结构:sh → 服务;
可以用于复杂命令组合,比如带参数、环境设置等;
但对简单命令来说,多了一层开销。
:::
:::info
ENTRYPOINT和CMD的区别:
ENTRYPOINT目的和CMD一样,都是指定容器启动程序及参数。
当指定了ENTRYPOINT后,CMD 的含义就发生了改变,不再是直接的运行其命令,而是将CMD 的内容作为参数传给ENTRYPOINT指令,实际执行时,将变为:<ENTRYPOINT> "<CMD>" 。
:::
- VOLUME 卷
作用:创建一个数据卷挂载点;
格式:VOLUME ["/data"]
注意:运行容器时可以从本地主机或其他容器挂载数据卷,一般用来存放数据库和需要保持的数据。
- USER
作用:指定运行容器时的用户名或 UID,后续的 RUN 等指令也会使用指定的用户身份。
格式:USER 用户名
注意:当服务不需要管理员权限时,可以通过该命令指定运行用户,并且可以在Dockerfile中创建所需要的用户。
举例:
# Base image
FROM rockylinux:9
# Maintainer
LABEL authors="1565627677@qq.com"
# Add user
RUN groupadd -r redis && useradd -r -g redis redis
USER redis
CMD ["/bin/bash"]
- WORKDIR
作用:为 RUN、CMD、ENTRYPOINT 指令配置工作目录
格式:WORKDIR 工作目录名(推荐使用绝对路径)
注意:可以使用多个WORKDIR指令,后续命令如果参数是相对路径,则会基于之前命令指定的路径。
举例:
# Base image
FROM rockylinux:9
# Maintainer
LABEL authors="1565627677@qq.com"
WORKDIR /data
COPY app.json .
WORKDIR /data/app/
COPY app.jar .
WORKDIR /data/applog/
CMD ["/bin/bash"]
- ONBUILD
作用:指定当基于所生成镜像创建子镜像时,自动执行的操作指令。
格式:ONBUILD [INSTRUCTION]
注意:使用 docker build 命令创建子镜像 ChildImage 时(FROM ParentImage),会首先执行 ParentImage 中配置的 ONBUILD指令。
- STOPSIGNAL
作用:指定容器接收退出的信号值;
- HEALTHCHECK
作用:配置所启动容器如何进行健康检查(如何判断健康与否),自Docker 1.12开始支持。
支持两种格式:
第一种:HEALTHCHECK [OPTIONS] 检查的命令:根据所执行命令返回值是否为 0 来判断;
第二种:HEALTHCHECK NONE:禁止基础镜像中的健康检查。
--interval=DURATION (default: 30s):过多久检查一次;
--timeout=DURATION (default: 30s):每次检查等待结果的超时;
--retries=N (default: 3):如果失败了,重试几次才最终确定失败。
举例:
# Base image
FROM rockylinux:9
# Maintainer
LABEL authors="1565627677@qq.com"
WORKDIR /usr/local/app
COPY http-demo .
HEALTHCHECK --interval=5s --timeout=3s --retries=3\
CMD curl -fs http://localhost:8080/
CMD ["./http-demo"]
- SHELL
作用:指定其他命令使用 shell 时的默认shell类型;
格式:SHELL ["executable", "parameters"]
默认值:["/bin/sh", "-c"]。
- RUN
作用:运行指定命令;
格式:
第一种:RUN <command>:在 shell 终端中执行;
第二种:RUN ["executable", "param1", "param2"]:使用 exec 执行。
注意:每条 RUN 指令将在当前镜像基础上执行指定命令,并提交为新的镜像层。当命令较长时可以使用 \ 来换行。
- ADD
作用:添加内容到镜像;
格式:ADD 想要添加的文件 添加到的位置;
其中 可以是 Dockerfile 所在目录的一个相对路径(文件或目录);也可以是一个 URL;还可以是一个tar 文件(自动解压为目录) 可以是镜像内绝对路径,或者相对于工作目录(WORKDIR)的相对路径。
- COPY
作用:复制内容到镜像;
格式:COPY 想要复制的文件 复制的目标位置
复制本地主机的 (为Dockerfile所在目录的相对路径,文件或目录)下内容到镜像中的 。目标路径不存在时,会自动创建。
路径同样支持正则格式。
:::info
在 Docker 官方的 Dockerfile 最佳实践文档 中要求,尽可能的使用 COPY,因为 COPY 的语义很明确,就是复制文件而已,而 ADD 则包含了更复杂的功能,其行为也不一定很清晰。最适合使用 ADD 的场合,就是需要自动解压缩的场合。
:::
制作镜像举例
- 制作Java应用镜像
制作rocky9+JDK11的镜像:
# Base image
FROM rockylinux:9
# Maintainer
LABEL authors="1565627677@qq.com"
# 定义JDK版本
ENV JAVA_VERSION=jdk-11.0.25
# 复制事先准备的JDK到容器中
COPY ${JAVA_VERSION} /usr/local/${JAVA_VERSION}
# 添加环境变量
ENV JAVA_HOME=/usr/local/${JAVA_VERSION}
ENV PATH=${JAVA_HOME}/bin:$PATH
CMD ["/bin/bash"]
# 构建镜像
docker build -t rocky-jdk11:v1 .
# 查看镜像
docker images rocky-jdk11:v1
# 运行容器
docker run -it rocky-jdk11:v1 /bin/bash
# 查看JDK版本
java -version
在`rocky9+JDK11`镜像中添加java应用,并制作成新的镜像:
FROM rocky-jdk11:v1
# Maintainer
LABEL authors="1565627677@qq.com"
# 设置时区
RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
RUN echo 'Asia/Shanghai' >/etc/timezone
# 监听端口
EXPOSE 8080
# 指定工作目录
WORKDIR /data/app/
# 上传java应用工作目录中
COPY app.jar .
# 启动容器命令
ENTRYPOINT ["java", "-jar", "app.jar"]
- 制作前端应用镜像
前端应用一般采用 Nginx 进行处理,Nginx 可以直接使用官方的镜像,我们只需要修改 nginx.conf配置文件,然后一起打包到镜像中就可以了。
# 前置镜像
FROM nginx:1.22.1
# 上传前端应用,前端项目打包后会生成dist目录,一起打包到镜像中
COPY /dist /usr/local/web/
# 上传nginx.conf
COPY nginx.conf /etc/nginx/nginx.conf
# 启动
CMD ["nginx", "-g", "daemon off;"]
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name localhost;
real_ip_header X-Real-IP;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location / {
root /usr/local/web;
index index.html;
try_files $uri $uri/ /index.html;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
}
docker build -t front-app:v1 .
docker run -d front-app:v1
构建上下文
- 当运行
docker build命令时,宿主机中当前工作目录被称为构建上下文,build context。 docker build默认查找当前目录的Dockerfile作为构建输入,也可以通过-f指定Dockerfile。docker build -t 镜像名 -f ./Dockerfile
- 当
docker build运行时,首先会将构建上下文传输给docker daemon,把没用的文件包含在构建上下文时,会导致传输时间长,构建需要的资源多,构建出来的镜像大等问题。- 可以通过
.dockerignore文件从编译上下文排除文件。
- 可以通过
- 需要确认构建上下文清晰,建议创建一个单独的目录放置
Dockerfile文件,并在目录中运行docker build。
.dockerignore文件
在使用 Docker 构建镜像时,我们通常会将项目的文件和文件夹复制到镜像中。然而,并不是所有的文件和文件夹都需要被复制进镜像中,有时我们需要排除一些不需要的文件夹或文件。这就是使用 .dockerignore 文件的作用。
.dockerignore 文件类似于 .gitignore 文件,它用于告诉 Docker 哪些文件或文件夹不应该被复制到镜像中。当构建镜像时,Docker 引擎会根据 .dockerignore 文件的规则来排除指定的文件和文件夹。
举例:
myapp/
├── app/
│ ├── index.js
│ ├── styles.css
│ └── images/
│ ├── logo.png
│ └── bg.png
├── config/
│ ├── db.js
│ └── secret.js
├── tests/
│ ├── test1.js
│ └── test2.js
├── README.md
└── .dockerignore
如果我们只想将 app 文件夹复制到镜像中,而不包含 config 和 tests 文件夹,我们可以在 .dockerignore 文件中添加以下内容:
config/
tests/
.dockerignore 文件的规则:
- #:用于添加注释。以 # 开头的行将被忽略。
- /path/to/folder:排除指定的文件夹以及其内容。
- /path/to/file:排除指定的文件。
- !:用于取反。如果文件夹被排除了,但是又想包含此文件夹内的某个文件,可以在前面加上!。
# 忽略所有 .txt 文件
*.txt
# 忽略所有文件夹和子文件夹中的 .log 文件
**/*.log
# 排除 .git 文件夹及其内容
.git/
# 排除 node_modules 文件夹及其内容
node_modules/
# 但是包含 node_modules/myapp 文件夹及其内容
!node_modules/myapp/
多平台架构
- 查看镜像支持的平台
# 查看本地镜像支持的架构平台
docker inspect 镜像名:版本号 | grep -i arch
# 查看远程仓库中的镜像支持的架构
docker manifest inspect 镜像名:版本号 | grep architecture
- 制作支持多平台架构的镜像
# 确认buildx功能启用
docker buildx create --use
# 构建多平台镜像,并推送到仓库
docker buildx build --platform linux/amd64,linux/arm64,... -t 镜像名:版本号 --load .
docker buildx 构建的镜像只保存在缓存中,本地无法查看,如果需要在本地显示,需要加 --load 参数,在本地加载镜像,注意 --load 参数只可以指定一个平台;
或者在构建时直接推送到仓库中:
docker buildx build --platform linux/amd64,linux/arm64 -t reg.xxhf.cc/library/rockylinux:v1 --push .
