【Agent】Towards General Agentic Intelligence via Environment Scaling
note
- 这篇论文提出了一种通过系统环境扩展和agent经验学习来提升通用agent智能的方法。通过程序化地将工具实例化为可执行的代码,并在数据库结构化的环境中进行操作,实现了大规模的可验证轨迹构建。
- 论文先将数万 API 按功能聚类成 1000+ 个语义域,每个域内只保留逻辑相关的工具;然后在同一个域内,采样少量、连贯的工具序列,反向合成自然语言用户 query,再在虚拟环境中执行得到多步 function call 轨迹,用于 SFT
- 基于这些环境,引入了两阶段agent经验学习框架(SFT),使agent能够在一般域中学习基本的工具使用技能,并在目标垂直域中进行细粒度训练。
- 广泛的实验结果表明,AgentScaler系列模型在开源模型中达到了最先进的性能,并在某些情况下与更大或闭源的对应模型相当。未来的研究方向包括在完全模拟的环境上集成强化学习和扩展管道以涵盖更广泛的模态和实际部署场景。
一、研究背景
- 研究问题:这篇文章要解决的问题是如何通过环境扩展来提升通用代理智能。具体来说,现有的语言模型在真实世界应用中存在function call调用能力不足的问题,尤其是在多样化的环境中进行交互时。
- 研究难点:该问题的研究难点包括:如何系统地扩展环境以覆盖更多的功能调用场景,以及如何有效地从与这些环境交互中获得的经验中训练代理的智能。
- 相关工作:该问题的研究相关工作包括两类方法:一类是反向范式,通过生成用户查询来匹配每个助手的功能调用;另一类是正向范式,即模拟代理-人类交互来生成轨迹数据。然而,这两类方法都存在一定的局限性,如生成的轨迹缺乏真实性或自然性,且环境不可扩展。
二、Environment Scaling
这篇论文提出了一种通过系统环境扩展来提升通用代理智能的方法。具体来说,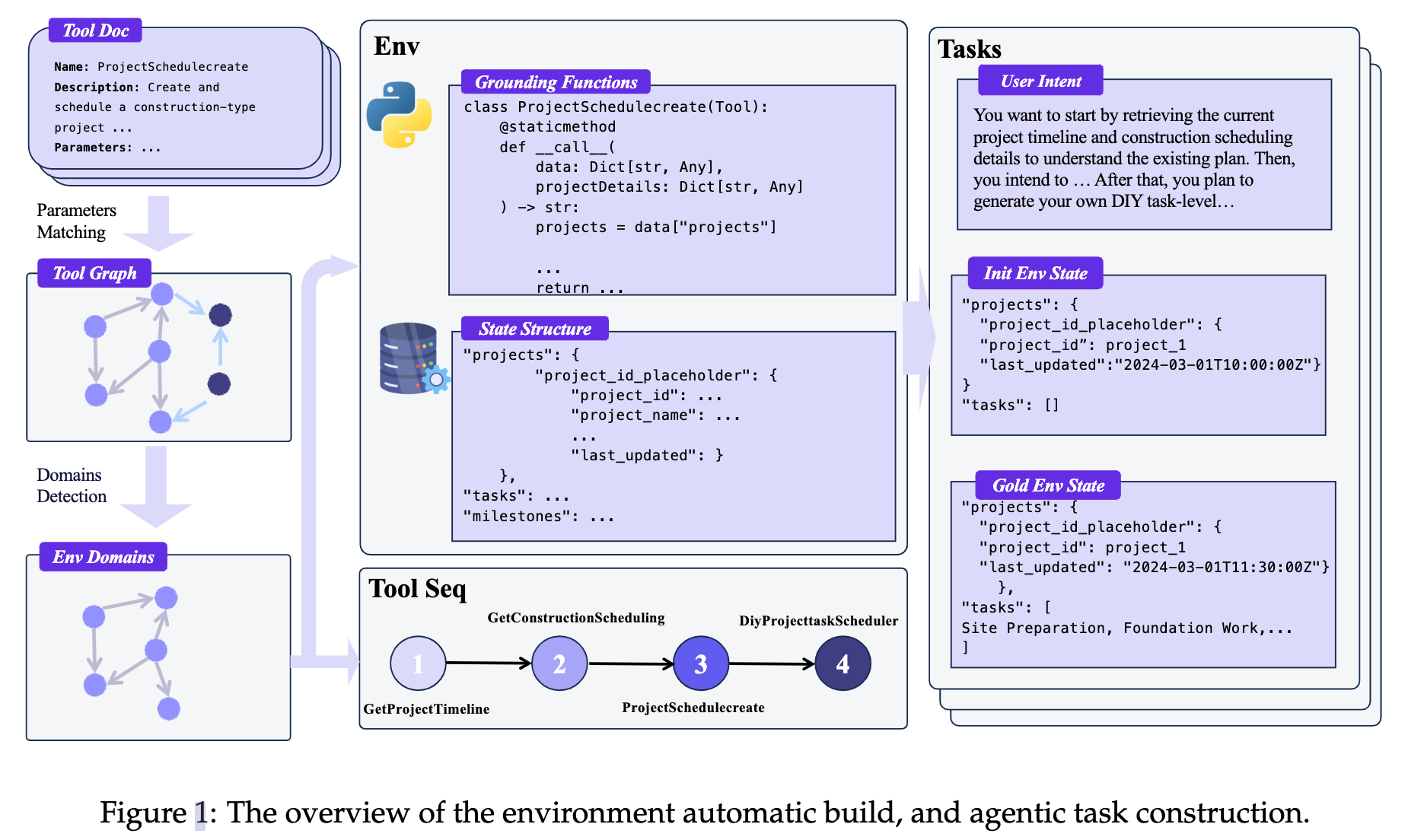
