开发日志4-RAG知识库构建step1-爬取数据+清洗
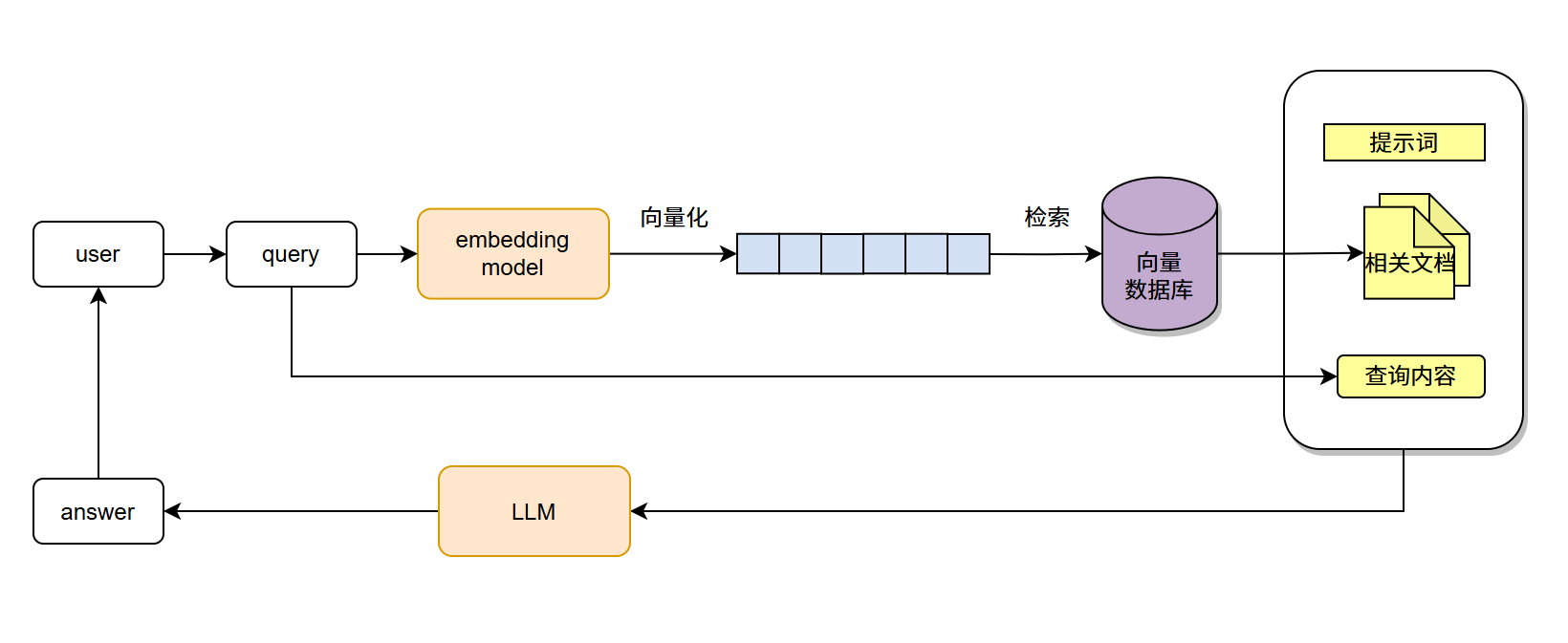
首先说明RAG工作原理:我们将收集到的资料(包括文本、网页、图片等)用embedding模型编码成向量存储到向量数据库中;之后用户在与模型的交互中,系统会将用户的搜索内容编码成向量,并查询向量数据库,比较查询向量和数据库向量之间的相似度,并返回最相似的几条数据。然后把这些相似数据和用户问题一起发送给大模型,模型将结合以上内容返回给用户最终答案。
绘制了一张RAG流程图助于理解:
为了构建知识库,我们首先需要收集资料,这里我选取的目标内容是和408考研强相关的权威笔记,不会覆盖和考点无关的内容。
一、爬取数据
1.首先将导航性博客源码保存在hub_page.html文件中,然后通过利用 BeautifulSoup 遍历 DOM 树,识别标签作为科目分类,并提取其后具体的笔记链接,实现动态分类与链接收集;

