文献计量学工具Bibliometrix (代码+Biblioshiny)(个人笔记)(完结!)
目录
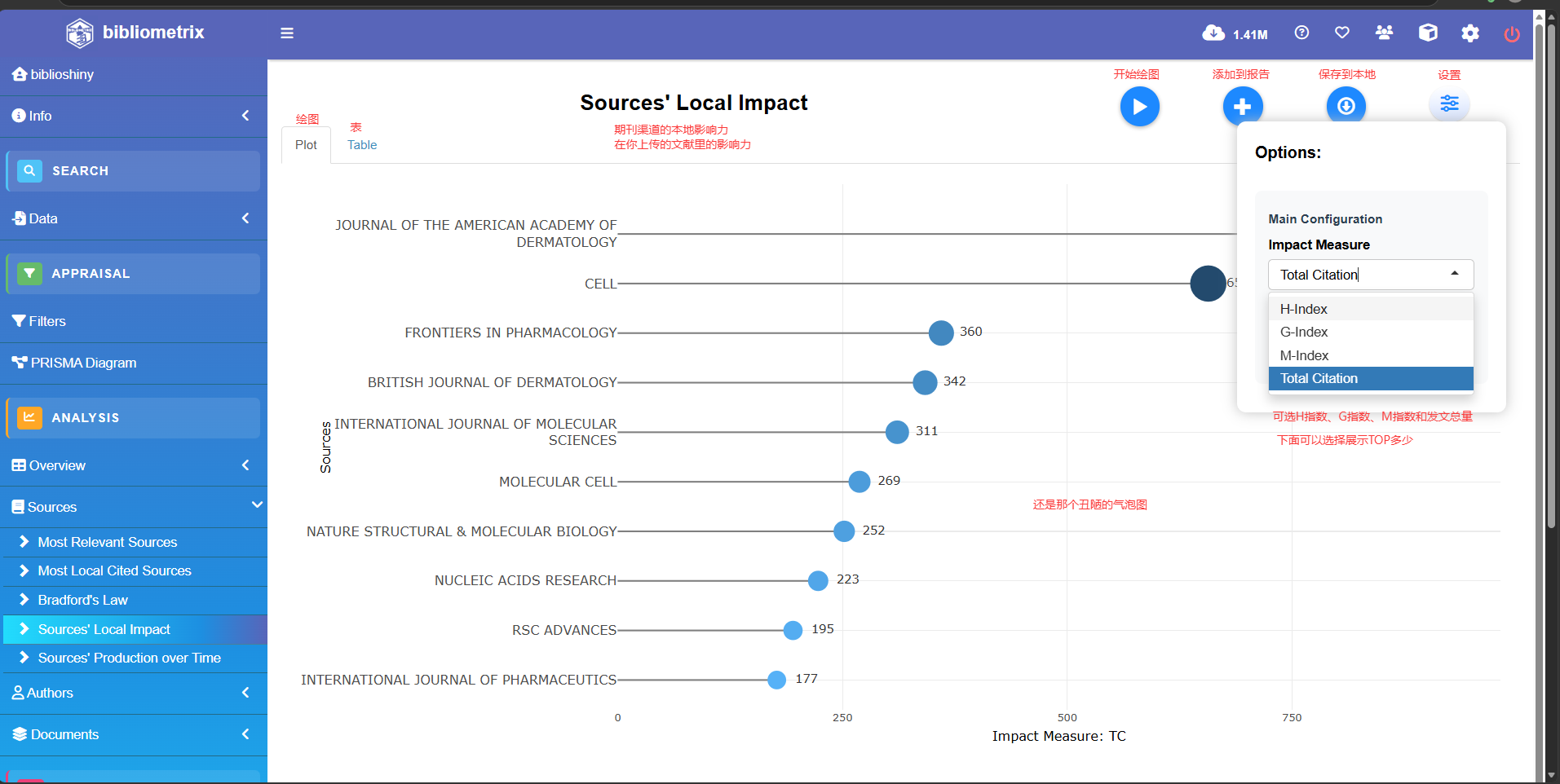
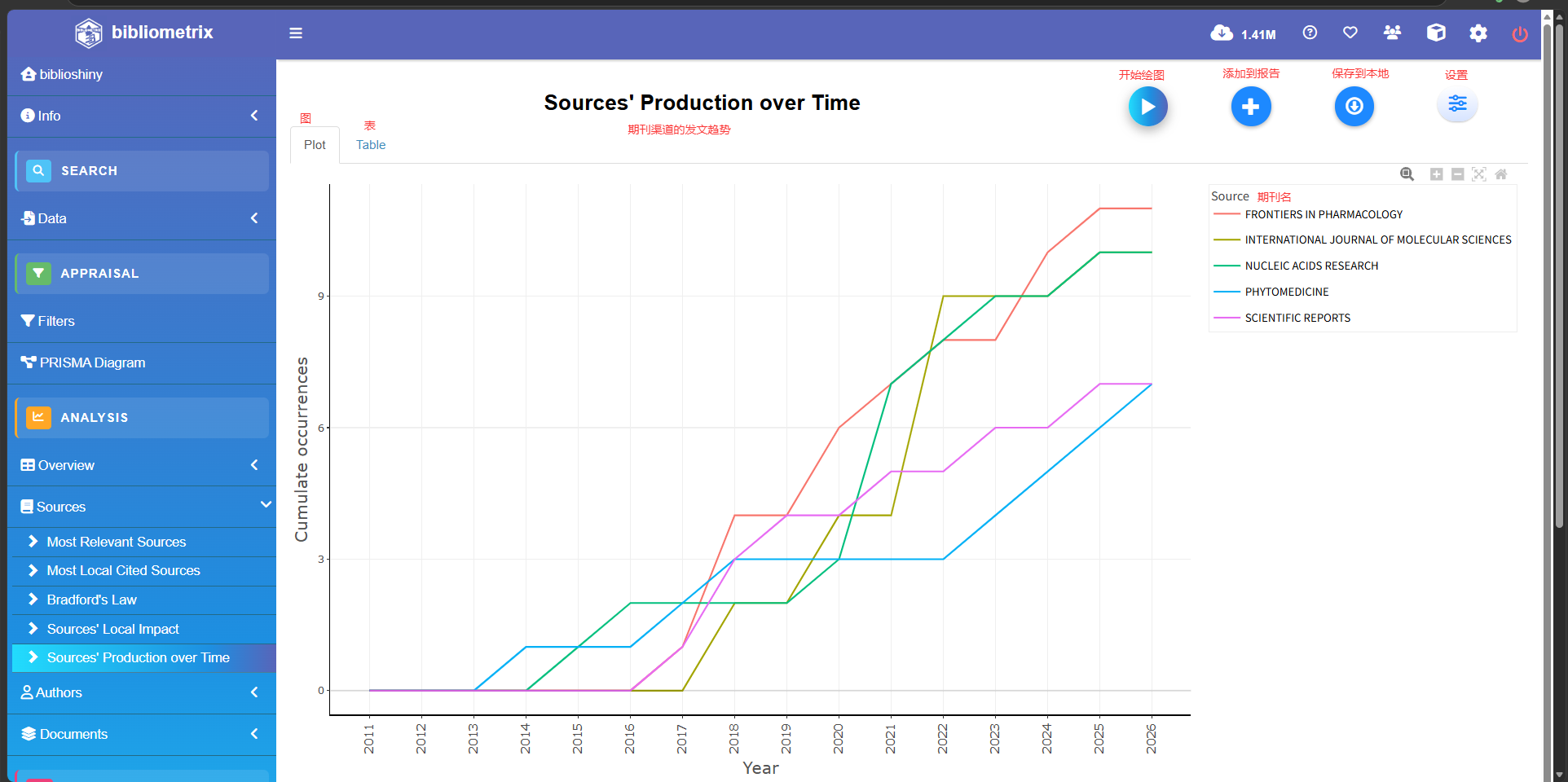
Sources's Production over Time
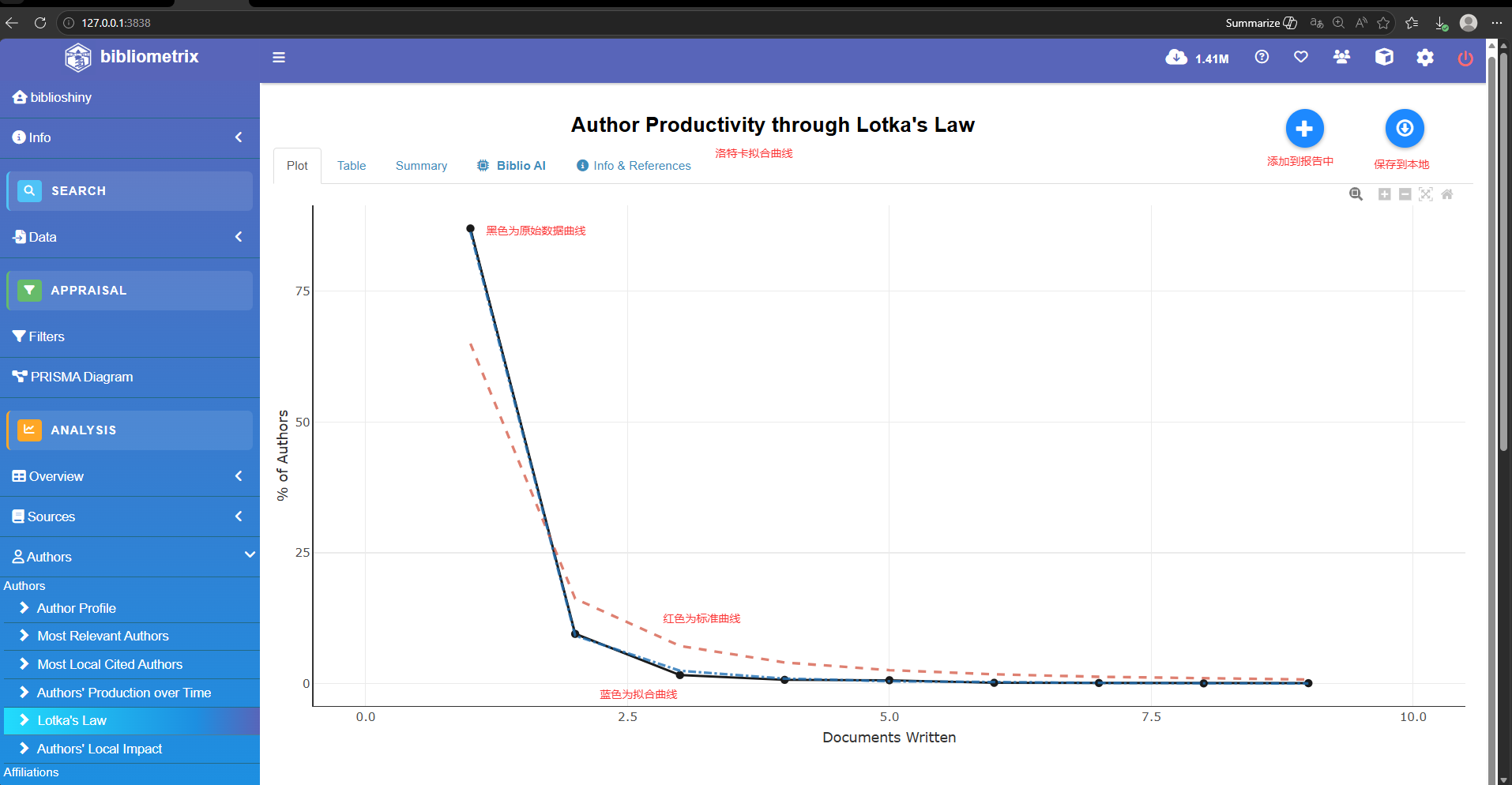
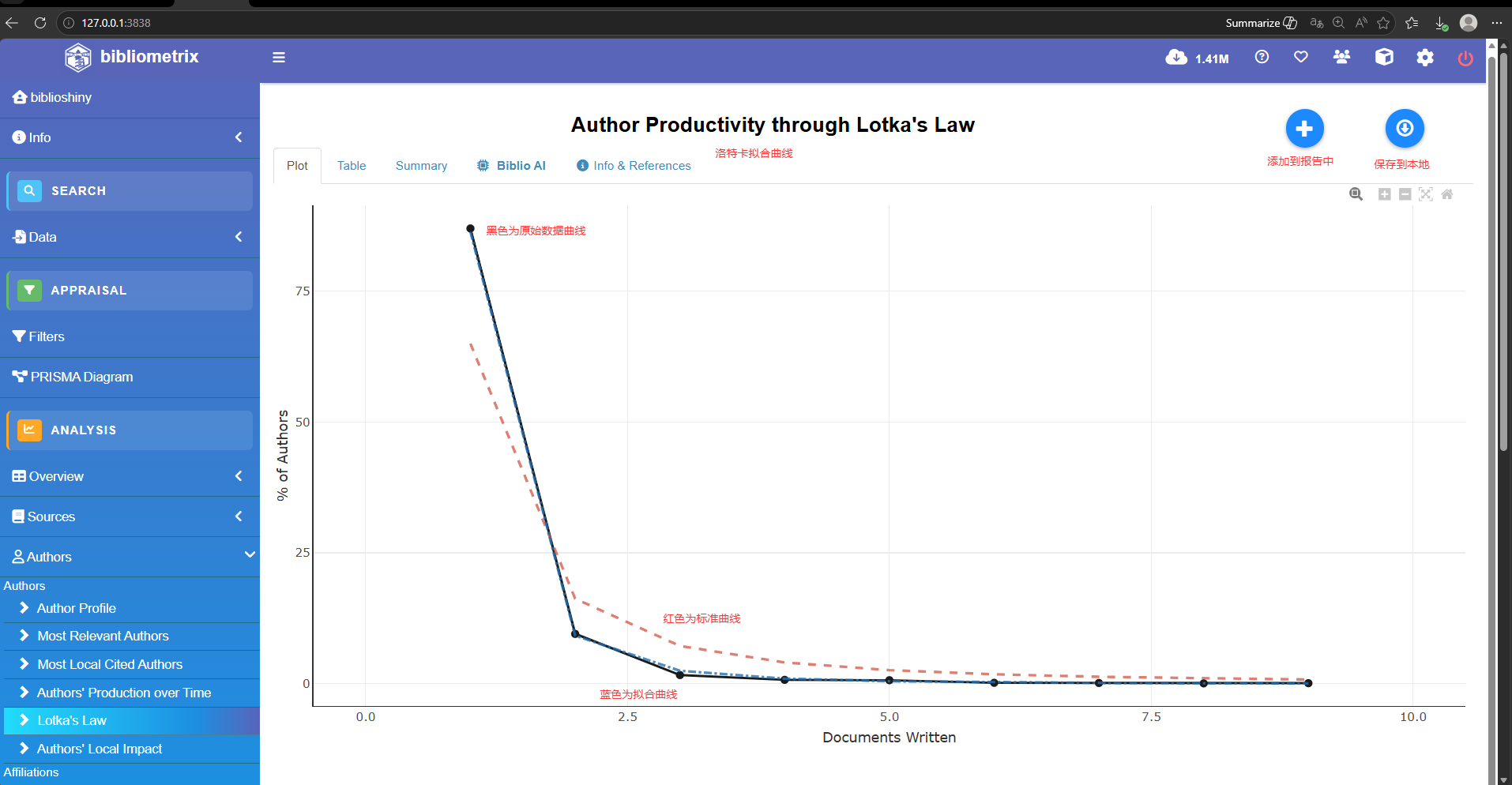
Author Productiveity through Lotka's Law
Affiliations' Production over Time
Corresponding Author's Countries
Countries' Scientific Production
Countries' Production over Time
Countries'Collaboration World Map
引言
更新时间2026年5月13日晚上
在全球科研产出呈指数级增长的当下,海量学术文献既是科研工作者把握领域发展脉络、识别前沿热点、挖掘核心研究力量的核心宝库,也给传统人工文献梳理方式带来了巨大挑战。文献计量学(Bibliometrics)与科学计量学(Scientometrics)作为以数学与统计学方法为核心,对文献特征、学术网络、知识演化规律进行定量分析的学科,已成为科研人员开展领域综述、选题论证、热点追踪的必备核心方法。
在众多文献计量分析工具中,由 Massimo Aria 与 Corrado Cuccurullo 开发的bibliometrix R 包,凭借完全开源、高度可复现、全流程覆盖、极强的定制化能力,成为 R 语言生态中文献计量分析的标杆工具。不同于 CiteSpace、VOSviewer 等以图形化界面为主的工具,bibliometrix 打通了多源文献数据导入、数据清洗与标准化、核心计量指标计算、学术网络构建、主题演化分析、可视化呈现到报告生成的全链路,可无缝衔接 R 语言生态中各类统计分析、机器学习、可视化拓展包,为科研人员提供了从基础描述性统计到深度知识挖掘的全维度分析能力。
本笔记为笔者学习与实操 bibliometrix 工具的全流程复盘记录,核心面向文献计量分析的入门与进阶学习者。笔记将从 bibliometrix 的环境搭建与基础语法入手,系统梳理文献数据获取规范、多源数据(Web of Science、Scopus、PubMed、OpenAlex 等)适配方法、数据预处理核心要点、主流分析模块(作者 / 机构 / 国家合作网络、关键词共现分析、共被引耦合分析、主题模型与时间演化分析等)的代码实现、结果解读与可视化优化技巧,同时补充实操过程中常见的报错解决方案与进阶定制化分析思路。
希望通过这份结构化的笔记,既能为笔者自身构建完整的 bibliometrix 知识体系、留存可复用的标准化分析代码模板,也能为同领域的科研工作者提供一份可落地、易复现的实操指南,帮助大家快速上手 bibliometrix 工具,高效完成文献计量分析工作。
文末特别说明:本文仅为个人学习记录,非专业权威内容,难免存在疏漏与错误,大佬勿喷,欢迎各位前辈评论区交流指正,感谢!
2025年5月13日晚22:15
历经不到2周的时间也是终于把文章更完了,这是第一次接触这个软件,从我老师让我学习这个软件到现在我也逐渐意识到了文献计量学的魅力。
Bibliometrix 的安装
检查pak包是否安装,然后使用pak安装bibliometrix
if (!require("pak", quietly=TRUE)) install.packages("pak")
pak::pkg_install("bibliometrix")
Bibliometrix 的使用
biblioshiny
优秀的可视化文献计量学工具,详见我另一篇文章
导入
Import or Load
Merge Collections
Reference Matching
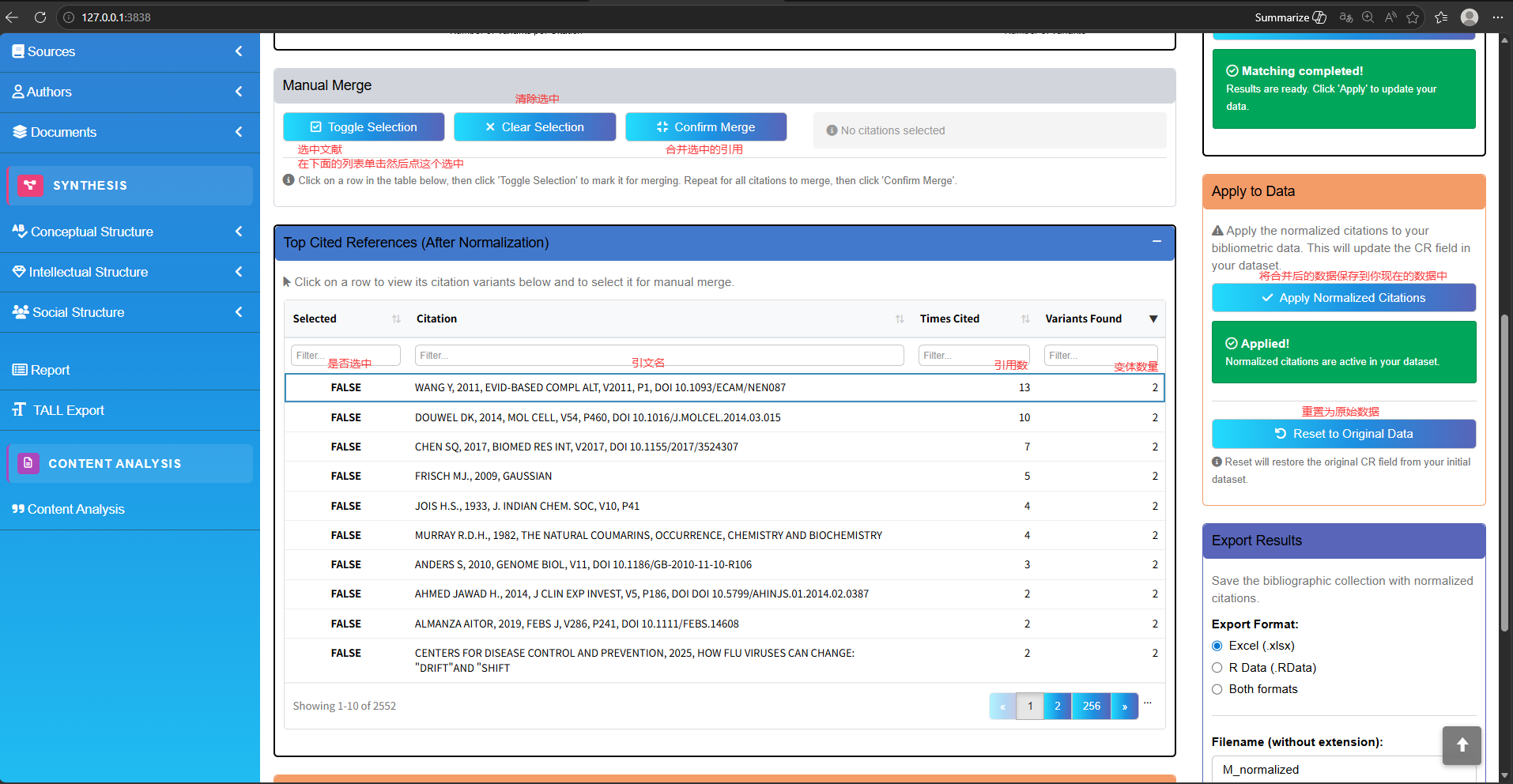
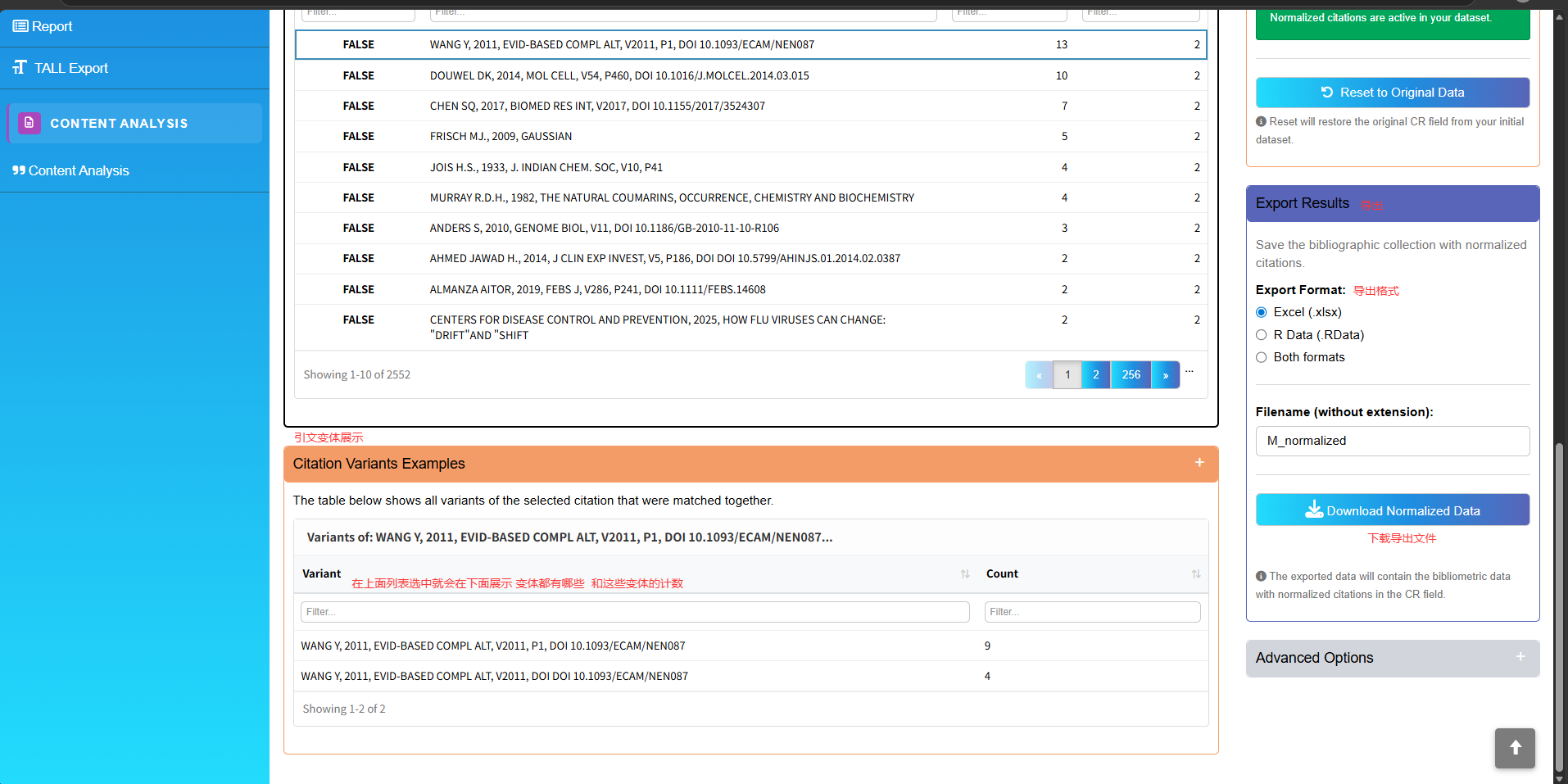
过滤
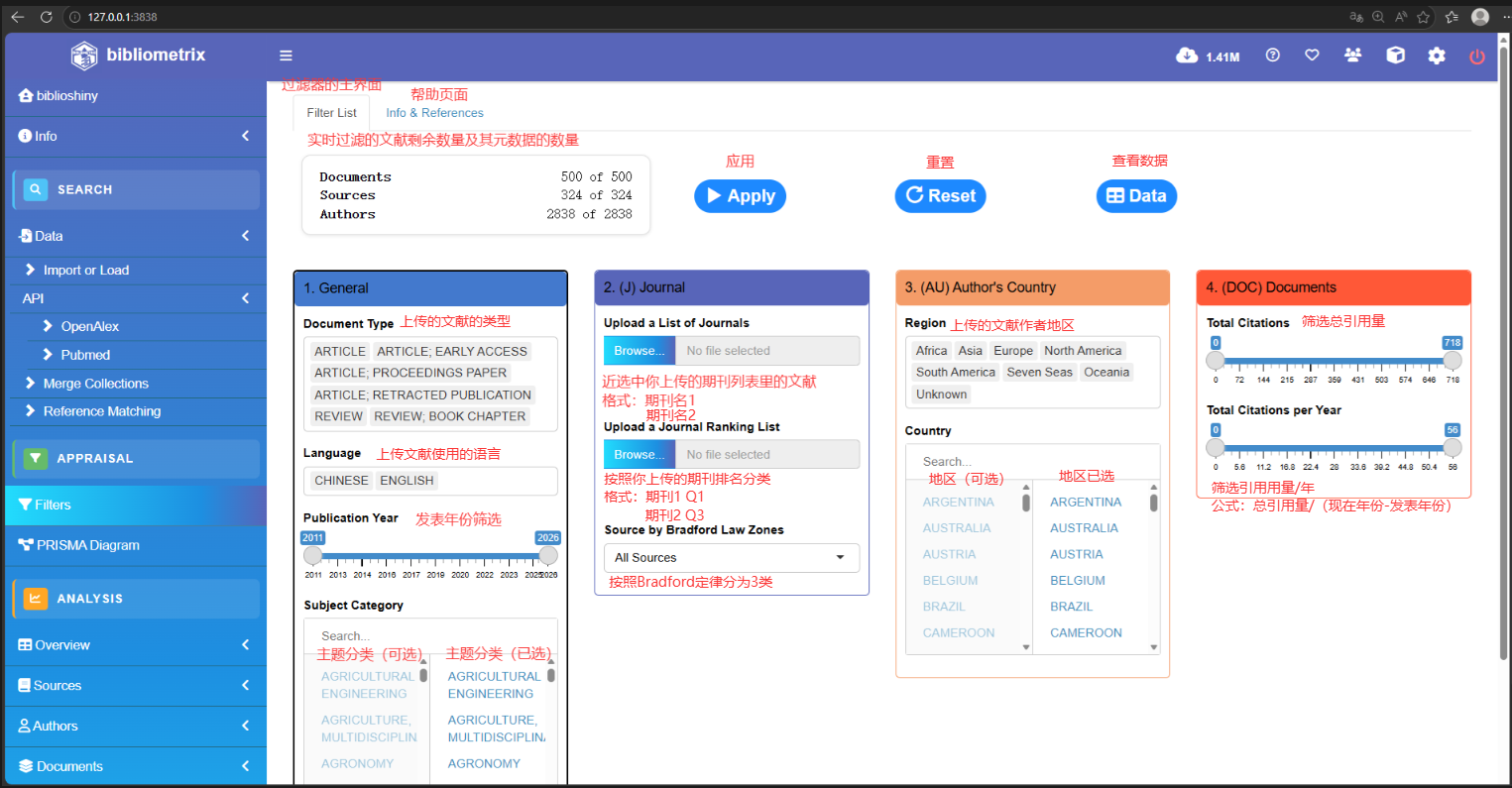
Fiters
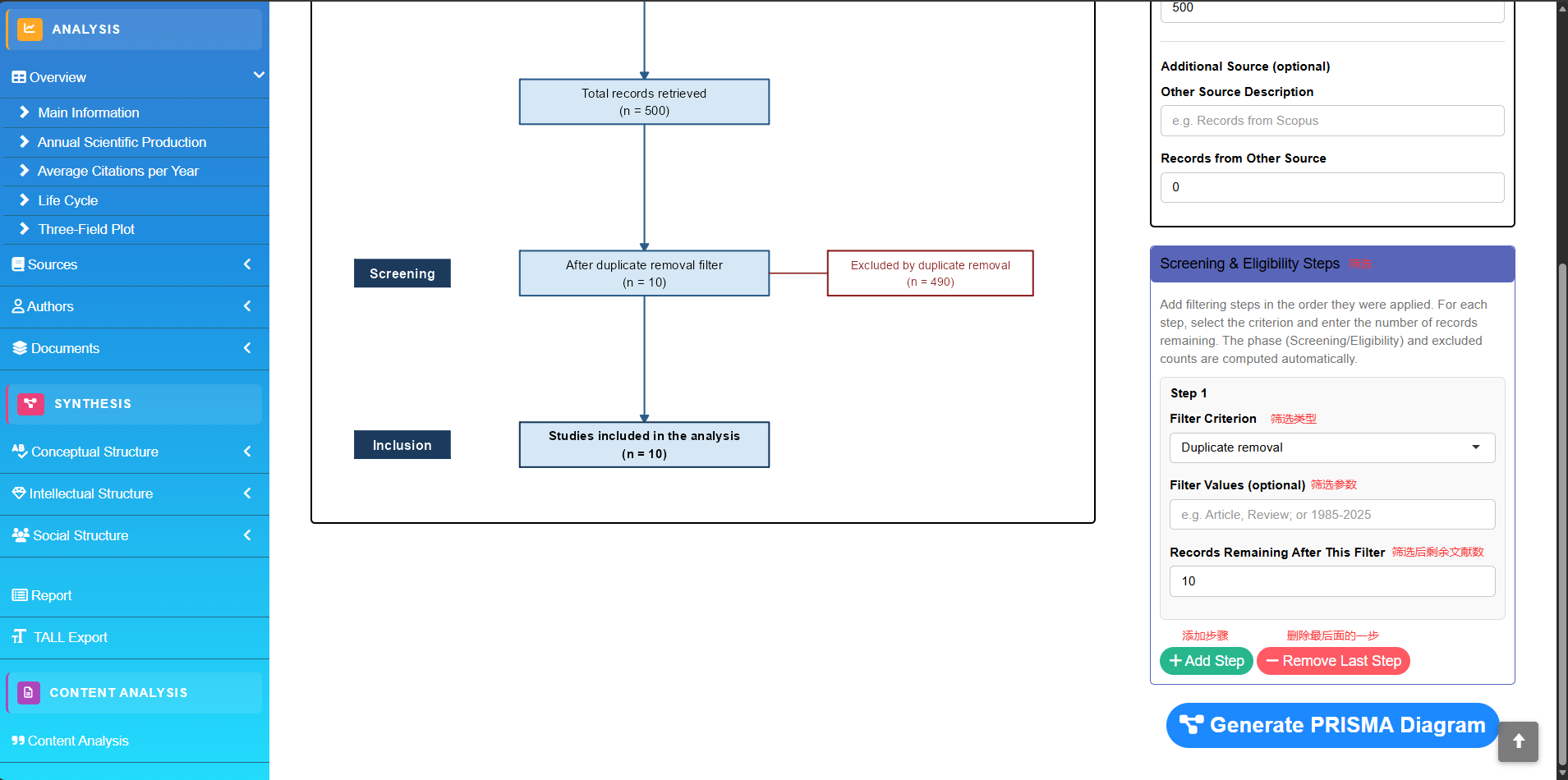
PRISMA Diagram


分析
Overview
Main Information
Annual Scientific Production
Average Citations Per year
Life Cycle
Three-Field Plot
Sources
Most Relevant Sources
Most Local Cited Sources
Bradford's Law
Sources's Local Impact
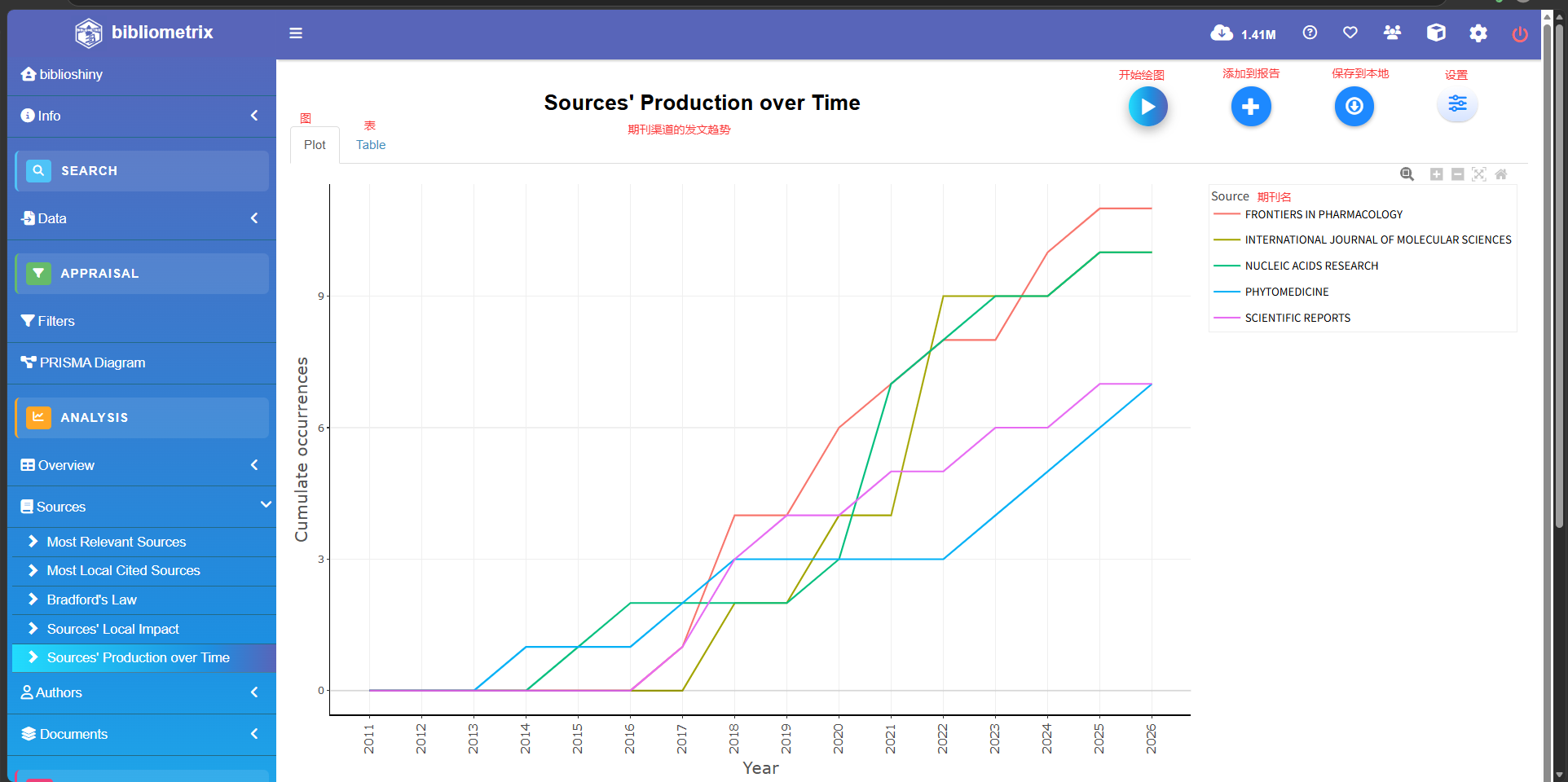
Sources's Production over Time
Authors
Author profile
略
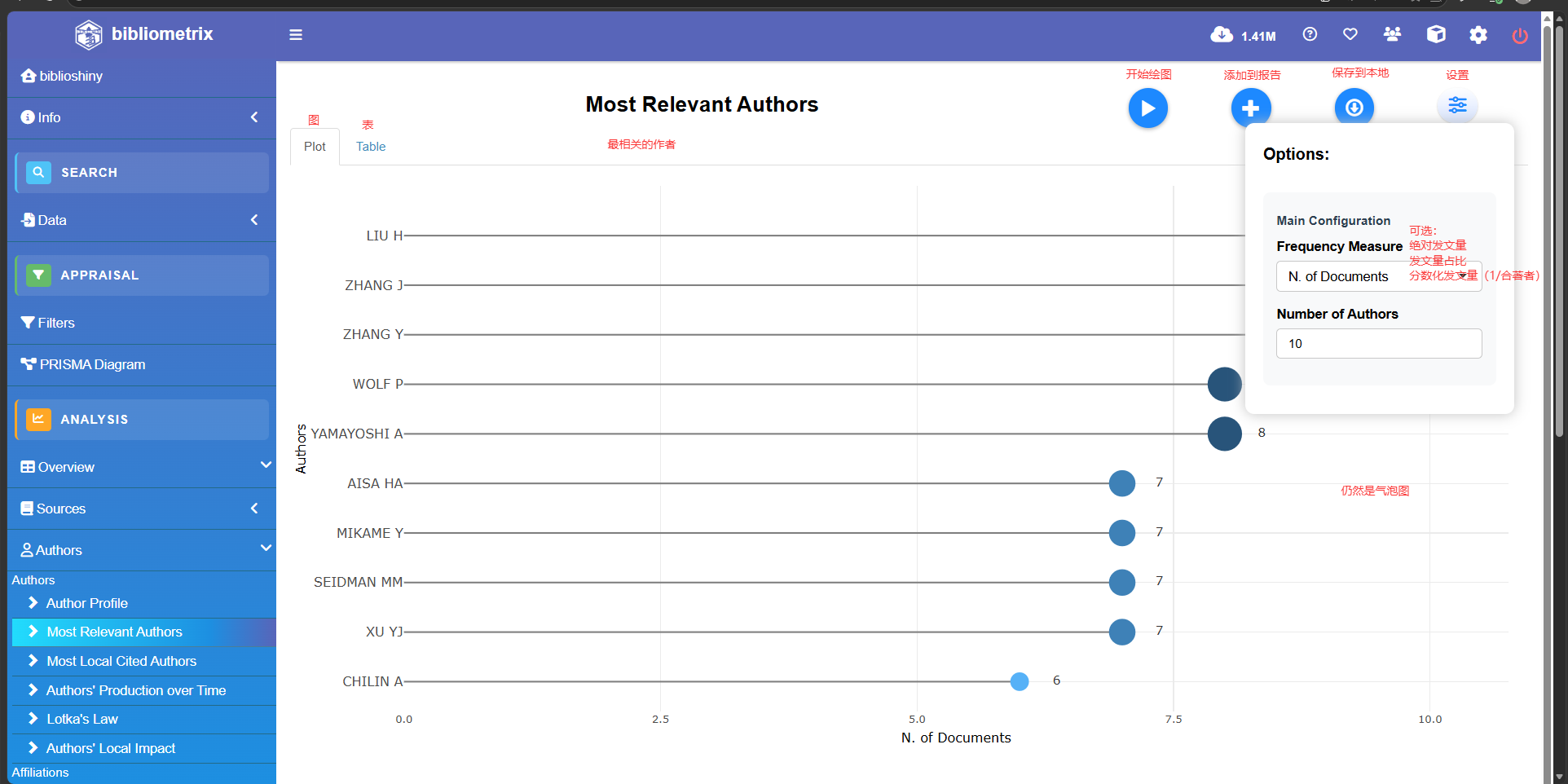
Most Relevant Authors
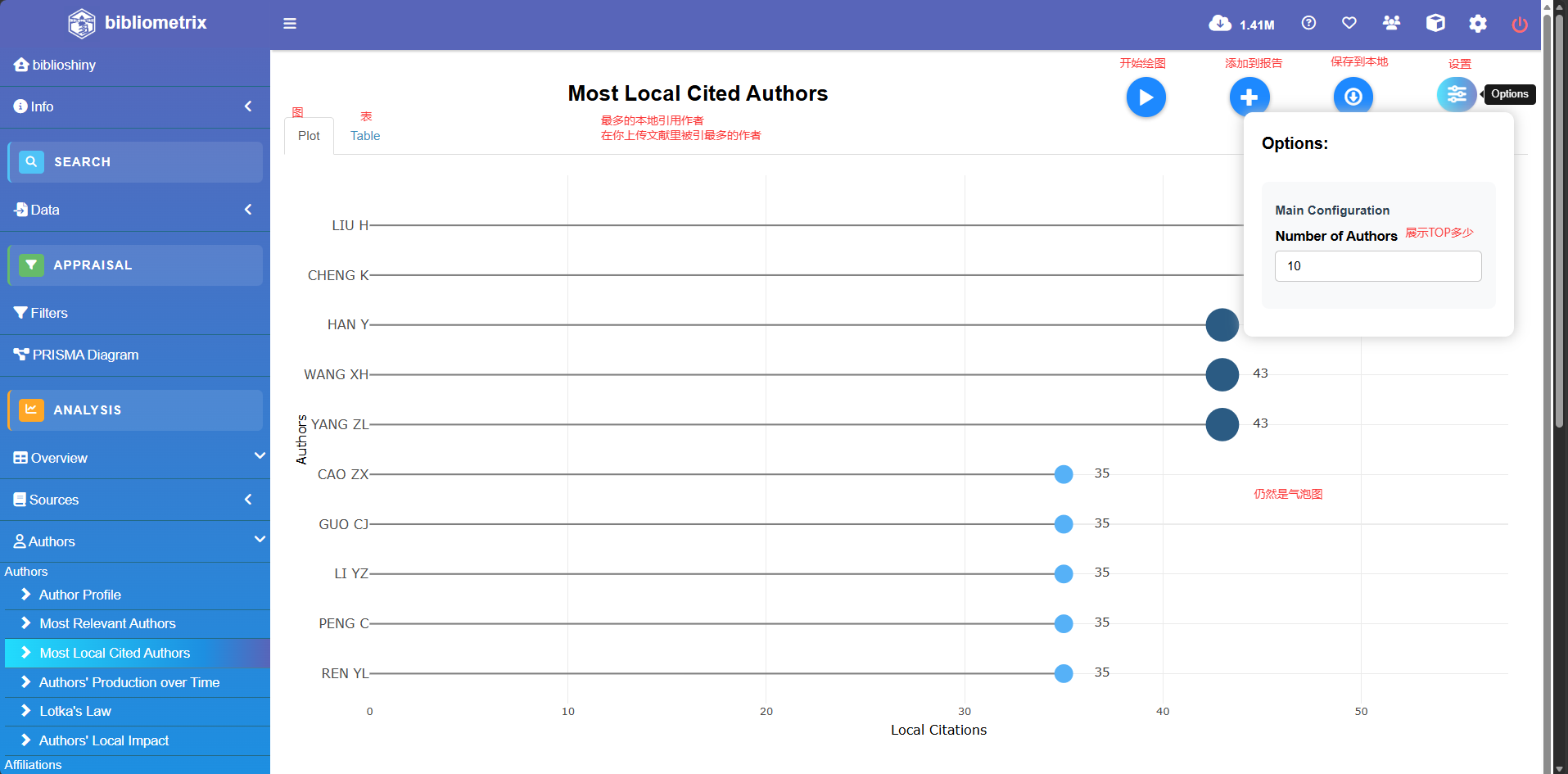
Most Local Cited Authors
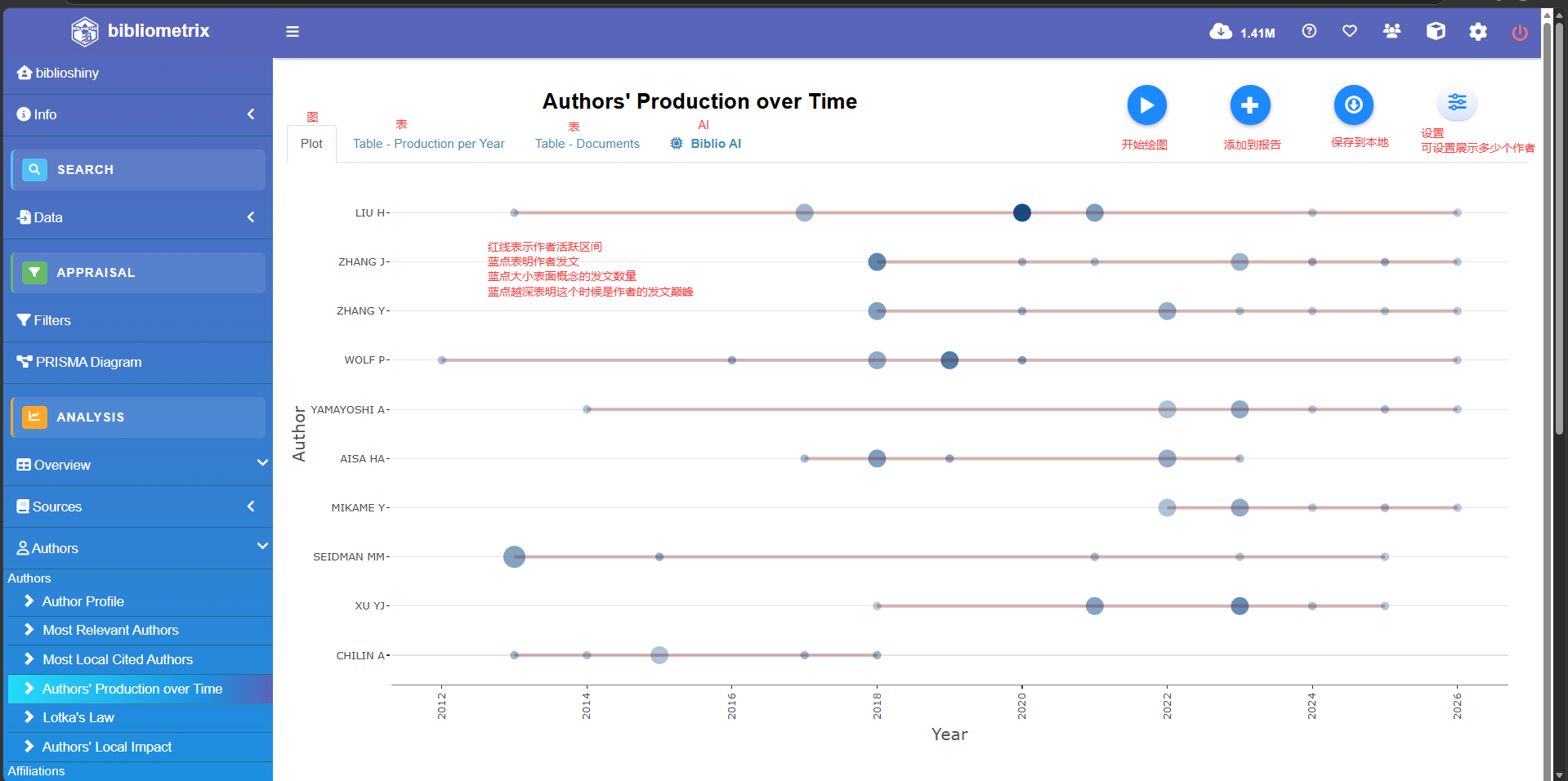
Authors' Production over Time
Author Productiveity through Lotka's Law
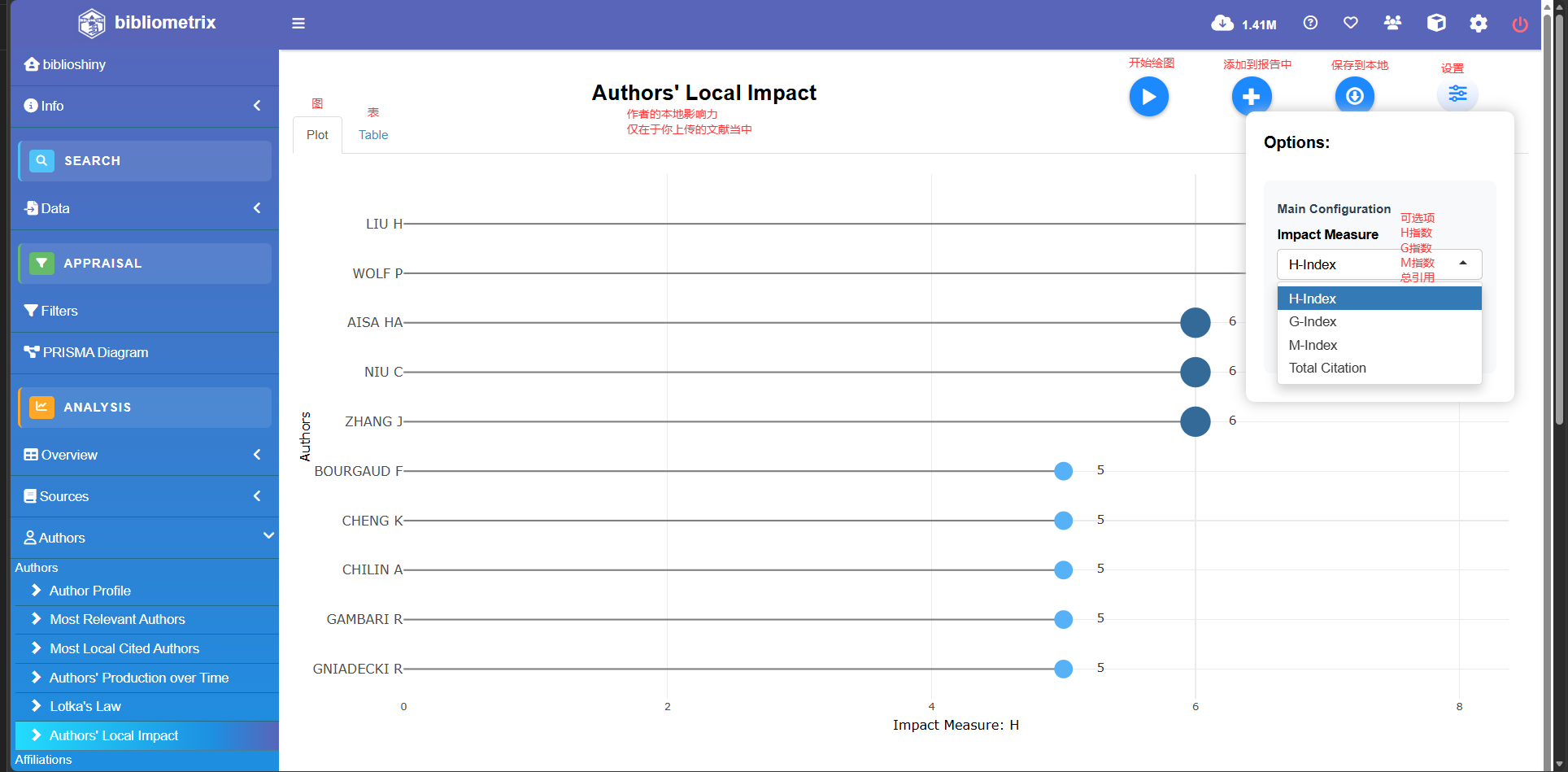
Authors' Local Impact
Affiliations
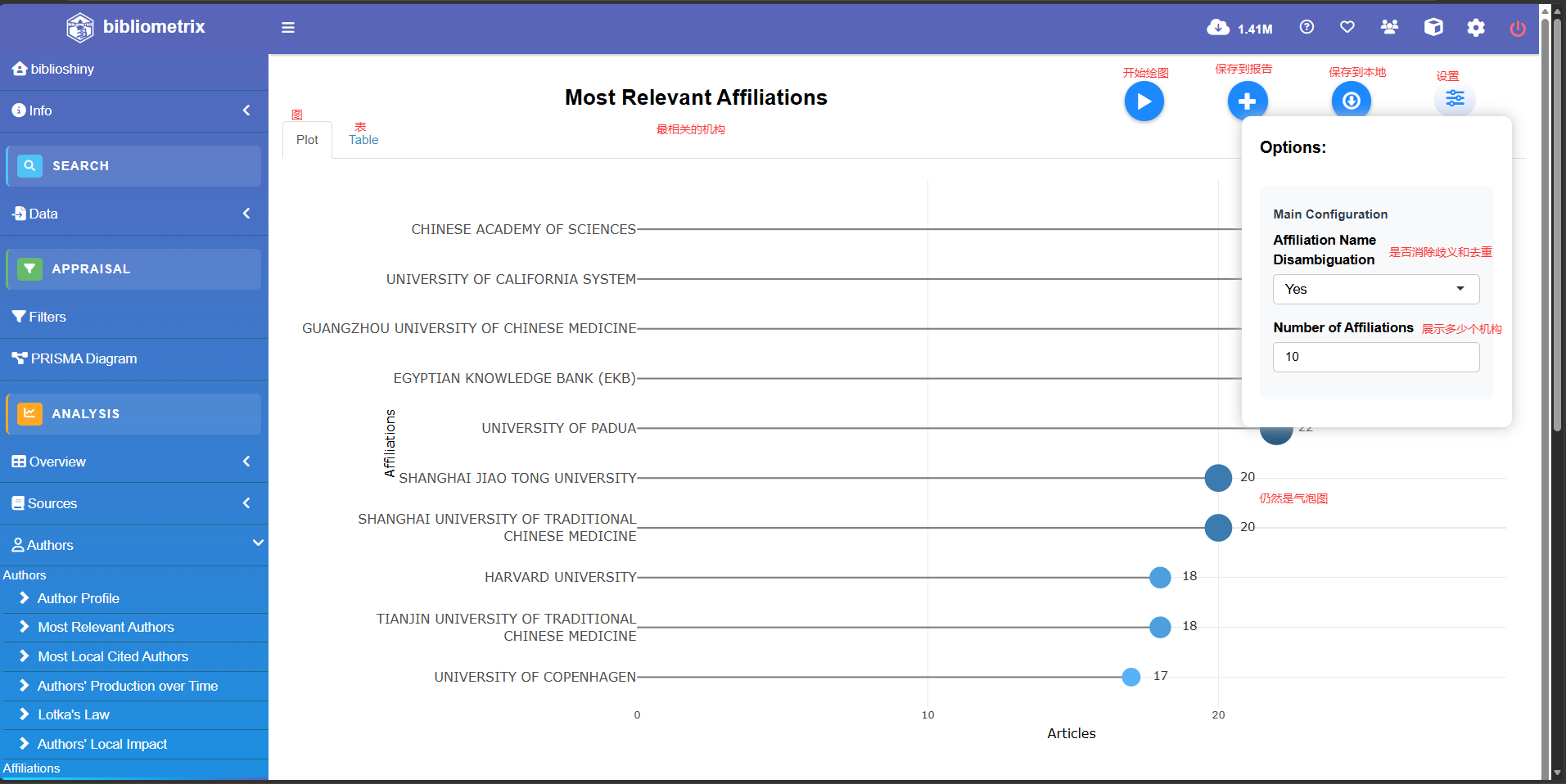
Most Rellevant Affiliations
Affiliations' Production over Time
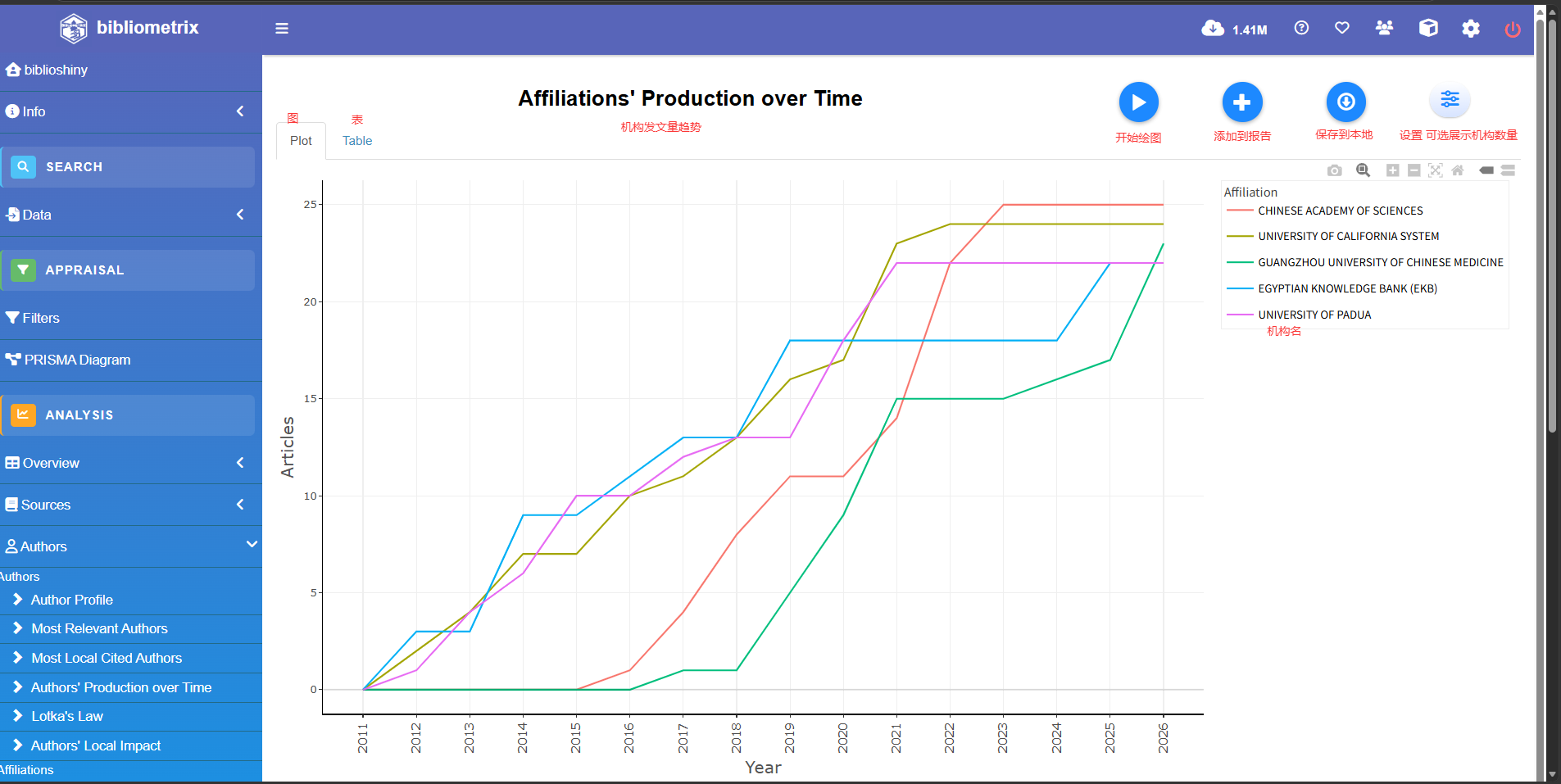
Countris
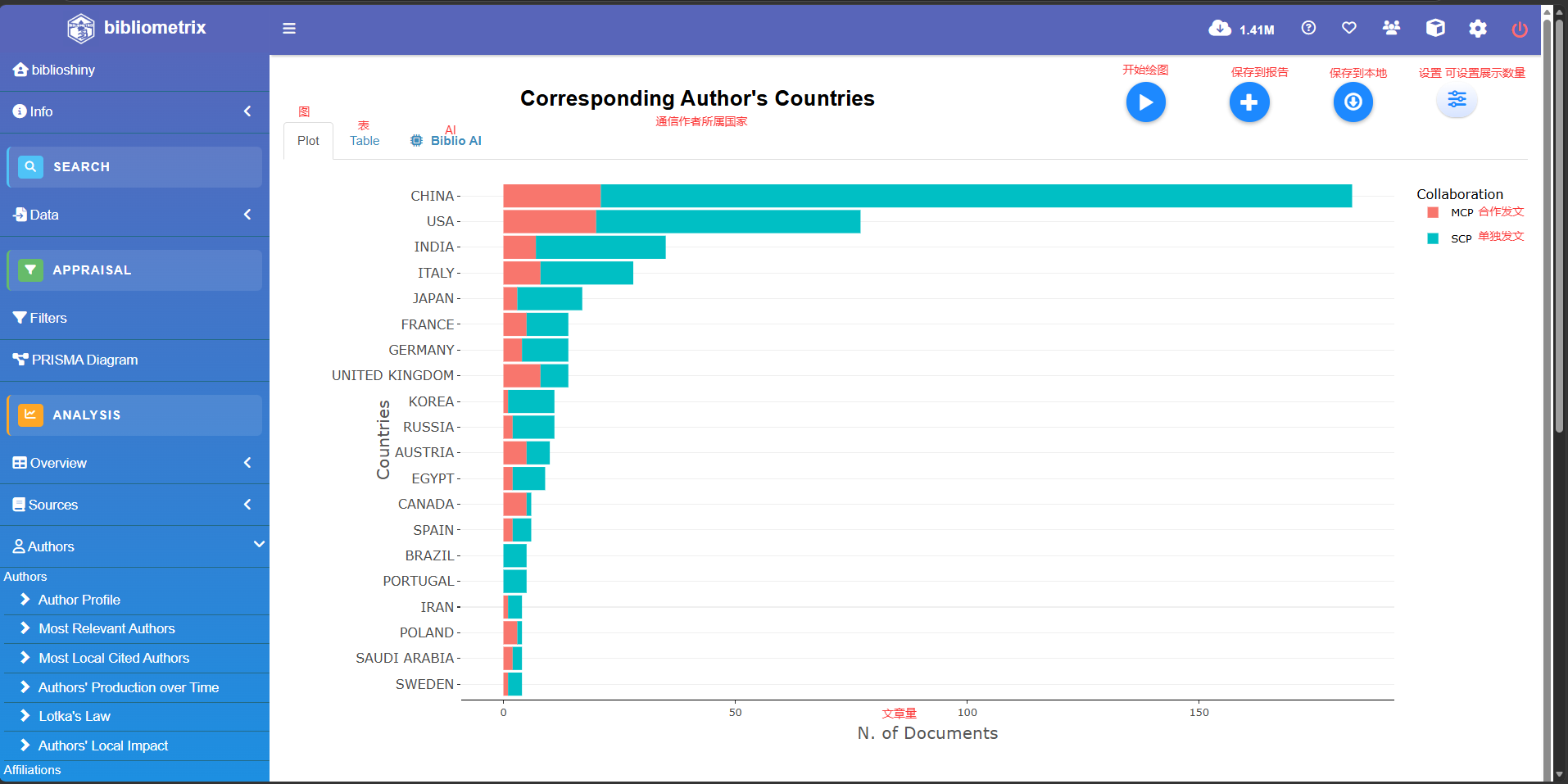
Corresponding Author's Countries
Countries' Scientific Production

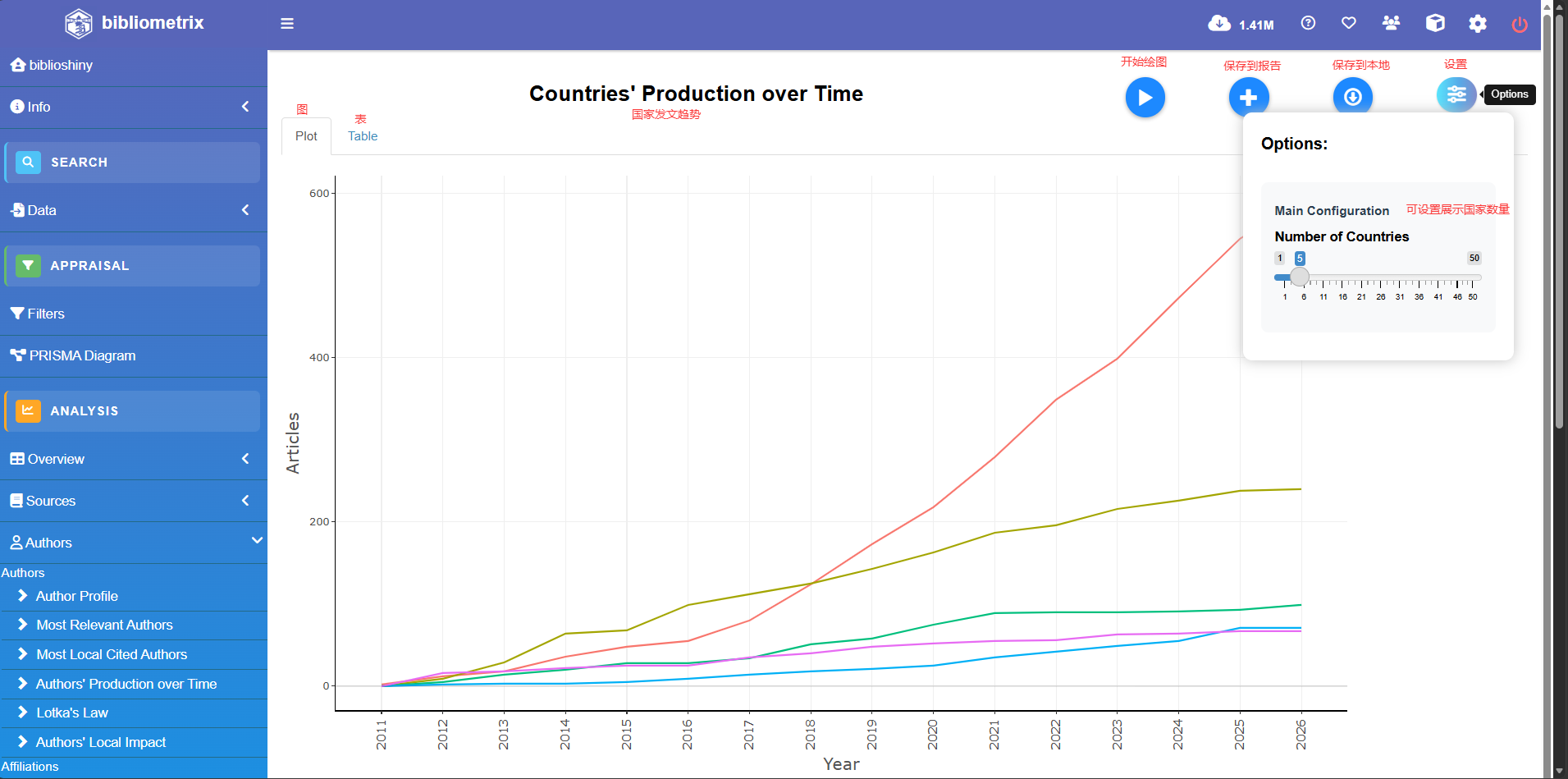
Countries' Production over Time
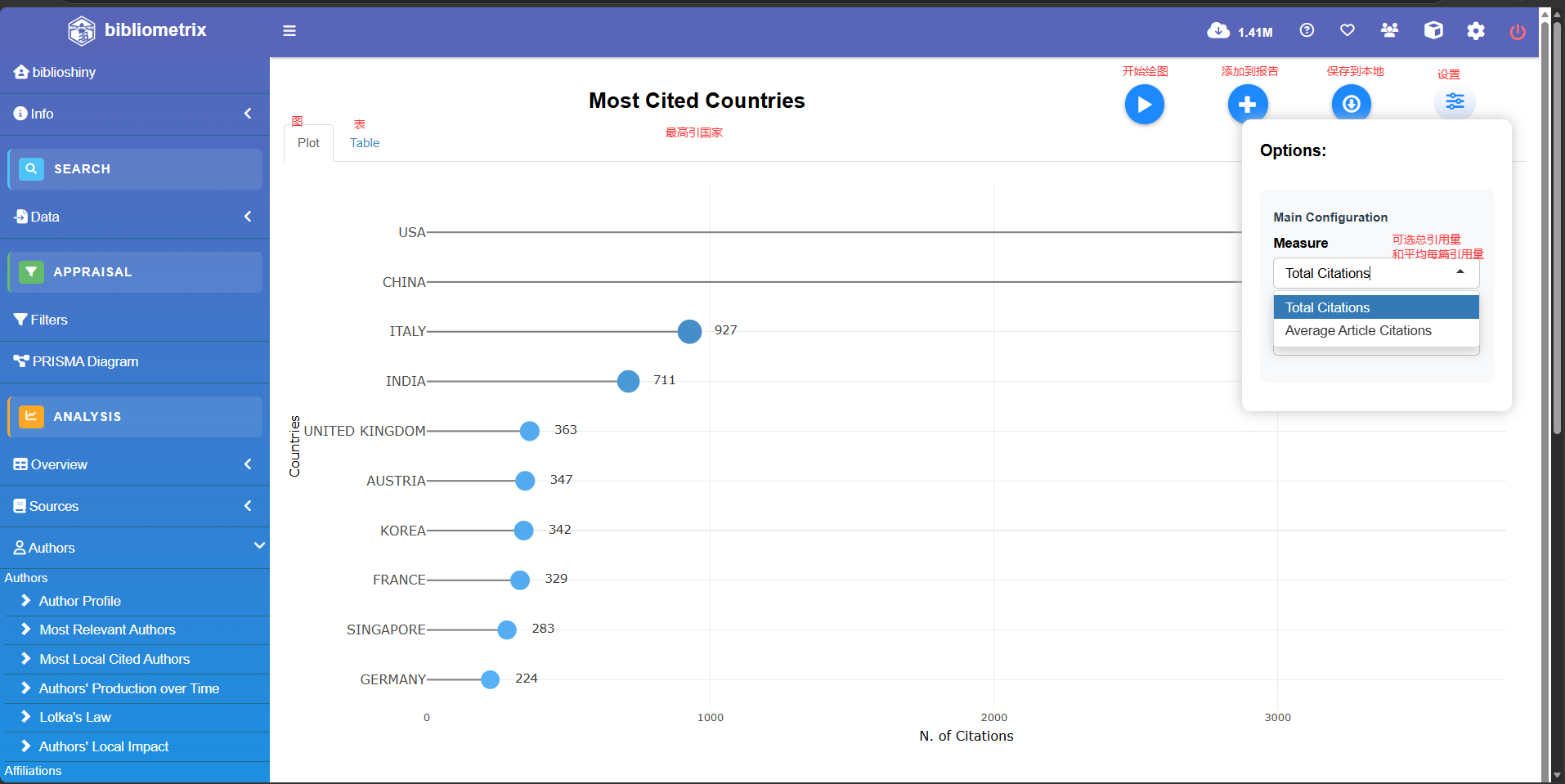
Most cited Coutries
Documents
Documents
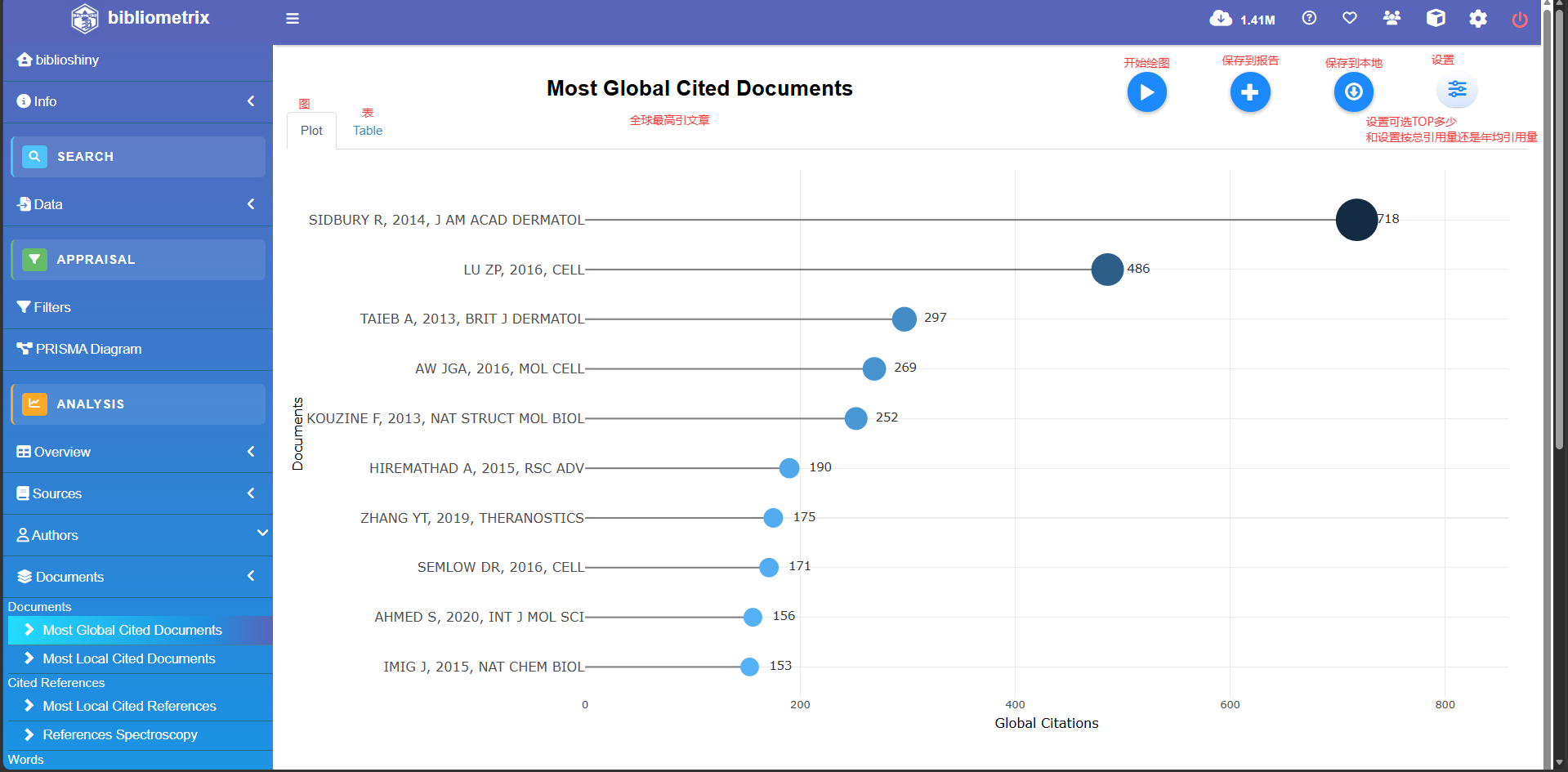
Most Global Cited Document
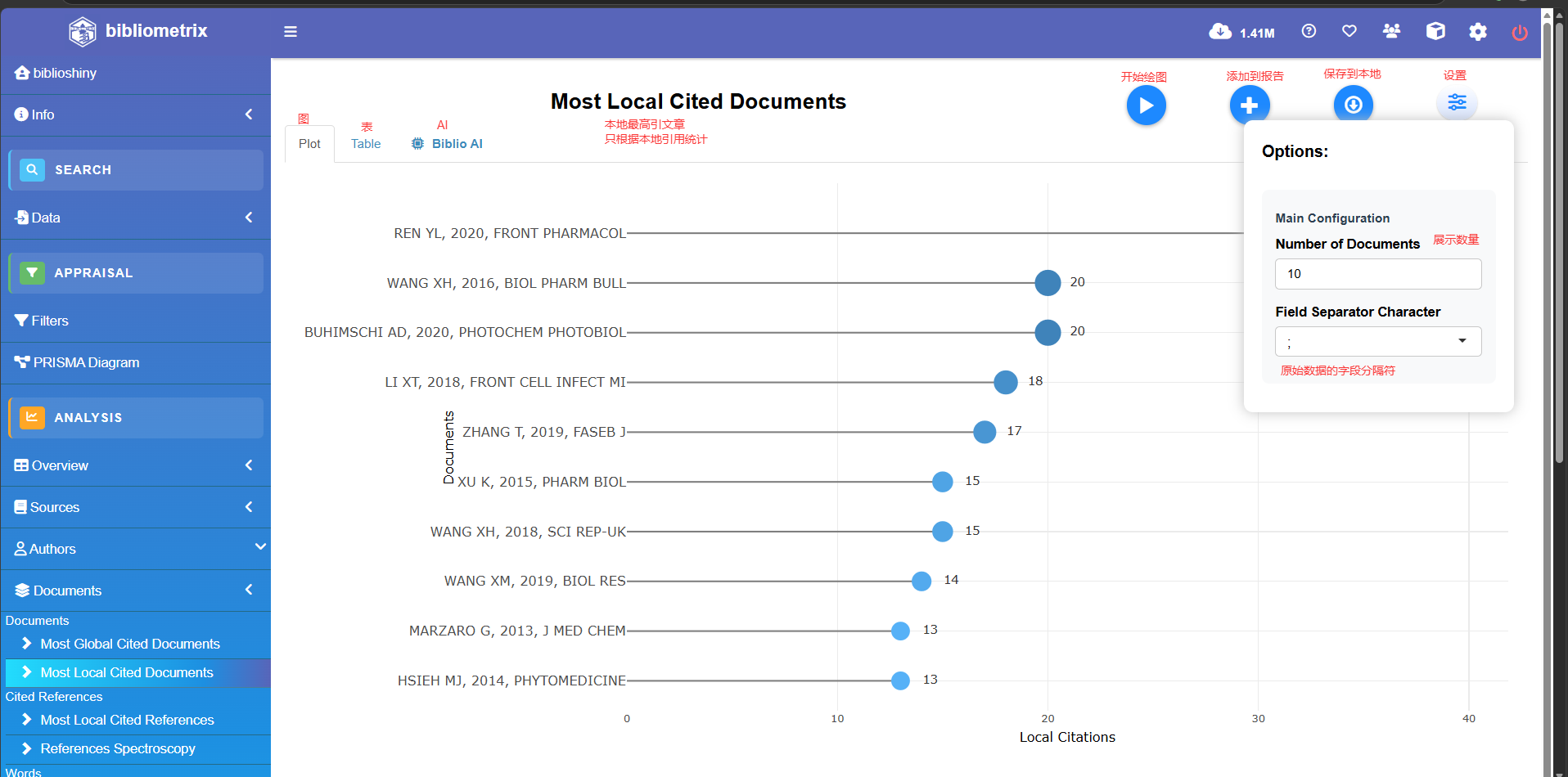
Most Lcoal Cited Documents
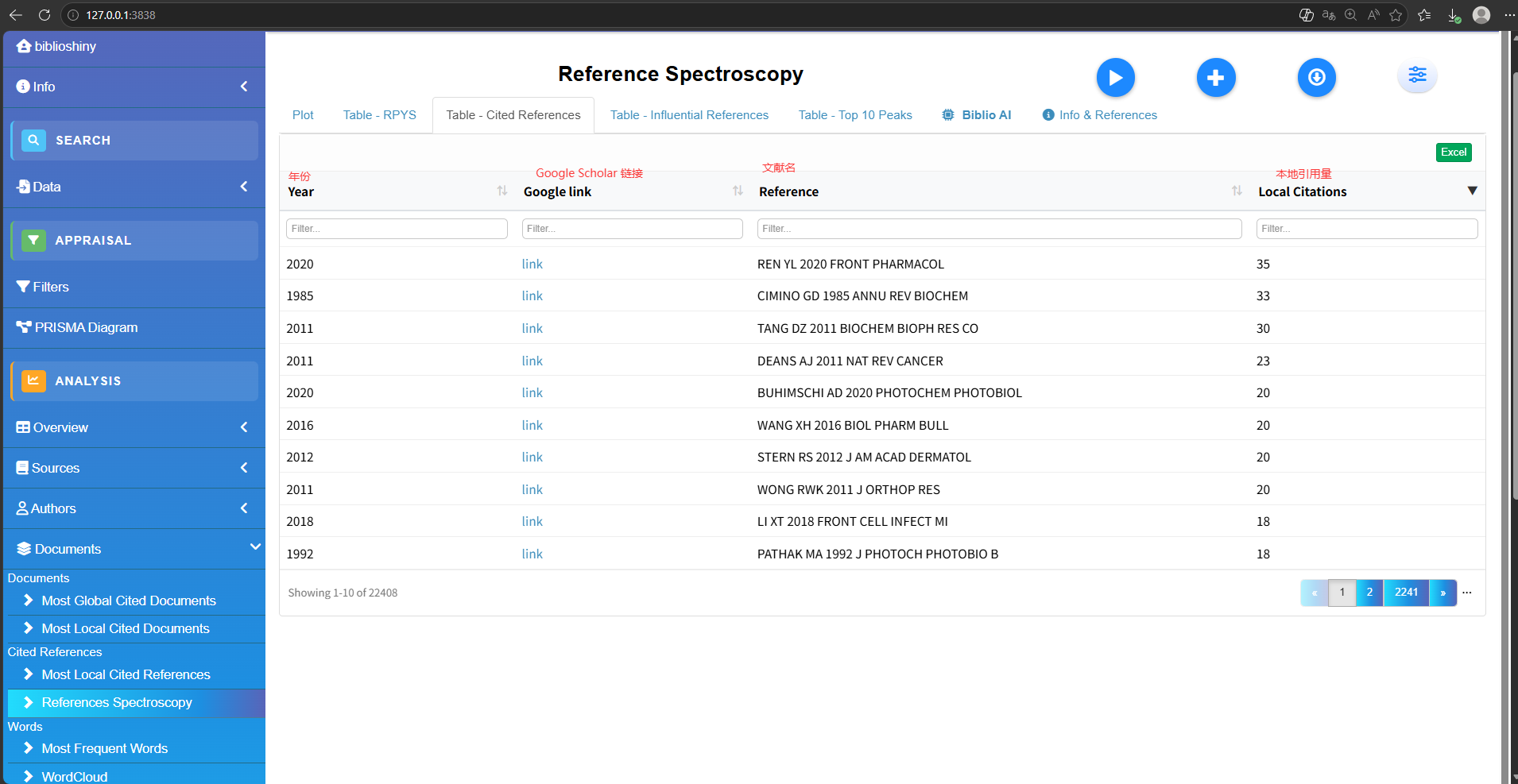
Cited References
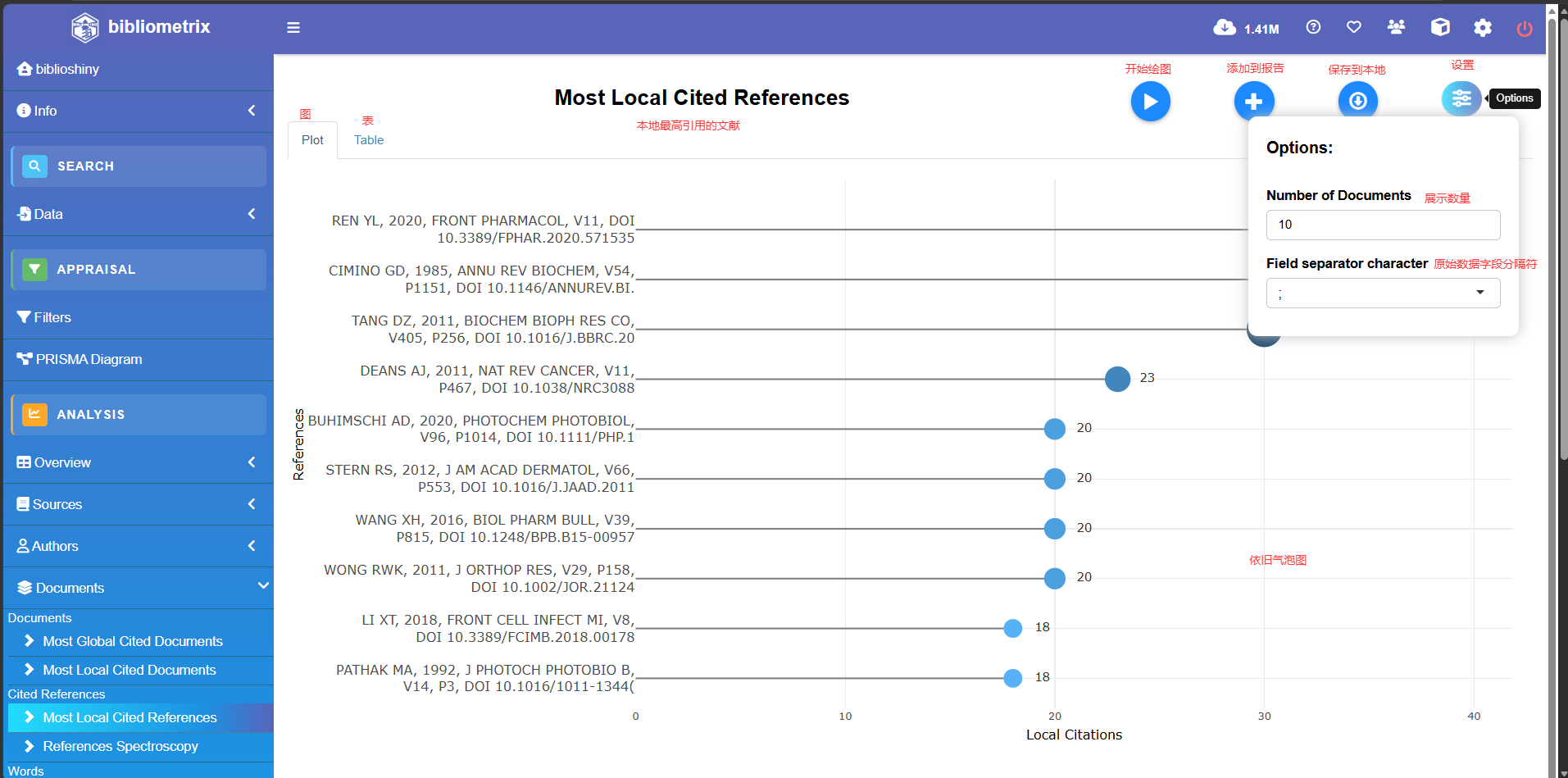
Most Local Cited References
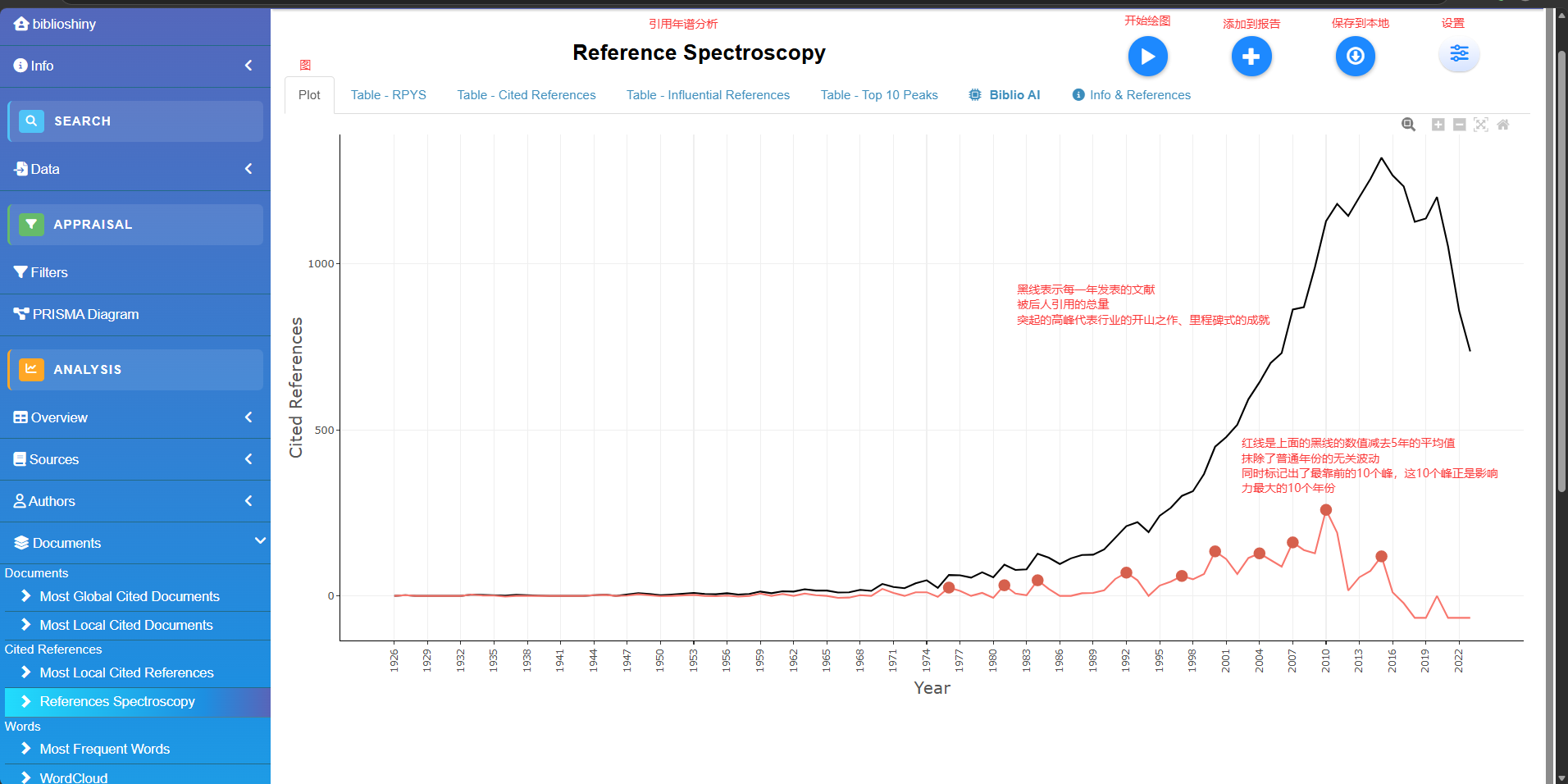
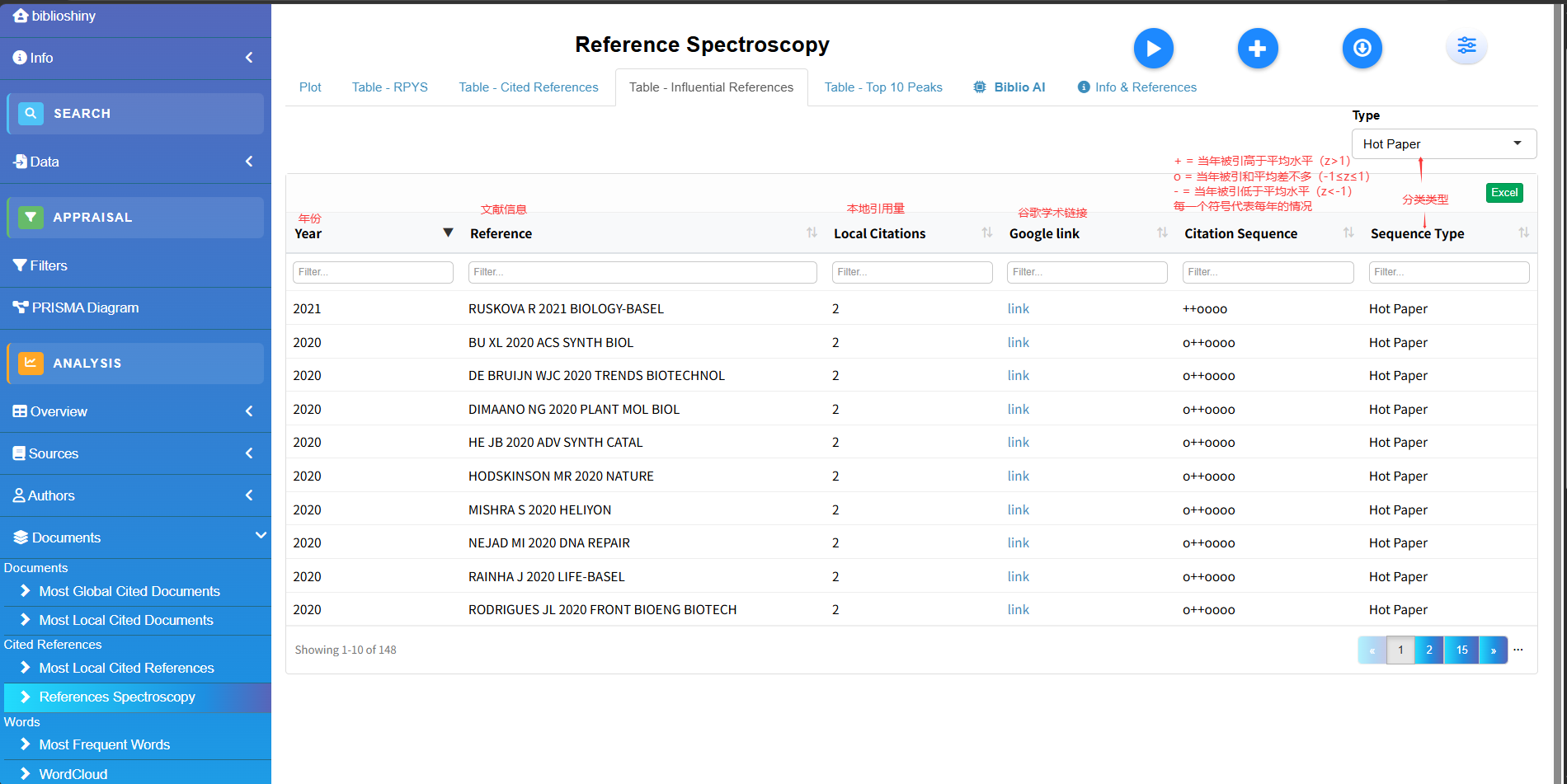
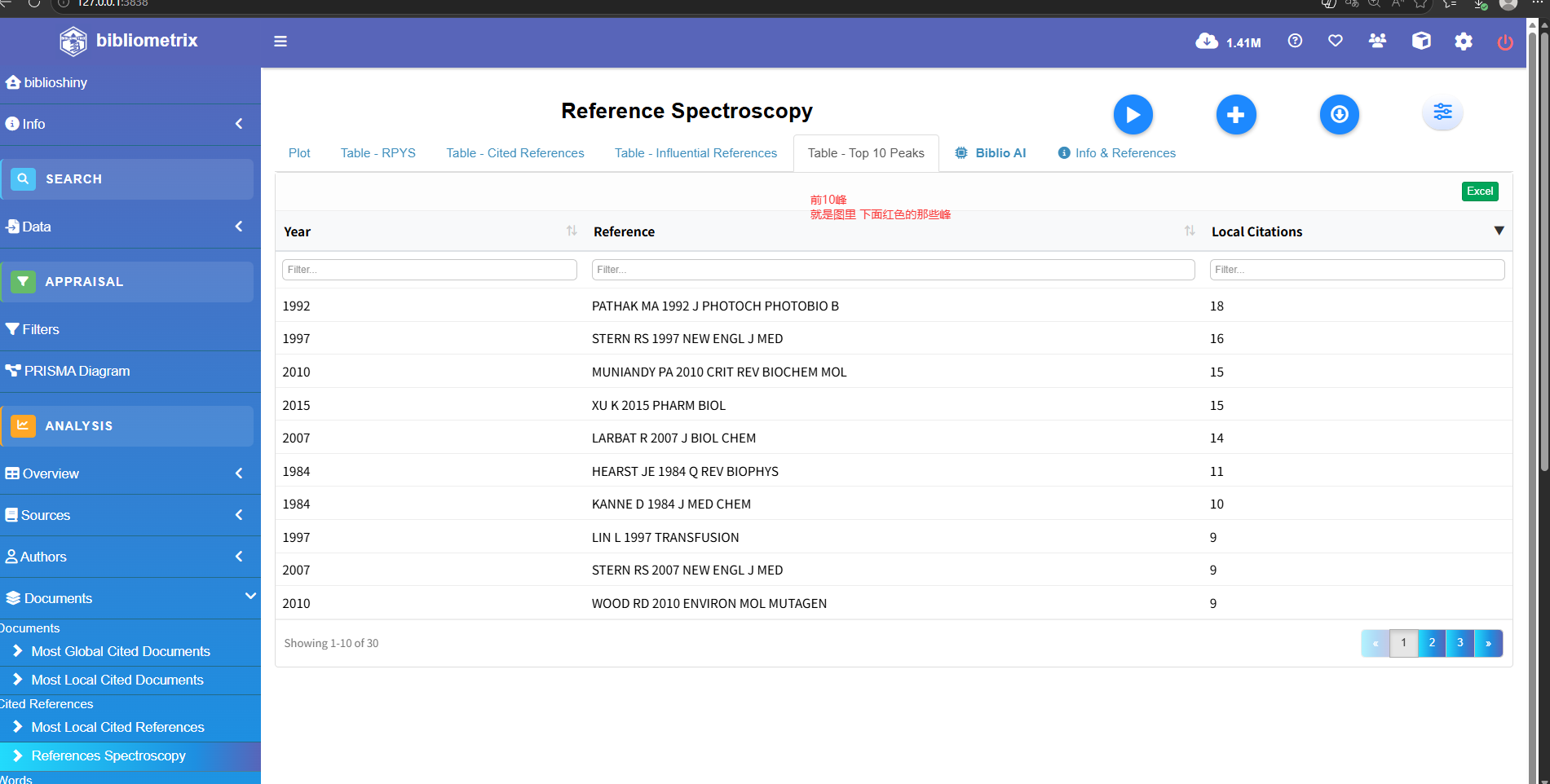
Reference Spectroscopy
Words
Most Frequent Words
WordCloud

TreeMap
Words'Frequency over Time
Trend Topics
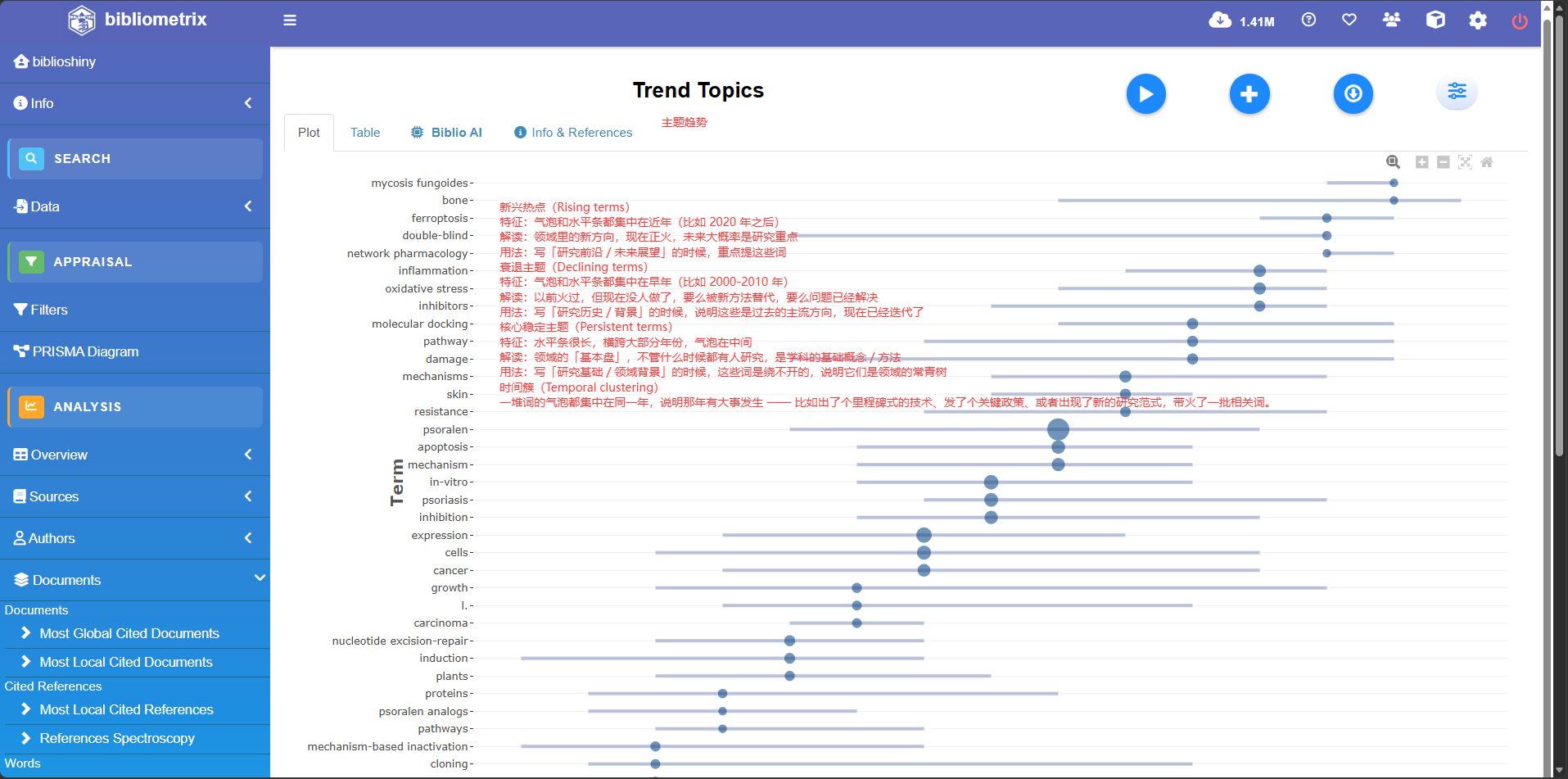
综合分析
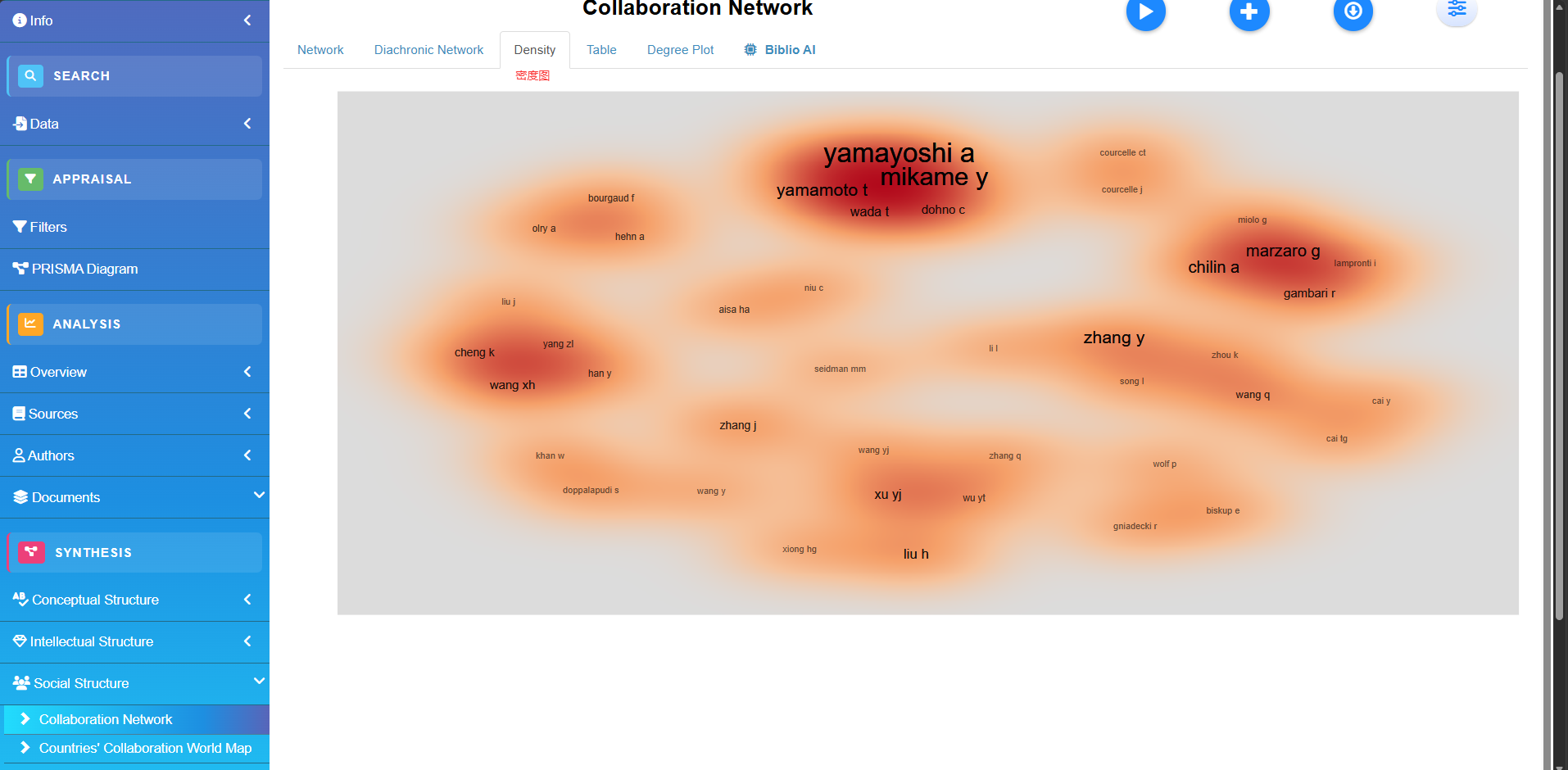
Conceptual Structure
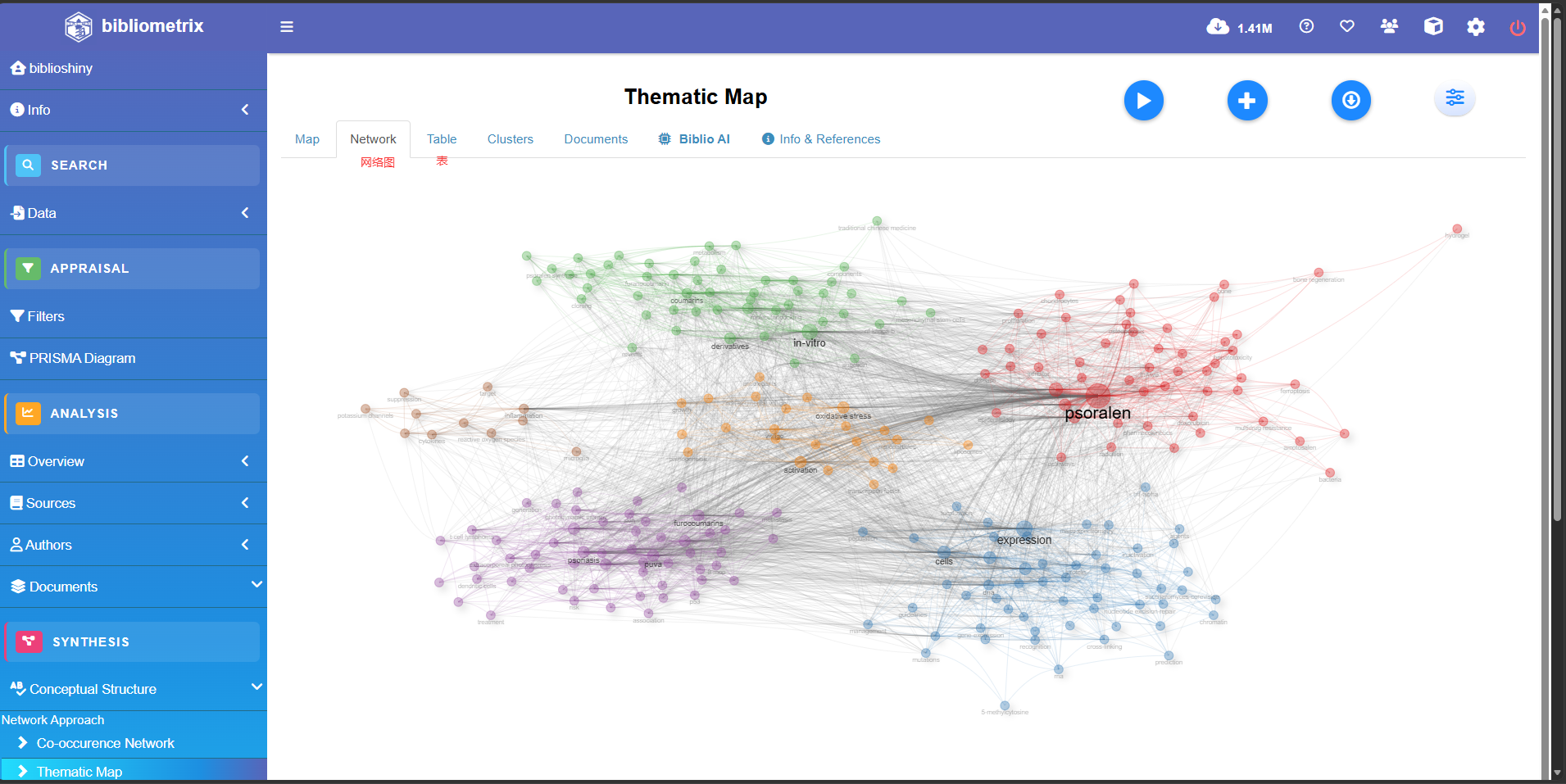
Co-occurrence Network
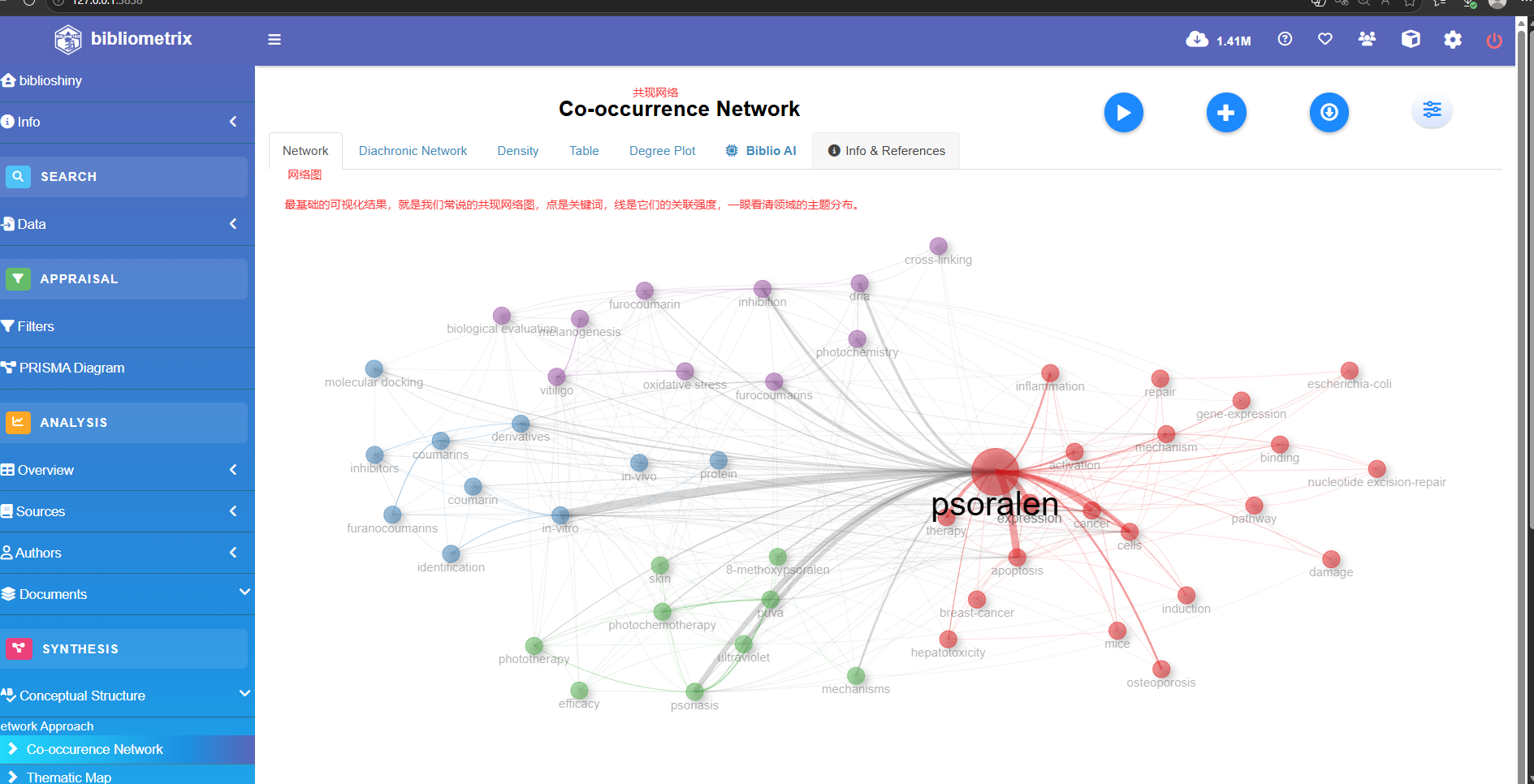
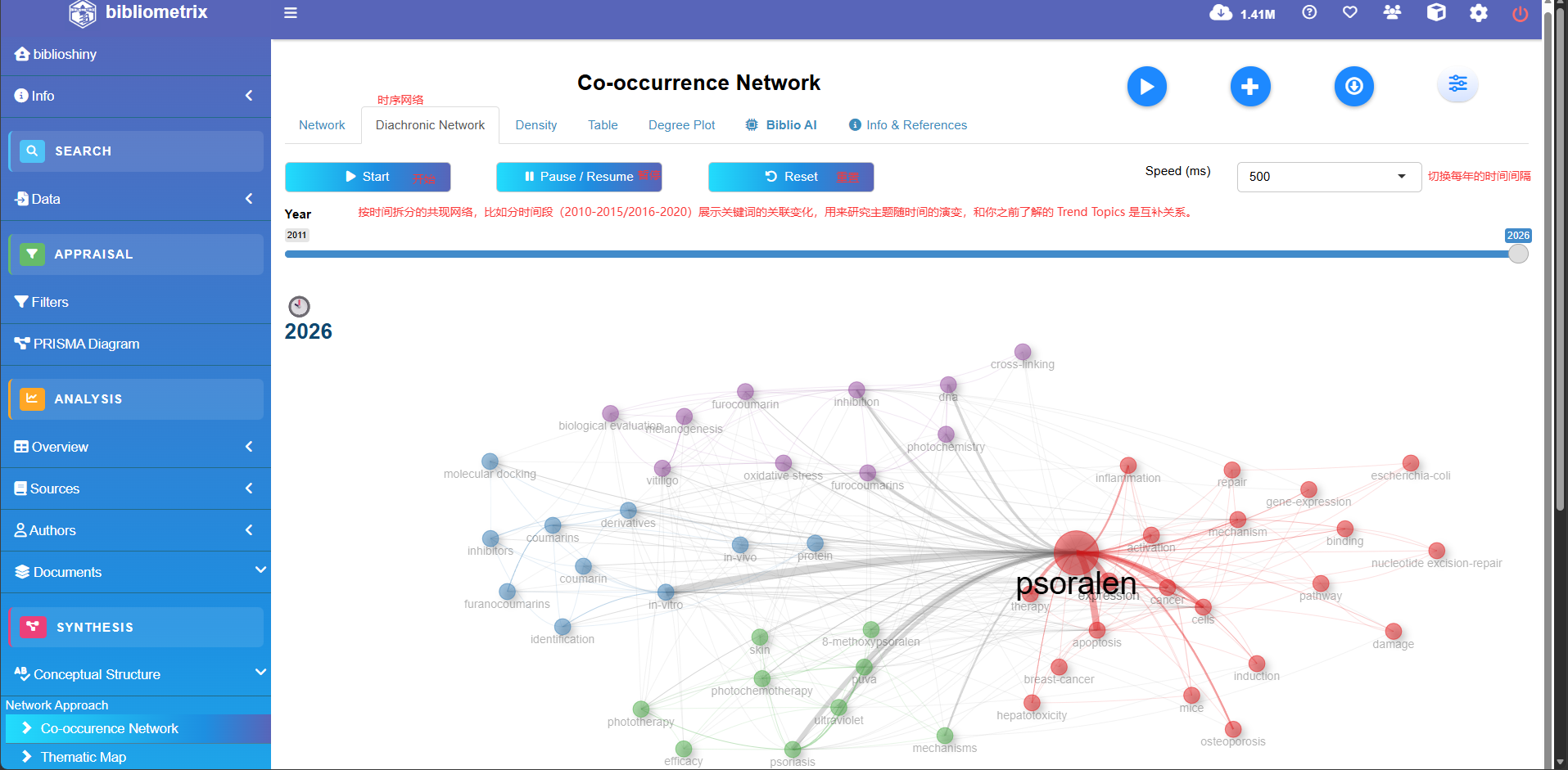
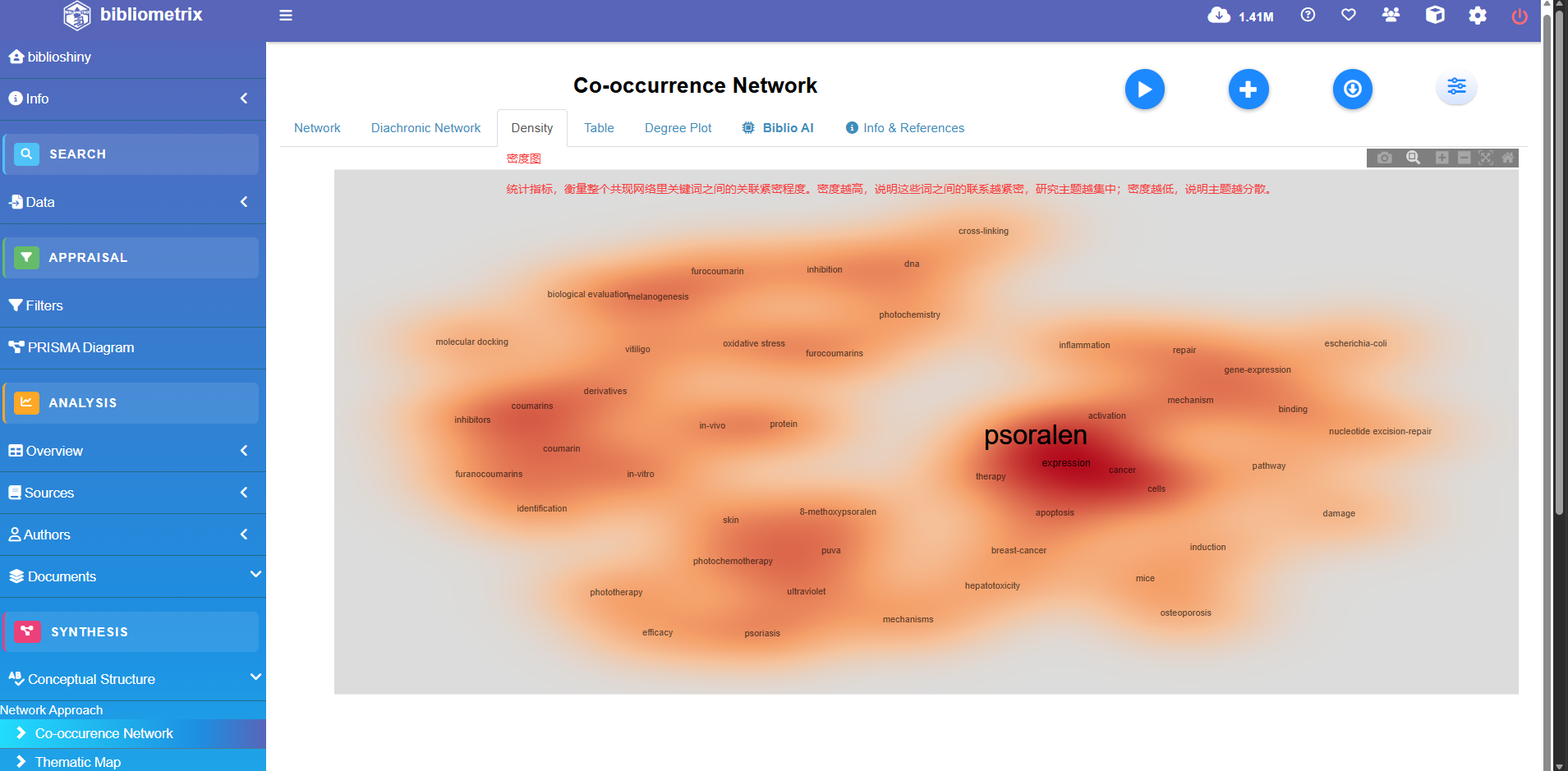
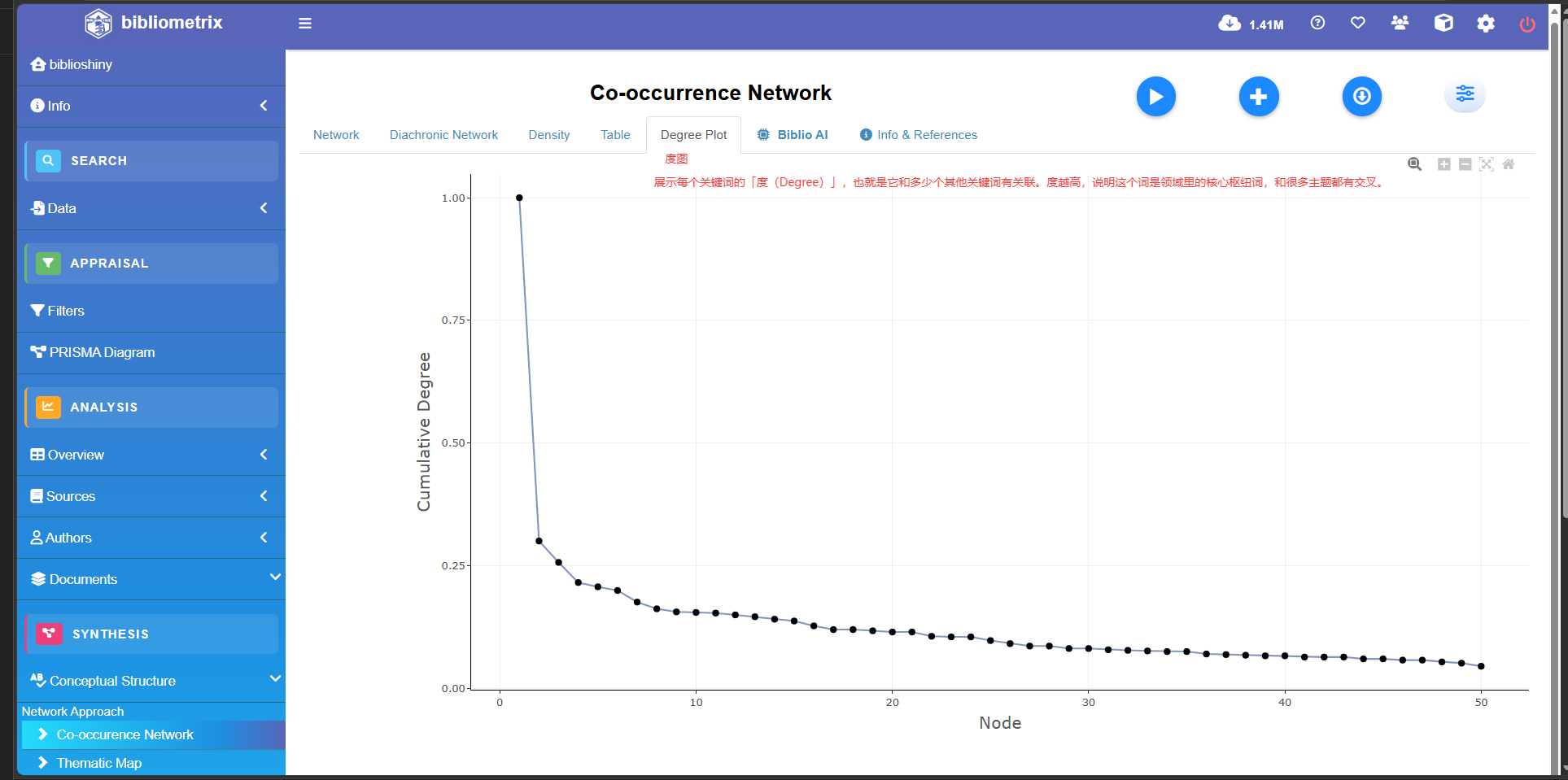
Thematic Map

Thematic Evolution
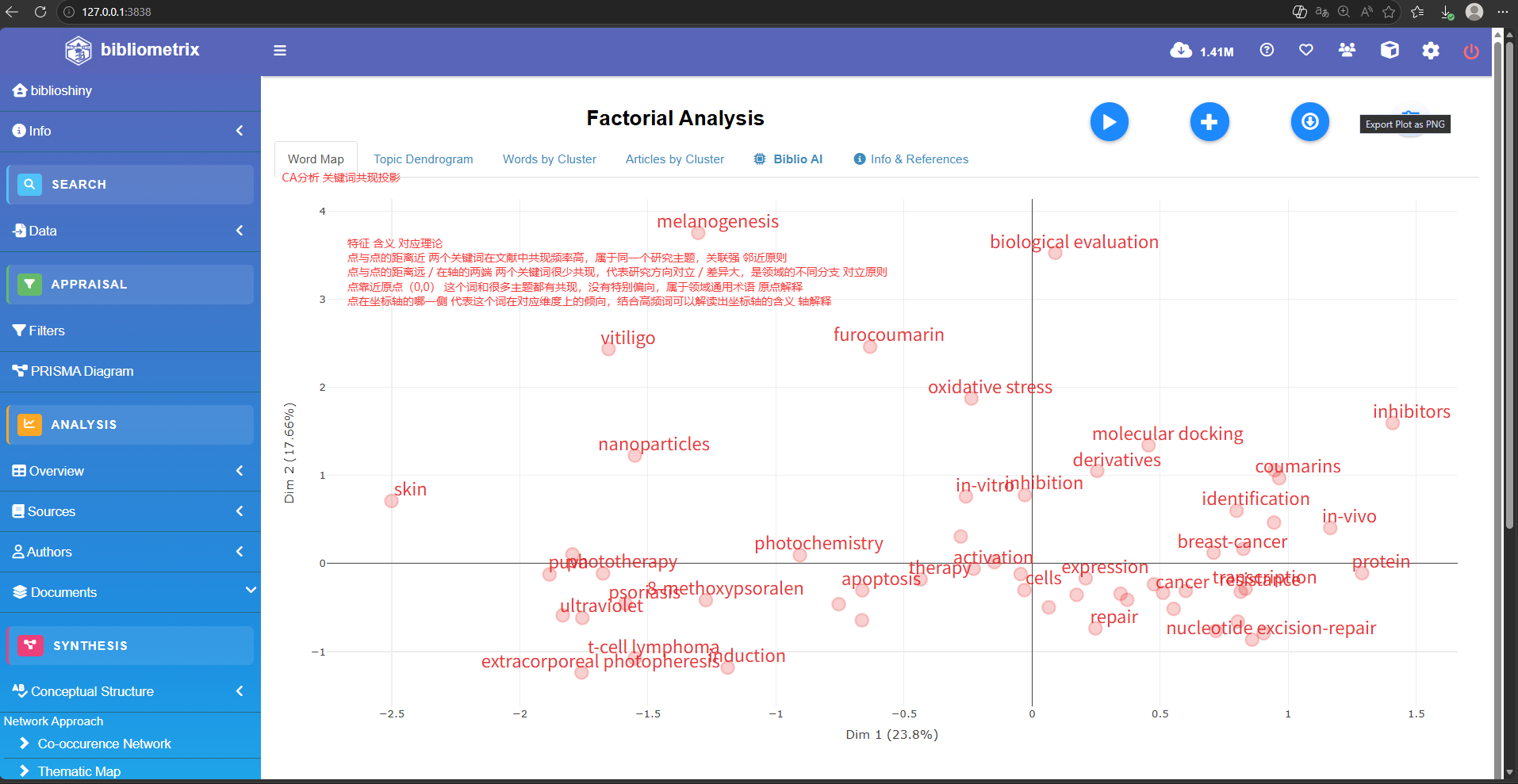
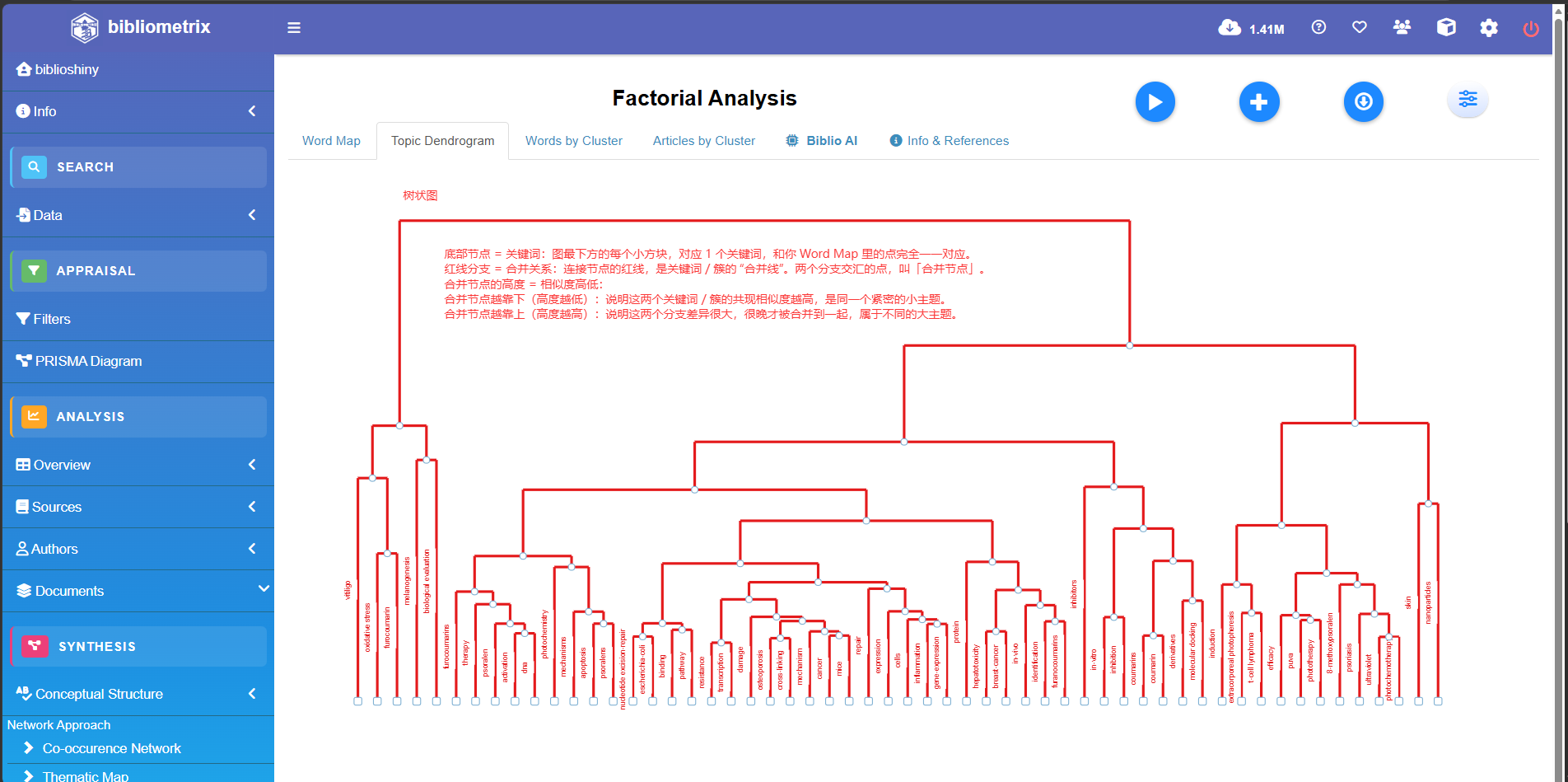
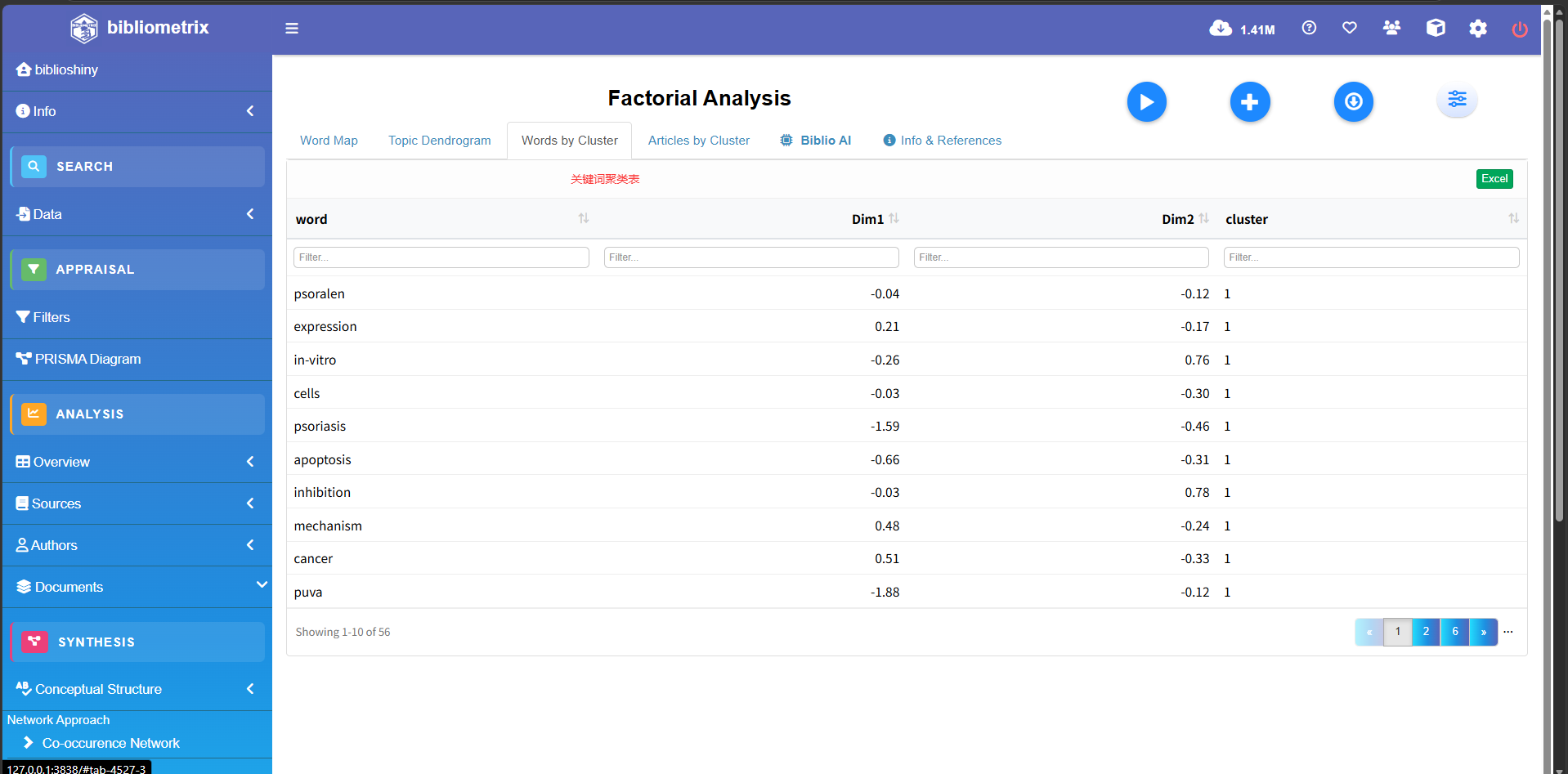
Factorial Analysis
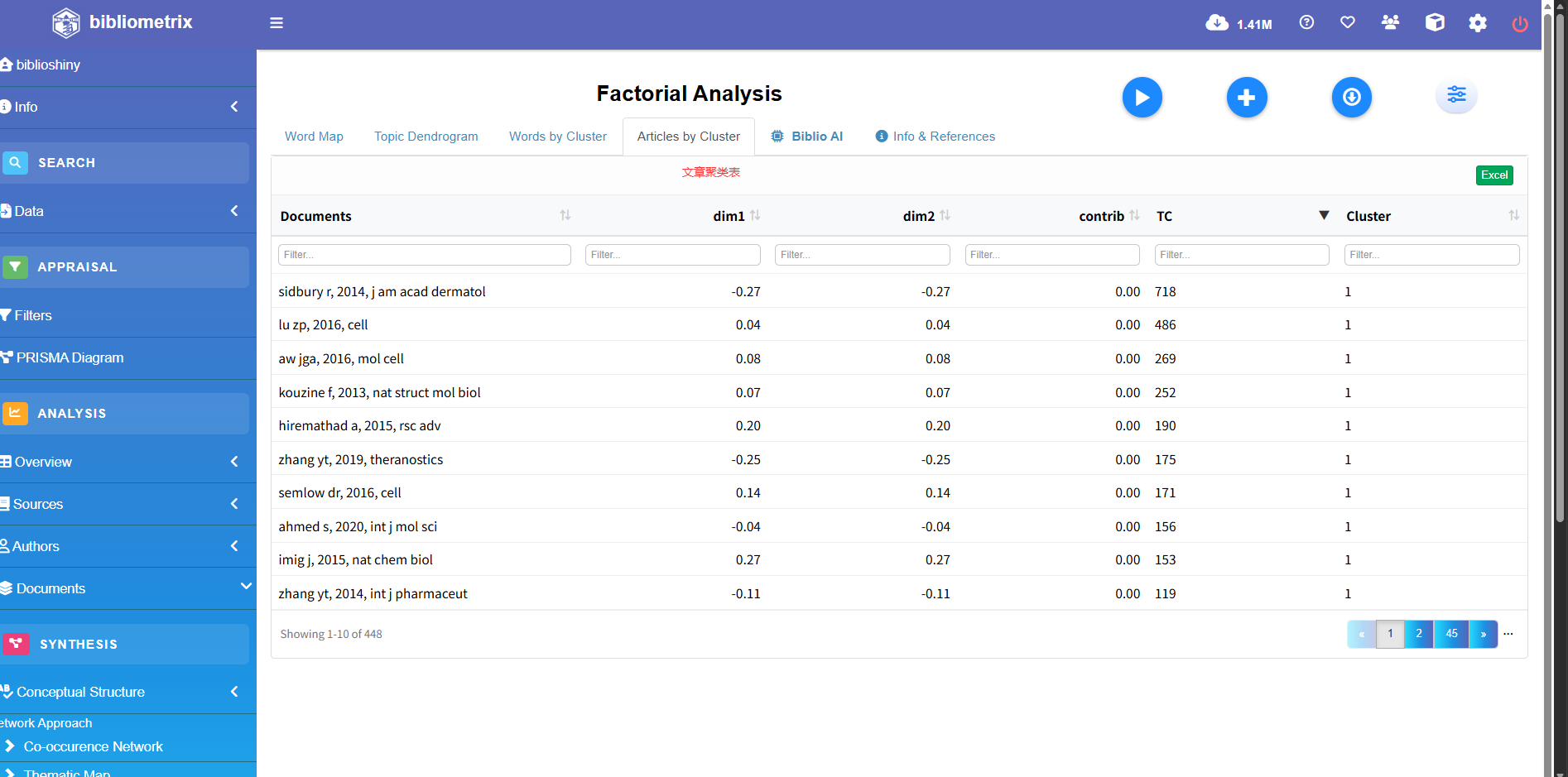
Intellectual Structure
Co-cition Network
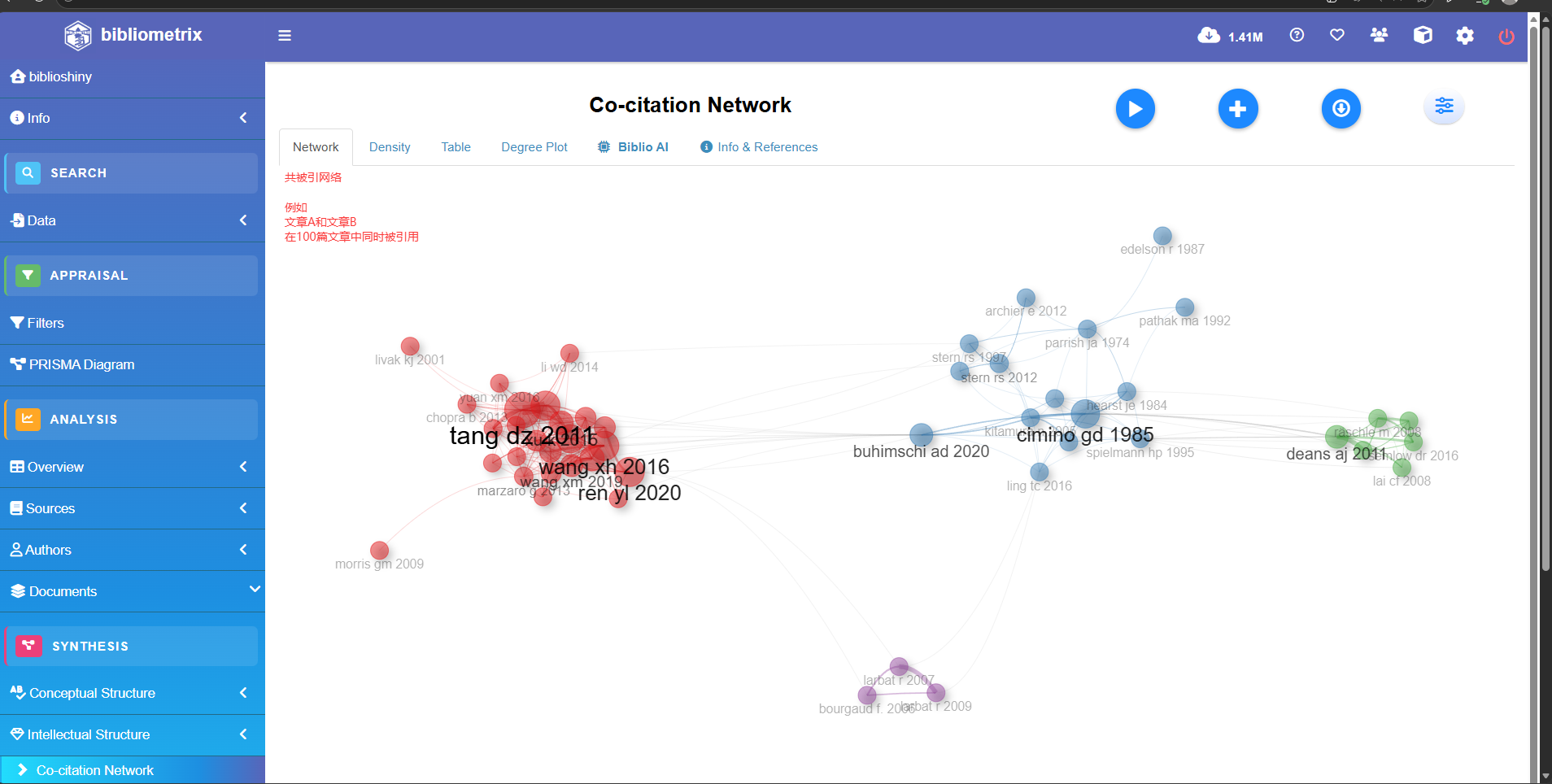
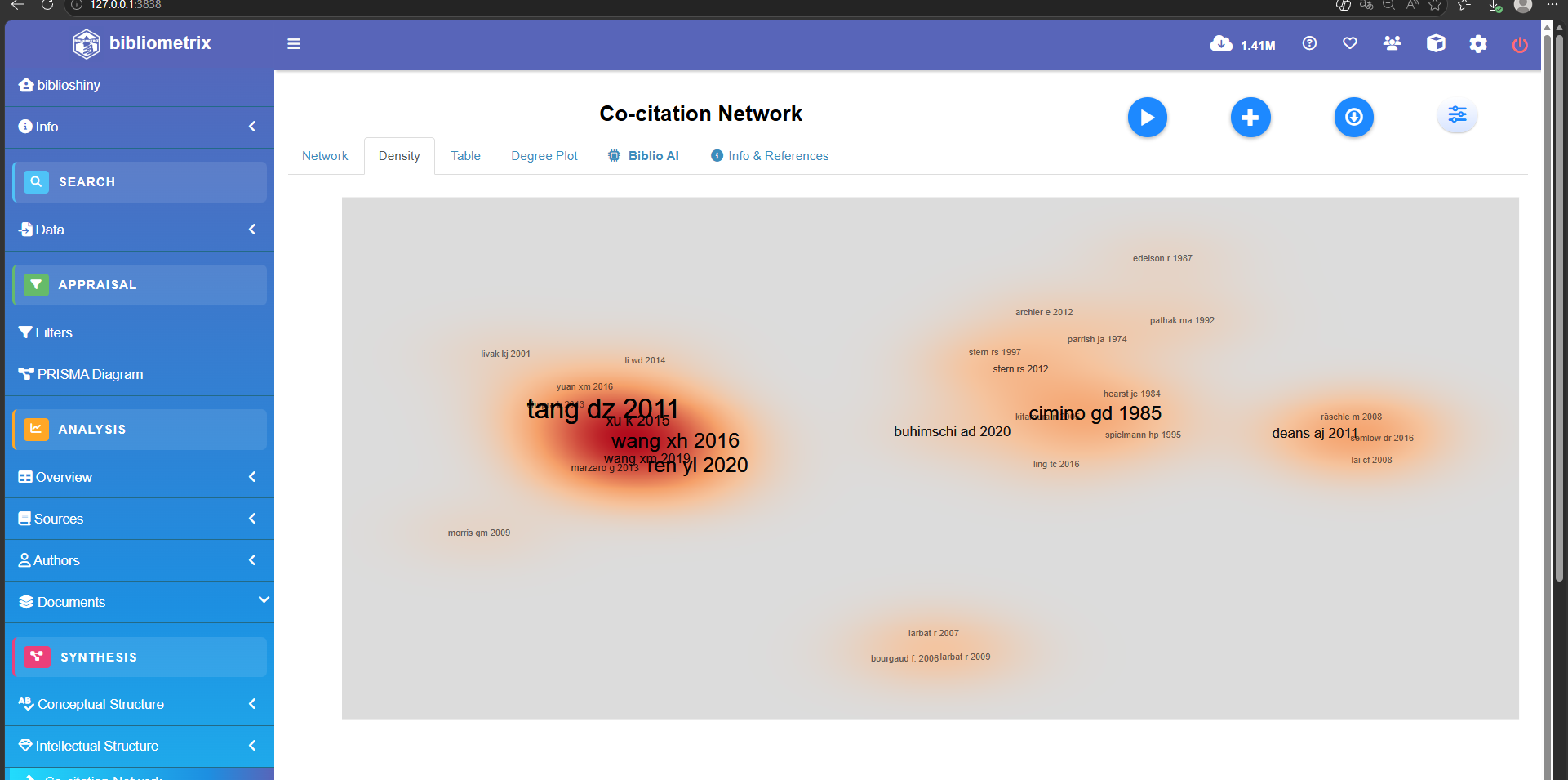
Historiograph
Social Structure
Collaboration Network
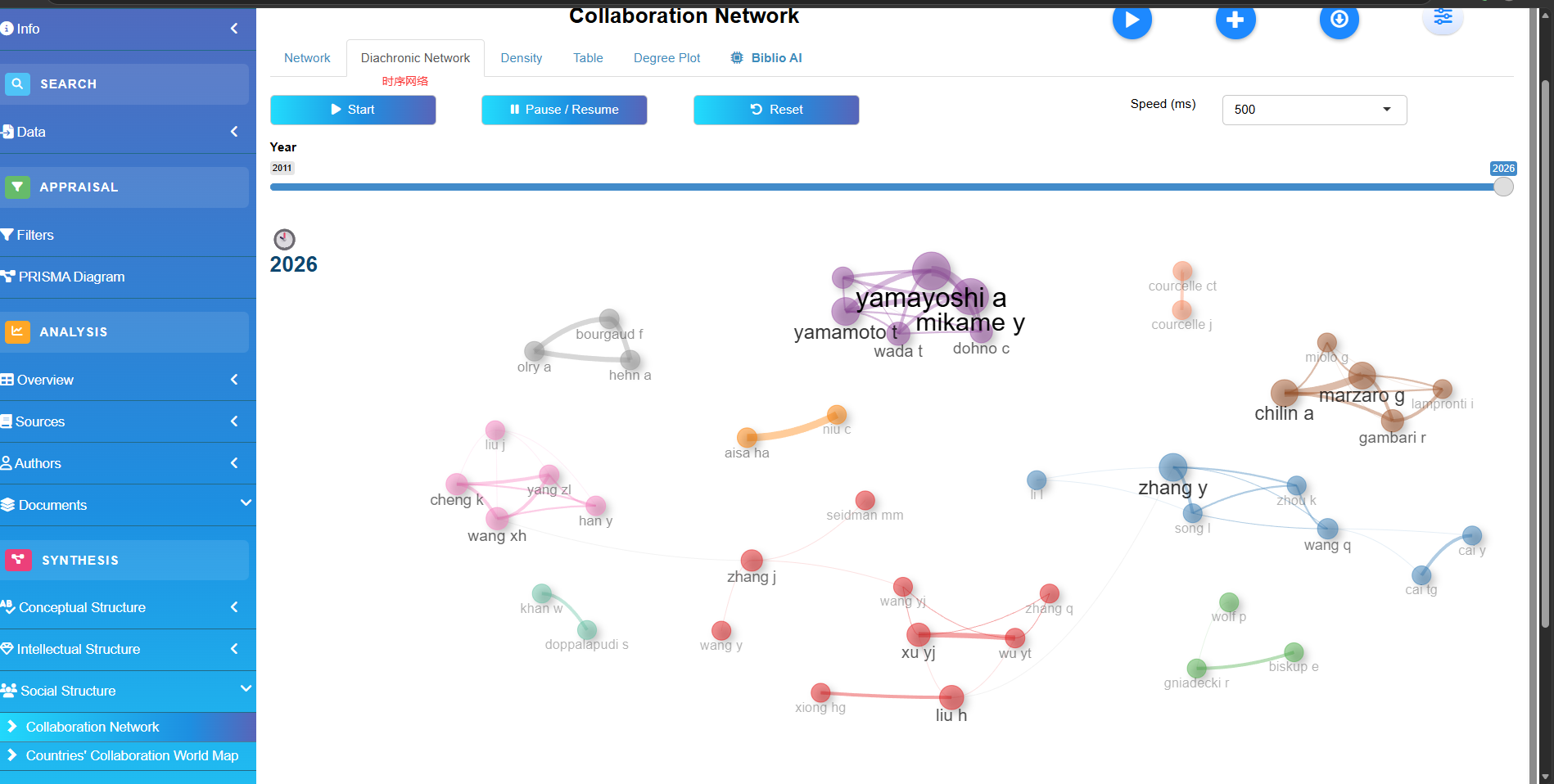
Countries'Collaboration World Map

报告
文献导入
各平台导出的文件类型
| 来源 | URL | 格式 | 文件后缀 |
|---|---|---|---|
| Web of Science | https://www.webofknowledge.com/ |
|
|
| Scopus | https://www.scopus.com/ |
|
|
| Dimensions | https://app.dimensions.ai/ |
|
|
| The Lens | https://lens.org/ |
|
|
| PubMed | https://pubmed.ncbi.nlm.nih.gov/ |
|
|
| Cochrane Library | https://www.cochranelibrary.com/ |
|
|
各平台可导出的元数据类型
| 来源 | 格式 | 元数据类型 |
|---|---|---|
| Web of Science |
|
|
| Scopus |
|
|
| Dimensions |
|
|
| The Lens |
|
|
| PubMed |
|
|
| Cochrane Library |
|
|
导入代码
library("bibliometrix")
# 设置工作目录
work_dir <- "C:\\Users\\47770\\Desktop\\test"
setwd(work_dir)
#你的文件名字
#方式1
file <- c("savedrecs.txt","savedrecs1.txt")
M <- convert2df(file, dbsource = "wos", format = "plaintext")
head(M['TC'])
#dbsource是你的数据库名,format是你导出的格式
#这里文件名用向量输入会自动合并
#你也可以手动合并如下
#方式2
#library(dplyr)
