论文解读:Mem0用7K token干翻26K全量上下文
1. AI的"金鱼记忆"困局
你有没有这样的体验——跟一个AI助手聊了三天,第四天它问你:"请问你有什么饮食偏好?"
你明明上周就告诉过它你是素食主义者、不吃乳制品。但它忘了。彻底忘了。
这不是个例,这是当前所有大模型的结构性缺陷。GPT-4有128K上下文窗口,Claude 3.7有200K,Gemini甚至号称支持10M token。但这些数字再大,本质上都是"短期记忆"——对话一旦超出窗口,信息就像从悬崖边掉下去一样,消失得干干净净。
更致命的是,即便上下文窗口足够大,注意力机制对远距离token的关注度也会急剧衰减。你上周提到的素食偏好,被埋在几千条编程讨论的token里,模型根本"看不见"。

图1
图1:左侧是没有持久记忆的AI——用户上次明确说了"我是素食者、不吃乳制品",下次问晚餐建议时系统却推荐了鸡肉。右侧是有记忆的AI——跨会话保持了饮食偏好,给出了素食且无乳制品的推荐。一个日常场景,暴露的是架构级缺陷。
这不是工程优化能解决的问题。这是架构本身的限制。
2. 为什么"加长上下文"是条死路
过去两年,行业的主流思路是"把上下文窗口做大"。从4K到128K到1M到10M——似乎只要窗口够大,记忆问题就自然解决了。
但这条路有两个致命缺陷。
第一,真实的人机关系是以周、月为单位发展的。一个用户和AI助手的对话历史,几个月下来轻松超过任何上下文限制。窗口再大,也只是"延迟"了遗忘,而非"解决"了遗忘。
第二,也是更关键的——真实对话几乎不存在"主题连续性"。用户今天聊饮食偏好,明天讨论代码bug,后天问旅行建议。当你需要回忆饮食偏好时,那条关键信息被埋在几万token的编程讨论里。全量塞进上下文?模型要在一堆无关信息中大海捞针,延迟爆炸、成本飙升,效果还不一定好。
在这样的背景下,Mem0团队提出了一个完全不同的思路——不是让模型"看到"所有历史,而是让模型像人一样"记住"关键信息。
研究团队由Prateek Chhikara、Dev Khant、Saket Aryan、Taranjeet Singh和Deshraj Yadav组成,来自Mem0.ai。Prateek Chhikara此前在知识增强智能体领域有深入积累(2023年发表于Knowledge Capture Conference),这支团队的核心定位是:把记忆从"学术概念"变成"生产级基础设施"。
3. Mem0的核心设计哲学:提取-整合-检索
Mem0的核心思想非常简单——不要存储对话原文,而是从对话中"提炼"出关键事实,像人类大脑一样进行选择性记忆。
