Agent工具调用中的错误处理 重试机制&降级处理
重试机制
重试机制(Retry) 是一种软件设计模式,它允许系统在检测到某个操作失败时,按照预定义的策略(如次数、间隔时间等)自动重新尝试执行该操作,提高容错能力并保障系统的稳定性。
详细内容可阅读tenacity文档
为什么需要重试机制
在设计agent时我们往往会调用外部api,在这个过程中往往很出现很多"暂时性"错误
-
网络抖动:包括连接超时、路由器临时阻塞、服务器无响应等等
-
api临时超时:目标接口瞬间负载过高报错,api调用的请求频率到达供应商限制等等
-
llm错误:llm输出格式不对导致解析失败
以上这些错误都是暂时性的,设计Retry的目的就是为了让模型自动重试处理这些错误而不需要人工处理;如果没有重试机制,那么任何微小的网络波动都会导致前端直接弹窗报错,迫使任务中断,每次中断都需要用户重新手动输入上一个问题,大大影响用户体验。
常见的重试策略有
-
立即重试:在发生错误后立即发起重试
-
等间隔重试:在发生错误后等待固定间隔(如2s)再发起重试
-
指数退避:每次错误发生后等待时间翻倍(1s,2s,4s),这样做能够缓解服务器压力
-
最大次数限制:设置重试上限(比如5次),防止死循环浪费token
Langchain内置重试RetryWithErrorOutputParser
RetryWithErrorOutputParser专门用于解析失败时的重试——当 LLM 输出格式不符合预期时,自动将错误信息传回给模型,让其重新生成。
from langchain.output_parsers import PydanticOutputParser
from langchain.output_parsers import RetryWithErrorOutputParser
parser = PydanticOutputParser(pydantic_object=MyModel)
retry_parser = RetryWithErrorOutputParser(
parser=parser,
retry_chain=llm,
max_retries=3
)
# 当解析失败时,会自动将错误信息发给 LLM 要求重新生成
result = retry_parser.parse_with_retry(bad_llm_output)参数:
-
parser:解析器,用于解析输出结果
-
max_retries:解析失败后尝试重新解析的最大次数
-
retry_chain:重试链,让这个chain重新尝试生成(补全)内容(retry_chain可以包含数据处理+Prompt + LLM + OutputParser 的完整组合)
tenacity 库——重试策略
tenacity 是 Python 生态中最流行的通用重试库。它通过装饰器(Decorator)的方式,让你能以极简的代码为任何可能失败的函数增加强大的重试逻辑
-
重试几次
-
重试等待时间(固定 / 指数退避)
-
什么错误才重试
-
重试失败后做什么(降级)
-
重试时打印日志
-
停止条件
安装tenacity库
pip install tenacity
基本格式
@retry(重试逻辑条件)
def do_something_unreliable(参数):
函数逻辑
return
基础重试
@retry
def never_gonna_give_you_up():
print("Retry forever ignoring Exceptions, don't wait between retries")
raise Exceptionraise Exception是一个触发器,在程序没有出错时我们在这里主动抛出一个错误,目的是观察重试策略。
在没有任何重试逻辑参数的条件下,retry默认进行无限次、无间隔的重试。
重试逻辑参数
stop:重试停止条件
-
stop=stop_after_attempt(5):在尝试5次过后放弃
-
stop=stop_after_delay(10):最多重试10秒
-
stop=(stop_after_delay(10) | stop_after_attempt(5)):组合条件,最多尝试5次和最多重试10秒
wait:重试等待策略
-
wait=wait_fixed(2):每次重试都等待2s,避免快速轮询
-
wait=wait_random(min=1, max=2):加入随机值,重试时间在1到2s内取值
-
wait=wait_exponential(multiplier=1, min=4, max=10):指数退避,min规定了最小重试时间,max规定了重试时间上限,当多个进程争夺共享资源时,指数级增长有助于减少碰撞。
-
wait=wait_random_exponential(multiplier=1, max=60):随机指数退避,在0到2^{重试次数-1}之间选择一个随机数,同时确保这个随机数不能大于60
retry:什么情况下需要重试
-
retry=retry_if_exception_type(IOError):只有当出现IOError这类错误时才会重试
-
retry=retry_if_exception_type((TimeoutError, ConnectionError)):只重试这两类错误
-
retry=retry_if_not_exception_type(ClientError):除了ClientError其他错误都重试
reraise:错误处理
-
reraise=True:如果你想在控制台的最后一行看到你的报错信息(Exception: 原始错误信息)而不是在中间部分,那么你就把reraise设置为True
before_sleep:在报错过后打印日志记录
-
before_sleep=before_sleep_log(logging.getLogger(), logging.WARNING):在每次重试等待之前,自动记录一条警告级别的日志,让你能够追踪重试的发生时间和原因
import logging
import sys
#日志配置
logging.basicConfig(stream=sys.stderr, level=logging.DEBUG)
logger = logging.getLogger(__name__)
@retry(stop=stop_after_attempt(3),
before_sleep=before_sleep_log(logger, logging.DEBUG))
def raise_my_exception():
raise MyException("Fail")
中间件ToolRetryMiddleware
ToolRetryMiddleware是Langchain中专门为工具调用创建的中间件
-
ToolRetryMiddleware默认是指数退避
-
范围:只对 Agent 的 tools 生效,不影响节点 / LLM 调用
-
配置:在创建 Agent 时全局注册,作用于全部或指定工具
-
