从 PDF 提取到论文对比:做科研工具时最容易忽视的 5 个问题

最近我在做一个论文对比分析工具,目标其实很朴素:把多篇论文中的标题、摘要、数据集、模型、评价指标、实验结果等关键信息提取出来,再统一整理成可以横向比较的结构化表格。 一开始我以为这件事的核心是大模型总结能力,后来才发现,真正决定工具上限的,往往不是模型,而是前面的 PDF 文本提取质量。
因为只要 PDF 提取得不对,后面的一切都会跟着偏。章节顺序一乱,模型方法和实验结果就可能被拼在一起;表格抽不出来,最关键的性能指标就会缺失;参考文献识别不准,后续做引文网络或相关工作分析也会受影响。 也就是说,论文对比分析工具表面上是在“做信息抽取”,本质上却是在和 PDF 这种顽固的文档格式做长期斗争。
我这篇文章不打算只讲“怎么调一个库”,而是想把自己做这个工具时最真实的 5 个坑讲清楚:为什么我最开始的方案跑不通,后来为什么要从“纯文本提取”转向“结构化提取 + 字段标准化”,以及一个真正可用的论文对比分析工具,底层到底应该长什么样。
我想做的,不是“读 PDF”,而是“比较论文”
先说清楚这个工具的目标。它不是简单把 PDF 转成 txt,也不是只做一个问答式的文献助手;我真正想解决的问题,是把一批同领域论文自动整理成统一视图,让我能快速比较它们的数据集、方法、骨干网络、指标、实验设置和最终结果。
换句话说,我要的不是“论文全文”,而是“可比较的论文结构”。这个需求在科研里很常见。比如你想调研一个方向,往往会下载几十篇 PDF,然后手动建一个表格,列出每篇论文用了什么数据集、用了什么 backbone、主指标是多少、有没有消融实验、有没有可视化分析。 真正耗时间的,通常不是读论文,而是把这些内容从不同风格、不同排版、不同章节命名的 PDF 中整理成统一格式。
所以我后面逐渐意识到,论文对比分析工具至少要有四层能力。第一层是 PDF 文本提取,先把内容拿出来;第二层是结构识别,知道哪些是标题、摘要、正文、图注、表注、参考文献;第三层是字段标准化,把 “Experiments”“Evaluation”“Results and Discussion” 这类不同标题统一映射到同一种语义字段;第四层才是对比分析和可视化展示。

最开始,我天真地以为“能提文本就够了”
我一开始用的是最直接的思路:先用 Python PDF 库把文本读出来,然后基于关键词去匹配标题、摘要、实验设置和结果字段。这个方案上手快,代码也短,看起来非常适合先做一个 MVP。 例如 PyMuPDF 本身就是一个高性能的 Python 文档处理库,支持直接遍历页面并调用 page.get_text() 获取文本。
import fitz # PyMuPDF
def extract_text_from_pdf(pdf_path):
doc = fitz.open(pdf_path)
pages = []
for page_id, page in enumerate(doc):
text = page.get_text("text")
pages.append({
"page": page_id + 1,
"text": text
})
return pages 这段代码本身没有问题,甚至在很多“文本型 PDF”上表现还不错。PyMuPDF 不仅能提取纯文本,还支持 text、blocks、words、dict、json 等不同模式,适合做从简单读取到布局感知的多层次处理。 但问题在于,学术论文不是普通文档,它们有双栏布局、页眉页脚、图表穿插、脚注、公式、参考文献区和复杂的章节结构,单靠“按页取文本”很容易把内容顺序弄乱。
