Pixelle-Video深度解构:零门槛AI短视频引擎的技术哲学与落地实践
一、短视频创作的范式转移:从"剪辑技能"到"创意表达"
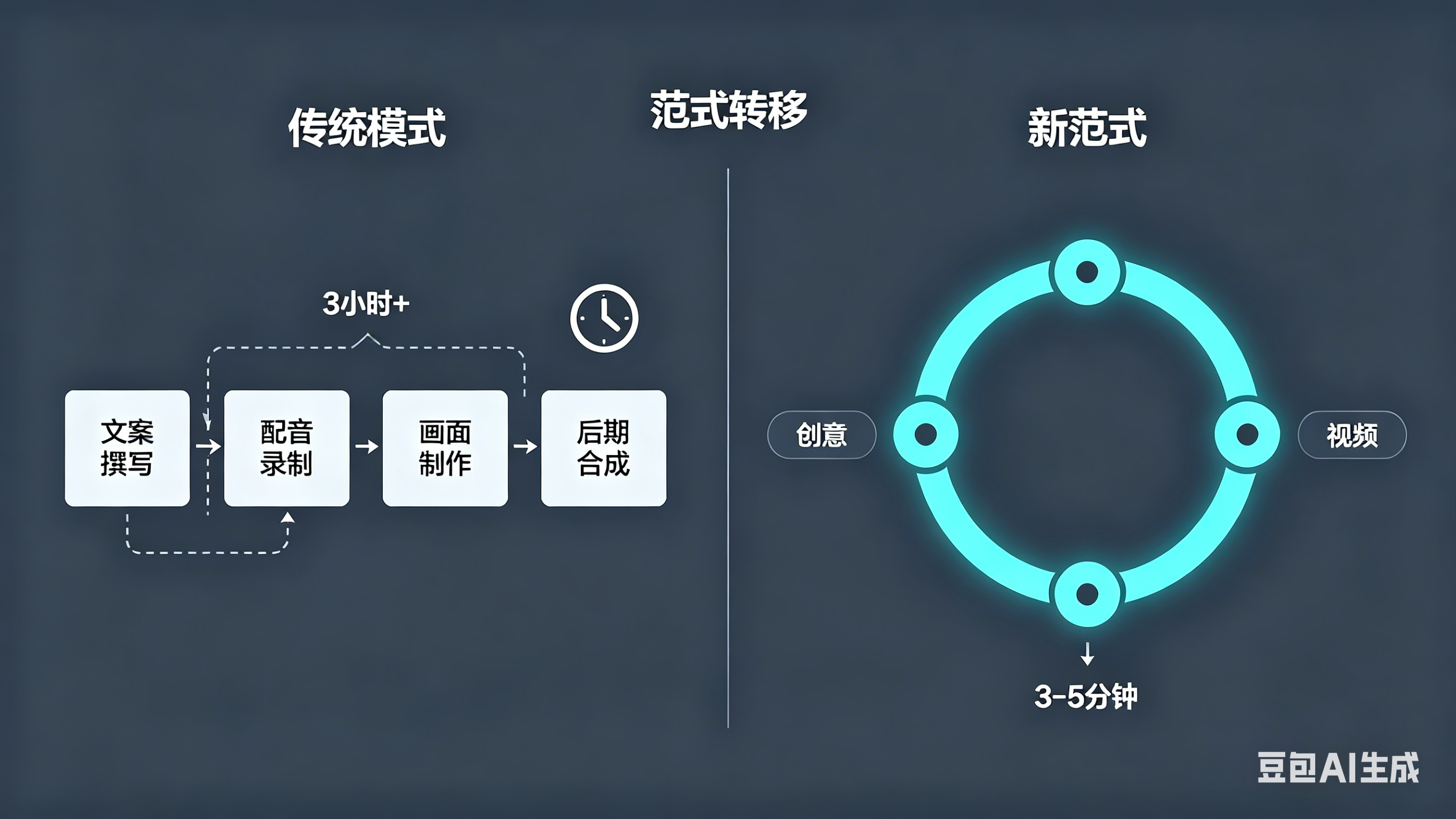
短视频市场在2025年已突破500亿美元规模,内容需求呈现指数级增长。然而传统视频制作的技术门槛与产能之间的矛盾并未缓解——一条2分钟的口播视频通常需要经历文案撰写、配音录制、画面制作、后期合成4个环节,耗时超过3小时。这种低效流程迫使创作者在"产量"和"质量"之间做出艰难取舍。
Pixelle-Video出现的意义,在于它将视频创作的核心瓶颈从"技术操作"转移到了"创意表达"。作为AIDC-AI团队开源的AI全自动短视频引擎,它彻底重构了视频生产流程:用户只需输入一个主题,系统便能自动完成文案撰写、AI配图/视频生成、语音合成、背景音乐添加以及最终合成——整个过程零门槛、零剪辑经验。
目前项目在GitHub已累计超11.1kStar,采用Apache 2.0许可证,支持商业使用。
二、架构剖析:ComfyUI赋能的四阶段生成管线
2.1 技术栈全景
从代码库构成来看,Pixelle-Video是一个以 Python(76.1%)为核心、HTML(22.9%)为前端界面的技术混合体。Python负责后端调度、API编排、AI模型调用和视频合成;HTML模板系统则负责视频画面的视觉呈现。再加上视频处理领域的工业标准工具FFmpeg,三者构成了完整的多模态生成引擎。
真正让Pixelle-Video区别于同类工具的,是其基于 ComfyUI 的节点式工作流架构。ComfyUI本质上是一个Stable Diffusion的可视化工作流编辑器,通过拖拽和连接不同功能节点来构建复杂的AI图像/视频处理流程。Pixelle-Video将这一理念提升到了整个短视频制作链条的高度——它不像HeyGen或Synthesia等闭源工具那样把用户锁定在固定流程中,而是强调开源灵活性,允许用户自定义工作流以满足个性化需求。
2.2 四阶段生成管线
Pixelle-Video的视频生成过程遵循一条清晰的流水线——不是简单的线性拼接,而是一个模块化设计、各环节独立可替换的智能调度系统,将短视频生产的全链条拆解为四个相互衔接又各自独立的核心阶段:
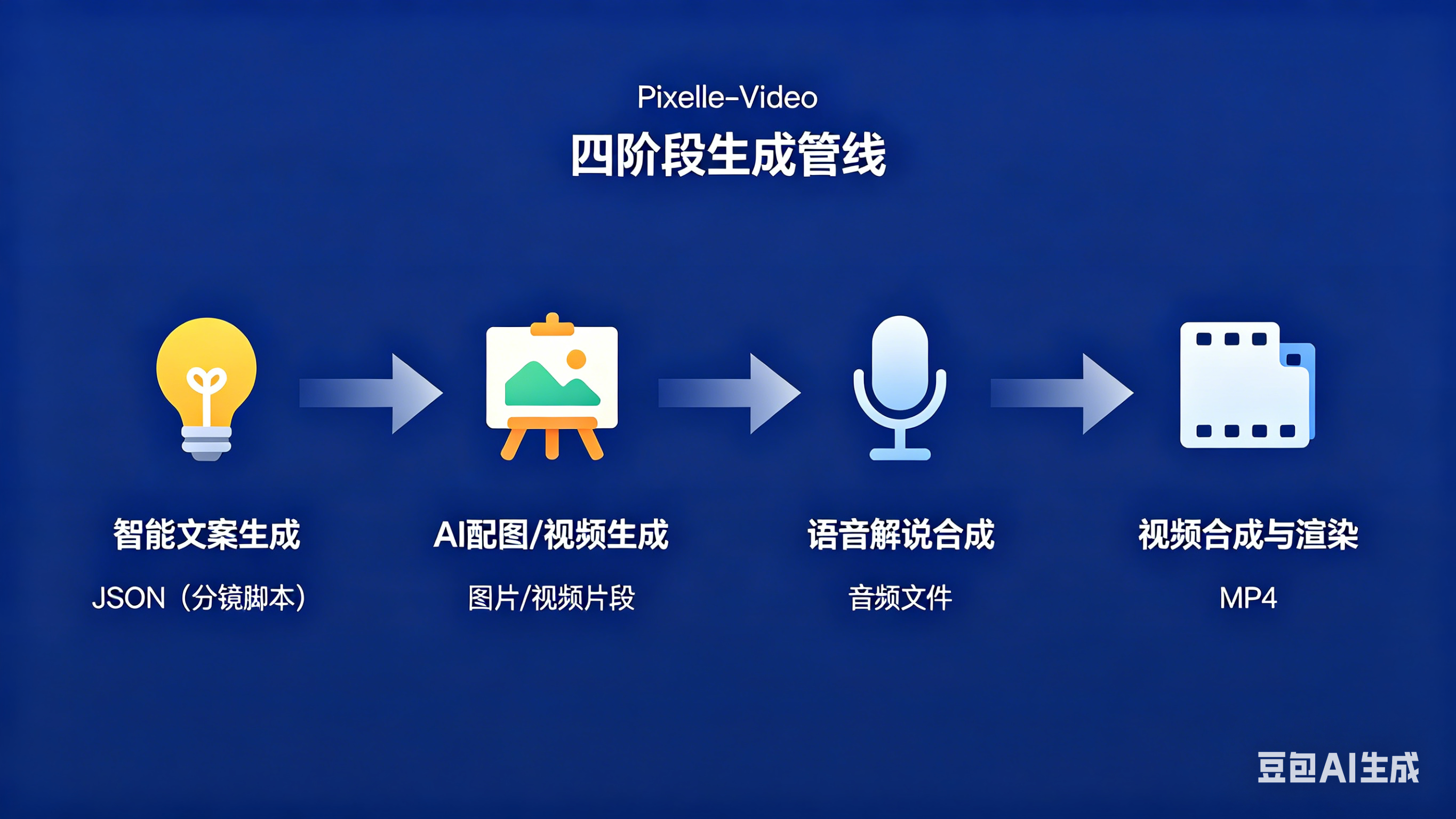
阶段一:智能文案生成。 用户输入一个主题后,系统并非简单地将主题扔给LLM自由发挥。它构造了精心设计的结构化Prompt,要求模型输出包含分镜结构的JSON数据——每个分镜都包含解说词文本、英文图像描述提示词以及时长估算。最新版本中团队对LLM结构化输出的解析逻辑进行了重构,增强了容错能力,即使模型返回格式略有偏差也能自动修正。
阶段二:配图规划与生成。 系统将阶段一生成的图像描述提示词逐一传递给ComfyUI工作流(本地或云端),为每个分镜生成对应的AI插图。若使用WAN 2.1等图生视频模型,还可以将静态图像转化为动态视频片段。用户可通过提示词前缀统一控制所有画面的视觉风格,例如使用"极简黑白火柴人风格插画"作为全局风格约束。
阶段三:语音解说合成。 文案通过TTS引擎转换为自然语音。Edge-TTS提供稳定的基础语音输出,Index-TTS则支持通过上传参考音频实现声音克隆——用户甚至可以用自己的声音去解说视频。系统还支持多语言音色扩展,满足跨境内容创作需求。
阶段四:视频合成与渲染。 所有视觉片段、语音解说、背景音乐和多语言字幕按照时间轴精确对齐合成,支持竖屏(9:16)、横屏(16:9)等多种输出尺寸,适配抖音、小红书、视频号等不同平台的分发需求。
2.3 原子化能力组合:从"一键生成"到"深度定制"
Pixelle-Video的核心设计哲学,是将每个生成环节都视为可被独立替换的原子化能力模块。这构成了一条完整的"可替换链":文案环节支持GPT系列、通义千问、DeepSeek、Ollama本地模型等任意LLM自由切换;图像环节可本地运行Stable Diffusion、FLUX,或调用云端RunningHub服务;语音环节可在Edge-TTS、Index-TTS及自定义声音克隆之间灵活选择;视觉模板环节则可根据需求切换static_(纯文本样式)、image_(AI图片背景)、video_(AI视频背景)等不同系列。