1、环境自动构建:首先,作者设计了一个系统化的流程来利用多样化的工具集。该流程包括场景收集、工具依赖图建模和功能模式程序化实现三个阶段。
- 场景收集:从ToolBench、API-Gen和内部工具库中收集了超过30,000个API,经过过滤和重写后,构建了API池。
- 工具依赖图建模:通过计算工具参数的余弦相似度,构建工具图,并使用
Louvain社区检测算法进行域划分。- 先把 3 万 + API 用聚类分成 1000 + 个 domain(域),每个域是一个独立小环境(如:天气域、机票域、外卖域)
- 每次只在同一个 domain 内采样工具,防止反向构造的query过于离谱
- 采样方式:在域内的工具依赖图上随机游走,直到设置的最大跳数 or 节点结束
- 功能模式程序化实现:将工具操作形式化为数据库交互,生成领域特定的数据库结构,并将工具实例化为可执行的Python代码。
2、agent任务构建:
- 通过前向模拟agent-人类交互来构建轨迹。具体步骤包括初始化环境状态、采样逻辑一致的工具序列、生成相应的参数并执行工具调用,确保轨迹的可验证性。
- 基于环境自动生成多步骤、有依赖、带约束的复杂任务(如 “查天气→订机票→预约接送”)。
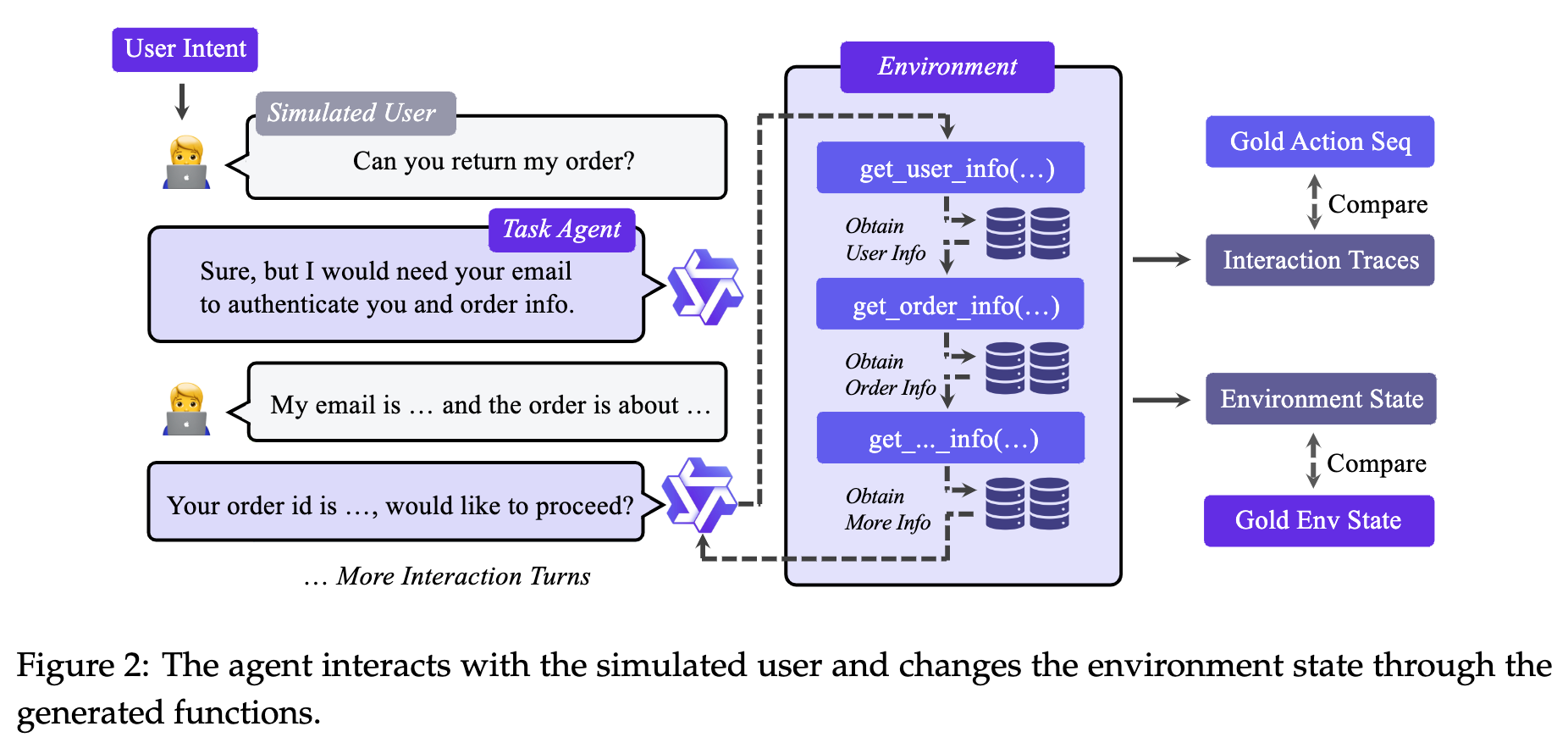
3、agent经验学习:采用两阶段agent经验学习框架(均为SFT)。
- 第一阶段,agent在一般域中学习基本的工具使用技能;
- 第二阶段,在目标垂直域中进行细粒度训练,使agent能够选择合适的工具、参数化调用并生成上下文相关的响应。
三、实验设计
- 基准测试:在三个成熟的代理基准上进行评估:t-bench、t2-Bench和ACEBench-en。对于t-Bench和t2-Bench,采用