这就像你和朋友聊了两小时天,事后你不会逐字记住每句话,但你会记住"他下个月要去日本""他最近换了工作""他对花生过敏"这些关键信息。Mem0做的就是这件事——把冗长的对话历史压缩成精炼的"记忆条目"。
整个系统分为两个阶段:提取(Extraction)和更新(Update)。
提取阶段:当一对新消息(用户消息 + 助手回复)进入系统时,Mem0不是简单地存储原文,而是结合两个上下文源来理解这对消息的含义——一个是整段对话的摘要S(提供全局语义理解),另一个是最近m条消息(提供细粒度时间上下文)。两者结合,形成一个完整的提示P = (S, {最近消息}, 当前消息对),送入LLM进行"记忆提取"。
翻译成人话——Mem0既看"大局"(整段对话在聊什么),又看"细节"(最近几轮说了什么),然后从当前这轮对话中提炼出值得记住的事实。
更新阶段:提取出的候选事实不是直接塞进数据库,而是要和已有记忆进行"对账"。系统用向量嵌入找到语义最相似的已有记忆,然后让LLM判断应该执行哪种操作:ADD(新增)、UPDATE(更新)、DELETE(删除矛盾信息)、NOOP(无需操作)。
这意味着什么?意味着Mem0的记忆库是"活的"——它会自我修正、自我更新、自我去重。用户说"我搬到了上海",系统会自动把之前"住在北京"的记忆标记为过时。这不是简单的追加存储,而是知识库级别的动态维护。
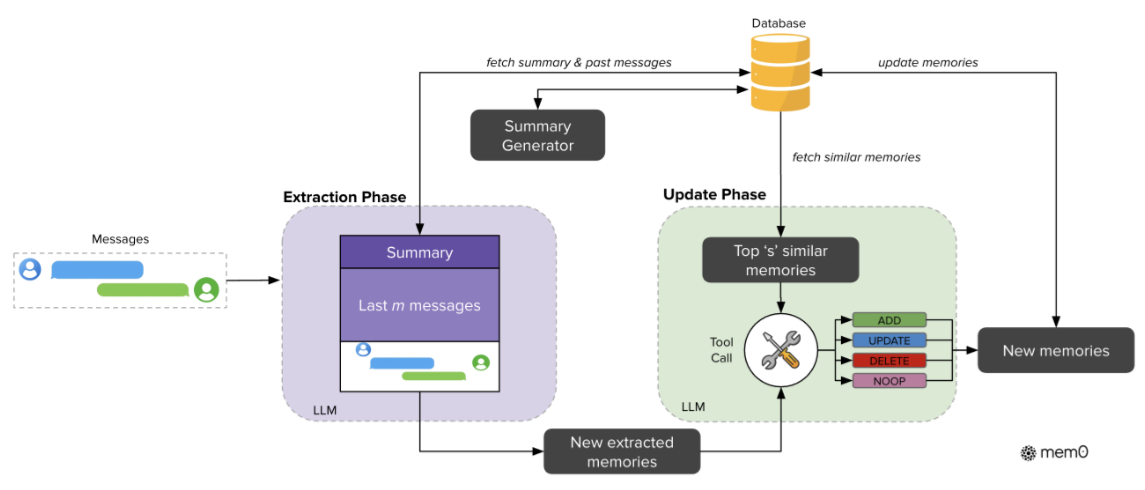
图2
图2:Mem0系统架构全景——左侧为提取阶段(从消息对+历史摘要+近期消息中提炼候选事实),右侧为更新阶段(通过Tool Call机制对已有记忆执行ADD/UPDATE/DELETE/NOOP四种操作)。数据库居中,既为提取提供上下文,又存储更新后的记忆。整个流程的精髓在于:提取不是"存原文",更新不是"追加",而是一套完整的知识管理逻辑。
4. 图记忆变体Mem0g:当事实有了"关系网"
基础版Mem0把记忆存储为自然语言文本——简洁高效,但有一个局限:它无法显式建模实体之间的关系。
这个局限在什么场景下会暴露?看一个具体的例子。
举个例子:如果用户说"Alice住在旧金山",又说"Alice在Google工作",基础版Mem0会存储两条独立的记忆。但当你问"住在旧金山的那个在Google工作的人是谁"时,系统需要跨记忆条目进行推理——这对纯文本检索来说并不容易。
Mem0g(graph memory版本)的解决方案是:把记忆组织成有向标记图G = (V, E, L)。节点V代表实体(如Alice、San_Francisco),边E代表关系(如lives_in),标签L给节点分类(如Person、City)。
