基于 ESP32S3 + RDK X5 的智能语音监管机器人:语音交互、人脸追踪与驾驶状态提醒一体化
目录
5.RDK X5 40Pin 接线:PWM6、PWM7 和 UART
2.为什么 0x01 要先启动人脸追踪,再启动 Qwen-ai
最近我完成了一个基于 ESP32S3 + RDK X5 的智能语音监管机器人。这个项目的目标不是简单做一个“摄像头识别人脸”的小 demo,而是把语音交互、嵌入式通信、视觉识别、云端大模型分析、人脸云台跟踪、系统服务自启动、电源管理全部整合到一台真实能运行的机器人里。关于机器人的所有源代码以及相关PCB文件我都已上传Github和嘉立创开源广场,链接在文末。

整个系统可以理解成三个核心模块:
1.ESP32S3 语音交互控制模块:它基于开源项目 xiaozhi-esp32,用来实现语音交互能力,并通过 UART 串口向 RDK X5 发送控制指令。

2.RDK X5 计算服务核心:RDK X5 负责运行两个主要视觉任务:一个是 Qwen-ai 驾驶行为监管脚本,用来识别闭眼、愤怒、玩手机、喝水等状态并进行语音提醒;另一个是人脸追踪脚本,用 USB 摄像头识别人脸,并通过 PWM6 和 PWM7 控制两个舵机,让摄像头云台跟随人脸移动。同时,RDK X5 还运行一个统一的 UART 控制脚本,用来接收 ESP32S3 发来的串口命令,并根据命令启动或关闭不同脚本。

3.电源管理模块:这个模块其实就是STM32舵机控制板,一般的连接方式是将控制信号通过UART串口发送到这个舵机控制板,然后驱动舵机转动,由于控制信号需要多经过一次STM32处理这会显著增加舵机转动的延迟,因此我直接将PWM信号线连接在了RDK X5上,电源线依旧接在舵机驱动板上给 RDK X5 和 ESP32S3 提供稳定的 5V 电源,同时给舵机提供独立的 7.4V 电源。由于舵机在启动和转动时电流波动比较大,所以不能简单地从开发板 5V 引脚取电,必须做独立供电和共地处理。

