LangChain 核心组件 [ 6 ]

文本分割器(Text splitters)
概念
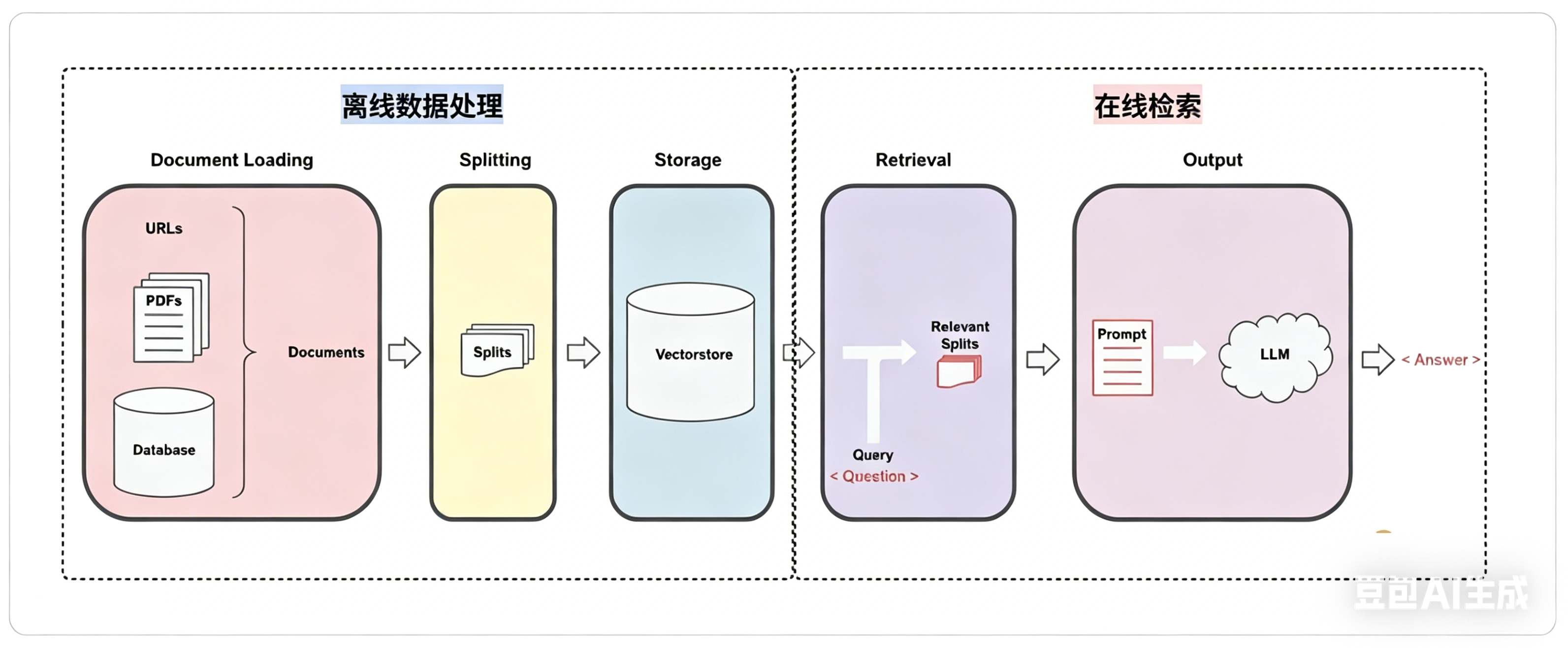
我们已经知道可以通过文档加载器完成各种数据源的加载,将其转换为文档对象 Document。那么接下来要做的就是文档拆分。
文档拆分通常是将大文本分解为更小的、易于管理的块。这对于索引数据并将其传递到模型中都很有用。因为,大块更难搜索并且不适合模型的有限上下文窗口。拆分可以提高搜索结果的粒度,从而可以更精确地将查询与相关文档部分进行匹配。
以下是详细的拆解原因:
1. 为什么大块更难搜索?(针对检索/向量搜索)
在 RAG(检索增强生成)中,文档会被转换成向量。如果块太大,会导致语义发散和分辨率降低。
-
语义模糊(高信噪比):一个大块可能包含 3 个不同的主题。当你搜索“苹果的手机”时,这个大块可能包含了“苹果种植技术”(第1段)和“iPhone 15”(第3段)。由于大部分内容是无关的,向量计算出的相似度会被稀释,导致检索系统认为这个块不够相关,或者把用户引向无关的段落。
-
颗粒度粗糙:假设你有一本 100 页的书,如果你把整本书作为一个块,用户搜索“第35页提到的某个公式”,系统只能返回整本书。它无法精准定位到那一页,导致下游模型需要去 100 页里翻找答案,很容易找错。
-
命中率低:如果查询非常具体,精确匹配在一大块文本中的占比很小。在向量空间中,这个具体的点很难被从一大片混杂的区域中“精确捞出来”。
2. 为什么不适合模型的有限上下文窗口?(针对 LLM 生成)
模型(如 GPT-4、Claude、文心一言)的上下文窗口不是无限大的(即使是 200 万上下文也有其弊端)。
-