六、镜像存储机制
什么是Docker镜像?
Docker镜像是一个只读的docker容器模板,含有启动Docker容器所需的文件系统结构及其内容,因此镜像是启动一个容器的基础。Docker镜像文件的内容加上一些运行Docker容器的配置文件组成了Docker容器的静态文件系统运行环境—rootfs。可以理解为:Docker镜像是Docker容器的静态视角,Docker容器是Docker镜像的运行状态。
rootfs是Docker容器在启动时内部进程可见的文件系统,即Docker容器的根目录。rootfs通常包含一个操作系统运行所需的文件系统,例如可能包含典型的类Unix操作系统中的目录系统,如 /dev、/proc、/bin、/etc、/lib、/usr、/tmp 及运行Docker容器所需的配置文件、工具等。
在传统的Linux操作系统内核启动时,首先挂载一个只读(read-only)的rootfs,当内核检测完整性之后,再将其切换为读写(read-write)模式。而在Docker架构中,当Docker deamon为Docker容器挂载rootfs时,沿用了Linux内核启动时的方式,将rootfs设置为只读模式,挂载完毕之后,利用联合挂载(union mount)的技术在已有的只读rootfs之上在挂载一个读写层。这样一来,可读写层位于Docker容器文件最上层,其下可能联合挂载多个只读层,只有在Docker容器运行过程中文件系统发生变化时,才会把变化的文件内容写到可读写层,并隐藏只读层中老版本的文件。
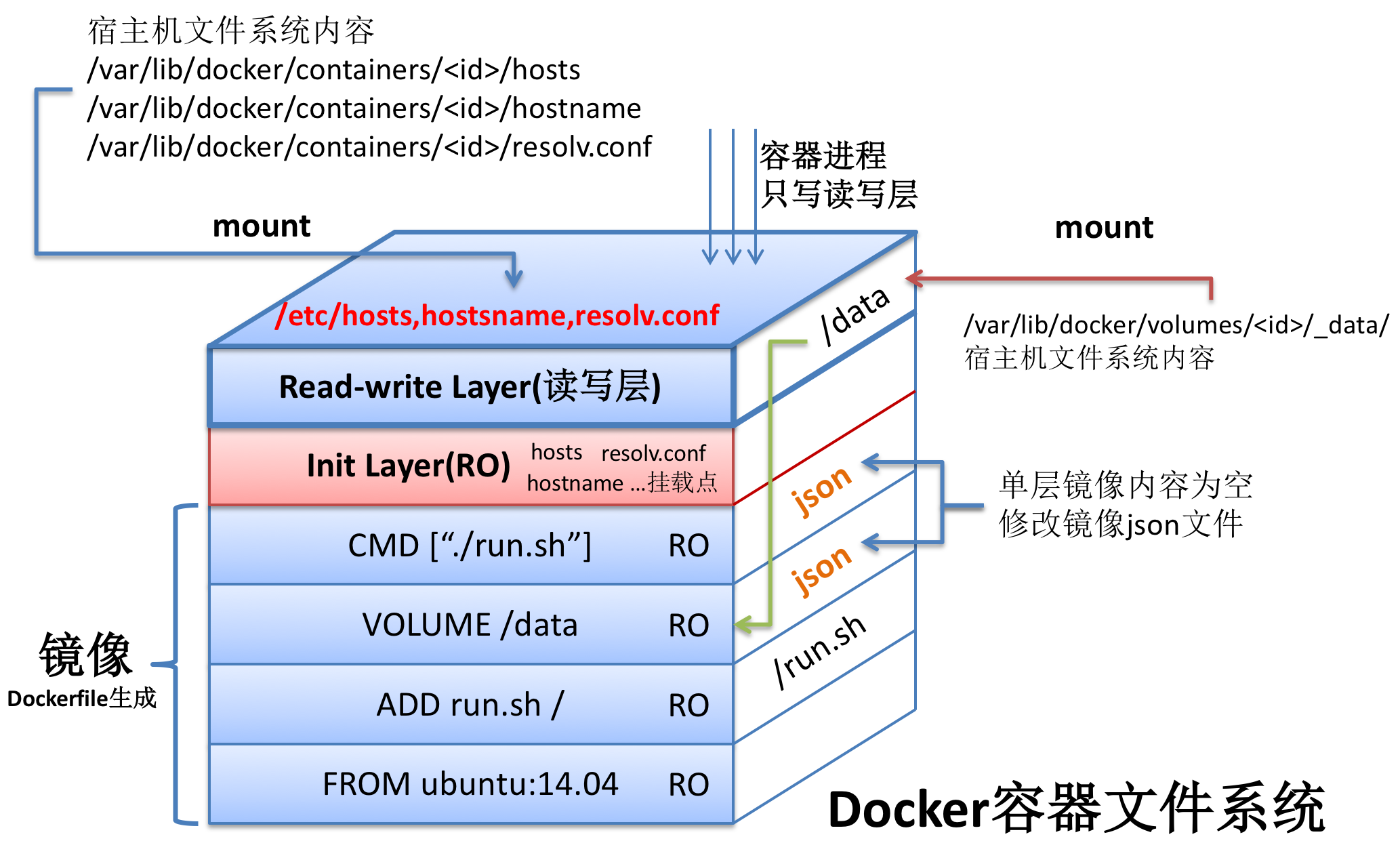
OverlayFS存储原理
OverlayFS结构分为三个层:LowerDir、UpperDir、MergedDir。
- LowerDir(只读层):
只读的 image layer ,其实就是容器的 rootfs,在使用Dockerfile构建镜像的时候,Image Layer 可以分为很多层,所以对应的 LowerDir 会很多(镜像源)。
- UpperDir(读写层):
UpperDir 就是在 LowerDir 之上的读写层。容器在启动时创建 UpperDir 层,所有对容器的修改操作都是在这个层。比如容器启动写入的日志文件,或者是应用程序写入的临时文件。
- MergedDir(合并层):
Merged 目录是容器的挂载点,在用户视角能够看到所有文件,都是从这层展示的,这层是启动容器时将 LowerDir 和 UpperDir 合并的新层。
- WorkDir(工作目录):
workdir 是 OverlayFS 内部用于处理写入操作的临时目录。
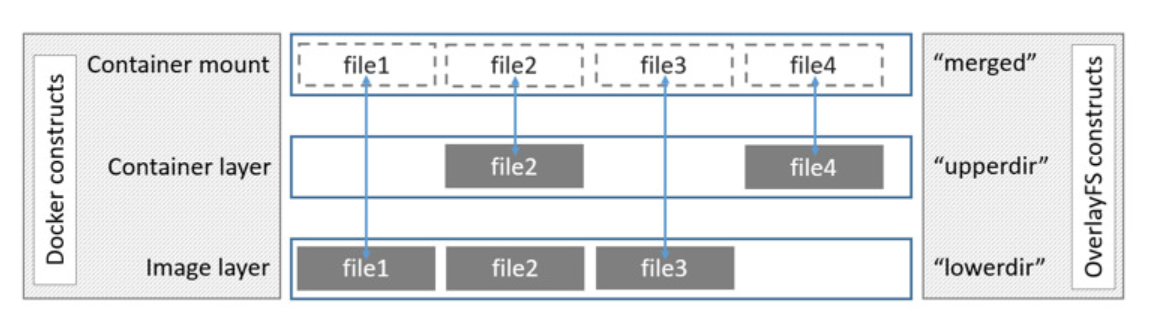
实验:验证OverlayFS文件系统
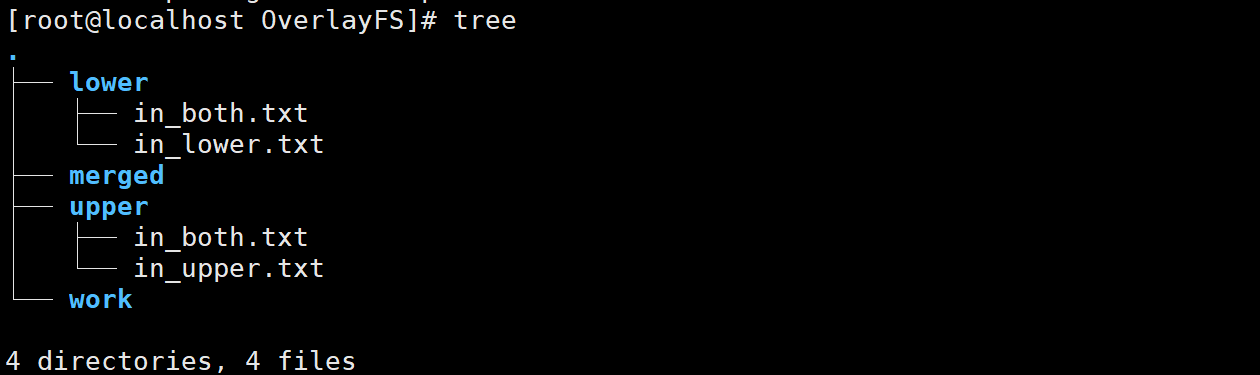
3. 创建模拟三层结构的文件系统:
# 创建需要的目录和文件
mkdir /OverlayFS
cd /OverlayFS
mkdir upper lower merged work
echo "I'm from lower" > lower/in_lower.txt
echo "I'm from upper" > upper/in_upper.txt
# `in_both` is in both directories
echo "I'm from lower" > lower/in_both.txt
echo "I'm from upper" > upper/in_both.txt
# 挂载 overlay 文件系统
mount -t overlay overlay \
-o lowerdir=/OverlayFS/lower,upperdir=/OverlayFS/upper,workdir=/OverlayFS/work \
/OverlayFS/merged
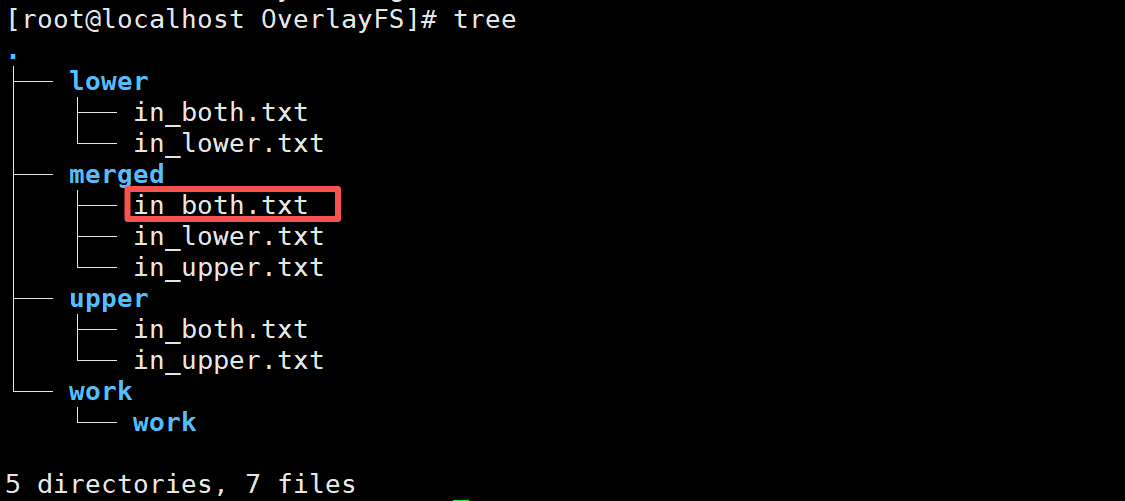

2. 实验结论:挂载后,OverlayFS文件系统会将 LowerDir(只读层) 和 UpperDir(读写层) 合并,并且优先显示UpperDir(读写层)的内容,当修改 MergedDir 中的 LowerDir(只读层)对应的内容时,只在 MergedDir(合并层)中修改,真正的LowerDir不做改变;当修改 MergedDir 中的 UpperDir(读写层)对应的内容时,MergedDir 和 UpperDir 都会修改内容;当在MergedDir中删除UpperDir和LowerDir都有的内容时,会在UpperDir生成一个同名的字符设备文件,用于遮挡LowerDir中的同名文件。
/var/lib/docker/overlay2
七、Docker网络
Docker网络启动过程
Docker 服务启动时会在主机上自动创建一个 docker0 的虚拟网桥,网桥可以理解为一个软件交换机,负责挂载在其上的接口之间的包转发。
Docker 随机分配一个本地未占用的私有网段中的一个地址给 docker0 接口,默认是172.17.0.0/16网段,此后启动的容器会自动分配一个该网段的地址。
当创建一个 Docker 容器的时候,同时会创建一对veth pair互联接口。当向任一个接口发送包时,另外一个接口自动收到相同的包。互联接口的一端位于容器内,即 eth0;另一端在本地并被挂载到 docker0 网桥,名称以veth 开头(例如 vethae12ch)。通过这种方式,主机可以与容器通信,容器之间也可以相互通信。如此一来,Docker 就创建了在主机和所有容器之间一个虚拟共享网络。
# 查看网桥
# brctl 命令默认没有安装,安装命令: yum -y install bridge-utils
brctl show
结果:
bridge name bridge id STP enabled interfaces
docker0 8000.02425d66988c no vethab7e230
vethae685cc
# 查看 docker0 接口
ifconfig docker0
结果:
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:5dff:fe66:988c prefixlen 64 scopeid 0x20<link>
ether 02:42:5d:66:98:8c txqueuelen 0 (Ethernet)
RX packets 2478196 bytes 478260325 (456.1 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2530684 bytes 573536572 (546.9 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 容器内接口 eth0@if211,宿主机上对应 ID 为 211 的接口。
ip a
结果:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
210: eth0@if211: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
ip a
结果:
211: vethae685cc@if210: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 3e:e7:73:e9:d9:13 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::3ce7:73ff:fee9:d913/64 scope link
valid_lft forever preferred_lft forever
Docker网络的连通性
- 容器访问外部
容器默认指定了网关为docker0网桥上的docker0内部接口。docker0内部接口同时也是宿主机的一个本地接口。因此,容器默认情况下可以访问到宿主机本地网络。如果容器要想通过宿主机访问到外部网络,则需要宿主机进行辅助转发。
- 开启内核包转发功能:
sysctl -w net.ipv4.ip_forward=1; - 配置 SNAT 规则:
假设容器内部的网络地址为172.17.0.2,本地网络地址为10.0.2.2。容器要能访问外部网络,源地址不能为172.17.0.2,需要进行源地址映射(Source NAT,SNAT),修改为本地系统的IP地址10.0.2.2。
映射是通过iptables的源地址伪装操作实现的。查看主机nat表上 POSTROUTING 链的规则。该链负责数据包要离开主机前,改写其源地址:
iptables -tnat -nvL POSTROUTING
结果:
Chain POSTROUTING (policy ACCEPT 7920 packets, 499K bytes)
pkts bytes target prot opt in out source destination
0 0 MASQUERADE all -- * !docker0 172.17.0.0/16 0.0.0.0/0
