AutoGluon1.5.0核心架构与3大优势解析
·
🤍 前端开发工程师、技术日更博主、已过CET6
🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1
🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》
🍚 蓝桥云课签约作者、上架课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入门到实战全面掌握 uni-app》
文章目录
AutoGluon 1.5.0 是亚马逊AWS开源的高性能自动化机器学习(AutoML)框架,核心是多层堆叠集成 + 全流程自动化,以“最少代码、最优性能”为目标,主打表格、多模态、时序任务。
一、AutoGluon 1.5.0 核心架构
1. 整体模块化架构
- Tabular:表格数据核心(分类/回归)
- Multimodal / AutoMM:文本+图像+表格联合建模
- TimeSeries:时序预测、异常检测
- Vision / Text:图像分类、文本分类等单模态
- Core:调度、训练、集成、分布式、评估底座

2. 表格任务核心流程(最核心)
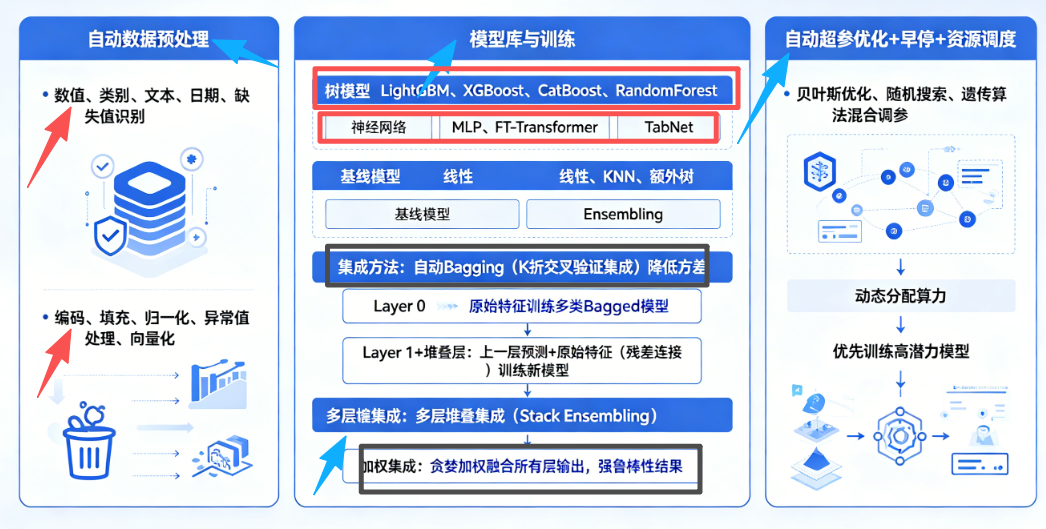
-
自动数据预处理
- 自动识别:数值、类别、文本、日期、缺失值
- 编码、填充、归一化、异常值处理、向量化
-
模型库与训练
- 树模型:LightGBM、XGBoost、CatBoost、RandomForest
- 神经网络:MLP、FT-Transformer、TabNet
- 线性、KNN、额外树等基线模型
- 自动Bagging(K折交叉验证集成)降低方差
-
多层堆叠集成(Stack Ensembling)
- Layer 0(基模型层):用原始特征训练多类Bagged模型
- Layer 1+(堆叠层):用上一层预测作为新特征 + 原始特征(残差连接)训练新模型
- 最终层(加权集成):贪婪加权融合所有层输出,得到强鲁棒性结果
-
自动超参优化 + 早停 + 资源调度
- 贝叶斯优化、随机搜索、遗传算法混合调参
- 动态分配算力,优先训练高潜力模型
3. 多模态(AutoMM)架构
- 统一 backbone:文本用 BERT/RoBERTa、图像用 CLIP/EfficientNet
- 多模态特征融合 + 跨模态注意力
- 端到端联合微调,支持图文表格混合输入
二、AutoGluon 1.5.0 三大核心优势

1. 极致预测性能(业界顶尖)
- 多层堆叠+加权集成:比单模型/简单集成精度显著更高
- OpenML/Kaggle:表格任务长期领先,1.0+版本在大量任务Top1
- 残差连接:保留原始特征,避免深层堆叠信息丢失
- 自动模型选择:同时训数十模型,自动保留最优组合
2. 极简使用,极低门槛(开箱即用)
- 3–5行代码完成从原始数据到高精度模型
from autogluon.tabular import TabularPredictor predictor = TabularPredictor(label="target").fit(train_data) preds = predictor.predict(test_data) - 全自动处理:缺失值、类别、文本、日期、异常值、特征工程
- 无需ML背景:非算法工程师也能快速产出工业级模型
3. 全场景覆盖 + 高度灵活可扩展
- 多任务支持:表格分类/回归、时序预测、文本/图像分类、多模态、NER、检测
- 大规模数据:支持5–30GB并行训练,速度提升2–4倍
- 高度自定义
- 自定义模型、特征处理器、指标、损失
- 自定义预处理/集成策略、分布式训练
- 部署友好:一键导出、支持 Torch/ONNX、云原生容器部署
三、1.5.0 版本关键增强(2026-03-26)
- 时序模块大幅强化:更快、更长序列、多变量、外生变量支持
- AutoMM 性能与速度提升:微调更快、精度更高
- 内存优化:大数据集内存占用显著降低
- scikit-learn 1.5.x 深度兼容
- bug 修复、稳定性、分布式训练增强
四、适用场景
- 快速 baseline、Kaggle/竞赛
- 业务数据预测(风控、销量、用户行为)
- 多模态(图文+表格)联合建模
- 非ML专家快速构建高可用模型
- 时序预测(销量、流量、指标)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)