“迷失在中间”现象:研究表明,大语言模型对位于长文本中间位置的内容关注度很低,容易忽略。如果一个大块是 10 万个 token,关键信息恰好在正中间,模型很可能会漏掉它,就像你在一间很吵的房间里听不清中间那句话一样。
-
时间与成本:处理大块文本会消耗更多的计算资源和时间。如果你传给模型 10 页不相关的废话,不仅花费更高,生成第一个字的速度也会变慢。
-
注意力分散:注意力机制虽然强大,但长距离依赖依然很难。如果相关的证据在块的开头,而问题是关于块结尾的,模型很难将这两部分完美关联起来,容易产生幻觉(自己编造连接逻辑)。
LangChain 的文本分割器便能将大型文档分解为更小的块。
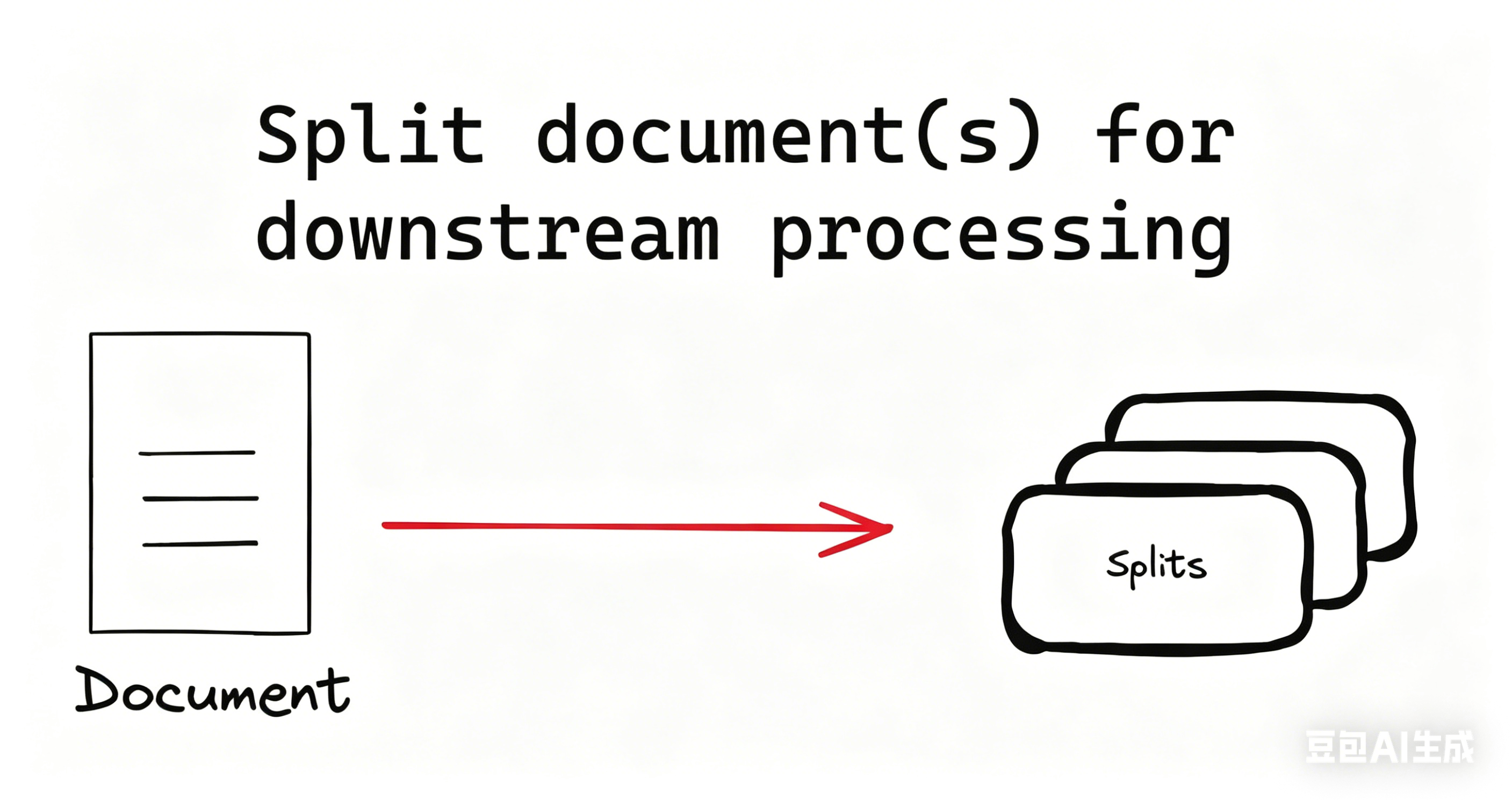
根据文档长度与文档语义拆分
我们可以直接根据文档的长度拆分文档,是最简单且有效的方法。可确保每个块不超过指定的大小限制。对于长度拆分,其实也分为两种:基于字符长度拆分 和 基于 Token 长度拆分。
基于字符长度拆分
根据给定的字符序列进行拆分,拆分的块长度则按字符数来衡量。
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
markdown_path = "../Docs/Markdown/脚手架级微服务租房平台Q&A.md"
# single 模式加载后,默认只有一个 Document 对象
loader = UnstructuredMarkdownLoader(markdown_path)
data = loader.load()
# 文本分割器
text_splitter = CharacterTextSplitter(
separator="\n\n", # 选择分隔符:它有一个默认的分隔符优先级列表,通常是["\n\n", "\n", " ", ""], 它会按顺序尝试这些分隔符
chunk_size=100, # 设定目标:目标块大小
chunk_overlap=20, # 设定目标:块之间的重叠大小
length_function=len, # 使用测量长度的函数
is_separator_regex=False,# 分隔符是正则表达式吗
)
# 分割文档,返回被分割的文档列表
texts = text_splitter.split_documents(data)
# 打印前10个被分割出来的文档
for document in texts[:10]:
print("*" * 30)
print(f"{document}\n")
关于
CharacterTextSplitter所有初始化参数见这里。
打印结果示例:
Created a chunk of size 128, which is longer than the specified 100
Created a chunk of size 133, which is longer than the specified 100
Created a chunk of size 108, which is longer than the specified 100
...
******************************
page_content='通用问题
为什么做这个项目?
回答1:(出于兴趣爱好开发)' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='大学期间,我和同学在外合租过一段时间,使用了一些租房平台,于是我有个想法,自己能不能开发一个租房平台,可以让我将理论知识与实践相结合。我希望通过实际项目来加深对Java编程语言和相关技术的理解。' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
...