收集到链接后将其存在course_links变量中。
观察csdn博客源代码可以发现博客的内容被包裹在id为content_views的<div>标签中:
![]()
于是在爬取数据的时候我们只需要爬取此div中的内容即可,并把网页代码转换成纯文本 Markdown,无格式垃圾,可以用于RAG向量库。

这里我设计了双层循环(按科目、按文章),自动创建相应的科目文件夹,自动清理文件名中的非法字符,爬取url网页内容,并在写入Markdown文件时,在头部动态注入原始 URL 以便未来溯源。之所以选择生成.md文件是因为:
Ⅰ.Markdown是带有标题标签的,比如一级标题#,二级标题##等等,为后续进行段落识别以及切片提供了便利。
Ⅱ.避免了html文件中冗余的标签和其他噪音。
2.解决反爬
这里需要说明的是在一开始使用原生的 requests进行爬取:
![]()
但频繁报错,这是因为目标网站部署了反爬虫防火墙,检测到了无头浏览器的异常并发请求,从而返回521状态码并抛出JS逆向挑战,导致原生请求库崩溃:
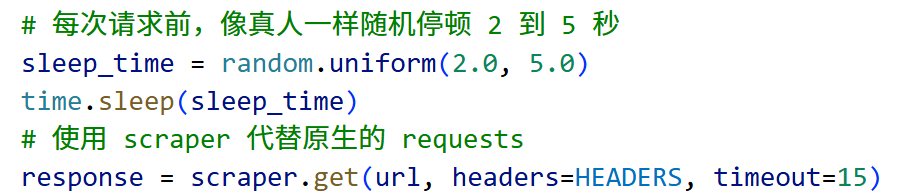
解决方法是引入了专门绕过 521 防护盾的 cloudscraper 模块替代原生请求,并在请求头中补充了更加逼真的 User-Agent 与 Referer,同时在代码中加入了随机休眠机制模拟真人阅读节奏:

3.运行结果展示与说明
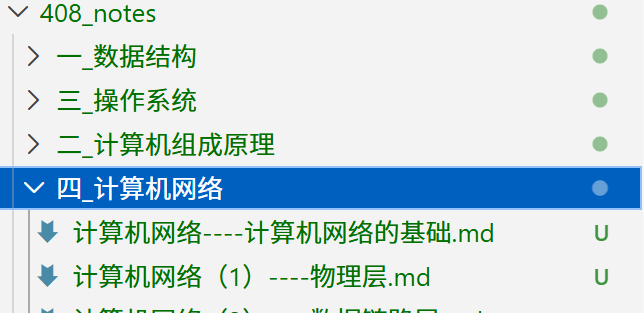
执行批量爬虫脚本后,项目根目录下成功生成了结构化的 408_notes/ 语料库目录。系统自动创建了四个子文件夹,后续向量数据库按可 Collection隔离数据;所有的笔记被分别保存为 .md文件,文件内不存在冗余的网页侧边栏或广告节点以及推荐链接,只有纯粹的知识点文本、层级标题以及被保留的图片描述标签。
二、数据清洗
1.粗清洗
爬取的数据中除了纯文本知识外,还包括图片,对于图片在上一步爬取时我们是将其URL保存了下来,对于图片的处理我们将在后面介绍,这里先介绍粗清洗工作,粗清洗时略过了对图片的处理。
(1)首先清除每篇博客开头自动生成的目录,这部分是噪音,知识库完全用不到:
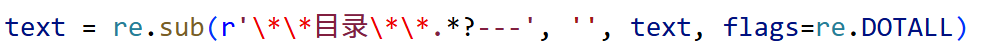
(2)然后把公式图片还原成文本公式,避免数学公式丢失。这步主要是由于网站为了防盗版和兼容老旧浏览器,为公式增加了视觉包装,把公式变成了图片。而我们写爬虫清洗数据,就是要把这层视觉包装撕掉,否则直接传递给模型会造成干扰。
清洗前:

清洗后:
![]()
(3)洗掉属于文本噪声的多余的 * # > - 等格式符号(严格限制必须只处理行首部分,避免将真正有意义的符号,比如a*b中的乘法符号*清洗掉);
(4)标题层级归一化
(5)去除连续空行,将连续3行空白行替换成1个空白行
2.人工复检
由于生数据的书写不规范等外在原因,有些地方很难用程序统一处理,需要人工检查做出细小的调整,不过这项工作并不多,因为大部分已经在程序中完成了。
(1)标题层级检查:有的四级标题下又出现了三级标题,有的没必要分层级......这对于之后切块时以标题层级为界限是灾难性的,需要手动修改一下。
(2)噪音文本:正文中含有作者的介绍性语言,比如“上一节我们介绍了...这一节我们继续...”这种语言,这种文本一般在最开头处,直接删掉就好。
3.图片处理
对于图片处理主要想到了三个解决方案:
(1)直接删图片只留文字:这种方案虽然简单,但对于文字部分没能解释清楚图片的数据来说效果非常差,造成RAG 知识库知识点残缺,用户问流程、对比、结构类问题完全答不上。
(2)给图片加一句人工语义描述:爬虫保留图片占位标记,在人工复检的时候,给每张关键配图下面加一行文字备注,比如: 【配图:操作系统进程五状态转换流程图,包含新建/就绪/运行/阻塞/终止五大状态及转换触发条件】。但这个方案工作量太大,因为爬取的数据量还是比较大的。
(3)使用多模态RAG:传统RAG只会读文字,不会看图。而多模态RAG能够让RAG系统同时拥有读+看的能力,把看到的内容用文字描述出来,同时运用“看”和“读”的信息回答问题。它用OpenAI的Vision模型(比如LLaVA)自动生成图片描述,把图片内容变成“可检索的文本”,然后把所有文本块和图片描述都转成向量(embedding),统一放进向量数据库。用户提问时,先把问题也转成向量,然后在向量库里找最相关的内容(不管是文本还是图片描述),最后把这些内容喂给大模型生成答案。
4.图片处理-多模态RAG:
这里我采用第三种方案对图片进行处理,选用的是视觉理解模型qwen3-vl-plus,具体步骤如下:
(1)登陆阿里百炼平台,创建我的API-KEY

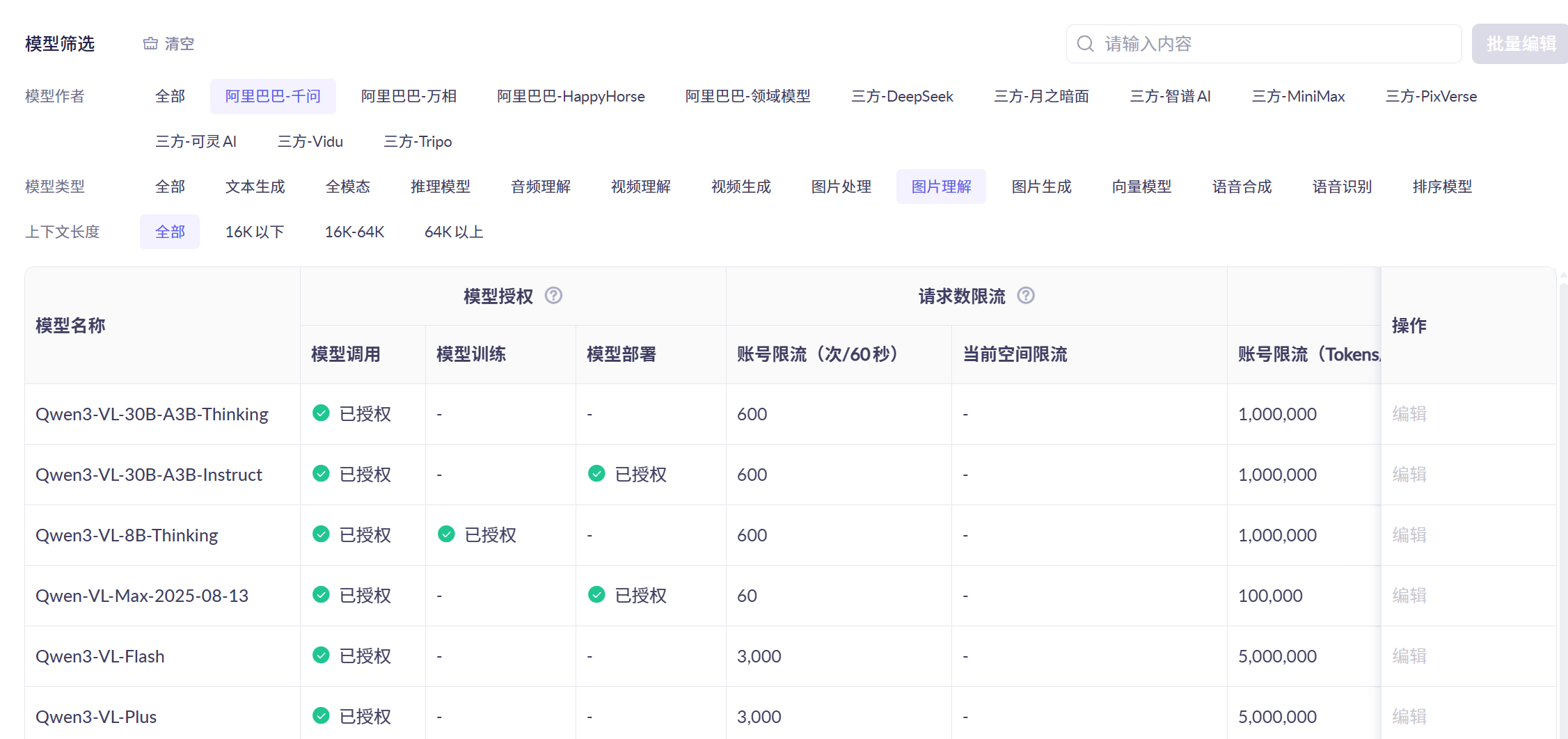
(2)访问业务空间管理界面,选择需要的模型编辑权限并保存
(3)在代码中进行API配置和地域配置

