软考(系统架构师)-论DDD领域驱动设计及其应用
摘要
2025 年初,我所在小组承担了某招聘管理系统项目的研发工作。该项目面向企业提供用工规划、候选人管理、招聘流程跟踪、人才沉淀、数据监控等服务,覆盖从候选人沟通、简历评估、笔试面试、Offer 发放到入职的全招聘生命周期,支持多租户、流程自定义、权限管控与可视化报表,业务复杂度高、迭代速度快,传统数据驱动开发模式难以满足长期演进需求。
我在项目中担任系统架构师,主导技术架构设计与落地,全面引入领域驱动设计(DDD)方法论:通过事件风暴完成业务领域梳理,合理划分核心域、支撑域与通用域,拆分为职位、候选人、招聘流程、Offer、面试、AI、报表、审批、用户权限等11 个限界上下文;完成核心聚合、实体、值对象、领域服务的战术建模,建立基于领域事件的异步解耦机制,并通过防腐层隔离外部系统差异;严格遵循 DDD 分层架构实现代码落地,并结合实际场景做适度工程化妥协。
项目于 2025 年 12 月顺利上线,系统模块边界清晰、业务规则高度内聚、扩展性与可维护性显著提升,有效支撑复杂招聘流程快速迭代与自定义配置,降低了维护成本与新人上手难度。
正文
我所在小组承担“某招聘管理系统”项目的研发。该项目面向企业招聘用工需求,系统定位于对招聘候选人从简历入库到发放offer并入职的完整路径跟踪,用于管理候选人、管理岗位、及候选人在对应岗位的状态流转,同时在整个流转链路中,会对同关联的系统整合和对接,并且随着如今AI的发展,系统引入AI相关能力赋能招聘场景,持续积累和沉淀招聘场景下的模型能力。我担任系统架构师,主要工作包括:主导整体技术架构设计与选型;引入并落地DDD方法论;组织事件风暴讨论,梳理并设计核心域聚合模型与领域事件机制;制定DDD开发规范并参与核心模块评审并进行经验沉淀与分享。
领域驱动设计(DDD)是一种以业务领域为核心的软件设计方法论,其核心思路是“以领域为中心,用领域模型驱动软件设计,把业务复杂度从代码里搬到领域模型里统一治理”。DDD通过战略设计与战术设计两个层面,来解决传统数据驱动模式下业务规则散落、模块边界混乱,外部数据污染等问题。
战略层面的领域设计,核心是做好业务合理拆分,包含五大关键抓手:
- 统一语言:对齐业务术语和领域模型术语,消除沟通歧义;
- 子域划分:按业务价值归类为核心域、支撑域、通用域,明确资源投入的优先级;
- 限界上下文:划定业务能力的语义边界,确保边界内模型逻辑自洽、语言标准统一;
- 事件风暴:以可视化手段梳理复杂业务流程,厘清各领域间的关联关系;
- 上下文映射:定义不同限界上下文的协作交互模式,常用有共享内核、防腐层、开放主机服务、发布订阅等方式。
战术层面的领域设计,侧重在单个限界上下文内部做建模落地,依托八大核心构件:实体、值对象、聚合、聚合根、领域服务、仓储、工厂、领域事件。
其中:实体拥有唯一身份标识和完整生命周期;值对象无唯一标识、且属性不可变;聚合是保障数据一致性的最小边界;聚合根作为聚合的唯一访问入口,封装核心业务规则;领域服务负责处理跨聚合的业务逻辑;领域事件实现上下文间异步通信、完成系统解耦。
聚合设计需遵循核心原则:聚合内部采用强数据一致性,跨聚合之间采用最终一致性;对象间通过 ID 关联而非直接对象引用;尽量设计小粒度聚合;业务规则统一收拢在聚合根中,基于充血模型提升业务内聚性。
在“招聘管理系统”项目中,我们按照DDD方法论开展业务建模与系统设计,同时结合实际情况在系统设计过程中作出适当调整。
首先战略设计事件风暴过程。我邀请业务以及开发测试产品团队,大家会议室集中头脑风暴,梳理业务流程逻辑,围绕招聘生命周期线,识别出10个核心领域事件(简历交换成功、职位更新、简历评估通过、面试通过、已发放offer等)、梳理出8条业务策略(候选人与职位匹配度、不同方式添加候选人、添加职位、与招聘渠道打通等)。