Created a chunk of size xxx, which is longer than the specified 100,这表示分割时的块超出了我们设定的 chunk_size=100 目标块大小。在这里要说明,这是一个在使用 LangChain 的文本分割器时非常常见的问题。看到这个信息,不要担心,这不是错误,而是预期的行为。
原因是为了保持语义的完整性!当文本分割器用尽所有指定的分隔符都无法将一段文本分割到你的目标大小 chunk_size 以下时,它会选择保留整个文本块,而不是强行将其截断为无意义的片段,因此我们会看到这个提示信息。因此我们可以看到,被分割出来的段落,基本上都是语义完整的一段话。
那么分割逻辑到底是什么,可以支持保持语义完整性?
尝试分割:首先,它尝试用 separator(我们设置的是 \n\n 双换行,通常代表段落之间)来分割文本。如果分割后的任何一个段落仍然大于 chunk_size,它会继续下一步。
如果仍然有单个单词或字符串的长度超过了 100,分割器就陷入了两难境地:
-
选项 A:强行把超长的字符串在任意位置截断(例如,把 "Christopher" 截断成 "Christop" 和 "her"),严重影响后续的嵌入或语言模型处理效果。
-
选项 B:保留这个完整的、超长的字符串作为一个块,并记录一条信息告知用户。
很明显,这里它选择了 B 选项。因此,我们看到了 Created a chunk of size 128, which is longer than the specified 100 这条日志信息。
如何应对和处理?适当增大 chunk_size:如果我们的大部分块都超长,可能是 chunk_size 设置得太小了。尝试适当增大它。
因此,根据打印的日志,可以发现,被拆分的文本大都徘徊在 100~200 之间,因此,可以将 chunk_size 设置为 200:
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=200,
chunk_overlap=20,
length_function=len,
is_separator_regex=False,
)
运行后,可以看到超出的分割已经很少了。
基于 Token 长度拆分
之前我们讲过,LLM 大模型实际上并不是直接接收字符串,而是需要先做 token 切分编码。这里我们可以借助 tiktoken 分词器 来进行 token 的切分编码。
先看个例子:给定一个文本字符串 "my name is LiHua!",使用 tiktoken 分词器进行切分编码,会得到什么结果:
import tiktoken # 导入 tiktoken 库,这是 OpenAI 开发的高效分词库,用于将文本切分成 token
# 定于cl100k_base编码方式的分词器
# cl100k_base 是 OpenAI 使用的一种分词编码方案(适用于 GPT-4、GPT-3.5-turbo 等模型)
# 这个编码方式可以将文本切分成模型能理解的 token 单元
enc = tiktoken.get_encoding("cl100k_base")
# 进行切分编码
# encode() 方法将输入的字符串文本转换成 token 列表(每个 token 是一个整数 ID)
# token 是模型处理文本的最小单位,可以是单词、子词、标点符号、空格等
# 例如:"my name is LiHua!" 会被拆分成多个 token
enc_output = enc.encode("my name is LiHua!")
# 打印结果
print(f"编码后的token: {str(enc_output)}")
# 遍历每个 token ID,将其解码回原始的文本形式
for token in enc_output:
# decode_single_token_bytes() 方法将单个 token ID 解码成字节串(bytes 类型)
# 因为某些 token(如非英文字符)可能需要特殊编码,所以返回的是字节串
# str() 将字节串转换为可读的字符串表示(会显示 b'xxx' 的形式)
# 例如:b'my' 表示字节串形式的 "my"
print(f"将token: {str(token)} 变成文本: {str(enc.decode_single_token_bytes(token))}")解释:cl100k_base 是 tiktoken 分词器中的一种编码方式。gpt-4、gpt-3.5-turbo 等都采用这种切分编码方式。
可以看到采用切分编码 cl100k_base,拆解后的文本字符串为 ["my", "name", "is", " Li", "H", "ua", "!"]。token 编码表示为 [2465, 836, 374, 14851, 39, 4381, 0]。
以上跟大家介绍了基于 Token 拆分文本的基本方式,主要就是了解设定了某种编码格式的 tiktoken 分词器可以进行文本拆分。那么接下来,我们就可以使用根据 cl100k_base 编码方式的 tiktoken 分词器来拆分文档。这对于 OpenAI 模型来说,会更准确。
在 LangChain 中,我们可以使用 CharacterTextSplitter 分割器的 .from_tiktoken_encoder() 方法来定义根据 tiktoken 分词器拆分文本的分割器,代码如下所示:
# 1. 导入必要的库
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
# 2. 定义文件路径
# ".." 表示上级目录,所以实际路径是:上一级目录/Docs/Markdown/文件名
markdown_path = "../Docs/Markdown/脚手架级微服务租房平台Q&A.md"
# 3. 加载文档
# UnstructuredMarkdownLoader 专门用于加载 Markdown 文件
# 它会保留 Markdown 的格式信息(如标题层级、列表结构等)
loader = UnstructuredMarkdownLoader(markdown_path)
# load() 方法执行实际的加载操作
# 返回一个列表,每个元素是一个 Document 对象
data = loader.load()