这也是我踩的第一个坑。
坑一:以为“提取出文本”就等于“拿到了论文内容”
这是我最早、也最典型的误判。很多人第一次做 PDF 处理时,都会默认“提取出的字符串”就是论文原文,但实际上,字符串只是最低层的载体,离“可理解内容”还有很远。
学术 PDF 最大的问题之一是阅读顺序。特别是双栏论文里,左栏和右栏的内容、页眉、页脚、图注、表注可能会被直接拼接在一起,最后得到一份看似完整、实际逻辑混乱的文本。 你可能本来想抽“Method”部分,结果里面混进了页脚页码、下一页的图注,甚至参考文献区的内容。等这些脏数据进入后续抽取环节后,错误就不是局部的,而是会沿着整条流程链一路放大。
后来我才意识到,PDF 提取至少要区分几个层次:纯文本提取、块级提取、坐标级提取和结构级提取。像 PyMuPDF 这样的库更适合做页面级文本块读取和坐标分析,而不是直接替代学术结构解析器。 如果目标只是“看一下 PDF 文本”,那 get_text("text") 足够;但如果目标是“做论文对比工具”,那你就必须关心段落边界、标题层级、正文区域和非正文区域的分离。

坑二:以为一个工具能从头包到尾
第二个坑,是我曾经很想偷懒地用“一个工具解决所有问题”。后来事实证明,这个想法几乎一定会失败。
不同工具擅长的事情完全不同。GROBID 是专门面向学术文档的信息提取系统,能够处理标题、摘要、作者、机构、关键词、DOI、参考文献,以及更细粒度的全文结构,比如章节标题、段落、脚注、图注和表格相关内容。 官方文档提到,在完整 PDF 处理中,GROBID 管理超过 55 个最终标签,用来构建相当细粒度的学术文档结构;它在参考文献解析上也给出了较高的 F1 指标表现。
而 CERMINE 也是面向科学文献的结构化抽取系统,重点在元数据和参考文献解析,同时支持从 born-digital scientific articles 中提取标题、作者、关键词、摘要等关键元数据,并强调这些信息对于文献组织、搜索、相似文档发现和引文网络构建非常重要。 从设计上看,CERMINE 采用模块化工作流,便于替换和扩展不同组件,这一点对科研工具开发其实很有价值。
相比之下,PyMuPDF 这样的通用库更像底层工具箱。它速度快、接口直接、适合做文本、图像、元数据和布局相关的底层读取,但它并不天然懂“学术论文语义”。 所以后来我的思路变成了:底层用通用 PDF 库做预处理和补救,结构层优先交给 GROBID 或 CERMINE,最后再自己做字段标准化和对比层逻辑。
| 工具 | 主要优势 | 主要短板 | 适合任务 |
|---|---|---|---|
| PyMuPDF | 高性能读取 PDF,支持多种文本提取模式与布局信息访问。 | 不直接提供学术论文级别的结构语义。 | 页面级文本提取、预处理、坐标分析。 |
| GROBID | 支持标题、摘要、作者、参考文献及全文结构化解析,标签粒度细。 | 部署、调用和后处理复杂度更高。 | 学术论文结构化抽取。 |
| CERMINE | 面向科学文献的元数据与参考文献抽取,工作流模块化。 | 生态热度和现代集成体验相对一般。 | 科学论文元数据与结构内容提取。 |
坑三:以为抽到了章节标题,就能直接横向对比