#M1 <- convert2df("savedrecs.txt", dbsource = "wos", format = "plaintext")
#M2 <- convert2df("savedrecs1.txt", dbsource = "wos", format = "plaintext")
#M3 <- bind_rows(M1,M2)注:导入方式大同小异,不做过多赘述,下文将对两种导入方式进行评析
方式1:官方推荐写法,自动合并+去重,代码简洁,缺点有文件损坏的时候不好排查
方式2:不太推荐,手动合并+后续需要手动去重,代码庞杂,占用巨量内存,更好更优的手动去重方法,后续我会发文章基于24年一篇文献里的方法,优于自带的去重算法
dbsource和format参照表
| dbsource | format |
| wos | bibtex |
| scopus | plaintext |
| dimensions | endnote |
| lens | csv |
| pubmed | excel |
| cochrane | pubmed |
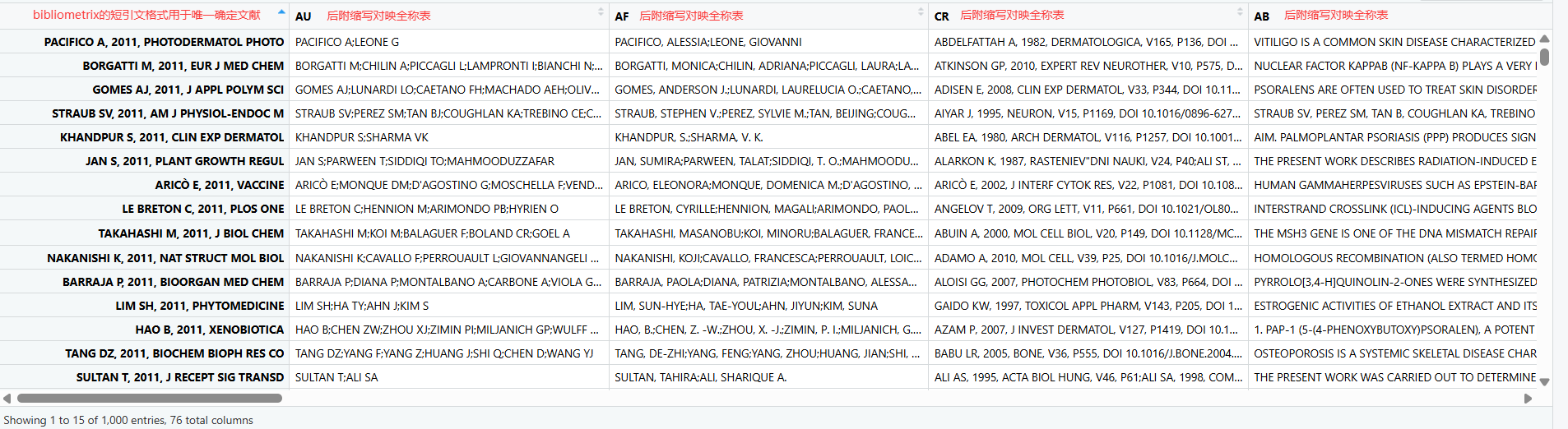
缩写与全称对映表
| Field Tag | Description |
|---|---|
| AU | Authors’ Names |
| TI | Document Title |
| SO | Journal Name (or Source) |
| JI | ISO Source Abbreviation |
| DT | Document Type |
| DE | Authors’ Keywords |
| ID | Keywords associated by SCOPUS or WoS database |
| AB | Abstract |
| C1 | Authors’ Affiliations |
| RP | Corresponding Author’s Affiliation |
| CR | Cited References |
| TC | Times Cited |
| PY | Publication Year |
| SC | Subject Category |
| UT | Unique Article Identifier |
| DB | Bibliographic Database |
文献去重清洗
清洗1(去重)
在这我们只介绍bibliometrix自带的去重,我未来会介绍另一种更加高级的去重方法,它文献里标称假阳率0%
M_new <- duplicatedMatching(M,Field = "TI",exact = FALSE,tol = 0.95)
#M为你的数据框
#Field为你去重的依据
#tol为你去重的阈值清洗2(关键词映射器)
引用下AI的话介绍下这个函数,主要是这个函数我也没咋用过,应该就是个ID和DE的映射器,把两个链接起来
这个函数
keywordAssoc(关键词关联/映射器) 是文献计量分析中一个非常硬核的“底层清洗与洞察工具”。在讲解它之前,必须先理清文献数据库(如 Web of Science 或 Scopus)里一个极其容易让人抓狂的概念:两种完全不同的关键词。
DE (Author Keywords / 作者关键词):作者自己填写的关键词。特点是非常具体、前沿、五花八门(比如作者可能填“深度卷积神经网络”、“CNN”、“ResNet50”)。
ID (Keywords Plus / 附加关键词):数据库官方算法根据这篇论文的“参考文献标题”自动提取的标准化词汇。特点是词汇高度统一、比较宽泛(比如不管作者写啥,官方可能统一打上一个大标签:“ARTIFICIAL INTELLIGENCE”)。
1. 核心功能:它是干嘛的?
keywordAssoc的作用就是做“词典翻译”和“概念拆解”。它会去寻找这两种关键词之间的关联:“当数据库给这批文章打上某个官方大标签 (ID) 时,底下的作者们实际上真正在研究的细分技术 (DE) 是什么?”
举个通俗的例子: 你用这个函数查一下 ID 里的
"CANCER"(癌症),它可能会返回给你关联度最高的前 10 个 DE:"LUNG CANCER" (肺癌),"CHEMOTHERAPY" (化疗),"APOPTOSIS" (细胞凋亡)等等。 这就把你从宏观的算法标签,直接拉回到了真实的微观研究细节里。2. 核心参数拆解:如何精准控制?
M: 你的总文献数据框。
sep: 关键词之间的分隔符,默认";"(一般不需要动)。
n: 你想为每个 ID 关联多少个 DE?默认是10。也就是查出每个大标签下最常出现的 10 个具体作者关键词。
excludeKW: (极其好用的“杀器”参数!) 剔除黑名单。很多时候,你的检索词(比如你就是搜“Machine Learning”下载的文献)会霸占所有关键词的榜首,变成没有信息量的废词。你可以把它们填在这里直接删掉(如c("MACHINE LEARNING", "REVIEW"))。3. 在写 SCI 论文时,它有什么妙用?
降维与合并词汇(预处理神器):如果你发现 ID 为 "OPTIMIZATION" 关联的 DE 全是各种拼写错误的算法名字,你就可以以此为依据,在后续画图前把这些词合并。
深度解释聚类图(拔高论文深度):当你画出主题战略图(
thematicMap),发现某个聚类的中心词是一个很虚的 ID 词汇(如 "SYSTEMS")。你就可以偷偷跑一下这个函数,然后在论文里写:“虽然该聚类的核心标签为 SYSTEMS,但通过keywordAssoc深度挖掘其底层作者关键词关联发现,该主题实质上聚焦于 X、Y、Z 等具体细分技术……” 这种分析会显得你极度专业。构建检索式:帮你扩充同义词,发现你以前没想到的检索词。
# =====================================================================
# 函数名称: keywordAssoc (来自 bibliometrix 包)
# 主要功能: 建立“附加关键词(ID)”与“作者关键词(DE)”之间的关联映射字典
# =====================================================================
# 1. 设定要剔除的“无意义高频词/检索词”黑名单 (非常建议设置)
# 假设你的综述就是写“大数据”的,那把“大数据”剔除掉能看到更多有用的细节
my_stopwords <- c("BIG DATA", "REVIEW", "META-ANALYSIS")
# 2. 运行关联提取
KWlist <- keywordAssoc(
M = your_dataframe, # 你的文献数据框
sep = ";", # 默认的分隔符
n = 10, # 为每个 ID 词汇提取排名前 10 的 DE 词汇
excludeKW = my_stopwords # 放入黑名单,防止它们霸榜
)
# 查看前 20 个最核心的 Keywords Plus (ID) 都是啥
print(names(KWlist)[1:20])
# 假设其中第一个词是 "ALGORITHMS",你想看作者在谈论算法时到底在谈论什么:
# 提取关联到第一个 ID 的前 10 个作者关键词 (DE)
print(KWlist[[1]][1:10])
# 如果你想精确查找某个特定的 ID (比如 "CLIMATE CHANGE") 关联了哪些 DE:
# print(KWlist[["CLIMATE CHANGE"]])清洗3(关键词合并)
# =====================================================================
# bibliometrix 数据清洗函数:mergeKeywords()
# =====================================================================
# 功能:将作者关键词(DE)和数据库补充关键词(ID)合并,并自动去重和清理格式。
# 结果:会在数据集中生成一个名为 "KW_Merged" 的新列。
M_cleaned <- mergeKeywords(
M = M_new, # 你的文献数据框
force = FALSE # 是否强制覆盖已有的 KW_Merged 列?
# FALSE(默认) = 如果已存在该列则跳过;TRUE = 强制重新生成并覆盖
)清洗4(细节数据提取)
metaTagExtraction(M_new, Field = "CR_AU", sep = ";", aff.disamb = TRUE)
# 参数详解:
# 1. M : [必填项] 数据框。经过 convert2df() 转换后的标准文献数据集。
#
# 2. Field : [必填项] 字符型。指定你要提取的目标字段,最常用的核心值包括:
# ▶ 参考文献相关 (用于共被引分析)
# - "CR_AU" : 提取每条参考文献的【第一作者】
# - "CR_SO" : 提取每条参考文献的【来源期刊】(极其常用!)
# ▶ 作者地理位置相关 (用于合作网络分析)
# - "AU_CO" : 提取所有合著者的【所属国家】
# - "AU1_CO" : 仅提取第一/通讯作者的【所属国家】
# ▶ 作者机构相关
# - "AU_UN" : 提取合著者的【所属大学/机构】(会同步生成第一作者机构 AU1_UN)
# ▶ 标签生成
# - "SR" : 提取/生成该文献的【短标签】(格式: 第一作者_年份_期刊短名)
#
# 3. sep : [可选项] 字符型。字段内多个元素的间隔符,默认值为 ";"。
#
# 4. aff.disamb : [可选项] 逻辑值。特供 Field="AU_UN" (提取机构) 使用。
# - TRUE (默认) : 自动启用消歧义算法,将拼写不同但实际是同一所
# 大学的条目进行合并(如 Harvard Univ = Univ Harvard)。
# - FALSE : 不进行智能合并,原样提取。清洗5(数据质量检查)
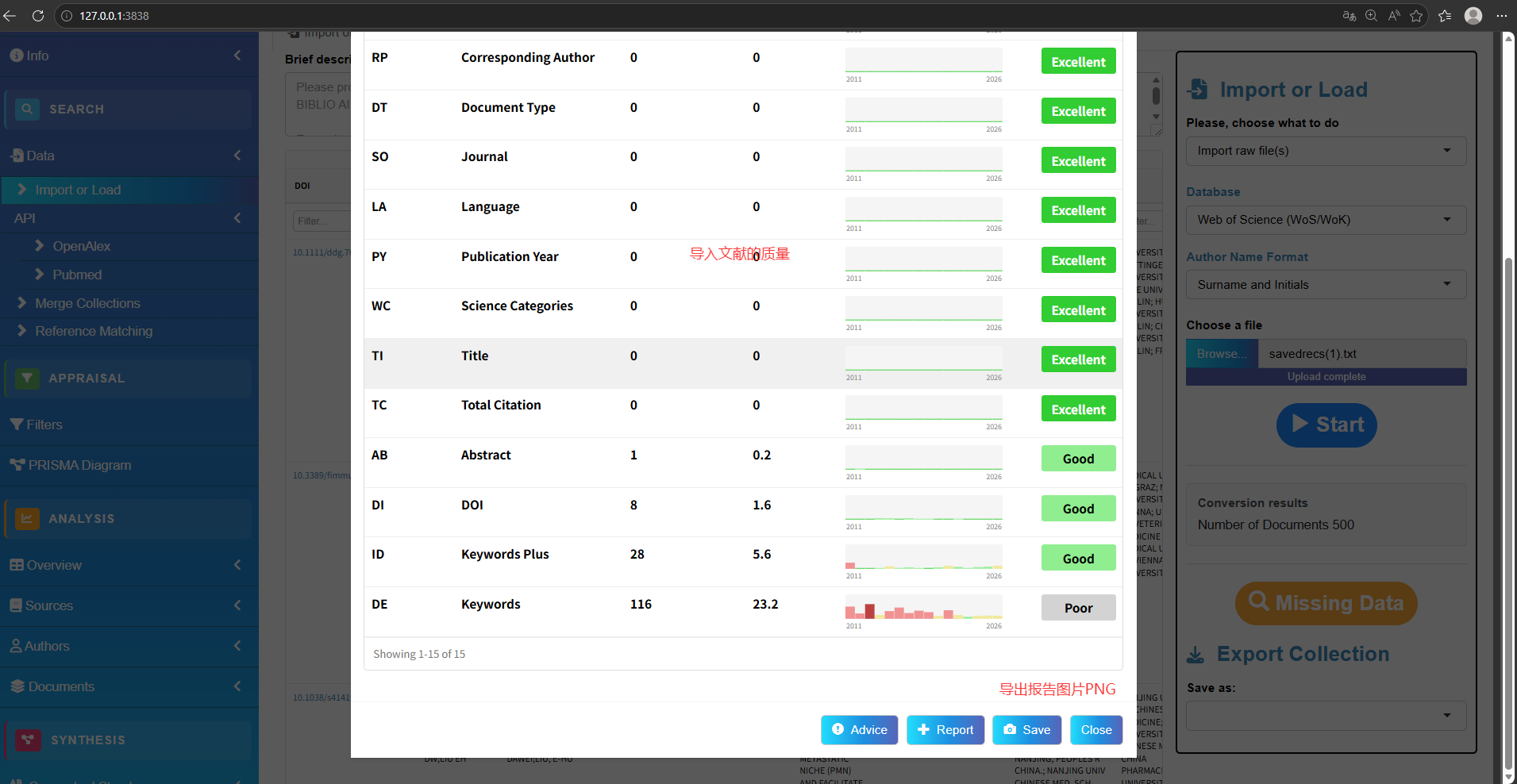
missingData(M_new)
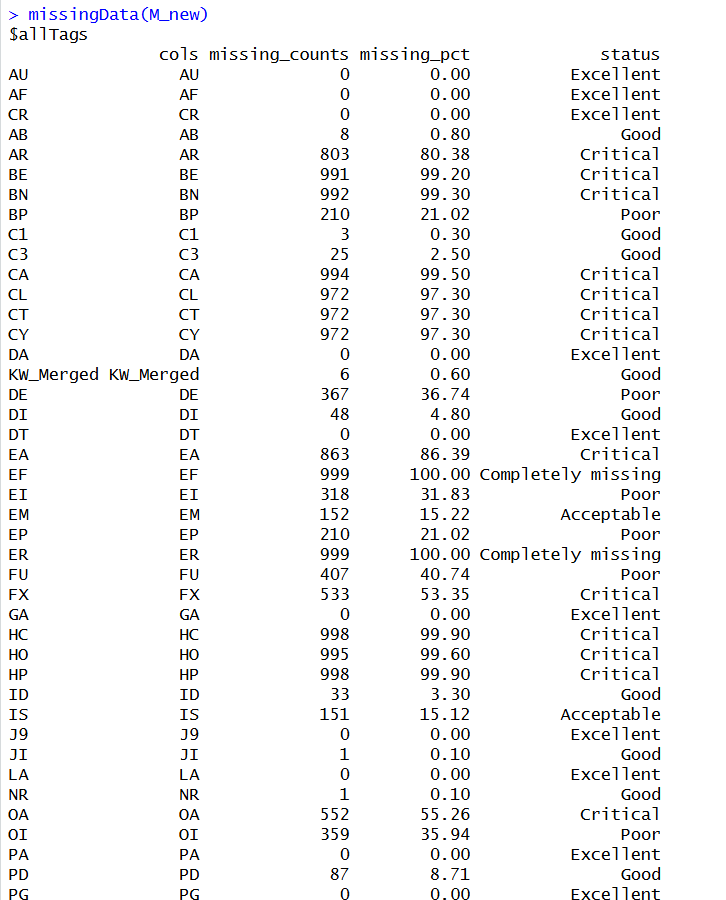
清洗6(引文标准化与清洗)
仅仅标准化 仅支持输入向量
CR<-M_new$CR
CR_vector <- unlist(strsplit(CR, ";"))
CR_vector <- trimws(CR_vector) # 去除首尾多余空格
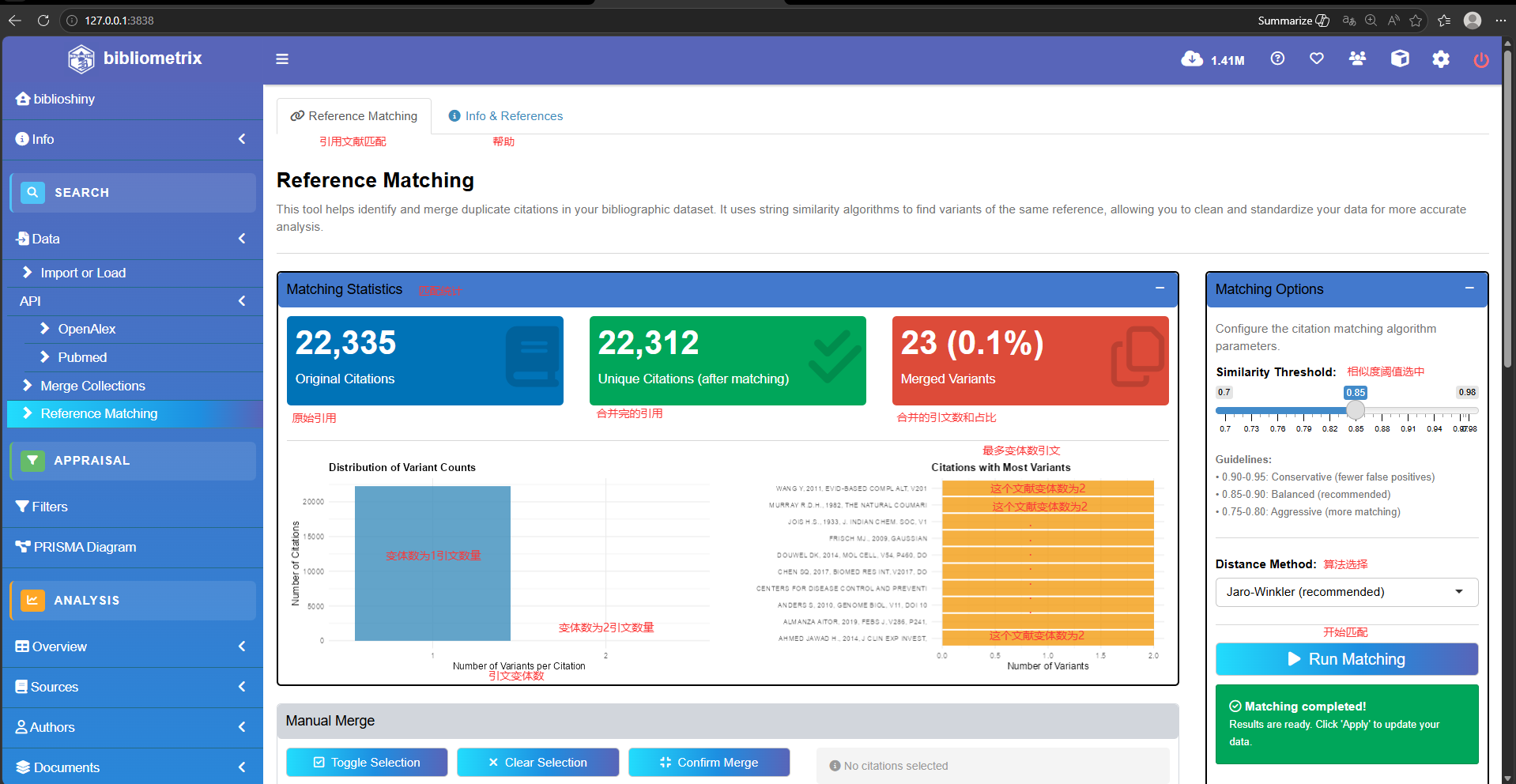
matched_data <- normalize_citations(
CR_vector = CR_vector, # [必填] 字符向量格式的参考文献原始数据
threshold = 0.9, # [可选] 相似度匹配阈值 (0~1)。
# 0.90-0.95 较保守(严谨,不易误判);
# 0.75-0.80 较激进(适合极度脏乱的数据)。
method = "jw", # [可选] 字符串距离计算方法。
# 默认 "jw" (Jaro-Winkler),极其适合处理书目信息的排版错漏;
# 也可选 "lv" (Levenshtein)。
min_chars = 20 # [可选] 判定为有效引用的最小字符数,默认20。太短的残缺文本会被忽略。
)全流程
# =====================================================================
# 自动化文献清洗与匹配:applyReferenceMatching()
# 功能:自动提取、匹配去重并重组整个数据框的参考文献 (CR) 字段。
# =====================================================================
results <- applyReferenceMatching(
