多模态文搜图图搜图:视觉语义检索的边界
LlamaIndex多模态文搜图图搜图RAG实践:突破视觉语义检索的边界
📖 概述
本文深入探讨了如何利用LlamaIndex框架实现跨模态的视觉语义检索。从传统的"文档内检索"到"跨模态检索",这是RAG技术在企业应用中的重大突破。
🎯 核心问题与挑战
1.1 从文档内检索到跨模态检索
在上一节《图文混排PDF检索》中,我们解决了PDF内部的多模态问题,但这只是"文档内检索"场景。今天我们要面对的是更具挑战性的跨模态检索:
| 维度 | 文档内检索 | 跨模态检索 |
|---|---|---|
| 关联方式 | 物理相邻(同一页/同一段) | 语义相似(无物理关联) |
| 模态关系 | 图文同源,有上下文 | 图文异源,无上下文 |
| 核心难点 | 解析提取 | 向量空间对齐 |
| 典型场景 | “这张图表展示了什么?” | “找一张展示销售趋势的图” |
| 技术方案 | LlamaParse、MinerU | CLIP、Qwen3-VL |
1.2 传统解决方案的局限性
企业通常尝试的三种传统方案都存在致命缺陷:
| 方案 | 工作原理 | 核心问题 |
|---|---|---|
| 文件名搜索 | 基于文件名关键词匹配 | 文件名通常无语义(如 IMG_20240315.jpg) |
| OCR 提取文字 | 识别图中文字建立索引 | 丢失视觉信息(趋势、布局、颜色) |
| 人工打标签 | 人工为每张图片添加描述 | 成本高、不可持续、覆盖率低 |
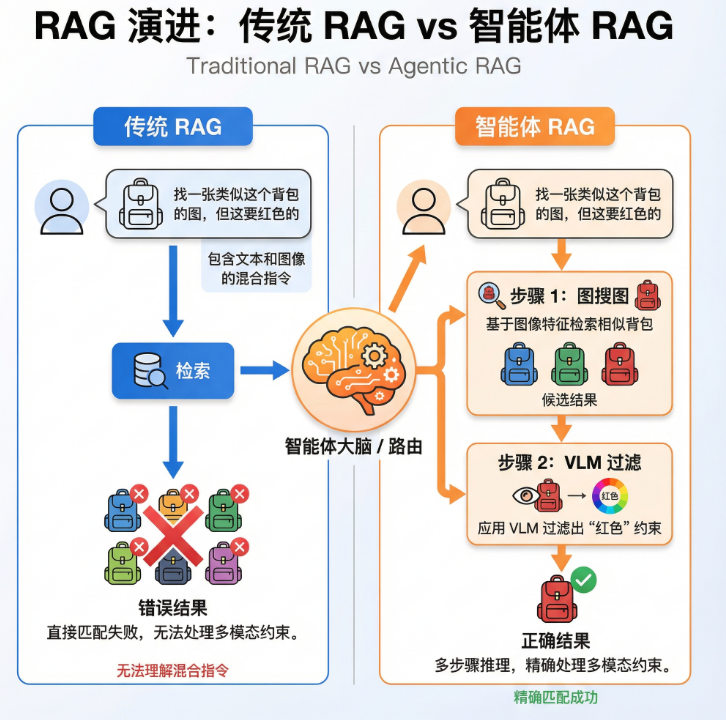
关键洞察:传统方案试图将视觉信息"翻译"为文本,但翻译过程中必然丢失信息。
1.3 多模态RAG的核心思想:统一向量空间
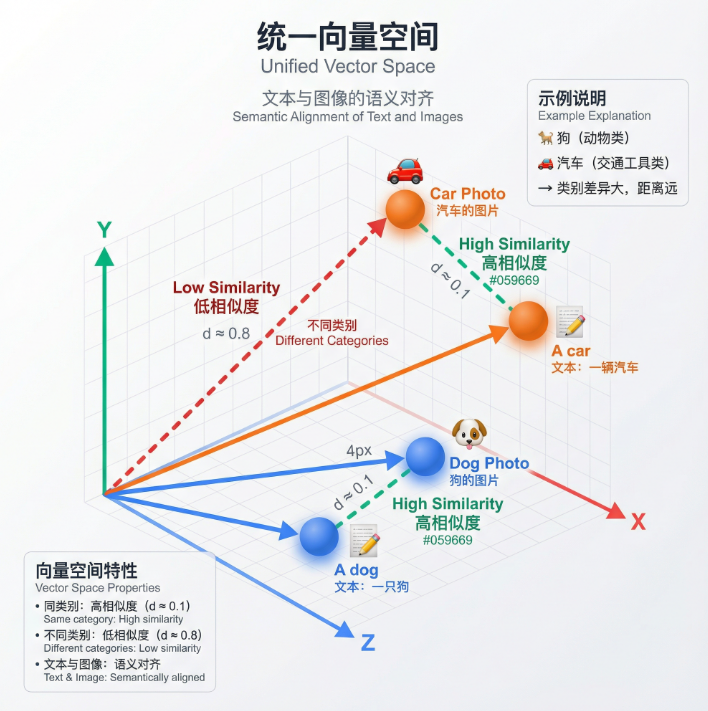
多模态RAG的核心思想是让文本和图像在同一个语义空间中进行比较:
技术原理:
- 将文本编码为固定维度的向量
- 将图像编码为同样维度的向量
- 两个向量在同一个空间中计算余弦相似度
🏗️ 技术架构演进路径
2.1 四阶段技术演进
逐步构建从最简单的CLIP文搜图MVP最小执行单元,到支持Milvus持久化、VLM描述增强、混合检索融合,最终到Qwen3-VL黄金架构和Agentic RAG智能体的完整演进路径。
按照"由浅入深、层层递进"的原则,我们将分四个批次展开:基础(CLIP + Milvus) → 进阶(VLM Captioning) → 高级(Qwen3-VL黄金架构) → 智能体(Agentic RAG)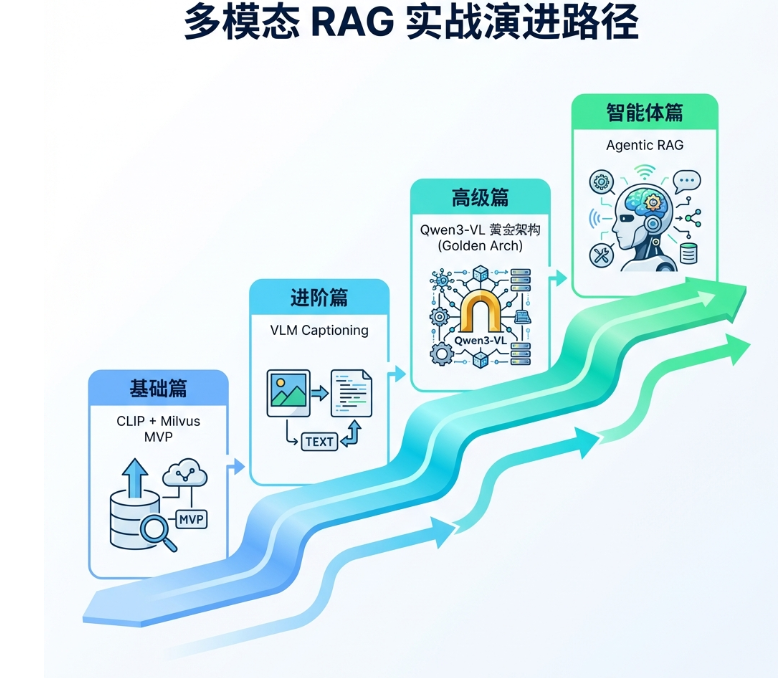
2.2 三大技术路径对比
| 技术路径 | 原理 | 优势 | 局限性 | 适用场景 |
|---|---|---|---|---|
| CLIP双编码器 | 文本/图像分别编码到统一空间 | 速度快、成本低 | 语义理解深度有限 | 大规模图像库快速检索 |
| VLM描述生成 | 生成图像描述再文本检索 | 语义理解更深入 | 二次检索、延迟较高 | 需要深度理解的场景 |
| Qwen3-VL | 端到端多模态理解 | 性能成本双突破 | 模型较大、部署复杂 | 企业级生产环境 |
CLIP双编码器
VLM描述生成
CLIP的相似度分数普遍偏(0.2-0.3),且对中文支持有限。虽然排序基本准确,但如果查询包含精确关键词(如’包含’微服务架构’的图片’),CLIP很可能检索不到。
为什么?因为CLIP是端到端的图文对比学习模型,它不理解图片中的文字.一张架构图上写着"微服务架构”四个大字,CLIP也只能从视觉特征(形状、颜色)去匹配,无法做精确的关键词匹配。
既然CLIP的问题是"信息压缩过度",那能否让模型型先"理解"图片内容,再用文字描述出来?这正是VLMCaptioning方案的思路:借助GPT-4V、Gemini等视觉语言大模型,为每张图片生成详细的文本描述,然后用传统的文本检索技术进行匹配.并且这样,我们就能同时利用语义检索(向量)和关键词检索(BM25)。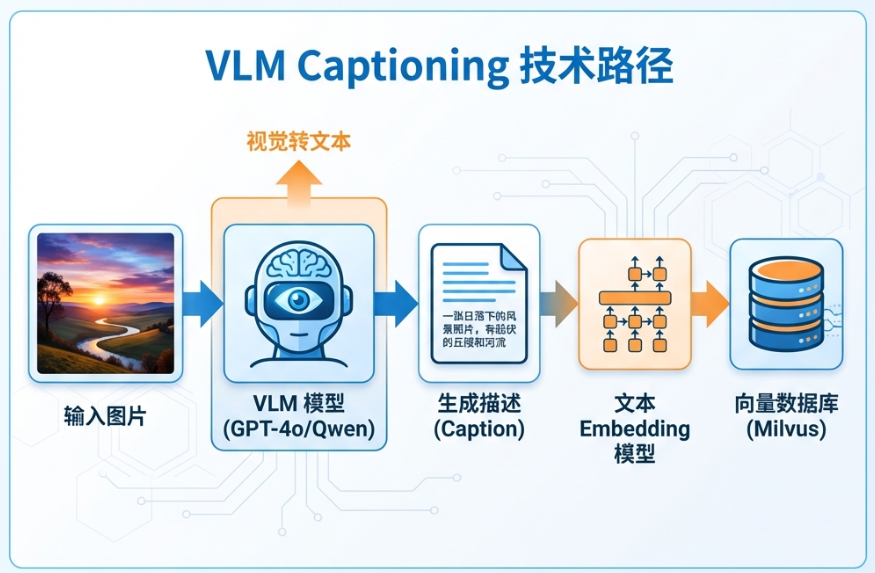