这种设计同时满足了小白用户的一键出片需求和高级用户的深度定制需求——前者只需在下拉菜单中做出选择,后者则可通过修改ComfyUI工作流JSON文件和HTML模板文件,打造完全个性化的视频生产管线。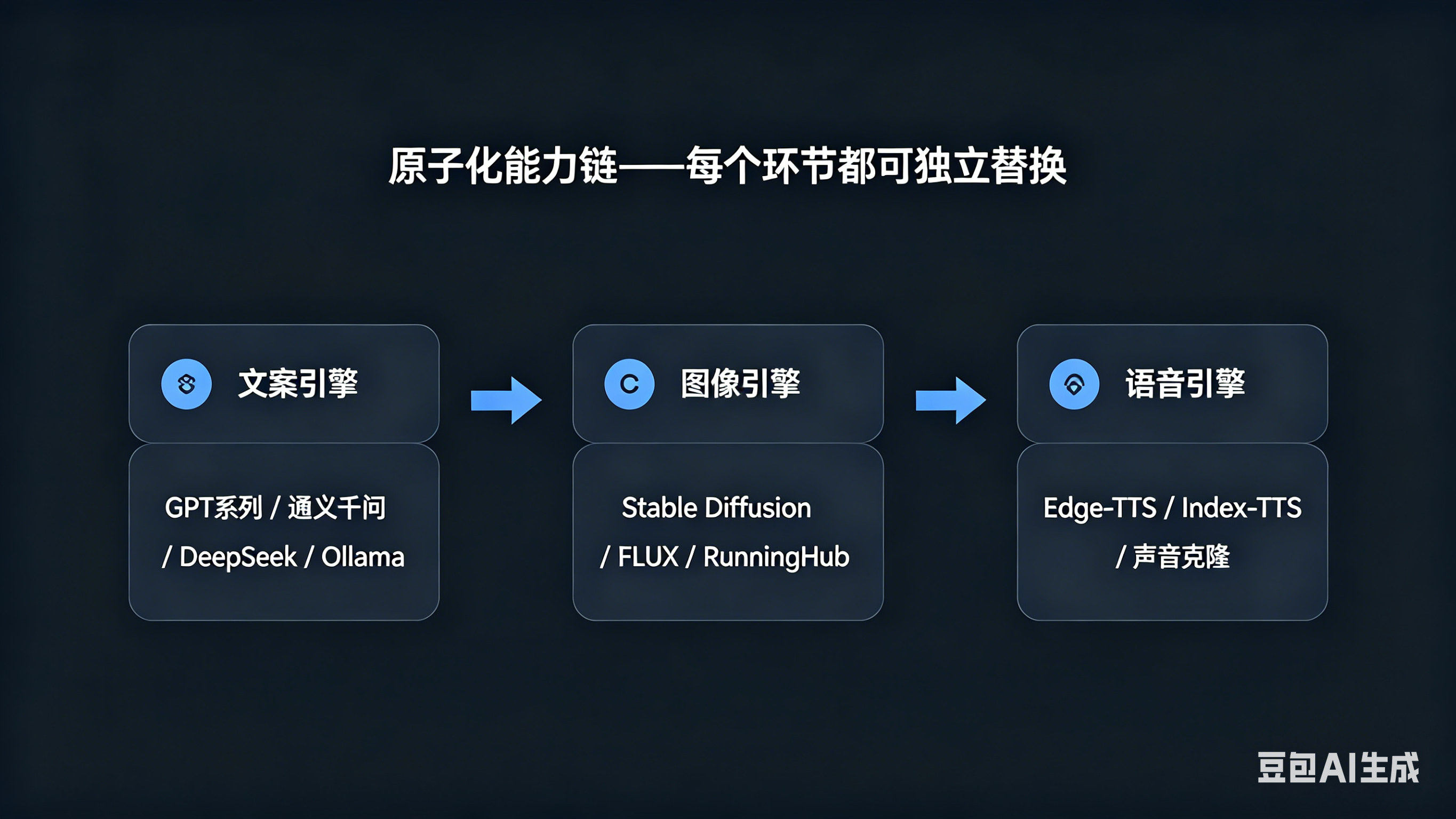
三、落地实践:从零到第一支AI视频
3.1 多路径部署方案
Pixelle-Video为不同技术背景的用户提供了分层式的部署选择:
| 部署方式 | 适用人群 | 核心要求 |
|---|---|---|
| Windows一键整合包 | 零基础用户 | 解压即用,双击start.bat启动 |
| Docker部署 | 追求环境隔离的用户 / 服务器长期运行 | 需安装Docker与Docker Compose,项目自带docker-compose.yml,支持国内镜像加速 |
| 源码安装 | macOS/Linux/深度定制用户 | 需预装uv和ffmpeg,执行uv run streamlit run web/app.py |
💡 提示:Pixelle-Video 提供了完整的 Docker 支持,项目根目录自带
docker-compose.yml,启动命令为docker compose up -d,Docker Hub 上亦有镜像aidcai/pixelle-video。在国内网络环境下构建时,建议开启USE_CN_MIRROR=true环境变量切换阿里云镜像源加速;若遇 Playwright(无头浏览器渲染依赖)安装超时,可临时注释掉 Dockerfile 中的playwright install --with-deps chromium行,先完成主服务构建后再手动安装。
3.2 成本方案选择指南
Pixelle-Video的一大核心亮点是完全支持免费运行:
| 方案 | LLM | 图像生成 | 成本 |
|---|---|---|---|
| 完全免费 | Ollama本地模型 | ComfyUI本地部署 | 0元 |
| 推荐 | 通义千问API | ComfyUI本地部署 | 极低 |
| 云端 | OpenAI API | RunningHub云端 | 按量付费 |
免费方案需要本地NVIDIA显卡支持,推荐方案则无需本地高端GPU,仅产生极低的API费用。
3.3 通过API集成自动化管线
