从 chat 提速到跨会话记忆——多路召回 + pgvector 用户画像
从 chat 提速到跨会话记忆——多路召回 + pgvector 用户画像
上周末说"下周要做"的两件事:检索 Agent 独立化、个性化总结。这周做完。
起因:按照任务进行工作
翻 week3 博客末尾的"下周要做的",最大的两条是检索 Agent 独立化(cosine + BM25 多路召回 + Cohere Rerank)和个性化总结(pgvector + user_paper_profile)。这周一并交付。
为啥这两件事一定要做。chat 现在是把 paper_text 整篇直接拼进 prompt 喂给 DeepSeek,短论文还行,长论文(我们样本里 5 篇 50k 字符以上)一次烧的 token 不少,LLM 处理长上下文的准确度也会掉。这个事儿不能拖到正式演示前。
跨会话记忆那条更直接,对应项目书原话"长短期记忆 + 个性化推荐"。上周做的 Checkpointer 解决的是会话级——同 conversation_id 内有效;用户开新会话,之前那次会话里 deep_read 的产物全归零。要做"基于你之前读过的 A 和 B 给当前 C 做有针对性的总结",必须有一个跨会话、跨论文的"用户画像",对应项目书原话的下半段。这条不补,14 个 Agent 还差一个。
两件事的关系比表面看更紧。第一件事要求把检索从被动调用升级成独立 Agent 节点,搭好之后第二件事就能直接复用同一套 BGE embedding——所以排在一周里一起做。两件事都靠之前搭的基础设施往前推一步:前者复用 BGE,后者既复用 BGE 又复用 paperagent-postgres 这个容器,再挂一张表。
一、检索 Agent 独立化:cosine + BM25 + Cohere Rerank
把整篇论文塞 prompt 是有现实代价的。23 篇论文里有 5 篇超过 50k 字符(也就是大概 15-20k token),每次 chat 都全文扔给 DeepSeek,单次开销不便宜,长上下文的注意力分散也会让回答变水。理想情况是用户一问问题,先在论文里 retrieve 出最相关的 5-10 段,把这些段塞进 prompt,比塞全文准而便宜。
这件事 RAG 框架已经做过千百次,没什么新鲜的。但有几个细节决定它在我们这个项目里能不能跑顺。
不止 cosine:cosine + BM25 二路召回
ChromaDB + BGE-large-zh 一开始就有,cosine 单路检索写起来直白:
results = self._collection.query(query_texts=[query], n_results=top_k, where={"doc_id": doc_id})
但单 cosine 有个常见漏洞,专有名词。论文里的人名、数据集缩写、模型名(Bumblebee、SiRNN、CKKS)这种 token,BGE 训练语料里没见过,向量化之后跟"普通中文"的相似度差异不明显,cosine 容易召回意思相近但不点中关键词的段落。这种情况 BM25 反而稳——它是基于词频的稀疏检索,关键词命中分数立刻拉高。
所以加了一路 BM25。rank-bm25 是个零外部依赖的纯 Python 包,5 行能用:
from rank_bm25 import BM25Okapi
corpus_tokens = [tokenize_zh_en(d) for d in docs] # 中英混合分词
index = BM25Okapi(corpus_tokens)
scores = index.get_scores(query_tokens)
ranked_idx = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)[:top_k]
中文分词这一步纠结了一下。jieba 准但要装词典;纯字符级 token 化简单但召回率差一截。最后选的是混合方案——汉字逐字独立 token,英文按空格切。这个决策完全是 MVP 取向,等以后真要做大规模检索再换 jieba。
def tokenize_zh_en(text: str) -> list[str]:
"""混合分词:每个汉字独立 token,英文按空格切。"""
tokens, buffer = [], ""
for ch in text:
if "一" <= ch <= "鿿":
if buffer.strip():
tokens.extend(buffer.split())
buffer = ""
tokens.append(ch)
else:
buffer += ch
if buffer.strip():
tokens.extend(buffer.split())
return [t for t in tokens if t]
实测下来对学术论文常见的英文专有名词(attention、transformer、ResNet 这种)召回率比纯字符级高一截。中文部分逐字 token 在我们的论文场景没出过准确率问题——学术中文很少出现需要切词才能区分语义的句子,模型缩写、数据集名、人名几乎都是英文。
