灵衢UB核心优势之内存池化|大规模AI集群内存访问机制技术深度解读
**
灵衢UB核心优势之内存池化|大规模AI集群内存访问机制技术深度解读
**
作者:周朋 上海方宜万强微电子有限公司
前言
AI模型规模、上下文长度和推理链路持续增长,内存系统正在从单卡容量问题转变为跨卡、跨节点协同问题。仅增加单卡HBM容量,难以解决集群中内存分布不均、远端访问开销高和权限隔离复杂等问题。
UB(Unified Bus,灵衢)协议从硬件栈底层定义跨节点内存访问机制。它把地址翻译、权限校验和Load/Store访问语义扩展到跨节点范围,使远端HBM能够以受控、可验证、低CPU介入的方式参与计算。
本文聚焦UB协议中的关键能力:跨节点内存池化。文章先提炼AI集群内存系统的主要约束,再梳理UB的设计思路、协议架构和硬件模块,随后通过跨节点共享内存案例串联核心机制,最后回到AI负载场景分析其价值。
一、AI集群内存系统的三重困境
要理解UB的价值,需要先看清内存池化要解决的三个核心约束:容量、资源利用率和访问开销。
第一是容量墙。大模型权重、KV Cache、激活值和优化器状态会共同占用大量显存。单卡容量增长有限,模型部署越来越依赖多卡和多节点协同。
第二是资源孤岛。不同加速卡或节点上的HBM通常归属各自设备,空闲显存难以被其他计算任务直接使用。即使集群总显存充足,单个任务仍可能因本地显存不足而受限。
第三是通信墙。远端数据访问如果停留在显式搬运模式,应用需要处理注册、同步、鉴权、重试和调试等复杂流程。对于高频小粒度访问,软件提交与轮询路径还会引入额外CPU开销。
这三个约束叠加后形成一个明确的工程矛盾:AI集群规模在增长,但跨卡、跨节点的有效内存协作能力没有同步提升。UB内存池化要解决的正是这种规模与协作能力之间的落差。
三重困境可以浓缩为下表,后续章节要解决的正是其中的每一项:
表1汇总了三类约束及其根本原因
二、灵衢UB的架构哲学
面对这三重困境,UB从硬件栈底层重新思考远端内存如何以接近本地内存的方式被访问,并围绕地址翻译、访问语义和权限校验建立完整机制。
三个关键设计选择决定了UB的构造定位。
第一,把远端内存纳入硬件级地址翻译体系。在UB中,远端内存不仅是可传输的数据区域,也可以通过受控地址语义被访问。这要求接收方在每次访问时完成地址翻译与权限校验。执行该工作的模块是UMMU(UB Memory Management Unit),可以理解为CPU MMU跨节点语义的延伸。
第二,同时支持同步和异步两种访问语义。UB提供URMA异步接口,也提供Load/Store同步语义:CPU的一条mov指令可以触发远端HBM读写,访问方式与本地MMIO访问保持一致。这依赖发起侧的UBDecoder硬件,它把本地物理地址反向翻译为远端地址和描述符。
第三,把身份管理从数据面剥离。UB引入分层标识符体系:CNA表示路由到节点,EID定位到实体,TokenID指向内存段,UBA精确到字节,TokenValue验证权限。这些标识符各司其职,分别由UBFM固件、UMMU硬件和应用软件等角色分配和使用。应用侧重点从网络路径管理转向凭据持有与访问语义。
这三个设计选择共同构建了UB内存池化的基础:全局统一地址空间 + 双模态访问语义 + 硬件权限校验。下一节我们从协议整体架构出发,看这三个设计如何落地到具体的硬件和协议层次上。
三、从协议架构看跨节点内存池化
UB是一套完整的协议栈,规范将其定义为六层结构加上两个横向协作的独立模块。要理解内存池化,必须先建立对整体架构的直观认识,再从中识别出直接参与池化的功能单元。
3.1 灵衢UB协议整体架构
规范第2.2章节描绘的UB协议栈从下往上依次是物理层、数据链路层、网络层、传输层、事务层和功能层,另有UMMU作为内存访问的旁路验证模块,UBFM作为全局资源管理的控制面实体。其抽象表达如下:
图1给出了UB协议栈与内存池化相关模块的整体关系。
功能层把Load/Store同步访问和URMA异步访问并列为两种合法的编程模型。应用既可以通过异步队列提交批量传输,也可以通过本地指针语义触发远端HBM细粒度访问。
事务层把内存访问单列为一类事务,与消息传递、维护操作、管理消息并列。规范定义的Write(TAOpcode=0x03)、Read(0x06)、Atomic_I(0x07-0x0F)等事务类型都属于此类,它们是内存池化的直接协议承载。