除了Web界面,Pixelle-Video还提供了RESTful API,便于将视频生成能力嵌入自动化内容生产流水线。API 文档基于 Swagger UI 提供,具体访问地址请参考项目 api/ 目录下的路由配置。以下是一个Python调用示例:
# Pixelle-Video 提供 FastAPI 驱动的 REST API,接口定义位于项目源码 api/routers/ 目录下
import requests
response = requests.post(
"http://localhost:8501/api/video/generate",
json={
"text": "人工智能正在重塑内容创作产业",
"mode": "fixed",
"frame_template": "1080x1920/image_default.html",
"template_params": {
"accent_color": "#2ecc71",
"font_size": 48
}
}
)
对于批量任务或长视频,推荐使用异步接口,通过task_id轮询或webhook回调获取结果。
四、功能全景:覆盖视频创作全生命周期
4.1 功能矩阵
Pixelle-Video的功能体系覆盖了视频创作的每一个环节,形成完整的自动化闭环:
| 功能模块 | 能力说明 | 技术实现 |
|---|---|---|
| AI智能文案 | 根据主题自动生成结构化脚本;支持固定文案输入模式 | LLM配置(支持多模型) |
| AI配图/视频生成 | 每句文案配AI插图;支持WAN 2.1等模型生成动态视频 | ComfyUI工作流 |
| 智能语音合成 | 多TTS引擎支持;声音克隆;多语言音色 | Edge-TTS/Index-TTS |
| 动作迁移 | 将参考视频的动作模式迁移到AI生成内容 | 2026年1月新增模块 |
| 数字人口播 | 支持自然语言驱动的数字人驱动与口型同步 | 2026年1月新增流水线 |
| 背景音乐 | 内置BGM库;支持自定义音乐上传 | FFmpeg音频混流 |
| 视觉模板 | 竖屏/横屏/方形多尺寸;HTML模板可定制 | 模板命名规范:static_/image_/video_ |