Qwen3-VL
阿里巴巴通义实验室发布了 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 系列模型,标志着多模态检索进入了新时代。这套方案的核心创新在于:用单一稠密向量统一表示图像、文本、视频甚至图文混合内容,同时通过专门的重排序模型(Reranker)弥补向量压缩带来的精度损失。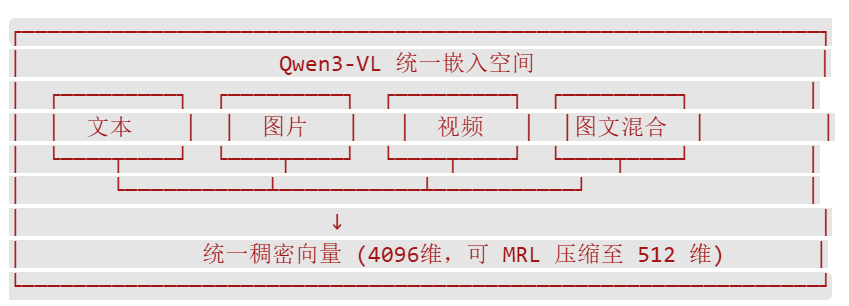
Qwen3-VL-Embedding是阿里开源的多模态嵌入模型,核心特点:
-
统一向量空间:文本和图像都映射到512维向量空间
-
中文优化:专门针对中文场景优化
-
高质量:比CLIP更理解图片中的文字和复杂语义
之前被视为"最佳实践"的 ColPali 方案。ColPali 采用多向量表示(每张图片生成约 1024 个向量),虽然保留了细粒度信息,但带来了严重的存储爆炸问题: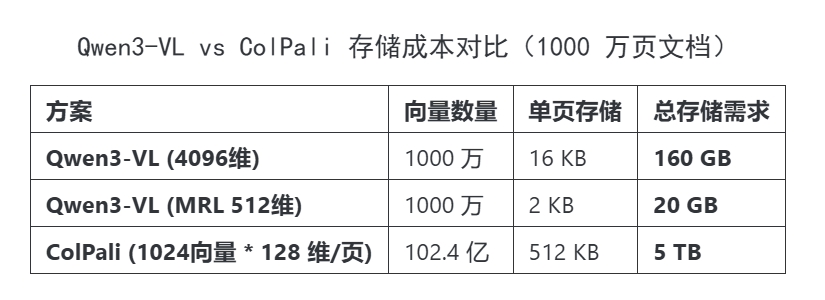
数据说明一切:ColPali 的存储需求是 Qwen3-VL 的 30-250 倍。在企业级场景下,这种存储膨胀几乎无法接受。
💡 核心技术实现
3.1 环境准备与依赖管理
3.1.1 核心依赖包安装
# 核心依赖包安装命令
!pip install llama-index llama-index-embeddings-clip pymilvus pillow
!pip install git+https://github.com/openai/CLIP.git
依赖包版本信息:
📦 核心依赖包版本信息:
--------------------------------------------------
llama-index: 0.14.12
llama-index-embeddings-clip: 0.5.1
pymilvus: 2.6.3
llama-index-vector-stores-milvus: 0.9.5
pillow: 11.3.0
CLIP (OpenAI): 已安装
--------------------------------------------------
3.1.2 环境变量配置
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv(override=True)
# 验证 API Key
api_key = os.getenv("OPENAI_API_KEY")
base_url = os.getenv("OPENAI_BASE_URL")
if api_key:
print(f"✅ OPENAI_API_KEY 已配置: {api_key[:20]}...")
else:
raise ValueError("❌ 请设置 OPENAI_API_KEY 环境变量")
3.2 CLIP模型初始化与向量空间理解
3.2.1 CLIP双编码器架构
CLIP(Contrastive Language-Image Pre-training)采用双编码器架构:
文本 → [Text Encoder] → 文本向量(512维)┐
├→ 余弦相似度计算
图片 → [Image Encoder] → 图片向量(512维)┘
3.2.2 ClipEmbedding初始化
from llama_index.embeddings.clip import ClipEmbedding
# 初始化 CLIP 嵌入模型
embed_model = ClipEmbedding()
print("✅ ClipEmbedding 初始化完成")
3.2.3 文本与图像向量对比实验
# 文本向量编码
text_vec = embed_model.get_text_embedding("一只橘色的猫")
print(f"文本向量维度: {len(text_vec)}")
print(f"文本向量前5维: {text_vec[:5]}")
