LangChain:流式传输
在聊天模型应用中,响应速度直接影响用户体验。试想,如果你问模型一个问题,等待了 20 秒才看到完整回答,难免感到焦虑。流式传输正是解决这一痛点的利器:它允许模型在生成内容的同时逐步输出,而不是一次性返回所有结果。本文将带你从基础用法到深层原理,全面掌握 LangChain 中的流式传输。
1、流式 vs 非流式
传统的 .invoke() 调用属于非流式传输。模型在内部完整地生成答案,然后一次性返回给用户。如果生成内容很长(比如一个 1000 字的笑话),可能要盯着白屏等待许久。
代码示例:
model = ChatOpenAI()
response = model.invoke("讲一个1000字的笑话")
# 等待约 20 秒后,一次性返回全文而流式传输则不同。例如 DeepSeek 客户端默认使用流式返回,它一边生成一边显示,等待时间被切分成极短的间隔,用户能立即看到内容,体验显著提升。
LangChain 的聊天模型同样支持流式返回,提供了 .stream()(同步)和 .astream()(异步)两种方法。
2、同步流式传输:.stream()
.stream() 方法返回一个迭代器,该迭代器会在生成输出时同步产出消息块(chunk),可以逐块处理并实时展示给用户。
基础示例:
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(model="deepseek-chat")
chunks = []
for chunk in model.stream("讲一个100字的笑话"):
chunks.append(chunk)
print(chunk.content, end="|", flush=True)输出效果(用竖线分割每个块):

这里每个 chunk 都是一个 AIMessageChunk 对象,它是 AIMessage 的片段版本。这些片段甚至可以直接相加:
print(chunks[0] + chunks[1] + chunks[2] + chunks[3] + chunks[4])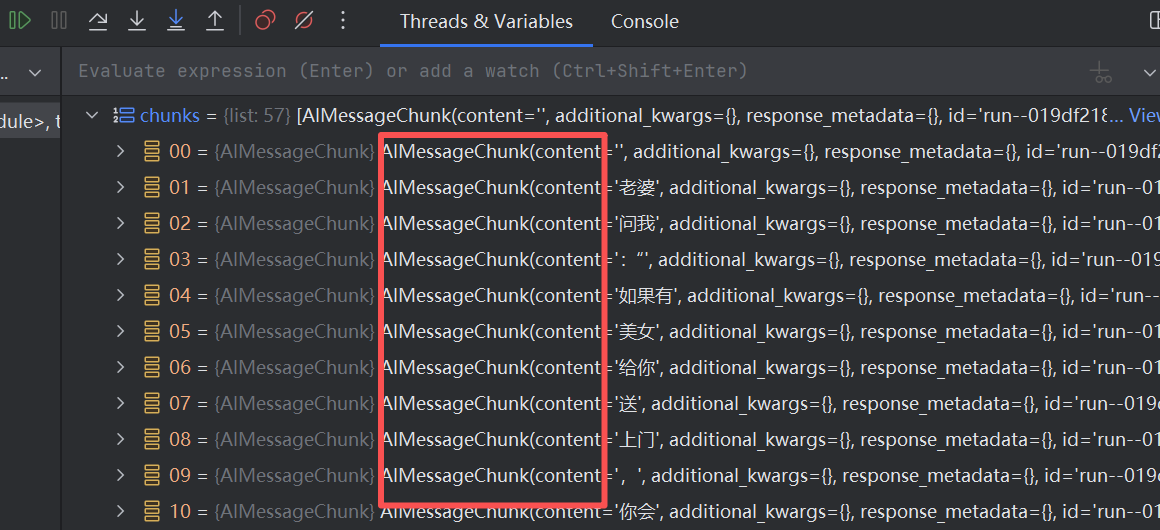
叠加后的内容会拼接起来,方便后续合并处理。
3、异步流式传输:.astream()
在构建高性能应用时,我们往往希望使用异步 IO 来避免阻塞。LangChain 提供了异步版本的 .astream(),结合 Python 的 asyncio 可以实现非阻塞的流式调用。
3.1、为什么要异步?—— 协程与事件循环
在讲解代码之前,先通过一个生活例子来理解同步和异步的区别。
假设你需要“煮一壶水”(耗时 5 秒)并且“给朋友发一条短信”(耗时 2 秒)。
同步方式:一件一件做,总耗时 7 秒。在烧水的 5 秒内,CPU 空闲却不能去做发短信的任务,效率低下。
import time
def boil_water():
print("开始煮水...")