两路结果 union 之后按文本前 200 字 dedup(同一段不同分数下不重复):
def _union_dedup(*lists):
seen, merged = set(), []
for lst in lists:
for item in lst:
key = item.get("text", "")[:200]
if key in seen:
continue
seen.add(key)
merged.append(item)
return merged
dedup 用前 200 字而不是全文 hash,是因为 chunk_overlap=100 会让相邻 chunk 头部有重叠,全文 hash 反而错过去重。前 200 字够区分。
BM25 索引按 doc_id 缓存
每次 query 重新建 BM25 索引太蠢——一篇 50k 字符的论文 ~50 个 chunks,建索引 30-50ms。设个按 doc_id key 的 module-level 字典缓存,第二次 query 直接拿:
class _BM25IndexCache:
def __init__(self):
self._cache = {}
def get_or_build(self, doc_id, rag_service):
if doc_id in self._cache:
return self._cache[doc_id]
# ... 从 ChromaDB 取该 doc_id 的所有 chunks,建索引,缓存
23 篇论文 × ~50 chunks 整个项目内存常驻 < 50MB,可以接受。如果有一天论文上千篇,再换成 LRU。
当前的实现还有一个轻微的并发隐患——_cache 是 module-level dict,多请求并发时 get_or_build 没加锁,理论上同一 doc_id 第一次访问可能被两个线程同时进入然后 build 两次。FastAPI 在 sync endpoint 下默认走线程池,这个场景是真的存在。但代价只是多 build 一次(结果覆盖时同样的索引),没数据正确性问题,所以没加锁。等真的有性能问题再说。
Cohere Rerank:第三道关,但可选
cosine + BM25 union 之后是最多 20 段候选,但 LLM 一次塞不下也不该塞那么多。Cohere 的 rerank API 是行业里"小而专"的代表——给它 query + N 段候选,它返回 top-K 重排序,准确度比纯向量好不少。
class RerankService:
def rerank(self, query, documents, top_n=5):
if not self.enabled:
return documents[:top_n] # 兜底
try:
resp = self._client.rerank(
model="rerank-multilingual-v3.0",
query=query, documents=[d["text"] for d in documents],
top_n=top_n,
)
return [documents[r.index] for r in resp.results]
except Exception as exc:
logger.warning("rerank failed: %s", exc)
return documents[:top_n]
跟 SP8 Checkpointer 学来的同一个 enabled flag 模式:COHERE_API_KEY 缺失或 SDK 调用失败,直接返回未重排的前 5 条。准确度差一点但能跑——演示日如果 key 还没申请下来,整个链路也不会断。这个决策这周第二次复用 enabled flag,已经成肌肉记忆了。
rerank-multilingual-v3.0 是 Cohere 的多语模型,专门为跨语言场景训过——我们论文有纯英文的(USENIX Security 那批)也有中英混合的(部分 NeurIPS 投稿带中文摘要),单一语言模型在跨语言场景下分数会偏。多语模型省了一层语言判定。
retriever 节点接进 LangGraph
新建 agents/nodes/retriever.py,约 50 行:
def retriever_node(state, rag_service=None, rerank_service=None):
query = state.get("user_query", "")
doc_id = state.get("document_id")
if not query or rag_service is None:
return {"retrieved_chunks": []}
candidates = multi_recall.search(query, doc_id, rag_service, top_k_per_path=10)
if rerank_service is not None and rerank_service.enabled:
candidates = rerank_service.rerank(query, candidates, top_n=5)
else:
candidates = candidates[:5]
return {"retrieved_chunks": candidates}
LangGraph 主图加一条边——chat / extract intent 走 router → retriever → qa(之前是直接 router → qa)。qa_node 改一行:
context = "\n---\n".join(c["text"] for c in state.get("retrieved_chunks", []))
if not context:
context = state.get("paper_text", "") # 兜底
顺带挪了一处旧代码:原来 hallucination_checker_node 内部自己也调 rag_service.retrieve 单路 cosine 检索做 Self-RAG 校验。这次顺手把它也改成调 multi_recall.search(top_k_per_path=3 等价原行为),算是 DRY——以后改检索逻辑只动一处。
前端 timeline 这边一行不用改,只往 agents/node_metadata.py 加了一条 retriever 元数据(icon Search,title “检索”)。SSE 协议自动把这个节点当一个独立 chip 渲染。chat 模式下用户看到的 timeline chip 流从原来的 路由分类 → 问答 变成 路由分类 → 检索 → 问答同时我们的整个全体agent的配合也逐渐实现流程,下面是我们的一个测试现状:
信息提取多了检索这个先前步骤:
整体全流程配合: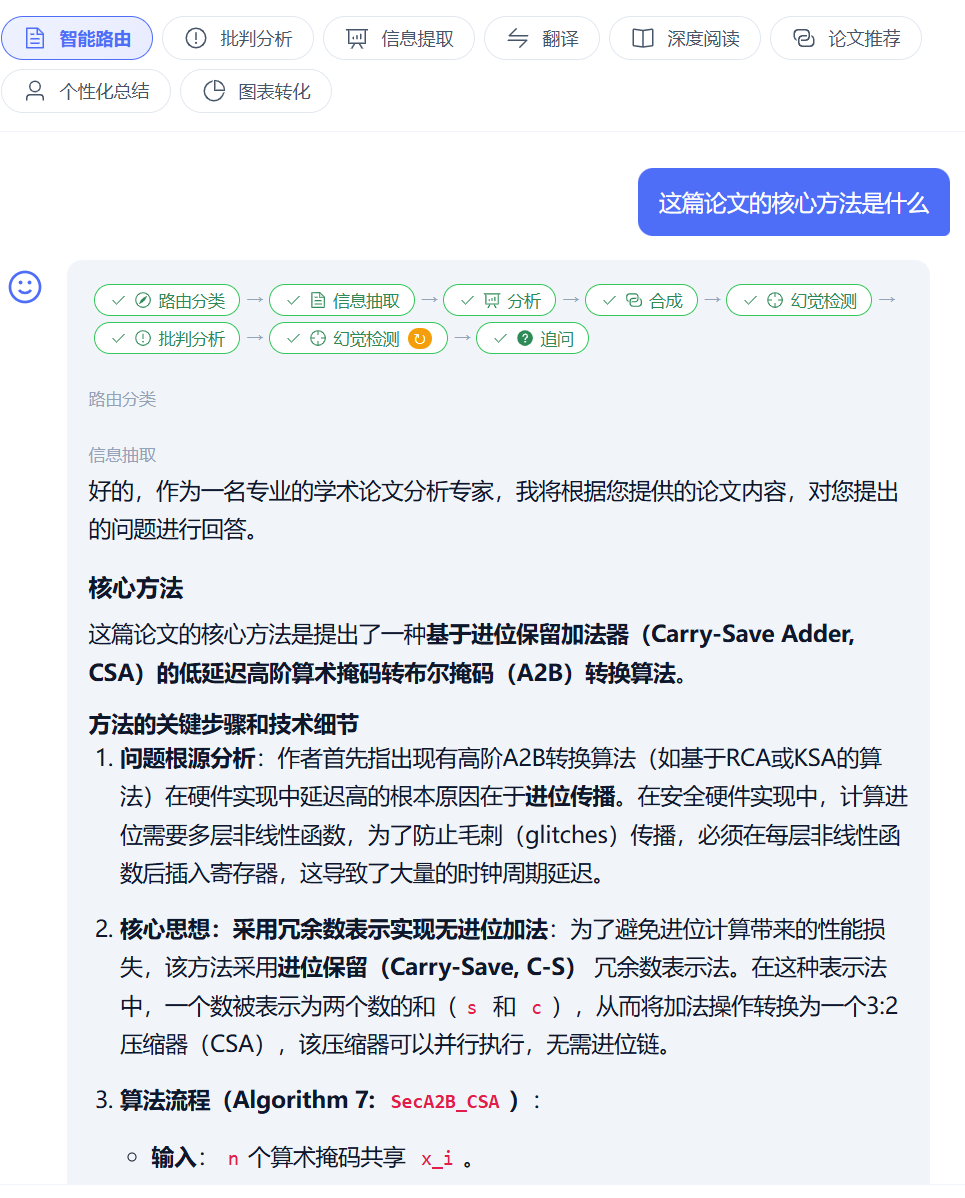
节省了多少 token
实测一篇 84k 字符的论文,问"这个方法的核心思想是什么":
- 之前:paper_text 原样塞 prompt → 输入约 22k token
- 现在:top-5 chunks 每段 500 字 → 输入约 1500 token
约 14× 缩减。对 DeepSeek 这种按 token 计费的接口,长论文 chat 一天下来能省一壶咖啡钱。回答质量我用同一个问题对比了几次,retriever 路径准确度跟全文路径基本持平,没看出明显退化——但只要 query 命中 chunks 没问题就行。
跑同一个问题的 LLM 响应延迟也差一截:全文路径首 token 等了 4-5 秒(DeepSeek 要先吃完 22k token),retriever 路径首 token 1 秒内出。这个体感比 token 省钱更直观——用户能明显感觉到"这次问完很快就开始打字了"。
二、让"读过哪些论文"变成长期记忆
第二件事是项目书"长短期记忆"的下半段。Checkpointer 是会话级——同一个 conversation_id 内有效;如果用户开新会话,之前那次会话里 deep_read 的产物全归零。如果想做"基于你读过的所有论文给当前论文做个性化总结",必须有一个跨会话、跨论文的"用户画像"。
最自然的实现就是 pgvector:用户每次让 Agent 处理一篇论文,把这篇论文的 embedding + 摘要 + read_at 时间戳写进一张表,下次新论文进来时按 cosine 检索 top-3 相似的历史阅读,喂给 LLM 拼"你之前读过 A 和 B,本文相比侧重在……"
pgvector 镜像替换:数据无损迁移
我们已经有 paperagent-postgres 容器(SP8 用它存 LangGraph state,登录系统也用它)。要启用 pgvector 扩展,最快的路是把镜像 postgres:15 换成 pgvector/pgvector:pg15——后者是官方维护的 pg15 + vector 扩展预装版本,跟 postgres:15 数据卷完全兼容。
# docker-compose.yml
paperagent-postgres:
image: pgvector/pgvector:pg15 # 改这一行
...
docker compose up -d paperagent-postgres 重建容器,原数据卷 ./data/pg_paperagent 不动。SP8 的 checkpoint_* 4 张表、auth 系统的 users / refresh_tokens 全部完整保留。
启动后跑:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS pgcrypto;
由 UserProfileService.init_db() 启动时 idempotent 执行。
一个第一次见的报错:collation 版本不匹配
新镜像启动后 psql 抛了个 warning:
WARNING: database "paperagent" has a collation version mismatch
DETAIL: The database was created using collation version 2.41,
but the operating system provides version 2.36.