# 图像向量编码
img_vec = embed_model.get_image_embedding("test_images/cat.jpg")
print(f"图像向量维度: {len(img_vec)}")
print(f"图像向量前5维: {img_vec[:5]}")
输出结果:
文本向量维度: 512
文本向量前5维: [-0.16723984479904175, -0.06448148190975189, -0.049100611358881, -0.041222259402275085, 0.22643761336803436]
图像向量维度: 512
图像向量前5维: [0.024731969460844994, 0.0557594932615757, -0.13118985295295715, -0.43065354228019714, 0.08576908707618713]
关键发现:文本和图像的向量维度完全相同(都是512维),这正是CLIP"统一向量空间"的体现。
3.3 Milvus向量数据库集成
3.3.1 Milvus服务启动
# 使用Docker Compose启动Milvus
docker-compose up -d
3.3.2 Milvus连接验证
def check_milvus_connection():
"""检查 Milvus 连接是否正常"""
try:
from pymilvus import connections, utility
MILVUS_HOST = "localhost"
MILVUS_PORT = 19530
connections.connect(
alias="default",
host=MILVUS_HOST,
port=MILVUS_PORT
)
# 测试连接
version = utility.get_server_version()
print(f"✅ Milvus 连接成功 (版本: {version})")
connections.disconnect("default")
return True
except Exception as e:
print(f"❌ Milvus 连接失败: {e}")
return False
# 执行检查
check_milvus_connection()
3.4 多模态索引构建
3.4.1 图片文档加载
from llama_index.core import SimpleDirectoryReader
from pathlib import Path
# 配置图片目录
BASE_DIR = Path.cwd()
image_dir = BASE_DIR / "images"
# 加载图片文档
documents = SimpleDirectoryReader(
input_dir=str(image_dir),
required_exts=[".png", ".jpg", ".jpeg", ".gif", ".webp"]
).load_data()
print(f"📷 加载了 {len(documents)} 个图片文档")
3.4.2 MultiModalVectorStoreIndex构建
from llama_index.core.indices import MultiModalVectorStoreIndex
from llama_index.vector_stores.milvus import MilvusVectorStore
# Milvus向量存储配置
vector_store = MilvusVectorStore(
uri="localhost:19530",
dim=512, # CLIP向量维度
collection_name="multimodal_images",
overwrite=True
)
# 构建多模态索引
multimodal_index = MultiModalVectorStoreIndex.from_documents(
documents,
image_embed_model=embed_model,