其次划分限界上下文。基于事件风暴的产生,我将系统划分为11个限界上下文:核心域包括职位上下文、候选人上下文、招聘流程上下文、Offer上下文、面试上下文、AI上下文;支撑域包括报表上下文、待办上下文、审批上下文;通用域采用成熟方案,包括用户权限上下文、登陆认证上下文。划分遵循业务能力、通用语言、团队边界、变化频率四大依据,团队最强人力配置在核心域上下文上。
接着设计上下文映射。上下文间采用差异化协作模式:AI 上下文作为上游提供开放主机服务,职位、候选人上下文通过防腐层(ACL)调用,隔离外部模型差异;招聘流程上下文对待办上下文采用发布订阅模式,招聘流程变更后发布“状态变更事件”,异步更新用户待办,确保其故障不影响主流程。
然后展开核心聚合的战术设计。以Offer上下文的“Offer聚合”为例:聚合根“Offer”管理OfferID、关联候选人ID、关联招聘流程ID、offer状态等属性,封装“创建offer”、“发送offer”、“接受offer”等业务方法,业务规则内聚于聚合根;内部实体“Offer详情”由聚合根统一管理,外部不能直接访问。Offer 审批由应用层编排,通过领域事件实现 Offer 聚合与审批聚合的协同。聚合状态变更后发布“审批通过”、“审批不通过”等领域事件,通过异步消息广播给下游限界上下文,其他领域也按此模式设计。这种“聚合根+内部实例+领域事件+跨聚合协作”的模式在所有核心域上下文中得到一致应用。
最后落地DDD四层架构。整体代码遵循用户接口层、应用层(编排聚合操作)、领域层(聚合根、实体、值对象、领域服务、领域事件)、基础设施层(仓储实现、ACL适配器、消息中间件)的分层结构,确保业务核心不依赖任何技术细节。然而在实际实践过程中,基于实际考虑增加了几个薄的模块,比如api层(很干净的dubbo接口定义,对外暴露,不依赖服务其他层)、common(纯通用工具类,定义一些工具和业务枚举,所有层都可以依赖),最终整体架构如下: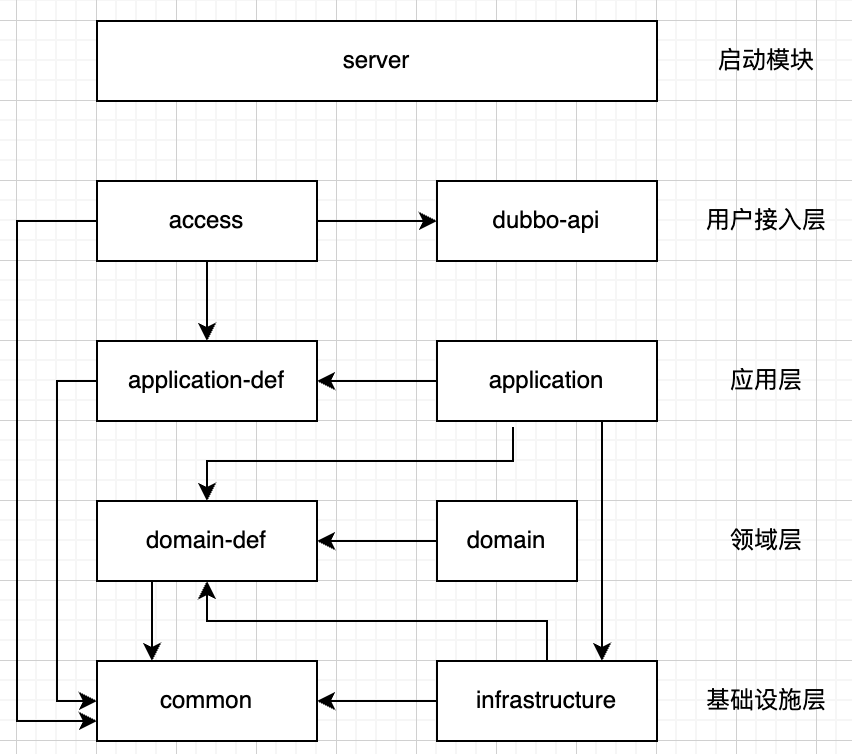
项目实施过程中主要面临两大痛点:
第一,现有应用层开发方式偏传统,采用事务脚本式的过程化编码。随着业务迭代演进,业务逻辑容易逐步散落、代码不断膨胀臃肿,系统慢慢退化成老旧架构的状态。为给只负责流程编排的应用层减负、降低整体复杂度,我们引入责任链设计模式重构逻辑编排:把聚合更新、第三方接口调用、消息推送等各类业务动作,各自封装成独立处理节点,再通过责任链串联执行。不仅逻辑链路清晰、架构层次规整,有效解决编排逻辑臃肿问题,还能实现各节点的复用。
第二,查询场景采用读写分离方案,原本严格遵循四层架构约束,要求应用层不能感知和依赖基础设施层的 PO 对象。但实际查询业务中,应用层又需要用到 PO 数据,只能由应用层定义查询接口、再由基础设施层做实现,由此引出数据转换逻辑归属不明确的问题,同时整体开发调用流程也十分繁琐。经团队评估讨论后,我们适当打破原有严格的依赖隔离规则,允许应用层直接使用 PO 实体,应用层与基础设施层之间直接复用同一套数据结构传输,简化了开发复杂度。
项目最终于2025年12月顺利上线。引入DDD后,业务规则集中可控、模块边界清晰,需求迭代更安全可控,新人上手周期缩短50%。后续随着业务推广引入“自定义招聘流程”仅需要对招聘流程域进行调整和扩展,开发和测试效率提升约40%,进一步验证了DDD在大型复杂系统长期演进方面的优越性。然而我们在实践过程中也要注意结合项目和实际情况,选择合适的技术和方法解决实际问题,必要时也可以做适当的妥协,在规范和效率之间取得平衡,切勿一股脑照搬。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)