(4)开始调用模型生成图片理解,这里适配的是dashscope,如果用openai请具体参考阿里云文档

(5)说明一下实践过程中遇到的坑:
报错1:
[⚠️ 解析失败] 无效响应: {"status_code": 403, "request_id": "832e7425-b0ba-9f54-bce4-e50e683c9b8c", "code": "AccessDeni...
上面这个403错误是由于地域访问限制,我们需要确认 API Key 与 URL 地域匹配(北京 API Key 必须用北京 URL,新加坡同理),配置合适的base_url,正如上面(3)中配置的那样。
报错2:

这是由于输入的message不匹配导致的,之前的message格式是:
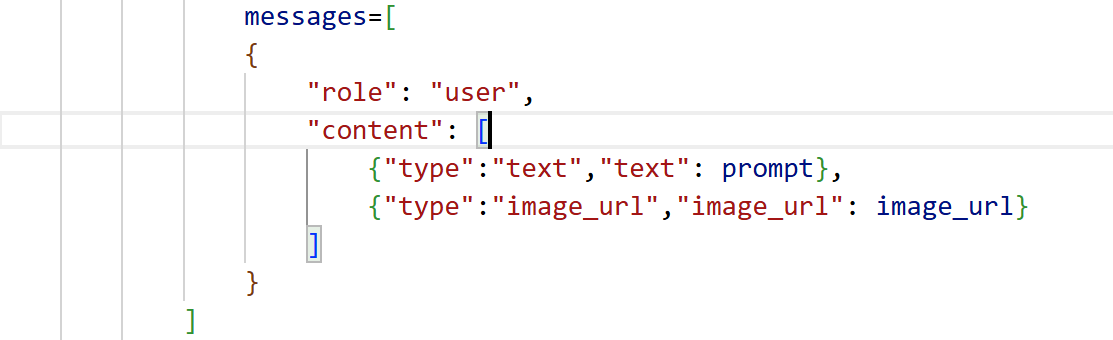
上面这个格式其实适配的是openai,dashscope正确格式应该如下:

(6)成功运行结果:
控制台输出:
运行效果:
处理前:

处理后:

处理完所有数据后我们可以进入切块步骤了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)