其中,上述规则将所有源地址在172.17.0.0/16网段,且不是从docker0接口发出的流量(即从容器中出来的流量),动态伪装为从系统网卡发出。
- 外部访问容器
容器允许外部访问,可以在docker run的时候通过-p或-P参数来启用。
不管用那种办法,其实也是在本地的 iptable 的 nat 表中添加相应的规则,将访问外部的 IP 地址的包进行目标地址转换,将目标地址修改为容器的 IP 地址。
以开放80端口的nginx为例,使用-P时,会自动映射本地的32768~65535范围内的随机端口为容器的80端口;使用-p 80:80时,会将本地的80端口映射为容器的80端口;
# -P
docker run --rm -P nginx:1.22.1
# -p
docker run --rm -p 80:80 nginx:1.22.1
# 查看端口映射关系
iptables -t nat -nvL
- 容器之间相互访问
容器默认都连接在 Docker0 网桥上,都可以互相访问,相当连于在一台二层交换机上。
但是容器的 IP 地址是动态变化的,如果两个应用之间要互相访问就无法通过 IP 地址互相通信,Docker 提供两种方案来解决。
方法一:--link:传统方式,目前 docker 官网不建议使用;
以部署一个WordPress应用为例:
docker pull registry.cn-beijing.aliyuncs.com/xxhf/wordpress:php7.4
docker tag registry.cn-beijing.aliyuncs.com/xxhf/wordpress:php7.4 wordpress:php7.4
docker pull registry.cn-beijing.aliyuncs.com/xxhf/mysql:8.0
docker tag registry.cn-beijing.aliyuncs.com/xxhf/mysql:8.0 mysql:8.0
# 启动mysql容器的时候需要指定数据库的参数
docker run -d --name db_wordpress --restart always \
-e MYSQL_ROOT_PASSWORD=wordpress \
-e MYSQL_DATABASE=db_wordpress \
-e MYSQL_USER=wordpress_rw \
-e MYSQL_PASSWORD=123456 \
-p 3306:3306 mysql:8.0
# 验证数据库正常运行
docker run -d --link db_wordpress -it mysql-client -uroot -pwordpress -hdb_wordpress
# 使用 --link 连接mysql数据库
docker run -d --name wordpress --restart always --link db_wordpress \
-e WORDPRESS_DB_HOST=db_wordpress:3306 \
-e WORDPRESS_DB_USER=wordpress_rw \
-e WORDPRESS_DB_PASSWORD=123456 \
-e WORDPRESS_DB_NAME=db_wordpress \
-p 80:80 wordpress:php7.4
`--link`是通过在本地解析文件 `/etc/hosts` 添加主机记录来实现DNS域名解析的。
docker exec -it wordpress cat /etc/hosts
结果:
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.17.0.2 db_wordpress 18722c02cb87
172.17.0.3 9aeb4e1dfe63
方法二:自定义网络
# 创建
docker network create wp-net
# 查看
docker network ls
结果:
NETWORK ID NAME DRIVER SCOPE
0cc88dcd390d bridge bridge local
385ab96da9ee host host local
43634758fc70 none null local
e4e3d1ee7062 wp-net bridge local
# 重新运行mysql容器
# 使用 --network 指定连接的网桥
docker run -d --name db_wordpress --restart always \
--network wp-net \
-e MYSQL_ROOT_PASSWORD=wordpress \
-e MYSQL_DATABASE=db_wordpress \
-e MYSQL_USER=wordpress_rw \
-e MYSQL_PASSWORD=123456 \
-p 3306:3306 mysql:8.0
# 重新运行WordPress容器
# 使用 --network 指定连接的网桥
docker run -d --name wordpress --restart always --network wp-net \
-e WORDPRESS_DB_HOST=db_wordpress:3306 \
-e WORDPRESS_DB_USER=root \
-e WORDPRESS_DB_PASSWORD=wordpress \
-e WORDPRESS_DB_NAME=db_wordpress \
-p 80:80 wordpress:php7.4
# 两个容器连接到同一个网桥,所以可以通过容器名相互通信。
自定义网桥可以自动实现容器间的DNS解析,没有修改 `/etc/hosts` 文件。
docker的网络模式
- host模式
Docker使用了Linux的Namespaces技术来进行资源隔离,如PID Namespace隔离进程,Mount Namespace隔离文件系统,Network Namespace隔离网络等。一个Network Namespace提供了一份独立的网络环境,包括网卡、路由、Iptable 规则等都与其他的 Network Namespace 隔离。一个 Docker 容器一般会分配一个独立的 Network Namespace。但如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。
例如,我们在10.10.101.105/24 的机器上用 host 模式启动一个含有web应用的Docker容器,监听 tcp80 端口。
当我们在容器中执行任何类似ifconfig命令查看网络环境时,看到的都是宿主机上的信息。而外界访问容器中的应用,则直接使用10.10.101.105:80即可,不用任何NAT转换,就如直接跑在宿主机中一样。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
- bridge模式
Docker 服务默认会创建一个 docker0 网桥(其上有一个 docker0 内部接口)。
Docker 默认指定了 docker0 接口 的 IP 地址和子网掩码,让主机和容器之间可以通过网桥相互通信。
--network bridge:设置容器工作在bridge模式下,即将容器接口添加至 docker0 网桥。
- none模式
此模式下容器不参与网络通信,运行于此类容器中的进程仅能访问本地环回接口,仅适用于进程无须网络通信的场景中,例如备份,进程诊断及各种离线任务等。
--network=none:设置模式容器工作在none模式下。
Namespace
Docker 是借助 Linux 内核技术 Namespace 来实现隔离的, Linux Namespaces 机制提供一种资源隔离方案。 PID,IPC,Network 等系统资源不再是全局性的, 而是属于某个特定的 Namespace。 每个 namespace 下的资源对于其他 namespace 下的资源都是透明, 不可见的。 因此在操作系统层面上看, 就会出现多个相同 pid 的进程。 系统中可以同时存在多个进程号为 0,1,2 的进程, 由于属于不同的 namespace, 所以它们之间并不冲突。 而在用户层面上只能看到属于用户自己 namespace 下的资源, 例如使用 ps 命令只能列出自己 namespace 下的进程。这样每个 namespace 看上去就像一个单独的 Linux 系统。
目前支持的Namespace类型:
| Namespace类型 | 内核版本 | 加入时间 | 描述 |
|---|---|---|---|
| Mount(mnt) | 2.4.19 | 2002年 | 隔离文件系统挂载点 |
| UTS | 2.6.19 | 2006年 | 隔离主机和域名 |
| IPC | 2.6.19 | 2006年 | 隔离进程间的通信(如消息队列,信号量等) |
| PID | 2.6.24 | 2008年 | 隔离进程ID空间 |
