深入浅出 YOLOv5:从核心原理到实战部署全攻略
在计算机视觉领域,目标检测作为核心技术之一,广泛应用于安防监控、自动驾驶、工业质检、智能家居等场景。从早期的 R-CNN 系列两阶段算法,到 YOLO 系列单阶段实时检测算法,目标检测技术在速度与精度的平衡上不断突破。YOLO(You Only Look Once)系列凭借端到端、高实时性的优势,成为工业界最常用的目标检测框架。
继 YOLOv1-v4 之后,YOLOv5 于 2020 年由 Ultralytics 团队发布,它并非严格意义上的全新算法创新,而是融合前沿技术的工程化优化产物,兼顾了精度、速度、易用性与部署灵活性。本文将结合 YOLO 系列核心思想,深度拆解 YOLOv5 的网络结构、算法原理,并基于 GitHub 开源代码,详细讲解 YOLOv5 的环境配置、数据准备、模型训练、推理测试与部署全流程,帮助开发者快速掌握 YOLOv5 的实战应用。
一、YOLO 系列基础回顾:单阶段检测的核心逻辑
在深入 YOLOv5 之前,需先理清 YOLO 系列的核心脉络,理解单阶段目标检测的本质。
1.1 两阶段 vs 单阶段目标检测
目标检测算法分为 ** 两阶段(Two-stage)和单阶段(One-stage)** 两大类:
- 两阶段算法:以 Faster R-CNN、Mask R-CNN 为代表,先通过 RPN 网络生成候选框,再对候选框进行分类与回归,精度高但速度慢,通常仅 5FPS 左右,难以满足实时需求。
- 单阶段算法:以 YOLO 系列、SSD 为代表,直接将检测任务转化为回归问题,通过单个神经网络同时输出目标类别与位置,速度极快,适合实时检测场景。
YOLO 系列的核心创新:将输入图像划分为 S×S 网格,每个网格负责预测中心落在该网格内的目标,一次性完成分类与定位,实现 "只看一次" 的实时检测。
1.2 YOLOv1-v4 演进关键节点
- YOLOv1:奠定单阶段检测基础,7×7 网格输出,速度快但小目标、重叠目标检测效果差。
- YOLOv2:引入 BatchNorm、先验框聚类、多尺度训练,移除全连接层,提升精度与稳定性。
- YOLOv3:采用 DarkNet-53 骨干网、多尺度特征融合(3 个检测尺度)、Logistic 分类器,支持多标签检测,小目标检测能力大幅提升。
- YOLOv4:融合 CSPDarkNet、SPP、PAN、Mish 激活函数、CIoU 损失、马赛克数据增强等技术,实现精度与速度的最优平衡。
YOLOv5:在 YOLOv4 基础上做工程化精简与优化,代码可读性极强、支持一键训练、多设备部署,成为工业落地首选框架。
二、YOLOv5 核心原理与网络结构深度解析