旧镜像(postgres:15)和新镜像(pgvector/pgvector:pg15)虽然都是 Debian 基底,但 glibc 版本不同——前者 2.41,后者 2.36。glibc 不同时 collation 会被 PostgreSQL 校验为不匹配。一行 SQL 解掉:
ALTER DATABASE paperagent REFRESH COLLATION VERSION;
排序、文本比较都不会出错,但记一下下次别慌。
user_paper_profile 表
CREATE TABLE IF NOT EXISTS user_paper_profile (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_id UUID NOT NULL,
doc_id TEXT NOT NULL,
title TEXT,
summary TEXT,
embedding VECTOR(1024),
read_at TIMESTAMP DEFAULT NOW(),
UNIQUE (user_id, doc_id)
);
CREATE INDEX IF NOT EXISTS idx_user_paper_user
ON user_paper_profile(user_id);
CREATE INDEX IF NOT EXISTS idx_user_paper_embedding
ON user_paper_profile USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 50);
几个决策:
(user_id, doc_id) 唯一约束加 UPSERT——用户重复读同一篇论文时不要新增一行,更新 read_at 时间戳即可。
embedding VECTOR(1024) 对应 BGE-large-zh-v1.5 的输出维度。直接复用上一节 SP9 的 RAGService 的 _embedding_fn,不再起新模型。这一步是这周做的最爽的一处复用——同一个加载好的 sentence-transformers 模型同时给 ChromaDB(论文 chunk 检索)和 pgvector(用户画像)当 encode 接口。
USING ivfflat (embedding vector_cosine_ops) WITH (lists = 50) 是 pgvector 的 ANN 索引。lists=50 在数据量小(< 100 条)时偏多,但功能上不影响 cosine 正确性。等画像积累到几千条再调。
UserProfileService
整个 service 写下来 200 行,结构跟 SP9 的 RerankService 几乎一样——一个 enabled flag,初始化失败默认 False,所有方法都先查 enabled 再走真逻辑:
class UserProfileService:
def __init__(self, rag_service=None):
self.enabled = False
self._rag = rag_service
self._url = _convert_url_to_psycopg(os.getenv("POSTGRES_AUTH_URL", ""))
if not self._url or rag_service is None:
return
if self.init_db():
self.enabled = True
enabled 默认 False 是为了让"任一前置条件没满足"都自然走兜底。失败场景列下来六七种:环境变量缺、rag 不可用、pgvector 扩展启不来、user_id 空、user_id 不是合法 UUID、用户画像表里没东西。每一种都返回"看起来正常的输出",节点上层不需要 try/except 一圈。
ingest 是节点 finalize 阶段调的——节点跑完拿到一段 LLM 总结之后,把 (user_id, doc_id, title, summary, embedding) UPSERT 进表:
def ingest(self, user_id, doc_id, title, summary):
if not self.enabled or not user_id:
return False
try:
emb = self._rag._embedding_fn([summary])[0] # 1024 dim
with psycopg.connect(self._url) as conn:
register_vector(conn)
conn.execute("""
INSERT INTO user_paper_profile (user_id, doc_id, title, summary, embedding)
VALUES (%s, %s, %s, %s, %s)
ON CONFLICT (user_id, doc_id) DO UPDATE
SET summary = EXCLUDED.summary,
embedding = EXCLUDED.embedding,
read_at = NOW()
""", (user_id, doc_id, title, summary, emb))
return True
except Exception as exc:
logger.warning("ingest failed: %s", exc)
return False
similar_papers 的查询走 cosine 距离 <=>,这是 pgvector 提供的运算符:
rows = conn.execute("""
SELECT doc_id, title, summary, 1 - (embedding <=> %s) AS score
FROM user_paper_profile
WHERE user_id = %s AND doc_id != %s
ORDER BY embedding <=> %s
LIMIT 3
""", (query_emb, user_id, current_doc_id, query_emb)).fetchall()
<=> 是 pgvector 的"cosine 距离"运算符,距离越小越相似,所以 1 - 距离 是相似度分数。doc_id != %s 排除当前正在读的论文本身(防止 LLM 看到"你之前读过 X,这次读 X"这种废话)。
节点:has_history / no_history 双分支 prompt
personalized_summary_node 拉历史 top-3,根据是否拿到走两个 prompt 模板:
<HAS_HISTORY>
用户之前读过的相关论文:
{{#history#}}
请重点说明本论文与已读论文的关联...