time.sleep(5) # 阻塞等待
print("水开了!")
def send_message():
print("开始发短信...")
time.sleep(2) # 阻塞等待
print("短信发送成功!")
def main():
boil_water()
send_message()
main() # 总耗时约7秒异步方式:使用 asyncio 和协程(async/await)。当某个任务遇到 await 等待时,它会主动让出控制权,事件循环会去执行其他任务,这样总耗时约等于最长的单个任务时间(5 秒)。
import asyncio
async def boil_water_async():
print("开始煮水...")
await asyncio.sleep(5) # 让出控制权,不阻塞
print("水开了!")
async def send_message_async():
print("开始发短信...")
await asyncio.sleep(2) # 让出控制权
print("短信发送成功!")
async def main():
task1 = asyncio.create_task(boil_water_async())
task2 = asyncio.create_task(send_message_async())
await task1
await task2
asyncio.run(main())输出顺序大概为:

关键概念:
协程(coroutine):用
async def定义的函数,可以在执行中暂停并恢复,是用户态的轻量级任务。事件循环(event loop):
asyncio的核心,像一个待办事项管理器,循环检查所有任务,遇到等待的就暂停该任务、切换去执行另一个就绪的任务。
3.2、异步流式代码
了解了异步机制,再来看 .astream() 的用法就简单了
from langchain_deepseek import ChatDeepSeek
import asyncio
model = ChatDeepSeek(model="deepseek-chat")
async def async_stream():
print("=== 异步调用 ===")
async for chunk in model.astream("讲一个50字的笑话"):
print(chunk.content, end="|", flush=True)
asyncio.run(async_stream())输出效果:

在异步环境中(如 FastAPI 的 Web 服务),使用 .astream() 可以避免阻塞整个线程,是推荐的最佳实践。
4、流式传输是所有 Runnable 的能力
流式传输并不是聊天模型的专属能力。实际上,所有实现了 LangChain Runnable 接口的组件都具备 .stream() 和 .astream() 方法。Runnable 标准接口支持:
-
invoke:单输入 → 单输出
-
batch:多输入批量处理
-
stream:流式传输输出块
-
inspect:查看输入输出模式
-
compose:用
|管道符组合多个 Runnable
因此,可以将模型与输出解析器组合成一条链(Chain),这条链整体也是一个 Runnable,同样支持流式。
4.1、使用 StrOutputParser 解析流式输出
当我们直接流式传输聊天模型时,得到的是 AIMessageChunk 对象。但通常我们只关心文本内容。StrOutputParser 能自动从每个 chunk 中提取出纯文本字符串,让流式处理更加流畅。
from langchain_deepseek import ChatDeepSeek
from langchain_core.output_parsers import StrOutputParser
model = ChatDeepSeek(model="deepseek-chat")
parser = StrOutputParser()
chain = model | parser
for chunk in chain.stream("写一段关于爱情的歌词,需要5句话"):
print(chunk, end="|", flush=True)输出效果:

现在每个块都是字符串,可以直接拼接显示
5、自定义流式解析器:按句子输出
默认情况下,流式返回的块大小不确定,可能是单个字符或几个字。如果希望按句子为单位进行流式输出,可以编写自定义的生成器函数,并嵌入到链中。
生成器的签名应为:Iterator[Input] -> Iterator[Output],异步版本则用 AsyncIterator。
下面实现一个按中文句号 . 分隔的自定义解析器:
from langchain_deepseek import ChatDeepSeek
from langchain_core.output_parsers import StrOutputParser
from typing import Iterator, List
model = ChatDeepSeek(model="deepseek-chat")
parser = StrOutputParser()
# 自定义生成器:将字符流组合成句子列表
def split_into_list(input_stream: Iterator[str]) -> Iterator[List[str]]:
buffer = ""
for chunk in input_stream:
buffer += chunk
while "。 " in buffer:
index = buffer.index("。 ")
sentence = buffer[:index].strip()
yield [sentence] # 产出一个句子
buffer = buffer[index+1:] # 保留剩余部分
if buffer.strip():
yield [buffer.strip()] # 产出最后的部分
chain = model | parser | split_into_list
for chunk in chain.stream("写一份关于爱情的歌词,需要5句话,每句话用句号分割"):
print(chunk, end="|", flush=True)输出效果(每个 chunk 是一个包含一句话的列表):
['你像晨光落进我眼底,把暗夜都推向潮汐']|['心跳的密语缠成线,系在无名指的缝隙']|['风穿过发梢的季节,你的温度是唯一答案']|['所有风景都退成模糊,你是清晰的那句诺言']|['后来日落沉入海平线,我们的故事还在写。']|
通过这种方式,可以灵活地按照业务需求控制流式输出的粒度
6、深度探索:LangChain 流式传输的底层协议
上面我们学会了如何使用流式传输,但是否好奇:LangChain 是怎样实现流式的?它依赖什么协议?
