实战指南:如何为你的AI应用选择最合适的Milvus索引
Milvus索引实战指南:从基础原理到生产实践
深入解析Milvus各种索引类型的区别、应用场景和关键参数调优,帮助您构建高性能的向量检索系统
🎯 Milvus索引概述### 为什么需要索引?
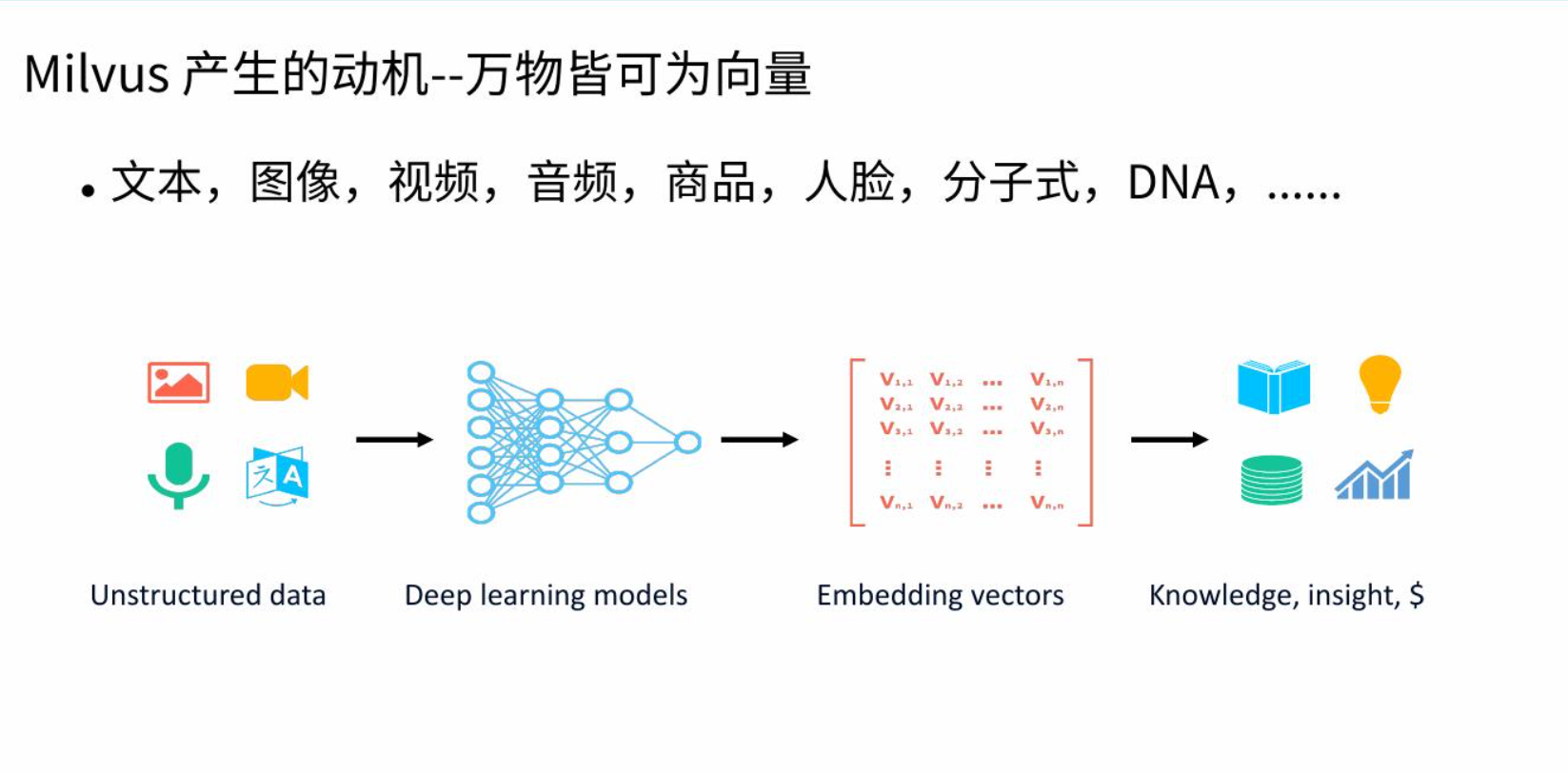
在向量数据库中,索引是提升检索性能的关键技术。没有索引时,每次查询都需要进行全量扫描(暴力搜索),这在海量数据场景下是不可行的。
# 暴力搜索 vs 索引搜索对比
暴力搜索时间复杂度: O(N) # 线性增长,大数据量下极慢
索引搜索时间复杂度: O(logN) # 对数增长,高效可扩展
索引工作原理流程图

Milvus支持的索引类型
Milvus提供了多种索引算法,适应不同的应用场景和性能需求:
| 索引类型 | 算法原理 | 适用场景 | 精度 | 内存占用 |
|---|---|---|---|---|
| FLAT | 暴力搜索 | 小数据量、高精度 | 100% | 高 |
| IVF_FLAT | 倒排文件 | 中等数据量、平衡型 | 95-99% | 中 |
| IVF_PQ | 乘积量化 | 大数据量、内存敏感 | 90-95% | 低 |
| HNSW | 图索引(分层导航小世界、通过构建多层图结构实现快速导航搜索) | 超大数据量、高性能 | 98-99% | 中高 |
| DISKANN | 磁盘ANN | 超大规模、磁盘存储 | 95-98% | 极低 |
🔬 索引类型深度解析
1. FLAT索引(暴力搜索)
核心原理
FLAT索引实际上就是不建立索引,直接进行暴力搜索(Brute-force Search)。
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType
# 创建使用FLAT索引的集合
fields = [
FieldSchema("id", DataType.INT64, is_primary=True),
FieldSchema("embedding", DataType.FLOAT_VECTOR, dim=512)
]
schema = CollectionSchema(fields, "使用FLAT索引的集合")
collection = Collection("flat_collection", schema)
# FLAT索引配置(实际上就是无索引)
index_params = {
"index_type": "FLAT",
"metric_type": "L2", # 距离度量方式
"params": {} # FLAT索引没有额外参数
}
collection.create_index("embedding", index_params)
适用场景
- 数据量小(< 10万条)
- 要求100%精度的检索任务
- 测试和验证场景
- 实时性要求不高的应用
性能特点
- 精度: 100%(绝对准确)
- 查询速度: 慢(O(N)复杂度)
- 内存占用: 高(需要加载全部数据)
- 构建时间: 几乎为0
2. IVF_FLAT索引(倒排文件)
核心原理
IVF(Inverted File)将向量空间划分为多个聚类中心(Clusters),查询时只在最相关的几个聚类中进行搜索。
# IVF_FLAT索引配置
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {
"nlist": 16384, # 聚类数量
"nprobe": 32 # 搜索时探查的聚类数
}
}
collection.create_index("embedding", index_params)
关键参数解析
nlist(聚类数量)
经验公式: nlist ≈ sqrt(data_size)
# nlist选择建议
def calculate_nlist(data_size):
"""根据数据量计算合适的nlist值"""
if data_size < 100000:
return 1024 # 小数据量
elif data_size < 1000000:
return 4096 # 中等数据量
else:
return 16384 # 大数据量
# 经验公式: nlist ≈ sqrt(data_size)
optimal_nlist = int(data_size ** 0.5)
nprobe(探查聚类数)
# nprobe选择策略
def optimize_nprobe(nlist, recall_requirement):
"""根据召回率要求优化nprobe"""
if recall_requirement == "high": # 高召回率
return min(nlist // 10, 256) # 探查更多聚类
