从1.4081到0.0010:一次迷你Transformer训练的环境搭建与观察
0. 这篇东西是干什么的
亲手跑一次Transformer训练,看损失值从1.4掉到0.001,亲眼确认那些概念是怎么在代码里工作的。
操作手册:照着做,先把环境跑通
如果你只想把代码跑起来,看一次完整的训练过程,直接按下面步骤来。如果中间遇到报错,跳到对应的小节查原因。
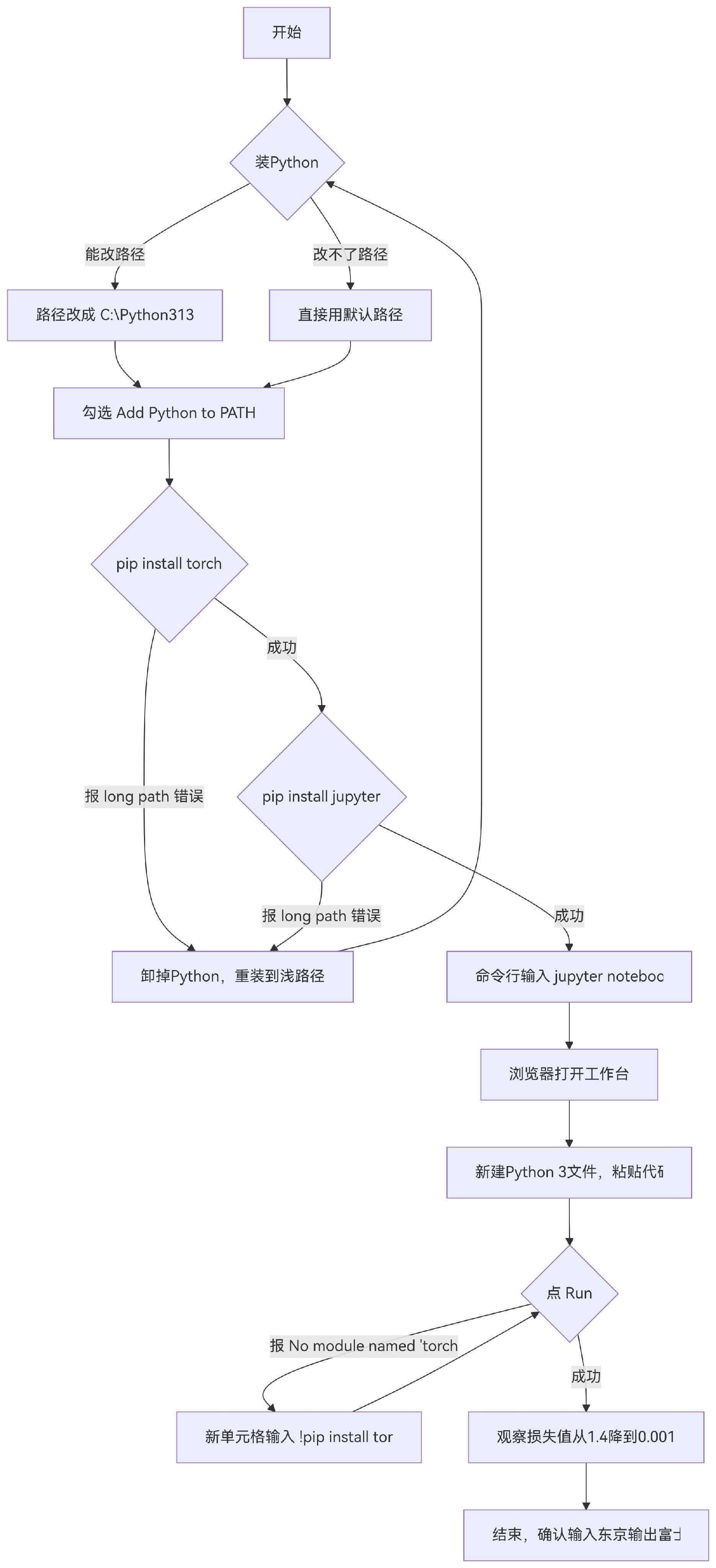
第一步:装Python
去 python.org,下载最新稳定版(比如Python 3.13)。你下载下来的应该是一个 .exe 安装包,根据你的系统选64-bit还是32-bit。安装时一定勾选 Add Python to PATH。
踩坑提示:安装界面上那个自定义路径的输入框,在某些版本的安装程序里可能是灰色的,点不了。如果你遇到了这种情况,直接用默认路径就行。新版Python的默认路径比微软商店版浅很多,一般不会再出问题。
第二步:装PyTorch
在黑框框里输入 pip install torch。如果报 long path 错误,见“踩坑1”。
第三步:装Jupyter Notebook
在黑框框里输入 pip install jupyter。如果报错,原因见“踩坑1”。装好后输入 jupyter notebook,浏览器会自动打开工作台(也有让你手动选的,反正选顺手的就行)。
第四步:跑代码
在Jupyter里新建一个Python 3文件,把第4部分的代码完整复制进去,点 Run。
常见报错速查:
· long path 问题:Windows对文件路径长度有限制。你的Python装在太深的位置,Jupyter依赖又远比PyTorch多,文件路径叠在一起就超限了。解决办法:卸掉现有Python,重装到浅路径(比如 C:\Python313),然后从第一步重新开始。如果你发现安装时改不了路径,参照第一步的踩坑提示。
· 下载下来的是源码包不是exe:网页上往下滑,找到 Windows installer (64-bit),那个才是安装包。
· ModuleNotFoundError: No module named 'torch':说明PyTorch没装。新开一个Jupyter单元格,输入 !pip install torch,跑完再重新运行主代码。
1. 为什么要搭这个环境
去年冬天在面包板上插第一个LED的时候,我连电阻为什么要接在正极和负极之间都不清楚。后来为了调试舵机,在VS Code里对着命令行敲了无数遍上传指令,才慢慢摸清一个道理:任何东西,不管它原理听起来多复杂,只要你能亲手把它跑通一遍,它就不再是黑箱。
这次想干的事很简单:亲手搭一个能训练的Transformer。不调别人的API,不用完整的GPT,就自己写一个模型,喂一点玩具数据,看它从乱猜到学会规律。
2. 环境是怎么搭起来的
2.1 Python
Python在这套流程里的角色,更像一个容器。它本身不做深度学习,但提供了一个大家都在用的标准环境。你在命令提示符里敲 python 能进去,就说明这个容器已经装好了。
装Python本身没什么复杂的。去官网,下载,安装时勾选 Add Python to PATH。我最早用的是微软商店版,路径长到自己都不认识,后面装Jupyter的时候被这个坑得不轻。这次重装时选了最新稳定版3.13,安装界面上那个自定义路径的输入框是灰色的、点不了,所以直接用了默认路径。好在默认路径本身不深,后面装各种包都没有再出问题。如果你也遇到了没法改路径的情况,不用纠结,直接默认就行。
2.2 PyTorch
PyTorch是用来搭建神经网络的核心框架。你不需要自己写反向传播的数学公式,它帮你自动算梯度、更新权重。我们在代码里写的 nn.Linear、nn.Embedding、CrossEntropyLoss,全都来自PyTorch。
装它的时候,我在命令提示符里敲 pip install torch,结果报了一个错误,后面跟着一串长得离谱的路径。