UMMU与UBFM作为协议栈旁路的独立模块存在。UMMU参与事务层的接收处理,承担地址翻译与权限校验;UBFM不参与任何单次事务处理,但负责全局身份分配和路由建立。它们不是协议栈的层,却是内存池化不可或缺的协作方。
3.2 灵衢UB系统的硬件组成
再看规范第2.1章节图2-1描绘的UB Domain系统组成。一个UB Domain由若干UBPU(UB Processing Unit,UB协议处理单元)通过UB Link互联构成UB Fabric。每颗UBPU内部是计算核(CPU/NPU/GPU/存储等不同类型)加上UB协议处理硬件的组合:
图2展示了UB Domain中不同UBPU与UB Fabric的连接方式。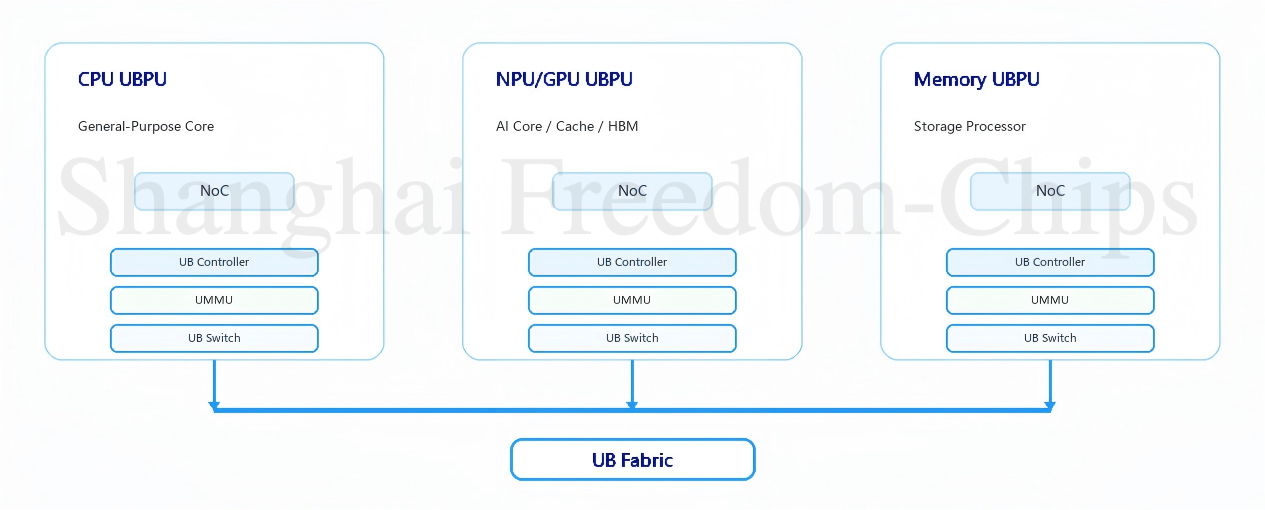
3.3 从架构到池化:相关模块的角色定位
把协议栈视图和硬件视图叠加起来,与内存池化直接相关的功能模块可以梳理为三组。
协议栈上的池化承载层。功能层暴露Load/Store和URMA两种编程入口;事务层通过MAETAH(Memory Access Extended Transaction Header)扩展头承载UBA与TokenID,通过TVETAH(Token Value Extended Transaction Header)承载32-bit权限凭证,TVETAH的携带与否由BTAH中的TV_EN位控制,只有启用权限校验的事务才会附带它;传输层为内存访问提供可靠(RTP)、轻量(CTP)或直通(TP Bypass)三种传输语义;网络层负责跨节点路由并通过FECN实现拥塞感知;数据链路层与物理层则是向远程显存发出和接收字节流的基础承载。
UBPU内的池化专用硬件。UB Controller是协议栈的主执行者,负责封包/解包与Jetty管理;UMMU是接收方的地址翻译与权限校验引擎,是整个池化机制的守门员;UB Decoder位于发起方,在Load/Store场景下把本地物理地址反向翻译为UBMD,让CPU的mov指令可以直达远端HBM;UB Switch是多端口的转发单元,负责ECMP路由与FECN标记。
控制平面的协调者。UBFM作为运行在某颗UBPU上的固件,承担拓扑枚举、CNA/EID分配、路由表下发等全局任务;OS驱动负责Jetty创建、内存段注册、UB Decoder页表维护等节点级管理。
这三组模块不是孤立存在的,它们在内存池化的每个环节都有精确分工。接下来的章节将深入最核心的几个抽象。
在展开细节之前,把后面反复出现的五个标识符先放在一张图上。内存池化的很多混淆都源于这套标识符体系。它们粒度 由粗到细,分别回答访问谁的五个子问题:
图3汇总了跨节点访问中从节点到权限凭据的标识符层次。
四、衢内存池化的核心抽象
从协议细节回到概念层面,UB内存池化的运行可以归结为一个简洁模型加上三层协作机制。
UB规范第九章首先建立了Home-User访问模型:注册并提供内存资源的一方称为Home;访问远端内存的一方称为User。模型本身很直白,但意义深远:它把跨节点共享内存定义为两个分布式系统中常被误解的概念,还原为谁拥有、谁使用的清晰主客体关系。任何一次跨节点内存访问,在规范术语中都可以简化为User持凭据访问Home的过程。后面的所有讨论都在这一模型之上展开:Home通过内存注册生产凭据,User通过凭据发起访问,硬件在两侧分别完成各自的翻译与校验工作。
围绕这个模型,三层机制层层递进:凭据系统让User能够精确表达我要访问哪块内存;翻译引擎在Home侧和User侧分别完成地址的正反翻译与权限校验;全局管理为前两者准备好网络身份与路由基础。三者环环相扣,缺一不可。
图4概括了Home-User模型中凭据、路由和访问上下文的关系。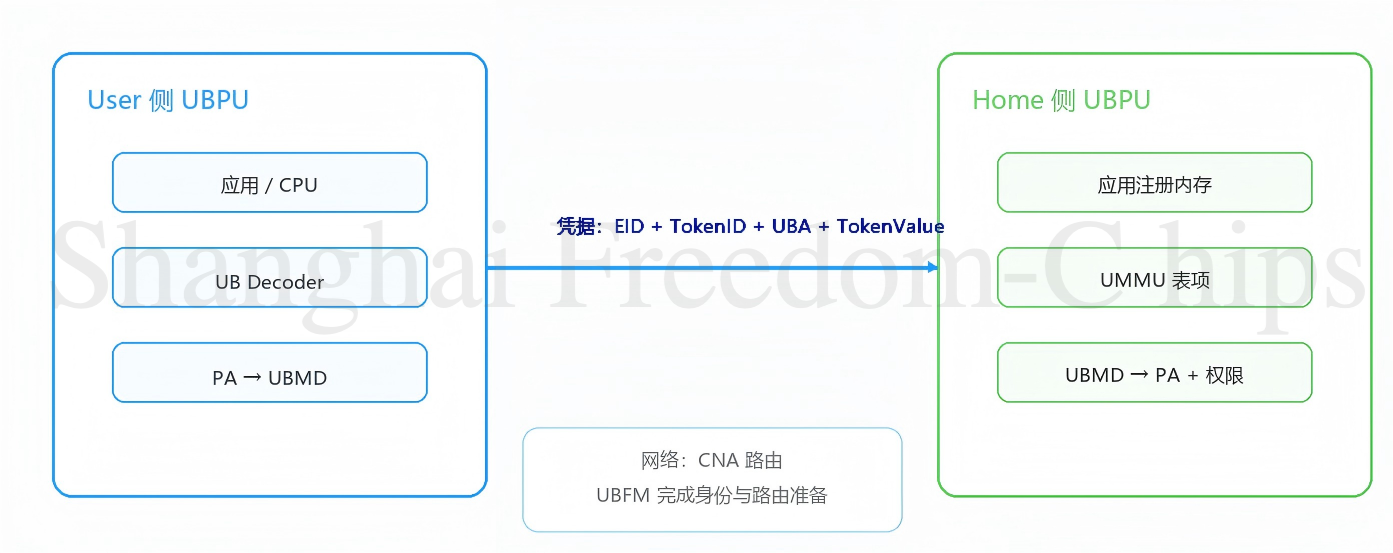
4.1 UBMD:跨节点访问的凭据系统
UBMD(UB Memory Descriptor,UB内存描述符)是UB规范定义的三元组:
UBMD = { EID, TokenID, UBA }
再配上一个独立传递的TokenValue,就构成了一次跨节点内存访问的完整凭据。
这四个字段可以按访问定位与权限校验的层次来理解:
EID标识目标内存归属的Entity。一颗UBPU可以承载多个Entity,每个Entity拥有独立资源配额,可服务不同租户或业务。
TokenID标识Entity内的共享内存段。一个Entity可以注册多块内存段,TokenID用于选择对应的翻译与权限上下文。
