【WM】LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
note
- LeWorldModel 的训练目标就是:从 raw pixels 学一个不会坍塌的 latent 状态空间,并在这个 latent 空间里学习“当前状态 + 动作 → 下一状态”的动力学模型。
- 稳定训练的trick:高斯正则防坍塌阶段【对 latent embedding 加 Gaussian regularizer,使表示分布保持展开,避免所有图像被编码成同一个向量】
- 在机器人控制、智能体规划里,很多时候不需要生成一张完整未来图片。LeWorldModel 在 latent 空间预测未来状态,所以更轻量,也更适合规划。
- 李飞飞对世界模型的定义:
- 1、Generative: World models can generate worlds with perceptual, geometrical, and physical consistency
- 2、Multimodal: World models are multimodal by design
- 3、Interactive: World models can output the next states based on input actions
文章目录
一、LeWorldModel
论文标题:LeWorldModel: Stable End-to-End JEPA from Pixels
论文地址:https://le-wm.github.io/
项目地址:https://arxiv.org/pdf/2603.19312v1
【世界模型进展】这篇 LeWorldModel: Stable End-to-End JEPA from Pixels 打的点是:让 JEPA 世界模型可以从原始像素端到端稳定训练,而不是依赖一堆复杂 loss、EMA、stop-gradient、预训练 encoder 或额外监督来防止表示坍塌。
论文提出 LeWorldModel / LeWM,只用两个核心目标:预测下一时刻 latent embedding,以及用一个 Gaussian regularizer 约束 latent 分布,避免所有输入被编码成同一个向量。作者称它是第一个能稳定从 raw pixels 端到端训练的 JEPA 世界模型。([arXiv][1])
1. 介绍JEPA
JEPA 的核心不是“生成下一帧图片”,而是:
把图像编码成 latent 表示,然后预测未来 latent 表示。
也就是:
当前图像 + 动作
→ encoder 编成 latent
→ predictor 预测下一步 latent
→ 和真实下一帧图像编码出来的 latent 对齐
它不关心像素级重建,比如“这块颜色是不是一模一样”,而是关心更抽象的状态变化,比如物体位置、速度、接触关系、运动趋势。
所以 JEPA 更像是:学一个压缩后的世界动力学模型。
2. 现有问题:JEPA 很容易“坍塌”
JEPA 最大的问题是 representation collapse。
因为训练目标是“预测 latent 越接近越好”,那模型可能偷懒:
所有图像都编码成同一个向量
预测结果也永远是这个向量
loss 很小,但什么都没学到
这就是坍塌。
以前很多方法为了防坍塌,会加很多工程技巧,比如:
- 用预训练视觉 encoder,不让 encoder 一起训;
- 用 EMA teacher;
- 用 stop-gradient;
- 加多个辅助 loss;
- 加重建、对比、方差、协方差等约束。
问题是这些东西会让系统很脆:loss 多、超参多、训练难调、复现成本高。
3. 核心思路
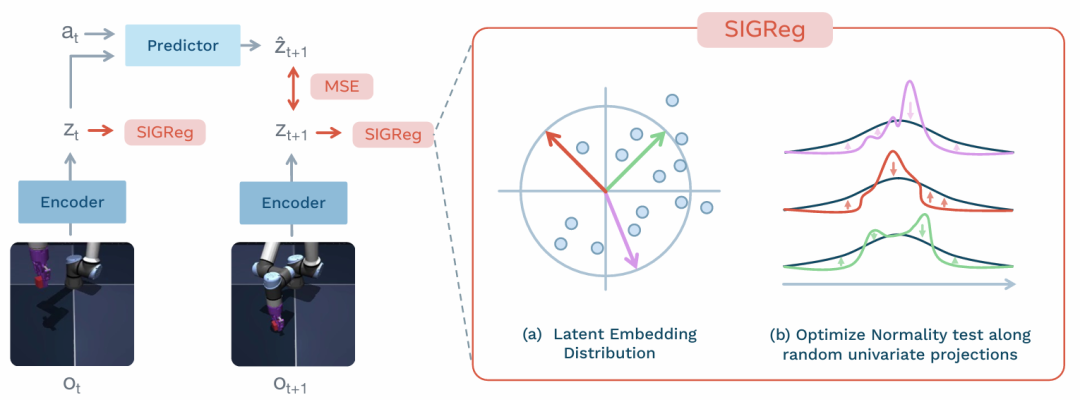