4.2 能力演进轨迹
从2025年11月开源至今,Pixelle-Video保持着高密度的功能迭代:
- 2025-11-18:RunningHub并行处理、历史记录、批量任务
- 2025-12-04:自定义素材功能(上传照片/视频,AI智能分析生成脚本)
- 2025-12-17:ComfyUI API Key配置、Nano Banana模型支持
- 2026-01-14:数字人口播、图生视频流水线、多语言TTS音色
- 2026-01-26:动作迁移模块(上传参考视频和图片进行动作迁移)
这一演进轨迹清晰展现了项目团队的战略方向:将核心能力与外部功能模块同步推进,尤其是数字人播报和图生视频两条新流水线,分别瞄准了口播类短视频和动态视觉内容两大高需求场景,既覆盖了当下最热门的短视频形态,又保持着对前沿技术的快速跟进。
五、真实体验:优点、局限与选型策略
5.1 效率革命的真实肌肉
通过在本地部署ComfyUI + Ollama的组合进行实测,Pixelle-Video在以下维度表现突出:
-
全流程无人值守:基于本地典型配置(NVIDIA RTX 4060 + Ollama + ComfyUI)的测试观察,从输入主题到 MP4 输出约需 3–5 分钟,而相同内容的传统制作流程(文案、素材、配音、剪辑)通常耗时 1–2 小时,效率提升幅度显著。此数据为笔者实测结果,非项目官方基准测试,实际表现可能因硬件与模型选择而异。
-
多场景适配能力:教育场景可自动生成结构化课程脚本和知识卡片;跨境营销场景支持多语言TTS和字幕一键转换,将多语言版本制作从2天压缩至8分钟;企业培训场景支持数字人形象复用和批量内容更新。
-
零专业设备依赖:普通笔记本电脑即可流畅运行完整功能,无需图形工作站或视频采集设备。
5.2 需要正视的边界
在推崇这项工程成就的同时,必须诚实分析其局限:
- 硬件与算力门槛:本地方案需要NVIDIA显卡支持复杂工作流(WAN 2.1等图生视频模型对显存要求较高,部分大模型需要H100级别硬件才能运行),低配机器可能只能运行基础文生图流程。
- 生成质量的概率性波动:AI生成的文案和画面存在随机性,偶尔出现图文不匹配或风格偏移,需要多次生成或手动微调提示词来优化。