第三个坑更隐蔽,也更接近真正的科研需求。哪怕你已经成功识别出论文的章节结构,事情也还远远没结束,因为不同论文的章节命名根本不统一。
例如有的论文写 “Methods”,有的写 “Methodology”,有的写 “Approach”,有的干脆把方法写成模型名;实验部分也一样,有的是 “Experiments”,有的是 “Evaluation”,有的是 “Results and Discussion”。如果你不做字段标准化,后面的比较表就会非常难看:相同语义的内容会被拆成多个列,不同语义的内容又可能被错误合并。
后来我给系统加了一层标准化映射。说白了,就是先定义一套“规范字段”,再把不同论文里的原始章节标题映射到这些规范字段上。最简单的代码大概像这样:
SECTION_MAP = {
"abstract": ["abstract", "summary"],
"introduction": ["introduction", "background"],
"method": ["method", "methods", "approach", "methodology"],
"experiment": ["experiment", "experiments", "evaluation", "results"],
"conclusion": ["conclusion", "discussion", "conclusions"]
}
def normalize_section(title):
title = title.strip().lower()
for canonical, variants in SECTION_MAP.items():
if title in variants:
return canonical
return "other"坑四:以为表格和公式只是“附属信息”
我最初做系统时,重点一直放在摘要、引言、方法、实验小节这些“正文文本”上,后来才意识到,论文对比分析里最重要的信息,往往恰恰不是大段正文,而是表格、图注和公式附近的短文本。
你想做论文对比,最核心的问题通常是这些:用了什么数据集、评价指标是多少、和谁做了对比、提升了几点、有没有消融实验。很多信息在正文里只是一句带过,真正完整、准确的版本往往在表格里。 如果你只能抽正文,抽不到表格,工具最后就会陷入一种很尴尬的状态:看起来很聪明,实际上关键结论抓不出来。
这也是为什么通用文本提取方案在科研分析里经常“看着能用,实际不够用”。通用库能很好地把文本读出来,但对复杂表格、跨页表、公式邻接语义和图表说明的处理,往往还需要更强的结构识别能力或者额外的后处理策略。 如果博客里你愿意再加一段经验总结,可以直接写:论文信息抽取不是一个 NLP-only 问题,它同时也是一个文档版面理解问题。
坑五:以为大模型能替我兜底
第五个坑,是很多做智能工具的人都会踩的:觉得前面的 PDF 提取哪怕不够准,后面交给大模型总结一下,也许就能“自动纠正”。可惜现实通常不是这样。
大模型当然很强,但它的前提是输入本身还保留着足够清晰的结构。如果你前面已经把章节拼乱了、字段边界打碎了、表格丢掉了、公式附近的解释断开了,那么模型再强,也只能在错误上下文里继续生成一个“看起来合理”的结果。 它不一定是完全胡说,但很可能是“局部正确、整体失真”,而这在科研场景里是很危险的。