这篇论文的核心思路很直接:
不要预测像素,只预测 latent;
不要堆复杂防坍塌技巧,而是强制 latent 分布像高斯分布;
只要 latent 不能全部挤成一个点,模型就必须学到有信息的表示。
具体来说,LeWM 只保留两个 loss:
-
next-embedding prediction loss
让模型根据当前 observation 和 action,预测下一时刻的 latent embedding。 -
Gaussian regularizer / SIGReg
约束 encoder 输出的 latent embedding 整体接近高斯分布,防止所有样本坍塌成同一个向量。
论文里说,相比此前端到端 JEPA 替代方案,LeWM 把可调 loss 超参从 6 个降到 1 个,模型约 15M 参数,单 GPU 几小时可训练,并且在规划速度上比 foundation-model-based world models 快最高 48 倍。([arXiv][1])
4. 方法流程
看 1)具体步骤:
step1. 像素输入阶段【输入是原始图像 observation,不依赖预训练视觉 encoder,而是从 raw pixels 开始端到端训练】
-> step2. 编码阶段【用 encoder 把当前图像压缩成 latent embedding,相当于把复杂像素压缩成一个“世界状态表示”】
-> step3. 动作条件预测阶段【把当前 latent 和 action 输入 predictor,预测执行该动作后下一时刻的 latent embedding】
-> step4. 目标 latent 构建阶段【把真实下一帧图像也输入同一个 encoder,得到真实下一时刻 latent,作为预测目标】
-> step5. 下一 embedding 预测损失阶段【让预测 latent 接近真实下一帧 latent,训练模型学习环境动力学,也就是“做这个动作后世界会怎么变”】
-> step6. 高斯正则防坍塌阶段【对 latent embedding 加 Gaussian regularizer,使表示分布保持展开,避免所有图像被编码成同一个向量;这个正则就是整篇论文稳定训练的关键】
-> step7. 离线训练阶段【模型从环境交互数据中学习,不需要 reward,也不需要像素重建,只学 observation-action-next observation 之间的 latent dynamics】
-> step8. 规划阶段【给定当前状态和候选动作序列,模型在 latent 空间里快速预测未来状态,用预测结果辅助选择更好的动作】
-> step9. 物理理解评估阶段【作者还用 probing 和 surprise evaluation 检查 latent 是否编码了物理量,以及能否识别不符合物理规律的异常事件】
二、具体细节
LeWorldModel:训练目标、输入输出到底是什么?
理解:LeWorldModel 是一个从像素训练的 latent 世界模型:输入当前图像和动作,输出下一时刻的 latent 状态;训练目标是预测准下一状态,同时防止 latent 表示坍塌。
1. 训练数据是什么?
训练样本来自环境交互轨迹,形式是:
( o t , a t , o t + 1 ) (o_t,\ a_t,\ o_{t+1}) (ot, at, ot+1)
其中:
- o t o_t ot:当前时刻图像,也就是 raw pixels
- a t a_t at:当前执行的动作
- o t + 1 o_{t+1} ot+1:执行动作后的下一帧图像
比如机器人推箱子:
o_t:箱子在左边
a_t:机械臂往右推
o_{t+1}:箱子往右移动了一点
2. 模型输入是什么?
