协变量泄露预防:训练测试阶段的时间切分策略与验证方法
·
🤍 前端开发工程师、技术日更博主、已过CET6
🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1
🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》
🍚 蓝桥云课签约作者、上架课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入门到实战全面掌握 uni-app》
文章目录
协变量泄露预防:时序预测最关键保命知识点
这是90%新手做销量预测翻车的核心原因:
未来信息偷偷流进训练集 → 本地效果极好 → 上线一塌糊涂
一、先搞懂:什么是「协变量泄露」?
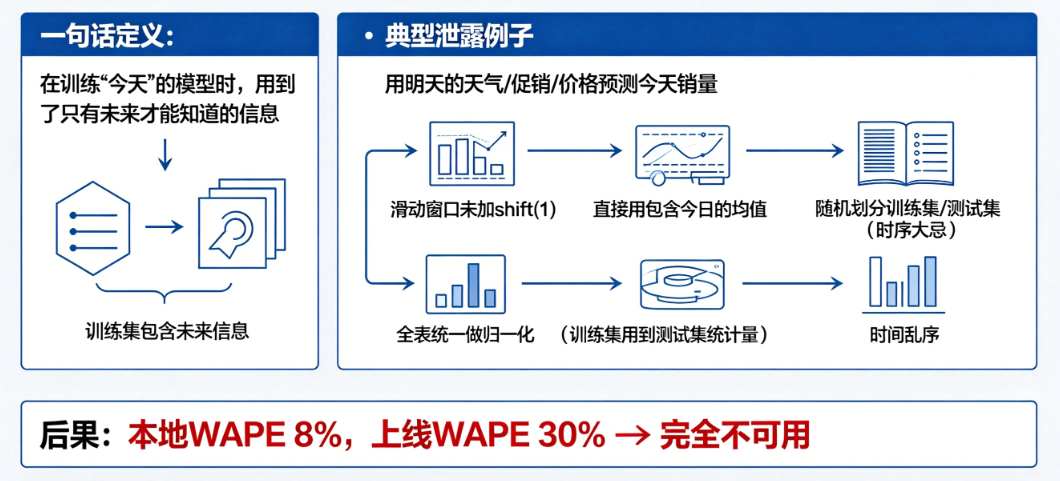
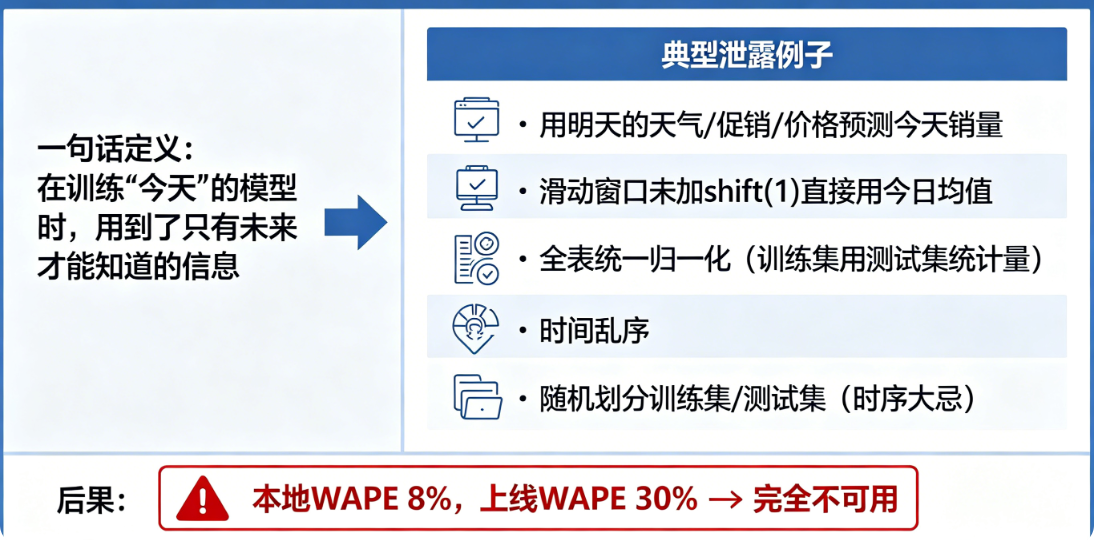
一句话定义
在训练“今天”的模型时,用到了只有未来才能知道的信息。
典型泄露例子(你肯定踩过坑)
- 用明天的天气/促销/价格预测今天销量
- 滑动窗口没加
shift(1),直接用包含今日的均值 - 全表统一做归一化(训练集用到了测试集统计量)
- 时间乱序,随机划分训练集/测试集(时序大忌)
后果
本地 WAPE 8%,上线 WAPE 30% → 完全不可用
二、根治泄露的核心:严格时间切分策略(3种标准策略)
时序数据绝对不能随机切分!