UBA(UB Address)表示段内逻辑地址。它由Home侧规划,不是物理地址,也不是User本地虚拟地址,而是Home Entity维护的地址空间,由UMMU翻译为真实物理地址。
TokenValue是运行时权限凭据。它不属于UBMD本身,可独立轮换,用于细粒度权限管理。
这四者缺一不可:EID定位实体,TokenID定位内存段,UBA定位段内字节,TokenValue负责权限验证。任一字段不匹配都会导致访问失败,这是多租户场景下硬件级隔离的基础。
一个值得注意的细节:规范允许MAPTE(MAPT Entry)同时存储主和备两个TokenValue。初始注册时两者可以相同也可以不同。这个设计为权限管理保留了更灵活的操作空间。若不同User或租户被分配了不同的TokenValue,需要撤销某个用户但保留其他用户的访问时,只需替换对应TokenValue即可,无需销毁整个内存段。这使权限回收可以在不销毁内存段的情况下完成,在大规模多租户环境下具有实际价值。
4.2 UMMU与UB Decoder:地址翻译的两端
UMMU(UB Memory Management Unit)位于每个Home侧UBPU内部,是内存池化的核心硬件执行者。它和CPU的MMU在功能上高度相似,都负责虚拟地址到物理地址的翻译和权限校验,区别在于CPU MMU服务于本机进程的虚拟地址空间,UMMU服务于跨节点访问产生的虚拟地址请求。
每当一个远端访问请求到达UMMU,它会在硬件流水线中完成四步验证,避免让CPU介入单次权限判断。首先按DEID查TECT(Target Entity Configuration Table),获得该Entity对应的TCT基址;然后按TokenID查TCT(Target Context Table),获得该内存段对应的MATT基址与MAPT基址;接着按UBA走MATT(Memory Address Translation Table)的多级页表,翻译出真实物理地址;最后按UBA查MAPT(Memory Address Permission Table),比对请求携带的TokenValue是否匹配MAPTE中的主/备锁,并校验Permission是否包含请求的访问类型。四步全部通过后,DMA引擎才会实际访问物理内存。
UMMU的设计中还有一个特别值得一提的细节:它支持两阶段地址翻译。Stage 1把UBA翻译为IPA(中间物理地址),Stage 2把IPA翻译为PA(真实物理地址)。这不仅完整对齐了ARM SMMU在虚拟化场景下的地址转换语义,一个Entity被直通给虚拟机时,Stage 1由Guest OS控制,Stage 2由Hypervisor控制,多租户的虚拟化隔离由硬件直接保证。这让UB Entity的虚拟化直通成为一种自然的硬件能力,而不是软件模拟出来的效果。
User侧:UB Decoder的反向翻译。
单靠UMMU只能解决Home如何验证外来请求的问题。要让Load/Store同步访问成立,还需要在User侧有一个反向的翻译机制,这就是UB Decoder的角色。
UB Decoder管理一套两级本地页表(L0/L1 PTE),把本地物理地址范围映射到远端UBMD。当CPU发出一条mov指令访问某个MMIO地址时,UB Decoder拦截这次访问,查本地页表得到{EID, TokenID, UBA_BASE, TokenValue},把本地物理地址的低位拼到UBA_BASE上形成完整的UBA。这组信息交给UB Controller封包发送,对CPU而言整个过程完全透明,从CPU视角看,这仍然是一次MMIO访问;跨芯片细节由UB Decoder和UB Controller处理。
UMMU和UB Decoder的关系可以这样概括:User侧UB Decoder把物理地址反向翻译为UBMD(PA到UBMD),Home侧UMMU把UBMD正向翻译为物理地址(UBMD到PA)。两端各自管理各自的页表,互不干扰。URMA异步访问则只走Home侧UMMU这一半,因为应用已经直接在WQE里提供了UBMD,不需要UB Decoder做反向翻译。
这里有一个根本的工程哲学:内存池化的权限控制必须在硬件完成,不能依赖软件。AI训练场景下单秒可能有数百万次远端内存访问,如果每次都需要CPU介入校验,软件根本扛不住。UMMU与UB Decoder的硬件化设计把单次翻译与校验从CPU调用路径中移出,让低CPU开销的池化访问从愿望变成现实。