| Network(net) | 2.6.29 | 2009年 | 隔离网络设备、协议栈、端口等 |
| User | 3.8 | 2013年 | 隔离用户和用户组ID |
| Cgroup | 4.6 | 2016年 | 隔离Cgroup视图 |
| Time | 5.6 | 2020年 | 隔离系统时间 |
- Namespace常用操作:
# 查看当前系统的Namespace
lsns
# 查看某个进程的Namespace
ls -la /proc/进程号/ns
# 进入某个Namespace执行命令
# 进入系统主进程下执行 ip addr 命令,查看到的结果跟在系统 bash下 执行 ip addr 结果一样
nsenter -t 1 -n ip addr
# 运行一个容器,在容器的Namespace下执行命令
# 运行一个容器
docker run -d nginx:1.22.1
# 查看容器运行的PID
docker inspect fba13bee9964 | grep -i pid
# 在容器的 namespace 中执行 命令
nsenter -t 容器PID -n ip a
# 查询容器的ip地址
docker inspect fba13bee9964 | grep -i ipaddr
网络Namespace
使用ip netns命令操作network namespace
# 创建一个名为 nstest 的 network namespace
ip netns add nstest
# 列出系统已存在的network namespace
ip netns list
或:
ls -al /var/run/netns/
# 在 network namespace 中执行命令
ip netns exec nstest ip addr
# 删除 network namespace: nstest
ip netns delete nstest
实验:为null模式的容器添加网络
第一步:运行一个网络模式为none的容器:
docker run --network=none -it busybox
# 查看容器的网络接口
docker exec 容器ID ip a
第二步:进入容器 namespace 查看网络配置:
# 获取容器进程ID
方法1:docker inspect 2350cedb3238 | grep -i pid
方法2:docker inspect -f '{{.State.Pid}}' 2350cedb323
# 查看容器的IP
nsenter -t 容器进程号 -n ip a
第三步:创建一个自定义网络 net0:
docker network create -d bridge --subnet 172.100.0.0/16 net0
以上命令创建了一个名为 net0 的网桥,该网络使用的是 bridge 模式,网段是 172.100.0.0/16, 该网络的第一个IP地址 172.100.0.1 分配给了网桥,网桥的名字可以通过ip a命令查到。
如果想查看网桥的详细信息,可以使用 inspect 命令:
docker network inspect net0
第四步:为容器绑定 veth pair 网卡,并接入上面创建的网桥上:
# 定义环境变量,用于给容器分配上网资源
# 获取容器运行的PID
PID=$(docker inspect -f '{{.State.Pid}}' fa228d33773c)
# 即将分配给容器的IP
IPADDR=172.100.0.2
# 掩码
NETMASK=255.255.0.0
# 网关
GATEWAY=172.100.0.1
# 如果想要netns命令管理容器的网络,容器的网络文件必须在/var/run/netns/目录下,这里采用创建软链接的方法
ln -s /proc/$PID/ns/net /var/run/netns/$PID
# 查看结果,能看到进程号说明成功
ip netns ls
# 创建一对veth pair,vetha 和 vethb
ip link add vetha type veth peer name vethb
# 将 vetha 绑定到新建的网桥上
brctl addif 网桥ID(ip a可看) vetha
# 启用 vetha
ip link set vetha up
# 将 vethb 放入指定的网络命名空间
ip link set vethb netns $PID
# 在指定的命名空间中将 vethb 改名为 eth0
ip netns exec $PID ip link set dev vethb name eth0
# 启用 eth0
ip netns exec $PID ip link set eth0 up
# 为 eth0 添加 IP 地址
ip netns exec $PID ip addr add $IPADDR/$NETMASK dev eth0
# 添加默认网关
ip netns exec $PID ip route add default via $GATEWAY
如何修改docker0的IP
修改 docker0 网桥IP地址段,打开 /etc/docker/daemon.json 文件,修改如下:
{
"bip": "192.168.1.1/24",
"fixed-cidr": "192.168.1.0/25"
}
修改配置文件之后需要重启docker才会生效。
八、Docker存储
Docker的镜像是由一系列的只读层组合而来的,当启动一个容器时,Docker加载镜像的所有只读层,并在最上层加入一个读写层。这个设计使得Docker可以提高镜像构建、存储和分发的效率,节省了时间和存储空间,然而也存在如下问题:
- 容器中的文件在宿主机上存在形式复杂,不能在宿主机上很方便地对容器中的文件进行访问。
- 多个容器之间的数据无法共享。
- 当删除容器时,容器产生的数据将丢失。
为了解决这些问题,Docker引入了数据卷(volume)机制。volume是存在于一个或多个容器中的特定文件或文件夹,这个目录以独立于联合文件系统的形式在宿主机中存在,并为数据的共享与持久化提供以下便利:
- volume 在容器创建时就会初始化,在容器运行时就可以使用其中的文件。
- volume 能在不同的容器之间共享和重用。
- 对volume中数据的操作会马上生效。
- 对volume中数据的操作不会影响到镜像本身。
- volume 的生存周期独立于容器的生存周期,即使删除容器,volume 仍然会存在,没有任何容器使用的volume也不会被Docker删除。
为容器添加volume,类似于Linux的mount操作,用户将一个文件夹作为volume挂载到容器上,可以很方便地将数据添加到容器中供其中的进程使用。多个容器可以共享同一个volume,为不同容器之间的数据共享提供了便利。
创建Volume
使用 docker volume 命令对volume进行创建、查看和删除,与此同时,传统的 -v 参数创建volume的方式也得到了保留。
# 创建一个新的volume
docker volume create my-vol
# 查看所有volume
docker volume ls
# Docker当前并未对volume的大小提供配额管理,用户在创建volume时也无法指定volume的大小。
# 删除卷
docker volume rm 卷名
使用`docker run`或`docker create` 创建新容器时,也可以使用 `-v` 标签为容器添加 volume,以下命令创建了一个随机名字的volume,并挂载到容器中的/data目录下。
docker run -d -v /data nginx:1.22.1
# -v 选项不加volume名时,会随机生成一个volume的卷,然后挂载(不推荐这种写法)
# 查看
docker volume ls
以下命令创建了一个指定名字的volume,并挂载到容器中的/data目录下。
docker run -d -v vol_simple:/data nginx:1.22.1
# -v 主机中的卷:容器中的挂载点 ,如果当前不存在这个卷,会自动创建一个新卷
#查看
docker volume ls
Docker 在创建volume的时候会在宿主机` /var/lib/docker/volumes/`中创建一个以`volume ID` 为名的目录,并将volume中的内容存储在名为data的目录下。
使用docker volume inspect 卷名命令可以获得该volume包括其在宿主机中该文件夹的位置等信息。
docker volume inspect vol_simple
结果:
[
{
"Name": "vol_simple",
"Driver": "local",
"Mountpoint": "/var/lib/docker/volumes/vol_simple/_data"
}
]
挂载volume
用户在使用docker run或docker create创建新容器时,可以使用-v标签为容器添加volume。用户可以将自行创建或者由 Docker 创建的 volume 挂载到容器中,也可以将宿主机上的目录或者文件作为 volume 挂载到容器中。下面分别介绍这两种挂载方式。