M = M_new, # 你的原始文献数据框 (由 convert2df 生成,必须包含 SR 和 CR 列)
threshold = 0.85, # 匹配阈值 (0~1)。0.85 为官方推荐的精准与召回率平衡点;
# 调高(如0.95)更保守防误判,调低(如0.75)更激进多合并。
method = "jw", # 字符串距离算法。默认 "jw" (Jaro-Winkler,最适合排版错漏),也可选 "lv"。
min_chars = 20 # 最小有效字符数限制,默认 20。太短的残缺引用会被直接忽略。
)
# 运行后,最重要是 results$CR_normalized。
# 将它与原数据框 M 合并(按 SR 列),替换掉旧的脏 CR 列,再进行网络分析。清洗7(主题提取)
这个函数会自动分词在标题等提取出关键词
# =====================================================================
# 文本挖掘与词汇提取引擎:termExtraction()
# 功能:从文献的文本字段(标题、摘要等)中自动提取单词或短语,
# 并在原数据框中生成一列全新的、干净的文本数据 (带有 _TM 后缀)。
# =====================================================================
M_new <- termExtraction(
M = , # 标准文献数据框
Field = "TI", # 目标提取字段。可选:"TI"(标题,默认), "AB"(摘要), "ID"(扩展关键词), "DE"(作者关键词)
ngrams = 1, # 提取的词组长度(1~4)。1为单字,2为双词短语(如 "data mining")
stemming = FALSE, # 逻辑值。是否进行词干提取?若为TRUE,会将 "running"/"runs" 统一截断为 "run"
language = "english", # 文本语言,默认 "english"
remove.numbers = TRUE, # 逻辑值。是否在提取前自动删除文本中的所有数字?默认 TRUE
remove.terms = NULL, # 黑名单字典(字符向量)。强制删除没有营养的常用词(如 c("paper", "study", "results"))
keep.terms = NULL, # 专有名词保护(字符向量)。遇到这些特定的复合词不要拆开(如 c("co-citation analysis"))
synonyms = NULL, # 同义词合并(字符向量)。格式为 "主词;同义词1;同义词2"
verbose = TRUE # 逻辑值。运行完毕后,是否在控制台打印展示最常出现的那些词?默认 TRUE
)

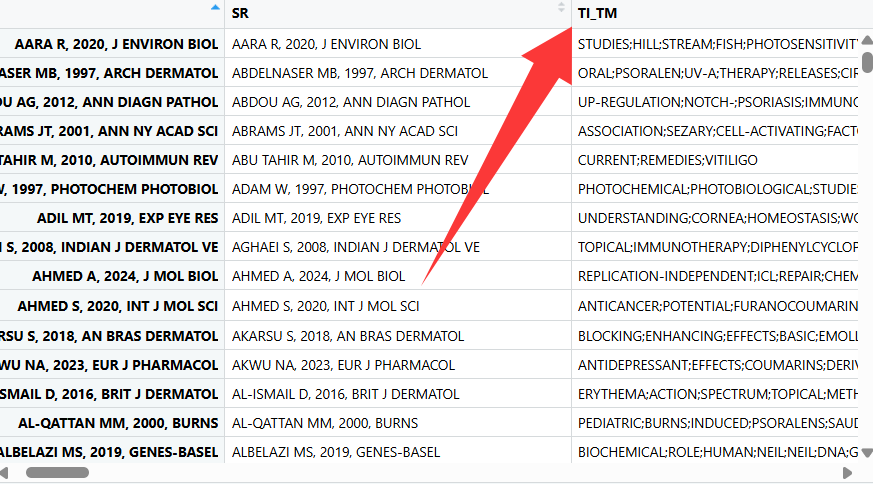
清洗8(去空格小函数)
-
用
trim()洗完变成:"人工智能 时代"(首尾干净了,中间不管) -
用
trim.leading()洗完变成:"人工智能 时代 "(只有前面干净了) -
用
trimES()洗完变成:" 人工智能 时代 "(中间多余的空格被干掉了)
# =====================================================================
# 底层文本清理函数:trim / trim.leading / trimES
# 功能:专门用于清除字符串中多余的空格,属于内部辅助小工具。
# =====================================================================
# 1. 掐头去尾:同时删除字符串【开头】和【结尾】的所有空格
res1 <- trim(
x = # [必填] 字符对象 (即你需要处理的文本内容或字符串向量)
)
# 2. 仅剔开头:只删除字符串【最前面】的空格(保留结尾的空格)
res2 <- trim.leading(
x = # [必填] 字符对象
)
# 3. 内部瘦身:删除文本中间【额外的/连续的多余空格】 (比如把连续的3个空格压缩成1个正常的空格)
res3 <- trimES(
x = # [必填] 字符对象
)多数据库合并
我们使用mergeDbSources函数对多数据库来源的文献进行合并
M <- mergeDbSources(M1, M2, remove.duplicated = TRUE, verbose = TRUE)
#M1,M2为convert2df转化完成的来自不同数据库的数据框1和数据框2
#remove.duplicated 是是否进行去重
#verbose为是否在控制台输出重复的文献文献基本主要信息
使用biblioAnalysis函数对转化完成的数据库进行文献计量学分析,然后通过summary函数进行汇总
results <- biblioAnalysis(M,sep=";")S <- summary(object = results, k = 10, pause = FALSE)
#k的值是你展示每个数据,展示多少条
S的数据结构
首先我们看一下控制台输出的内容
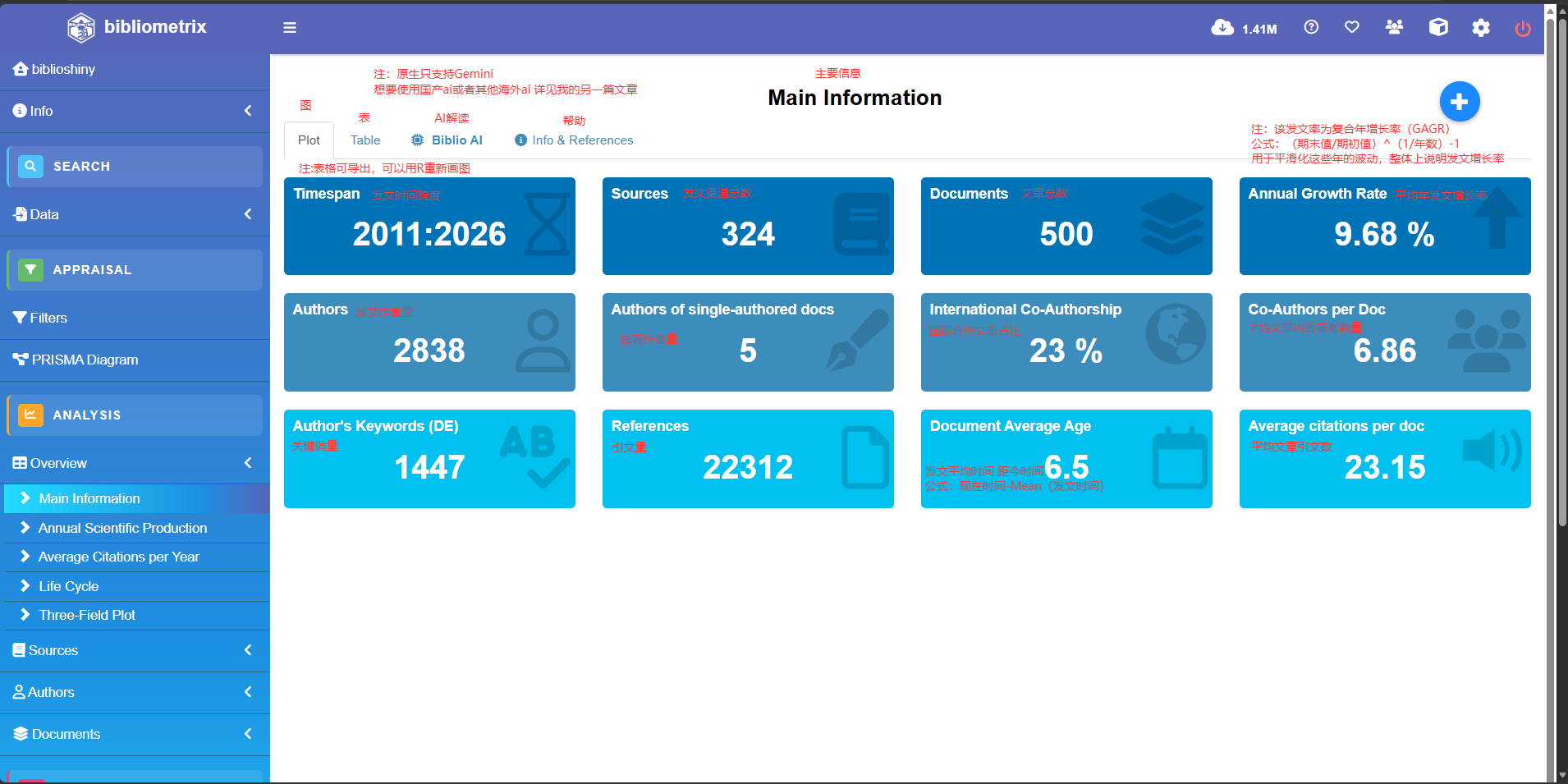
文献基本主要信息
MAIN INFORMATION ABOUT DATA
Timespan 1997 : 2026 #时间跨度
Sources (Journals, Books, etc) 491 #期刊数量
Documents 1000 #导入的文章总数
Annual Growth Rate % -1.53
#年发文量复合增长率 注意这个增长率不是算数增长率 公式如下(期末值/期初值)^(1/年数)-1
#这样弄的好处是可以考虑起始和结束 从而平滑掉这些年的波动 从整体上说明增长情况
Document Average Age 14.4 #发文平均时间距今的时间
Average citations per doc 35.15 #每篇文章被引数
Average citations per year per doc 2.407 #被引数每年每篇
References 36569 #总引文数
DOCUMENT TYPES
article 871 #文章类型们
article; early access 3
article; proceedings paper 27
article; retracted publication 1
review 97
review; book chapter 1
DOCUMENT CONTENTS
Keywords Plus (ID) 3420 #文章类型
Author's Keywords (DE) 2173
AUTHORS
Authors 4454 作者数(去重后)
Author Appearances 5781 作者数(去重前)
Authors of single-authored docs 31
AUTHORS COLLABORATION
Single-authored docs 32 #独著文章数
Documents per Author 0.225
Co-Authors per Doc 5.78
International co-authorships % 21.3 #国际合作者占比
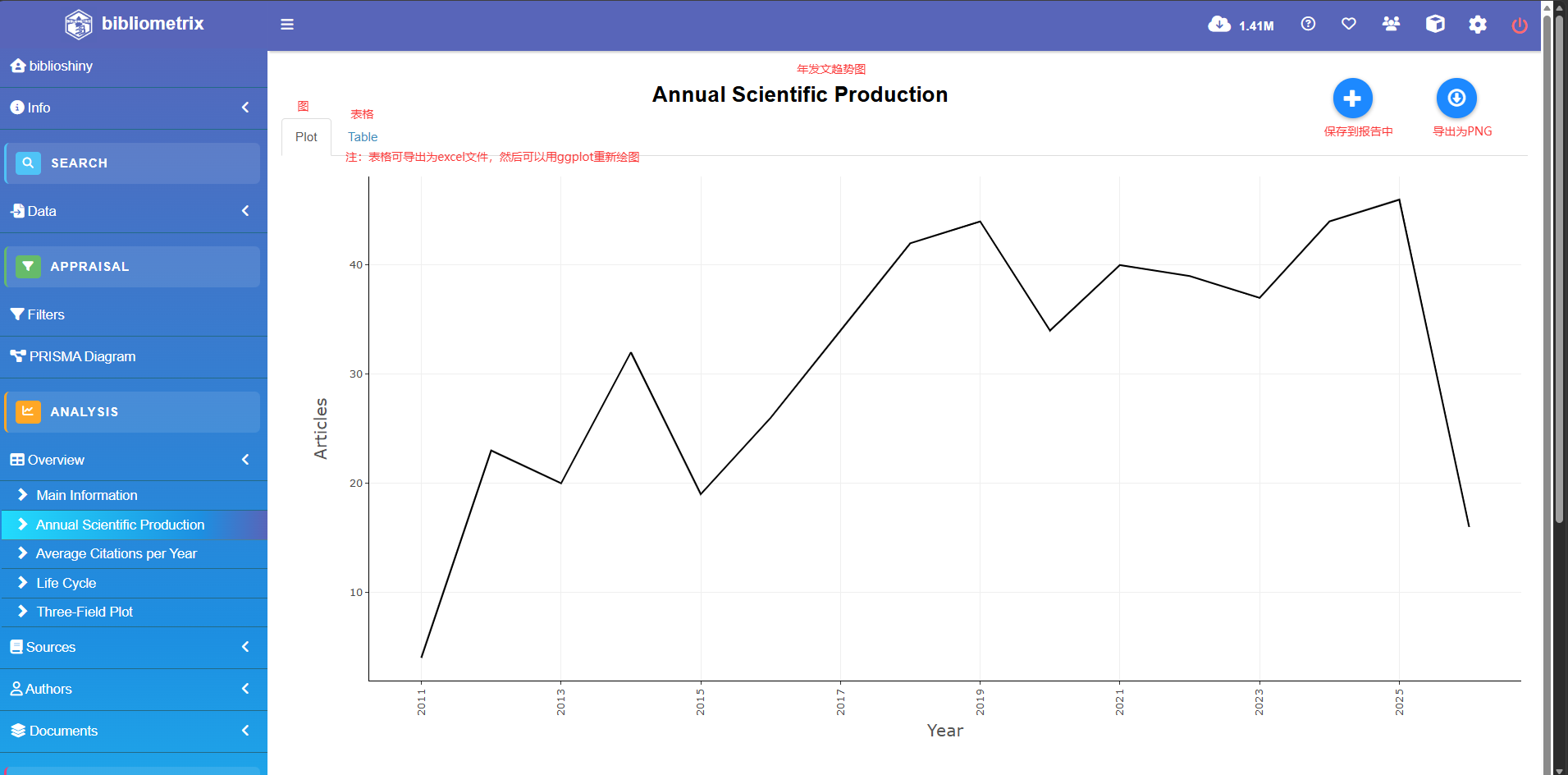
Annual Scientific Production #年发文趋势
Year Articles
1997 25
1998 35
1999 40
2000 32
2001 41
2002 38
2003 30
2004 41
2005 30
2006 38
2007 36
2008 31
2009 36
2010 28
2011 23
2012 23
2013 20
2014 32
2015 19
2016 26
2017 34
2018 42
2019 44
2020 34
2021 40
2022 39
2023 37
2024 44
2025 46
2026 16
Annual Percentage Growth Rate -1.53
Most Productive Authors#最高产作者
#注:左侧为正常的文章数量,每篇权重为1,右侧为分数化的文章数量,每篇文章权重为1/总合著者
Authors Articles Authors Articles Fractionalized
1 SEIDMAN MM 28 VASQUEZ KM 6.58
2 GLAZER PM 19 GLAZER PM 5.46
3 VASQUEZ KM 19 SEIDMAN MM 4.89
4 WOLF P 17 WOLF P 3.19
5 MAJUMDAR A 13 CAFFIERI S 2.85
6 MILLER PS 12 OH DH 2.42
7 GIA O 11 MILLER PS 2.31
8 YAMAYOSHI A 11 IBBOTSON SH 2.27
9 CHILIN A 10 RANA TM 2.03
10 LI L 10 GIA O 2.00
Top manuscripts per citations
Paper DOI TC#总引数 TCperYear#年均引用数 NTC
1 GRIFFITH JD, 1999, CELL 10.1016/S0092-8674(00)80760-6 1976 70.6 18.26
2 SIDBURY R, 2014, J AM ACAD DERMATOL 10.1016/j.jaad.2014.03.030 718 55.2 14.13
3 LU ZP, 2016, CELL 10.1016/j.cell.2016.04.028 486 44.2 7.58
4 MASUTANI C, 2000, EMBO J 10.1093/emboj/19.12.3100 447 16.6 7.62
5 MURUVE DA, 1999, HUM GENE THER 10.1089/10430349950018364 394 14.1 3.64
6 CHIU YL, 2002, MOL CELL 10.1016/S1097-2765(02)00652-4 304 12.2 7.24
7 TAIEB A, 2013, BRIT J DERMATOL 10.1111/j.1365-2133.2012.11197.x 297 21.2 6.42
8 SCHNELL MA, 2001, MOL THER 10.1006/mthe.2001.0330 285 11.0 5.98
9 CESARE AJ, 2004, MOL CELL BIOL 10.1128/MCB.24.22.9948-9957.2004 279 12.1 6.17
10 VAN RHENEN D, 2003, BLOOD 10.1182/blood-2002-03-0932 273 11.4 7.50
Corresponding Author's Countries
#通讯所在国家
Country Articles Freq SCP MCP MCP_Ratio
1 USA 275 0.2792 221 54 0.196
2 CHINA 192 0.1949 169 23 0.120
3 ITALY 68 0.0690 49 19 0.279
4 GERMANY 53 0.0538 40 13 0.245
5 JAPAN 43 0.0437 38 5 0.116
6 INDIA 42 0.0426 35 7 0.167