pass^1指标进行评估,并分析pass^k的趋势;对于ACEBench-en,报告正常、特殊和代理类别的准确性,以及整体性能。 - 基线对比:将训练的一系列模型与以下类型的模型进行对比:闭源大型语言模型(如Gemini-2.5-pro、Claude-Sonnet-4、GPT-o3等)和开源大型语言模型(如GPT-OSS-120B-A5B、Deepseek-V3.1-671B-A37B等)。
- 模型训练:通过在Qwen3模型的不同规模上进行训练,构建AgentScaler系列模型(4B、8B、30B-A3B)。
四、实验结果

主要结果:闭源大型语言模型在大多数域和基准上仍然保持明显的性能优势。然而,AgentScaler在参数规模较小的情况下取得了显著的性能,特别是在t-bench、t2-Bench和ACEBench-en上。例如,AgentScaler-4B在零售和航空领域的得分分别达到了64.3和54.0,接近30B参数模型的性能。
消融研究:通过消融分析验证了两阶段代理经验学习框架的有效性。结果表明,第一阶段和第二阶段的训练都显著提高了模型性能,特别是第二阶段的多步代理训练进一步提升了代理集的得分。
跨领域评估:在ACEBench-zh上的评估结果显示,AgentScaler模型在所有规模上均优于其Qwen基线模型,特别是在正常和代理子集上表现出色。例如,AgentScaler-30B-A3B在整体得分上达到了81.5。
稳定性和长时工具调用挑战:AgentScaler-30B-A3B在所有评估的pass^k设置上均优于Qwen3-Thinking-30B-A3B,表明模型的稳定性显著提高。然而,长时工具调用的挑战仍然存在,工具调用数量与任务准确性之间存在负相关关系。
Reference
[1] Towards General Agentic Intelligence via Environment Scaling

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)