- 挂载用户自行创建的volume
用户可以使用如下命令创建volume,并将其创建的volume挂载到容器中的 /data 目录下。
docker volume create --name vol_nginx
docker run -d -v vol_nginx:/data nginx:1.22.1
如果用户不执行第一条命令而直接执行第二条命令的话,Docker会代替用户来创建一个名为 vol_nginx 的 volume,并将其挂载到容器中的 /data目录下。
- 挂载宿主机目录
Docker 也允许我们将宿主机上的目录挂载到容器中。
docker run -d -v /data/docker-volume:/data nginx:1.22.1
使用以上命令将宿主机中的/data/docker-volume 文件夹作为一个 volume 挂载到容器中 /data 目录下。
文件夹必须使用绝对路径,如果宿主机中不存在 /data/docker-volume,将创建一个空文件夹。
在 /data/docker-volume 文件夹中的所有文件或文件夹可以在容器的 /data 文件夹下被访问。如果镜像中原本存在 /data 文件夹,该文件夹下原有的内容将被隐藏,以保持与宿主机中的文件夹一致。
- 挂载宿主机文件
用户还可以将单个的文件作为 volume 挂载到容器中。
docker run -d -v /data/docker-volume/docker-volume.txt:/data/docker-volume.txt nginx:1.22.1
使用上述命令将主机中的 /data/docker-volume/docker-volume.txt 文件作为一个volume挂载到容器中的 /data/docker-volume.txt 。文件必须使用绝对路径。
- 指定挂载权限
将主机上的文件或文件夹作为 volume 挂载时,可以使用 :ro 指定该 volume 为只读。
docker run -d -v /data/docker-volume:/data:ro nginx:1.22.1
- 挂载多个卷
在使用docker run或docker create创建新容器时,可以使用多个-v标签为容器添加多个volume。
docker run -d -v vol-name:/data1 -v /data2 -v /host/dir:/container/dir:ro nginx:1.22.1
使用Dockerfile添加Volume
使用 VOLUME 指令向容器添加 volume。
VOLUME /data
在使用`docker build`命令生成镜像并且以该镜像启动容器时会挂载一个 volume 到 /data 目录下。
共享Volume
在使用docker run或docker create创建新容器时,可以使用--volumes-from标签使得容器与已有的容器共享volume。
# 共享方式1:
docker run --name nginx-01 -d -v myVolume nginx:1.22.1
docker run --name nginx-02 -d -v myVolume nginx:1.22.1
# 启动的容器使用 -v 挂载同一个卷或同一个目录,从而实现volume共享
# 共享方式2:
docker run --name nginx-01 -d --volumes-from myVolume nginx:1.22.1
docker run --name nginx-02 -d --volumes-from nginx-01 nginx:1.22.1
# 后启动的nginx-02使用--volumes-from指向先启动的nginx-01,nginx-02就会自动挂载nginx-01的volume
新创建的容器 nginx-02 与之前创建的容器 nginx-01 共享 volume。
删除Volume
如果创建容器时从容器中挂载了volume,在 /var/lib/docker/volumes 下会生成与 volume 对应的目录,使用docker rm删除容器并不会删除与 volume 对应的目录,这些目录会占据不必要的存储空间,即使可以手动删除,因为有些随机生成的目录名称是无意义的随机字符串,要查找它们与容器的对应关系也十分麻烦。所以在删除容器时需要对容器的 volume 妥善处理。
在删除容器时一并删除volume有以下两种方法。
- 使用
docker rm -v <container_name>删除容器。 - 在运行容器时使用
docker run --rm, --rm 标签会在容器停止运行时删除容器以及容器所挂载的volume。
:::danger
注意:
- 在使用
docker volume rm删除 volume 时,只有在没有任何容器使用时,该 volume 才能成功删除。 - 两种方法只会删除未命名的 volume,而对用户指定名字的 volume 进行保留。
- 如果 volume 是从宿主机中挂载的,无论对容器进行任何操作都不会导致其在宿主机中被删除。
:::
在Docker与宿主机间复制文件
在docker容器与宿主机之间复制文件有两种方式:
方式1:使用lrzsz传输到真实机里
# 先安装lrzsz服务
dnf -y install lrzsz
# 传输:
sz 文件名 ---> 选择接收的目录
方式2:docker cp
# 将宿主机里的文件复制到容器
docker cp 宿主机的文件 容器名:存放路径
docker cp /root/yaml.tgz nginx-01:/tmp/
# 将容器里的文件复制到宿主机
docker cp 容器名:文件 宿主机的路径
docker cp nginx-01:/tmp/yaml.tgz /root
--mount
mount选项也可以用来设置容器启动时挂载的目录或文件:
- 挂载Volume
docker run -d \
--name devtest \
--mount type=volume,source=myvol2,target=/app \
nginx:latest
- 挂载本地目录
docker run -d \
-it \
--name devtest \
--mount type=bind,source="$(pwd)"/target,target=/app \
nginx:latest
docker run -d \
-it \
--name devtest \
--mount type=bind,source="$(pwd)"/target,target=/app,readonly \
nginx:latest
# type:类型;source:挂载谁;target:挂载点;readonly:只读
- 挂载tmpfs
docker run -d \
-it \
--name tmptest \
--mount type=tmpfs,destination=/app \
nginx:latest
-v 和 --mount 的区别:
- -v 或 --volume:由三个字段组成,用冒号字符(:)分隔。这些字段必须按照正确的顺序,并且每个字段的含义不太清晰。
- –mount:由多个键值对组成,用逗号分隔,每个键值对由=组成。–mount 语法比 -v 或 --volume 更冗长,但键的顺序并不重要,并且该标志的值更易于理解。
九、镜像多阶段构建
镜像Cache机制
Docker Daemnon 通过 Dockerfile 构建镜像时,当发现即将新构建出的镜像与已有的某镜像重复时,可以选择放弃构建新的镜像,而是选用已有的镜像作为构建结果,也就是采取本地已经 cache 的镜像作为结果。
Cache注意事项:
ADD 命令与 COPY 命令:Dockerfile 没有发生任何改变,但是命令ADD run.sh / 中 Dockerfile 当前目录下的 run.sh 文件内容发生了变化,从而将直接导致镜像层文件系统内容的更新,原则上不应该再使用 cache。那么,判断 ADD 命令或者 COPY 命令后紧接的文件是否发生变化,则成为是否延用 cache 的重要依据。Docker 采取的策略是:获取 Dockerfile 下内容(包括文件的部分 inode 信息),计算出一个唯一的 hash 值,若 hash 值未发生变化,则可以认为文件内容没有发生变化,可以使用 cache 机制;反之亦然。
RUN 命令存在外部依赖:一旦 RUN 命令存在外部依赖,如RUN apt-get update,那么随着时间的推移,基于同一个基础镜像,一年前的 apt-get update 和一年后的 apt-get update, 由于软件源软件的更新,从而导致产生的镜像理论上应该不同。如果继续使用 cache 机制,将存在不满足用户需求的情况。Docker 一开始的设计既考虑了外部依赖的问题,用户可以使用参数 --no-cache 确保获取最新的外部依赖,命令为docker build --no-cache -t="my_new_image" .