elif recall_requirement == "medium": # 平衡型
return min(nlist // 20, 128)
else: # 高性能
return min(nlist // 50, 64)
适用场景
- 中等数据量(10万 - 1000万条)
- 精度和性能平衡的场景
- 通用向量检索应用
- 资源受限环境
3. IVF_PQ索引(乘积量化)
核心原理
PQ(Product Quantization)将高维向量分解为多个子空间,每个子空间进行独立量化,大幅减少存储空间。
# IVF_PQ索引配置
index_params = {
"index_type": "IVF_PQ",
"metric_type": "L2",
"params": {
"nlist": 4096, # 聚类数量
"m": 8, # 子空间数量
"nbits": 8 # 每个子空间的量化位数
}
}
collection.create_index("embedding", index_params)
关键参数解析
m(子空间数量)
# m参数选择指南
def select_m(dimension, compression_ratio):
"""根据向量维度和压缩比选择m值"""
# m必须是维度的约数
divisors = [d for d in range(1, dimension+1) if dimension % d == 0]
if compression_ratio == "high": # 高压缩比
return min(divisors[-1], 16) # 选择较大的m
elif compression_ratio == "medium": # 平衡型
return divisors[len(divisors)//2]
else: # 高精度
return min(divisors[0], 8) # 选择较小的m
# 常见配置
# 128维: m=8, 256维: m=8或16, 512维: m=8或16
nbits(量化位数)
# nbits对精度的影响
def evaluate_nbits_impact():
"""评估nbits对检索精度的影响"""
nbits_options = [8, 12, 16]
precision_results = {}
for nbits in nbits_options:
# nbits越大,量化越精细,精度越高,但存储空间越大
precision = 0.95 + (nbits - 8) * 0.01 # 近似公式
storage_ratio = 32 / nbits # 相对于float32的压缩比
precision_results[nbits] = {
"precision": precision,
"storage_ratio": storage_ratio
}
return precision_results
适用场景
- 超大规模数据(> 1000万条)
- 内存敏感的应用
- 精度要求适中的场景
- 移动端和边缘计算
4. HNSW索引(图索引,分层导航小世界)
核心原理
HNSW(Hierarchical Navigable Small World)基于图结构,通过构建多层网络实现高效近似最近邻搜索。
# HNSW索引配置
index_params = {
"index_type": "HNSW",
"metric_type": "L2",
"params": {
"M": 16, # 层内连接数
"efConstruction": 200, # 构建时的搜索范围
"ef": 64 # 搜索时的搜索范围
}
}
collection.create_index("embedding", index_params)
关键参数解析
M(层内连接数)
# M参数优化策略
def optimize_M(performance_requirement):
"""根据性能要求优化M值"""
if performance_requirement == "high_recall":
return 24 # 高召回率,更多连接
elif performance_requirement == "balanced":
return 16 # 平衡型
else: # high_speed
return 8 # 高速度,较少连接
# M的影响:
# - M越大:召回率↑,构建时间↑,内存占用↑
# - M越小:速度↑,内存占用↓,召回率可能↓
efConstruction和ef
# ef参数配置指南
def configure_ef(M, data_scale):
"""配置efConstruction和ef参数"""
# efConstruction(构建参数)
efConstruction = min(M * 12, 400) # 经验公式
# ef(搜索参数)
if data_scale == "small":