YOLOv5 的核心设计理念:轻量化、高效化、易用化,整体结构分为输入端、骨干网络(Backbone)、颈部网络(Neck)、检测头(Head) 四个模块,同时优化了损失函数、非极大值抑制与数据增强策略。
2.1 YOLOv5 模型版本:按需选择的轻量化设计
YOLOv5 根据网络宽度与深度,提供 5 个版本,满足不同场景需求:
- YOLOv5n(Nano):超轻量化,适合端侧设备(手机、嵌入式)
- YOLOv5s(Small):轻量版,速度与精度均衡,常用基础版本
- YOLOv5m(Medium):中等精度,适合服务器端常规检测
- YOLOv5l(Large):高精度版本,适合对精度要求高的场景
- YOLOv5x(Xlarge):超大精度版本,算力充足时使用
所有版本结构一致,仅通过depth_multiple(深度因子)、width_multiple(宽度因子) 调整网络规模,无需重新设计结构。
2.2 输入端:数据增强与预处理优化
YOLOv5 在输入端继承并优化了 YOLOv4 的数据增强策略,提升模型泛化能力:
- 马赛克数据增强(Mosaic)将 4 张随机图像拼接为 1 张,丰富目标尺度与背景,减少 GPU 显存占用,适合小数据集训练。
- 自适应锚框计算(Auto Anchor)无需手动设置先验框,训练时自动基于数据集标注通过 K-means 聚类生成最优锚框,适配不同数据集。
- 自适应图片缩放按比例将图像缩放到指定尺寸,对不足部分填充灰色边缘,避免拉伸变形,提升推理速度。
- 标签平滑(Label Smoothing)将硬标签(0/1)转化为软标签(如 0.05/0.95),防止模型过拟合,提升泛化性。
2.3 骨干网络(Backbone):CSPDarkNet-53
YOLOv5 采用CSPDarkNet-53作为骨干网,基于 YOLOv4 的 CSP 结构优化,核心作用是提取图像特征:
- CSP 结构(Cross Stage Partial)将特征图分为两部分,一部分经过残差模块提取特征,另一部分直接拼接,减少计算量、降低内存占用、增强特征传播,解决网络加深带来的梯度消失问题。
- Focus 结构对输入图像进行切片操作,将 4×4×3 的图像转换为 2×2×12 的特征图,下采样同时保留完整特征信息,替代传统池化层,提升速度。
- CBS 模块由卷积(Conv)+ BatchNorm + SiLU 激活函数组成,作为基础特征提取单元,SiLU 激活函数比 ReLU 更平滑,提升精度。
- BottleneckCSP 模块堆叠残差结构,加深网络的同时控制计算量,提取深层语义特征。
2.4 颈部网络(Neck):SPP + PANet
颈部网络用于融合骨干网提取的多尺度特征,让不同尺度的特征信息相互补充,提升小目标、大目标检测能力:
- SPP(空间金字塔池化)通过 5×5、9×9、13×13 最大池化,将任意尺度特征图转化为固定长度特征,解决多尺度输入问题,扩大感受野,提取全局特征。
- PANet(路径聚合网络)采用自顶向下 + 自底向上双向特征融合:
- 自顶向下:传递高层语义特征(负责分类)
- 自底向上:传递底层定位特征(负责位置)相比 YOLOv3 的 FPN,PANet 增强了底层特征的传播,小目标检测精度大幅提升。
2.5 检测头(Head):多尺度检测
YOLOv5 沿用 3 尺度检测策略,对应 3 种不同感受野,适配不同大小目标:
- 13×13 尺度:大感受野,检测大目标
- 26×26 尺度:中等感受野,检测中等目标
- 52×52 尺度:小感受野,检测小目标
每个尺度输出3 个先验框,每个先验框包含位置(x,y,w,h)、置信度、类别概率,最终通过置信度过滤与 NMS 输出检测结果。
2.6 损失函数:CIoU Loss + 置信度损失 + 分类损失
YOLOv5 采用多任务损失函数,平衡位置回归、置信度、分类三个任务:
- 位置损失:CIoU Loss优化预测框与真实框的重叠面积、中心点距离、长宽比,解决 IoU、GIoU、DIoU 的缺陷,收敛更快、定位更准。
- 置信度损失:二元交叉熵预测框内是否存在目标的概率。
- 分类损失:二元交叉熵替代 Softmax,支持多标签检测(一个目标属于多个类别)。
2.7 后处理:DIOU-NMS
非极大值抑制用于过滤冗余框,YOLOv5 采用DIOU-NMS,同时考虑框的重叠度与中心点距离,避免重叠目标漏检,比传统 NMS 更精准。
三、YOLOv5 环境配置(基于 GitHub 开源代码)
本文使用 Ultralytics 团队官方开源的 YOLOv5 代码(https://github.com/ultralytics/yolov5),基于 Windows/Linux + PyTorch 框架配置环境。
模型结构如下:
3.1 环境准备
- 基础环境
- Python 3.8 及以上
- PyTorch 1.7 及以上(支持 GPU)
- CUDA 11.0 及以上(GPU 训练必备)
- 下载代码
git clone https://github.com/ultralytics/yolov5.git cd yolov5 - 安装依赖库
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
四、YOLOv5 准备数据集训练全流程
4.1 准备数据集
数据集可以自行在网上找一些免费的数据集使用,我以我找的口罩的数据集为例
4.2 启动训练