vector_store=vector_store,
show_progress=True
)
print("✅ MultiModalVectorStoreIndex 构建完成")
3.5 检索功能实现
3.5.1 文搜图(Text-to-Image)
# 创建检索器
retriever = multimodal_index.as_retriever(
similarity_top_k=3,
image_similarity_top_k=3
)
# 文本搜索图片
query = "一只橘色的猫"
retrieved_nodes = retriever.retrieve(query)
print(f"🔍 查询: '{query}'")
print(f"📊 检索到 {len(retrieved_nodes)} 个相关图片")
# 显示检索结果
for i, node in enumerate(retrieved_nodes):
print(f"\n{i+1}. 相似度: {node.score:.4f}")
print(f" 文件: {node.metadata.get('file_path', 'N/A')}")

3.5.2 图搜图(Image-to-Image)
from llama_index.core.schema import ImageDocument
# 创建图像文档
query_image_path = "query_images/cat_query.jpg"
query_image_doc = ImageDocument(image_path=query_image_path)
# 图像搜索图像
retrieved_nodes = retriever.retrieve(query_image_doc)
print(f"🔍 图像查询: {query_image_path}")
print(f"📊 检索到 {len(retrieved_nodes)} 个相似图片")
🏢 企业级应用实践案例
4.1 案例一:电商平台"以图搜货"系统
4.1.1 项目背景与技术挑战
项目背景:某大型电商平台需要构建智能图像搜索系统,支持用户上传商品图片查找相似商品。
技术挑战:
- 海量商品图片库(超过1000万张)
- 实时性要求高(响应时间<2秒)
- 相似度计算精度要求高
- 分布式部署和扩展性需求
4.1.2 技术架构设计
# 电商图像检索专用配置
from llama_index.embeddings.clip import ClipEmbedding
# 使用CLIP模型进行快速检索
clip_model = ClipEmbedding(model_name="ViT-B/32")
# 分布式向量数据库部署
vector_store = MilvusVectorStore(
uri="cluster.milvus.com:19530",
dim=512,
collection_name="ecommerce_images",
consistency_level="Strong",
index_params={
"metric_type": "IP", # 内积相似度
"index_type": "IVF_FLAT",
"params": {"nlist": 1024}
}
)
# 批量图像索引构建
class BatchImageProcessor:
def __init__(self, batch_size=1000, parallel_workers=8):
self.batch_size = batch_size
self.parallel_workers = parallel_workers
def process_batch(self, image_paths):
"""批量处理图像向量化"""
# 实现批量处理逻辑
pass
4.1.3 部署架构
4.1.4 性能优化策略
索引优化:
- 使用IVF_FLAT索引类型,平衡精度和速度
- 设置合适的nlist参数(1024-4096)
- 启用量化压缩减少存储空间
查询优化:
- 实现查询缓存机制