ef = 32
elif data_scale == "medium":
ef = 64
else: # large
ef = 128
return {"efConstruction": efConstruction, "ef": ef}
适用场景
- 超高性能要求的应用
- 实时检索场景
- 高精度需求
- 数据分布复杂的情况
5. DISKANN索引(磁盘ANN)
核心原理
DISKANN将索引存储在磁盘上,通过内存映射技术实现高效检索,适合超大规模数据。
# DISKANN索引配置
index_params = {
"index_type": "DISKANN",
"metric_type": "L2",
"params": {
"search_list": 100, # 搜索列表大小
"pq_code_budget_gb": 0.1 # PQ编码预算(GB)
}
}
collection.create_index("embedding", index_params)
适用场景
- 超大规模数据(> 10亿条)
- 磁盘存储为主的环境
- 成本敏感的应用
- 冷数据检索
📊 索引性能对比分析
综合性能矩阵
| 索引类型 | 数据规模 | 查询速度 | 精度 | 内存占用 | 构建时间 |
|---|---|---|---|---|---|
| FLAT | < 10万 | 慢 | 100% | 高 | 几乎为0 |
| IVF_FLAT | 10万-1000万 | 中等 | 95-99% | 中 | 中等 |
| IVF_PQ | 1000万-10亿 | 快 | 90-95% | 低 | 中等 |
| HNSW | 1000万-10亿 | 极快 | 98-99% | 中高 | 长 |
| DISKANN | > 10亿 | 中等 | 95-98% | 极低 | 长 |
性能对比可视化图表
实际测试数据
# 模拟性能测试结果(基于100万条512维向量)
performance_data = {
"FLAT": {
"query_time": "2.1s",
"recall": "100%",
"memory": "2.0GB"
},
"IVF_FLAT": {
"query_time": "45ms",
"recall": "98.5%",
"memory": "1.2GB"
},
"IVF_PQ": {
"query_time": "32ms",
"recall": "94.2%",
"memory": "0.3GB"
},
"HNSW": {
"query_time": "18ms",
"recall": "99.1%",
"memory": "1.8GB"
}
}
🎯 关键参数调优指南
1. 距离度量选择(metric_type)
# 不同距离度量的适用场景
def select_metric_type(data_type, application):
"""选择合适的距离度量方式"""
if application == "图像检索":
return "L2" # 欧氏距离,适合图像特征
elif application == "文本相似度":
return "IP" # 内积,适合余弦相似度
elif application == "推荐系统":
return "JACCARD" # 杰卡德距离,适合集合数据
else:
return "L2" # 默认选择
# 常用距离度量对比
metric_comparison = {
"L2": {"含义": "欧氏距离", "适用": "通用向量检索"},
"IP": {"含义": "内积", "适用": "余弦相似度计算"},
"HAMMING": {"含义": "汉明距离", "适用": "二进制向量"},
"JACCARD": {"含义": "杰卡德距离", "适用": "集合相似度"}
}
距离度量选择流程图
2. 内存优化策略
# 内存占用估算
def estimate_memory_usage(index_type, data_size, vector_dim):
"""估算不同索引的内存占用"""
base_memory = data_size * vector_dim * 4 # float32占用4字节
if index_type == "FLAT":
return base_memory
elif index_type == "IVF_FLAT":
return base_memory * 1.2 # 增加20%索引开销
elif index_type == "IVF_PQ":
return base_memory * 0.3 # 压缩到30%
elif index_type == "HNSW":
return base_memory * 1.5 # 增加50%索引开销
else:
return base_memory * 0.1 # DISKANN主要使用磁盘
# 内存优化建议
def optimize_memory_usage(available_memory, data_requirements):
"""根据可用内存优化配置"""
required_memory = estimate_memory_usage(
data_requirements["index_type"],
data_requirements["data_size"],
data_requirements["vector_dim"]
)
if required_memory > available_memory:
# 内存不足,选择更节省内存的索引
if data_requirements["recall"] > 0.95:
return "IVF_FLAT" # 平衡型
else:
return "IVF_PQ" # 高压缩比
else:
return data_requirements["index_type"]
内存优化决策流程图
3. 查询性能优化
# 查询性能优化策略
class QueryOptimizer:
def __init__(self, collection, index_type):
self.collection = collection
self.index_type = index_type
def optimize_search_params(self, query_requirements):
"""根据查询要求优化搜索参数"""
search_params = {}
if self.index_type == "IVF_FLAT":
# IVF_FLAT参数优化
search_params["nprobe"] = self._optimize_nprobe(
query_requirements["recall"],
query_requirements["latency"]
)
elif self.index_type == "HNSW":
# HNSW参数优化
search_params["ef"] = self._optimize_ef(
query_requirements["recall"],
query_requirements["data_size"]
)
return search_params
def _optimize_nprobe(self, recall_target, latency_budget):
"""优化IVF_FLAT的nprobe参数"""
if latency_budget < 50: # 毫秒
return 16 # 低延迟
elif recall_target > 0.98:
return 64 # 高召回率
else:
return 32 # 平衡型
def _optimize_ef(self, recall_target, data_size):
"""优化HNSW的ef参数"""
base_ef = 32
if data_size > 1000000: # 大数据量
base_ef = 64
if recall_target > 0.99:
return base_ef * 2 # 高召回率
else:
return base_ef
🏆 实际应用案例
案例1:电商图像检索系统
# 电商图像检索配置
def setup_ecommerce_image_search():
"""电商图像检索系统索引配置"""
# 场景特点:
# - 数据量:1000万张商品图片
# - 精度要求:高(>98%)
# - 响应时间:<100ms
# - 内存预算:16GB
index_params = {
"index_type": "HNSW", # 选择HNSW满足高性能要求
"metric_type": "L2", # 图像特征适合L2距离
"params": {
"M": 16, # 平衡构建时间和查询性能
"efConstruction": 200,
"ef": 64 # 保证高召回率
}
}
return index_params
电商图像检索系统架构图
案例2:智能客服问答系统
# 智能客服问答系统配置
def setup_customer_service_qa():
"""智能客服问答系统索引配置"""
# 场景特点:
# - 数据量:50万条问答对
# - 精度要求:极高(>99%)
# - 响应时间:<200ms可接受
# - 成本敏感
index_params = {
"index_type": "IVF_FLAT", # 平衡精度和成本
"metric_type": "IP", # 文本相似度适合内积
"params": {
"nlist": 2048, # 中等聚类数量
"nprobe": 32 # 保证高精度
}
}
return index_params