这就是Windows的路径长度限制导致的。Windows对文件路径的最大长度有一个默认的上限,大约在两百多个字符左右。我用的Python装在微软商店的默认路径里,本身就又深又长。PyTorch的依赖相对来说还不多,我用 pip install torch --target=C:\torch_env 绕开了。当时以为问题已经解决,没往深处想。
2.3 Jupyter Notebook
Jupyter是一个在浏览器里写Python的工具。你可以一段一段地运行代码,立刻看到输出。对我们这次实验来说,它最大的好处是:训练的过程中,每一轮的损失值都会一行行打印出来,你能亲眼看着数字往下掉。
但装Jupyter的时候,同样的路径长度问题又出现了。这次用同样的方法绕开,不管用了。
原因很简单:Jupyter和PyTorch虽然都是通过 pip 安装的,但复杂程度差了好几个数量级。PyTorch只需要带几个核心数学库,而Jupyter是一个完整的网络应用,它需要在浏览器里运行一个交互界面,为此拉家带口地拖了几十个依赖包。每个包都有自己又深又长的文件路径,叠在一起,轻轻松松超过了系统对路径长度的默认限制。
走到这一步才知道,绕开不是办法。问题的根源不是安装命令的问题,而是Python本身的路径太深。我卸掉了微软商店版,重新从官网下了最新版。安装时发现改不了路径,就直接用了默认路径。重装后一切顺利。
3. 代码里每个部分在干什么
下面把代码拆成几块,分别说明。每个概念尽量用一句话讲清楚它是什么、为什么放在这里。
3.1 手写自注意力机制
```python
class MySelfAttention(nn.Module):
def __init__(self, d_model):
super().__init__()
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.d_model = d_model
def forward(self, x):
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_model)
attention_weights = torch.softmax(scores, dim=-1)
return torch.matmul(attention_weights, V)
```
nn.Linear:也叫全连接层或线性层。它的作用是做一个最简单的数学变换:输入一组数字,乘上一组权重,再加上一组偏置,输出另一组数字。公式就一句话,y = Wx + b。这里 W_q, W_k, W_v 三个线性层,分别把输入映射成查询向量Q、键向量K和值向量V。训练过程中,这三个线性层的权重会不断更新。
Q、K、V:Transformer的核心概念。简单理解:Q是“我在找什么”,K是“我是什么”,V是“我包含什么信息”。Q和K做点积,算出“当前位置和其他位置的相关程度”,然后把这个权重乘到V上。
scores 计算:Q和K做矩阵乘法,再除以 math.sqrt(self.d_model)。除以这项是为了缩放,防止向量维度太大导致内积值过大,这样后面Softmax的梯度不会消失得太快。
softmax:把一堆任意数字,变成一堆0到1之间的数,且加起来等于1。在这里的作用是把“相关分数”变成“注意力权重”,让模型知道每个词应该花多少注意力去看其他词。
torch.matmul(attention_weights, V):加权求和。把每个词的值向量按注意力权重加起来,得到当前位置的最终输出。
3.2 模型结构
```python
class MyTransformerBlock(nn.Module):
def __init__(self, vocab_size, d_model):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.attention = MySelfAttention(d_model)
self.fc_out = nn.Linear(d_model, vocab_size)
def forward(self, x):
x_emb = self.embedding(x)
attn_out = self.attention(x_emb)
return self.fc_out(attn_out)
```
