讲讲字符编码
前言:
文章最初版本发布时间:2026-05-05 0:53
文章最新版本发布时间:2026-05-05 1:14
最近在复习javase中的io流,涉及到了字符编码的知识 ,字符编码其实很早前就学过,但是没完整的学,只是浅显的跳着学了一下,这就差点意思了,懂但不完全懂...于是,最近系统的完整的学了一遍,然后写了这篇博客。
篇幅过长,格式也没太注意(从我的笔记粘过来稍微调了一下),建议用电脑观看。
0.为什么要有字符编码:
存储在计算机中的所有数据的本质是0101这样的比特序列(在本质点就是两种不同的物理状态,可以是电荷的有无,可以是磁化方向,可以是电压的高低…),那么我们所用的汉字、英文字母、各种字符…(下文统称为字符)是如何存到计算机上的呢?从而产生了字符编码的概念。
首先需要把要存的字符转成比特序列,那这不是想转成什么序列就转成什么的,需要有一个标准,于是就有了一个叫字符集的东西,在这里面有我们需要存的字符,以及对应的序号(专业术语叫,码位),(一个字符对应一个码位,像一张表,所以也可以叫它为编码表、字符集,这篇文章统一叫它为字符集),比如我们要存汉字“我”,然后我们在字符集中寻找这个字对应的码位,查出是25105,然后将它转为二进制存到电脑中(这里不讨论如何变成物理状态的过程),(注意,字符集不是只有一个,在本篇笔记会讲到有哪些)。
接下来详细介绍都有什么字符编码标准,该标准中包括字符集和编码方式。主要以这四个方面进行讲解:
1)该标准的历史由来:
2)该标准的介绍:
3)具体的编码过程:
4)具体的解码过程:
1.ASCII标准:
1)该标准的历史由来:0中的内容。
2)该标准的介绍:
ASCII标准中规定了ASCII字符集,(字符很少,这是美国人用于解决自己国家字符存储问题做的一张表,只有美国人用的字符,没有汉字等其它字符…,至于为什么没把其它国家的字符放进去,是因为当时其它国家没普及计算机),以及编码解码方式。
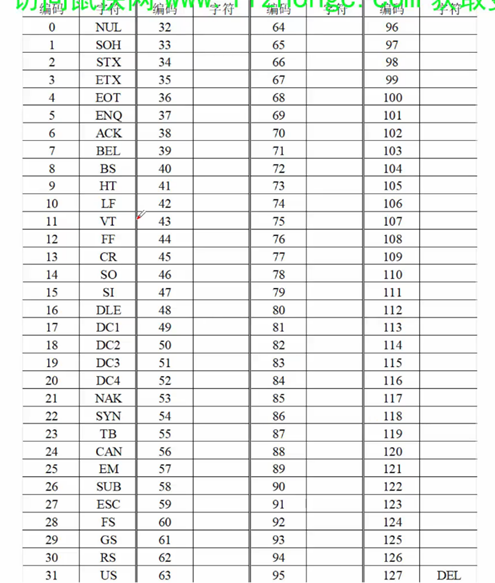
下图是ASCII字符集,图片出自BV1gZ4y1x7p7。