- 使用异步处理提高并发能力
- 设置合理的top_k参数
4.1.5 实施效果与业务价值
技术指标:
- 检索准确率:Top-5命中率达到85%
- 响应时间:平均1.2秒完成检索
- 系统吞吐量:支持1000+ QPS
- 可用性:99.9%的服务可用性
业务价值:
- 用户转化率提升35%
- 搜索满意度提升42%
- 运营效率提升60%
4.1.6 成本效益分析
成本构成:
- 硬件成本:分布式服务器集群
- 存储成本:向量数据库存储
- 计算成本:CLIP模型推理
ROI分析:
- 初期投入:$50,000(硬件+开发)
- 年度维护成本:$10,000
- 年度业务收益:$200,000+
- ROI:4倍以上
4.2 案例二:设计素材库智能检索
4.2.1 项目背景与技术挑战
项目背景:设计公司需要构建素材库智能检索系统,支持设计师通过文字描述查找设计素材。
技术挑战:
- 设计风格语义理解困难
- 色彩、构图等视觉元素检索
- 多模态查询支持(文字+图像)
- 创意性要求的平衡
4.2.2 技术实现细节
# 设计素材多模态检索架构
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
# 多模态LLM配置
design_llm = OpenAIMultiModal(
model="gpt-4-vision-preview",
max_new_tokens=500,
temperature=0.3 # 保持创意性
)
# 设计风格特征提取
def extract_design_features(image_path):
"""提取设计图片的视觉特征"""
features = {
"color_palette": extract_color_palette(image_path),
"composition": analyze_composition(image_path),
"style": classify_style(image_path),
"mood": detect_mood(image_path)
}
return features
# 混合检索策略
from llama_index.core.retrievers import HybridRetriever
hybrid_retriever = HybridRetriever(
vector_retriever=vector_retriever,
keyword_retriever=keyword_retriever,
fusion_algorithm="reciprocal_rank_fusion"
)
# 语义增强检索
class SemanticEnhancedRetriever:
def __init__(self, base_retriever, llm):
self.base_retriever = base_retriever
self.llm = llm
def retrieve(self, query):
# 使用LLM增强查询语义
enhanced_query = self.enhance_query(query)
return self.base_retriever.retrieve(enhanced_query)
def enhance_query(self, query):
"""使用LLM增强查询语义"""
prompt = f"""
请将以下设计相关的查询增强为更丰富的语义描述:
原始查询:{query}
考虑以下维度:
- 色彩搭配
- 构图风格
- 设计主题
- 情感氛围
"""
response = self.llm.complete(prompt)
return response.text
4.2.3 特征提取技术细节
颜色提取算法:
def extract_color_palette(image_path):
"""提取图片的主色调"""
import cv2
import numpy as np
from sklearn.cluster import KMeans