</HAS_HISTORY>
<NO_HISTORY>
(这是用户首次记录的论文阅读,按结构化导读模板进行总结。)
</NO_HISTORY>
后端用字符串处理切到对应分支,没引 Jinja。30 行的 _strip_block 函数搞定。模板引擎本来是"以后再上"的备选,这次发现纯字符串处理在两分支场景下足够清晰。等真的要 A/B 测试 prompt 时再换。
user_id 链路:还了 week2 那笔账
这次 SP10 顺手补了一条欠了两周的账。week2 博客里我写过这么一段:“节点本身这周还不用读 user_id,但字段通道打通了。下一步做个性化记忆可以直接挂在这个字段上。”——当时是在 paper_metadata 里搭了个 user_id 字段做样子。两周过去这件事拖到现在,因为没有节点真的需要读它。这次 personalized_summary 必须按用户隔离画像,链路才真的不能再敷衍。
四步改动:
api/routes/agents.py把dependencies=[Depends(get_current_user)]换成显式形参current_user: User = Depends(get_current_user),函数体里能拿到current_user.idorchestrator.route(...)增user_idkwarglanggraph_engine.run_graph(...)把 user_id 写进initial_state- 节点从
state.get("user_id")读
中间一处代价是 SP5 写的 SSE 测试 fixture 用 lambda: {"user_id": 1, "username": "test"} 模拟 user,dict 没有 .id 属性,回归挂了。改成轻量 _FakeUser 类,FakeOrch.route 加 user_id=None kwarg 才回归全绿。这种链路改动经常会牵出"看似无关"的测试失败,做的时候心里要有数。
演示效果
跑两次 personalized_summary 同一用户、不同论文。
第一次(首次阅读)输出大致:
## 一、与你过往阅读的关联
这是你首次记录的论文阅读。
## 二、研究背景与动机
...
第二次(用户已有 1 篇画像):
## 一、与你过往阅读的关联
你之前读过的《Attention Is All You Need》主要讨论了 Transformer 的自注意力机制。
本论文相比侧重在...
## 二、研究背景与动机
...
DB 里 SELECT user_id, doc_id, title, read_at FROM user_paper_profile; 看到对应两行。手动 docker stop paperagent-postgres 之后再点一次 personalized_summary,节点照样返回但走"首次阅读"分支,前端没崩——兜底矩阵奏效。
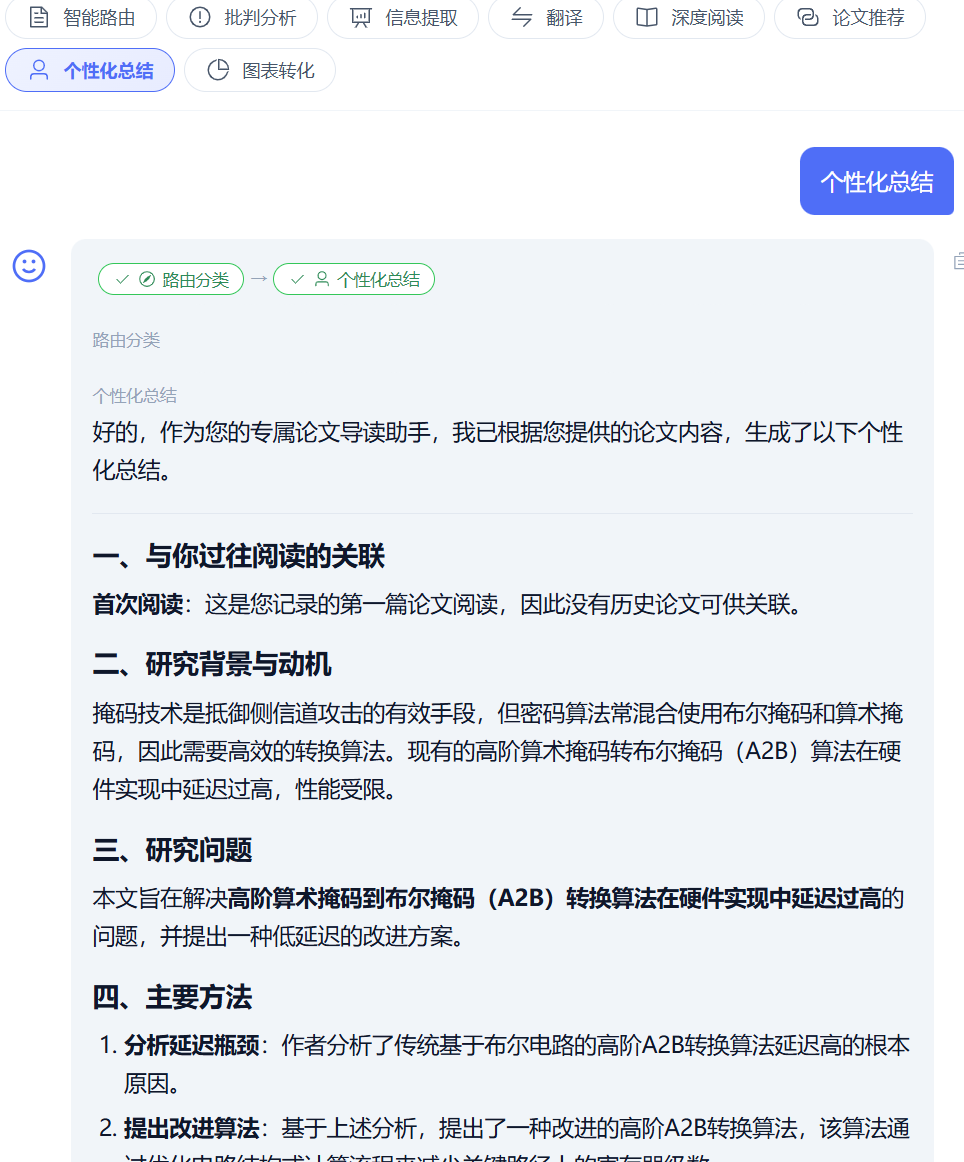
首次输入时显示没有读过,因为先前没有加上这个功能,默认关闭。
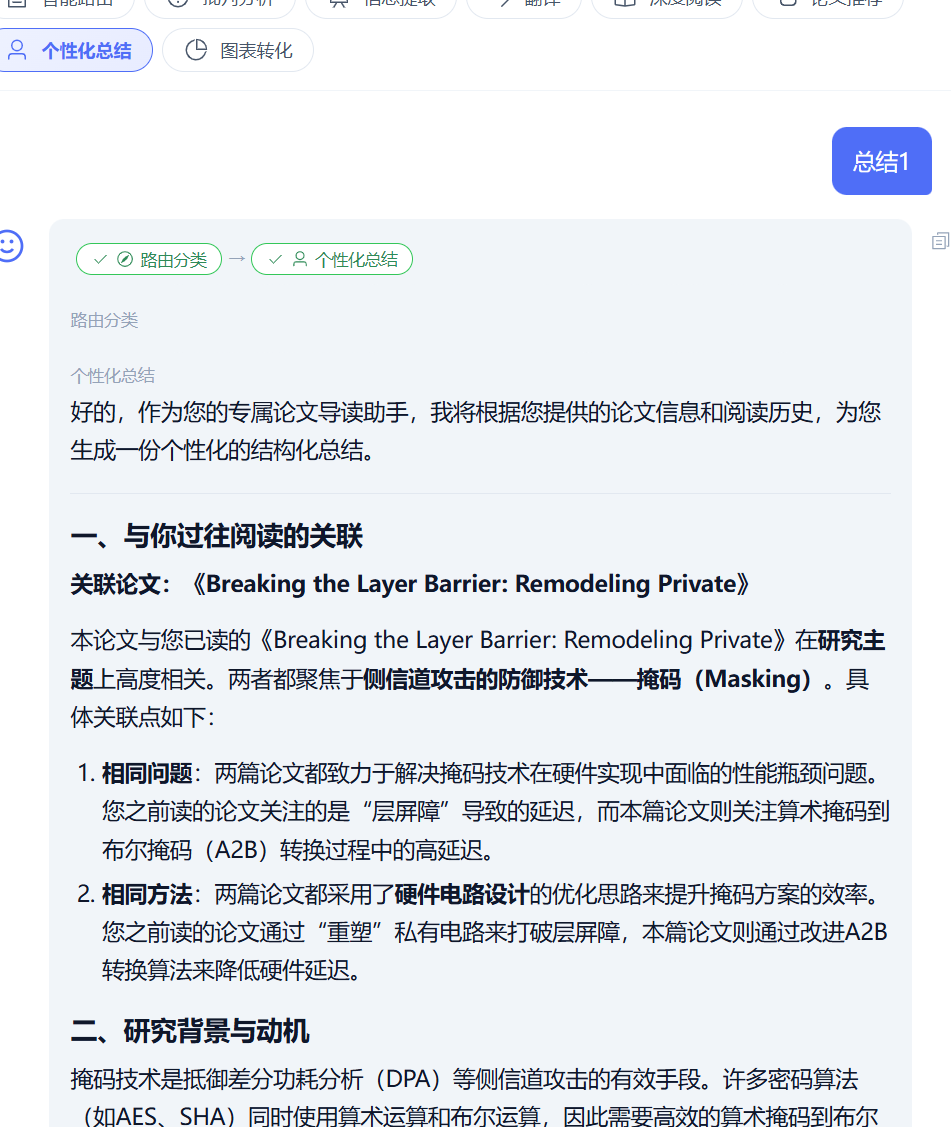
可以看到实现了我们的关联阅读,用户画像期间还解决了一些bug,后续bug阶段说明。
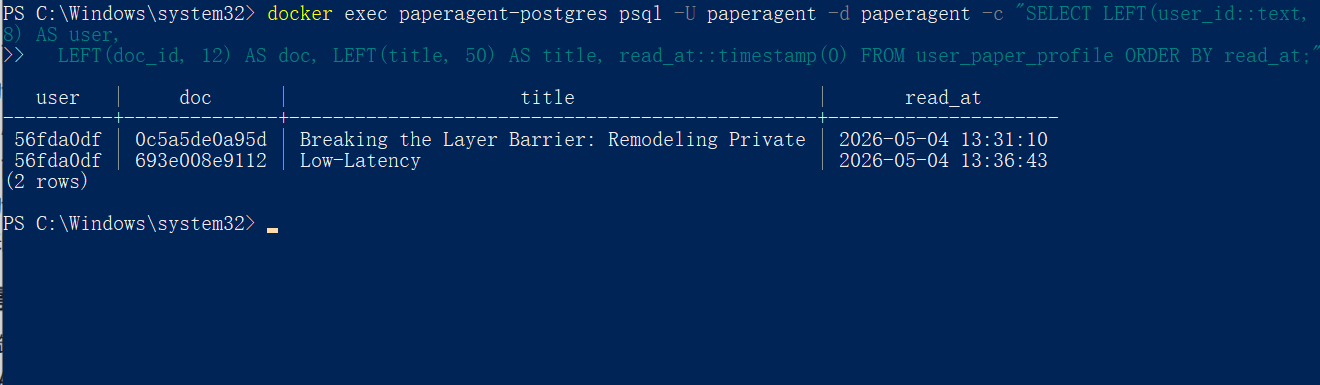
这里可以看到我们的sql里面正常记录了,所以确实记录了用户画像。
三、两件事怎么互相借力
回头看这周做的事,全是在上周搭的东西上接出口。
SP9 的 retriever 节点直接吃 ChromaDB 已有的 BGE 论文 chunks,不动 ingest 流程。