UMMU的四步流水可以画成下面这张流程图,便于看清每一步的输入、操作、产出:
图5展示了UMMU在接收侧完成地址翻译和权限校验的流水。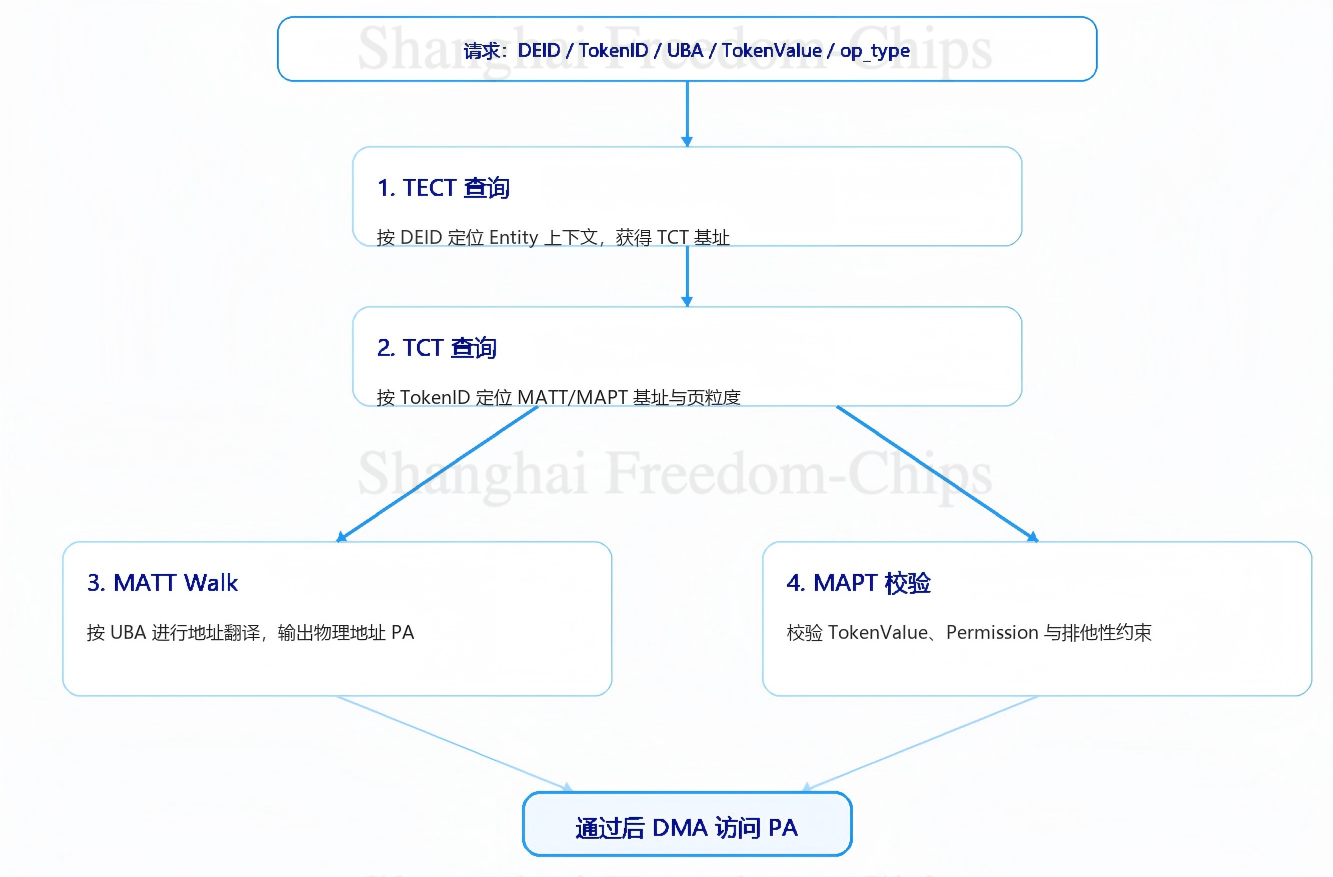
4.3 UBFM:全局资源的调度中枢
凭据系统和翻译引擎解决的是单次访问怎么做,但任何一次跨节点访问成立的前提是:两颗芯片都已经拥有网络身份,路由表已经配好,Entity上下文已经建立。这些全局性的准备工作落在UBFM(UB Fabric Manager)身上。
UBFM是运行在某颗UBPU上的固件,负责超节点级的全局管理。它不参与任何单次数据访问,但没有它的前期工作,内存池化根本无从建立。UBFM的工作可以概括为三件事。
枚举与身份分配:系统上电后UBFM通过拓扑查询命令发现每颗UBPU,按规划分配Primary CNA与EID,并通过Configure CNA与Entity Registration命令写入各UBPU的配置空间。CNA决定网络中这个UBPU被如何寻址;EID决定这个软件实体被如何标识。
路由表与分区:UBFM基于拓扑生成路由与多路径信息,生成路由表并下发到各UB Switch的1GB路由表区。协同与维护、Entity注册、UPI分区、热插拔、故障恢复等事件都由UBFM协调处理。
一个不常被注意到的事实是:UBFM本身跑在UB内部,它使用的网络正是它自己在管理的网络。这种自举设计需要UBFM通过一些特殊的Bootstrap机制,如保留的UPI=0x7FFF管理分区,在网络完全就绪之前也能工作。控制面和数据面共享物理链路,但通过保留特权身份避开了鸡生蛋的循环依赖。
把三层机制汇到一张表上,可以清楚看出它们的分工与协作:
表2总结了凭据系统、翻译引擎和全局管理之间的分工。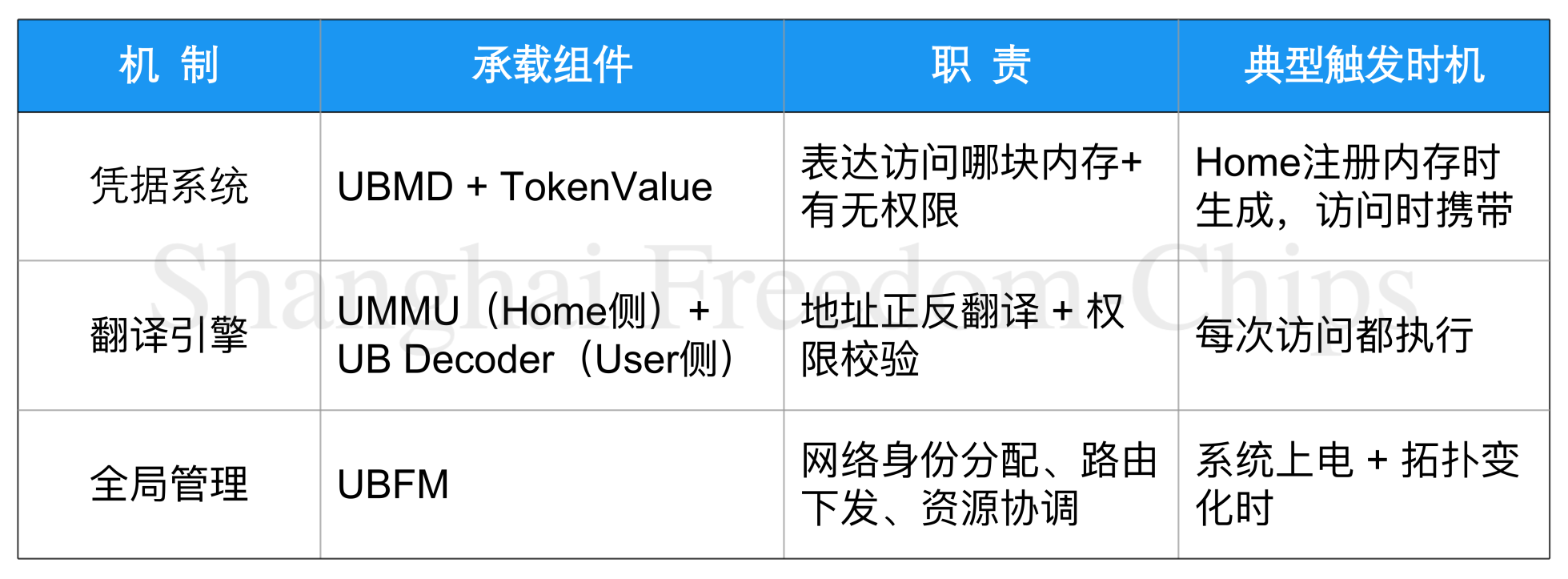
五、完整剖析:一次跨节点内存共享是如何发生的
抽象概念需要具体场景来落地。下面用一个完整案例串起所有机制:GPU A借用NPU B的64MB HBM存放训练中的激活值。这个场景刻意选得简单,以便专注于流程本身;更复杂的多节点、多租户场景只是规模上的叠加。
整个建链与访问过程可以划分为七个阶段,时间轴与关键动作如下:
图6按时间顺序总结了一次跨节点内存共享的主要阶段。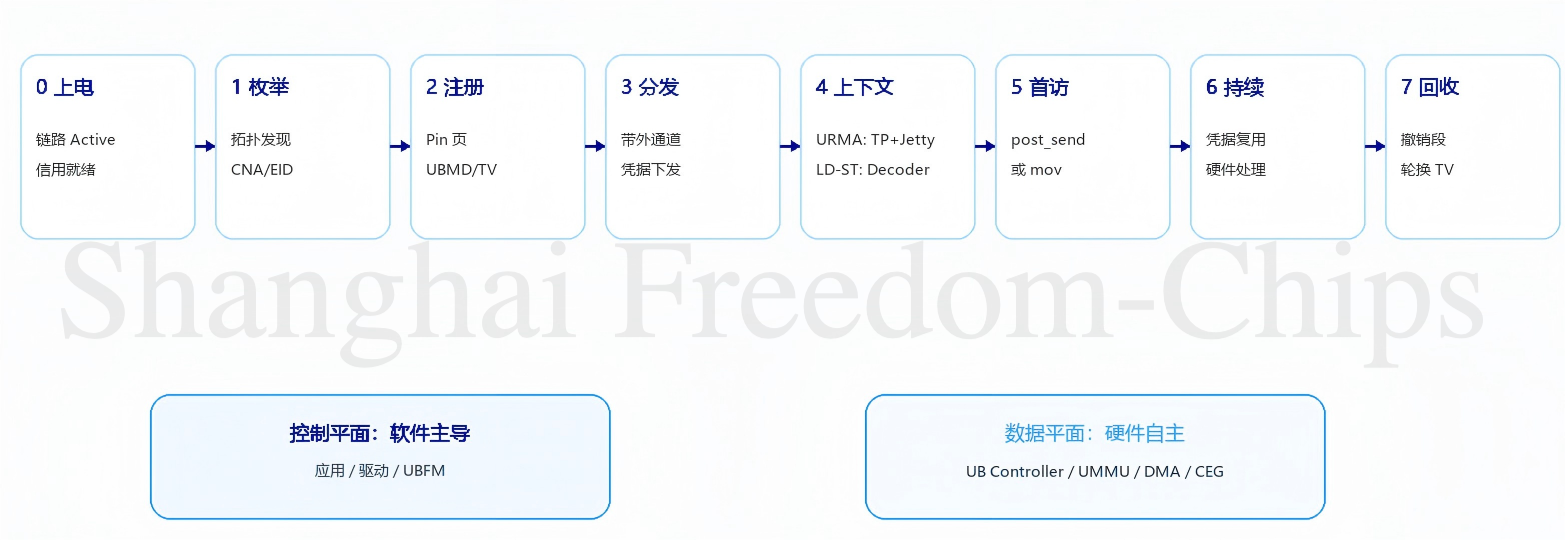
5.1 上电:物理基础的建立
故事从系统上电开始。两颗UBPU通过UB Link连接。物理层LMSM状态机完成Lane训练、速率协商、FEC配置,进入Link_Active状态。数据链路层初始化信用流控,双方交换Init Block协商链路参数。
这个阶段两颗芯片完成了物理意义上的握手,线已经通了,但上层一片空白:没有网络地址,没有通信端点,没有任何应用可以跨芯片交流。它们只是两颗知道对方存在的芯片,还不构成一个超节点。
5.2 UBFM登场:从芯片到超节点
超节点的成形始于UBFM的登台。系统某个UBPU在启动的时候被确定为UBFM角色,它开始在整个Fabric内部扫描、编目、分配。
首先是拓扑枚举。UBFM从自己出发,向每个直连邻居发送拓扑查询命令(Configure CNA命令CMD=0),邻居返回本节点信息后,UBFM继续向它们的邻居查询,按广度优先遍历扫遍整个超节点。这个过程类似传统网络中的邻居发现协议,但通信基础是UB自己的报文格式。
然后是身份分配。UBFM为每颗UBPU分配Primary CNA(24-bit节点地址),为每个Entity分配EID(128-bit实体标识)。这些值通过Configure CNA与Entity Registration命令下发,写入对应UBPU的CFGO_BASIC寄存器。假设GPU A得到CNA=0x1001,NPU B得到CNA=0x2002(例子使用16-bit CNA模式,对应后续CFG=6的非一致性访问场景);两颗芯片各自的业务Entity分别得到EID_A与EID_B。
最后是路由下发。UBFM基于拓扑运行最短路径算法(包含ECMP支持和环路避免约束),计算出每个UB Switch应如何转发到任意目标CNA,把这些路由条目写入各UB Switch的CFG0_ROUTE_TABLE。