提取过程分两步:先用LLM从文本中抽取实体及其类型,再用关系生成器推导实体间的语义连接。比如从"Alice住在旧金山"中,系统会抽取出三元组(Alice, lives_in, San_Francisco)。
更精妙的是冲突检测机制。当新信息与已有图结构矛盾时(比如"Alice搬到了纽约"),系统不是物理删除旧关系,而是将其标记为"无效"——这样既保留了时间线上的历史信息,又确保了当前查询的准确性。
检索时,Mem0g采用双路策略:一条路是"实体中心"——先识别查询中的关键实体,找到图中对应节点,然后沿着关系边探索相关子图;另一条路是"语义三元组"——把整个查询编码为向量,与图中所有三元组进行相似度匹配。两条路互补,既能处理精确的实体查询,也能应对模糊的概念性问题。
底层实现上,图数据库用的是Neo4j,LLM推理引擎用的是GPT-4o-mini。
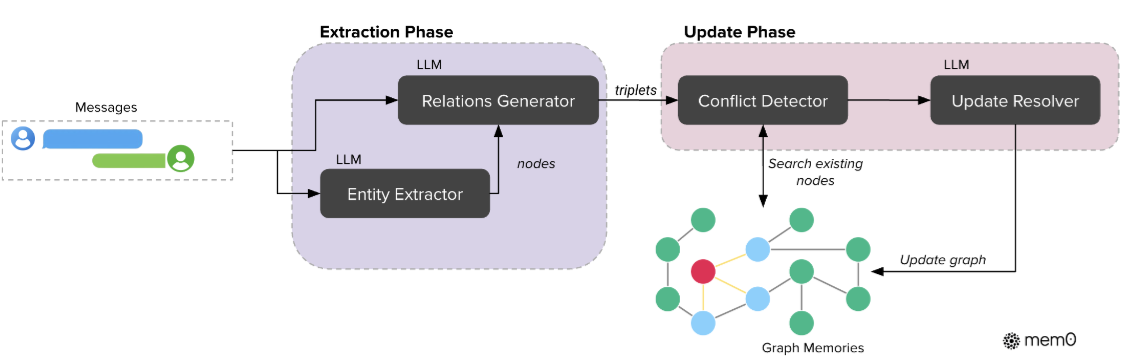
图3
图3:Mem0g的图记忆架构——展示了从对话消息到实体三元组的提取过程,以及新信息与已有知识图谱整合时的冲突检测与解决机制。注意右侧的"conflict detection"模块,这是保证图一致性的关键。
5. 实验设计:LOCOMO基准的全面对决
评测使用的是LOCOMO数据集——专门为长期对话记忆设计的基准。它包含10段长对话,每段约600轮对话、26000 token,跨越多个会话。每段对话配有约200个问题,分为四类:
-
单跳问题(Single-hop):答案在单轮对话中就能找到
-
多跳问题(Multi-hop):需要综合多个会话的信息
-
时序问题(Temporal):涉及事件的时间顺序和持续时间
-
开放域问题(Open-domain):需要结合对话记忆和外部知识
对比的基线覆盖了六大类:已有记忆增强系统(LoCoMo、ReadAgent、MemoryBank、MemGPT、A-Mem)、开源记忆方案(LangMem)、RAG方案(不同chunk size和k值的组合)、全量上下文方案、商业模型(OpenAI ChatGPT记忆功能)、以及专业记忆平台(Zep)。
评测指标方面,除了传统的F1和BLEU-1,团队特别引入了LLM-as-a-Judge(J)——用一个独立的LLM来判断生成答案是否正确。为什么?因为传统词汇重叠指标有严重缺陷:如果正确答案是"Alice三月出生",而系统回答"Alice七月出生",F1分数依然很高(因为"Alice""出生"这些词都匹配上了),但事实完全错误。J指标能捕捉到这种语义层面的对错。
6. 实验结果:全面碾压,但各有所长