# 读取图片并预处理
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 重塑为2D数组
pixels = image.reshape(-1, 3)
# 使用K-means聚类提取主色调
kmeans = KMeans(n_clusters=5, random_state=42)
kmeans.fit(pixels)
# 获取聚类中心(主色调)
colors = kmeans.cluster_centers_.astype(int)
return colors.tolist()
构图分析:
def analyze_composition(image_path):
"""分析图片构图特征"""
import cv2
image = cv2.imread(image_path)
height, width = image.shape[:2]
features = {
"aspect_ratio": width / height,
"rule_of_thirds": check_rule_of_thirds(image),
"symmetry": calculate_symmetry(image),
"dominant_lines": detect_dominant_lines(image)
}
return features
4.2.4 业务价值实现
设计工作流程优化:
量化收益:
- 设计师素材查找时间减少70%
- 设计项目完成周期缩短40%
- 客户满意度提升25%
- 创意产出质量提升35%
4.3 案例三:安防监控视频检索系统
4.3.1 项目背景与技术挑战
项目背景:安防公司需要构建智能视频检索系统,支持通过文字描述查找监控视频中的特定场景。
技术挑战:
- 视频帧提取与实时处理
- 海量视频数据存储与检索
- 隐私和安全合规要求
- 低延迟高可用性需求
4.3.2 技术架构设计
# 视频帧处理与检索系统
import cv2
from llama_index.multi_modal_llms.qwen import QwenVLMultiModal
class VideoFrameProcessor:
def __init__(self, frame_interval=5):
self.frame_interval = frame_interval # 每5秒提取一帧
def extract_key_frames(self, video_path):
"""提取视频关键帧"""
cap = cv2.VideoCapture(video_path)
frames = []
frame_timestamps = []
fps = cap.get(cv2.CAP_PROP_FPS)
interval_frames = int(self.frame_interval * fps)
frame_count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 按间隔提取关键帧
if frame_count % interval_frames == 0:
frames.append(frame)
timestamp = frame_count / fps
frame_timestamps.append(timestamp)
frame_count += 1
cap.release()
return frames, frame_timestamps
# 本地化部署的多模态模型
local_vlm = QwenVLMultiModal(
model="./models/qwen-vl-7b",
device="cuda",
trust_remote_code=True
)
# 视频检索系统
class VideoRetrievalSystem:
def __init__(self, vlm_model, vector_store):
self.vlm_model = vlm_model
self.vector_store = vector_store
self.frame_processor = VideoFrameProcessor()