这一阶段结束时,整个超节点具备了最基础的网络可达性。GPU A发一个DCNA=0x2002的包,UB Switch能准确送达NPU B。但应用还不能互通,缺少传输层和事务层的通信上下文。
5.3 NPU B注册内存:把本地HBM变成可共享资源
现在轮到NPU B的应用主动出场。它调用一个注册接口:
urma_register_seg(
ctx,
.addr = shared_buf,
.size = 64 * 1024 * 1024,
.perm = URMA_ACCESS_READ | URMA_ACCESS_WRITE,
&token_id, &uba_base, &token_value
);
这行代码背后发生了相当多的事情。OS驱动首先锁定64 MB物理页(Pin住,防止被操作系统换出),然后向UMMU申请一个空闲的TCT条目,UMMU分配TokenID=0x00042。驱动规划一段UBA虚拟地址区间,比如从0x10_0000_0000到0x10_0400_0000,正好64MB。接着生成TokenValue(用硬件RNG或软件随机数,比如0xCAFE_BABE)。
然后驱动要填四张UMMU硬件表:TECTE告诉UMMU这个Entity的TCT基址在哪;新分配的TCTE指向该段的MATT与MAPT;MATT建立UBA到物理地址的多级映射;MAPTE填入Permission=RW和主/备TokenValue。
至此,NPU B的UMMU硬件已经知道这段64 MB内存的存在,并且拥有完整的访问控制策略。但这些映射和权限上下文仍位于NPU B本地,GPU A需要后续凭据分发才能访问。
5.4 凭据分发:带外通道的角色
UBMD与TokenValue组成的四元组,必须从NPU B传递到GPU A,两者才能建立数据面通信。UB规范没有强制规定分发方式,这实际上属于带外通道的职责。
典型的选择是走TCP/IP管理网络:两侧应用守护进程通过集群协调服务(如etcd/ZooKeeper)交换元数据。更高安全性的场景会经UBFM中转,由UBFM基于全局权限策略控制凭据流向。少数实现也会通过UB的公知Jetty 1(事务层信息交换端点)做分发,但这要求基础通信已经建立。
不论走哪条路,分发的都是同一个四元组:
{ home_eid, token_id, uba_base, size, token_value, permissions }
值得一提的是,TokenValue相当于访问密码,明文传输有泄露风险。UB规范的CIP机制(AES-GCM / SM4-GCM)可以为数据面加密,但带外通道自身的安全性需要管理面另行保障。在可信网络内部可以简化处理,跨安全域传输时必须加密。
5.5 建链:从还不能发到可以发
GPU A现在手握凭据,但不同访问路径还需要不同的本地准备工作:URMA路径需要传输层TP Channel和应用层Jetty;LD-ST路径则需要UB Decoder映射和对应的一致性/访问属性配置。
URMA路径的TP Channel建立由UB Controller硬件与固件协同完成。规范第6.3.1章节明确TP Channel的具体建立流程不在本规范定义范围内,这是UB规范目前的一个留白。但可以将它合理抽象为:两端由系统软件,典型做法是通过公知Jetty 0(传输层信息交换端点)完成协商;双方协商TPN分配、PSN初值、BitMapSize、拥塞算法类型、MTU等关键参数。协商完成后各自建立TP Channel上下文。多条TP Channel通常组成一个TPCG(Transport Channel Group),用于后续的多路径负载均衡和带宽聚合。
Jetty创建也是URMA路径的应用层准备。GPU A调用urma_create_jetty创建一个通信端点,驱动从[32, 1023]范围分配Jetty ID,配置Jetty Context Table(JETC)、权限与JFC,为配套的SQ与RQ缓冲区分配内存页。Jetty在UB协议中是URMA编程模型的基本通信单元,可以理解为自带硬件队列的socket。LD-ST路径不依赖Jetty队列,而是依赖UB Decoder页表把本地地址窗口映射到远端UBMD。