能力:指数退避、jitter、按工具过滤、重试后返回 ToolMessage 等
具体参数
-
max_retries:最大重试次数
-
tools:可选工具列表,应用于重试逻辑
-
retry_on:对某一组错误类型进行重试
-
backoff_factor:重试时间倍数,跟multplier作用相同
-
initial_delay:第一次重试前的延迟
-
max_delay:两次重试之间的最大延迟
-
jitter:是否加入随机抖动
代码示例
from langchain.agents.middleware import ToolRetryMiddleware
# 工具A:网络API,重试3次、指数退避
retry_api = ToolRetryMiddleware(
max_retries=3,
backoff_factor=2.0,
initial_delay=1.0,
tools=["search_api"] # 只给 search_api 用
)
# 工具B:本地脚本,只重试1次、固定延迟
retry_local = ToolRetryMiddleware(
max_retries=1,
backoff_factor=0, # 固定延迟
initial_delay=0.5,
tools=["local_script"] # 只给 local_script 用
)
# 工具C:支付类,完全不重试(不加入任何中间件)
agent = create_agent(
tools=[search_api, local_script, payment_tool],
middleware=[retry_api, retry_local] # 两个中间件并行
)降级策略
降级策略是工具经过多次重试仍然失败,不再继续报错、不再卡死流程,主动启用兜底方案,保证整个 Agent 任务能继续往下走的方法。它是重试多次不成功后的保险方案,也是在主要功能无法使用时使用简要功能或者牺牲一部分性能的权宜之计。
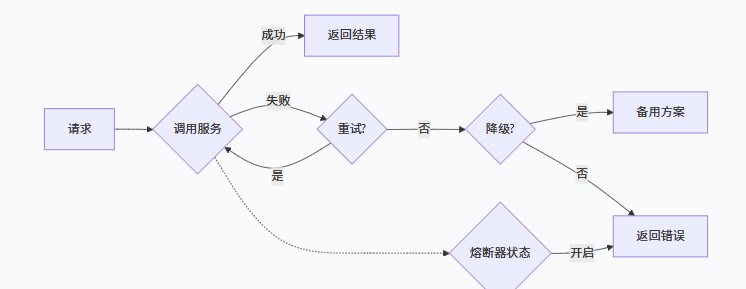
在agent中,我们通常依赖很多外部服务:api调用(失败)、搜索引擎(超时)、数据库(限流),每一个外部服务都存在相应的潜在问题,路径上某一个部分出了问题,如果写了降级策略,我们可以让agent继续工作,提高工作流的稳定性
异常捕获
异常捕获是降级的触发器,只有捕获了异常,系统才知道需要切换为降级方案
# 降级的基本模式
try:
result = primary_service() # 尝试主服务
except Exception as e: # 捕获异常
result = fallback_service() # 触发降级
try-except本质上是异常拦截器,他可以阻止异常向其他地方传递,但是它并不具备异常处理的能力,在捕获了异常过后,我们还需要写具体的处理逻辑
为什么需要捕获异常
如果不处理异常,异常会逐层向上传播,如果函数a调用了函数b,函数b出现的异常会向上传递到函数a直至遇到异常捕获程序,如果没有异常捕获,在Langgraph中异常就会蔓延到整个图。
如果异常被捕获了,调度器就能决定是重试、跳过、还是使用降级策略。
模型降级:ModelFallbackMiddleware
ModelFallbackMiddleware是Langchain的一个中间件(在主模型中引用),专门负责在错误时回归其他模型,直至所有可用模型全部耗尽。
#基本格式
ModelFallbackMiddleware(
self,
first_model
*additional_models
)
from langchain.agents import create_agent
from langchain.agents.middleware import ModelFallbackMiddleware
agent = create_agent(
model="gpt-4o", # 主模型
middleware=[
ModelFallbackMiddleware(
"gpt-4o-mini", # 备用1
"claude-3-5-sonnet" # 备用2
)
]
)工具降级
当agent依赖的主工具或者api失效时,我们可以用平替工具进行替换或者使用模型自带的知识,实在不行输出一个“该功能暂时不可用”的提醒而不是直接报错。
from langchain.tools import tool
@tool
async def robust_search(query: str) -> str:
"""带降级的搜索工具"""
# 一级:专业搜索
try:
return await tavily_search(query)
except Exception:
pass
# 二级:通用搜索
try:
return await google_search(query)
except Exception:
pass
# 三级:本地知识
return f"无法搜索到'{query}'的实时结果,请稍后重试"数据降级
实时数据获取失败时,函数返回缓存数据或者默认数据
import logging
import time
logger = logging.getLogger("DataFallback")
class DataService:
def __init__(self):
self.cache = {"user_1": {"name": "张三", "level": 10}} # 模拟本地缓存
async def get_user_data(self, user_id: str):
try:
# 1. 尝试从主数据库/实时 API 获取(模拟可能失败)
logger.info(f"正在请求实时数据库: {user_id}")
result = await self._fetch_from_remote_db(user_id)
# 成功后更新缓存
self.cache[user_id] = result
return result, "REAL_TIME"
except Exception as e:
# 2. 降级逻辑:使用缓存数据
logger.warning(f"实时数据获取失败: {e}。执行数据降级:返回缓存数据。")
fallback_data = self.cache.get(user_id)
if fallback_data:
return fallback_data, "CACHED (DEGRADED)"
else:
# 3. 最终兜底:返回静态默认值
return {"name": "Anonymous", "level": 1}, "DEFAULT_VALUE"功能降级
在一些非核心功能(日志、埋点、通知)失败时,我们可以选择跳过当前工具环节而避免异常阻塞工作流的后续进程

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 31
31 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)