7 FRANCE 40 0.0406 29 11 0.275
8 UNITED KINGDOM 38 0.0386 28 10 0.263
9 AUSTRIA 23 0.0234 13 10 0.435
10 RUSSIA 22 0.0223 18 4 0.182
SCP: Single Country Publications
MCP: Multiple Country Publications
Total Citations per Country #国家被引量
Country Total Citations Average Article Citations
1 USA 15543 56.52
2 CHINA 3424 17.83
3 GERMANY 1915 36.13
4 UNITED KINGDOM 1809 47.61
5 ITALY 1703 25.04
6 JAPAN 1521 35.37
7 FRANCE 1474 36.85
8 AUSTRIA 885 38.48
9 INDIA 872 20.76
10 KOREA 523 29.06
Most Relevant Sources#最高产的期刊 和 发表的篇数
Sources Articles
1 NUCLEIC ACIDS RESEARCH 40
2 BIOCHEMISTRY 24
3 JOURNAL OF BIOLOGICAL CHEMISTRY 20
4 PHOTOCHEMISTRY AND PHOTOBIOLOGY 19
5 BRITISH JOURNAL OF DERMATOLOGY 16
6 MOLECULAR AND CELLULAR BIOLOGY 12
7 PHOTODERMATOLOGY PHOTOIMMUNOLOGY & PHOTOMEDICINE 12
8 PROCEEDINGS OF THE NATIONAL ACADEMY OF SCIENCES OF THE UNITED STATES OF AMERICA 12
9 FRONTIERS IN PHARMACOLOGY 11
10 JOURNAL OF INVESTIGATIVE DERMATOLOGY 11
Most Relevant Keywords #最相关的关键词
Author Keywords (DE) Articles Keywords-Plus (ID) Articles
1 PSORALEN 185 PSORALEN 156
2 PSORIASIS 33 EXPRESSION 96
3 PUVA 28 IN-VITRO 76
4 VITILIGO 24 DNA 67
5 DNA REPAIR 23 CELLS 65
6 8-METHOXYPSORALEN 19 MECHANISM 54
7 APOPTOSIS 18 MAMMALIAN-CELLS 53
8 PHOTOCHEMOTHERAPY 16 NUCLEOTIDE EXCISION-REPAIR 53
9 FUROCOUMARIN 15 INHIBITION 52
10 PHOTOTOXICITY 15 PHOTOCHEMOTHERAPY 51ggplot2绘制年份图
接下来我们使用ggplot绘制一下 年发文的折现图
注:你在绘图的时候可能会遇到2个问题:
1:bibliometrix生成的数据框名字里面会有空格和隐藏符,需要你手动删除
2:ggplot会默认把你的年份识别成字符串或者因子 导致你只有点没有线
代码如下
colnames(AnnualProduction) <- trimws(colnames(AnnualProduction))#给表名去空格
AnnualProduction$Year <- as.numeric(as.character(AnnualProduction$Year))#让你年份数字化
ggplot(AnnualProduction, aes(x = Year, y = Articles)) + #绘图
geom_line(linewidth = 1.2, color = "#2980b9") + #绘线
geom_point(size = 2.5, color = "#2980b9") + #绘点
labs(
x = "发表年份",
y = "年度发文量",
title = "研究领域年度发文趋势"
) +
theme_bw()+#简约化
theme(
axis.text.x = element_text(angle = 45, hjust = 1),
plot.title = element_text(hjust = 0.5, face = "bold")
)+#图注位置和坐标轴上面刻度字体
scale_x_continuous(breaks = AnnualProduction$Year)#确保每个年份都显示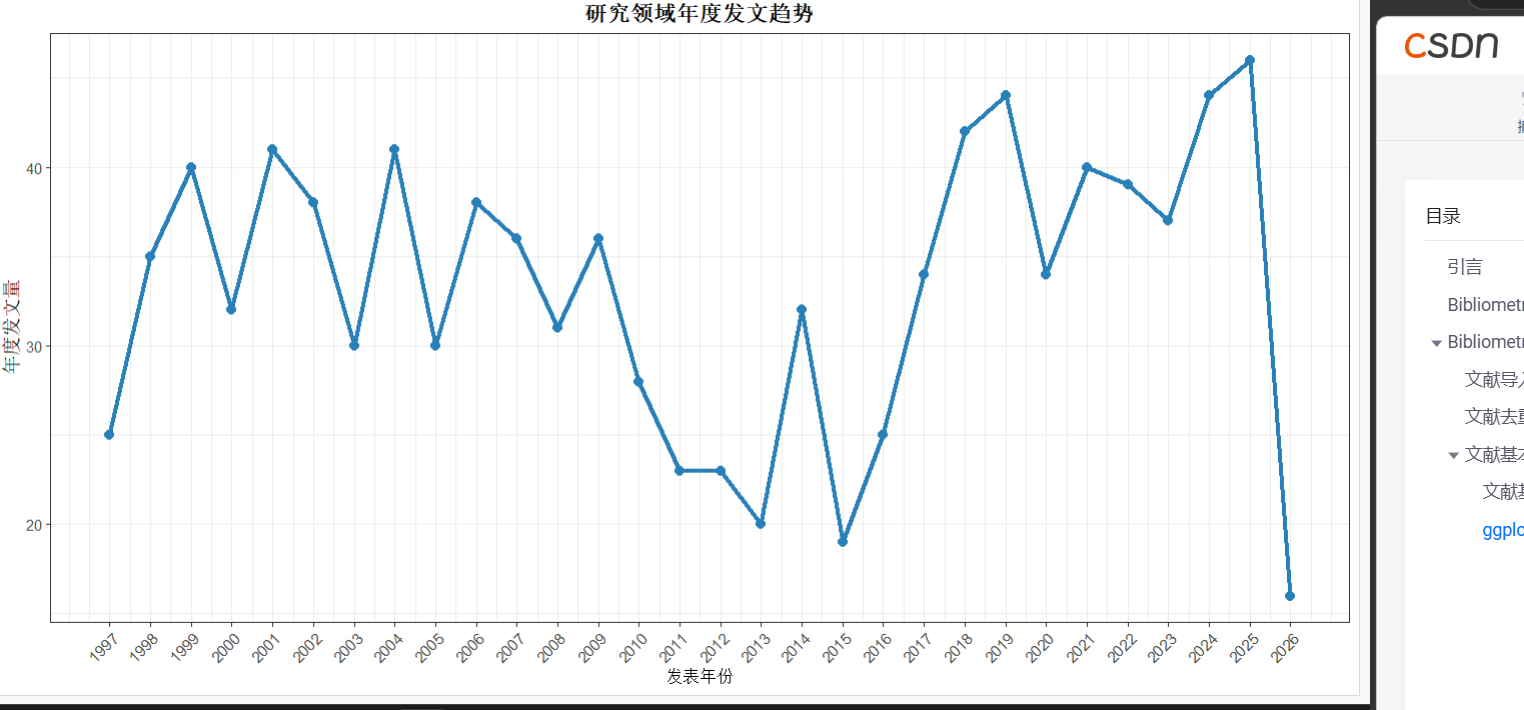
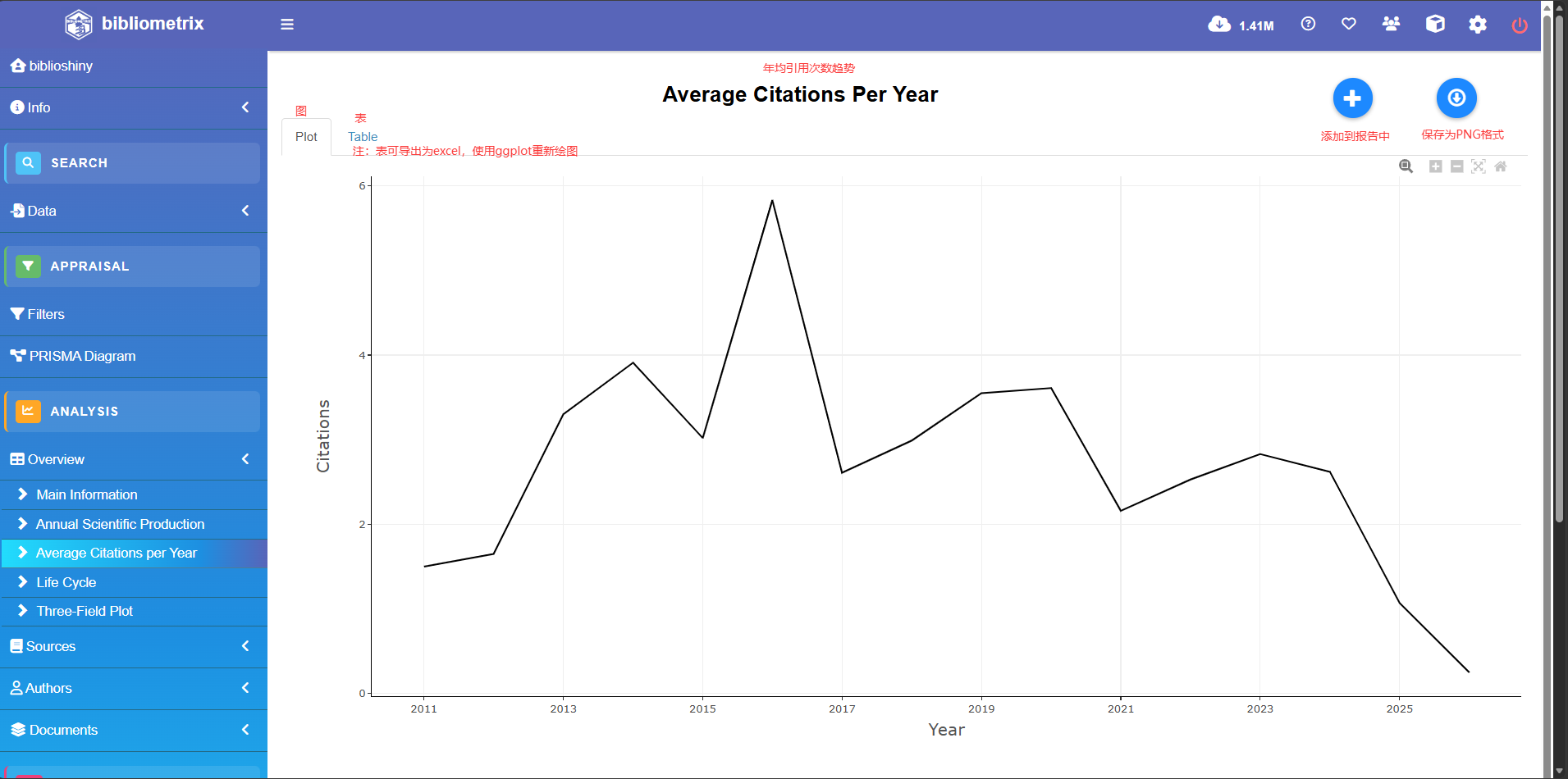
绘制年均引用趋势图
因为bibliometrix里面的biblioanalysis没有集成这个功能 故我们使用dylyr包实现
library("dplyr")
citation_data <- M_new %>%
filter(!is.na(PY))%>% #对发表年份为NA 的文献进行过滤
mutate(
PY= as.numeric(PY),
TC = as.numeric(TC)
)%>%#将PY列和TC列转化为数字格式
group_by(PY) %>%#按发表年份分组
summarise(
total_articles = n(),#统计一共每年有多少文献
total_citations = sum(TC , na.rm = TRUE),#统计每年的总引用量
meanTC = total_citations/total_articles#计算均值
)
ggplot(citation_data, aes(x = PY, y = meanTC)) +
geom_line(linewidth = 1.2, color = "#2980b9") +
geom_point(size = 2.5, color = "#2980b9") +
labs(
x = "发表年份",
y = "平均引用量",
title = "研究领域平均引用量趋势"
) +
theme_bw()+
theme(
axis.text.x = element_text(angle = 45, hjust = 1),
plot.title = element_text(hjust = 0.5, face = "bold")
)+
scale_x_continuous(breaks = citation_data$PY)#绘图跟发文趋势用的同款不做过多介绍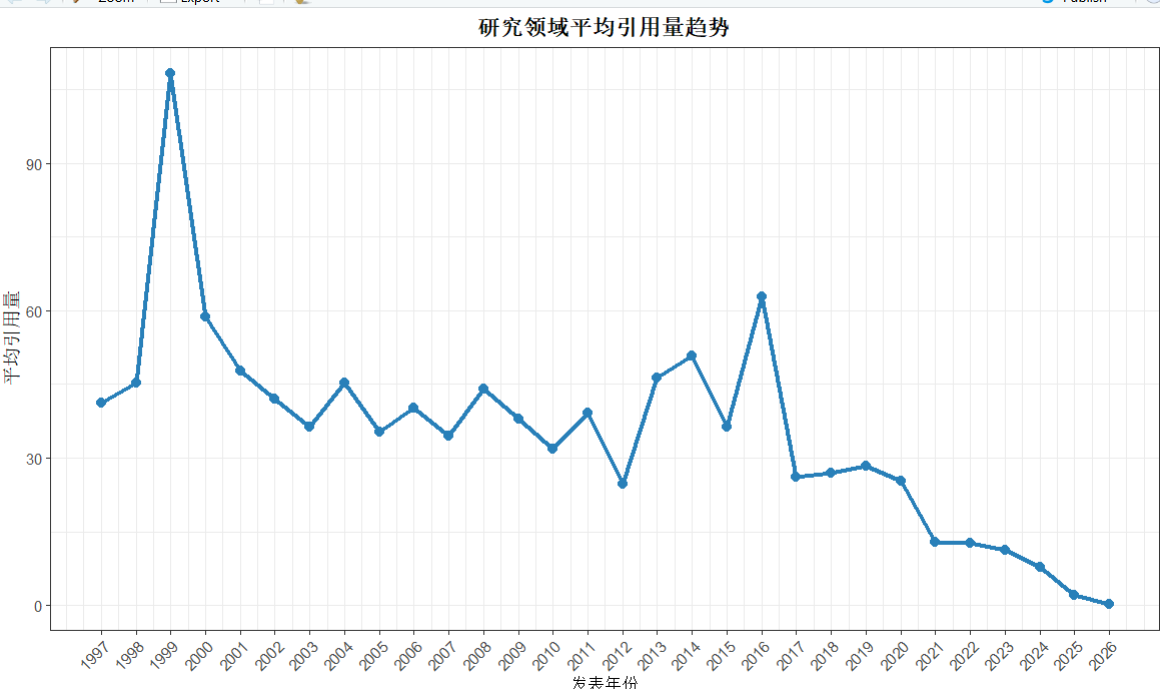
网络分析
网络构建
我们使用biblioNetwork函数进行构建
network_results <- biblioNetwork(
M,#你要分析的数据框
analysis = "collaboration",#分析的类型
network = "authors",#分析的对象
n=NULL,#分析前多少名
sep = ";",#间隔符,如作者1;作者2;作者3 间隔符就是“;”
short = FALSE,#是否精简,精简的是作者名或者机构名(缩写)
shortlabel = TRUE,#是否排序
remove.terms = NULL,#黑名单词 输入的是一个向量 如c("the","so")
synonyms = NULL#合并同义词 输入的是一个向量 如c("AI;Artificial Intelligence")
)可选的网络分析见下表
| 网络大类 (Category) | 网络类型 (Network Type) | 说明 | analysis 参数 | network 参数 |
|
Collaboration Networks (合作网络) |
Authors collaboration | 作者合作网络 | "collaboration" |
"authors" |
| University collaboration | 机构/大学合作网络 | "collaboration" |
"universities" |
|
| Country collaboration | 国家/地区合作网络 | "collaboration" |
"countries" |
|
|
Co-citation Networks (共被引网络) |
Authors co-citation | 作者共被引网络 | "co-citation" |
"authors" |
| Reference co-citation | 文献共被引网络 | "co-citation" |
"references" |
|
| Source co-citation | 期刊/来源共被引网络 | "co-citation" |
"sources" |
|
|
Coupling Networks (文献耦合网络) |
Manuscript coupling | 文献耦合网络 | "coupling" |
"references" |
| Authors coupling | 作者耦合网络 | "coupling" |
"authors" |
|
| Source coupling | 期刊/来源耦合网络 | "coupling" |
"sources" |
|
| Country coupling | 国家/地区耦合网络 | "coupling" |
"countries" |
|
|
Co-occurrences Networks (共现网络) |
Authors co-occurrences | 作者共现网络 | "co-occurrences" |
"authors" |
| Source co-occurrences | 期刊/来源共现网络 | "co-occurrences" |
"sources" |
|
| Keyword co-occurrences | 关键词共现网络 (通常指 Keywords Plus) | "co-occurrences" |
"keywords" |
|
| Author-Keyword co-occurrences | 作者关键词共现网络 | "co-occurrences" |
"author_keywords" |
|
| Title content co-occurrences | 标题词汇共现网络 | "co-occurrences" |
"titles" |
|
| Abstract content co-occurrences | 摘要词汇共现网络 | "co-occurrences" |
"abstracts" |
二分网络矩阵
可略过99%需求用不到,仅作简单介绍
WA <- cocMatrix(
M = M_new, # 数据框:通过 convert2df 函数转换得到的文献数据集
Field = "AU", # 提取字段:"AU"(作者), "DE"/"ID"(关键词), "CR"(参考文献), "SO"(期刊) 等
type = "sparse", # 矩阵类型:"sparse"(稀疏矩阵,默认且推荐,省内存) 或 "matrix"(普通矩阵)
n = NULL, # 提取数量:设置一个整数提取前n个高频元素;设为 NULL 则提取全部
sep = ";", # 分隔符:用于拆分同一单元格内多个元素的符号,默认是分号 ";"
binary = TRUE, # 计数方式:TRUE 表示只记录0和1(出现/未出现);FALSE 表示记录出现的具体频次
short = FALSE, # 过滤低频:TRUE 表示删除出现频次小于2的元素以缩小矩阵;FALSE 表示保留所有