必须按时间先后顺序切割。
策略1:简单时间切分(最常用、最稳)
规则
- 训练集:所有早于 cutoff 日期的数据
- 测试集:所有晚于等于 cutoff 日期的数据
- 两者无任何时间重叠
- 特征、标签、协变量全部按时间切割
示例
训练集:2024-01-01 ~ 2024-11-30
测试集:2024-12-01 ~ 2024-12-31
优点
- 最简单
- 最贴近真实上线环境
- 完全杜绝泄露
策略2:滚动时间窗切分(Rolling Window,最严谨)
适合需要多组验证、保证模型稳定性的场景。
规则
- 固定训练窗口
- 滚动预测一小段测试窗口
- 逐步后移
- 永远只用历史预测未来
示例
窗口1:
训练:1-6月
测试:7月
窗口2:
训练:2-7月
测试:8月
窗口3:
训练:3-8月
测试:9月
优点
- 结果更可靠
- 适合竞赛、企业级上线验证
策略3:滞后排除切分(防止滞后特征泄露)
规则
如果你用了 lag_7、lag_14 特征:
- 训练集和测试集之间必须空出滞后最大天数
- 例如用了 lag_14 → 必须空出 14天 不参与任何训练/测试
示例
训练集:~ 11月15日
空窗期:11月16日 ~ 11月30日(14天)
测试集:12月1日 ~
为什么必须空窗?
不空窗 → 测试集样本直接用到了自己的历史信息 → 隐形泄露!
三、协变量泄露的4条黄金预防规则
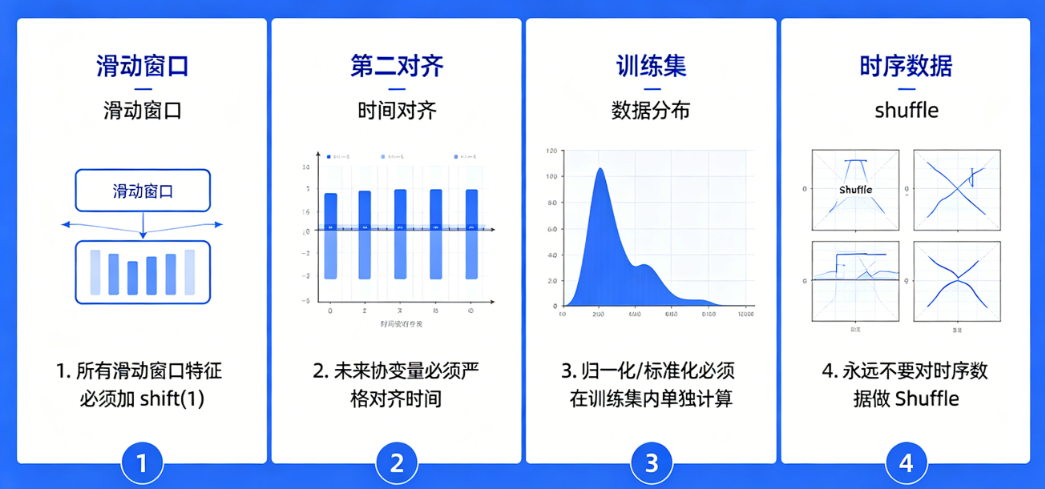
1. 所有滑动窗口特征必须加 shift(1)
# 正确(只用过去7天)
df['roll_mean_7'] = g.shift(1).rolling(7).mean()
# 错误(包含今天,泄露!)
df['roll_mean_7'] = g.rolling(7).mean()
2. 未来协变量必须严格对齐时间
- 天气必须是当日天气
- 促销必须是当日促销
- 绝不允许:用未来的天气/促销填充历史
3. 归一化/标准化必须在训练集内单独计算
# 正确
mean = train['price'].mean()
train['price_norm'] = train['price'] - mean
test['price_norm'] = test['price'] - mean
# 错误(全表均值,包含测试集)
df['price_norm'] = df['price'] - df['price'].mean()
4. 永远不要对时序数据做 Shuffle
训练、测试、验证集必须保持时间升序
四、最简单有效的「泄露验证方法」(3个必做)
你可以用这 3 个方法1分钟自查是否泄露。
方法1:特征相关性校验(最简单)
操作
查看测试集未来协变量与标签的相关性:
- 如果相关性异常高 → 大概率泄露
- 例如:测试集“明天销量”和今天标签相关系数 0.9 → 严重泄露
方法2:特征值范围校验
操作
- 训练集、测试集分别统计最大值、最小值
- 如果测试集特征范围完全包含在训练集里
- 且没有出现训练集不存在的未来日期 → 安全
方法3:空集测试(最准、最狠)
操作
- 把测试集标签全部置为0或随机数
- 用训练好的模型预测
- 如果预测结果仍然很准 → 100% 泄露
原理
标签都废了,模型还能准 → 只能是偷看到了未来信息。
五、AutoGluon 时序训练最佳实践(直接照抄)
1. 时间切分
cutoff = "2024-12-01"
train = df[df["date"] < cutoff]
test = df[df["date"] >= cutoff]
2. 特征构造(全程无泄露)
g = train.groupby("sku")["sales"]
train["lag_1"] = g.shift(1)
train["roll_mean_7"] = g.shift(1).rolling(7).mean()
3. 测试集特征必须复用训练集统计量
test["roll_mean_7"] = test.groupby("sku")["sales"].shift(1).rolling(7).mean()
4. 训练时禁止乱序
predictor.fit(train, time_limit=600, random_state=42)
六、极简总结(保命口诀)
- 时序不随机切分,只按时间切分
- 滑动窗口必加 shift(1)
- 未来协变量只取当日,不取未来
- 归一化只在训练集算
- 用空集测试验证是否泄露
做到这 5 条,协变量泄露永远与你无关。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)