AI算力硬件大揭秘:CPU、GPU、NPU、TPU、DPU、VPU各显神通,一文看懂全场景落地!
本文全面解析了AI算力硬件的多元格局,涵盖了CPU、GPU、NPU、TPU、DPU、VPU等处理器的核心特性、差异与应用场景。从通用算力的CPU到并行计算的GPU,再到端侧AI专用的NPU,以及谷歌定制的TPU、数据中心的DPU和视觉处理专用的VPU,文章详细介绍了各类处理器在灵活性、并行性、功耗与效率间的权衡,旨在帮助读者快速掌握AI算力硬件的全貌,从而更好地理解AI技术在不同场景下的应用与落地。
人工智能技术飞速发展,算力硬件已从传统 CPU、GPU 主导,演进为通用 + 专用异构协同的多元格局。CPU、GPU、NPU、ASIC 类加速器(如 TPU)、LPU(特定架构)、DPU、VPU 等处理器各司其职,在灵活性、并行性、功耗与效率间做出不同权衡,共同支撑 AI 从云端到终端的全场景落地。本文全面拆解各类处理器核心特性、差异与应用场景,帮你快速看懂 AI 算力硬件全貌。
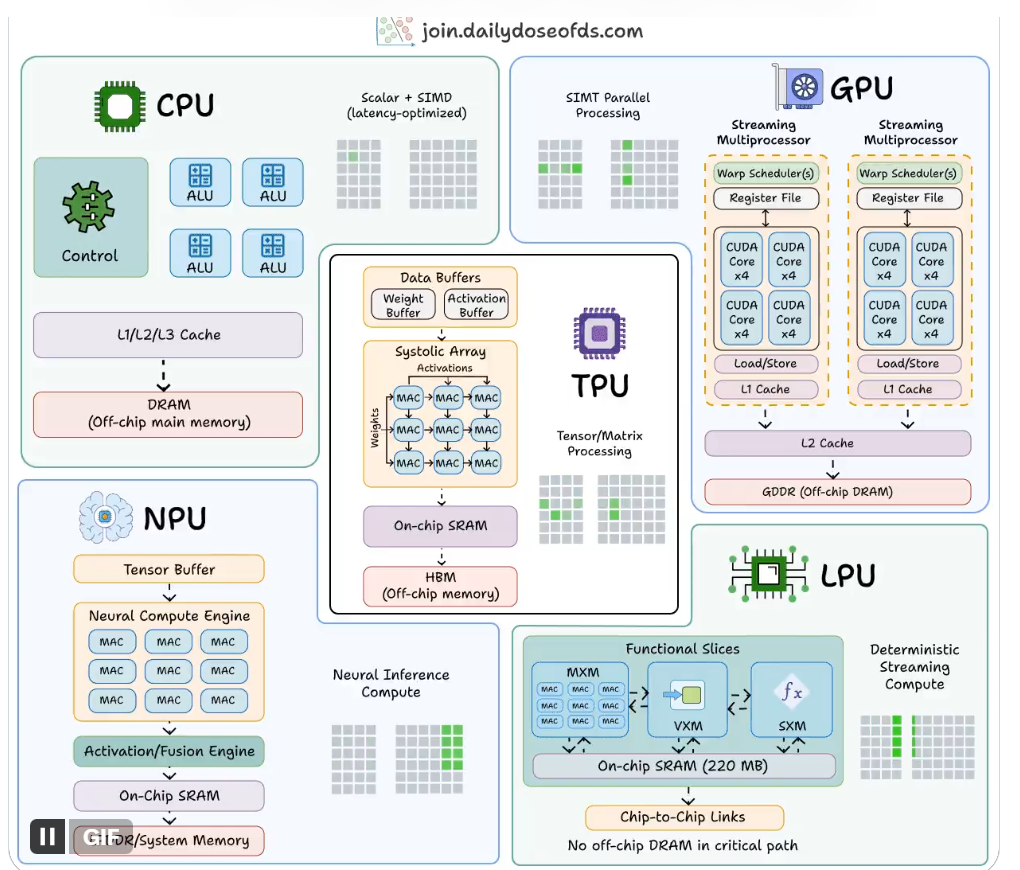
1. 通用算力核心:CPU——计算机的“万能大脑”
CPU(中央处理器)是所有电子设备的基础核心,定位为通用计算中枢,负责系统调度、逻辑控制与复杂运算。
核心特点
- 擅长串行任务、复杂逻辑判断、分支跳转,单线程性能强悍
- 配备 L1/L2/L3 三级缓存,兼顾通用性与低延迟
- 核心数:消费级 4–16 核(部分采用大小核架构),服务器级 64–128 核甚至更高,灵活性拉满,兼容全场景程序
硬件与局限
缓存速度快,但片外 DRAM 内存带宽有限,不擅长大规模并行矩阵运算。在 AI 系统中适合担任调度员,承担数据预处理、任务分配、系统管控等辅助工作。
代表厂商
英特尔、AMD、ARM、华为海思、高通
典型场景
个人电脑、服务器、手机系统调度、日常办公、AI 任务总控
2. 并行计算王者:GPU——AI 训练的“主力工厂”
GPU(图形处理器)最初为图形渲染设计,凭借超强并行计算能力成为深度学习训练的核心硬件。
核心特点
- 众核架构,数千至上万个小型计算核心,极致并行处理
- 高带宽 HBM/GDDR 内存,支撑海量数据并发,算力远超 CPU
- 兼顾通用计算,可做科学计算、视频编解码、3D 渲染
- 支持 FP16、BF16、INT8 等混合精度训练
AI 适配性
完美匹配深度学习矩阵运算、卷积运算,是当前 AI 大模型训练与推理的绝对主力平台(尤其是云端)。
代表厂商
英伟达、AMD、沐曦集成、摩尔线程
典型场景
游戏渲染、影视特效、深度学习训练、大规模云端 AI、科学计算
3. 端侧 AI 专用:NPU——低功耗推理“节能专家”
NPU(神经网络处理器)专为 AI 神经网络计算优化,主打低功耗、高推理效率,是终端与边缘 AI 的核心硬件。
核心特点
- 专用 MAC 阵列、向量引擎、激活函数硬件加速,专注矩阵/卷积运算
- 片上 SRAM + 智能缓存,减少片外访问
- 功耗:端侧典型 1–5W,部分边缘场景可达数十瓦
- 能效比极高,推理速度远超通用 CPU/GPU,适配端侧实时 AI
技术优势
- 支持张量加速、稀疏运算、混合精度,在神经网络推理上表现突出