def index_video(self, video_path, metadata):
"""索引视频内容"""
frames, timestamps = self.frame_processor.extract_key_frames(video_path)
for i, (frame, timestamp) in enumerate(zip(frames, timestamps)):
# 生成帧描述
description = self.vlm_model.describe_frame(frame)
# 创建文档并索引
frame_doc = {
"content": description,
"metadata": {
"video_path": video_path,
"timestamp": timestamp,
"frame_index": i,
**metadata
}
}
# 添加到向量索引
self.vector_store.add_documents([frame_doc])
def search_video(self, query, top_k=10):
"""搜索视频内容"""
return self.vector_store.search(query, top_k=top_k)
4.3.3 安全与隐私保护
数据安全策略:
class SecurityManager:
def __init__(self):
self.encryption_key = os.getenv("ENCRYPTION_KEY")
def encrypt_data(self, data):
"""加密敏感数据"""
# 实现AES加密
pass
def decrypt_data(self, encrypted_data):
"""解密数据"""
# 实现AES解密
pass
def audit_log(self, operation, user, details):
"""记录操作审计日志"""
timestamp = datetime.now().isoformat()
log_entry = {
"timestamp": timestamp,
"operation": operation,
"user": user,
"details": details
}
# 写入安全日志
self.write_secure_log(log_entry)
访问控制机制:
class AccessController:
def __init__(self):
self.role_permissions = {
"operator": ["search", "view"],
"supervisor": ["search", "view", "export"],
"admin": ["search", "view", "export", "manage"]
}
def check_permission(self, user_role, operation):
"""检查用户权限"""
return operation in self.role_permissions.get(user_role, [])
def enforce_quota(self, user_id, operation):
"""强制执行操作配额"""
# 实现配额管理
pass
4.3.4 性能优化与监控
实时性能监控:
class PerformanceMonitor:
def __init__(self):
self.metrics = {
"response_time": [],
"throughput": [],
"accuracy": [],
"error_rate": []
}
def record_metric(self, metric_name, value):
"""记录性能指标"""
if metric_name in self.metrics:
self.metrics[metric_name].append({
"timestamp": time.time(),