remove.terms = NULL, # 停用词表:传入一个字符向量(如 c("word1", "word2")),在提取前会删掉这些词
synonyms = NULL # 同义词表:传入字符向量,格式为 "标准词;同义词1;同义词2",用于合并同义词
)他会生成类似于下面的这种矩阵,仅在特殊情况下需要用到不做过多介绍,biblionetwork运行过程中应该也会调用这个
| 作者A | 作者B | 作者C | |
| 文献 1 | 1 | 1 | 0 |
| 文献 2 | 0 | 1 | 1 |
| 文献 3 | 1 | 0 | 1 |
历史引文网络
hist_results <- histNetwork(
M = M_new, # 你的文献数据框
sep = ";", # 引文列的默认分隔符
network = TRUE, # 必须为 TRUE 才能生成网络矩阵
verbose = TRUE # 打印进度条
)网络标准化
# =====================================================================
# 网络标准化函数:normalizeSimilarity()
# 所属R包:bibliometrix
# 核心功能:将原始的共现频次矩阵,转换为消除“高频水分”的相对相似度矩阵。
# 这是进行高质量聚类(Clustering)和降维可视化的核心前置步骤。
# =====================================================================
NetMatrix <- biblioNetwork(
M = M_new,
analysis = "co-occurrences",
network = "keywords",
sep = ";"
)
# 此时的 NetMatrix 里面装的是绝对数字(比如 词A和词B 共同出现了 5 次)
# ---------------------------------------------------------
# 2. 对网络矩阵进行标准化处理
# ---------------------------------------------------------
# 方案 A: 使用 VOSviewer 的同款算法 (关联强度)
S_assoc <- normalizeSimilarity(
NetMatrix = NetMatrix,
type = "association"
)
# 方案 B: 使用经典的 Jaccard 算法
S_jaccard <- normalizeSimilarity(
NetMatrix = NetMatrix,
type = "jaccard"
)
# 标准化后的矩阵 (S_assoc) 可以直接喂给 networkPlot() 函数进行绘图,
# 或者导出为 Pajek 等格式,这样画出来的网络图,节点间的聚类关系会更加科学严谨。网络可视化
Bibliometrix自带的可视化
普通网络可视化
net <- networkPlot( network_results,
normalize = "association",#标准化方法选中,NULL则不进行标准化
n = 50,#节点数
degree = 5,#节点想要出现的最少频率
Title = "作者合作网络分析",#标题名
type = "auto",#布局选择 auto自动 circle 圆形 sphere 球形
label = TRUE, #是否显示标签
labelsize = 1,#标签大小
label.cex = FALSE,#标签缩放是否跟随度变化
label.color = FALSE,#标签颜色是否与聚类一致
label.n = 90,#标签出现的数量
halo = TRUE,#节点周围是否根据聚类产生光晕
cluster = "walktrap",#聚类算法
community.repulsion = 0.5,#不同聚类之间的排斥力 一般为0.5-0.7
vos.path = NULL,#vosviewer jar 文件路径
size = 3,#节点默认大小
size.cex = FALSE,#节点缩放是否跟随度变化
curved = FALSE,#线是直的还是弯的
noloops = TRUE,#是否删除自己连自己
remove.multiple = TRUE,#是否把多个重复的线合为一条
remove.isolates = TRUE,#是否删除孤立节点
weighted = NULL,#决定是否创建加权图(边的粗细由关联强度决定)。
edgesize = 1,#连线粗细
edges.min = 5,#连线阈值
alpha = 0.5,#节点透明度
seed = 123,#随机种子
verbose = TRUE#是否把图绘制出来
)标准化方法参照表
| 标准化方法 (参数值) | 适用场景与特点 |
"association" |
VOSviewer 的默认算法(关联强度)。强烈推荐用于文献计量学分析,能极好地揭示社群结构,发文章最常被认可。 |
"salton" |
即余弦相似度(Cosine)。常用于信息检索,对文本挖掘和关键词网络非常有效。 |
"jaccard" |
并集交集比。衡量“只要两人中有一人发文,两人合作的概率有多大”。非常严格,适合评估非常紧密的共被引关系。 |
"inclusion" |
辛普森指数(Simpson)。偏向于保护小节点,容易把小节点吸附到大节点周围。 |
然后我们就画出了第一个及其丑陋的网络图
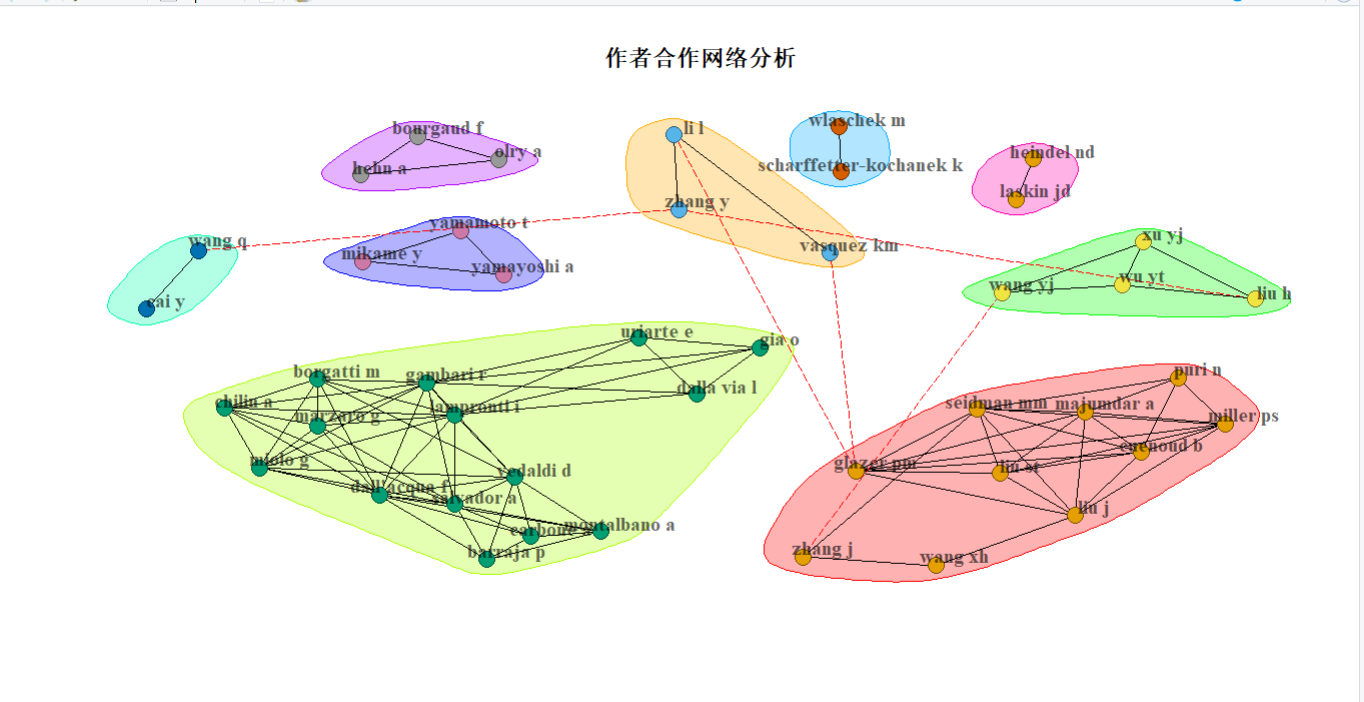
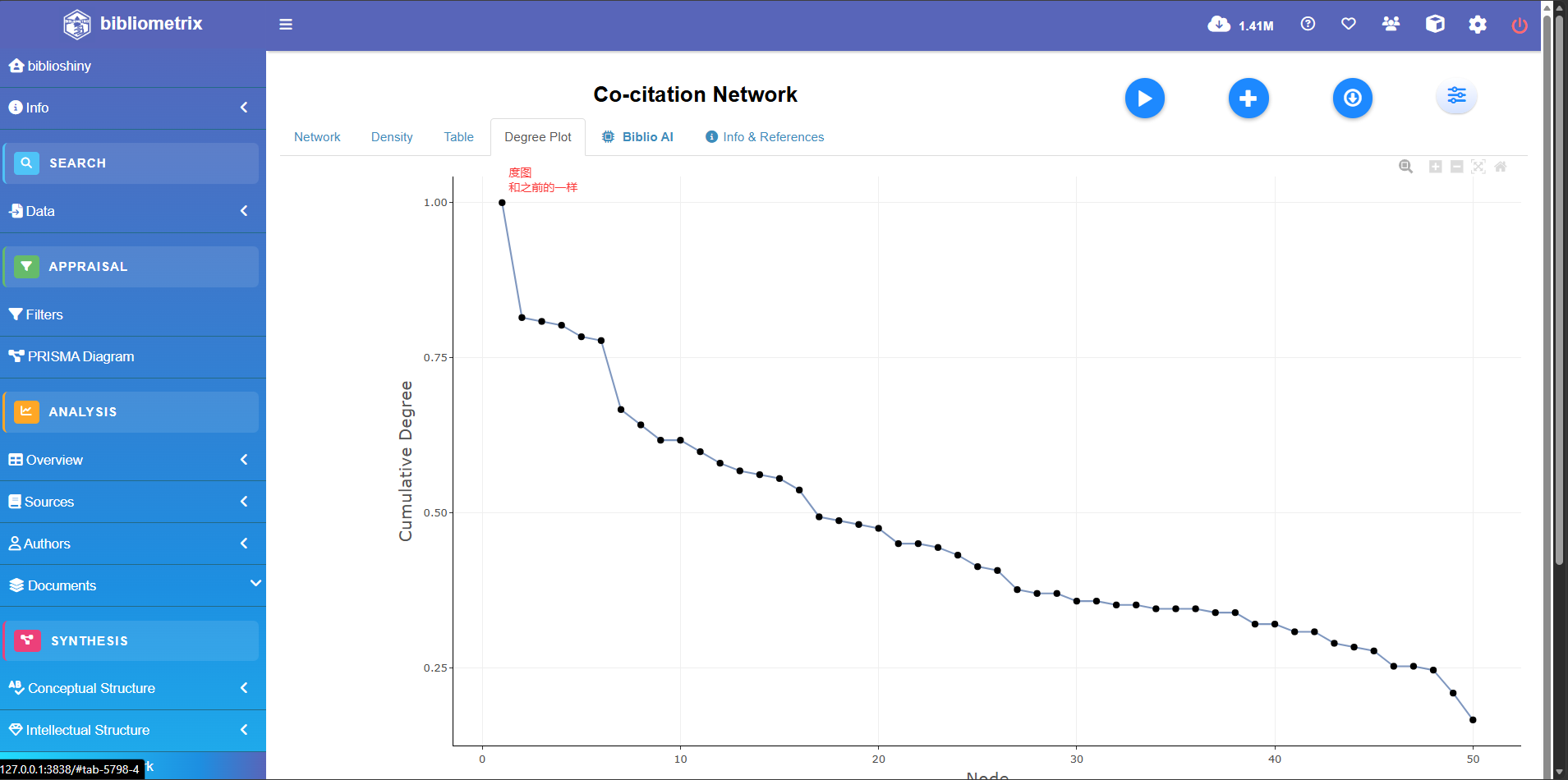
历史引文网络可视化
net_graph <- histPlot(
histResults = hist_results, # 填入上一步 histNetwork 算出来的结果变量名
n = 10, # 画图的节点数
size = 5, # 节点气泡的默认大小
labelsize = 5, # 标签文字的默认大小
remove.isolates = TRUE, # 是否剔除孤立节点?
label = "short", # 标签显示内容: "short"(默认, 作者+年份), "title"(标题), "keywords"(关键词)
verbose = TRUE, # 是否在控制台打印生成过程的提示信息
)
# 这个函数不仅画图,还会返回一个包含网络数据对象的列表
# 1. 提取绘图对象 (如果你想后期用 ggplot2 的语法微调画面)
# plot(net_graph$g)
# 2. 提取底层图网络对象 (供高级网络分析如 igraph 包使用)
# net_graph$net
使用Vosviewer可视化
仅作展示,不推荐这么做,建议直接使用原生Vosviewer进行网络分析
非常不推荐这样给他桥接过去
net2VOSviewer(net, vos.path = "C:\\Users\\47770\\Desktop\\vos")
#vos.path里要包括 vos的jar文件 jar文件在官网可以下载到
这里会有很多问题
第一导出的不是你通过networkPlot限制好的,他会重新找到network_results,把全部节点都导入进去
说实话有点美感 但啥实际意义都没有,你可以通过
重新绘图 但是意义不大,导入本来就有问题,如果有大佬知道如何解决请在评论区指出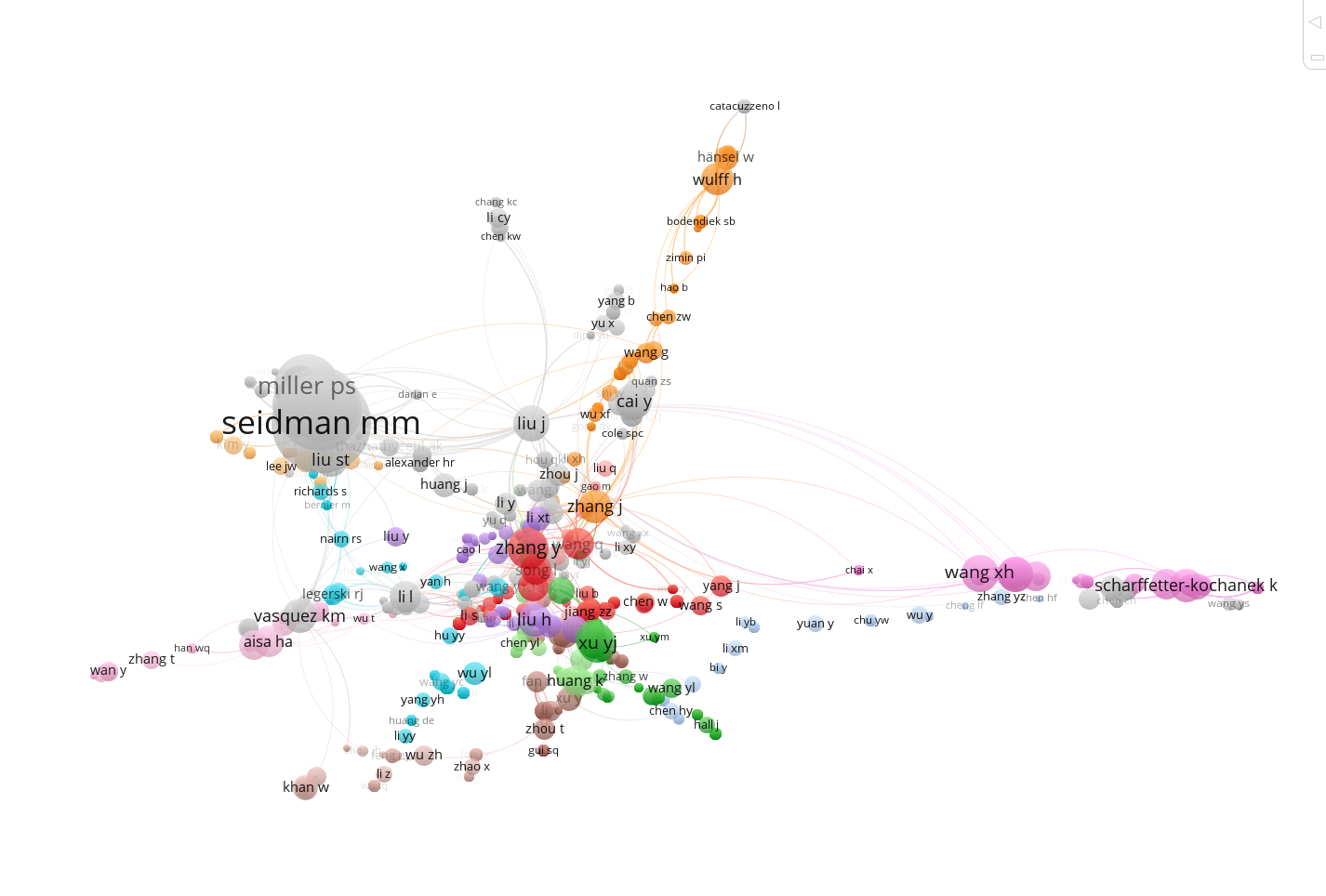

不如使用原生vosviewer 原生在这方面就是碾压,bibliometrix本身就不是为了这方面来的,未来我会更新vosviewer和citespace使用
数据框导出为WOS格式用于VOSviewer和Citespace
WOS格式
FN Clarivate Analytics Web of Science
VR 1.0
PT J
AU Pacifico, A
Leone, G
AF Pacifico, Alessia
Leone, Giovanni
TI Photo(chemo)therapy for vitiligo
SO PHOTODERMATOLOGY PHOTOIMMUNOLOGY & PHOTOMEDICINE
LA English
DT Article
DE excimer laser; excimer light; narrow-band UVB; PUVA; targeted
phototherapy; vitiligo
ID BAND ULTRAVIOLET-B; 308-NM EXCIMER-LASER; PSORALEN-PLUS-ULTRAVIOLET;
SQUAMOUS-CELL CARCINOMAS; DOUBLE-BLIND TRIAL; SKIN-CANCER RISK; UV-A
THERAPY; BROAD-BAND; TOPICAL CALCIPOTRIOL; TACROLIMUS OINTMENT
AB Vitiligo is a common skin disease characterized by loss of normal melanin pigments in the skin and its pathogenesis is still unclear. Treatment modalities include psoralen plus ultraviolet A, narrow-band ultraviolet B (NB UVB) phototherapy, topical and systemic steroids, topical calcineurin inhibitors, topical vitamin D analogues in monotherapy or in association with phototherapy, and surgical treatment. NB UVB (310-315 nm) radiation is now considered as the 'gold standard' for the treatment of diffuse vitiligo, and treatment with two recently introduced UVB sources that emit 308 nm wavelengths, the 308 nm xenon chloride (XeCl) excimer laser and the 308 nm XeCl excimer light, has also been reported to be effective and might be the treatment of choice for localized disease: this treatment modality has been defined as 'targeted phototherapy.'
C1 [Pacifico, Alessia; Leone, Giovanni] San Gallicano Dermatol Inst, Photodermatol Unit, I-00144 Rome, Italy.
C3 IRCCS Istituti Fisioterapici Ospitalieri (IFO); IRCCS San Gallicano
Dermatological Institute (ISG)
RP Leone, G (corresponding author), San Gallicano Dermatol Inst, Photodermatol Unit, Via Elio Chianesi 53, I-00144 Rome, Italy.
