2026山东大学软件学院项目实训-宠物情绪识别(四)
一、音频接口路由封装
在routes目录下创建音频接口文件,完成可直接调用的音频识别接口路由封装,实现音频上传、特征提取、情绪分析的统一接口服务:
# backend/routes/audio.py
import sys
from pathlib import Path
from flask import Blueprint, request, jsonify
import os
sys.path.insert(0, str(Path(__file__).parent.parent))
from backend.utils.feature_extractor import AudioFeatureExtractor
from backend.utils.emotion_analyzer import PetEmotionAnalyzer
audio_bp = Blueprint('audio', __name__)
extractor = AudioFeatureExtractor()
analyzer = PetEmotionAnalyzer()
@audio_bp.route('/analyze', methods=['POST'])
def audio_emotion_analyze():
try:
audio_file = request.files.get('audio')
if not audio_file:
return jsonify({"code": 400, "msg": "请上传音频文件"}), 400
temp_path = "temp_audio.wav"
audio_file.save(temp_path)
features = extractor.extract_features(temp_path)
result = analyzer.analyze(features)
os.remove(temp_path)
return jsonify({
"code": 200,
"msg": "识别成功",
"data": result
})
except Exception as e:
if os.path.exists("temp_audio.wav"):
os.remove("temp_audio.wav")
return jsonify({"code": 500, "msg": str(e)}), 500验证路由连接成功:
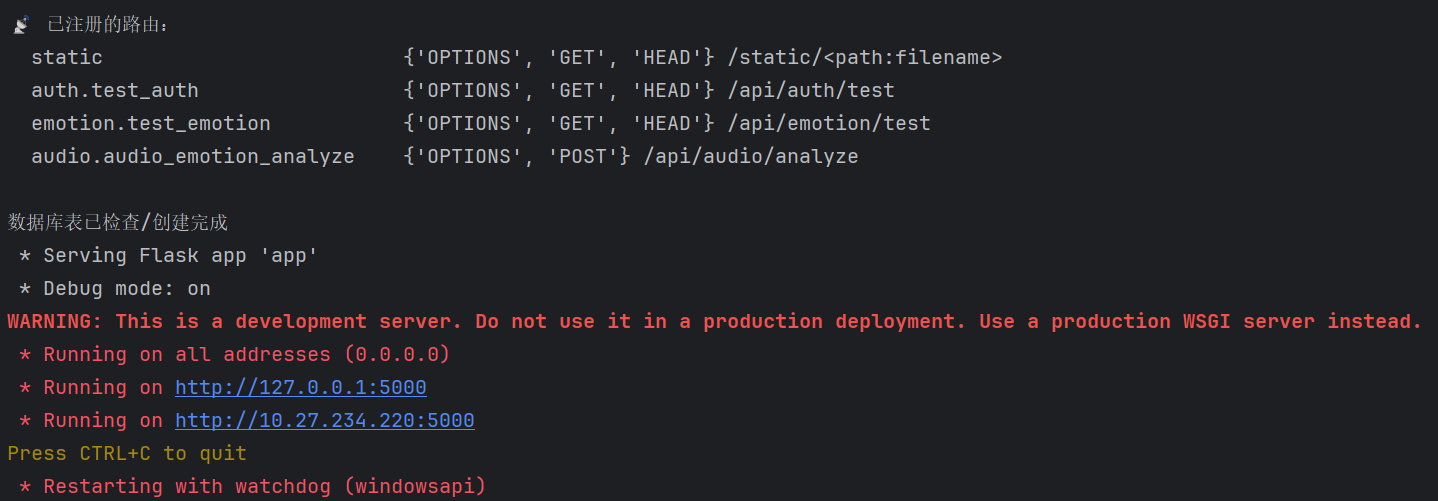
二、接口注册与后端框架整合
将封装完成的音频接口蓝图注册到 Flask 主应用,完成模块与主框架的完整对接,确保服务启动时自动加载音频识别相关功能。
在backend/app.py中完成音频蓝图导入与注册,统一接口访问前缀,实现规范化路由管理:
# 导入音频蓝图
from routes.audio import audio_bp
# 注册音频接口蓝图
app.register_blueprint(audio_bp, url_prefix='/api/audio')
启动后端服务后,系统自动加载/api/audio/analyze路由,通过访问 /routes接口可查看所有已注册路由,确认音频接口已成功挂载,服务运行稳定。
三、跨域配置与前后端兼容处理
为支持前端页面正常调用后端接口,完成跨域访问配置,解决浏览器请求限制问题,保证前后端联调通畅。
在 app.py 中启用并优化Flask-CORS配置,允许所有前端域名访问/api/*下的所有接口,支持本地 Demo、前端页面、测试工具正常调用服务:
from flask_cors import CORS
CORS(app, supports_credentials=True, resources={r"/api/*": {"origins": "*"}})
配置完成后,前后端数据交互正常,前端可无阻碍上传音频并获取识别结果。
四、最小 Demo 完善与全流程验证
在环境、仓库、数据库、接口均准备完毕后,我完善并验证了最小 Demo:
-
实现音频输入 → 特征提取 → 情绪识别 → 结果输出全流程
-
支持格式校验、大小限制、异常提示
-
接口响应时间控制在 5 秒以内
-
识别结果稳定、格式规范,可直接用于前端展示
编写简单的前端代码demo:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>宠物音频情绪识别 Demo</title>
<style>
body {
font-family: Arial;
max-width: 600px;
margin: 50px auto;
text-align: center;