为了更好的利用 docker cache 机制,在书写 Dockerfile 时,应该将更多静态的安装、配置命令尽可能地放在 Dockerfile 的较前位置。
传统的Build流程
先编译打包(生成一个很大的镜像,但是很多东西用不到),再将打包好的应用复制到最终镜像中。
# 基础镜像
FROM golang:1.20 AS build
# 定义环境变量
ENV GO111MODULE=on
ENV GOPROXY=https://goproxy.cn
# 指定工作目录
WORKDIR /go/src/app
# 复制项目到镜像中
COPY . .
# 编译,生成二进制文件,放到/go/bin/app目录中
RUN go mod download
RUN CGO_ENABLED=0 go build -o /go/bin/app
docker build -f Dockerfile-build -t app-build:v1 .
# 运行容器
docker run -it --name app-build app-build:v1 bash
# 取出编译好的二进制文件
docker cp app-build:/go/bin/app .
FROM alpine:3.18
COPY app /
# 运行命令
CMD ["/app"]
Dockerfile中多阶段构建(multi-stage)
# 第一阶段的基础镜像
FROM golang:1.20
WORKDIR /go/src/app
COPY . .
RUN go mod download
RUN CGO_ENABLED=0 go build -o /go/bin/app
# 第二阶段的基础镜像
FROM alpine:3.18
# 复制第一阶段中文件到当前阶段
COPY --from=0 /go/bin/app /
CMD ["/app"]
# AS:为当前阶段起别名
FROM golang:1.20 AS build
WORKDIR /go/src/app
COPY . .
RUN go mod download
RUN CGO_ENABLED=0 go build -o /go/bin/app
FROM alpine:3.18
# 使用别名,从别名为build的镜像中复制
COPY --from=build /go/bin/app /
CMD ["/app"]
Dockerfile优化方案
- 不要安装无效软件包;
- 应简化镜像中同时运行的进程数,理想状况下,每个镜像应该只有一个进程 ;
- 如果无法避免同一镜像运行多进程时,应选择合理的初始化进程(init process) ;
- 最小化层级数:
- 最新的Docker只有 RUN、COPY、ADD 创建新层,其他指令创建临时层,不会增加镜像大小。
- 比如 EXPOSE 指令就不会生成新层。
- 多条 RUN 命令可通过连接符连接成一条指令集,以减少层数 &&
- 通过多阶段构建减少镜像层数
- 最新的Docker只有 RUN、COPY、ADD 创建新层,其他指令创建临时层,不会增加镜像大小。
- 编写 Dockerfile 的时候,应该把变更频率低的编译指令优先构建,放在镜像底层,有效利用 build cache;
- 复制文件时,每个文件应独立复制,这确保某个文件变更时,只影响该文件对应的缓存;
- 选择可以满足业务需求最优的 base image;
目标: 易管理、少漏洞、镜像小、层级少、利用缓存
十、Docker资源限制
cgroup介绍
cgroup是Linux内核提供的一种机制,这种机制可以根据需求把一系列系统任务及其子任务整合(或分隔)到按资源划分等级的不同的组内,从而为系统资源管理提供一个统一的框架。
通俗的说,cgroup 可以限制、记录进程组所使用的物理资源(包括 CPU、Memory、IO等),为容器实现虚拟化提供了基本保证,是构建 Docker 等一系列虚拟化管理工具的基石。
实现 cgroup 的主要目的是为不同用户层面的资源管理,提供一个统一化的接口。从单个任务的资源控制到操作系统层面的虚拟化,cgroup 提供了以下四大功能。
- 资源限制:cgroup 可以对任务使用的资源总额进行限制。如设定应用运行时使用内存的上限,一旦超过这个配额就发出 OOM(Out of Memory)提示。
- 优先级分配:通过分配的CPU时间片数量及磁盘IO带宽大小,实际上就相当于控制了任务运行的优先级。
- 资源统计:cgroup 可以统计系统的资源使用量,如CPU使用时长、内存用量等,这个功能非常适用于计费。
- 任务控制:cgroup 可以对任务执行挂起、恢复等操作。
cgroup 目前有两个版本,在Rockylinux 9 中使用的是 cgroup v2。
如何判断当前操作系统使用的是哪个版本,在操作系统中执行mount | grep cgroup命令。
cgroup v2:限制进程可使用的CPU资源
- 创建一个目录 example ,这个目录表示一个进程组:
cd /sys/fs/cgroup
mkdir example
- 在example进程组中会自动生成各种配置文件
[root@docker example]# ls
结果:
cgroup.controllers cpu.weight.nice memory.low
cgroup.events hugetlb.1GB.current memory.max
cgroup.freeze hugetlb.1GB.events memory.min
cgroup.kill hugetlb.1GB.events.local memory.numa_stat
cgroup.max.depth hugetlb.1GB.max memory.oom.group
cgroup.max.descendants hugetlb.1GB.numa_stat memory.peak
:::info
要是没有想要的目录:
查看这两个文件中的内容:


:::
- 限制进程可以使用的CPU资源:
# 查看占用CPU资源过高的进程的进程号
ps -ef | grep busyloop
# 把进程号添加到cgroup.procs文件中
echo "进程号" >> cgroup.procs
# v2 版本限制cpu的文件使用 cpu.max, 这样会限制 155677 进程最多使用 1 核 CPU.
echo "100000 100000" > cpu.max
Docker限制容器CPU资源
运行一个容器,限制可以使用2个 cpu,使用 stress 占用4个 cpu:
# 启动容器,限制使用2核CPU
docker run -it --rm --cpus=2 registry.cn-beijing.aliyuncs.com/xxhf/stress /bin/bash
# 容器内启动进程,使用4核CPU
stress -c 4
观察容器CPU利用率:
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
2e7bdd1296cb nifty_banach 200.56% 788KiB / 15GiB 0.01% 656B / 0B 0B / 0B 6
容器 CPU 的负载为 200%,它的含义为单个 CPU 负载的两倍。我们也可以把它理解为有两颗 CPU 在 100% 的为它工作。
观察宿主机CPU利用率:
top - 22:45:42 up 27 days, 13:25, 3 users, load average: 2.66, 1.03, 0.81
Tasks: 160 total, 5 running, 155 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.3 us, 0.0 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 49.8 us, 0.0 sy, 0.0 ni, 50.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 50.5 us, 0.0 sy, 0.0 ni, 49.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu4 : 0.7 us, 0.3 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 49.5 us, 0.0 sy, 0.0 ni, 50.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu6 : 50.3 us, 0.0 sy, 0.0 ni, 49.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu7 : 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 15731672 total, 11204824 free, 511580 used, 4015268 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 14883056 avail Mem
四个 CPU 的负载都是 50%,加起来容器消耗的 CPU 总量就是两个 CPU 100% 的负载。限制成功。
Docker限制容器内存资源
docker run -it --rm -m 300M registry.cn-beijing.aliyuncs.com/xxhf/stress /bin/bash
# 使用docker status查看容器资源使用情况
docker status 容器ID
结果:
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
c8bb524c6f28 objective_knuth 100.17% 282.9MiB / 300MiB 94.30% 656B / 0B 0B / 0B 3
如果操作系统有swap 分区,容器会使用swap分区来保存内存文件,需要使用 ‘stress --vm 1 --vm-bytes 600M’ 才会触发限制。
或者加一个参数 --memory-swap=300M,表示 可以使用的内存和交换空间的总和:
docker run -it --rm -m 300M --memory-swap=300M registry.cn-beijing.aliyuncs.com/xxhf/stress /bin/bash
按照官方文档的理解,如果指定 -m 内存限制时不添加 --memory-swap 选项,则表示容器中程序可以使用 100M 内存和 200M swap 内存。默认情况下,--memory-swap 会被设置成 memory 的 2倍。
为容器保留 128M 内存空间,确保在资源有限的环境中,关键业务也可以正常运行:
docker run -it --memory-reservation 128m nginx:1.22.1
十一、Docker Compose
简介
Compose项目是 Docker 官方的开源项目,负责实现对 Docker 容器集群的快速编排。
Compose的定位是“定义和运行多个 Docker 容器的应用(Defining and running multi-container Docker applications) ”。
我们通过一个Dockerfile文件可以让用户很方便的定义一个单独的应用容器镜像。然而,在日常工作中,经常会碰到需要多个容器相互配合来完成某项任务的情况。例如要实现一个 Web 项目,除了 Web 服务容器本身,往往还需要再加上后端的数据库服务器,甚至还包括负载均衡容器等。
Compose恰好满足了这样的需求。它允许用户通过一个单独的docker-compose.yml或compose.yml模板文件(YAML格式)来定义一组相关联的应用容器为一个项目(project)。
Compose中有两个重要的概念:
- 服务(service):一个应用的容器,实际上可以包含若干个运行的镜像的容器实例。
- 项目(project):由一组关联的应用容器组成的一个完整的业务单元,在
docker-compose.yml文件中定义。
Compose的默认管理对象是项目,通过子命令对项目中的一组容器进行便捷的生命周期管理。
安装
目前 Docker 官方用 GO 语言重写了 Docker Compose,并将其作为了 docker cli 的子命令,称为 Compose V2。你可以参照官方文档安装,然后将 v1 版的 docker-compose 命令替换为 docker compose,即可使用 Docker Compose。
v2版本安装:
yum install docker-compose-plugin
Compose应用模型
一个项目由以下几部分组成:
- services:服务,写镜像配置;
- networks:网络,定义服务使用到的网络;
- volumes:卷,定义服务使用到的卷;
- configs:声明服务用到的明文配置文件;
- secrets:声明服务使用到的密文配置文件;
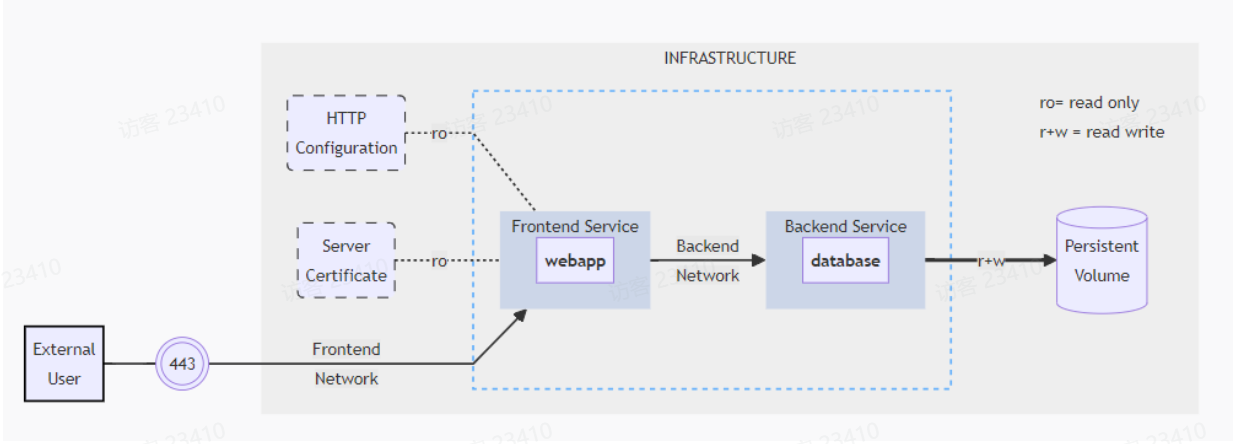
例:以下是一个项目的top图,根据图中提示写出compose文件:
分析:
该应用由以下几个部分组成:
- 2个service:webapp 和 database;
- 2个网络:Frontend Network 和 Backend Network;
- 1个密文配置文件:HTTPS证书,注入到前端容器;
- 1个明文配置文件:注入到前端容器;
- 1个Volume持久卷,注入到数据库的容器中;
- 端口映射关系为:
443:443,3306:3306
# 定义services,项目中有几个镜像,services中就写几项
services:
frontend: # 第一个服务的名称,自定义
image: webapp # 第一个服务使用的镜像名称
ports: # 第一个服务使用的端口,可以是多个端口,所以用数组
- "443:443" # 相当于 -p 443:443
- "8080:80"
networks: # 使用服务使用的网络
- frontend-net # 相当于 --network frontend-net
- backend-net
configs: # 使用明文配置文件
- httpd-config # 相当于 -v ./httpd-config.conf /httpd-config
secrets: # 使用密文配置文件
- server-certificate # 相当于 -v ././xxx.crt /run/certificate
backend: # 第二个服务的名称,自定义
image: database # 第二个服务使用的镜像名称
volmues: # 使用持久卷
- db-data: /data/database:ro # 相当于 -v db-data:/data/database:ro
networks: # 使用网络
- backend-net # 相当于 --network backend-net
volmues: # 定义卷
db-data: # 卷名,自定义
driver: local
driver_opts:
size: "10GiB"
configs: # 定义明文配置文件
httpd-config: # 自定义名
file: ./httpd-config.conf # 使用的文件
secrets: # 定义密文配置文件
server-certificate: # 自定义名
file: ./xxx.crt # 使用的文件
networks: # 定义网络
frontend-net: {} # 自定义名,使用默认
backend-net: {}
体验项目
现有一个python项目,依赖redis服务,我们使用 compose 的方式将服务运行起来。
- 步骤一:创建应用文件
创建目录 compose-python-demo ,进入目录 创建文件 app.py ,内容如下:
import time
import redis
from flask import Flask
app = Flask(__name__)
cache = redis.Redis(host='redis', port=6379)
def get_hit_count():
retries = 5
while True:
try:
return cache.incr('hits')
except redis.exceptions.ConnectionError as exc:
if retries == 0:
raise exc
retries -= 1
time.sleep(0.5)
@app.route('/')
def hello():
count = get_hit_count()
return 'Hello World! I have been seen {} times.\n'.format(count)
@app.route('/ping')
def ping():
return 'pong'
创建文件requirements.txt ,内容如下:
flask
redis
- 步骤二:创建 Dockerfile 文件
创建 Dockerfile 文件 ,内容如下:
FROM python:3.7-alpine
WORKDIR /code
ENV FLASK_APP=app.py
ENV FLASK_RUN_HOST=0.0.0.0
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
EXPOSE 5000
COPY . .
CMD ["flask", "run"]
- 步骤三:定义compose文件
定义 compose 服务:
services:
web:
build: .
ports:
- "8000:5000"
redis:
image: "redis:alpine"
- 构建和运行应用
[root@docker project-python-demo]# docker compose up
[+] Running 8/8
✔ redis 7 layers [⣿⣿⣿⣿⣿⣿⣿] 0B/0B Pulled 5.2s
✔ 96526aa774ef Already exists 0.0s
✔ b11f9c76abbd Pull complete 0.7s
✔ 6617b52cbeba Pull complete 0.7s
✔ d690774d7e1a Pull complete 0.8s
✔ 7c08c8068f7a Pull complete 1.3s
✔ 4f4fb700ef54 Pull complete 1.4s
✔ ea389a5fca7b Pull complete 1.5s
[+] Building 18.5s (17/17) FINISHED docker:default
=> [web internal] load build definition from Dockerfile 0.1s
测试结果:
curl http://127.0.0.1:8000
Docker compose 命令
- 启动项目:
docker compose -f compose文件名 up -d
- 查看服务日志:
docker compose logs
# 查看指定服务的日志
docker compose logs web
docker compose 命令在执行时 必须在 compose.yaml 文件所在的目录下:
docker compose -f compose.yml up -d 默认省略了参数 -f compose.yml;
理解 Compose 文件
Compose 文件是通过 YAML 文件定义的,由以下几个顶级元素组成:
- version(弃用)
- name(可选),如果不写的话,默认使用compose文件所在目录名作为name
- services(必须)
- networks
- volumes
- configs 明文配置
- secrets 密文配置
version 和 name 元素属性
version:
version 是为了向后兼容保留的,没有实际用途,也不会影响运行结果。
name:
定义项目名称,默认使用 compose.yml 文件所在的目录名。
例:
version: "3"
name: project-busy
services:
foo:
image: busybox
environment:
- COMPOSE_PROJECT_NAME
command: echo "I'm running ${COMPOSE_PROJECT_NAME}"
services 指令属性
services 是计算资源的抽象定义,由一组容器组成,services 中的所有容器都是根据这些参数创建的。
compose 文件中必须声明 services 元素。
例:
services:
web: # 服务名
image: nginx:1.22.1
redis: # 服务名
image: redis:alpine
- build
指定Dockerfile所在文件夹的路径(可以是绝对路径,或者相对于 compose.yml 文件的路径)。Compose将会利用它自动构建这个镜像,然后使用这个镜像。
可以使用context选项指定Dockerfile所在文件的路径。
使用dockerfile选项指定Dockerfile文件名。
使用target选项指定要构建的阶段,如在多阶段构建中。
services:
frontend:
#image: example/webapp
build: ./webapp # 构建上下文 Dockerfile
backend:
image: example/database
build:
context: backend # 构建上下文
dockerfile: ../backend.Dockerfile
target: builder # 多阶段构建
- command
覆盖容器启动后的命令。
version: "3"
name: project-busy
services:
busy:
image: busybox
command: echo "hello compose"
- restart
指定容器退出后的重启策略为始终重启。该命令对保持服务始终运行十分有效,在生产环境中推荐配置为always或者unless-stopped。
restart: always
- healthcheck
通过命令检查容器是否健康运行。
version: "3"
name: nginx-demo
services:
busyapp:
image: nginx:1.22.1
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost"]
interval: 30s
timeout: 5s
retries: 3
- environment
设置环境变量。可以使用数组和对象两种格式。
给定名称的对象会自动获取运行 compose 主机上对应变量的值,可以使用来防止泄露不必要的数据。
environment:
RACK_ENV: development
SHOW: 'true'
environment:
- RACK_ENV=development
- SHOW=true
如果变量名称或者值中用到 true|false,yes|no 等表达布尔含义的词汇,最好放到引号里,避免 YAML 自动解析某些内容为对应的布尔语义。
- expose
暴露端口,但不映射到宿主机,服务间相互访问。
仅可以指定内部的端口信息。
expose: # 声明应用监听 的端口
- "3000"
- "8000"
- depends_on
解决容器的依赖、启动先后的问题。以下例子会先启动redis、db,再启动web。
version: '3'
services:
web:
build: .