EM gleone@ifo.it
RI Leone, Giovanni/AAW-7785-2021; Pacifico, Alessia/AAE-9908-2019
OI Leone, Giovanni/0000-0001-6120-2712; Pacifico,
Alessia/0000-0003-0348-0620
CR ABDELFATTAH A, 1982, DERMATOLOGICA, V165, P136, DOI 10.1159/000249932
AbdelNaser MB, 1997, ARCH DERMATOL, V133, P1530, DOI 10.1001/archderm.133.12.1530
Ada S, 2005, PHOTODERMATOL PHOTO, V21, P79, DOI 10.1111/j.1600-0781.2005.00139.x
Al-Mutairi N, 2010, DERMATOL SURG, V36, P499, DOI 10.1111/j.1524-4725.2010.01477.x
Anbar TS, 2006, PHOTODERMATOL PHOTO, V22, P157, DOI 10.1111/j.1600-0781.2006.00222.x
Arca E, 2006, J DERMATOL, V33, P338, DOI 10.1111/j.1346-8138.2006.00079.x
Asawanonda P, 2008, ACTA DERM-VENEREOL, V88, P376, DOI 10.2340/00015555-0469
Asawanonda P, 2006, PHOTODERMATOL PHOTO, V22, P133, DOI 10.1111/j.1600-0781.2006.00217.x
AVERBECK D, 1989, PHOTOCHEM PHOTOBIOL, V50, P859, DOI 10.1111/j.1751-1097.1989.tb02917.x
Bakis-Petsoglou S, 2009, BRIT J DERMATOL, V161, P910, DOI 10.1111/j.1365-2133.2009.09252.x
Baltás E, 2002, ARCH DERMATOL, V138, P1619, DOI 10.1001/archderm.138.12.1619
Bhatnagar A, 2007, J EUR ACAD DERMATOL, V21, P1276, DOI 10.1111/j.1468-3083.2007.02170.x
Bhatnagar A, 2007, J EUR ACAD DERMATOL, V21, P638, DOI 10.1111/j.1468-3083.2006.02035.x
Bianchi B, 2003, J EUR ACAD DERMATOL, V17, P408, DOI 10.1046/j.1468-3083.2003.00758.x
Birlea SA, 2011, J INVEST DERMATOL, V131, P371, DOI 10.1038/jid.2010.337
BOISSY RE, 1991, J INVEST DERMATOL, V97, P395, DOI 10.1111/1523-1747.ep12480976
Brazzelli V, 2007, J EUR ACAD DERMATOL, V21, P1369, DOI 10.1111/j.1468-3083.2007.02278.x
Brazzelli V, 2006, PHOTODERMATOL PHOTO, V22, P211, DOI 10.1111/j.1600-0781.2006.00224.x
Budiyanto A, 2002, PHOTOCHEM PHOTOBIOL, V76, P397, DOI 10.1562/0031-8655(2002)076<0397:FOCPDA>2.0.CO;2
Camacho F, 1999, ARCH DERMATOL, V135, P216, DOI 10.1001/archderm.135.2.216
Campolmi P., 2002, Int J Immunopathol Pharmacol, V13, P14
Campolmi P, 2002, INT J IMMUNOPATHO S1, V13, P11
Canton M, 2002, FEBS LETT, V522, P168, DOI 10.1016/S0014-5793(02)02926-5
Cario-André M, 2007, PIGM CELL RES, V20, P385, DOI 10.1111/j.1600-0749.2007.00396.x
Caron-Schreinemachers ALDB, 2005, ACTA DERM-VENEREOL, V85, P24, DOI 10.1080/00015550410022203
Casacci M, 2007, J EUR ACAD DERMATOL, V21, P956, DOI 10.1111/j.1468-3083.2007.02151.x
CHAKRABARTI SG, 1982, J INVEST DERMATOL, V79, P374, DOI 10.1111/1523-1747.ep12529859
COELHO JD, 2010, DERMATOL ONLINE J, V15, P16
CORMANE RH, 1985, ARCH DERMATOL RES, V277, P126, DOI 10.1007/BF00414110
CUI J, 1991, J INVEST DERMATOL, V97, P410, DOI 10.1111/1523-1747.ep12480997
Dell'Anna ML, 2007, CLIN EXP DERMATOL, V32, P631, DOI 10.1111/j.1365-2230.2007.02514.x
Dell'Anna ML, 2006, PIGM CELL RES, V19, P406, DOI 10.1111/j.1600-0749.2006.00333.x
Dogra S, 2003, ARCH DERMATOL, V139, P393, DOI 10.1001/archderm.139.3.393
Drake LA, 1996, J AM ACAD DERMATOL, V35, P620
DRAKE LA, 1994, J AM ACAD DERMATOL, V31, P643
El Mofty M, 2006, PHOTODERMATOL PHOTO, V22, P6, DOI 10.1111/j.1600-0781.2006.00189.x
El-Khateeb EA, 2010, CLIN EXP DERMATOL, V12, P1
El-Mofty M, 2006, PHOTODERMATOL PHOTO, V22, P214, DOI 10.1111/j.1600-0781.2006.00229.x
Elgoweini M, 2009, J CLIN PHARMACOL, V49, P852, DOI 10.1177/0091270009335769
Fai D, 2007, J EUR ACAD DERMATOL, V21, P916, DOI 10.1111/j.1468-3083.2006.02101.x
Falabella R, 2009, PIGM CELL MELANOMA R, V22, P42, DOI 10.1111/j.1755-148X.2008.00528.x
Freeman K, 1984, Photodermatol, V1, P147
Gambichler T, 2008, J DERMATOL SCI, V50, P115, DOI 10.1016/j.jdermsci.2007.11.013
Gawkrodger DJ, 2009, BRIT J DERMATOL, V161, P721, DOI 10.1111/j.1365-2133.2009.09292.x
Gniadecka M, 1996, ACTA DERM-VENEREOL, V76, P429
Goktas EO, 2006, J EUR ACAD DERMATOL, V20, P553, DOI 10.1111/j.1468-3083.2006.01546.x
GREINER D, 1994, HAUTARZT, V45, P460, DOI 10.1007/s001050050104
GRIMES PE, 1993, DERMATOL CLIN, V11, P325, DOI 10.1016/S0733-8635(18)30271-7
GRIMES PE, 1982, J AM ACAD DERMATOL, V7, P771, DOI 10.1016/S0190-9622(82)70159-8
GUPTA AK, 1987, J AM ACAD DERMATOL, V17, P703, DOI 10.1016/S0190-9622(87)70255-2
Hadi S, 2006, PHOTOMED LASER SURG, V24, P354, DOI 10.1089/pho.2006.24.354
Halpern SM, 2000, BRIT J DERMATOL, V142, P22, DOI 10.1046/j.1365-2133.2000.03237.x
Handa S, 2001, J DERMATOL, V28, P461, DOI 10.1111/j.1346-8138.2001.tb00012.x
Hannuksela-Svahn A, 1999, J AM ACAD DERMATOL, V40, P694, DOI 10.1016/S0190-9622(99)70148-9
Hartmann A, 2005, INT J DERMATOL, V44, P736, DOI 10.1111/j.1365-4632.2004.02154.x
Hearn RMR, 2008, BRIT J DERMATOL, V159, P931, DOI 10.1111/j.1365-2133.2008.08776.x
Hearn RMR, 2006, BRIT J DERMATOL, V155, P866, DOI 10.1111/j.1365-2133.2006.07477_3.x
Hofer A, 2006, J EUR ACAD DERMATOL, V20, P558, DOI 10.1111/j.1468-3083.2006.01547.x
Hofer A, 2005, BRIT J DERMATOL, V152, P981, DOI 10.1111/j.1365-2133.2004.06321.x
Hong SB, 2005, J KOREAN MED SCI, V20, P273, DOI 10.3346/jkms.2005.20.2.273
Ibbotson SH, 2001, J INVEST DERMATOL, V116, P813, DOI 10.1046/j.1523-1747.2001.01348.x
Ibbotson SH, 1999, J INVEST DERMATOL, V113, P346, DOI 10.1046/j.1523-1747.1999.00700.x
Imokawa G, 2004, PIGM CELL RES, V17, P96, DOI 10.1111/j.1600-0749.2003.00126.x
Jin Y, 2010, NEW ENGL J MED, V362, P1686, DOI 10.1056/NEJMoa0908547
Juhlin L, 1997, ACTA DERM-VENEREOL, V77, P460
Kanwar AJ, 2005, INT J DERMATOL, V44, P57, DOI 10.1111/j.1365-4632.2004.02329.x
Kawalek AZ, 2004, DERMATOL SURG, V30, P130, DOI 10.1111/j.1524-4725.2004.30058.x
KHEMIS A, 2004, NOUV DERMATOL, V23, P7
Kim DY, 2005, J DERMATOL, V32, P771, DOI 10.1111/j.1346-8138.2005.tb00843.x
Kobayashi K, 2009, PHOTODERMATOL PHOTO, V25, P30, DOI 10.1111/j.1600-0781.2009.00396.x
Köllner K, 2005, BRIT J DERMATOL, V152, P750, DOI 10.1111/j.1365-2133.2005.06533.x
Koster W, 1990, Z Hautkr, V65, P1022
Kostovic K, 2007, ACTA DERMATOVENER CR, V15, P10
Kovacs SO, 1998, J AM ACAD DERMATOL, V38, P647, DOI 10.1016/S0190-9622(98)70194-X
Kreimer-Erlacher H, 2003, J INVEST DERMATOL, V120, P676, DOI 10.1046/j.1523-1747.2003.12085.x
Kullavanijaya P, 2004, PHOTODERMATOL PHOTO, V20, P248, DOI 10.1111/j.1600-0781.2004.00114.x
Kumar YHK, 2009, INDIAN J DERMATOL VE, V75, P162, DOI 10.4103/0378-6323.48662
Kwok YKC, 2002, CLIN EXP DERMATOL, V27, P104, DOI 10.1046/j.1365-2230.2002.00984.x
Lan CCE, 2009, BRIT J DERMATOL, V161, P273, DOI 10.1111/j.1365-2133.2009.09152.x
Lan CCE, 2006, J INVEST DERMATOL, V126, P2119, DOI 10.1038/sj.jid.5700372
Lapidoth M, 2007, CLIN EXP DERMATOL, V32, P642, DOI 10.1111/j.1365-2230.2007.02469.x
Le Duff F, 2010, BRIT J DERMATOL, V163, P188, DOI 10.1111/j.1365-2133.2010.09778.x
Lee DY, 2010, PHOTODERMATOL PHOTO, V26, P219, DOI 10.1111/j.1600-0781.2010.00520.x
Lee DY, 2010, J DERMATOL, V37, P500, DOI 10.1111/j.1346-8138.2010.00807.x
Leone G, 2006, CLIN EXP DERMATOL, V31, P200, DOI 10.1111/j.1365-2230.2005.02037.x
Leone G, 2003, J EUR ACAD DERMATOL, V17, P531, DOI 10.1046/j.1468-3083.2003.00818.x
Leone G, 2010, VITILIGO, P353, DOI 10.1007/978-3-540-69361-1_3.3.2
Lerche CM, 2008, EXP DERMATOL, V17, P57, DOI 10.1111/j.1600-0625.2007.00617.x
Lim-Ong M, 2005, J PHILIPP DERMATOL S, V14, P17
Mai DW, 1998, PEDIATR DERMATOL, V15, P53, DOI 10.1046/j.1525-1470.1998.1998015053.x
Majid I, 2010, PHOTODERMATOL PHOTO, V26, P230, DOI 10.1111/j.1600-0781.2010.00540.x
Majumder PP, 2000, VITILIGO, P18
Man I, 2005, BRIT J DERMATOL, V152, P755, DOI 10.1111/j.1365-2133.2005.06537.x
Maresca V, 1997, J INVEST DERMATOL, V109, P310, DOI 10.1111/1523-1747.ep12335801
McNeely W, 1998, DRUGS, V56, P667, DOI 10.2165/00003495-199856040-00015
Mehrabi D, 2006, ARCH DERMATOL, V142, P927, DOI 10.1001/archderm.142.7.927
Menchini G, 2003, J EUR ACAD DERMATOL, V17, P171, DOI 10.1046/j.1468-3083.2003.00743.x
Middelkamp-Hup MA, 2007, J EUR ACAD DERMATOL, V21, P942, DOI 10.1111/j.1468-3083.2006.02132.x
Moretti S, 2002, PIGM CELL RES, V15, P87, DOI 10.1034/j.1600-0749.2002.1o049.x
Morison WL, 1997, J AM ACAD DERMATOL, V36, P183, DOI 10.1016/S0190-9622(97)70277-9
Nataraj AJ, 1997, J INVEST DERMATOL, V109, P238, DOI 10.1111/1523-1747.ep12319764
Natta R, 2003, J AM ACAD DERMATOL, V49, P473, DOI 10.1067/S0190-9622(03)01484-1
Navarro-Zorraquino M, 2007, J INVEST SURG, V20, P283, DOI 10.1080/08941930701598792
Nicolaidou E, 2007, J AM ACAD DERMATOL, V56, P274, DOI 10.1016/j.jaad.2006.09.004
Nijsten TEC, 2003, J INVEST DERMATOL, V121, P252, DOI 10.1046/j.1523-1747.2003.12350.x
Njoo MD, 1999, ARCH DERMATOL, V135, P1514, DOI 10.1001/archderm.135.12.1514
Njoo MD, 2000, J AM ACAD DERMATOL, V42, P245, DOI 10.1016/S0190-9622(00)90133-6
Noborio R, 2010, PHOTODERMATOL PHOTO, V26, P159, DOI 10.1111/j.1600-0781.2010.00510.x
NORDLUND J, 2002, ANN DERMATOL VENEREO, V129
NORRIS PG, 1994, BRIT J DERMATOL, V130, P246
Novák Z, 2004, PHOTOCHEM PHOTOBIOL, V79, P434, DOI 10.1562/RA-003R.1
Novák Z, 2002, J PHOTOCH PHOTOBIO B, V67, P32, DOI 10.1016/S1011-1344(02)00280-4
Ongenae K, 2006, J EUR ACAD DERMATOL, V20, P1, DOI 10.1111/j.1468-3083.2005.01369.x
Ongenae K, 2003, PIGM CELL RES, V16, P90, DOI 10.1034/j.1600-0749.2003.00023.x
Orecchia GE, 2000, VITILIGO, P142, DOI 10.1002/9780470760116.ch18
ORTEL B, 1988, J AM ACAD DERMATOL, V18, P693, DOI 10.1016/S0190-9622(88)70092-4
ORTEL B, 1986, CURR PROBL DERMATOL, V15, P256
ORTONNE JP, 1979, BRIT J DERMATOL, V101, P1, DOI 10.1111/j.1365-2133.1979.tb15285.x
Ozawa M, 1999, J EXP MED, V189, P711, DOI 10.1084/jem.189.4.711
PACIFICO A, 2011, 20 ANN M PHOT SOC 3
PARRISH JA, 1981, J INVEST DERMATOL, V76, P359, DOI 10.1111/1523-1747.ep12520022
Parsad D, 1998, DERMATOLOGY, V197, P167, DOI 10.1159/000017991
Parsad D, 2006, J EUR ACAD DERMATOL, V20, P175, DOI 10.1111/j.1468-3083.2006.01413.x
Passeron T, 2005, J AUTOIMMUN, V25, P63, DOI 10.1016/j.jaut.2005.10.001
Passeron T, 2004, ARCH DERMATOL, V140, P1065, DOI 10.1001/archderm.140.9.1065
Passeron T, 2006, CLIN DERMATOL, V24, P33, DOI 10.1016/j.clindermatol.2005.10.024
Patel DC, 2002, CLIN EXP DERMATOL, V27, P641, DOI 10.1046/j.1365-2230.2002.01142.x
Pathak M A, 1984, Natl Cancer Inst Monogr, V66, P165
PROCACCINI EM, 1995, J DERMATOL TREAT, V6, P117, DOI 10.3109/09546639509097164
Rivard J, 2007, PHOTODERMATOL PHOTO, V23, P258, DOI 10.1111/j.1600-0781.2007.00311.x
Saraceno R, 2009, DERMATOL THER, V22, P391, DOI 10.1111/j.1529-8019.2009.01252.x
Sassi F, 2008, BRIT J DERMATOL, V159, P1186, DOI 10.1111/j.1365-2133.2008.08793.x
SCHALLREUTER KU, 1991, J INVEST DERMATOL, V97, P1081, DOI 10.1111/1523-1747.ep12492612
SCHALLREUTER KU, 1988, ARCH DERMATOL RES, V280, P137, DOI 10.1007/BF00456842
SCHALLREUTER KU, 1995, DERMATOLOGY, V190, P223, DOI 10.1159/000246690
Schallreuter KU, 2003, EXP DERMATOL, V12, P268, DOI 10.1034/j.1600-0625.2003.00084.x
Schallreuter KU, 2002, DERMATOLOGY, V204, P194, DOI 10.1159/000057881
Scherschun L, 2001, J AM ACAD DERMATOL, V44, P999, DOI 10.1067/mjd.2001.114752
SIDDIQUI AH, 1994, DERMATOLOGY, V188, P215, DOI 10.1159/000247142
Sitek JC, 2007, J EUR ACAD DERMATOL, V21, P891, DOI 10.1111/j.1468-3083.2007.01980.x
Spencer JM, 2002, J AM ACAD DERMATOL, V46, P727, DOI 10.1067/mjd.2002.121357
Stern RS, 1997, NEW ENGL J MED, V336, P1041, DOI 10.1056/NEJM199704103361501
Stern RS, 1999, PHOTODERMATOL PHOTO, V15, P37, DOI 10.1111/j.1600-0781.1999.tb00052.x
STERN RS, 1994, CANCER-AM CANCER SOC, V73, P2759, DOI 10.1002/1097-0142(19940601)73:11<2759::AID-CNCR2820731118>3.0.CO;2-C
STOLK L, 1981, BRIT J DERMATOL, V104, P443, DOI 10.1111/j.1365-2133.1981.tb15315.x
Taneja A, 2003, INT J DERMATOL, V42, P658, DOI 10.1046/j.1365-4362.2003.01997.x
Taneja A, 2002, J DERMATOL TREAT, V13, P19, DOI 10.1080/09546630252775207
Tang LY, 2006, PHOTODERMATOL PHOTO, V22, P310, DOI 10.1111/j.1600-0781.2006.00250.x
THEODORIDIS A, 1976, ACTA DERM-VENEREOL, V56, P253
Tjioe M, 2002, ACTA DERM-VENEREOL, V82, P369, DOI 10.1080/000155502320624113
Tzung TY, 1998, PHOTOCHEM PHOTOBIOL, V67, P647, DOI 10.1111/j.1751-1097.1998.tb09107.x
Weischer M, 2004, ACTA DERM-VENEREOL, V84, P370, DOI 10.1080/00015550410026948
Welsh O, 2009, INT J DERMATOL, V48, P529, DOI 10.1111/j.1365-4632.2009.03928.x
Westerhof W, 1997, ARCH DERMATOL, V133, P1525
Westerhof W, 1999, ARCH DERMATOL, V135, P1061, DOI 10.1001/archderm.135.9.1061
Wu CS, 2007, BRIT J DERMATOL, V156, P122, DOI 10.1111/j.1365-2133.2006.07584.x
Wu CS, 2004, EXP DERMATOL, V13, P755, DOI 10.1111/j.0906-6705.2004.00221.x
Yang HL, 2009, PEDIATR DERMATOL, V26, P354, DOI 10.1111/j.1525-1470.2009.00914.x
Yashar SS, 2003, PHOTODERMATOL PHOTO, V19, P164
Yones SS, 2007, ARCH DERMATOL, V143, P578, DOI 10.1001/archderm.143.5.578
Yu HS, 2003, J INVEST DERMATOL, V120, P56, DOI 10.1046/j.1523-1747.2003.12011.x
NR 161
TC 52
Z9 65
U1 0
U2 8
PU WILEY
PI HOBOKEN
PA 111 RIVER ST, HOBOKEN 07030-5774, NJ USA
SN 0905-4383
EI 1600-0781
J9 PHOTODERMATOL PHOTO
JI Photodermatol. Photoimmunol. Photomed.
PD OCT
PY 2011
VL 27
IS 5
BP 261
EP 277
DI 10.1111/j.1600-0781.2011.00606.x
PG 17
WC Dermatology
WE Science Citation Index Expanded (SCI-EXPANDED)
SC Dermatology
GA 825JN
UT WOS:000295269000010
PM 21950634
DA 2026-04-22
ER
开头 中间 和结尾 还有缩减问题 具体见代码里,如果有需要我可以出一个用excel演示代码操作表格的过程
代码
library(tidyverse)
export_to_wos <- function(df, output_file){
#预处理,因为citespace识别的时候以PT开头,所以首先检查PT列是否存在里面是否都有值,没有用J填充(不影响分析,只是方便citespace去导入)
if(!"PT" %in% names(df)){
df <- df%>%mutate(PT="J")
}else{
df<-df%>%mutate(
PT = case_when(
is.na(PT)~"J",
str_trim(PT) == "" ~"J",
TRUE ~as.character(PT)
)
)
}
#上面是在进行:如果没PT列就全部加上PT列 值全部为J 如果有 就检查有没有NA的有没有空的 替换为J
text_data <- df %>% mutate(doc_id=row_number())%>%#给每一条文献打上标签,防止一会变成长表混乱
mutate(across(everything(), as.character))%>%#防止傻福R因为数据类型报错
pivot_longer(
cols = -doc_id,#将除了doc_id的列全转为长表
names_to = "tag",#列名加到tag列
values_to = "val",#值加到val列
values_drop_na = TRUE#丢弃NA值
)%>%
dplyr::filter(nchar(tag) == 2) %>%#去除中间过程列
dplyr::filter(str_trim(val)!="")%>%#过滤空字符串
mutate(
is_multi = tag %in% c("AU", "AF", "CR", "C1", "RP"),#可能出现多个机构或者作者或者其他东西的地方
val=if_else(is_multi,
str_split(val, ";\\s*(?![0-9])(?![^\\[]*\\])"),
map(val, ~.) # 不是多行字段的保持原样(套个 list 方便后面一起展开)
)
)%>%unnest(val)%>%#将列表展开为多行
mutate(val = str_trim(val))%>%dplyr::filter(val != "")%>%#掐头去尾去空值
#按照wos的标准格式给该加缩进的地方加上缩进和按照wos格式排版
group_by(doc_id,tag)%>%
mutate(
item_idx = row_number(),
line_text=if_else(
item_idx == 1,
str_c(tag," ",val),# 第1个条目:标签 + 空格 + 内容
str_c(" ",val)# 第2个及以上条目:3个空格 + 内容
)
)%>%
ungroup()%>%arrange(doc_id, tag != "PT", tag, item_idx)#把PT移到第一列
#拼装为纯文本格式
final_text <- text_data%>%
group_by(doc_id)%>%
# 把每篇文献的所有行拼起来,并在末尾加上 ER 和空行
summarise(
doc_block = str_c(c(line_text,"ER",''),collapse = "\n"),
.groups = "drop"
)%>%
pull(doc_block)%>%
str_c(collapse = "\n")
header <- "FN Clarivate Analytics Web of Science\nVR 1.0\n"#加上开头
write_file(str_c(header, final_text), file = output_file)
message("文件已保存至: ", output_file)
}
export_to_wos(df=M,output_file = "downloaded.txt")给所有用 CiteSpace 的朋友提个醒:数据导入分析前,有个致命大坑一定要避开 ——必须先通过 CiteSpace 自带功能完成去重清洗,再用去重后的文件做后续分析。
原因很关键:CiteSpace 的分析模块几乎没有容错能力,数据里极小的问题都会直接导致程序崩溃;但它的去重模块容错性极强,能有效清洗导入的脏数据,从源头规避报错。
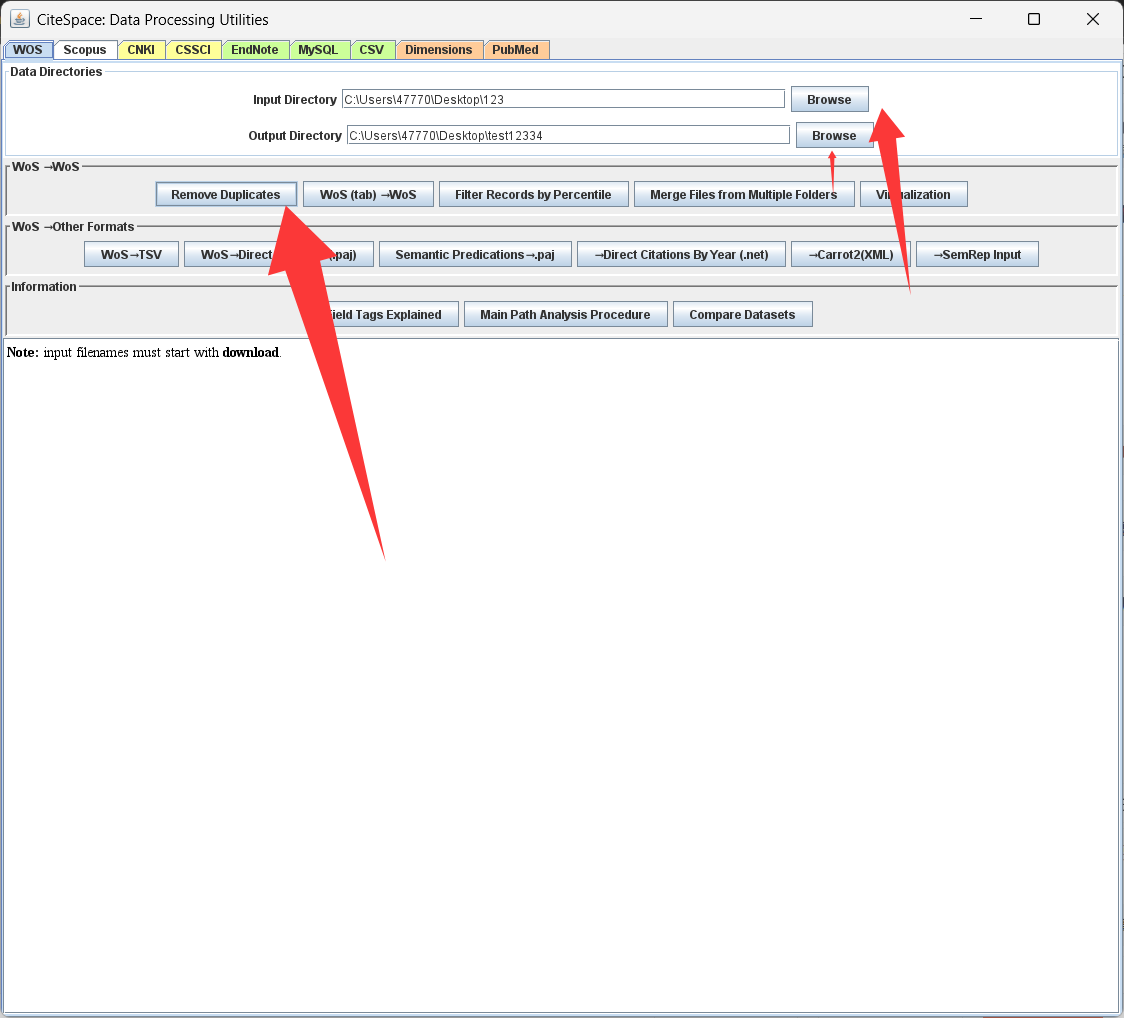 设置你的输入文件夹和输出文件夹
设置你的输入文件夹和输出文件夹
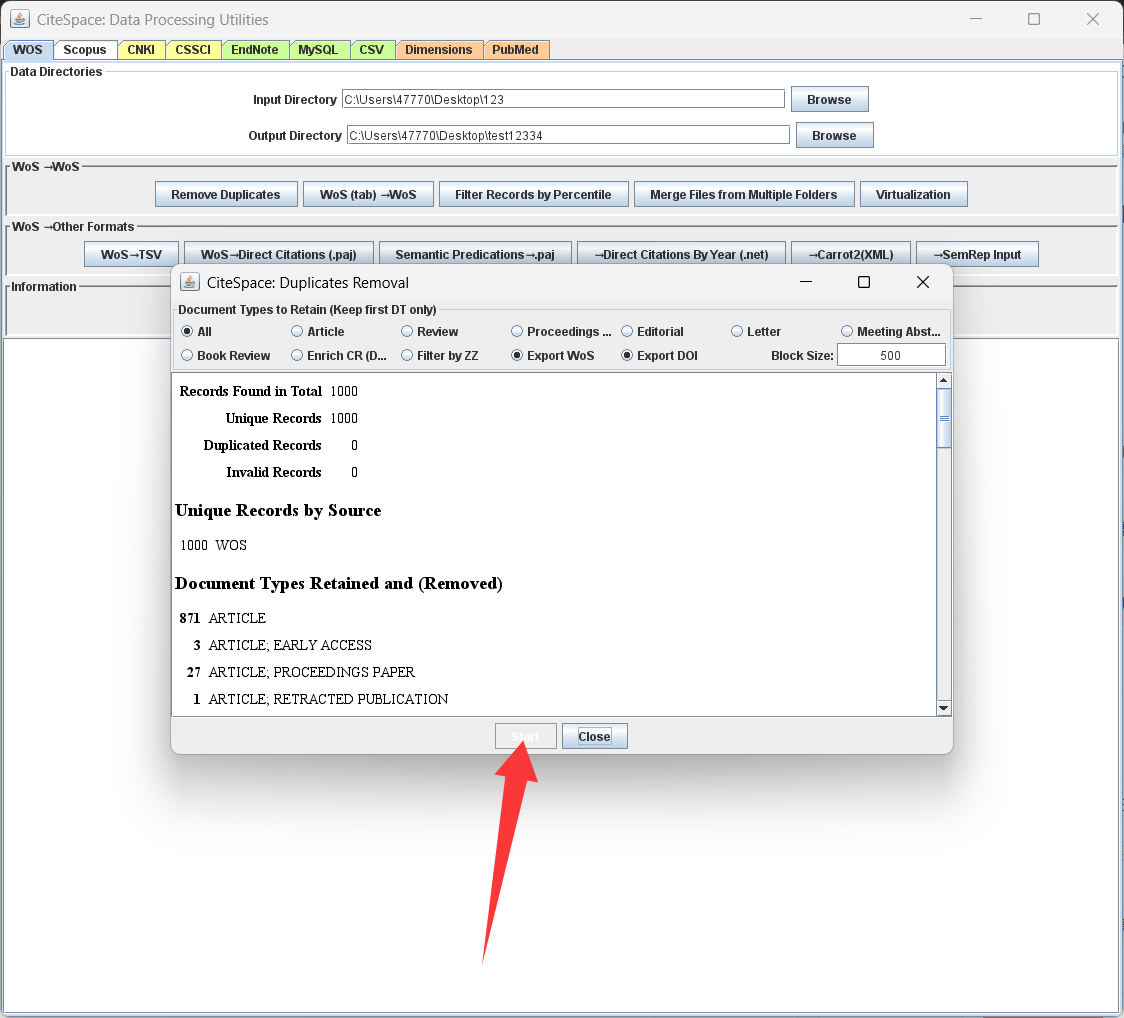
进行去重 然后拿去重后的文件去导入到citespace 因为citespace的分析模块好像没有做啥容错,非常微小的问题就会直接挂掉 但是这个去重模块的容错相当强,会把脏的导入数据洗干净
测试
经测试pubmed和wos数据合并没问题 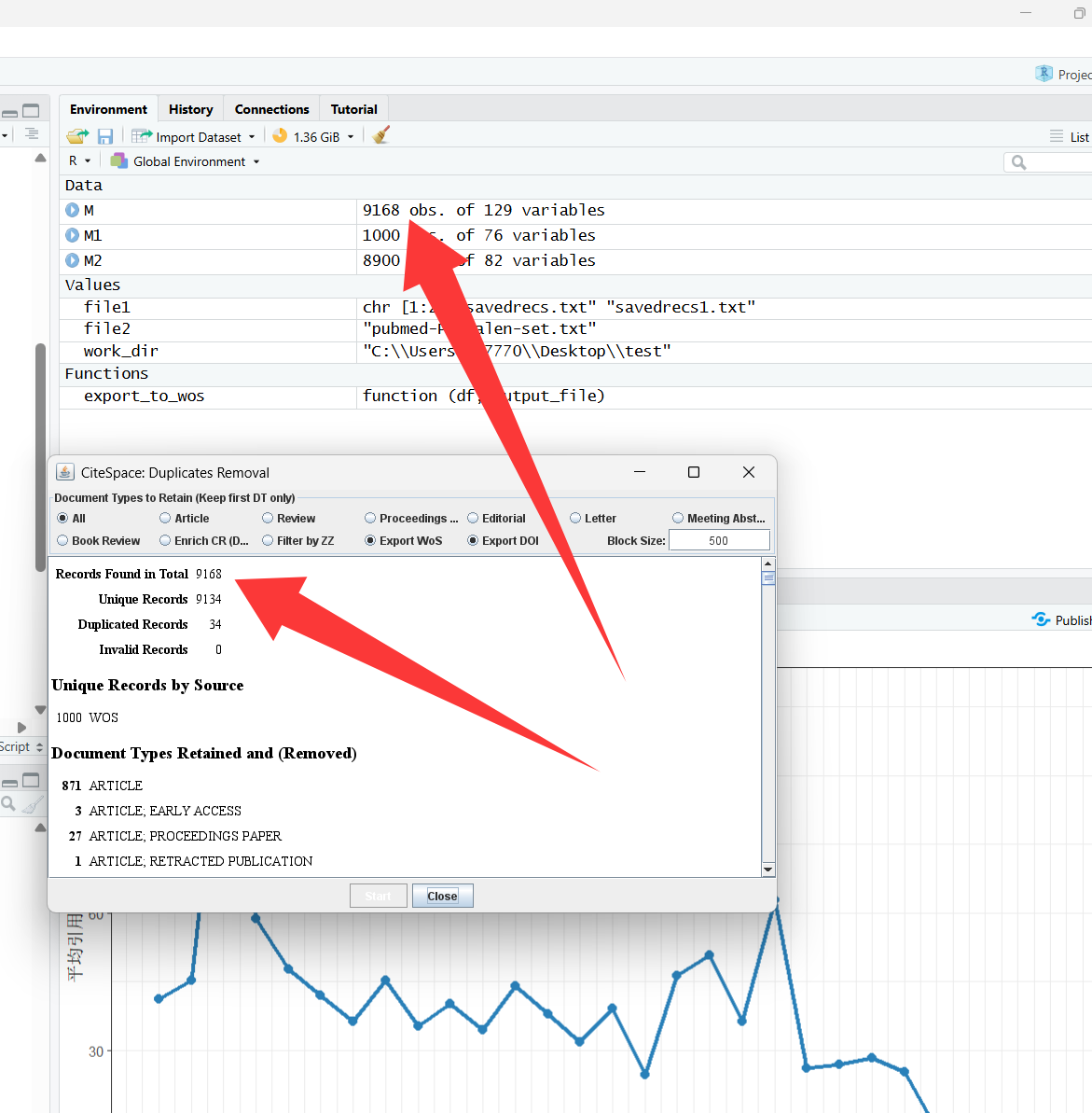
并没有文献数量上的丢失
VOSviewer的要求非常松 所有不做过多说明 直接就能导入进去
导出到Pajek
net2Pajek(
net = net, # 传入上一步生成的 net 对象
filename = "pajekfiles", # 导出的文件名
path = NULL # NULL 表示保存在当前 R 工作目录
)网络数据分析
netstat <- networkStat(
object = NetMatrix, # [必填] 刚才生成的网络矩阵使用biblionetwork生成的那个
stat = "all", # [推荐] "all" 表示同时计算整体网络和单个节点的指标
type = "all" # [推荐] "all" 表示把 Degree, Betweenness, PageRank 等中心度全算了
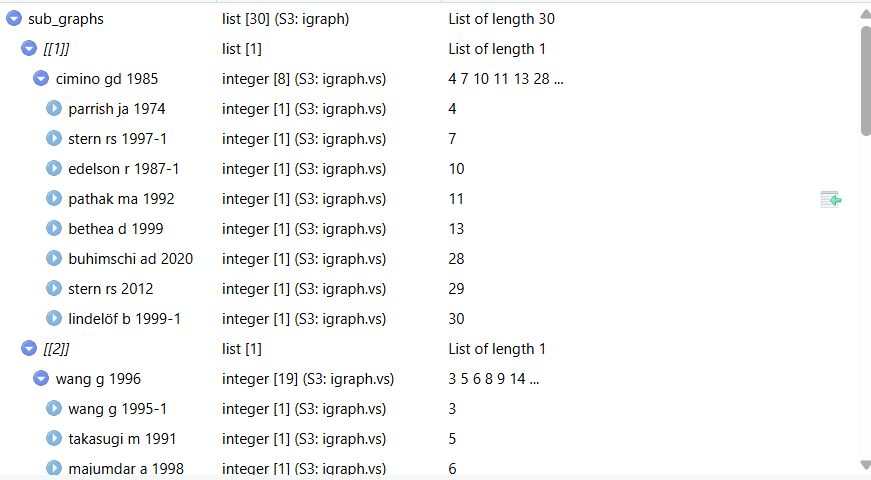
)提取网络聚类
net <- networkPlot(NetMatrix, n = 30, type = "auto")
sub_graphs <- splitCommunities(
graph = net$graph, #networkplot生成的网络
n = 30#一个聚类展示多少个节点
)
*主题的四象限图*
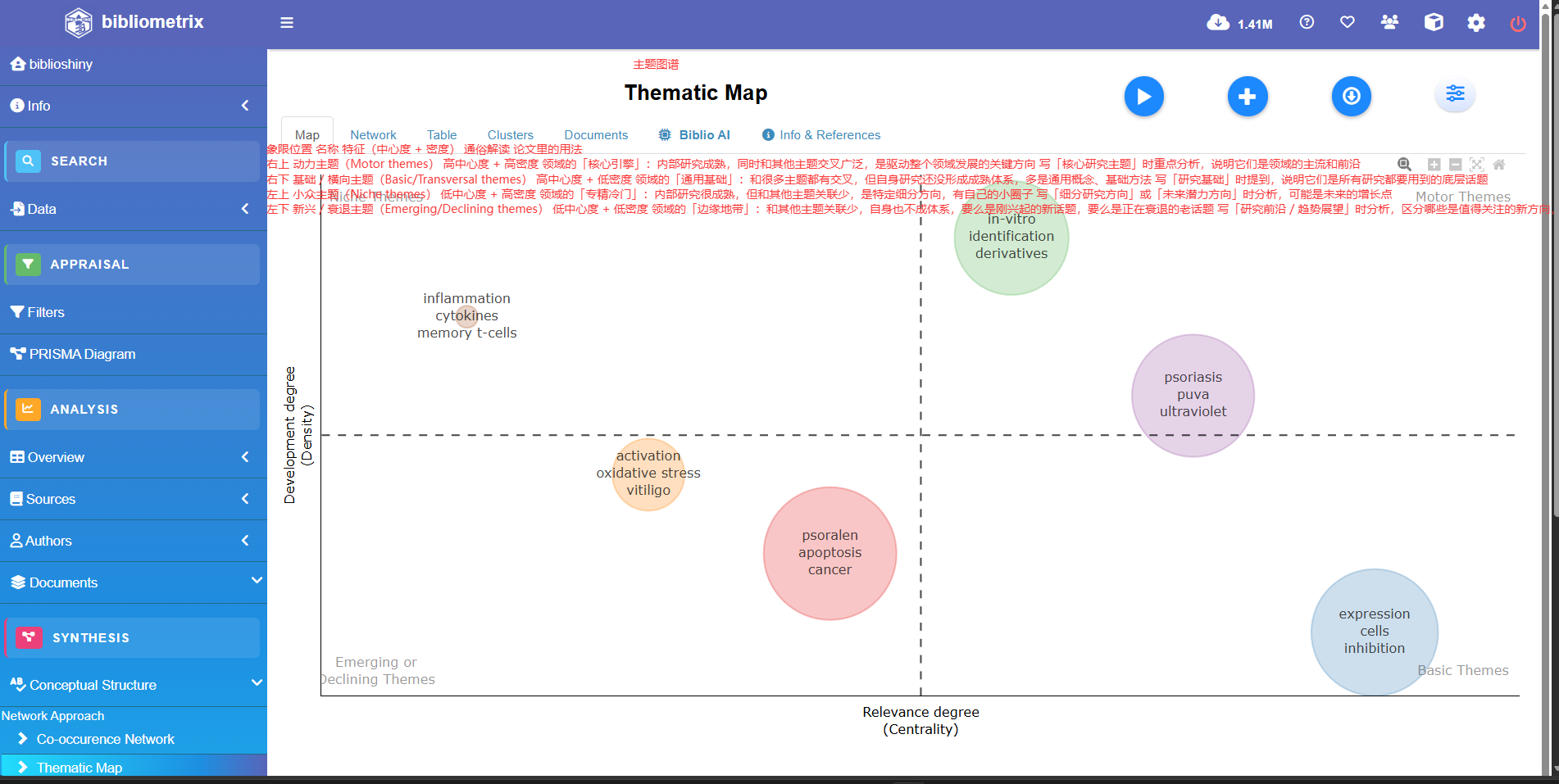
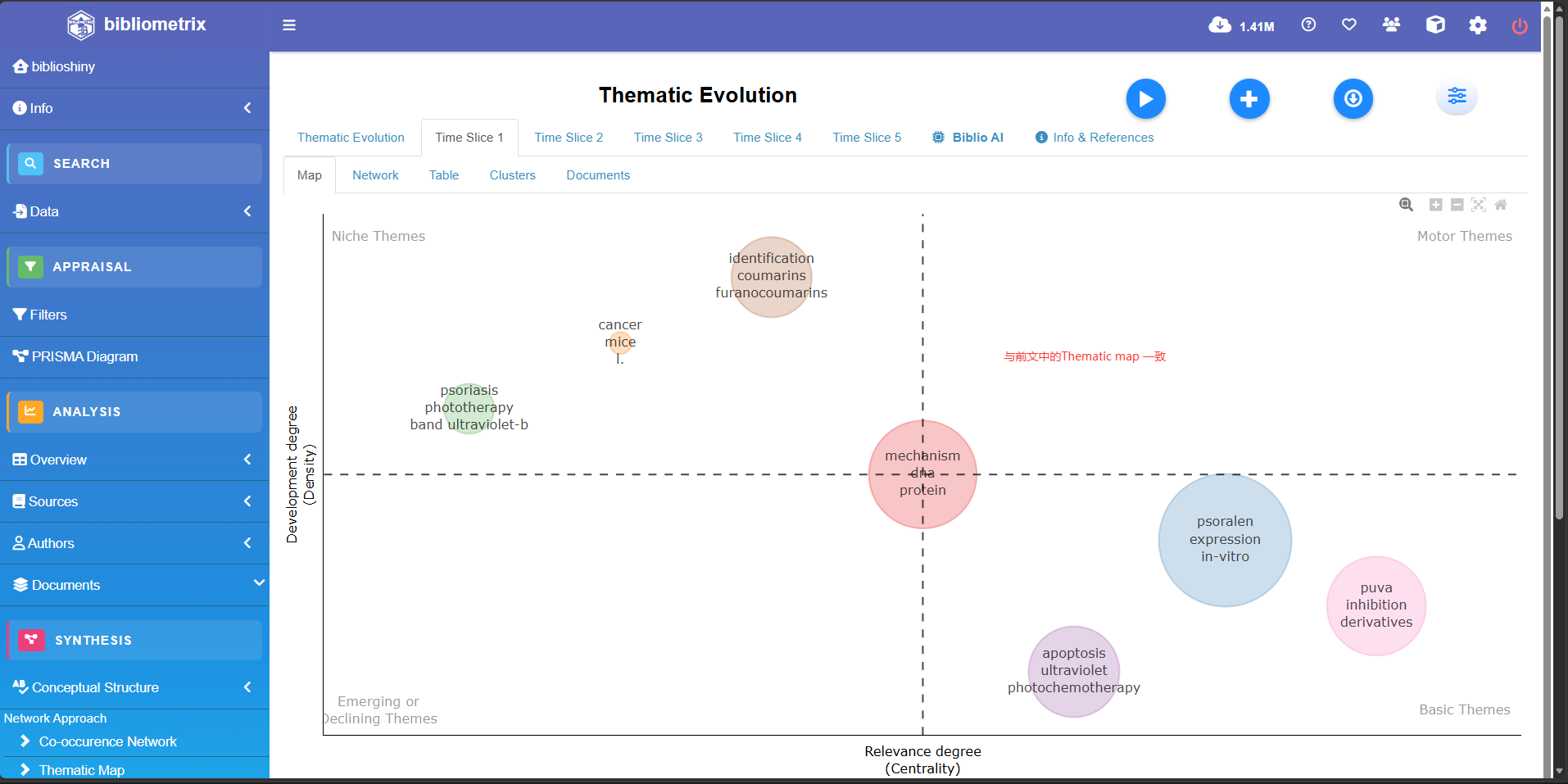
themmap <- thematicMap(
# -------------------- 1. 数据与基础设置 --------------------
M = M_new, # 你的文献数据框
field = "TI", # 从哪里提取词汇?
# - "TI" = 从论文标题 (Title) 提取
# - "DE" = 作者提供的关键词 (Author Keywords)
# - "ID" = 数据库生成的扩展关键词 (Keywords Plus,默认值)
# - "AB" = 从摘要 (Abstract) 提取 (词汇量最大,但也最杂)
# -------------------- 2. 网络与词频控制 --------------------
n = 500, # 纳入分析的最高频词的数量。你设了500,词汇量比较大,图可能会比较丰富但也可能略显拥挤
minfreq = 1, # 一个主题聚类在图上显示所需的最小词频(千分比或绝对频次)。设为1表示即使是非常冷门的主题也会被画出来
ngrams = 1, # 提取词组的长度。1=单字(如"data"),2=双词组(如"data mining"),3=三词组
# 建议:如果领域内专业术语多为组合词,强烈建议改为 2 或 3
# -------------------- 3. 文本清洗与处理 --------------------
stemming = FALSE, # 是否进行词干提取?TRUE=把复数/过去式还原(如 runs -> run)。默认 FALSE
remove.terms = NULL, # 自定义停用词表。传入一个字符向量 (例如: c("study", "paper")) 来删掉这些无意义的通用词
synonyms = NULL, # 自定义同义词表。用于合并意思相同的词 (格式见上文示例),对提高图表质量极其重要
# -------------------- 4. 聚类算法设置 --------------------
cluster = "louvain", # 网络社区发现(聚类)的算法。还有"leiden", "walktrap", "fast_greedy" 等
community.repulsion = 0.5,# 聚类气泡之间的排斥力 (0到1之间)。数值越大,气泡在图上分得越开
subgraphs = FALSE, # 是否返回各个聚类的子图数据?默认 FALSE,一般不需要改
alpha = 0.5, # 在确定每个聚类(气泡)的代表性标签词时,词频(frequency)和PageRank中心度(centrality)的权重平衡点。0.5代表两者同等重要
# -------------------- 5. 可视化与复现控制 --------------------
size = 0.5, # 图中聚类气泡的大小比例。取值范围 (0.01, 1),觉得气泡太大互相遮挡可以调小
n.labels = 1, # 每个气泡上显示几个核心关键词作为标签?默认是1,如果想看得更清楚可以改为 2 或 3
repel = TRUE, # 是否开启标签防重叠功能?
seed = 1234 # 随机数种子
)
plot(themmap$map)
注意thematicmap函数输出的包括几个重要内容
-
themmap$map: 这就是那张四象限图的 ggplot2 对象,直接用plot(res$map)就可以画出来。(同时你也可以进行自定义) -
themmap$clusters: 这是一个表格,里面记录了每个聚类(主题)的具体中心度和密度数值。 -
themmap$words: 每个主题具体包含了哪些关键词,这对于你解释图表至关重要! -
themmap$net: 原始的词汇共现网络数据。
展示下效果并解释一下这个图
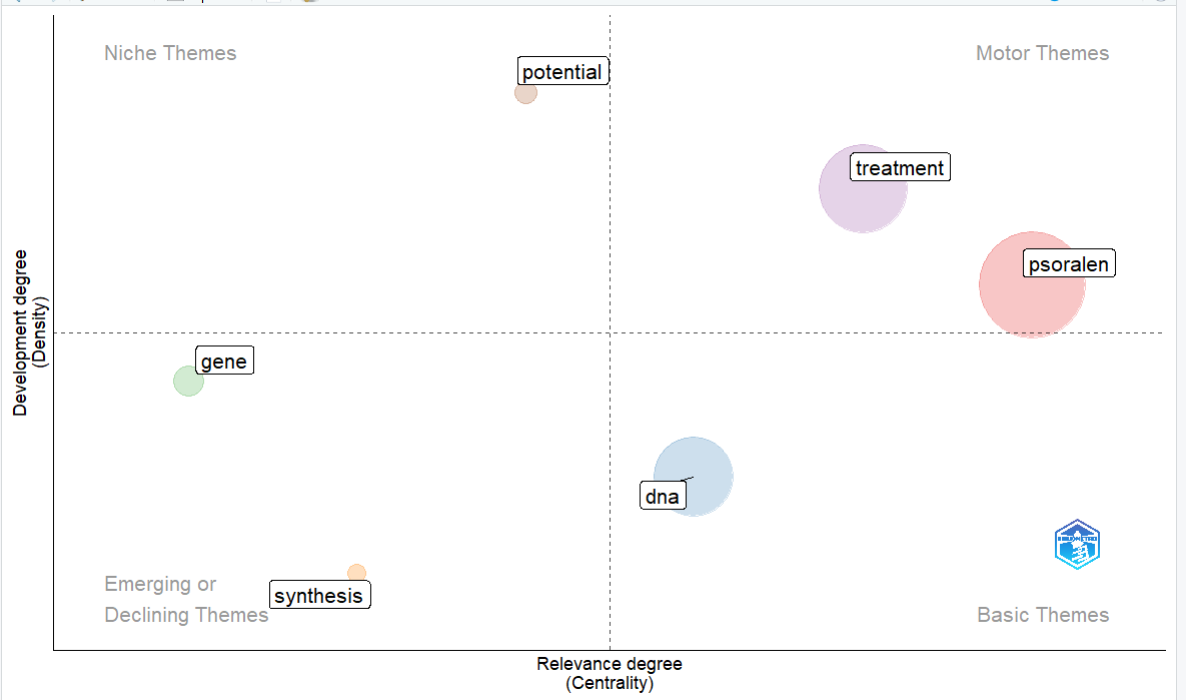
-
横坐标(中心度 Centrality): 代表该主题与领域内其他主题的关联程度(重要性)。越往右,说明这个主题越是该领域的核心。
-
纵坐标(密度 Density): 代表该主题内部关键词之间联系的紧密程度,即该主题的发展成熟度。越往上,说明这个主题研究得越透彻、越成熟。
借鉴一下我另一篇文章里面的解释
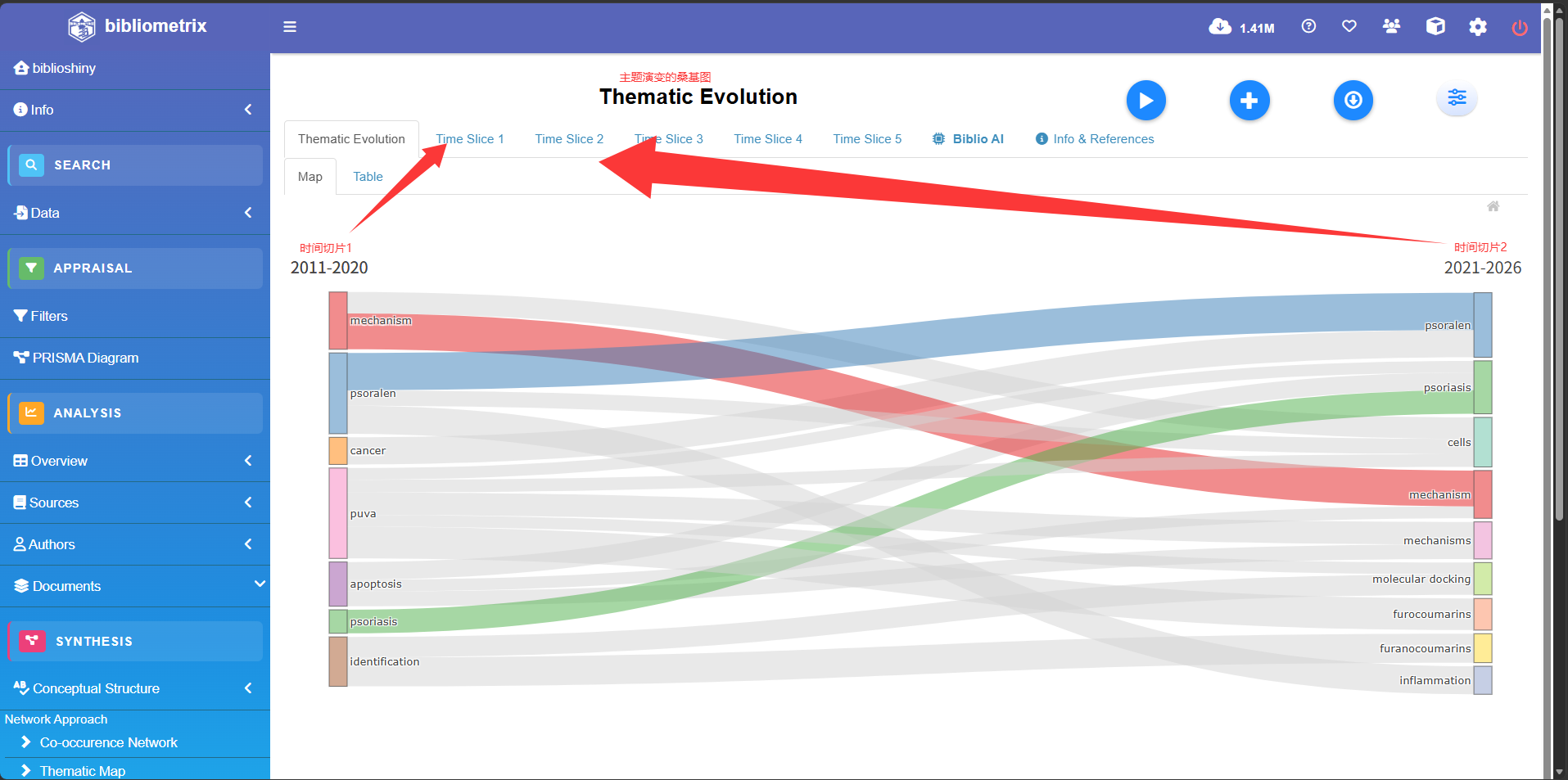
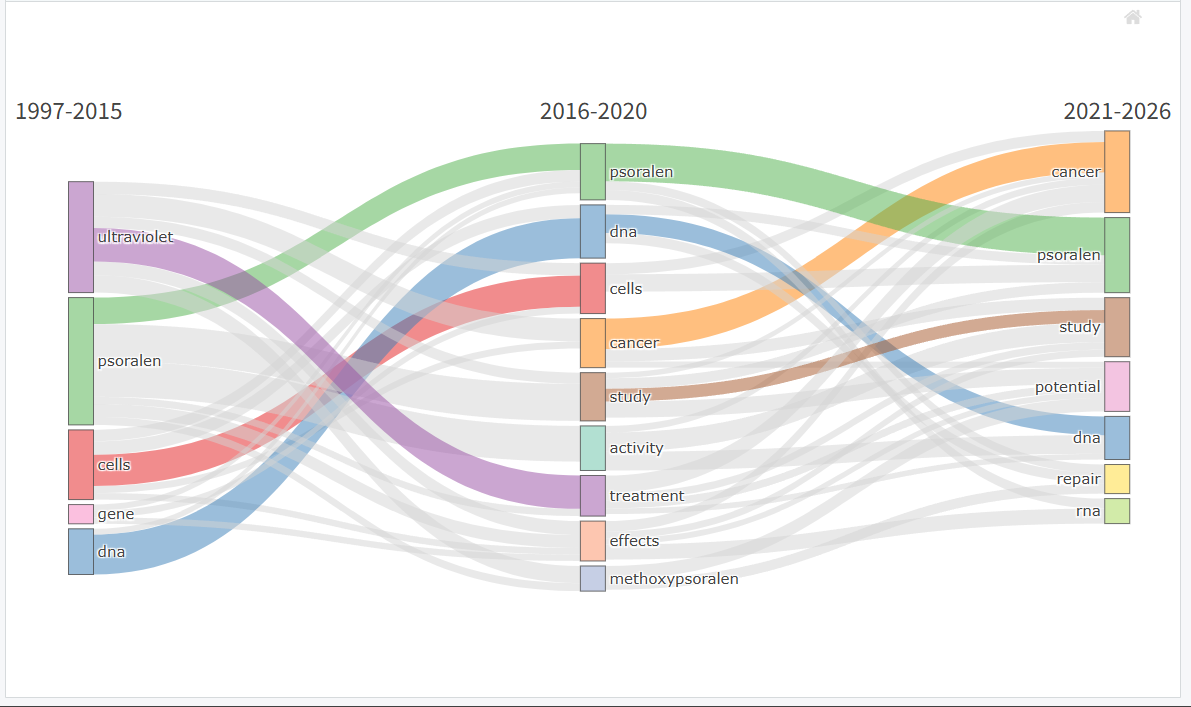
*主题演化桑基图*
-
切分时间 (Slicing):按时间轴将总文献划分为连续的数个阶段。
-
提取主题 (Mapping):各阶段独立运行
thematicMap,生成当期代表性主题(气泡)。 -
连线追踪 (Tracking):对比相邻阶段,若两主题共享大量核心关键词(包容指数高),则判定存在演化“血缘”并建立连线。
evol_analysis <- thematicEvolution(
# -------------------- 1. 数据与时间切片 --------------------
M = M_new, # 你的文献数据框
field = "TI", # 提取词汇的来源
years = c(2015, 2020), # 时间切点。
# 这样写代表切分为3个阶段:(1) 2015年及以前; (2) 2016-2020年; (3) 2021年至今
# -------------------- 2. 网络与词频控制(同 thematicMap)--------------------
n = 250, # 每个时间段纳入网络分析的高频词数量。
# 注意:如果时间切片分得很细(比如每2年一个切片),每个切片里的文献较少,这个 n 可以适当调小。
minFreq = 2, # 词汇被纳入聚类的最低频率
ngrams = 1, # 提取词组长度(同理,如果是专业术语,可设为 2 或 3)
# -------------------- 3. 文本清洗(极其重要)--------------------
stemming = FALSE, # 是否词干化
remove.terms = NULL, # 剔除的垃圾词
synonyms = NULL, # 合并的同义词
# -------------------- 4. 聚类与视觉控制 --------------------
cluster = "louvain", # 聚类算法
n.labels = 1, # 图上每个主题方块显示的标签词数量
repel = TRUE, # 开启标签防重叠
size = 0.5, # 主题方块的相对大小
seed = 1234, # 随机数种子
# -------------------- 5. 演化专用参数 --------------------
assign.evolution.colors = list(assign = TRUE, alpha = 0.5)
# 控制演化连线(桑基图路径)的颜色。
# assign = TRUE 表示连线的颜色会继承源头主题的颜色,方便追踪。
# alpha = 0.5 控制连线的透明度。
)
my_evol_plot <- plotThematicEvolution(
Nodes = evol_analysis$Nodes,
Edges = evol_analysis$Edges,
min.flow = 0.05
)
print(my_evol_plot)
#着色?