所以我后来越来越认同一个观点:论文分析工具的上限,不在最后一步摘要模型,而在前面的结构化输入质量。 你可以把大模型放在系统的后端,做字段补全、术语归一化、结果摘要和自然语言解释,但不能让它代替前面所有脏活累活。
这其实也改变了我对整个系统架构的理解。以前我把它看成 “PDF → 大模型 → 输出”;后来我才意识到,更合理的架构应该是 “PDF → 结构化解析 → 标准化 → 可比较表示 → 模型增强总结”。
后来,我把整个工具链改成了这样
经历完上面五个坑后,我现在更倾向于把论文对比分析工具拆成四层。
第一层是 PDF 读取层,负责基础文本、页面块、坐标、图像或元数据读取,这一层可以用 PyMuPDF 一类库来做。 第二层是结构化解析层,把学术论文中的标题、摘要、作者、章节、参考文献等信息抽出来,这一层更适合交给 GROBID 或 CERMINE 这类面向 scholarly documents 的工具。
第三层是语义标准化层,这是我觉得最容易被低估、但对最终可用性影响最大的部分。它负责把不同论文里的章节名、指标名、实验字段和数据集名称对齐成统一 schema。 第四层才是展示与分析层,包括论文对比表、筛选、排序、标签检索,甚至进一步调用模型生成“这一领域主流方法对比结论”。
import pandas as pd
papers = [
{
"title": "Paper A",
"dataset": "COCO",
"backbone": "ResNet50",
"metric": "mAP",
"main_result": "42.1"
},
{
"title": "Paper B",
"dataset": "LTM-Tomato",
"backbone": "Custom CNN",
"metric": "F1",
"main_result": "0.966"
}
]
df = pd.DataFrame(papers)这篇博客最值得读者带走的东西
如果让我现在回头总结,做论文对比分析工具时,我最大的认知变化就是:不要把“PDF 文本提取”理解成一个简单的数据读取步骤,它其实决定了整个系统后面的信息质量、字段稳定性和可比较性。 尤其在学术论文场景下,PDF 不是普通文档,结构、布局、表格、参考文献和章节命名差异都会直接影响最终效果。
所以如果你也想做类似工具,我的建议会非常明确。不要一上来就把所有希望压在大模型上;先把 PDF 结构解析这件事做好,再谈自动比较和智能总结。 不要迷信“一个库包打天下”;通用 PDF 库、学术结构解析器和你自己的标准化逻辑,通常都不可缺少。 也不要只盯着正文;真正决定科研比较价值的,往往是表格、图注、指标字段和实验设置这些“结构化密度更高”的区域。
对我来说,这个项目最有意思的地方就在这里:它表面上是在做一个文献工具,实际上却把文档解析、信息抽取、结构化建模和科研工作流连接在了一起。 而当我真正踩完这些坑之后,我反而越来越觉得,论文对比分析工具最难的部分,从来不是“最后那句总结”,而是前面那些看起来不够炫、但决定系统是否真正可靠的基础工作。
最终也给大家展示一下我的提取内容的分类以及结果:

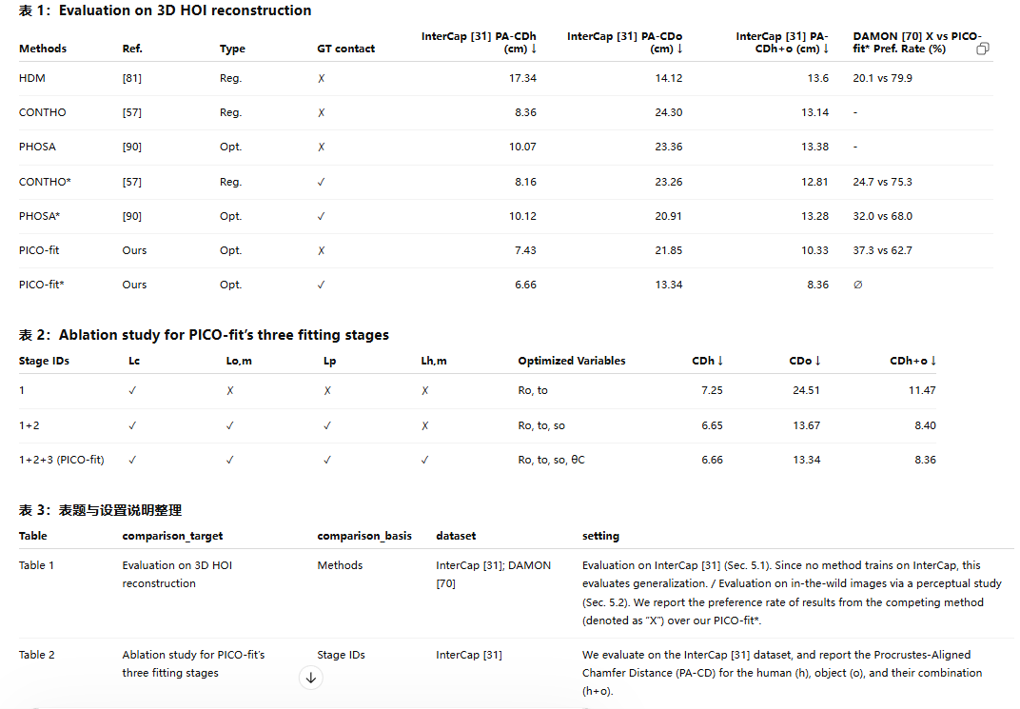
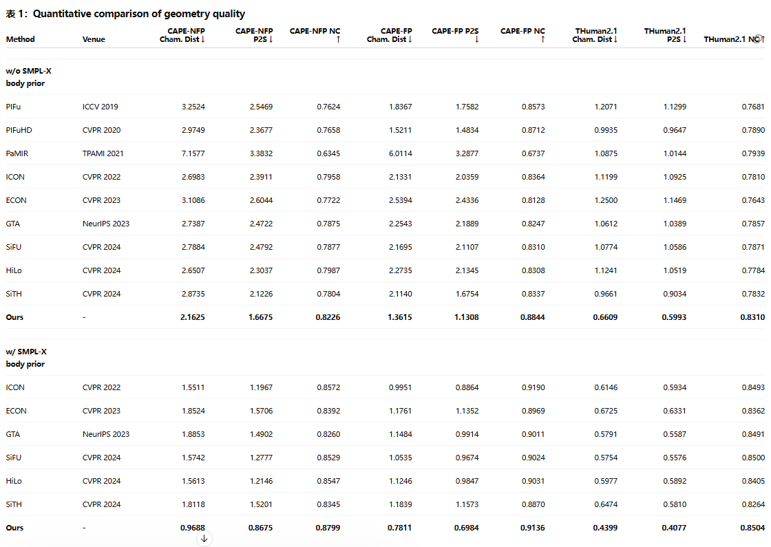
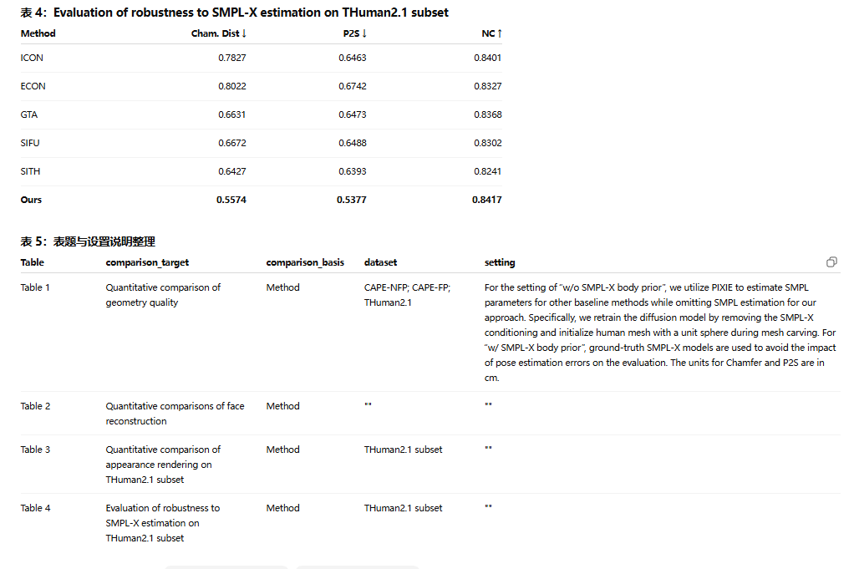

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)