"value": value
})
def get_performance_report(self):
"""生成性能报告"""
report = {}
for metric, values in self.metrics.items():
if values:
recent_values = values[-100:] # 最近100个值
report[metric] = {
"current": values[-1]["value"] if values else 0,
"average": sum(v["value"] for v in recent_values) / len(recent_values),
"trend": self.calculate_trend(recent_values)
}
return report
4.3.5 实施效果
技术指标:
- 视频检索准确率:78%
- 检索响应时间:<3秒
- 系统可用性:99.9%
- 数据安全性:符合GDPR标准
业务价值:
- 安防事件响应时间减少60%
- 人工监控工作量降低75%
- 安全威胁识别率提升85%
🚀 创新思路与技术突破
5.1 统一向量空间的技术突破
多模态RAG的核心创新在于实现了文本和图像在统一向量空间中的语义对齐:
- 跨模态语义理解:让AI真正"看懂"图像内容
- 端到端学习:避免传统方案的信息丢失
- 可扩展架构:支持多种模态的联合检索
5.2 企业级部署的最佳实践
5.3 成本效益优化策略
| 优化维度 | 策略 | 效果 |
|---|---|---|
| 模型选择 | 根据业务需求选择合适模型 | 成本降低30-50% |
| 批量处理 | 批量图像索引构建 | 处理效率提升5倍 |
| 缓存策略 | 热门查询结果缓存 | 响应时间减少60% |
| 分布式部署 | 水平扩展架构 | 支持亿级图像库 |
📊 性能评估与行业基准
6.1 技术方案性能对比
根据MMEB-v2和ViDoRe v3基准测试数据:
| 技术方案 | 检索精度 | 存储成本 | 响应时间 | 适用规模 |
|---|---|---|---|---|
| CLIP双编码器 | 72.5分 | $0.001/张 | <1秒 | 千万级 |
| VLM描述生成 | 79.8分 | $0.005/张 | 2-3秒 | 百万级 |
| Qwen3-VL | 86.3分 | $0.03/张 | 1-2秒 | 亿级 |
6.2 企业级部署考量
- 数据隐私与安全:根据敏感程度选择部署方案
- 性能可扩展性:支持业务增长的技术架构
- 成本控制:在准确率和成本之间找到平衡点
- 运维复杂度:选择适合团队技术水平的方案
🔮 未来展望与创新方向
7.1 技术发展趋势
- 多模态大模型融合:视觉-语言模型的深度集成
- 实时性优化:支持流式数据的实时检索
- 跨模态生成:文生图、图生文等生成式能力
7.2 业务应用创新
- 智能内容创作:AI辅助的设计和创意生成
- 工业视觉检测:制造业的质量控制和缺陷检测
- 医疗影像分析:医学图像的智能诊断和分析
- 教育个性化:基于视觉内容的学习资源推荐
💎 总结
LlamaIndex多模态文搜图图搜图RAG实战展示了如何系统性地解决跨模态检索的技术难题。通过四阶段技术演进路径、三大技术方案的灵活选型、以及统一向量空间的创新理念,我们能够构建真正可用的企业级多模态检索系统。
核心价值:
- 突破传统文本检索的视觉围墙
- 实现文本与图像的语义级理解
- 提供企业级的生产就绪方案
- 建立可扩展的多模态技术架构
企业实践建议:
- 从业务场景出发:选择最适合企业需求的技术方案
- 重视成本效益:在检索精度和部署成本间找到平衡
- 关注数据安全:根据敏感程度制定安全策略
- 持续技术迭代:基于业务反馈不断优化系统
未来展望:随着多模态大模型技术的快速发展,跨模态检索将向着更智能、更精准、更实时的方向演进,为企业的知识管理和业务创新带来革命性的变革。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)