nexus_colored <- assignEvolutionColors(
evol_analysis,
threshold = 0.5, # 设定强关联门槛,高于此值的主题将被视为同一血脉
palette = NULL, # 使用默认调色板 (也可自定义如 c("#333333", "#666666"))
alpha = 0.5 # 设置颜色的透明度
)
print(my_evol_plot)
plotThematicEvolution(nexus_colored$Nodes, nexus_colored$Edges)
其他桑基图
tf<-threeFieldsPlot(
M_new,#convert2df转化的数据框
fields = c("DE","AU","SO"),#你桑基图上的分段
n=c(20,20,20)#每段展示几个标签
)
#下面是简单改个颜色,未来我会出一个bibliometrix各种图的修改教程#
print(tf$x$attrs$e3c063a57df6$node$color)
node_count <- length(tf$x$attrs[[1]]$node$color)
my_colors <- rep(c("#E63946", "#457B9D", "#2A9D8F", "#E9C46A"), length.out = node_count)
tf$x$attrs[[1]]$node$color <- my_colors
tf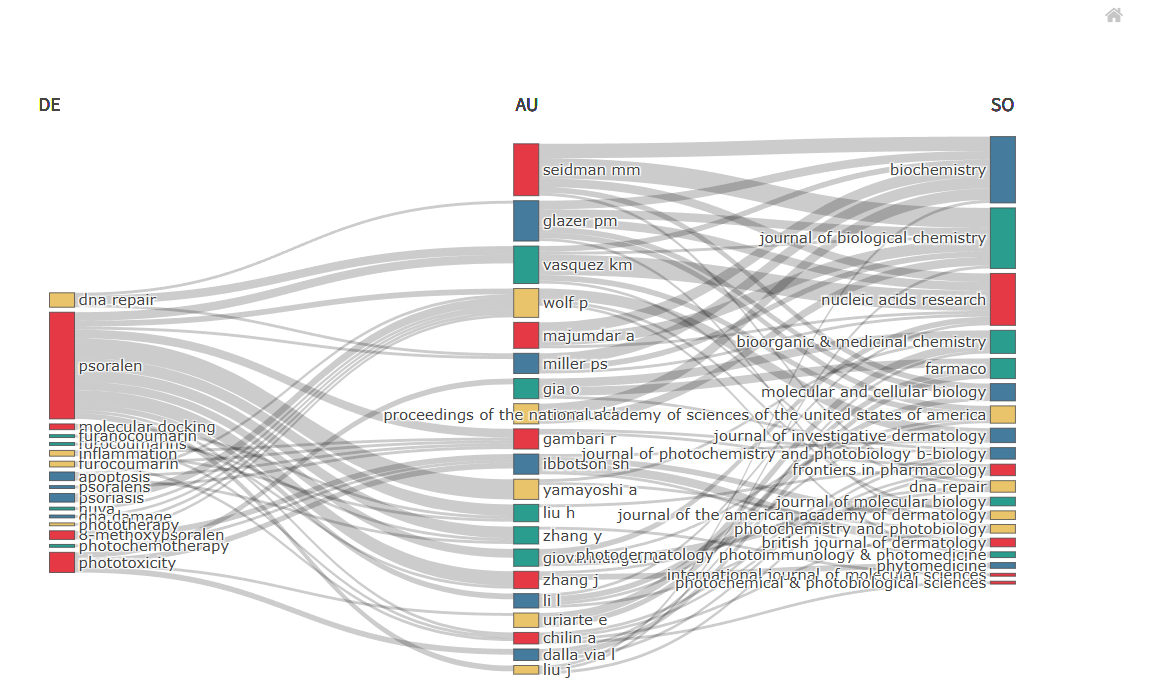
LIFE CYCLE(LOGISTIC MODEL)
year_pub<-biblioAnalysis(M)%>%summary()
year_pub <- year_pub$AnnualProduction
names(year_pub)<-c("PY","n")
year_pub$PY <- as.numeric(as.character(year_pub$PY))
year_pub$n <- as.numeric(as.character(year_pub$n))
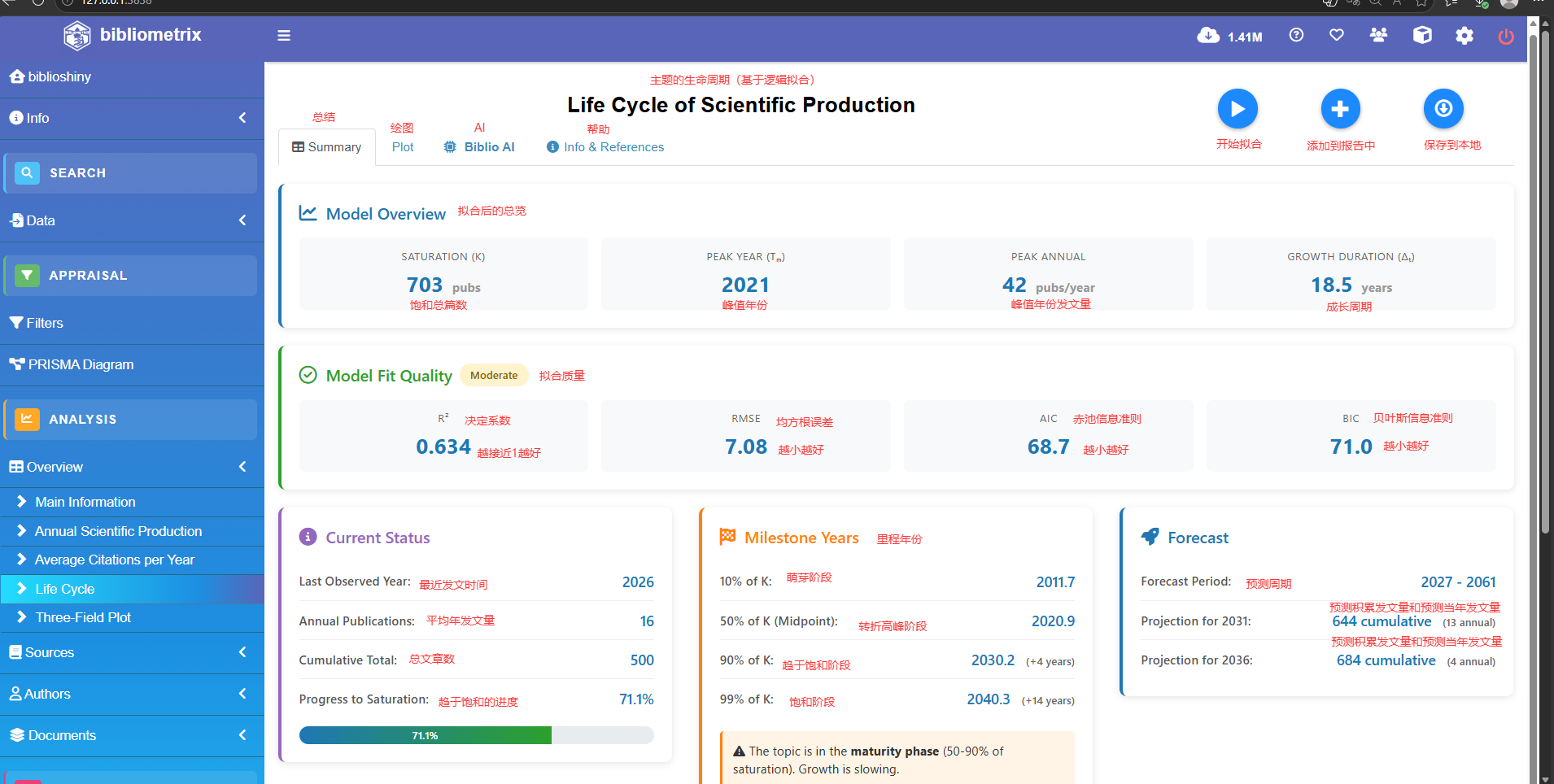
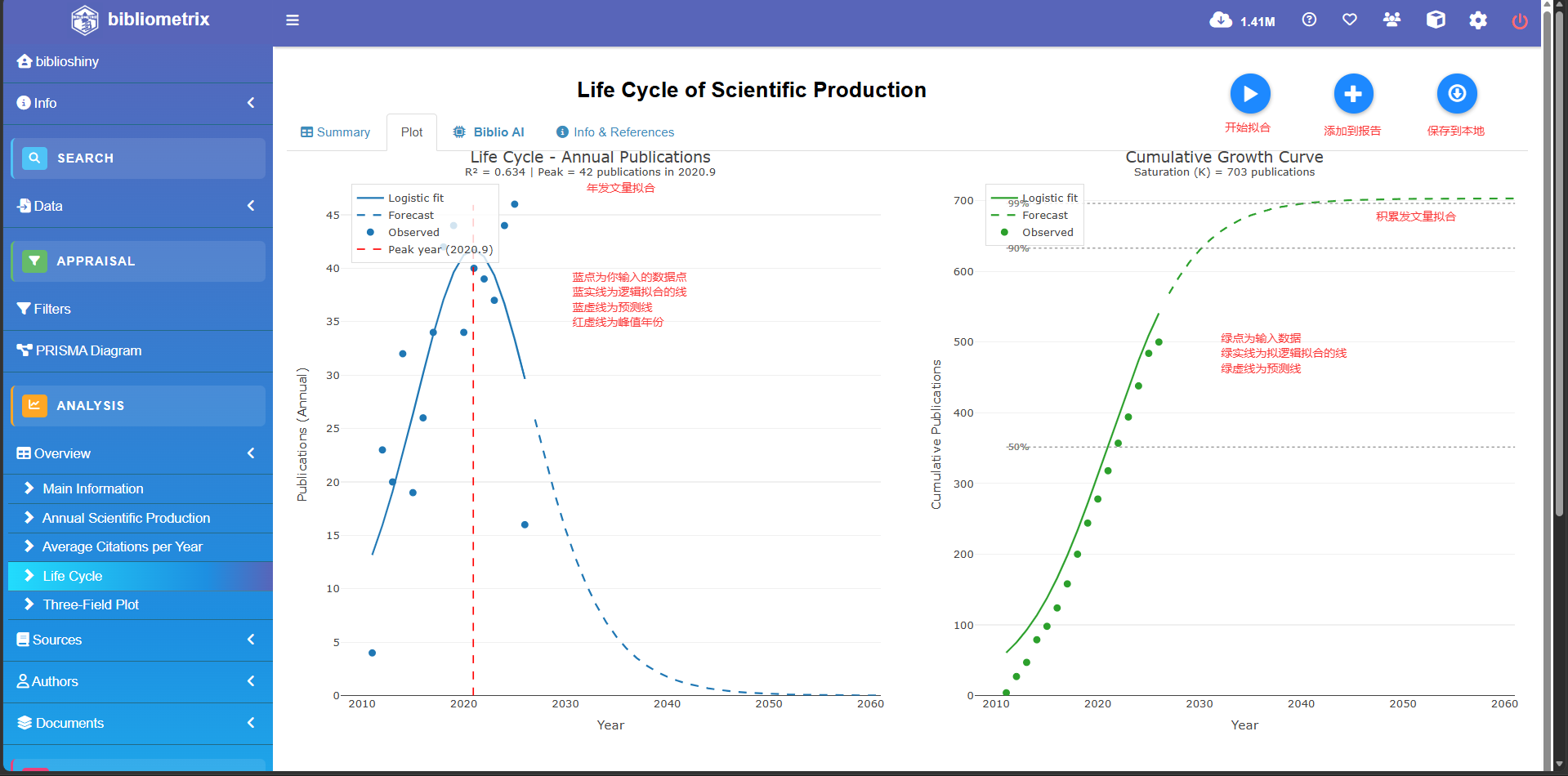
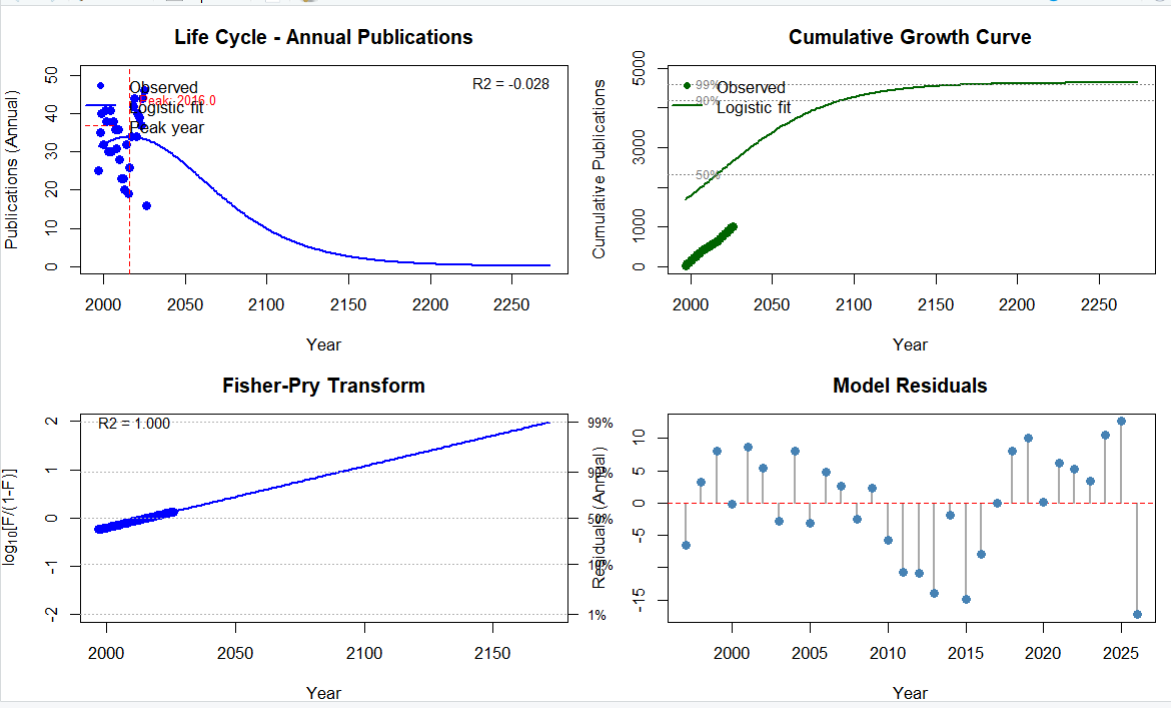
lc<-lifeCycle(year_pub, forecast_years = 100, plot = TRUE, verbose = TRUE)
=== LIFE CYCLE ANALYSIS (LOGISTIC MODEL) ===
Model: Logistic (fitted on annual publications)Estimated Parameters:
K (saturation limit): 4638.29 # 理论上的总发文量上限(预估这个领域最多只能发这么多篇文章就会饱和)
tm (midpoint index): 19.95 # 时间中点(增长最快、发文量爆发的拐点)
delta_t (duration 10-90%): 150.00 # 发展周期(走完领域生命周期的10%到90%需要整整150年)Fit Metrics:
R_squared RMSE AIC BIC
1 -0.028 7.974 130.575 134.778
# 极其重要:R方(拟合优度)是 -0.028!
# 正常应该在0到1之间,如果是负数,说明你的数据根本不符合“爆发-衰退”的规律(波动太大),
# 因此,下面的所有预测年份在学术上都是不可靠的,只能当个乐子看。Interpretation:
- Estimated saturation (K): 4638 cumulative publications # 最终总计发表量将停留在 4638 篇
- Peak year (tm): 2016.0 # 预测的巅峰年份:2016年(发文最多)
- Peak annual publications: 34 # 巅峰那一年大概发了 34 篇文章
- Growth duration 10-90% (delta_t): 150.0 years
- Year reaching 50% of K: 2016.0 # 2016年时,该领域已经完成了一半的寿命
- Year reaching 90% of K: 2091.0 # 预测2091年该领域90%的研究都被挖空了(即将进入衰退期)
- Year reaching 99% of K: 2172.8 # 预测2172年彻底凉凉--- Forecast Summary ---
Last observed year: 2026 (16 annual / 1000 cumulative) # 你的真实数据最后截止到了2026年
Forecast extends to: 2273 # 机器强行往后预测到了2273年Projection for 2031: 2822 cumulative publications # 预测到2031年时,该领域历史累计总文章数会达到2822篇
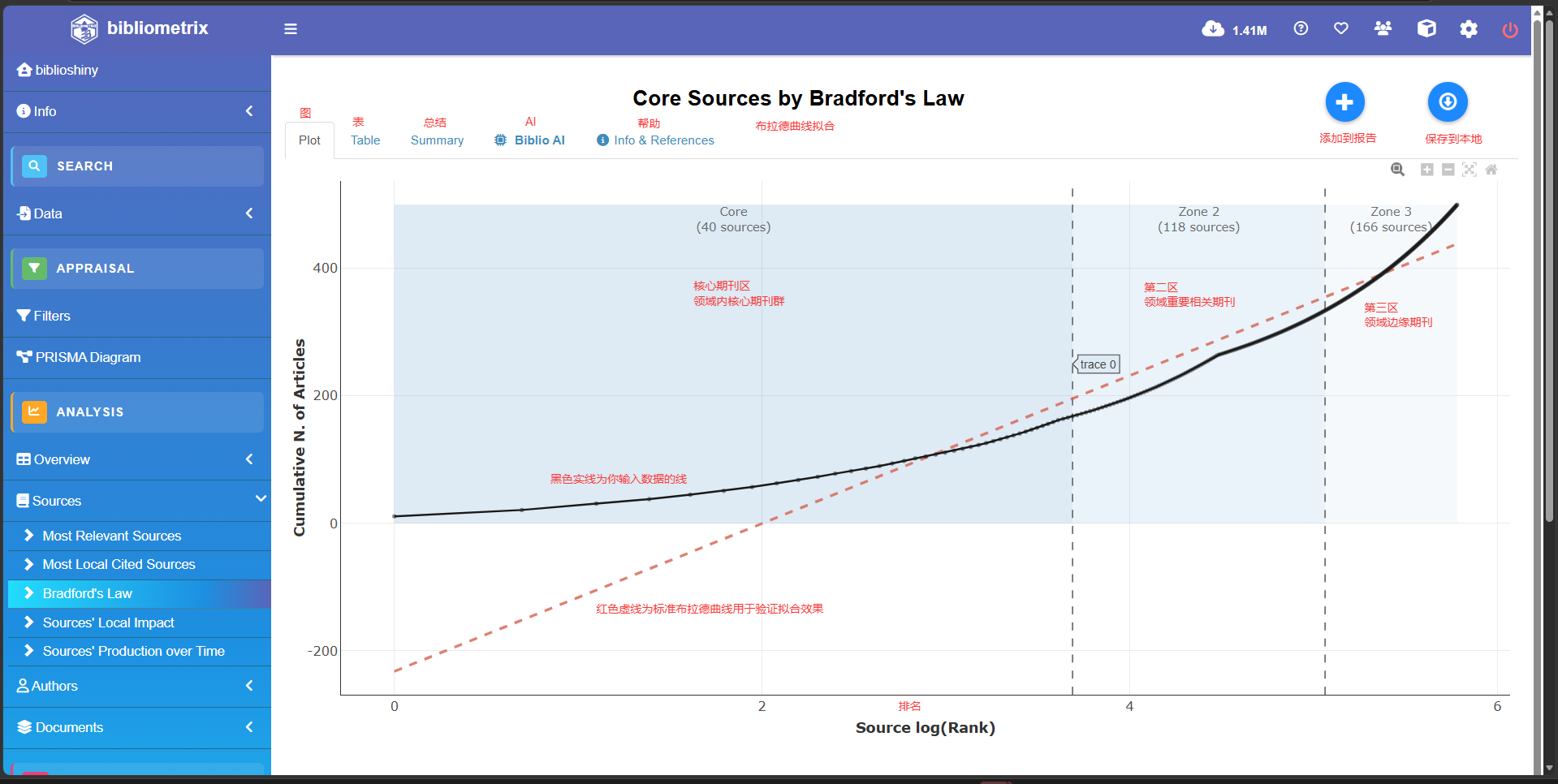
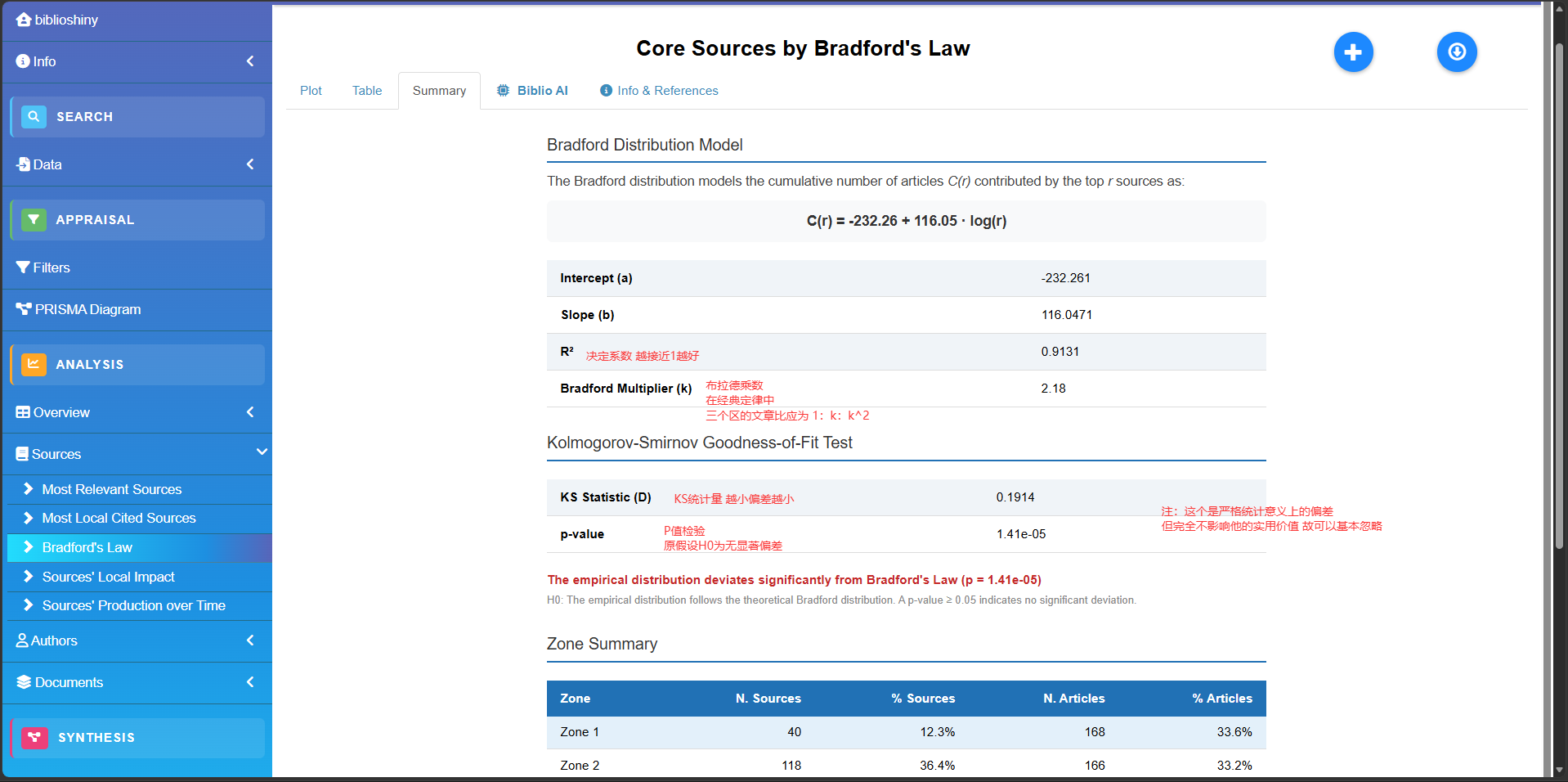
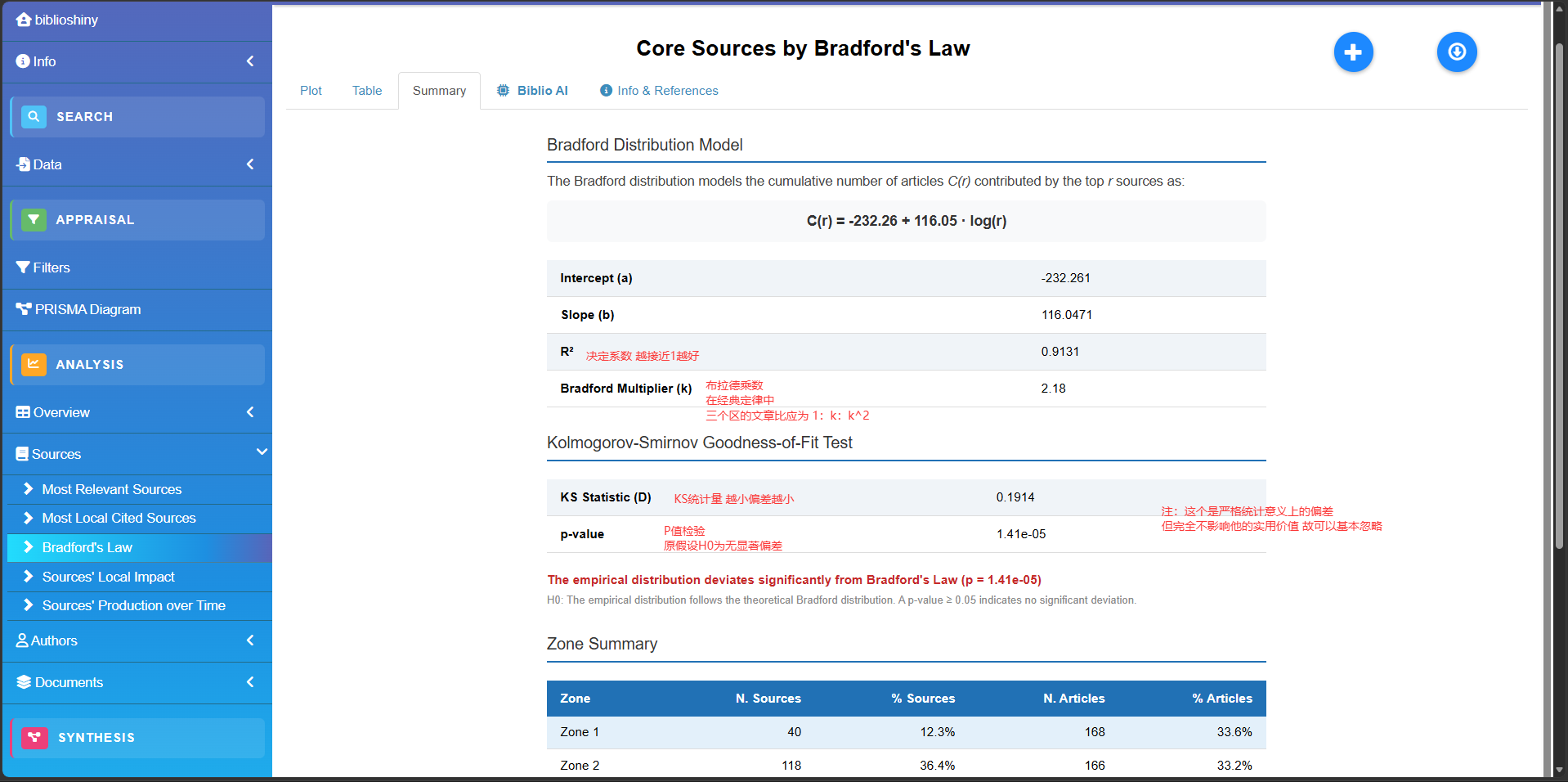
BRADFORD 定律拟合
bf<-bradford(M_new)
plot(bf$graph)
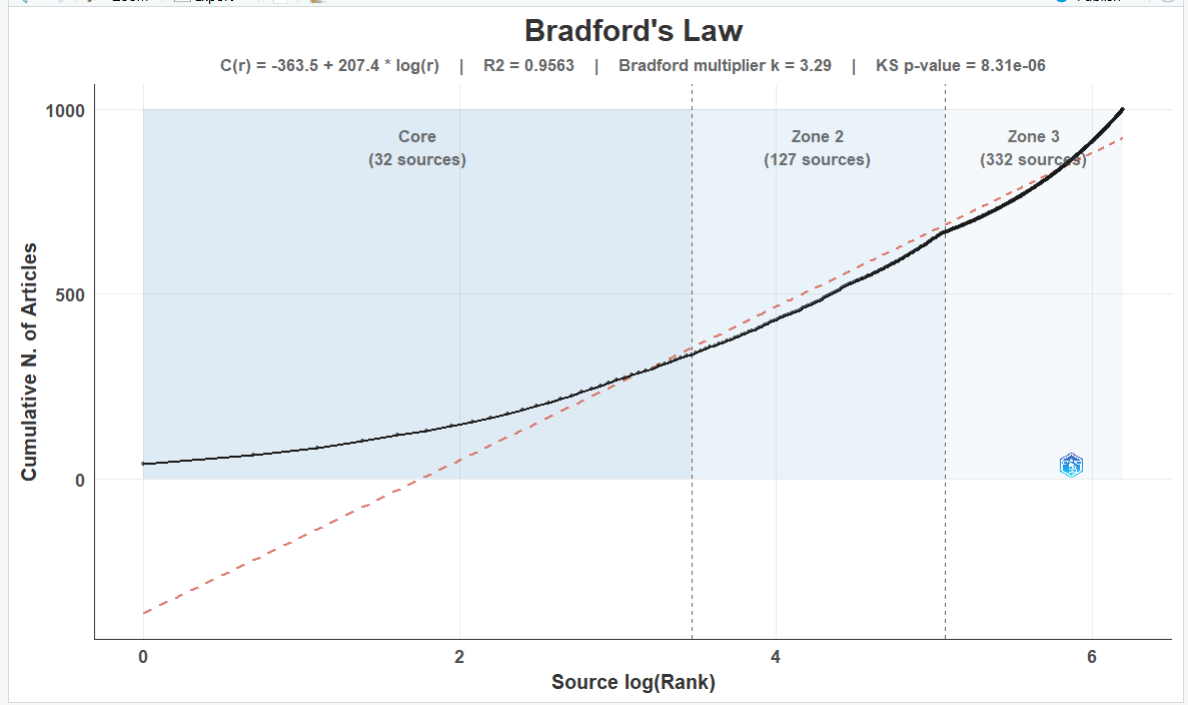
-
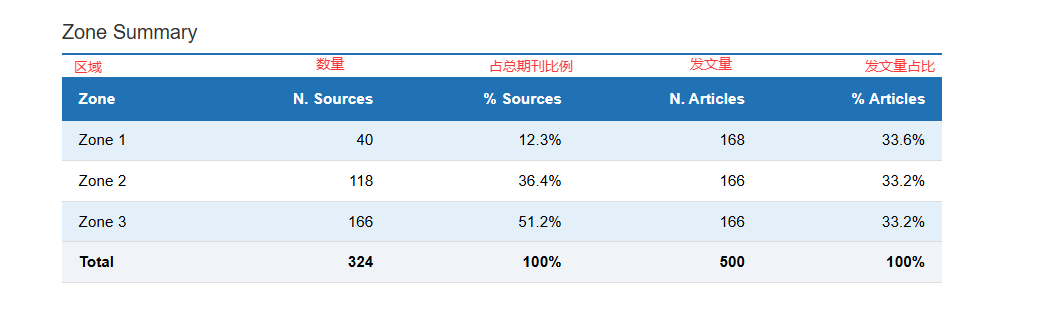
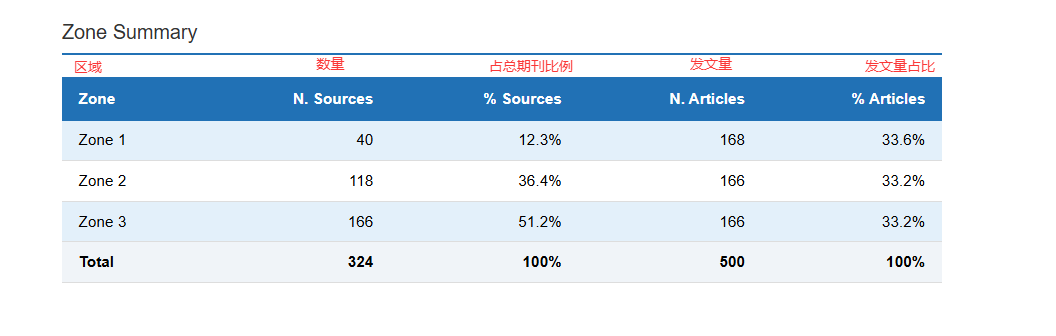
table(核心期刊表):所有被引期刊的详细名单。附带了分区标签(Zone 1 核心区,Zone 2 相关区,Zone 3 边缘区)。 -
zoneSummary(分区数据汇总):高度浓缩的统计表。直观展示三大分区各自包含的期刊数和文章数 -
graph(可视化图):用ggplot2绘制的布拉德福分布曲线图。 -
stat(统计检验):数学拟合结果。重点看Bradford multiplier(算出的乘数 )和R2(决定系数)。 -
graph_shiny:biblioshiny网页版专用的无 logo 图表
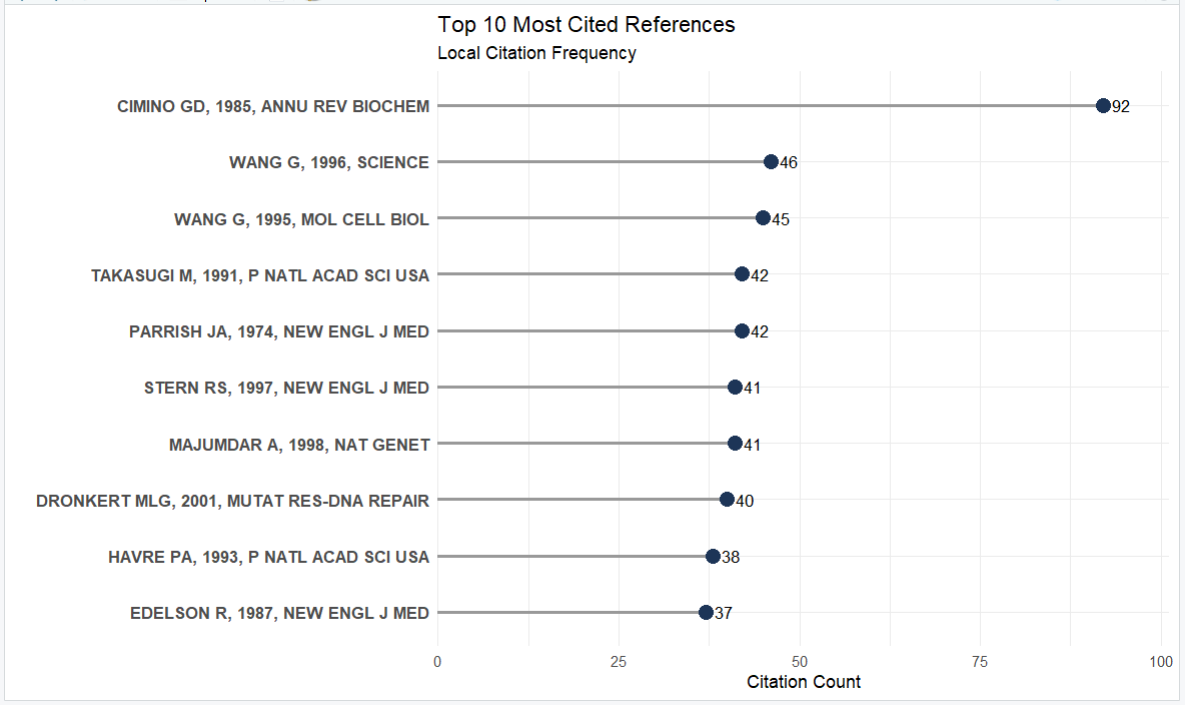
TOP被引文献棒棒糖图
CR <- citations(M_new, field = "article", sep = ";")
CR_table <- data.frame(
name = names(CR$Cited)[1:10], # 取前10篇文献的名称
count = CR$Cited[1:10], # 取前10篇文献的被引次数
year = CR$Year[1:10], # 取前10篇文献的年份
sor = CR$Source[1:10] # 取前10篇文献的来源期刊
)
CR_table$clean_name <- sapply(strsplit(as.character(CR_table$name), ","), function(x) {
# 提取前3项,并用 trimws() 自动去掉逗号前后的多余空格
parts <- trimws(x[1:min(3, length(x))])
# 把提取出来的干净的这3项,重新用逗号拼接起来
paste(parts, collapse = ", ")
})
# 确保 count.Freq 列是数值型
CR_table$count.Freq <- as.numeric(CR_table$count.Freq)
ggplot(CR_table, aes(x = reorder(clean_name, count.Freq), y = count.Freq)) +
geom_segment(aes(x = reorder(clean_name, count.Freq), xend = reorder(clean_name, count.Freq),
y = 0, yend = count.Freq),
color = "gray60", linewidth = 1) +
geom_point(color = "#1D3557", size = 4) +
geom_text(aes(label = count.Freq), hjust = -0.5, color = "black", size = 3.5) +
coord_flip() +
scale_y_continuous(expand = expansion(mult = c(0, 0.1))) +
theme_minimal() +
labs(
title = "Top 10 Most Cited References",
subtitle = "Local Citation Frequency",
x = "",
y = "Citation Count"
) +
theme(
axis.text.y = element_text(size = 10, face = "bold")
)
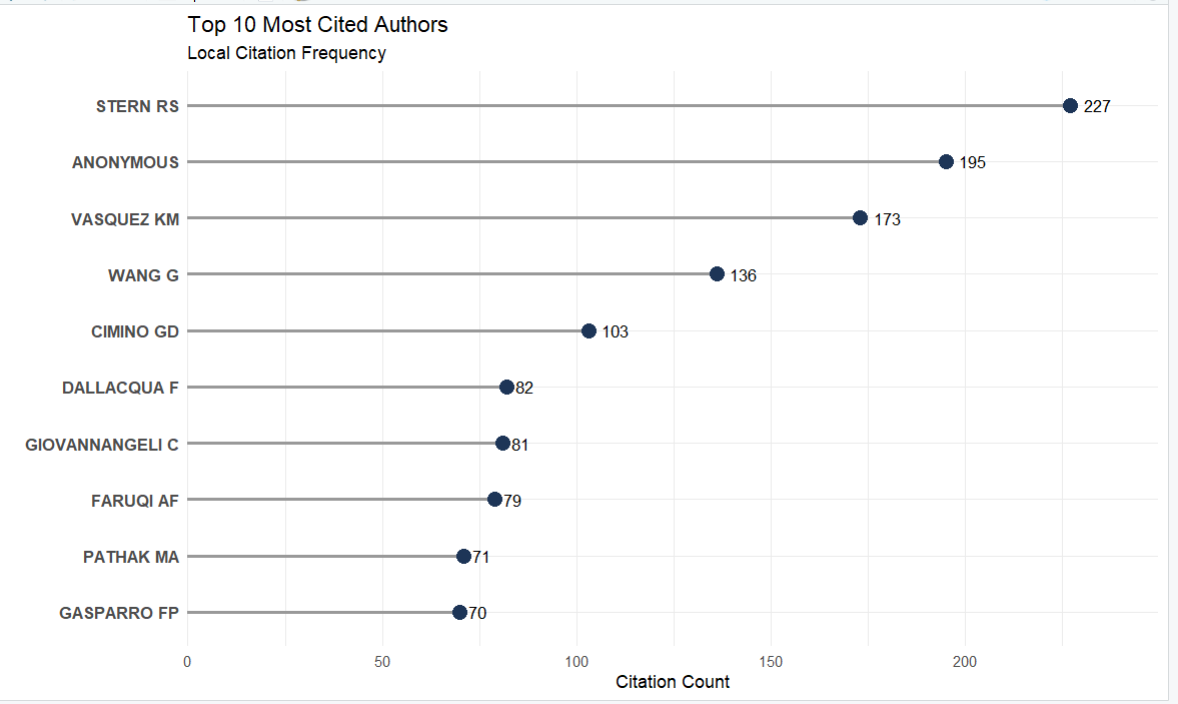
TOP被引作者棒棒糖图
全局被引
CR_author_raw <- citations(M_new, field = "author", sep = ";")
CR_author_df <- data.frame(
author = names(CR_author_raw$Cited)[1:10], # 提取作者名字
count = as.numeric(CR_author_raw$Cited)[1:10] # 提取对应的被引次数
)
ggplot(CR_author_df, aes(x = reorder(author, count), y = count)) +
geom_segment(aes(x = reorder(author, count), xend = reorder(author, count),
y = 0, yend = count),
color = "gray60", linewidth = 1) +
geom_point(color = "#1D3557", size = 4) +
geom_text(aes(label = count), hjust = -0.5, color = "black", size = 3.5) +
coord_flip() +
scale_y_continuous(expand = expansion(mult = c(0, 0.1))) +
theme_minimal() +
labs(
title = "Top 10 Most Cited Authors",
subtitle = "Local Citation Frequency",
x = "",
y = "Citation Count"
) +
theme(
axis.text.y = element_text(size = 10, face = "bold")
)
本地被引
CR_results <- localCitations(
M = M_new,
fast.search = FALSE, # [可选参数] 是否开启快速计算?