depends_on:
- db
- redis
redis:
image: redis
db:
image: postgres
- ports
映射端口到宿主机。
ports:
- "3000" # 3000表示容器里的端口,相当于 -P 映射容器中的3000到宿主机的随机端口
- "8080:80" # 相当于 docker run -p 8080:80
- "49100:80"
- "127.0.0.1:8001:8001"
:::danger
注意:
当使用 HOST:CONTAINER 格式来映射端口时,如果你使用的容器端口小于 60 并且没放到引号里,可能会得到错误结果,因为 YAML 会自动解析 xx:yy 这种数字格式为 60 进制。为避免出现这种问题,建议数字串都采用引号包括起来的字符串格式。
:::
long 语法支持配置 short 语法中不支持的附加字段,这些附加字段有:
- target:指定容器内的端口。
- published:指定公开的端口。
- protocol:指定端口协议(tcp或udp)。
- mode:使用`host`在每个节点公开一个主机端口。
ports:
- target: 80 # 目标 容器中监听 的端口 -p 8080:80
published: 8080 # 发布 宿主机
protocol: tcp
mode: host
- target: 8090 # 容器
published: 8090 # 宿主机
protocol: tcp
mode: host
version: "3"
name: project-demo
services:
nginx:
image: nginx:1.22.1
ports:
- target: 80
published: 8080
protocol: tcp
mode: host
- networks指令属性
配置容器连接的网络。
services:
frontend:
image: nginx:1.22.1
networks: # 一个容器可以配置多个网络,所以使用数组
- front-tier # 根据名字引用
- back-tier
networks: # 定义网络
front-tier: # 使用默认的参数
back-tier: # 空的属性 默认值 自动分配:网段,网关
- volumes
定义容器可访问的挂载主机路径或命名卷。
services:
front:
image: nginx:1.22.1
volumes:
- log-dir:/var/log/nginx # 挂载非宿主机的目录需要在volumes标签中定义
database:
image: mysql:5.7
environment:
MYSQL_ROOT_PASSWORD: 123456
volumes:
- /data/mysql:/var/lib/mysql/ # 挂载宿主机的目录不需要在volumes标签中定义
volumes: # 挂载之前需要定义volumes卷
log-dir:
可以使用 volumes 指定多种类型的挂载 比如:volume, bind, tmpfs。
services:
front:
image: nginx:1.22.1
volumes:
- type: volume
source: nginx-log
target: /var/log/nginx
database:
image: mysql:5.7
environment:
MYSQL_ROOT_PASSWORD: 123456
volumes:
- type: bind
source: /data/mysql
target: /var/lib/mysql
volumes:
nginx-log:
- configs 指令属性 明文配置文件
configs允许服务调整自己的配置,而无需重建 Docker 镜像。
与卷一样,配置作为文件挂载到服务容器的文件系统中。容器内挂载点的位置在Linux容器中的根目录下。
version: "3"
name: project-demo
services:
busyapp:
image: busybox
command: cat /my_config # 默认挂载目录
configs:
- my_config # 容器启动时 使用 my_config 配置文件
configs:
my_config:
file: ./my_config.conf # my_config 配置文件 位置
挂载时指定配置文件的挂载路径:
version: "3"
name: nginx-demo
services:
busyapp:
image: nginx:1.22.1
ports:
- "80:80"
configs:
- source: nginx_config
target: /etc/nginx/conf.d/default.conf
configs:
nginx_config:
file: ./default.conf
- secrets 指令属性 密文配置文件
存敏感数据,例如:证书、各种密码等。
version: "3"
name: project-demo
services:
busyapp:
image: busybox
command: cat /run/secrets/my_secret # 默认挂载目录
secrets:
- my_secret
secrets:
my_secret:
file: ./my_secret.info
docker compose 案例:部署Wordpress
services:
mysql:
image: mysql:8.0
volumes:
- db_data:/var/lib/mysql
restrat: always
environment:
- MYSQL_ROOT_PASSWORD=123456
- MYSQL_DATABASE=wordpress
- MYSQL_USER=wordpress
- MYSQL_PASSWORD=123456
expose:
- 3306
wordpress:
image: wordpress:php7.4
volumes:
- wp_data=/var/www/html
ports:
- "80:80"
restart: always
environment:
- WORDPRESS_DB_HOST=mysql:3306
- WORDPRESS_DB_USER=wordpress
- WORDPRESS_DB_PASSWORD=123456
- WORDPRESS_DB_NAME=wordpress
depends_on:
- mysql
volumes:
db_data:
wp_data:
十二、优雅退出
Linux信号
- kill参数
信号是一种进程间通信的方法,应用于异步事件的处理。信号的实质是一种软中断。
使用kill -l可以查看Linux系统中的所有信号,如下:
| 信号值 | 信号名 | 说明 |
|---|---|---|
| 1 | SIGHUP | 启动被终止的程序,可让该进程重新读取自己的配置文件,类似重新启动。 |
| 2 | SIGINT | 相当于用键盘输入 [ctrl]-c 来中断一个程序的进行。 |
| 9 | SIGKILL | 代表强制中断一个程序的进行,如果该程序进行到一半,那么尚未完成的部分可能会有“半产品”产生,类似 vim 会有 .filename.swp 保留下来。 |
| 15 | SIGTERM | 以正常的方式来终止该程序。由于是正常的终止,所以后续的动作会将他完成。不过,如果该程序已经发生问题,就是无法使用正常的方法终止时,输入这个 signal 也是没有用的。 |
| 19 | SIGSTOP | 相当于用键盘输入 [ctrl]-z 来暂停一个程序的进行。 |
- 什么是信号
信号是 Linux 内核与进程以及进程间通信的一种方式。针对每个信号进程都有个默认的动作,不过进程可以通过定义信号处理程序来覆盖默认的动作,除了 SIGSTOP 和 SIGKILL。二者都不能被捕获或重写,前者用来将进程暂停在当前状态,而后者则是从内核层面立即杀掉进程。
有两个比较重要的进程 SIGTERM 和 SIGKILL。SIGTERM 是优雅地关闭命令,SIGKILL 则是暴力的关闭命令。比如 Docker,容器会先收到 SIGTERM 信号,10s 后会收到 SIGKILL 信号。
容器中的信号
- 容器中的进程属于容器的1号进程
Docker 的 stop 和 kill 命令都是用来向容器发送信号的。注意,只有容器中的 1 号进程能够收到信号,这一点非常关键!stop 命令会首先发送 SIGTERM 信号,并等待应用优雅的结束。如果发现应用没有结束(用户可以指定等待的时间),就再发送一个 SIGKILL 信号强行结束程序。docker kill 命令默认发送的是 SIGKILL 信号,当然你可以通过 -s 选项指定任何信号。
- 容器中的进程不属于容器的 1 号进程
- 在脚本中捕获信号
- 使用tini作为容器启动入口
tini 是一套更简单的 init 系统,专门用来执行一个子程序(spawn a single child),并等待子程序结束,即便子程序已经变成僵尸程序也能捕捉到,同时也能转送 Signal 给子程序。如果你使用docker来跑容器,可以非常简便的在docker run的时候用 --init 参数,就会自动注入tini程式 (/sbin/docker-init) 到容器中,并且自动取代ENTRYPOINT设定,让原本的程式直接跑在 tini程序底下。
注意:Docker 1.13 以后的版本开始支持 --init 参数,并內建 tini 在內。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)