训练时输入是:
o t , a t o_t,\ a_t ot, at
但模型不会直接在像素空间预测下一帧,而是先把当前图像编码成 latent:
z t = E ( o t ) z_t = E(o_t) zt=E(ot)
再把当前 latent 和动作输入 predictor:
z ^ t + 1 = P ( z t , a t ) \hat{z}_{t+1} = P(z_t,\ a_t) z^t+1=P(zt, at)
所以本质链路是:
当前图像 o_t
↓
Encoder E
↓
当前 latent z_t
当前 latent z_t + 动作 a_t
↓
Predictor P
↓
预测下一 latent z ^ t + 1 \hat{z}_{t+1} z^t+1
3. 模型输出是什么?
模型输出不是下一帧图片,而是: z ^ t + 1 \hat{z}_{t+1} z^t+1
也就是预测的下一时刻 latent 状态。
它不追求:
下一帧每个像素都长得对
而是追求:
物体位置怎么变
速度怎么变
机械臂和物体关系怎么变
环境状态怎么变
所以它是在学:
当前状态 + 动作 → 下一状态 \text{当前状态} + \text{动作} \rightarrow \text{下一状态} 当前状态+动作→下一状态
而不是学:
当前图像 + 动作 → 下一帧图像 \text{当前图像} + \text{动作} \rightarrow \text{下一帧图像} 当前图像+动作→下一帧图像
4. 训练目标是什么?
真实监督信号是什么?
真实下一帧图像 o t + 1 o_{t+1} ot+1 也会经过同一个 Encoder: z t + 1 = E ( o t + 1 ) z_{t+1} = E(o_{t+1}) zt+1=E(ot+1)
这个 z t + 1 z_{t+1} zt+1 就是预测目标。
训练时要求: z ^ t + 1 ≈ z t + 1 \hat{z}_{t+1} \approx z_{t+1} z^t+1≈zt+1
也就是:预测出来的下一 latent≈真实下一帧图像编码出来的 latent
LeWorldModel 的训练目标Loss函数:
L = L pred + λ L reg \mathcal{L}=\mathcal{L}_{\text {pred }}+\lambda \mathcal{L}_{\text {reg }} L=Lpred +λLreg
其中:
- L p r e d \mathcal{L}_{pred} Lpred:下一状态预测损失,让模型学会预测世界怎么变
- L r e g \mathcal{L}_{reg} Lreg:高斯正则损失,防止 latent 表示坍塌
- λ \lambda λ:控制正则强度
所以它不是在训练一个图像生成器,而是在训练一个:稳定的 latent 状态空间 + latent 动力学预测器
4.1 下一状态预测损失
核心目标是让预测 latent 接近真实 latent:
L pred = d ( z ^ t + 1 , z t + 1 ) \mathcal{L}_{\text {pred }}=d\left(\hat{z}_{t+1}, z_{t+1}\right) Lpred =d(z^t+1,zt+1)
这里的 d ( ⋅ ) d(\cdot) d(⋅) 可以简单理解为“距离函数”。
即目标是:模型预测的下一 latent 和真实下一 latent 越接近越好
这个 loss 逼模型学习:
( z t , a t ) → z t + 1 (z_t,\ a_t) \rightarrow z_{t+1} (zt, at)→zt+1
4.2 高斯正则,防止表示坍塌
如果只有预测损失,模型可能偷懒:
所有图像都编码成同一个 z
预测器也永远输出同一个 z
loss 看起来不高
但模型其实什么世界规律都没学到
这叫 representation collapse,也就是表示坍塌。
所以 LeWorldModel 加了一个高斯正则,大意是让一批 latent z z z 的分布接近高斯分布:
z ∼ N ( 0 , I ) z \sim \mathcal{N}(0, I) z∼N(0,I)
通俗理解:
不同图像要有不同表示
latent 空间要展开
不能所有样本都挤成一个点
这个正则的作用是:
防止 Encoder 把所有输入都压成同一个向量
逼 latent 表示保留有效信息
保证端到端训练稳定
5. 整体训练流程
相关伪代码:
训练样本:
( o t , a t , o t + 1 ) (o_t, a_t, o_{t+1}) (ot,at,ot+1)
-
当前图像编码:
o t → E → z t o_t → E → z_t ot→E→zt -
动作条件预测:
z t + a t → P → z ^ t + 1 z_t + a_t → P → \hat{z}_{t+1} zt+at→P→z^t+1 -