# 此时 data 是一个列表,通常包含 1 个 Document(整个文件的内容)
# Document 结构示例:
# Document(
# page_content="文件的所有文本内容...",
# metadata={"source": "../Docs/Markdown/xxx.md", "last_modified": "..."}
# )
# 4. 配置文本分割器
# from_tiktoken_encoder: 使用 OpenAI 的 tiktoken 库作为分词器
# 为什么要用 tiktoken?
# - 可以准确计算 token 数量(与 OpenAI API 保持一致)
# - 按 token 分割而不是按字符,更符合大语言模型的处理方式
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", # 分词编码:cl100k_base 对应 GPT-4/GPT-3.5-turbo
chunk_size=200, # 每个块最多 200 个 token(约 150 个中文字符)
chunk_overlap=50 # 相邻块重叠 50 个 token,保持上下文连贯
)
# 分割器的工作流程:
# 1. 先按 token 计算,找到合适的分割点
# 2. 尽量在自然边界(段落结束、句子结束)处分割
# 3. 确保每个块不超过 chunk_size
# 4. 块之间保持 chunk_overlap 的重叠
# 5. 执行分割
# split_documents() 接收 Document 列表,输出分割后的 Document 列表
texts = text_splitter.split_documents(data)
# 分割后的每个 Document 包含:
# - page_content: 该块的实际文本内容
# - metadata: 继承了原始文档的元数据,可能还会添加额外的位置信息
# 6. 查看分割结果
# 遍历前 10 个分割后的文档块
for document in texts[:10]:
print("*" * 30) # 打印分隔线,便于区分不同的块
print(f"{document}\n") # 打印文档块对象
# Document 对象的 __str__ 方法会显示格式化的内容结果如下:
Created a chunk of size 916, which is longer than the specified 200
Created a chunk of size 916, which is longer than the specified 200
Created a chunk of size 260, which is longer than the specified 200
******************************
page_content='通用问题
为什么做这个项目?
回答1:(出于兴趣爱好开发)
大学期间,我和同学在外合租过一段时间,使用了一些租房平台,于是我有个想法,自己能不能开发一个租房平台,可以让我将理论知识与实践相结合。我希望通过实际项目来加深对 Java 编程语言和相关技术的理解。于是我便查找了一些资料,看了一些开源项目,进行了一些改进。
回答2:(开源项目的解释)' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='回答2:(开源项目的解释)
这个项目其实是在 github 上找到的一个开源项目,主要是可以支持一些常规的聊天项目,我对于聊天如何实现的比较感兴趣。顺便也想锻炼一下自己工程代码能力,在网上就找到了这个开源项目和项目的一些比较完善的文档和介绍,再加上找了一个业务场景:租房。所以就确定了这个项目。
回答3:(学校课设的解释)' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='回答3:(学校课设的解释)
这是学校的课设题目,然后在课设项目的基础上,查找了一些资料,进行了一些改进。
这个项目为啥和上个(之前)同学的项目一样?