在train.py文件中修改形参,如下:
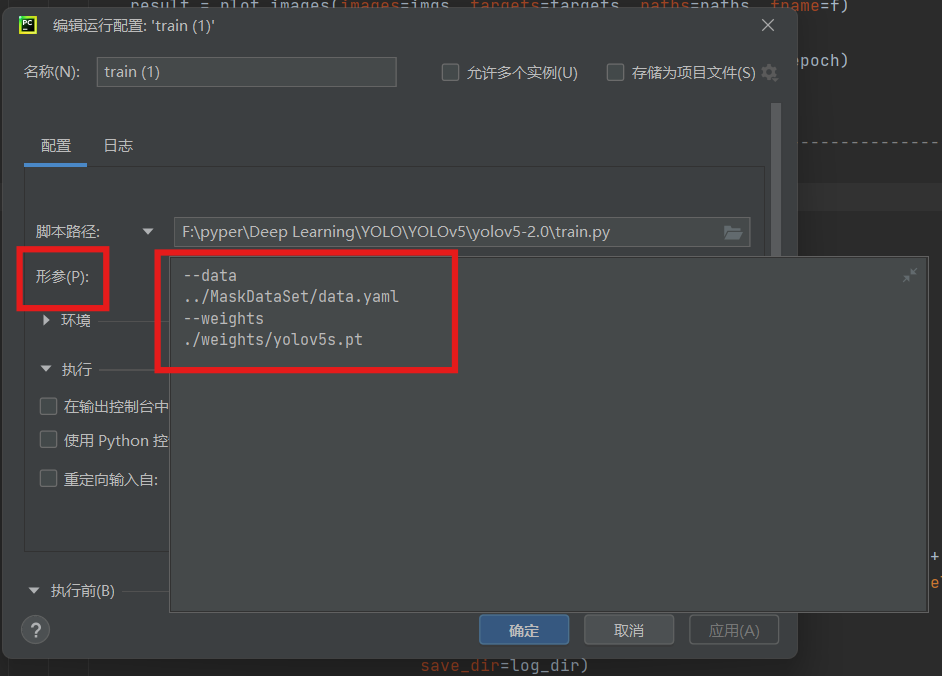
--data
../MaskDataSet/data.yaml
--weights
./weights/yolov5s.pt参数说明:
--data:数据集配置文件--weights:预训练权重(迁移学习,提升精度)
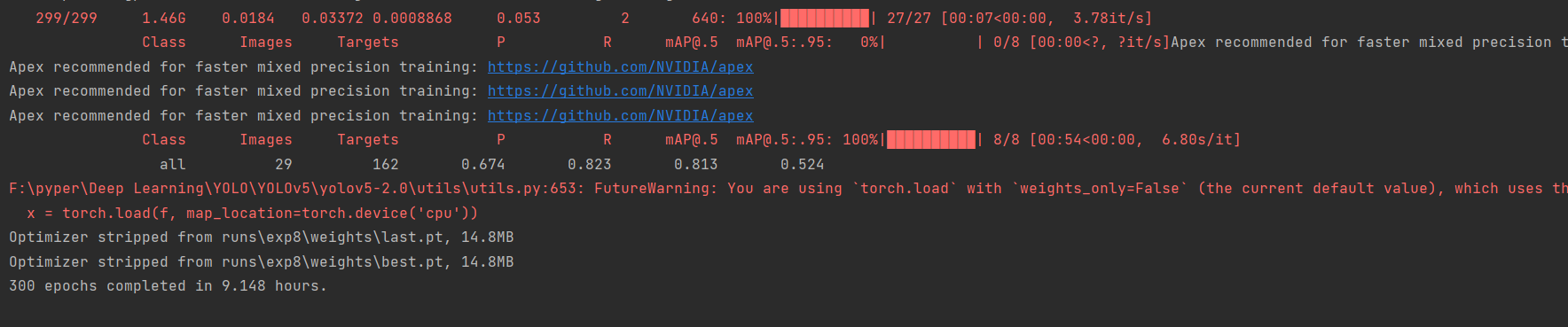
4.4 训练结果查看
五、YOLOv5 模型推理与部署
训练完成后,可对图像、视频、摄像头实时推理,并支持导出为 ONNX、TensorRT 格式部署。
在detect.py中修改形参,
5.1 单张图像 /摄像头推理
--weights ./runs/exp8/weights/best.pt --source F:\img.png 图片识别
--weights ./runs/exp8/weights/best.pt --source 0 摄像头
5.3 推理结果说明
推理结果保存在runs/detect/exp,包含:
- 带检测框的图像
- 检测结果标签(类别、置信度、坐标)

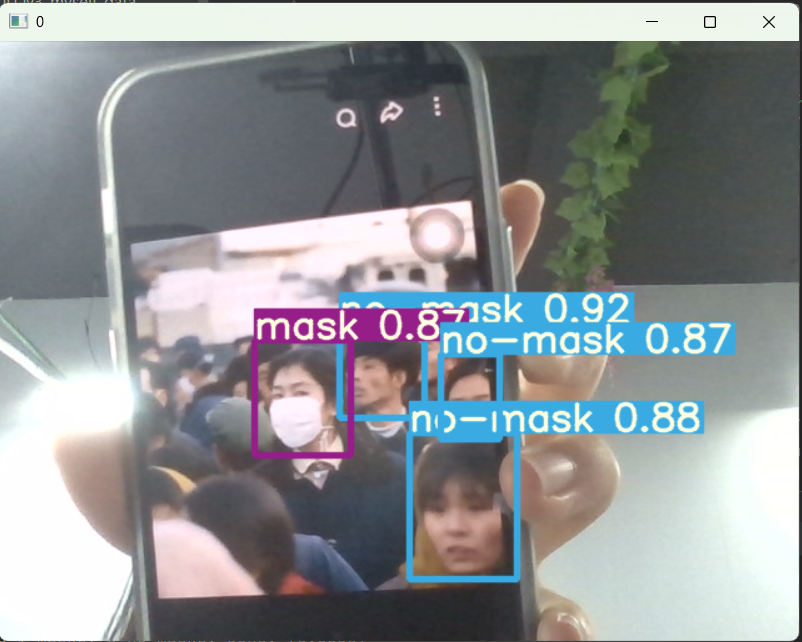
六、YOLOv5 优化技巧(工业落地必备)
- 小目标检测优化增大输入图像尺寸(如 640→1280),增加小目标标注数量,调整锚框聚类参数。
- 速度优化使用 YOLOv5n/nano 版本,开启 TensorRT 加速,降低输入图像尺寸。
- 精度优化增加训练轮数,使用马赛克增强,添加难例挖掘,调整损失函数权重。
- 部署优化量化模型(INT8),裁剪冗余层,适配端侧设备(RK3588、Jetson)。
七、总结与展望
YOLOv5 作为工程化最优的 YOLO 系列模型,完美平衡了精度、速度与易用性,继承了 YOLOv4 的核心算法创新,同时简化了代码结构、降低了使用门槛,从数据准备到模型部署全流程一键完成,是计算机视觉工业落地的首选框架。
从技术演进来看,YOLO 系列始终围绕实时性、高精度、轻量化三大核心发展,YOLOv5 之后的 YOLOv6、YOLOv7、YOLOv8 均延续了这一思路,但 YOLOv5 凭借稳定的代码生态、完善的部署支持,依然是中小企业与开发者的最优选择。
未来,目标检测将向端侧实时化、多任务融合、小样本学习方向发展,而 YOLOv5 作为基础框架,依然是学习目标检测、快速落地项目的最佳入门工具。
本文从原理到实战完整讲解了 YOLOv5,希望能帮助开发者快速掌握目标检测核心技术,落地属于自己的视觉项目。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)