- 端侧 NPU(手机、耳机)仅支持推理;云端/边缘 NPU(如昇腾、寒武纪)可支持训练与微调
代表厂商
华为昇腾、寒武纪、苹果、高通、瑞芯微、晶晨
典型场景
智能手机 AI、智能家居、自动驾驶感知、边缘摄像头、可穿戴设备
4. 谷歌定制张量引擎:TPU——云端 AI 专用加速器
TPU(张量处理器)由 Google 研发,针对张量运算深度定制,是云端 AI 训练/推理的专业化方案。
核心特点
- 脉动阵列 MAC 单元,波浪式数据处理,减少数据搬运开销
- 编译器精准控制,无硬件调度损耗,大规模集群能效极佳
- 高算力、低功耗,适配云端大规模神经网络任务
应用边界
- 主要用于 Google 云端 AI 服务、内部大模型训练,以云服务(Google Cloud)或整机形式(如 Cloud TPU v4)对外提供算力,不单独出售芯片
- 已支持 PyTorch(通过 PyTorch/XLA)及 TensorFlow
- 通用性弱于 GPU,但专用场景效率更高
典型场景
谷歌搜索/翻译、云端大模型训练、TensorFlow/PyTorch 框架加速
5. 语言模型低延迟推理架构:LPU——云端低延迟推理单元
说明:LPU 非行业通用芯片标准,为特定企业(如 Groq)提出的推理架构。
LPU(语言处理单元)基于全片上 SRAM 存储权重设计,彻底移除片外 DRAM,核心目标是实现极低延迟推理,目前主要用于云端低延迟场景。
核心特点
- 全片上 SRAM 存储权重,无片外内存访问延迟
- 编译器统一调度,无缓存未命中与硬件调度开销,确定性低延迟
- 缺点:片上存储容量有限,单卡模型容量小,大型模型需集群部署,成本较高
典型场景
云端低延迟 AI 对话、交互式 LLM 推理(不适用于端侧)
代表企业(非通用厂商)
Groq 等
6. 数据中心基石:DPU——数据搬运与安全管家
DPU(数据处理单元)聚焦数据中心数据流转、存储、网络与安全,解放 CPU 专注业务计算。
核心特点
- 高效数据搬运、网络加速、存储虚拟化、硬件级安全加密
- 降低 CPU 负载,提升数据中心整体吞吐量与安全性
- 不直接参与 AI 模型矩阵运算,但可卸载推理中的网络和存储任务
代表厂商
NVIDIA BlueField、Intel IPU、AMD(Pensando),以及主流云厂商自研方案(如阿里 CIPU、AWS Nitro)
典型场景
云计算数据中心、5G/6G 通信、大规模存储系统、网络安全
7. 视觉处理专用:VPU——图像视频加速单元
VPU(视觉处理单元)专注图像/视频处理,兼顾编解码与轻量视觉辅助,是智能视觉场景的重要组成部分。
核心特点
- 硬解 8K/4K 视频(H.265/AV1 等),低功耗实时处理
- 可配合 NPU/GPU 完成目标检测、人脸识别等视觉 AI 任务,自身侧重图像前处理、缩放、去噪与编解码加速
- 多屏异显、多路摄像头数据并行处理
代表厂商
英特尔(Movidius)、瑞芯微、晶晨(面向安防、边缘、嵌入式视觉)
典型场景
安防监控、自动驾驶视觉、手机影像、视频会议、无人机
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献158条内容
已为社区贡献158条内容

所有评论(0)