6.1、SSE(Server-Sent Events)协议简介
HTTP 是无状态的请求-响应协议,本不支持服务器主动推送数据。SSE 是一种基于 HTTP 的轻量级实时通信技术,允许服务器向客户端单向推送事件流。
核心特性:
基于标准 HTTP/HTTPS,无需额外端口,兼容性好。
单向通信:服务器 → 客户端持续发送数据。
自动重连:连接中断时客户端可自动重连。
报文格式:服务端响应头设置
Content-Type: text/event-stream,数据由若干消息组成,每个消息以\n\n分隔,消息内部行格式为field: value。
常见字段:
data:数据内容(必需)
event:自定义事件类型(可选,默认为message)
id:数据标识符(可选)
retry:重连间隔(可选,单位毫秒)
6.2、LangChain 如何使用 SSE?
LangChain 本身并不创造底层协议,它复用了各大模型提供商原有的流式能力。以 OpenAI 为例:
-
发起 HTTP 请求:LangChain 内部集成了 OpenAI Python SDK,定义了一个 HTTP 客户端(
_SyncHttpxClientWrapper),向https://api.openai.com/v1发起请求。 -
开启流式模式:在请求参数中设置
stream=True(见_stream()源码第一步),告知 OpenAI 服务器用 SSE 格式返回数据。 -
接收 SSE 数据块:服务器保持连接,以 SSE 格式持续推送 JSON 块。
-
转换为 LangChain 内部格式:LangChain 通过
_convert_chunk_to_generation_chunk()和_convert_delta_to_message_chunk()方法,将 OpenAI 的原始块转换为AIMessageChunk对象。转换过程会根据delta中的role和content等信息,创建对应的消息块(如AIMessageChunk、ToolMessageChunk等),还能处理函数调用、工具调用等高阶功能。
总结链路:
用户调用 .stream()
→ LangChain 构造 HTTP 请求(stream=True)
→ OpenAI API 以 SSE 格式返回事件块
→ LangChain 逐块接收并解析
→ 将每个块转换为 AIMessageChunk
→ 通过迭代器逐个产出给用户代码
这意味着,无论底层的模型提供商是 OpenAI、Anthropic 还是其他,LangChain 都能以统一的消息块形式呈现流式结果,方便开发者无缝切换或集成。
7、总结
流式传输显著提升用户体验,让模型一边生成一边显示。
.stream() 提供同步迭代器,适合简单脚本或测试。
.astream() 结合 asyncio 实现异步非阻塞流式,适合生产环境的 Web 应用。
流式是 Runnable 接口的通用能力,用 | 组合的链同样支持流式;StrOutputParser 可将消息块转换为纯文本流。
自定义解析器可以按业务需求调整输出粒度(如按句子、段落输出)。
底层上,LangChain 通过 SSE 协议接收模型提供商的流式数据,并在内部转换为 AIMessageChunk,实现了跨提供商的统一流式处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)