一句话概括:Mem0和Mem0g在绝大多数任务上刷新了SOTA,且两者各有擅长的领域。
单跳问题:Mem0以J=67.13领跑,比OpenAI的63.79高出约5%。图记忆版Mem0g(65.71)略低于基础版——这说明对于"答案就在一个地方"的简单检索,自然语言记忆的效率反而更高,图结构的额外开销没有带来收益。
多跳问题:Mem0的J=51.15,大幅领先第二名LangMem的47.92。多跳推理需要跨会话整合信息,Mem0的精炼记忆索引在这里展现了明显优势。有趣的是,Mem0g(47.19)在这个任务上反而不如基础版——图结构在多步推理中可能引入了冗余路径。
时序推理:这是Mem0g的主场。J=58.13,显著超过基础版Mem0的55.51。图结构对时间关系的显式建模在这里发挥了关键作用。值得注意的是,OpenAI的记忆功能在时序任务上惨败(J=21.71),原因是它生成的记忆条目大多丢失了时间戳信息——尽管提示词中明确要求保留时间信息(这说明"提示词工程"在关键场景下的脆弱性)。
开放域:Zep以J=76.60小幅领先Mem0g的75.71和Mem0的72.93。这是唯一一个Mem0未能登顶的类别,但差距极小。
把这些数字放在一起看,格局就很清晰了。
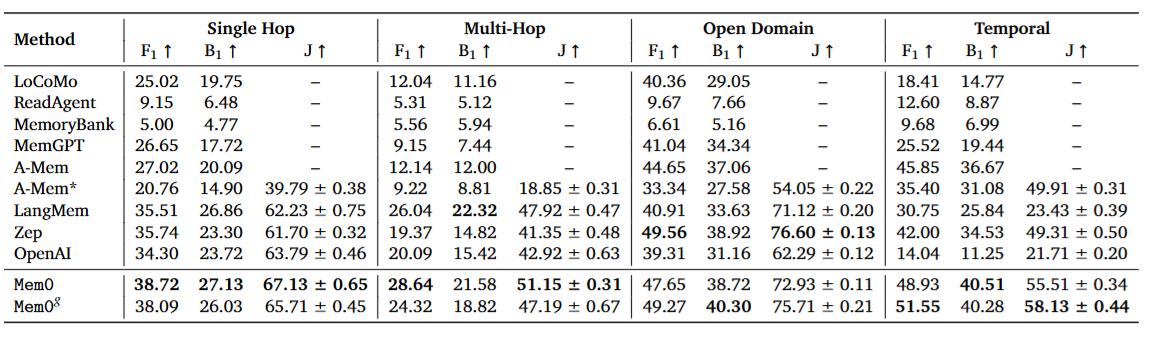
表1
表1:各方法在LOCOMO四类问题上的LLM-as-a-Judge得分对比。Mem0在单跳和多跳上领跑,Mem0g在时序推理上登顶,Zep仅在开放域保持微弱优势。注意OpenAI在时序任务上的断崖式下跌(J=21.71)——时间戳丢失是致命伤。
7. 延迟与成本:生产级部署的真正门槛
性能好只是故事的一半。对于生产环境来说,延迟和成本才是决定能否上线的关键。
全量上下文方案虽然J分数最高(72.90),但p95延迟高达17.1秒——每个查询都要处理26000 token的完整对话历史。这在实时交互场景中完全不可接受。
Mem0的搜索延迟是所有方案中最低的:p50仅0.148秒,p95仅0.200秒。总延迟p95为1.44秒——比全量上下文方案降低了91%。
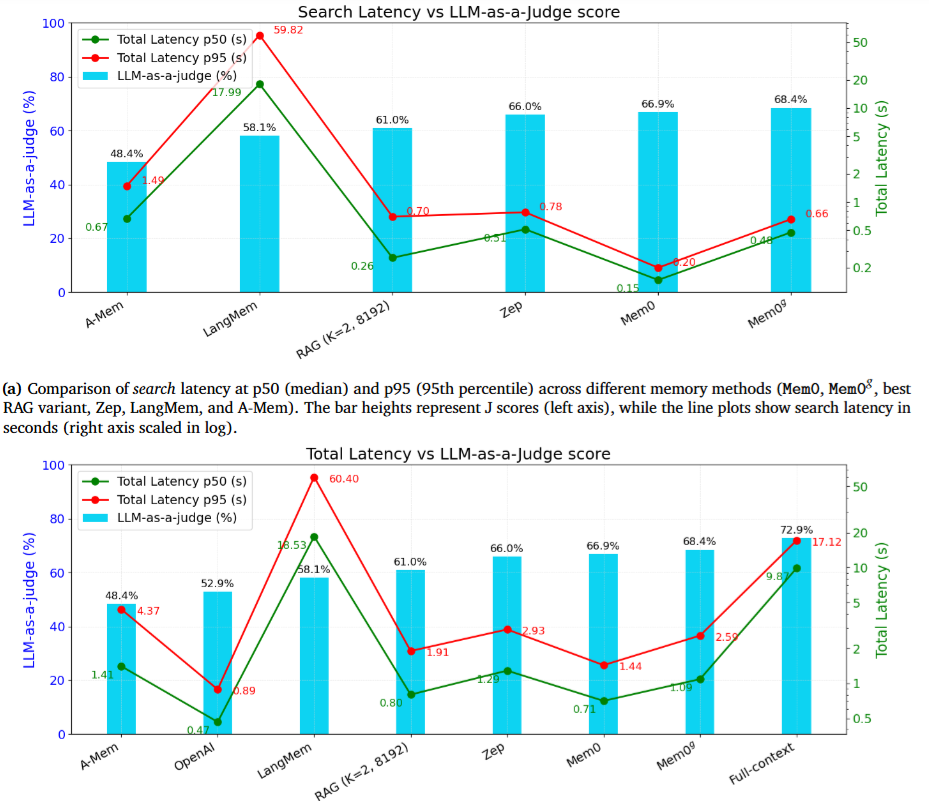
图4
图4:各方法的J分数(柱状图)与延迟(折线图)对比。左图为搜索延迟,右图为总响应延迟。Mem0在两张图中都处于"高分数+低延迟"的最优象限——这正是生产部署最渴望的位置。
Mem0g因为需要额外的图检索,延迟略高(总p95为2.59秒),但仍然远优于全量上下文方案,且获得了所有方案中最高的J分数(68.44%)。