nn.Embedding:词嵌入层。它的作用是给每个词一个独一无二的向量表示。训练过程中,意思相近的词,它们的向量会被慢慢拉近。这和独热编码不同:独热编码只是给每个词一个编号,但编号之间没有任何关系;词嵌入让模型知道“北京”和“东京”虽然字不同,但都是首都,向量应该靠得近一些。
MySelfAttention:上面手写的自注意力层。在词嵌入的基础上,计算每个词和整句话里其他词的关系。
nn.Linear(d_model, vocab_size):输出层。把自注意力的输出映射回词表大小,相当于模型在预测:下一个词是词表里的哪一个。
3.3 训练过程
```python
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
```
损失函数:衡量模型预测和真实答案之间的差距。损失值越大说明错得越离谱,训练的目标就是把这个值尽量压低。
优化器:训练过程中负责更新权重的算法。Adam 是目前最主流的一种,会根据之前的梯度大小动态调整步子。lr 是学习率,控制每次更新迈多大步。
```python
for epoch in range(100):
...
output = model(src)
loss = criterion(output[:, -1, :], tgt[:, -1])
loss.backward()
optimizer.step()
```
loss.backward():反向传播。自动计算损失值相对于模型里每个参数的梯度。你不用自己算导数,PyTorch帮你全搞定了。
optimizer.step():更新权重。根据刚才算出来的梯度,把所有权重朝着让损失更小的方向挪一点点。
这两步合在一起,就是“训练”这个词在代码层面上的全部含义:算梯度,然后更新权重。每一轮训练,模型都会比上一轮更准一点点。
4. 训练结果与观察
这是在我电脑上跑出来的真实数据。词表里有23个汉字,输入是地名(比如“东京”),期望输出是名胜(“富士山”)。
```
第 10 轮 --- 总损失: 1.4081
第 20 轮 --- 总损失: 0.0121
第 30 轮 --- 总损失: 0.0064
第 40 轮 --- 总损失: 0.0042
第 50 轮 --- 总损失: 0.0031
第 60 轮 --- 总损失: 0.0023
第 70 轮 --- 总损失: 0.0018
第 80 轮 --- 总损失: 0.0015
第 90 轮 --- 总损失: 0.0012
第100 轮 --- 总损失: 0.0010
```
损失值从1.4081一路掉到0.0010。前10轮是“顿悟期”,模型从完全乱猜迅速摸到了规律。之后几十轮是“微调期”,损失一直在0.01以下,缓慢地往更精确的方向磨。
最终测试的时候,输入“东京”输出了“山”,输入“纽约”输出了“神”。虽然只是预测了正确答案的第一个字,但也说明模型确实学会了地名和名胜之间的对应关系——它知道往哪个方向去猜,只是我们的模型太小了,23个汉字的词表,一个极简的Transformer,能学到这个程度已经说明差不多了。
5. 和想象中不一样的地方
在跑这个实验之前,我以为能看到权重矩阵在屏幕上闪烁、梯度在层与层之间像水流一样传递、神经元一个个被点亮又熄灭。
实际上,我看到的是:一个黑框框,二十几行打印出来的损失值。CPU太快了,数据太小了,整个过程很快就结束了。
后来想想。那些酷炫的神经网络动画、那些像大脑一样放电的可视化图表,全都是事后用专门的工具画出来的,不是训练过程中实时呈现的。真正在训练的时候,你看到的就是一个数字往下掉。
这个落差本身,也是一种理解。所谓“机器学习”,在物理层面上,就是一堆矩阵乘法加上一个不断变小的数字。
6. 一些零碎的想法
这门课最有价值的,不是那些需要背诵的名词解释。期末考完,你可能不会再需要手写反向传播的公式。但如果有一天,你亲手搭过一个模型,喂过一批数据,看过损失值在你的电脑上从1.4掉到0.001,你就会比那些只会背定义的人多知道一件很重要的事:所谓“学习”,不是玄学,是一个可以观察、可以测量、可以复现的过程。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)