SP10 的 user_paper_profile 表接的是 SP8 时已经搭好的 paperagent-postgres 容器,再挂一张表;BGE encode 直接调用 SP9 的 rag_service._embedding_fn,不再起新模型;URL 转换函数 _convert_url_to_psycopg 是 SP8 写的;orchestrator 的 enabled flag 模式是 SP8 写的;prompt 双分支思路从 SP11 那个 emoji verdict 借的。
复用最直接的好处是新代码量小、新出 bug 的面也小——这周新写的逻辑里没有新引入的依赖(pgvector 只是已有 postgres 加了个扩展),没有新的连接池、没有新的鉴权机制、没有新的序列化协议。所有"新"的部分都跟着既有代码的运行模式走。
测了哪些
两件事加起来 30 个新单测,全 fake,不连真 ChromaDB / Cohere / pgvector / S2 真实链路。
- multi_recall:分词、仅 cosine 路径、union dedup、两路全失败(4 个)
- rerank_service:disabled、空输入、mock cohere 成功、API 失败兜底(4 个)
- retriever_node:无 rag、空 query、完整流水线、selected_text 优先(4 个)
- user_profile_service:enabled flag、UUID 解析、ingest disabled、similar_papers 各种空、has_history(10 个)
- personalized_summary_node:service None / 空历史 / 含历史 / 空 user_id / disabled service / 流式输出 / 模板渲染(8 个)
跑 pytest tests/test_rerank_service.py tests/test_multi_recall.py tests/test_retriever_node.py tests/test_user_profile_service.py tests/test_personalized_summary_node.py -v 全绿。整套 79 个单测全绿,回归没破。
踩过的坑
register_vector(conn)必须在 cursor execute 之前调,不然 pgvector 的类型适配器没注册,写入时会抛cannot adapt type list。文档里有但混在 import 一坨示例里很容易漏。- pgvector 的 ivfflat 索引在数据量 <
lists时不会用索引,会做全表扫——这不是 bug,是设计。所以建表初期搜索其实还是 sequential scan,等画像积累到 500+ 行才会真正走索引。 - BGE encode 是 IO + GPU 操作,第一次
_embedding_fn(["test"])要 1.3 GB 模型加载,启动后端时如果 lazy 路径走通会很慢——所以 RAGService 是懒加载的,第一次访问_embedding_fn才触发。 - BM25 的
get_scores(query_tokens)返回的是 numpy array,写测试时直接拿来 max() 会得到 numpy float64 不是 Python float。assert 比较时要float(scores[i])转一下。 - SP5 SSE 测试 fixture 用 dict mock current_user,加 user_id 链路后挂回归。改 fixture 是必走的,不要试图用
getattr(current_user, "id", current_user.get("id"))这种"两边兼容"的 hack——hack 多了将来更乱。 app.dependency_overrides[get_current_user]这个 FastAPI 的 dep override 在 fixture 里用完要app.dependency_overrides.clear(),不然下个 test 会继承上一个的 override。- pgvector 容器换镜像后第一次写入抛了一次