回答1:(开源项目的回答)' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='回答1:(开源项目的回答)
因为这个项目本身就是开源项目,网上一搜都是好多都是这个项目的博客分析,写得优质的主要就是那几篇,可能我们参考了一样的博客讲解梳理框架吧。抽奖系统虽然听起来简单,但实际上涉及到数据存储、状态转换、异常处理等多个技术点。
回答2:(学校课设的回答)' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='回答2:(学校课设的回答)
这个问题面试官可能会直接的指出:上个同学和你学校不同,但是跟你的项目完全一样。
这个项目确实是我们学校的开源项目,但是我在实现的时候也在网上找了跟课设要求类似的开源项目,而且我发现网上针对这个类型的项目文档还完善的。可能其他的同学也是在网上跟我一样找到了类似的而仓库或开源项目进行借鉴的吧。' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='(注:以下内容不需要同学自己思考项目的扩展,如不清楚,不建议参考话术,容易给自己挖坑。说到上面的内容就可以了。不要使用课上讲解的扩展,大家都懂一样的也不行)' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='但这个项目除了常规流程,我还进行了(功能扩展/性能优化/代码优化)……(并解释一下扩展点)' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='诚实面对: 如果确实使用了代码而没有适当的引用或修改,那么诚实地承认这一点,可以说我是从github上找到的开源项目,并解释你当时的想法和决策过程(参考答案举例)。同时,如果抄袭代码是面试的大忌,要及时说明你已经了解到了这个问题,并在未来的工作中会更加注意。
展示学习过程: 如果是面试官发现项目确实有抄袭现象,也可以说项目原本的一些问题,你进行了优化、改进。体现自己是有思考和发展的,也可以说:“这个项目原本是…,我在它的基础上,进行了…的优化/改进。”' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='请求反馈: 询问面试官对你的项目有什么具体的反馈或建议,这表明你愿意学习和改进。
介绍一下这个项目。
回答一:(精简版)' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='回答一:(精简版)
基于脚手架的微服务在线租房系统,业务模型对标了贝壳、安居客、闲鱼等流行应用。无论是交互体验、架构设计,还是数据模拟都达到真实的工业水准设计。' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='本项目是一个 Java 综合项目,涵盖【前端】与【后端】开发,业务上包含房客管理、租户和房东沟通、房源上下架等整套业务流程。核心技术包括微服务、分布式集群、高并发、分布式对象存储、高速缓存、消息队列、即时通信、用户权限方案设计。' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='后端采用 Spring Cloud 微服务架构,引入脚手架,将系统拆分为五个微服务。服务间借助 OpenFeign 实现相互调用。同时,项目集成了 Nginx、Nacos、MySQL 等 10 多个主流 Java 后端组件,技术栈丰富且前沿。' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='前端包含 Web 管理端和 微信小程序端,基于 Vue 3 框架,使用 Vite 构建工具,以 JavaScript 为主要语言,利用 Axios 作为高交互数据应用引入。Element-Plus 组件库,让系统界面既实用又美观。C 端使用了微信小程序作为面向移动端应用入口。' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
同样,为了保持语义的完整性,文本分割器无法将一段文本分割到你的目标大小 chunk_size 以下,它会选择保留整个文本块。
其实文档拆分时所谓的“保持语义完整性”,原理并不是让程序真正“理解”语义,而是通过一系列启发式规则(Heuristic Rules)来猜测语义边界。具体来说,拆分器会优先在段落标记(如 \n\n)、句子结束符(如句号、感叹号、问号)、自然语言分隔符(如逗号、分号)等位置进行切割,因为这些位置在人类书写习惯中通常对应一个相对完整的意思单元。同时,通过设置重叠窗口(Chunk Overlap),让相邻块共享部分内容,从而缓解因硬性切断导致的信息丢失。这套方法依赖于文本的结构特征而非真正的语义理解,只是在工程实践中能很好地近似保持语义的连贯性。
硬性约束长度拆分
如果我们就想要求任何块都不能超过指定大小,可以使用 RecursiveCharacterTextSplitter 类或 RecursiveCharacterTextSplitter.from_tiktoken_encoder 方法,它会严格遵守对块大小的硬约束。下面展示一下用法:
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
markdown_path = "../Docs/Markdown/脚手架级微服务租房平台Q&A.md"
# single 模式加载后,默认只有一个 Document 对象
loader = UnstructuredMarkdownLoader(markdown_path)
data = loader.load()
# 生成分割器
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=100,
chunk_overlap=0,
)
# 分割文档
texts = text_splitter.split_documents(data)
# 打印前10个被分割出来的文档
for document in texts[:10]:
print("*" * 30)
print(f"{document}\n")
结果如下,严格不超出指定块大小:
******************************
page_content='通用问题
为什么做这个项目?