- 高度定制的学习成本:从"一键生成"到"深度定制"之间存在技能跃迁——自定义ComfyUI工作流和HTML模板需要额外的技术学习投入。
- 版权合规风险:AI生成内容(尤其是通过文生视频模型和音乐)的版权归属尚未在全球范围内形成统一法律共识,商用前需谨慎评估具体场景的法律风险。
5.3 选型决策框架
| 场景类型 | 推荐方案 | 理由 |
|---|---|---|
| 知识科普/产品介绍/日常更新 | ✅ 强烈推荐 | 自动化程度匹配需求,效率提升最显著 |
| 品牌广告/影视级作品 | ⚠️ 谨慎使用 | 视觉一致性要求高,需要精细人工后期 |
| 个人创作者/自媒体 | ✅ 推荐免费方案 | Ollama本地LLM + ComfyUI本地部署 = 0成本 |
| 企业团队/批量生产 | ✅ 推荐API方案 | RESTful API支持自动化管线集成 |
推荐工作流:使用Pixelle-Video快速生成多个视频草稿 → 人工筛选和微调文案与画面 → 使用传统剪辑软件进行最终精剪和包装。将AI作为创意激发和初稿生产的前端,人工进行质量把控和艺术升华。
六、从"界面"回归"流水线"
Pixelle-Video的核心价值,不在于任何一个单独的AI模型,而在于它将文案、配图、语音、合成这四个原本割裂的生产要素,通过模块化架构和原子化能力组合的设计,整合为一条可配置、可扩展的自动化流水线。
它不要求用户成为AI专家,也不要求用户具备剪辑技能。它真正做到的,是把视频创作的定义从"操作一个复杂的软件"下沉为"提出一个清晰的创意命题"。在短视频吞噬互联网注意力的时代,这种范式转换可能比任何单一模型的性能提升都更具有生产力解放的意义。
从IDE里的自动补全,到浏览器里的全自动视频工厂,AI的触角正在从代码层延伸到内容层。Pixelle-Video不是这一趋势的终点,但它无疑代表了一个正确的起点——让技术退到幕后,让创意回到台前


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 17
17 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)