# - FALSE (默认): 计算所有文献的 LCS
# - TRUE: 仅计算被引排名前 25% 文献的 LCS,适合大数据集
sep = ";", # 参考文献(CR列)的分隔符,默认是分号 ";"
verbose = FALSE # 是否在屏幕上打印计算过程?
)
结构概念图(一种聚类)
# 绘制概念结构图 (聚类与降维)
CS <- conceptualStructure(
M = M_new, # 文献数据框 (convert2df 的结果)
field = "ID", # 提取字段: "ID"(默认关键词), "DE"(作者关键词), "TI"(标题), "AB"(摘要)
ngrams = 1, # 词组长度 (1-4): 1代表单字词,2代表双词短语
method = "MCA", # 降维算法: "MCA"(多重对应分析), "CA" 或 "MDS"
quali.supp = NULL, # 分类补充变量索引 (仅用于 MCA/CA)
quanti.supp = NULL, # 定量补充变量索引 (仅用于 MCA/CA)
minDegree = 2, # 过滤阈值: 词频低于此值的词将被剔除
clust = "auto", # 聚类数量: "auto" 或设定具体数字 (2-8)
k.max = 5, # 自动聚类时允许的最大主题(簇)数量
stemming = FALSE, # 是否提取词根 (如将 clusters 和 clustering 合并)
labelsize = 10, # 图形中词汇标签的字体大小
documents = 2, # 在图中每个主题下展示的代表性高引文献数量
graph = TRUE, # 运行后是否自动弹出绘制好的图形
remove.terms = NULL, # 自定义停用词表: c("word1", "word2")
synonyms = NULL # 自定义同义词表: c("标准词;同义词1", "AI;artificial intelligence")
)关键词聚类图
plot(CS$graph_terms)
-
注释:核心主题图 (Theme Map)。通过 MCA/MDS 降维算法,将高维共现关系投影到二维平面。图中距离越近的词代表其在文献中共同出现的频率越高。
-
用途:用于识别领域内的 “研究子主题”。不同颜色的多边形(聚类簇)代表了该学科下不同的研究流派或知识领域。
-
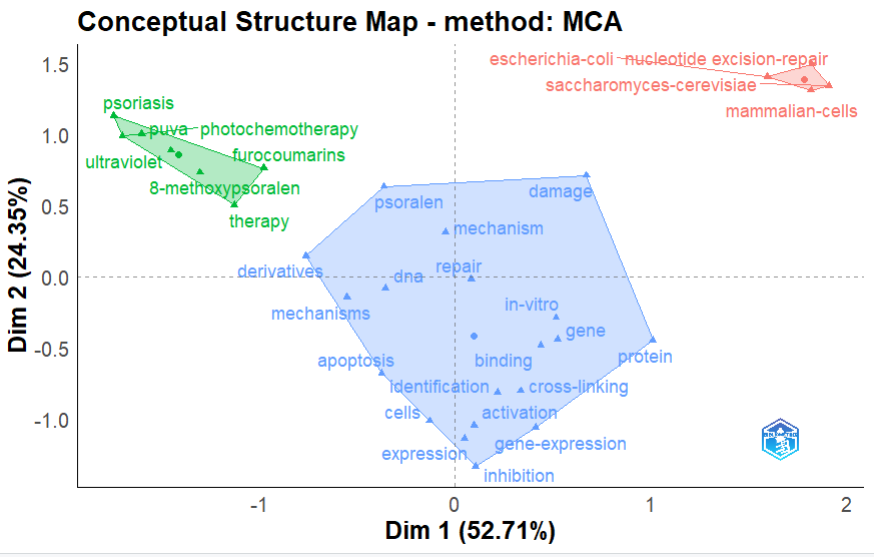
层次聚类树状图
plot(CS$graph_dendogram)
-
注释:主题亲疏图 (Hierarchy Tree)。展示了关键词之间逐级合并的过程。纵轴代表距离(Dissimilarity),横轴是关键词。
-
用途:用于观察主题之间的 “亲缘关系”。分支合并越早,说明这两个概念在学术讨论中越不可分割;而虚线切分出的不同颜色支系则对应了散点图中的聚类。
-
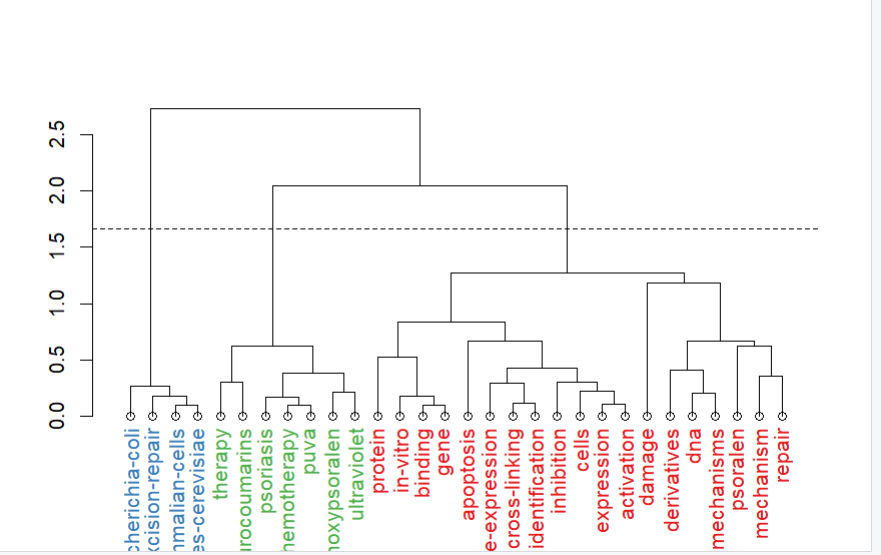
高贡献度文献图
plot(CS$graph_documents_Contrib)
-
注释:基因定义图 (Defining Documents)。展示了对每个聚类主题的“数学特征”贡献最大的代表性文献。
-
用途:用于寻找 “最纯正的主题代表作”。这些文章可能不是被引最高的,但它们的关键词构成最能代表该聚类的本质特征,是撰写综述时必须参考的“主题定义性”文献。
-
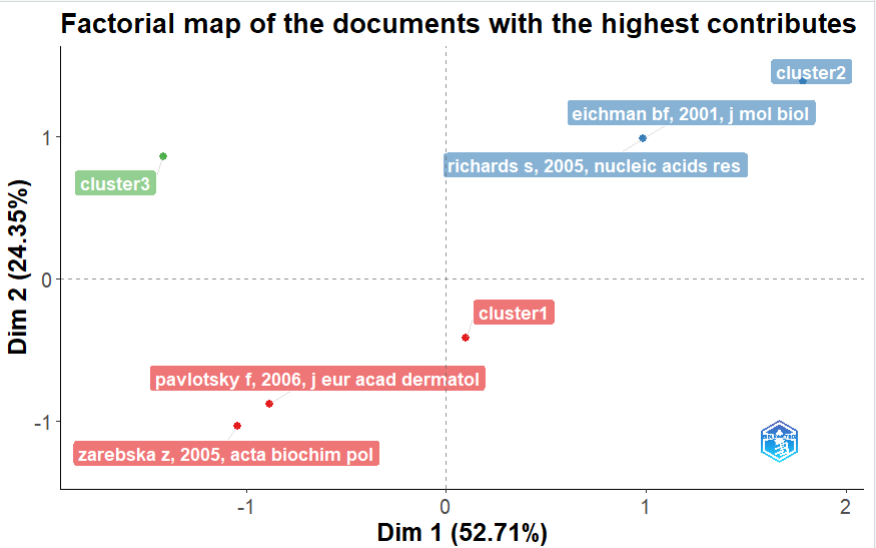
高被引文献图
plot(CS$graph_documents_TC)
-
注释:学术基石图 (Influential Documents)。将领域内被引用次数最高(Total Citations)的经典文献投射到主题空间中。
-
用途:用于寻找 “大佬级奠基作”。通过观察高引文章分布在哪个聚类周围,可以判断该研究主题是否由某些顶刊文章或行业巨头所支撑。
-
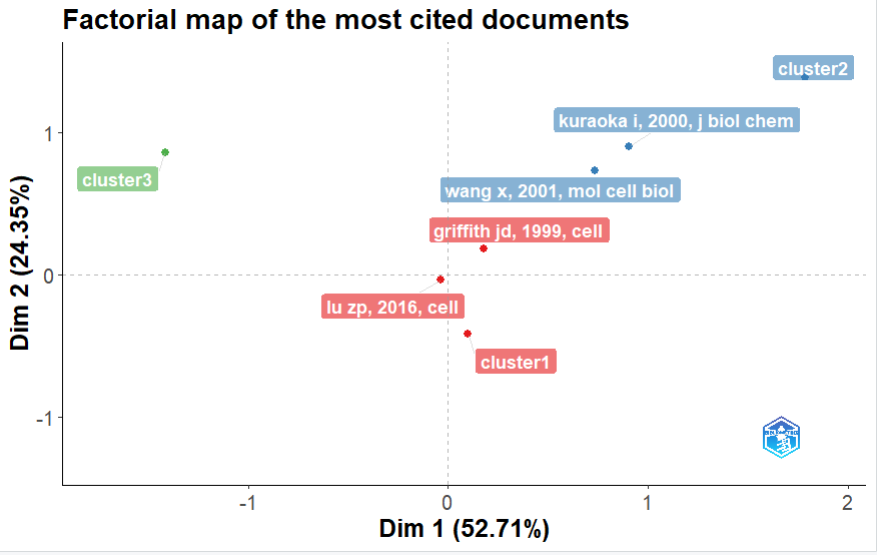
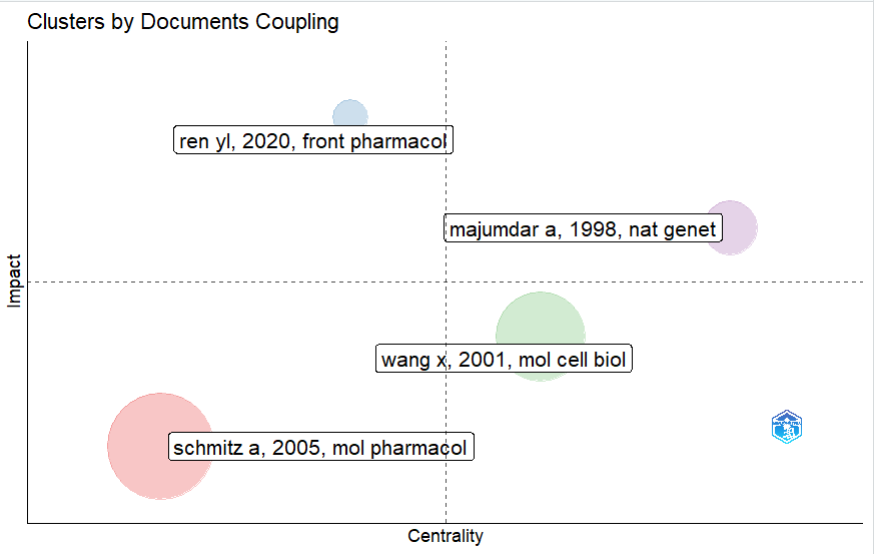
文献耦合分析
# =====================================================================
# 函数名称: couplingMap
# 主要功能: 执行文献耦合分析,并绘制带有“中心度-影响力”评估的二维聚类图
# =====================================================================
res <- couplingMap(
M = M_new, # 文献数据框 (通过 convert2df 获取)
analysis = "documents", # 评价对象: "documents"(文章), "authors"(作者), "sources"(期刊)
field = "CR", # 耦合依据: "CR"(默认参考文献耦合), "ID"/"DE"/"TI"/"AB"(文本内容耦合)
n = 500, # 纳入分析的节点总数 (例如提取前 500 篇)
label.term = NULL, # 聚类命名依据: "ID"/"DE"/"TI"/"AB", 设为 NULL 则自动使用节点名
ngrams = 1, # 词组长度 (1-4), 仅在用文本字段耦合时生效
impact.measure = "local", # Y轴影响力计算方法: "local"(基于本地引用的 NCS), "global"(基于全局引用的 NGCS)
minfreq = 5, # 聚类最小频率阈值 (千分比范围: 0-1000)
community.repulsion = 0.1, # 网络社区排斥力 (0-1), 值越大聚类分得越开
stemming = FALSE, # 是否提取词根 (如合并 cluster 和 clustering)
size = 0.5, # 图中聚类气泡(圆圈)的显示大小 (0.01-1)
n.labels = 1, # 图中每个聚类显示的代表性标签数量
repel = TRUE, # 标签是否防重叠 (会调用 geom_label_repel)
cluster = "walktrap" # 社区划分(聚类)算法: "walktrap", "louvain", "infomap", "optimal" 等
)
# 查看并输出最终生成的二维耦合评价图
plot(res$map)-
X轴 (Centrality / 中心度):代表“交际能力”。越往右,说明这个主题和其他方向交叉融合得越多,是领域的骨干桥梁。
-
Y轴 (Impact / 影响力):代表“吸流能力”。越往上,说明这个主题里的文章平均被引量越高,是学术界
-
右上角—— 【核心且极热】: 这是该领域的绝对主流霸主。它不仅处于研究的十字路口(中心度高),而且备受瞩目(影响力高)。
-
左上角—— 【小众但极热】: 这是孤岛型爆款。它和其他主题很少交叉(比较独立或垂直),但在自己的细分领域里热度极高,通常代表某个极具潜力的前沿突破口。
-
右下角—— 【核心但欠热】: 这是默默奉献的基石。大家的研究都离不开它(中心度高),但可能因为它偏向底层方法或老生常谈的背景理论,难以获得爆发性的直接引用(影响力偏低)。
-
左下角—— 【边缘且冷门】: 这是过气或边缘地带。注意看,红圈的气泡很大(说明发文量不少,很多人在灌水),但它既不处在核心圈,也没什么实质性的高引用。可能是已经衰退的老旧方向的顶流热点。
作者支配度
results <- biblioAnalysis(M_new)
DF_table <- dominance(results,k=10)
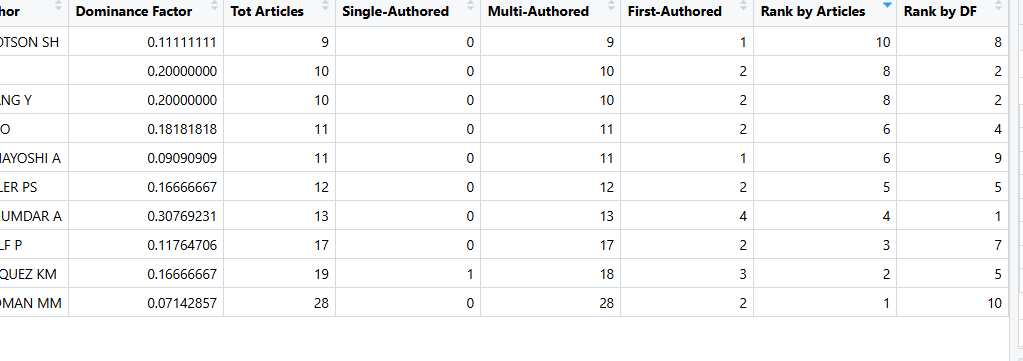
-
Tot Articles (TAA): 总发文量。(普通统计)
-
Single Authored (SAA): 独作文章数。
-
Multi Authored (MAA): 合作文章数。(总数减去独作数)
-
First Authored (FAA): 作为第一作者参与的合作文章数。
-
Dominance Factor: 支配因子。数值越接近 1,说明该作者在团队中越是核心带头人,用于排除挂名的那种。
-
Rank by Articles: 按总发文量排的名次。
-
Rank by DF: 按支配因子排的名次。
画个棒棒糖图
library(ggplot2)
library(dplyr)
plot_data <- DF_table %>%
arrange(desc(`Dominance Factor`)) %>%
mutate(Author = factor(Author, levels = rev(Author)))
DF_plot <- ggplot(plot_data, aes(x = Author, y = `Dominance Factor`)) +
geom_segment(aes(x = Author, xend = Author, y = 0, yend = `Dominance Factor`),
color = "gray70", linewidth = 1.5) +
geom_point(color = "#377EB8", size = 5) +
coord_flip() +
geom_text(aes(label = round(`Dominance Factor`, 2)),
hjust = -0.5, size = 3.5, color = "black") +
theme_minimal() +
theme(
panel.grid.major.y = element_blank(),
axis.text.y = element_text(face = "bold"),
plot.title = element_text(face = "bold")
) +
labs(
title = "Top 10 Authors' Dominance Factor",
subtitle = "Who is the real leader in collaborative research?",
x = "Author",
y = "Dominance Factor (DF)"
)
plot(DF_plot)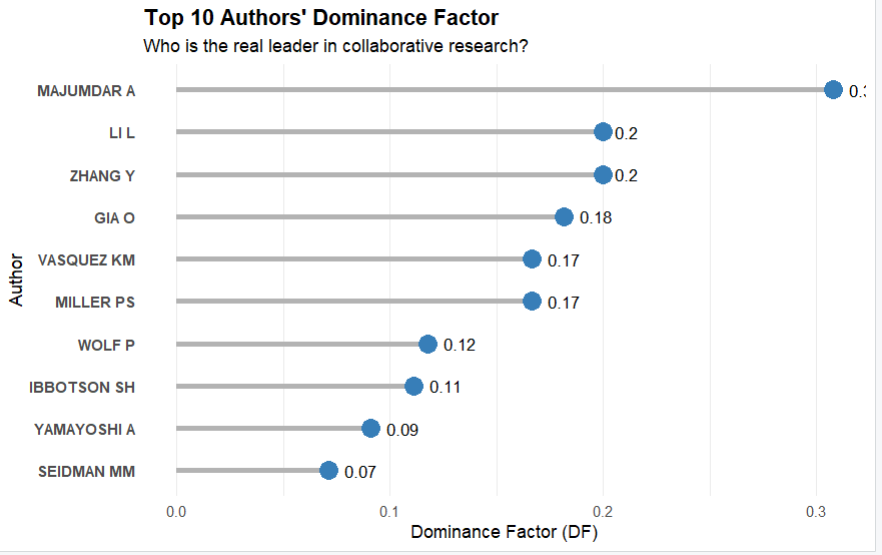
全周期的作者产出分析
AUpt <- authorProdOverTime(M_new, k = 10)
会输出3个内容
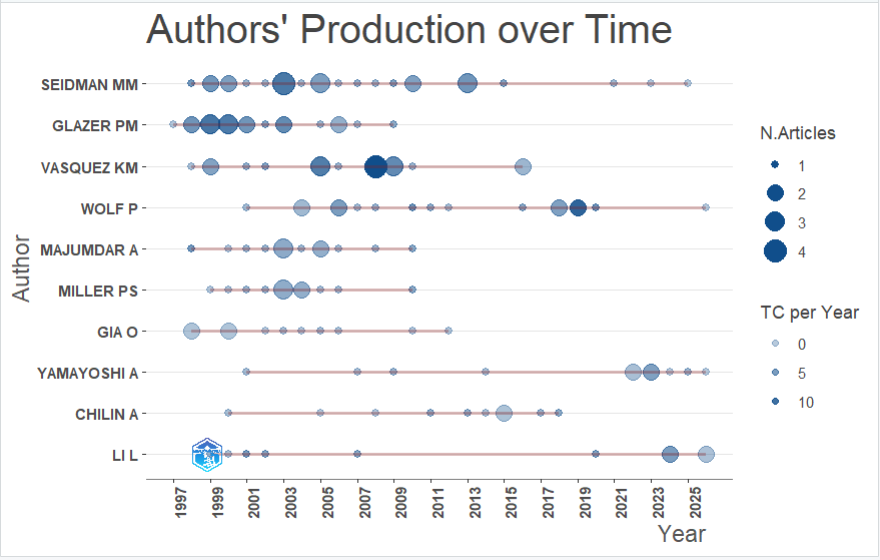
各种趋势分析
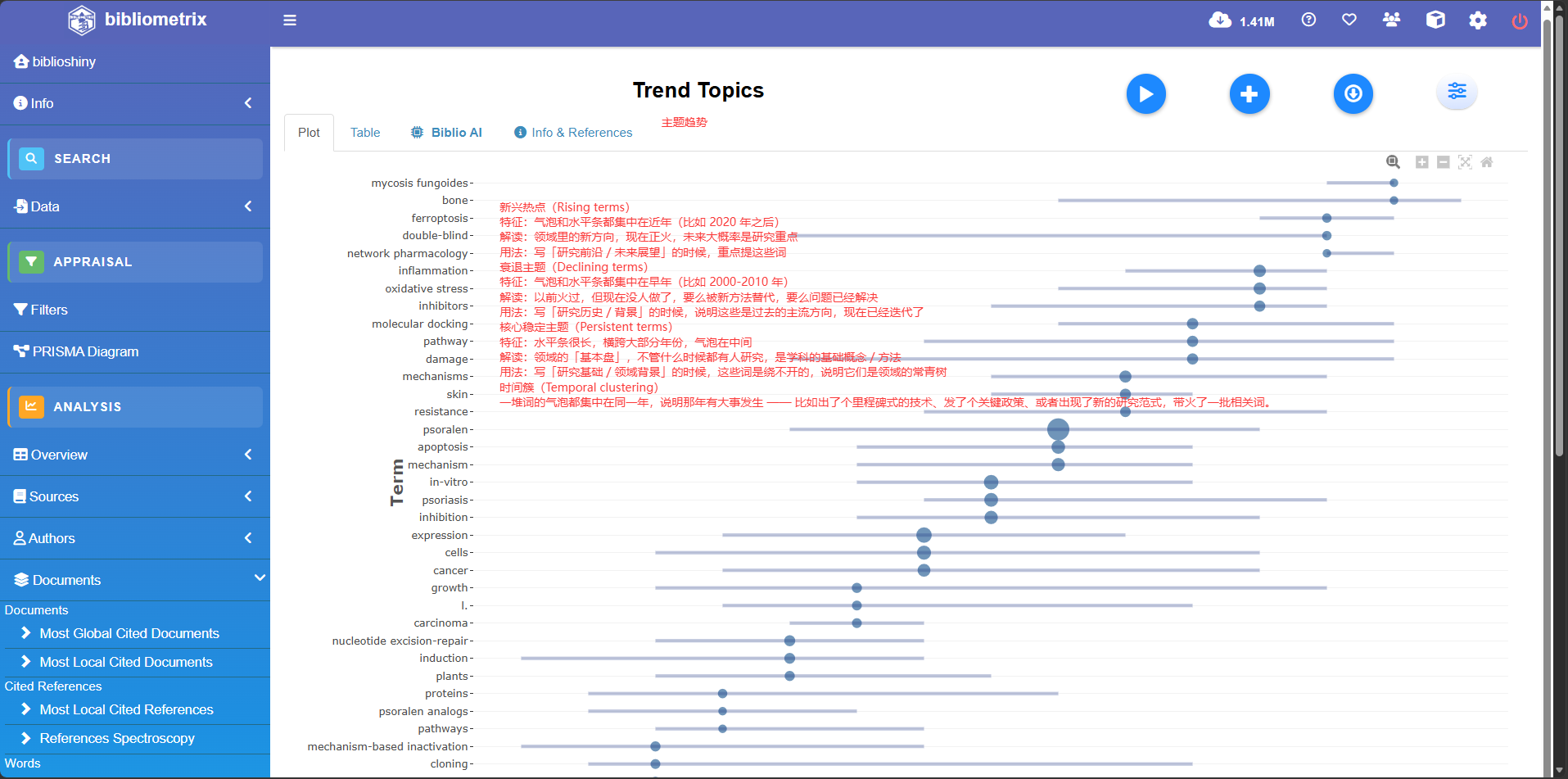
FB <- fieldByYear(
M = M_new, # 你的文献数据框
field = "ID", # 分析对象: "ID"(默认关键词), "DE"(作者关键词), "AU"(作者)
timespan = c(2005, 2025), # 限制分析的时间范围 (可选,不填即为全周期)
min.freq = 30, # 阈值:只分析至少出现过 5 次的词汇
n.items = 5, # 绘图限制:每年最多展示 5 个代表性词汇,保持画面整洁
dynamic.plot = FALSE, # 是否生成交互式网页图 (TRUE 为交互式,FALSE 为静态 ggplot)
graph = TRUE # 是否自动出图
)

精准查找某个作者的本地全部文献
aria_works <- findAuthorWorks(
author_name = "ARIA M", # 目标作者名字
data = M_new, # 你的总文献数据框
partial_match = TRUE # 允许部分匹配,防止漏掉缩写变体
)
H,G,M指数(根据本地生成)
indices_result <- Hindex(
M = M_new, # 文献数据框 (必填,通过 convert2df 获取)
field = "author", # 评价维度: "author"(评价学者,默认) 或 "source"(评价期刊)
elements = NULL, # 评价名单: 填 NULL 会计算所有人/期刊(耗时较长);也可指定如 c("ARIA M", "WANG X")
sep = ";", # 原始数据中的名字分隔符 (默认 ";",一般不需要改动)
years = Inf # 评估时间窗口: Inf(默认,计算全周期); 填具体数字如 5 表示只算近5年
)
# 1. 提取并查看最终的指数排名表 (包含 h, g, m 指数及总被引 TC 等)
# View(indices_result$H)
# 2. 提取某位作者的“支撑文献清单” (即他具体哪几篇文章被引了多少次,用于核对证据)
# 这里的 [[1]] 代表 elements 里指定的第一个作者
# head(indices_result$CitationList[[1]])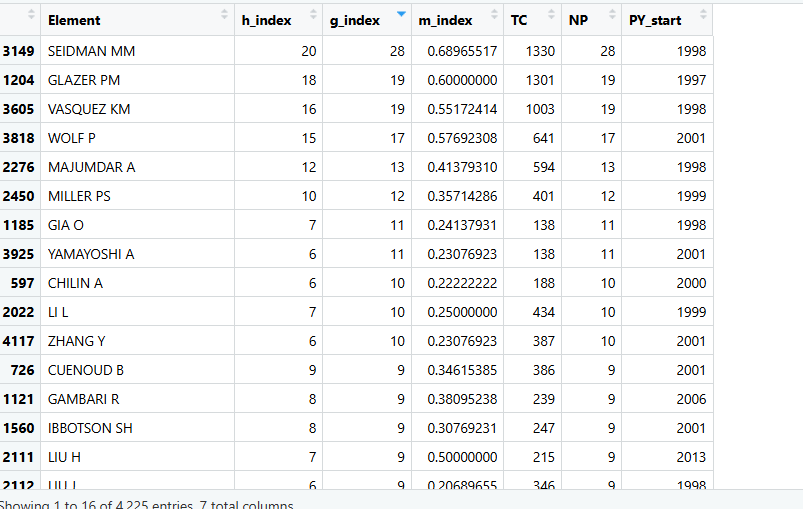
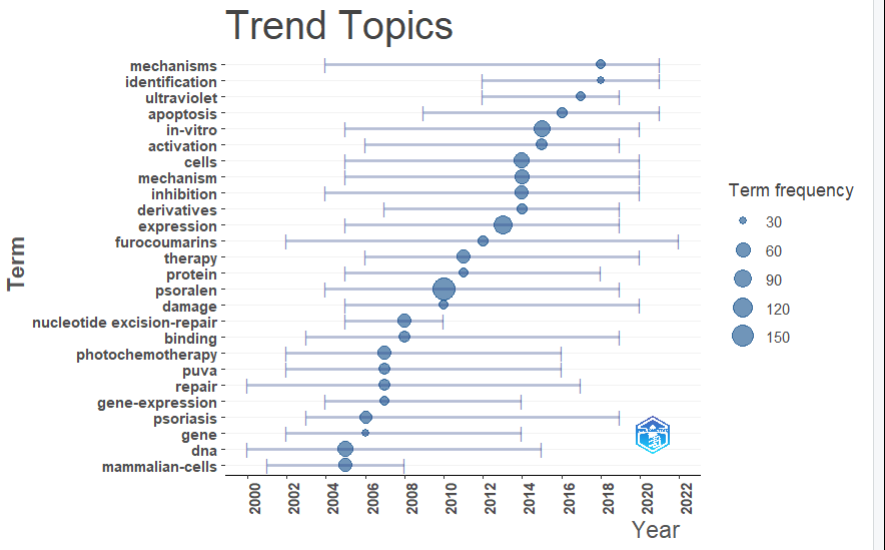
关键词趋势(积累或某年)
topKW <- KeywordGrowth(
M = M_new,
Tag = "ID", # 目标字段: "ID" 或 "DE"
sep = ";",
top = 5, # 选取排名前 5 的热词画图
cdf = TRUE, # TRUE = 累积历史总和 (曲线一直上升); FALSE = 每年真实发文量 (有起伏)
remove.terms = NULL,
synonyms = NULL
)
library(reshape2)
library(ggplot2)
DF <- melt(topKW, id = "Year") #
# 4. 绘制并美化增长折线图
p_growth <- ggplot(DF, aes(x = Year, y = value, group = variable, color = variable)) +
geom_line(linewidth = 1.2) +
geom_point(size = 2) +
theme_minimal() +
labs(
title = "Top 5 Keywords Growth Dynamics",
x = "Year",
y = "Cumulative Occurrences",
color = "Keywords"
) +
theme(legend.position = "bottom")
# 显示折线图
plot(p_growth)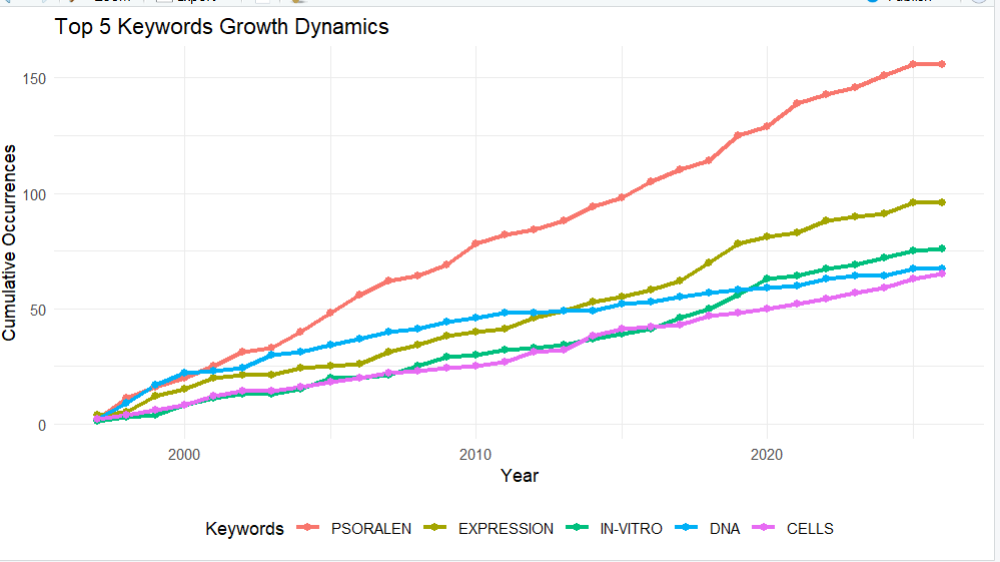
期刊发文趋势(积累或每年)
画图代码与关键词趋势类似不做赘述
top_sources_trend <- sourceGrowth(
M =M_new,
top = 5, #你想分析排名前几的期刊?默认提取前 5 名。
cdf = TRUE # 逻辑值。是否计算累积分布 (Cumulative Distribution)?
# - TRUE (默认): 计算累积发文总量(呈逐年上升曲线),展现期刊的历史总贡献度。
# - FALSE: 仅计算单年的绝对发文量(曲线有升有降),展现期刊每年的活跃度波动。
)
洛特卡定律拟合
l<- lotka(M_new)
plot(l$g)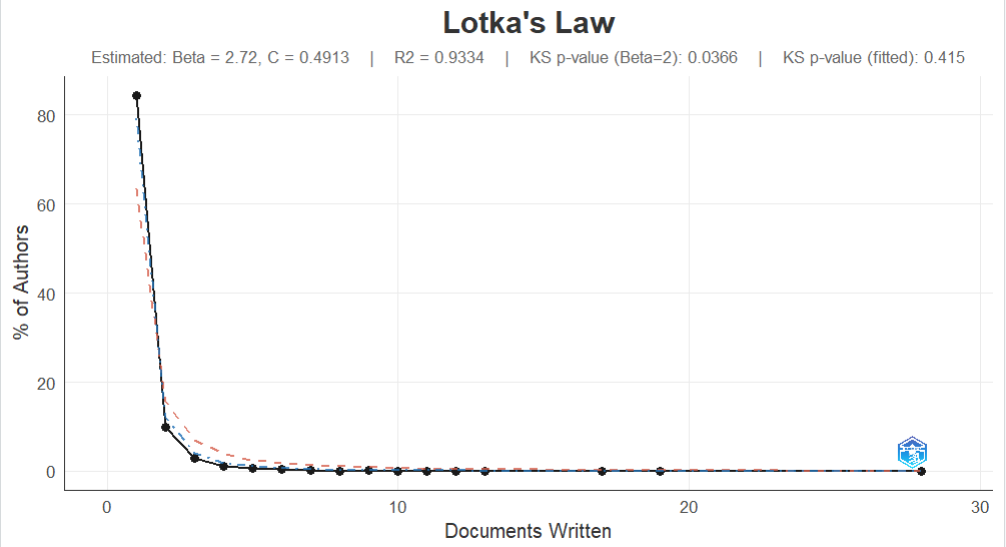
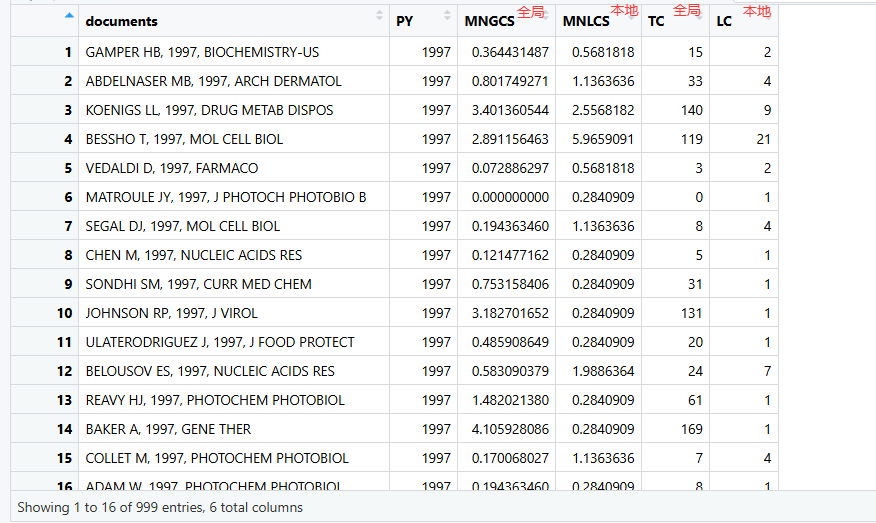
标准化本地引用得分
NCS_docs <- normalizeCitationScore(
M = management,
field = "documents", # 分析对象:单篇文献
impact.measure = "local" # 数据基准:使用本地被引(LCS)进行测算
)
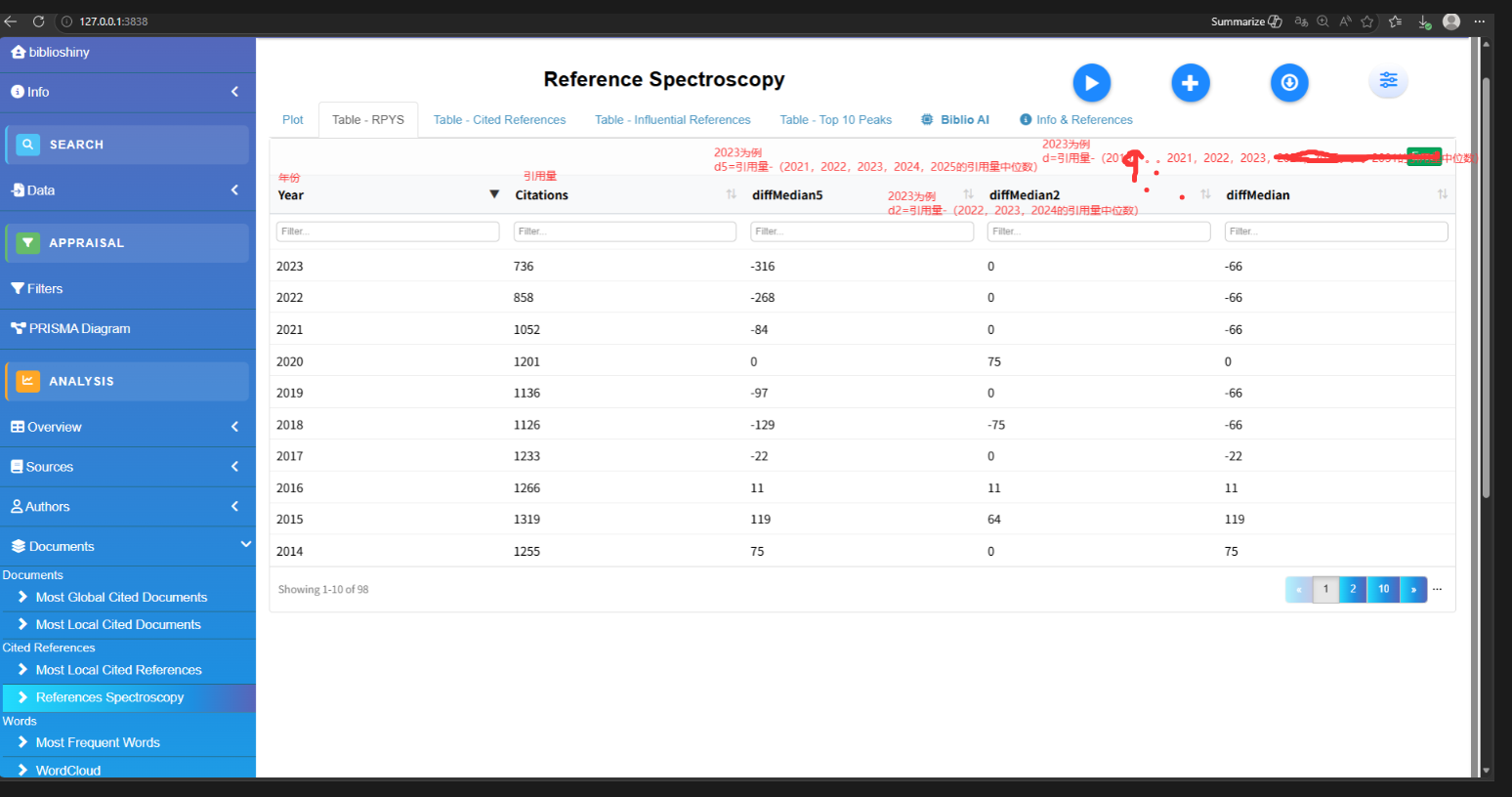
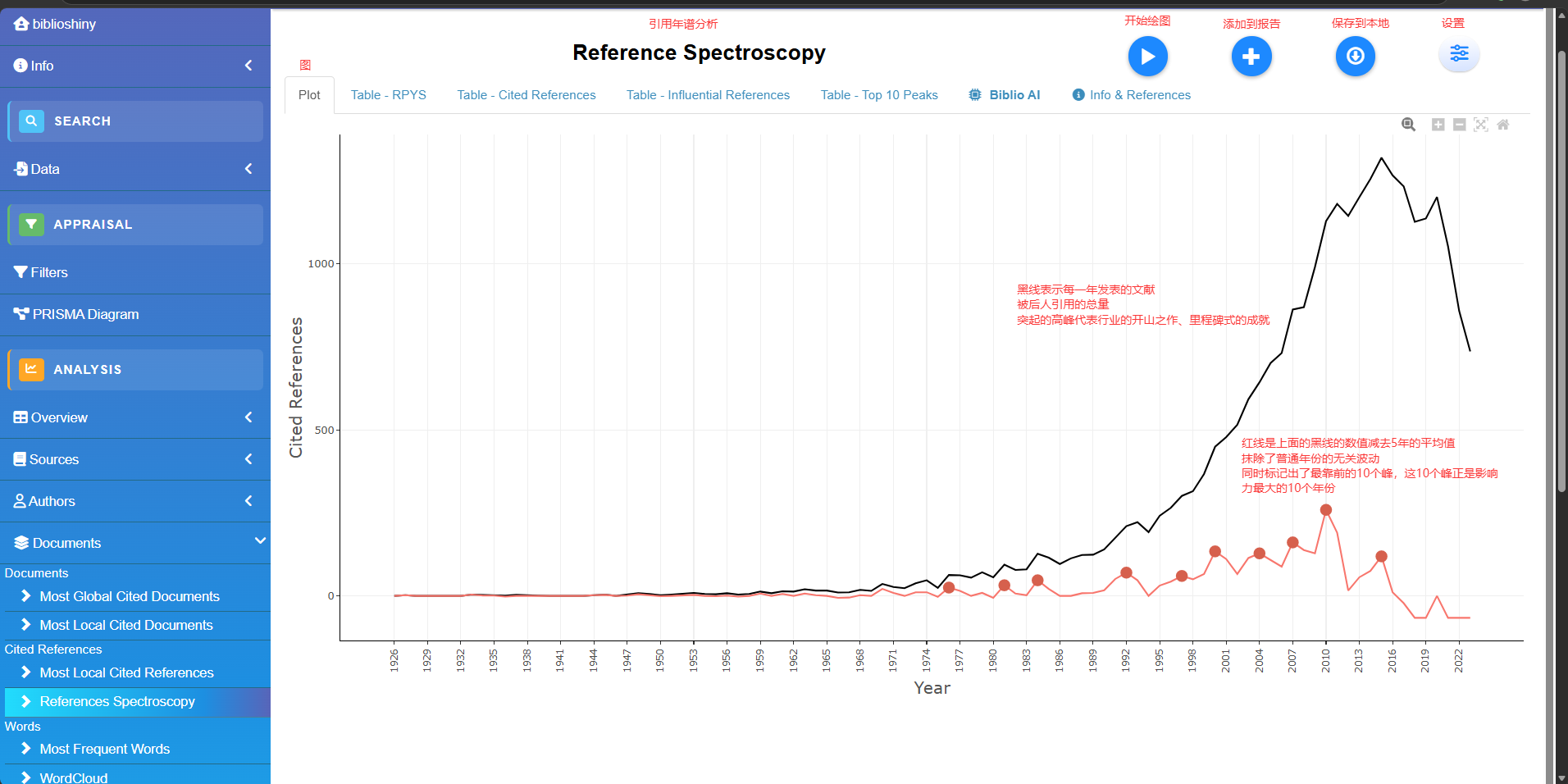
参考文献出版年份光谱分析RPYS
# 1. M : [必填] 标准的文献数据框 (需包含 CR 参考文献列)。
# 2. sep : [可选] 参考文献的分隔符,默认 ";"。
# 3. timespan : [可选] 时间跨度限制,格式如 c(1980, 2020)。默认 NULL (分析所有年份)。
# 4. median.window : [算法关键] 中位数的计算窗口。用于过滤历史增长趋势,突显异常尖峰。
# - "centered" (默认): 使用中心5年中位数 (即 t-2 年到 t+2 年)。
# - "backward": 使用向后5年中位数 (即 t-4 年到 t 年)。
# 5. graph
# 【返回值】
# 返回一个 List,里面不仅包含一张光谱图 (ggplot2对象),还包含三个数据框:
# - 历年绝对被引次数
# - 每一年被引用的具体参考文献列表 (可用于直接去查当年是哪篇牛文制造了尖峰)
# - 按年记录的引用明细
res <- rpys(
M = M_new,
sep = ";",
graph = TRUE
)
head(res$rpysTable)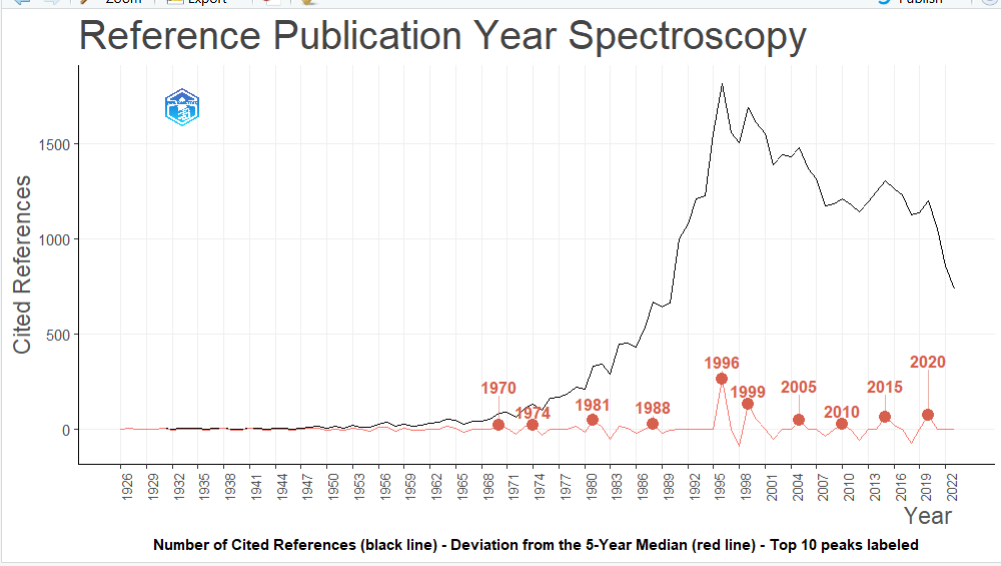
词频字频统计
Tab <- tableTag(
M = M_new,
Tag = "CR", # 想要统计频次的特定字段标签 (如: "CR"为参考文献, "DE"为作者关键词, "AU"为作者等)
sep = ";", # 字段内多个元素的间隔符,默认值为 ";"
ngrams = 1, # 提取的词组长度(1到3)。用于从标题(TI)或摘要(AB)中提取双词或三词短语
remove.terms = NULL, # "黑名单"字典(字符向量)。
synonyms = NULL # "同义词"字典(字符向量)。
)
时间切片
list_df <- timeslice(
M = , # [必填] 标准文献数据框 (由 convert2df 生成)
breaks = NA, # [核心参数] 自定义年份切割点 (数值向量)。
# 例如 c(1995, 2005) 会将数据切分为三个阶段:
# 1. 截止到 1995年; 2. 1996年-2005年; 3. 2006年及以后。
k = 5 # [可选参数] 如果你懒得自己想切分年份,可以直接指定 k=5,
# 系统会自动帮你把总时间跨度等分成 5 份。(注意:如果填了 breaks,k 就会失效)
)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)