ERROR: type "vector" does not exist——因为 service 启动顺序里init_db()先建表后建扩展,对调一下顺序(先CREATE EXTENSION再CREATE TABLE)解决。
测试时候的bug
代码侧测试全绿、commit 也都干净,但真正打开浏览器跑端到端的时候,一个不缓和的事实出现了:链路从 API 一直串到LLM,每一层都有自己的隐式契约,单测覆盖不到的地方在演示日全暴露了。按追到的顺序记一下。
第一个:前端点"个性化总结"按钮,timeline 出来的 chip 流是 路由分类 → 检索 → 问答,不是预期的 路由分类 →个性化总结。看着像路由没走,实际是 router 节点里的白名单 _VALID_INTENTS 当时只列了 chat / critical / verify_sources等老 intent,新加的 personalized_summary 和 extract_charts 漏注册。前端虽然把 forced_intent 传过来了,但 router第 36 行 if forced and forced in _VALID_INTENTS 一查发现不在里面,直接忽略,回退到让 LLM 判 intent,结果被判成chat。修法是补两行白名单,但教训是:新增 intent 时所有 enum/whitelist/mapping 都得同步改,不能只改_route_by_intent 一处。
第二个:路由对了,节点跑通了,HTTP 200,可 user_paper_profile 表始终 0 行——ingest 像没发生过。打 log 才发现_encode 函数里用 if not vec or not vec[0] 判 BGE 返回值,但 vec[0] 是个 numpy ndarray,对它做布尔判断会抛ValueError: The truth value of an array with more than one element is ambiguous。这条异常被外层 try/except 吞掉返None,ingest 静默返 False,所有写入都被跳过。改成 len(vec) == 0 or len(vec[0]) == 0 显式判长。经典教训:不要写"对list / array 都管用"的写法,明确写 is None 或 len() == 0。
第三个:终于写进去了,但表里 title 字段0c5a5de0a95d414197967a75d414cf0e 这样的 doc_id字符串,不是论文真实标题。原因是 orchestrator 构造 LangGraph 入参时,paper_metadata 只塞了 {"forced_intent": agent_name},没有把LocalPaperStore.load(doc_id) 拿到的 title / filename 透传过去。节点里的 title 解析有四级fallback paper_metadata.title → paper_metadata.filename → doc_id → "当前论文",前两级都空,掉到 doc_id。修法是orchestrator 把 paper_data 里的 title / filename 也塞进 paper_metadata。