智能客服问答系统架构图
案例3:大规模推荐系统
# 推荐系统索引配置
def setup_recommendation_system():
"""大规模推荐系统索引配置"""
# 场景特点:
# - 数据量:1亿用户行为数据
# - 精度要求:中等(>90%)
# - 响应时间:<50ms
# - 内存敏感
index_params = {
"index_type": "IVF_PQ", # 内存优化选择
"metric_type": "IP", # 推荐系统适合内积
"params": {
"nlist": 4096, # 较大聚类数量
"m": 8, # 512维向量的合理选择
"nbits": 8 # 平衡精度和存储
}
}
return index_params
推荐系统架构图
🔧 索引创建和优化实战
索引创建最佳实践
import time
from pymilvus import utility
def create_optimized_index(collection, field_name, index_params):
"""创建优化索引的完整流程"""
# 1. 检查集合状态
if not utility.has_collection(collection.name):
raise Exception("集合不存在")
# 2. 加载数据到内存(如果使用内存索引)
collection.load()
# 3. 创建索引
start_time = time.time()
collection.create_index(field_name, index_params)
build_time = time.time() - start_time
print(f"索引构建完成,耗时: {build_time:.2f}秒")
# 4. 验证索引状态
index_info = collection.index()
print(f"索引信息: {index_info}")
return index_info
# 索引创建示例
collection = Collection("my_collection")
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 2048}
}
create_optimized_index(collection, "embedding", index_params)
索引创建流程图
索引性能测试
def benchmark_index_performance(collection, query_vectors, search_params):
"""索引性能基准测试"""
results = {
"query_times": [],
"recall_rates": [],
"throughput": 0
}
# 预热(避免冷启动影响)
for _ in range(10):
collection.search(query_vectors[:1], "embedding", search_params, limit=10)
# 正式测试
start_time = time.time()
for query_vec in query_vectors:
query_start = time.time()
results = collection.search([query_vec], "embedding", search_params, limit=10)
query_time = time.time() - query_start
results["query_times"].append(query_time)
total_time = time.time() - start_time
# 计算性能指标
avg_query_time = sum(results["query_times"]) / len(results["query_times"])
throughput = len(query_vectors) / total_time
return {
"avg_query_time_ms": avg_query_time * 1000,
"throughput_qps": throughput,
"total_queries": len(query_vectors)
}
🚀 生产环境部署建议
1. 硬件资源配置
# 硬件配置建议
def recommend_hardware_config(index_type, data_scale):
"""根据索引类型和数据规模推荐硬件配置"""
configs = {
"FLAT": {
"small": {"CPU": "4核", "内存": "8GB", "磁盘": "100GB"},
"medium": {"CPU": "8核", "内存": "32GB", "磁盘": "500GB"}