这里需要特别澄清一个容易混淆的点:由于GPU A执行的是Write/Read(内存语义)而非Send(消息语义),NPU B侧不需要创建专门的接收Jetty。UMMU会直接按UBMD定位内存并完成访问,不经过NPU B的任何Jetty。这是内存语义最典型的单边特征:发起方需要完整的访问凭据,接收方只需暴露UMMU表项。相比之下,如果GPU A要发Send消息给NPU B,则NPU B必须有接收Jetty且已经在RQ挂好接收缓冲,发送方还需显式携带目标Jetty标识(MTETAH.TGT_TC_ID),那是另一套路径。
5.6 真正的访问:URMA和LD-ST两条路径
一切就绪后,GPU A终于可以访问NPU B的内存了。UB提供两条访问路径,覆盖不同的性能需求。
URMA路径让应用通过API显式发起:
urma_post_jetty_send_wr(
jetty_a,
.opc = URMA_WRITE,
.local_buf = activation_data,
.length = 40 * 1024 * 1024,
.remote = { EID_B, 0x00042, 0x10_0000_0000, 0xCAFE_BABE },
.wr_id = step_id
);
UB Controller读取这条WQE,查Jetty Context找到绑定的TPG,TPG调度选择一条TP Channel,得到SrcTPN和DstTPN,分配一个INI_RC_ID记录SQ Context(用于后续响应匹配),查EID-CNA获得DCNA。40 MB数据按MTU切成若干TP Packet,每个包自动加PSN、计算ICRC。包头里的MAETAH携带UB Address与TokenID,TVETAH携带TokenValue,CFG字段根据访问类型派生为6(16-bit CNA非一致性访问)。这些工作几乎全部由硬件自主完成,应用只提供了WQE里的几个核心字段。
这一过程中包头字段的填入分工,可以直接画在包的层叠结构上:
图7展示了URMA Write从WQE到CQE的数据面路径。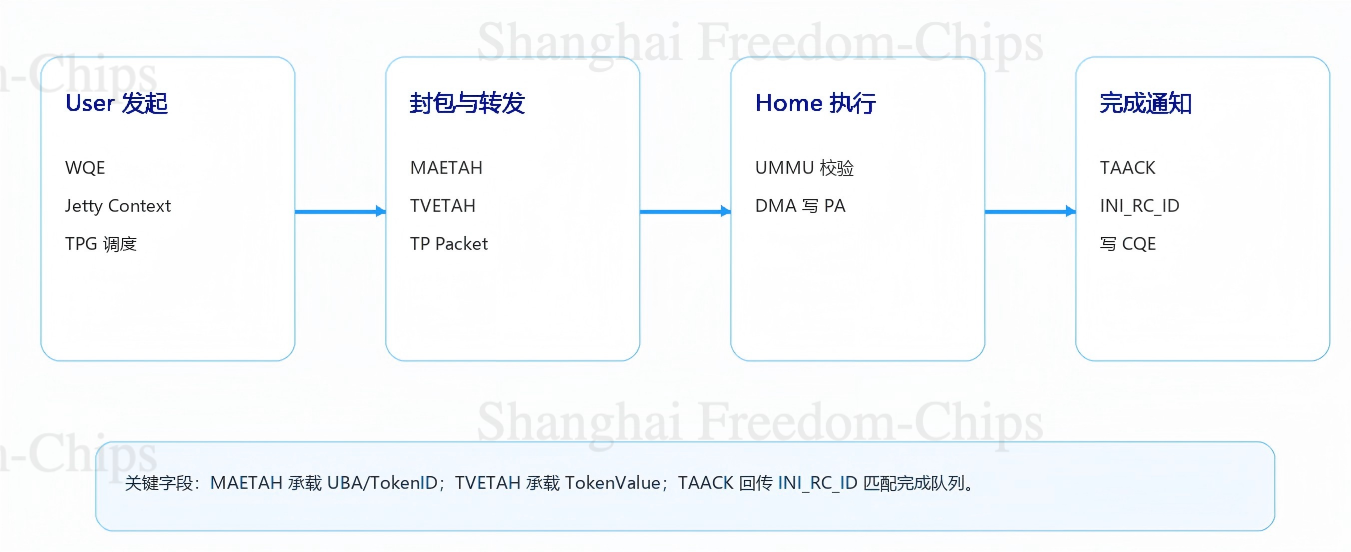
LD-ST路径面向同步细粒度访问,将远端访问映射到本地MMIO地址范围。配置阶段驱动把UBMD写入UB Decoder的两级页表,建立本地物理地址范围到远端UBMD的映射:
ub_decoder_map(
.local_pa_range = { 0x7F_E000_0000, 0x7F_E400_0000 },
.remote_ubmd = { EID_B, 0x00042, 0x10_0000_0000, 0xCAFE_BABE }
);
运行时CPU直接用本地指针访问:
int *remote_ptr = (int*)0x7F_E000_1000;
int value = *remote_ptr; // 读远端HBM
*remote_ptr = 42; // 写远端HBM
__sync_fetch_and_add(remote_ptr, 1); // 远端原子加
CPU发出mov指令后,本地MMU识别该地址为MMIO(Uncacheable属性),请求送到UB Decoder。UB Decoder查本地两级页表,得到{EID, TokenID, UBA_BASE, TokenValue},把本地物理地址的低位拼到UBA_BASE上形成完整的UBA。随后UB Controller按当前一致性域、地址属性和传输配置封包;在典型LD-ST配置中,可使用一致性访问语义和TP Bypass等低开销路径。CPU流水线阻塞等待响应,响应到达后数据写入寄存器,流水线解除阻塞。
对应用而言,int value = remote_ptr;这条C语句即可触发一次跨节点内存读。访问粒度可以细到单个Cache Line;实际延迟取决于拓扑距离、拥塞状态、表项命中率、一致性域配置以及具体芯片实现。
两条路径共享同一套UMMU校验逻辑,但在发起侧走了不同的硬件路径。URMA依赖Jetty的SQ/CQ管理,适合批量和异步场景;LD-ST依赖UB Decoder的地址反向翻译,适合细粒度和同步场景。它们不是替代关系,而是互补关系。AI训练中大多数场景是用URMA传梯度,用LD-ST读远端状态标志这样的混合使用。
5.7 持续使用与权限回收
建立之后的持续访问成本极低。同一条UBMD可以被反复使用,每次访问无需重新建链。URMA只需重复post_send,LD-ST只需继续使用本地指针访问,硬件自动完成所有翻译、封包、校验。