第四个有点哭笑不得。我为了排查上面那些问题,往节点函数里加了几条 logger.info(...)调试日志。结果重启后端再跑——整图直接 fallback 到 legacy,前端看到"未知的智能体模式: personalized_summary"。看 uvicorn日志:LangGraph 执行失败,降级到 Legacy: name 'logger' is not defined。agents/nodes/personalized_summary.py模块顶部根本没写 logger = logging.getLogger(__name__)——之前没用过 logger 所以没漏出来,加了第一行 logger.info 就抛NameError,被 orchestrator 的 try/except 接住降级。为了 debug 写的代码自己制造了新 bug,又花了五分钟。补一行import + getLogger 解决。
第五个最有意思。前面四条全修完,再跑一次:表里 2 行真历史similar_papers 召回 1 行(cosine score 0.38)、节点 debug log 显示 service_ok=True / similar_papers returned 1 rows、prompt 模板渲染我也直接 dump 出来检查过——HAS_HISTORY段确实被保留、Low-Latency 这个真历史标题确实被注入。可 LLM 输出第一节还是写的"首次阅读,这是您首次记录的论文阅读"。定睛看 prompt 模板才发现:模板末尾的"输出指令"那一节里有这么一行——“若有历史论文,明确指出 1-2篇关联论文及关联点;若无历史则跳过此节并注明’首次阅读’”。这条指令无条件出现在最终 prompt 里,不管 has_history是 true 还是 false。LLM 看到上面 HAS_HISTORY段填了真历史,但下面又看到"若无历史则注明首次阅读"这种模板规则,它把规则当规则执行,覆盖了上面给的实际数据。修法是把这条指令也分到 HAS_HISTORY / NO_HISTORY 两个互斥块里,并且 HAS_HISTORY块明确写一句"不允许在有历史的情况下输出’首次阅读’"。
总结 这一连串 bug 让我意识到一件事:prompt 也是协议。代码层的契约——函数签名、字段名、返回类型——开发者会本能地小心,但prompt 模板作为"LLM 的契约"经常被随手写。前面四条 bug 都是代码契约层面,单测能覆盖;最后一条是 prompt契约层面,单测覆盖不到(你测的是模板渲染对不对,不是 LLM 解读对不对)。这条以后写新节点时要专门注意:prompt里出现的任何指令性句子都要确保在所有数据分支下都自洽,不能写一条"看上去通用"的兜底句子,那种句子在边角分支里就是bug。
下周要做的
- 推图表智能转化(SP12,最大头,需要 vision 模型,等用户申请 API key)
- 把
_convert_url_to_psycopg从 checkpointer.py 挪到 services 公共目录(DRY,已经被复用两次) - 给
personalized_summary加一个用户侧反馈按钮(这次推荐有用 / 没用 → 调权重)
小结
这周交付的两件事各自独立但互相成全。SP9 让 chat 路径从"整篇灌"升级成"按需召回",长论文场景的 token 成本和响应延迟都掉了一大截,并且把检索这一层从 hallucination_checker 内部偷偷调用提升成了 LangGraph 主图里有自己 chip 的独立节点——这意味着以后任何节点想用检索,都从 multi_recall.search 一处统一接入,不会再有第二处 ad-hoc 实现。
SP10 把项目书"长短期记忆 + 个性化推荐"那一行的下半段补齐了。Checkpointer 是会话级(同一个 conversation 内对话连续),user_paper_profile 是用户级(跨会话跨论文记得用户读过哪些)。两层记忆叠在一起就构成项目书要求的"长短期"双层结构,不再是平面的对话历史。
到这周结束 还差一个复杂的agentSP12 图表智能转化。它需要 vision 模型支持,等 API key 申请下来就动手,可以适当清理冗余,对接队友工作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)