回答1:(出于兴趣爱好开发)' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='大学期间,我和同学在外合租过一段时间,使用了一些租房平台,于是我有个想法,自己能不能开发一个租房平台,可以让我将理论知识与实践相结合。我希望通过实际项目来加深对Java' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='编程语言和相关技术的理解。于是我便查找了一些资料,看了一些开源项目,进行了一些改进。' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='回答2:(开源项目的解释)' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='这个项目其实是在 github' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='上找到的一个开源项目,主要是可以支持一些常规的聊天项目,我对于聊天如何实现的比较感兴趣。顺便也想锻炼一下自己工程代码能力,在网上就找到了这个开源项目和项目的一些比较完善的' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='文档和介绍,再加上找了一个业务场景:租房。所以就确定了这个项目。' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='回答3:(学校课设的解释)' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='这是学校的课设题目,然后在课设项目的基础上,查找了一些资料,进行了一些改进。
这个项目为啥和上个(之前)同学的项目一样?
回答1:(开源项目的回答)' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='因为这个项目本身就是开源项目,网上一搜都是好多都是这个项目的博客分析,写得优质的主要就是那几篇,可能我们参考了一样的博客讲解梳理框架吧。抽奖系统虽然听起来简单,但实' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
******************************
page_content='际上涉及到数据存储、状态转换、异常处理等多个技术点。' metadata={'source': '../Docs/Markdown/脚手架级微服务租房平台Q&A.md'}
但这样,其实是剥夺了一些保证语义完整性的能力,可以看到某些含义相似的内容,被强制分开。
除此之外,还要再说明的是,文本内容是中文时,使用默认分隔符列表 ["\n\n", "\n", " ", ""] 拆分文本可能会导致一个词组被拆分成两个字,导致语义失效。若要将词组放在一起,可以覆盖分隔符列表以包含其他标点符号,例如中文的逗号 ,、句号 。 或其他中文符号,如下所示:
text_splitter = RecursiveCharacterTextSplitter(
separators=[
"\n\n",
"\n",
" ",
"。",
",",
"",
],
# Existing args
)
这样在分割时将递归用 separators 来尝试分割文本:
- 首先,它尝试用
\n\n(双换行,通常代表段落)来分割,如果分割后的任何一个段落仍然大于chunk_size,它会继续下一步。 - 接着,它尝试用
\n(单换行,通常代表行之间)来分割那些仍然过大的段落。 - 然后,它尝试用 (空格,单词之间)来分割。
- ...
特殊文档结构拆分
若对于代码等特殊文本,可以尝试使用 Language 提供的不同的分割器(如 PythonCodeTextSplitter、HTMLHeaderTextSplitter 等)效果会更好,它会理解代码的语法结构。
这里了解下常见的拆分原则即可:
- Markdown:根据标头拆分(例如,
#、##、###) - HTML:使用标签拆分
- JSON:按对象或数组元素拆分
- Code 代码:按函数、类或逻辑块拆分
这里我们以 Python 代码举例,其他的使用姿势可以参考官网接口,实际上用法与我们上面讲解的类似。
from langchain_text_splitters import PythonCodeTextSplitter
# 字符串文档
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
def hello_python():
print("Hello, Python!")
"""
python_splitter = PythonCodeTextSplitter(chunk_size=50, chunk_overlap=0)
python_docs = python_splitter.create_documents([PYTHON_CODE])
for document in python_docs[:2]:
print("*" * 30)
print(f"{document}\n")
结果如下:
******************************
page_content='def hello_world():\n print("Hello, World!")'
******************************
page_content='def hello_python():\n print("Hello, Python!")'

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)