当协作结束,NPU B可以选择两种方式回收权限:完全撤销(urma_unregister_seg销毁TCTE,后续所有访问被拒绝)或者精细撤销(修改MAPTE的主/备TokenValue,让特定用户的旧凭据失效而保留其他用户的访问)。精细撤销中主/备TokenValue机制的价值充分显现:换锁芯而不销毁保险柜,无需通知其他用户,无需销毁内存段,完全在UMMU内部完成。
六、软硬件协作的分工原则
回看整个流程,一个规律清晰浮现:控制平面软件主导,数据平面硬件主导。
上电、UBFM枚举、CNA/EID分配、路由下发、内存注册、TP Channel建立、Jetty创建、UB Decoder页表配置,这些建链相关动作大部分由软件(UBFM固件、OS驱动、应用库)主导,硬件被动响应(写寄存器、更新上下文表)。建链完成后,数据面的每次访问几乎完全由硬件自主完成:UB Controller封包,UMMU翻译和校验,DMA读写内存,CEG生成CQE。软件只负责提交请求和查询完成。
这种分工不是偶然,而是基于一个根本的工程考量:建链次数少但逻辑复杂,交给软件更灵活;数据访问次数多但逻辑固定,交给硬件更高效。建链每个会话只做一次,涉及策略决策、资源协调、配置下发,用软件实现成本低、可迭代性强。数据访问每秒可能发生数百万次,延迟和吞吐都是关键指标,必须硬件化才能达到us级响应和TB级带宽。
以一次典型的URMA Write为例,软件提供的仅仅是WQE里的几个字段:对端EID、TokenID、UBA、TokenValue、数据长度、操作码。其余所有包头字段都由硬件自主填入:SCNA来自寄存器读取,DCNA来自EID-CNA路由查询,SrcTPN/DstTPN来自TPG调度器的选择,PSN来自TP Channel上下文的递增,CFG根据目标地址类型自动派生,LBF由硬件按负载均衡策略生成,ICRC由硬件流水计算。粗略估算,大约70%的包头字段由硬件自主产生,这正是UB能做到零CPU开销的根本原因。
对LD-ST路径而言,CPU的参与度更低。发出一条指令后CPU就进入流水线阻塞,其余所有工作(本地物理地址到UBMD的翻译、封包、发送、接收响应、解除阻塞)都在硬件流水中完成。CPU甚至不知道这是一块远端访问,它以为自己在等一次本地MMIO完成。
这种分工模式让UB内存池化在应用层呈现两种接口形态:URMA面向异步批量传输,LD-ST面向同步细粒度访问。但底层是同一套硬件、同一套协议栈、同一套权限校验。
七、灵衢UB两种访问模式的取舍
URMA和LD-ST并非并列的两套协议,而是同一协议栈的两种使用方式。它们共享TAOpcode编码(Write都是0x03,Read都是0x06),共享UMMU的翻译与校验流程,但在发起侧的触发方式和完成管理上完全不同。
URMA是异步编程模型,适合批量、大块、吞吐优先的场景。一次post_send可以提交一个GB级的传输请求,内部被切成大量TP Packet并发发送,硬件在后台完成所有传输,应用在合适的时机poll_cq查询结果。它的端到端延迟包含CPU提交、队列处理、网络传输和完成轮询开销,但吞吐更容易贴近链路上限。AI训练中的参数同步、Checkpoint保存、权重拉取、Pipeline激活值传递,都是URMA的典型舞台。
LD-ST是同步编程模型,适合细粒度、低延迟、控制流场景。一条mov或cmpxchg指令可以完成一次Cache Line级别的访问,语义更接近本地内存访问。原子操作可由硬件映射到对应Atomic事务,但具体ISA支持和一致性保证取决于处理器、UB Decoder配置和一致性域。此类访问通常不需要Jetty队列,可使用TP Bypass等低开销路径。分布式锁、远端状态查询、小控制字段更新、跨节点一致性维护,都是LD-ST适用的应用场景。
在真实系统中两者往往混用。AI训练框架用URMA传梯度,用LD-ST读远端的同步标志位;MoE推理用LD-ST访问远端专家的路由表,用URMA批量回传中间激活值;分布式KV Cache用LD-ST查询元信息,用URMA搬运数据主体。这种混合使用体现了UB的接口分层价值:同一套底层协议和标识符体系,可以按场景选择不同访问路径。
LD-ST适合细粒度同步访问,URMA则保留了异步模型在大块传输场景下的吞吐优势。LD-ST每次访问都让CPU流水线阻塞等待RTT,对于传输1 GB数据这样的任务,阻塞上百万个RTT时间并不经济。URMA允许应用一次提交后让CPU继续处理其他工作,DMA引擎在后台并发传输。 两种模式各自覆盖不同访问需求,共同构成完整的访问能力谱系。