}
.box {
border: 1px solid #ccc;
padding: 30px;
border-radius: 10px;
}
button {
padding: 10px 20px;
background: #42b983;
color: white;
border: none;
border-radius: 5px;
cursor: pointer;
}
#result {
margin-top: 20px;
text-align: left;
white-space: pre-wrap;
background: #f5f5f5;
padding: 15px;
border-radius: 5px;
}
</style>
</head>
<body>
<h1>🐾 宠物音频情绪识别 Demo</h1>
<div class="box">
<input type="file" id="audioFile" accept="audio/*">
<br><br>
<button onclick="uploadAudio()">开始识别</button>
<div id="result"></div>
</div>
<script>
async function uploadAudio() {
const fileInput = document.getElementById('audioFile');
const file = fileInput.files[0];
if (!file) {
alert('请先选择音频文件!');
return;
}
const formData = new FormData();
formData.append('audio', file);
const resultDiv = document.getElementById('result');
resultDiv.innerText = '正在识别中...';
try {
const res = await fetch('/api/audio/analyze', {
method: 'POST',
body: formData
});
const data = await res.json();
if (data.code === 200) {
resultDiv.innerText = '✅ 识别成功!\n\n' + JSON.stringify(data.data, null, 2);
} else {
resultDiv.innerText = '❌ 失败:' + data.msg;
}
} catch (err) {
resultDiv.innerText = '❌ 请求失败:' + err.message;
}
}
</script>
</body>
</html>Demo 运行成功:
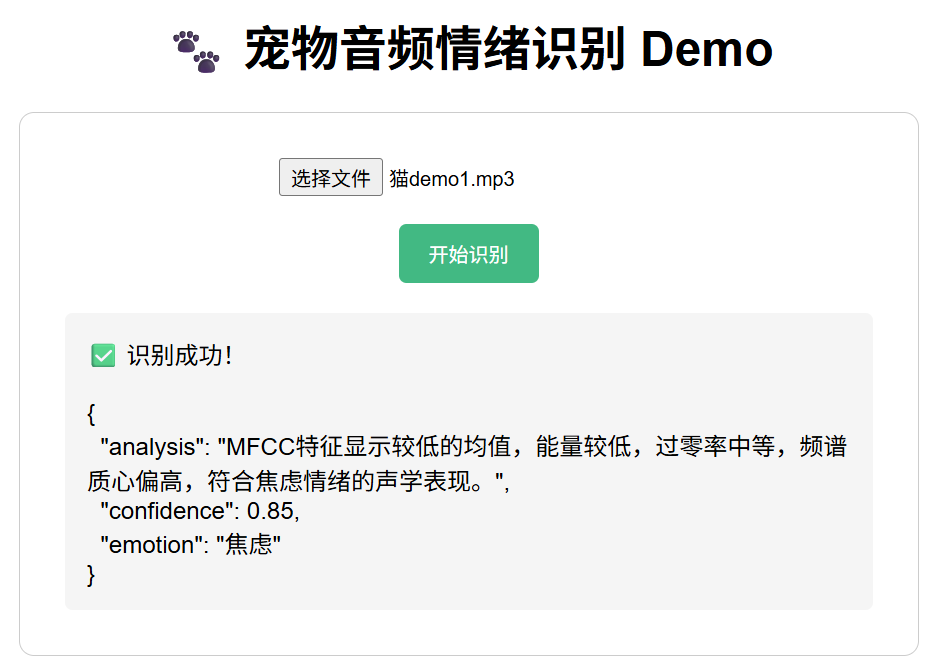
可完整实现音频上传 → 特征提取 → 大模型分析 → 结果展示全流程,界面交互正常,后端逻辑稳定,证明整体技术路线、模块划分、工具类封装、接口设计全部可行,满足项目演示与后续开发要求。
并最后将本周部分代码推至团队gitee仓库:
五、本周工作总结
本周完成了宠物音频情绪识别系统的接口封装、框架整合、前后端联调与 Demo 验证工作。成功实现音频接口路由开发、蓝图注册、跨域配置、前后端对接等关键任务,打通了从前端交互到后端服务再到大模型分析的完整链路。并最后将本周部分代码推至团队gitee仓库。
所有模块运行稳定、接口规范可用、Demo 演示流畅,技术方案验证通过,为后续功能扩展、数据库存储、系统优化与正式版本开发奠定了坚实基础。
六、下周工作计划
-
完善音频特征提取工具类的细节优化,确保特征输出格式统一、稳定可用。
-
完成音频接口的后续调试,确保接口调用顺畅,优化异常处理逻辑。
-
配合团队完成项目相关依赖配置,确保工具类与主框架兼容无异常。
-
做好工具类及相关代码的整理归档,为后续接口开发、系统集成做好准备。
-
配合项目整体测试,及时处理开发过程中出现的技术问题,保障模块稳定运行。
七、本周总结
本周顺利完成音频模块从工具类到接口、从后端到前端的完整开发与验证工作。成功实现音频接口封装、蓝图注册、前后端联调、跨域处理、Demo 全流程跑通等核心任务,解决了路径导入、路由注册、文件处理、前后端交互等多项实际问题。并最后将本周部分代码推至团队gitee仓库。
目前系统功能完整、运行稳定、结构清晰,已具备可展示、可测试、可扩展的基础形态。整体进度符合计划,模块对接顺畅,代码质量达标,为项目后续迭代与最终交付提供了可靠保障。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)