下一帧图像编码:
o t + 1 → E → z t + 1 o_{t+1} → E → z_{t+1} ot+1→E→zt+1 -
预测损失:
让 z ^ t + 1 \hat{z}_{t+1} z^t+1 接近 z t + 1 z_{t+1} zt+1 -
高斯正则:
让一批 z 的分布保持展开,避免坍塌
更直观地说:
模型看到当前画面
知道执行了什么动作
然后预测下一步世界状态的 latent 表示
最后和真实下一帧的 latent 表示对齐
loss逐渐收敛:
6. 和传统图像生成世界模型的区别
传统生成式世界模型通常是:
( o t , a t ) → o ^ t + 1 (o_t,\ a_t) \rightarrow \hat{o}_{t+1} (ot, at)→o^t+1
也就是:
输入:当前图像 + 动作
输出:下一帧图像
目标:生成未来画面
LeWorldModel 是:
( o t , a t ) → z ^ t + 1 (o_t,\ a_t) \rightarrow \hat{z}_{t+1} (ot, at)→z^t+1
也就是:
输入:当前图像 + 动作
输出:下一帧 latent 表示
目标:预测未来状态
核心区别:
传统方法关心像素级生成
LeWorldModel 关心 latent 状态预测
所以它的优势是:
-
不重建像素,训练目标更轻
不用浪费能力去还原纹理、颜色、背景细节。 -
在 latent 空间规划,推理更快
不需要一步步生成图片,只需要预测向量变化。 -
端到端从像素训练
不依赖冻结的 DINO、CLIP 或其他视觉 foundation encoder。 -
防坍塌机制更简单
主要靠 Gaussian regularizer,而不是一堆工程 trick。
三、实验结果

2)看结果:论文在多个 2D 和 3D 控制任务上评估 LeWM,包括 manipulation、navigation、locomotion 等场景。结果显示,LeWM 用约 15M 参数就能取得有竞争力的控制表现,同时规划速度最高比 foundation-model-based world models 快 48 倍;此外,作者通过物理量 probing 发现 latent 中确实编码了一些有意义的物理结构,并且 surprise evaluation 表明模型能检测物理上不合理的事件。([arXiv][1])
也就是说,它不只是“能跑控制任务”,还说明 latent 空间里学到了一定的世界规律。
四、总结
1. 相关理解
这篇论文真正有价值的点,不是又提出一个世界模型,而是把 JEPA 世界模型训练不稳定 这个老问题做简单了。
以前 JEPA 最大痛点是:理论上很优雅,工程上很难训。因为一旦端到端从像素训,模型很容易表示坍塌,所以大家不得不用各种 teacher、EMA、预训练 encoder、多项 loss 来兜底。
LeWM 的贡献是:用一个简单的 latent 分布约束,让端到端 JEPA 世界模型变成一个更可控的工程方案。
它和大规模视频生成式世界模型不是一个路线。后者追求生成逼真的未来画面,LeWM 更偏向机器人/智能体控制:不需要画得像,只要 latent 里能预测“世界状态怎么变”,就足够用于规划。
总结:LeWorldModel 是一个轻量、稳定、端到端的 JEPA 世界模型方案,核心是用高斯正则解决 latent 坍塌,让模型从原始像素中学到可用于规划的世界动力学。
2. 李飞飞对世界模型的定义
Stanford李飞飞-From Words to Worlds: Spatial Intelligence is AI’s Next Frontier,链接:https://drfeifei.substack.com/p/from-words-to-worlds-spatial-intelligence
李飞飞对世界模型的定义:
1、Generative: World models can generate worlds with perceptual, geometrical, and physical consistency
2、Multimodal: World models are multimodal by design
3、Interactive: World models can output the next states based on input actions
Reference
[1] LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
[1]: https://arxiv.org/abs/2603.19312?utm_source=chatgpt.com “LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)