把两种模式的关键差异汇总成表,能更直观看出各自的适用边界:
图8给出了URMA与LD-ST的适用场景选择矩阵。
表3对比了URMA与LD-ST在触发方式、粒度、延迟和场景上的差异。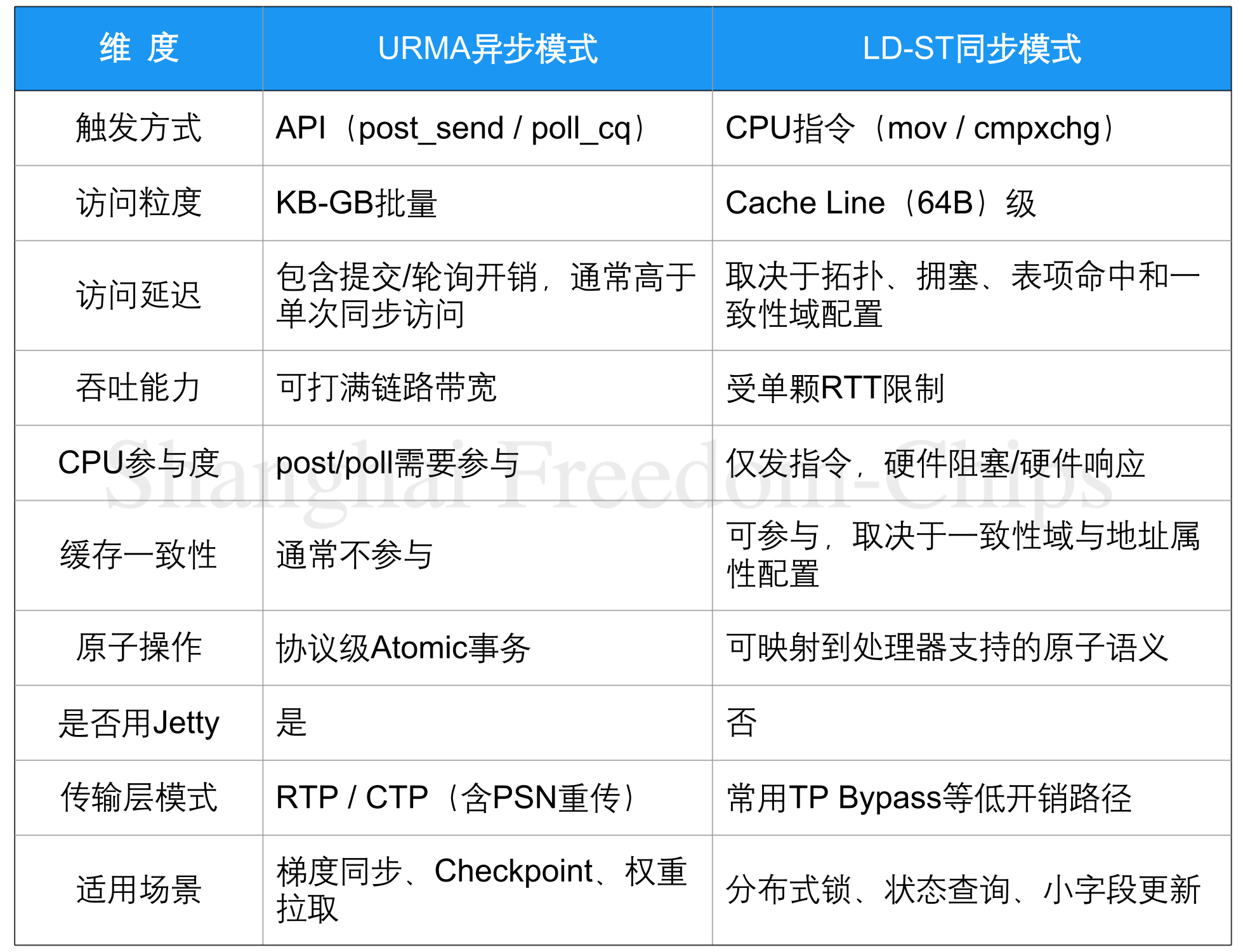
八、灵衢UB AI负载中的价值显现
内存池化不是展板上的技术名词,而是解决具体工程问题的手段。几个典型的受益场景可以说明它的实战价值。
MoE大模型推理中的专家访问。DeepSeek V4这类模型有数百个专家,一次token路由可能激活其中若干个。传统方案下专家权重分散在不同节点,每次路由往往需要显式的Dispatch/Combine通信。UB内存池化下,专家权重可以暴露为全局内存段,计算节点有机会通过LD-ST直接读取所需专家权重,从而减少显式通信和调度开销。具体延迟收益取决于专家放置、拓扑距离、访问粒度和缓存命中情况。
KV Cache的动态池化。百万token上下文下的KV Cache可能占几十GB。不同请求之间的负载极不均衡。传统方案中,单请求超出本卡HBM上限只能拒绝或截断;UB内存池化允许KV Cache分散在整个集群内存池中,让内存紧张的节点按需使用其他节点的空闲HBM。它的价值在于提高可调度空间和削峰能力,实际利用率提升幅度需要结合负载分布、调度策略和远端访问比例评估。
参数服务器架构的重新评估。经典PS架构在大模型训练场景中因为CPU处理瓶颈逐渐被AllReduce替代(推荐系统等场景仍在使用)。UB内存池化让PS在大模型训练中重新具备讨论空间:PS节点把权重暴露为全局内存段,Worker直接用LD-ST或URMA拉取权重,PS的CPU完全不介入数据面。PS的灵活性(异构Worker、动态调度)和AllReduce的性能(零CPU介入)第一次可以兼得。
训练中的低干扰Checkpoint。Checkpoint曾是训练中CPU与IO的共同瓶颈,每次保存可能占用数秒到数十秒的计算时间。UB内存池化下,Checkpoint可以通过URMA异步写入专用存储节点的共享内存,使计算与存储更充分并行。最终吞吐损失取决于Checkpoint频率、写入带宽、存储节点能力和后台传输调度。
这些场景的共同点是:它们都不是UB发明的需求,而是AI工程师一直面对的痛点。UB通过提供统一的内存访问基础设施,让这些痛点有了系统性的解决方案,而不是让每个团队各自打补丁。基础设施的价值,往往体现在它把复杂的跨节点协作转化为可复用的系统能力。
结语:从远程搬运到统一内存访问
过去二十年,分布式计算的演进方向一直是让多台机器更好地协作。局部高速互联、跨卡内存扩展和跨机数据传输分别解决了不同层面的问题。面向8192卡尺度的AI集群,内存系统还需要同时具备全局地址组织、硬件级权限校验、低开销访问路径和可扩展管理能力。
UB内存池化走到了这个交叉点上。它通过UB Controller、UMMU、UB Decoder、UB Switch、UBFM的端到端协同,让超节点规模的所有HBM第一次以统一的地址空间、统一的访问语义呈现给软件。对AI应用开发者而言,这意味着数据在哪里从架构设计一等公民变成运行时绑定部署细节。
这不只是性能优化,更是编程模型的变化。当一个8192卡集群能够以统一地址和统一访问语义暴露给软件,分布式协作就可以从应用显式编排,逐步转移为基础设施默认提供的能力。
推理模型把计算从秒级拉到分钟级,Agent把单次任务的状态从MB拉到GB,多模态把显存消耗推向另一个数量级。DeepSeek V4这一代模型对内存系统的要求,早已超出了单卡更大HBM能解决的范围。整个行业需要的是一次从远程数据访问到统一内存访问的范式变化。
UB内存池化的意义,在于把跨节点内存访问从应用显式搬运转向基础设施级访问语义。这是一种从局部优化到机制重构的变化,也是UB作为下一代互联协议的重要技术价值。
参考资料
UB Base Specification 2.0.1
UB Firmware Specification 2.0
UB Software Reference Design for OS 2.0
UB SuperPoD Architecture White Paper

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)