},
"IVF_FLAT": {
"small": {"CPU": "8核", "内存": "16GB", "磁盘": "200GB"},
"medium": {"CPU": "16核", "内存": "64GB", "磁盘": "1TB"},
"large": {"CPU": "32核", "内存": "128GB", "磁盘": "5TB"}
},
"HNSW": {
"medium": {"CPU": "16核", "内存": "64GB", "磁盘": "1TB"},
"large": {"CPU": "32核", "内存": "256GB", "磁盘": "10TB"}
}
}
return configs.get(index_type, {}).get(data_scale, {})
2. 集群部署策略
# 集群部署配置
def setup_cluster_config(index_type, workload):
"""集群部署配置建议"""
if index_type in ["FLAT", "IVF_FLAT"]:
# 单机或小集群部署
return {
"node_count": 1 if workload == "light" else 3,
"replica_factor": 1,
"shard_num": 1
}
else:
# 大集群部署
return {
"node_count": 3 if workload == "medium" else 8,
"replica_factor": 2,
"shard_num": 4
}
📈 监控和调优
性能监控指标
# 关键性能指标监控
class IndexMonitor:
def __init__(self, collection):
self.collection = collection
self.metrics_history = []
def collect_metrics(self):
"""收集索引性能指标"""
metrics = {
"timestamp": time.time(),
"query_latency": self._get_query_latency(),
"recall_rate": self._get_recall_rate(),
"memory_usage": self._get_memory_usage(),
"throughput": self._get_throughput()
}
self.metrics_history.append(metrics)
return metrics
def detect_anomalies(self):
"""检测性能异常"""
if len(self.metrics_history) < 10:
return []
recent_metrics = self.metrics_history[-10:]
avg_latency = sum(m["query_latency"] for m in recent_metrics) / 10
current_latency = self.metrics_history[-1]["query_latency"]
if current_latency > avg_latency * 1.5:
return ["查询延迟异常升高"]
return []
💡 总结与最佳实践
索引选择决策树
-
数据规模:
- < 10万:FLAT
- 10万-1000万:IVF_FLAT或HNSW
-
1000万:IVF_PQ或DISKANN
-
精度要求:
- 100%精度:FLAT
-
98%精度:HNSW
-
95%精度:IVF_FLAT
-
90%精度:IVF_PQ
-
性能要求:
- 极致性能:HNSW
- 平衡性能:IVF_FLAT
- 内存优化:IVF_PQ
索引选择决策流程图
关键参数调优原则
- 渐进式调优:从默认值开始,逐步优化
- A/B测试:对比不同参数组合的效果
- 监控反馈:基于实际性能数据调整
- 业务导向:参数选择服务于业务需求
生产环境注意事项
- 备份策略:定期备份索引数据
- 版本管理:记录索引版本和参数变更
- 容量规划:预留足够的存储和内存空间
- 灾难恢复:制定索引重建和恢复方案
综合性能对比图表
🎯 可视化总结
通过本文的可视化图表,您可以更直观地理解:
- 索引工作原理:通过流程图理解暴力搜索与索引搜索的区别
- 性能对比:通过柱状图和折线图直观比较不同索引的性能特点
- 决策流程:通过决策树流程图指导索引选择
- 系统架构:通过架构图理解实际应用中的系统设计
- 参数调优:通过流程图掌握参数优化策略
这些可视化工具将帮助您在实际项目中做出更明智的技术决策,构建高效的向量检索系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)