图片中的ASCII码就是前面讲的码位。然后为什么不用第八位,始终置为0?因为在最早期通信的时候通常是七位传输格式,编码的时候第八位通常置0或者当校验位。
2)具体编码过程:
假设我们在a.txt文件中输入“ABC”(没有双引号,下文会有类似场景,不在赘述),计算机底层会寻找这几个字符在 ASCII字符集中对应的码位,然后在计算机中存这个码位,此过程为编码。
3)具体解码过程:
假设我们编写完a.txt文件后退出,然后重新打开a.txt文件,计算机底层会在ASCII字符集中查询“xxxx…(这些是比特位)”对应哪个字符,查完显示出来,我们看到了“ABC”。
解码的过程就是编码逆过程,解码是去字符集上找对应字符,然后显示出来,编码是去字符集上找对应码位,然后存起来。
4)补充:
补充1:控制字符是换行、缩进、回车…这样的带控制功能的不可见字符。“空格”不是控制字符。
补充2:上面的ASCII字符集是美国制定的第一版字符集(也可以说是美国版ASCII字符集),但是随着其它国家的计算机开始普及后,美国版的ASCII字符集中的一些符号在其它国家不适应,它们有自己的符号,于是ISO组织就制定了ISO 646标准,这个标准中规定了原先的ASCII字符集中,33个控制字符固定不变,在95个可见字符中的某12个字符可以替换,至于是哪12个自行查阅,这种字符集也叫变种ASCII字符集。
2.ISO/IEC 2022标准与GB 2311标准:
1)该标准的历史由来:
随着计算机的进一步普及,全球各语言需要更多字符,变种ASCII字符集已经无法满足,因此国际化标准组织ISO和国际电工委员会IEC一起制定了ISO/IEC 2022标准,(下文开始简写为iso标准)。我国根据这个标准制定了GB 2311标准,规定了字符集(加了一些新的字符),规定了编码方式(遵循iso标准中的编码方式),随着技术发展,GB 2311标准中的内容逐渐落后,变为推荐标准,GB/T 2311标准。
2)该标准的介绍:
它规定了字符集框架,以及G0,G1,G2,G3区域,然后让每个国家可以规定自己的字符集,放在这些区域,意味着每个区对应一个字符集,(G0默认是放美国ASCII字符集或者是变种ASCII字符集,可见兼容了上一代的技术),(GB 2311标准中的字符集就是将一些汉字字符放到这里后的变成的新字符集)。
G0,G1,G2,G3区域可以用转义字符切换(具体的直接看下面例子去理解)。
那么,G0-G3区域中存放的字符集长什么样?下面这张图(出自BV1LvS1YnEmQ)就是字符集框架,其中,码位为33-126的就是G区(32是空格),每个国家可以把自己需要用的字符放在这里,这部分也叫做图形区,(这里的G和G0-G3中的G不是一个东西,不要弄混,所以这里我们干脆就叫它中文名——图形区),码位为0-31和127的叫控制区(C区),码位为32的既不是图形区也不是C区。控制区中的字符和32码位的字符都不可以变动。
然后解释一下双字节字符集:
因为汉字比较多,图形区中的94个位置不够用,于是就想到将两张表拼在一起(也就是说,一个字符用两个字节去表示),这样的话可以表示94×94=8836个字符/汉字。这个不是意味着我占两个G区(比如占了G1和G2),占的区还是一个(比如G1),可以想象为G1区对应两个字符集(即两张表),所以两个码位对应一个字符/汉字。
3)具体的编码过程:
直接上例子,下面这个例子是“ABC你好”的编码例子。也就是说,当我们输入“ABC你好”的时候会编码为如下二进制。

至于这些数字的详细解释,在下面的解码过程中解释。
4)具体的解码过程:现在将我们的视角切换为计算机的视角。
解码就是编码的逆过程,根据码位找字符的过程:
a)我首先碰到了41 42 43,
第一个碰到的不是1B,而是41,意味着不需要切换G区,默认使用G0区,G0区对应的字符集是ASCII字符集,根据码位在字符集中找对应的字符,找到了,是"ABC"。
b)1B 24 29 41,
分别对应:ESC 美元符号 ) A,简单说一下这些字符的含义:ESC是切换专用字符,美元符号是双字节字符集,)是放入 G1,A是有中文的字符集,也可以说是GB 2312(这种说法有点不严谨,毕竟GB 2312是一个标准)
继续解码,我第一个碰到的是1B,意味着需要切换G区了,那我要切换到哪个区?导入哪个字符集(就是那个编码表)?,该字符集是单字节字符集还是双字节字符集?这些是根据24 29 41来判断的,也就是说,我识别到了24 29 41后我就知道了我要切换到G1区,导入有中文的字符集,该字符集是双字节字符集。
c)68 43 59 72,
继续解码,去我刚刚导入的字符集里找68 43 59 72对应哪个字符,找到了,是"你好"。
d)
后面没数字了(如果继续深究的话应该是有的,表示结束的那种标志),解码结束,ABC你好显示在屏幕上。
编码、解码部分讲完了,若想知道更细节的内容,可自行查阅学习,本人是就掌握到这里了(当作常识肯定是够用了)。
然后,下面这个是韩文编码(看一看,扩展思维),其中KSX1001就相当于韩国那边根据iso标准做的属于自己国家的标准。

5)补充:
补充1:G0默认是美版ASCII字符集或变种ASCII字符集,但是可以去更改,比如把GB 2311标准中的字符集放到G0位置。
补充2:Base64
Base64将二进制数据位每6位为一组,若有不够的,用0填充,构成的新的二进制位映射到 RFC 4648 定义的 Base64 字符集(A–Z、a–z、0–9、+、/),变为新的字符,若新字符不是四的倍数用“=”号来补充(这是规定)。
下图为具体的例子,助于理解:

Base64 不关心字符或语言,只关心原始二进制数据,与字符编码属于完全不同的领域。通过Base64编码之后得到新的字符(Asdfha这种),然后传输这些新的字符,接收端会根据base64字符集解码第一层,拿到原始比特位,然后进行第二层解码(这个就是我们上面讲的那些)。
看完后觉得base64编码没有必要,像是绕远路,其实并不是,它的出现是因为某些传输协议在进行数据传输的时候会限制码位范围,Base64 的作用就是把“码位对应的二进制”变成“安全范围内的二进制”然后进行传输,比如说早期的Email是纯ASCII通道,它在碰到控制字符对应的码位的二进制时会被吞掉或解释成命令,码位第127的二进制甚至会被过滤掉,这就会导致接收方接受的二进制数据是不全的,这样解码的时候会乱码,如果用Base64技术将码位二进制转为安全范围内的二进制的话,那就不会出现这种问题了。这个技术现在还是广泛的被应用的,再详细的自行查阅资料。除了bsse64之外还有base16等等,原理都差不多,感兴趣可自行了解。
base64的细节没必要掌握,知道有这么个技术,为什么出现了这个技术就行。
补充3:其实初期版本的ISO/IEC 2022是只有ISO组织参与并且前缀中没用IEC,因为后来ISO和IEC合并了,然后它们一起维护这个标准,因此后人认为是它们两个一起制定的标准。
3.ISO/IEC-8859标准:(简写为iso 8859)
1)该标准的历史由来:
iso 8859标准是iso 2022标准的改进版/简化版,iso 2022标准需要通过特殊的控制字符在不同字符集之间动态切换,这很麻烦,编码解码效率低。
2)该标准的介绍:
于是iso 8859标准用第八位来区分扩展字符集还是ASCII字符集,若第八位置1那么去扩展字符集找对应字符,若置0则表示ASCII字符集找对应字符。但是,该标准的设计目标只是扩展欧洲地区用的字符,无法编码汉字。
注意:ISO-8859 编码中第八位为0时,它不等价于ISO 2022,ISO-8859 第八位为0只是意味着去ASCII字符集里去找,文件里根本没有任何 ISO 2022 的转义序列和状态机概念。
iso 8859还有一些子标准,iso 8859-1到iso 8859-15,区别是扩展字符集不同,也就是意味着不同子标准支持不同语言的字符。
3)具体的编码过程:参考ASCII标准的编码过程。
4)具体的解码过程:参考ASCII标准的解码过程。
4.GB 2312标准:
1)该标准的历史由来:
该标准的主要上位标准是GB 2311标准,相当于是它的改进版。这个标准也叫ISO-2022-CN。同一时期日本韩国基于iso 2022标准制定了属于自己的标准,分别叫做ISO-2022-JP,ISO-2022-KR。
下图出自GB2312-80官方文档:

随着技术发展,GB 2312标准中的内容逐渐落后,变为推荐标准,GB/T 2312标准。
2)该标准的介绍:
这个标准内容和GB 2311标准差不多,(GB 2311标准又是参考iso 2022标准的)。简单讲一下完善的地方,提出了区号和位号,区号有94个,位号有94个,这个就是iso 2022中提到的国家可以自己定义的字符数量,由于我国汉字比较多用了两张表,也就是两个字节(在讲iso 2022时讲过),第一个字节代表区号,第二个字节代表位号,下图是具体的一个区里的字符集(图片出自GB2312-80官方文档)。

3)编码过程:
下图出自GB2312-80官方文档:

具体的参考iso 2022。
4)解码过程:
参考iso 2022。
5.收尾:
由于GB 2312标准中使用的字符集所涵盖的汉字还是不够,于是就出来了GBK标准,GBK标准所使用的字符集兼容ascii字符集并扩充了很多汉字,对于ascii字符集中的字符使用单字节编码,而汉字及扩展的字符使用双字节编码(废弃了iso 2022标准中切换字符集的那种编码方式,具体细节可自行查阅,iso 8859标准也废弃了切换字符集的那种编码方法)。后来很多少数民族也使用计算机,而字符集上没有少数民族字符,于是又出来了GB 18030标准。
但是,无论是 GB 2312、GBK 还是 GB 18030,本质上都是专门针对汉字设计的字符编码标准。由于它们未能兼顾全球其他国家的语言文字,而各国又多采用各自独立的编码体系,这种“各自为政”的局面最终导致了信息交换时的标准不统一。
于是ISO组织进行了统一,制定了Unicode标准,该标准所定义的字符集集合了世界各地语言文字,相继出现了ucs-2字符集(16位表示一个字符)、ucs-4字符集(32位表示一个字符,可表示将近43亿个字符)。该标准还定义了utf-8编码方式(它是针对ucs-4字符集的),utf-8编码方式将ucs-4字符集中的码位划分为四个区间,每个区间有对应的二进制表示模板,编码某个字符的时候需要看这个字符的码位落在哪个区间,然后使用那个区间的模板,xxx里存的是该字符对应的码位的二进制。
具体如下图(出自BV1gZ4y1x7p7):

(“王”落在第三个区间不是巧合,在utf-8编码模式中,所有汉字都落在第三个区间,即三个字节编码一个汉字)
后记:
下次可能会讲讲线路编码。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)