再看token消耗:Mem0平均每段对话只需要约7K token的记忆存储,Mem0g约14K token。而Zep的记忆图?超过600K token——因为它在每个节点都缓存了完整的抽象摘要,导致大量冗余。作为对比,原始对话本身也才26K token。Zep的记忆比原始数据还大23倍,这显然不是一个可持续的设计。
更关键的是,Zep的记忆构建存在严重的异步延迟问题——添加记忆后立即检索往往失败,需要等待数小时才能正常工作。而Mem0的图构建在最坏情况下也能在一分钟内完成。
这说明什么?说明Mem0不只是一个学术原型,而是一个真正面向生产环境设计的系统。
8. 在记忆版图中的定位
把Mem0放在更大的AI记忆研究版图中,可以看到三条主要路线:
路线一:上下文扩展派。代表是GPT-4的128K、Gemini的10M。优势是简单直接,不需要额外架构。但问题也很明显——延迟和成本随对话长度线性增长,且注意力衰减导致远距离信息检索效果差。
路线二:RAG派。把对话历史当文档切块,查询时检索相关片段。优势是成本可控。但缺陷也非常致命——chunk边界可能切断关键信息,且原始文本中包含大量噪声,检索精度有限。实验中最好的RAG配置(256 token chunk, k=2)J分数也只有60.97%。
路线三:操作系统派。代表是MemGPT,把记忆管理类比为操作系统的内存管理。思路很优雅,但实际效果有限——在LOCOMO上的表现远不如预期。
换句话说,扩展派太贵,RAG派太粗,OS派太理想化。三条路都没有真正触及"如何像人一样选择性记忆"这个核心问题。
Mem0的定位正是在这三者之间找到一个新的平衡点:像人类一样从对话中提炼关键事实,用结构化方式组织和更新,在需要时精准检索——同时保持生产级的延迟和成本。
9. 总结与展望
Mem0展示的不是一个"更好的RAG",而是一种全新的AI记忆范式——从"存储原文"到"提炼记忆",从"被动检索"到"主动维护",从"学术原型"到"生产就绪"。
它让AI智能体从"每次对话都是第一次见面"迈向"真正认识你、记住你、理解你"。
未来的演化方向至少有三个:一是优化Mem0g的图操作延迟,让关系推理更快;二是探索层次化记忆架构,在效率和关系表达之间找到更优解;三是将记忆框架扩展到对话之外——程序推理、多模态交互、具身智能,都需要持久化的记忆能力。
如果说过去的AI是"聪明但健忘的陌生人",Mem0展示的是"有记忆的长期伙伴"的第一块基石。
参考资料:https://arxiv.org/pdf/2504.19413

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)