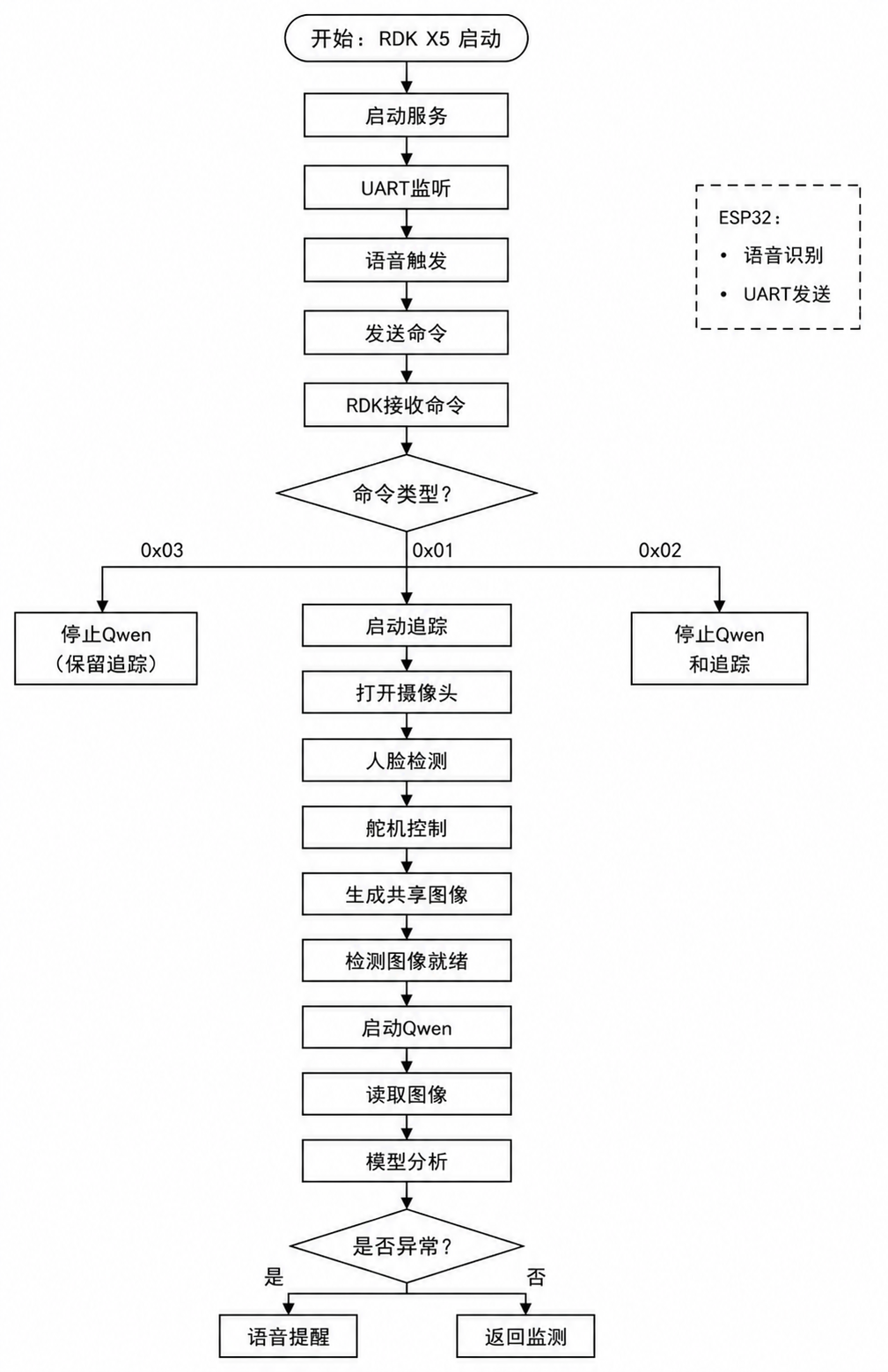
机器人最终实现的效果是:用户可以通过 ESP32S3 语音助手下发控制指令,ESP32S3 再通过 UART 通知 RDK X5。RDK X5 收到指令后,先启动人脸追踪,让摄像头云台跟随人的脸;然后启动 Qwen-ai 驾驶行为监管脚本,持续分析摄像头画面。如果检测到闭眼、愤怒、玩手机、喝水等异常行为,就播放本地语音进行提醒。如果收到停止命令,则可以关闭全部脚本,或者只关闭 Qwen-ai,保留人脸追踪继续运行。
一、为什么采用 ESP32S3 + RDK X5 的架构
这个项目一开始就没有把所有任务都塞进 ESP32S3,ESP32S3 在系统里承担“前端控制器”的角色。它负责接收人的语音输入,然后把语音意图转换成非常简单的 UART 指令。这样做的好处是控制协议很稳定,ESP32S3 不需要理解 RDK X5 里每个 Python 脚本的细节,只需要发送 0x01、0x02、0x03 这样的命令即可。
RDK X5 在系统里承担“计算核心”的角色。Ubuntu操作系统,可以使用 Python、OpenCV、DashScope/Qwen API、systemd 服务、Hobot.GPIO 等工具。它不仅能处理 USB 摄像头,还能控制 40Pin Header 上的 PWM 引脚,让两个舵机实现云台运动。
这种分工的好处是非常明显的:ESP32S3 保持轻量稳定,专注语音交互;RDK X5 负责高算力任务和进程调度;两者之间只通过 UART 传递极简指令,系统耦合度很低,后期维护也比较方便。
二、硬件组成
这个机器人主要用到下面这些硬件:
1.ESP32S3 开发板
用来运行 xiaozhi-esp32 语音交互助手,具体安装教程可见:飞书云文档![]() https://my.feishu.cn/wiki/F5krwD16viZoF0kKkvDcrZNYnhb考虑到机器人组装的美观以及连接稳定性,我自己绘制了一块ESP32S3扩展板,PCB板尺寸长95mm,宽56mm与RDK X5和电源模块的挖槽孔位一致便于后续拼合,同时ESP32S3-CAM扩展板的UART0接口采用HX2.54mm标准接口,UART1采用PH2.0mm接口。PCB工程文件我已发布到立创开源广场:
https://my.feishu.cn/wiki/F5krwD16viZoF0kKkvDcrZNYnhb考虑到机器人组装的美观以及连接稳定性,我自己绘制了一块ESP32S3扩展板,PCB板尺寸长95mm,宽56mm与RDK X5和电源模块的挖槽孔位一致便于后续拼合,同时ESP32S3-CAM扩展板的UART0接口采用HX2.54mm标准接口,UART1采用PH2.0mm接口。PCB工程文件我已发布到立创开源广场:
立创开源广场![]() https://oshwhub.com/yoyoyan/project_nkgaqghu
https://oshwhub.com/yoyoyan/project_nkgaqghu
2.RDK X5 开发板
用来运行 OpenCV人脸追踪、Qwen-ai、UART 控制服务和 PWM 舵机控制。

3.USB 摄像头
实际识别到的设备是 Generalplus Technology Inc. 808 Camera,USB ID 为 1b3f:2002。

4.两个舵机+云台结构件
一个控制摄像头抬头低头,也就是俯仰轴;另一个控制摄像头左右旋转,也就是水平轴。


5.电源模块
分别给 RDK X5、ESP32S3 和舵机供电,上面也提到了电源模块就是24路电机驱动模块+7.4v电池。


6.杜邦线、共地线、电源线、必要的固定件
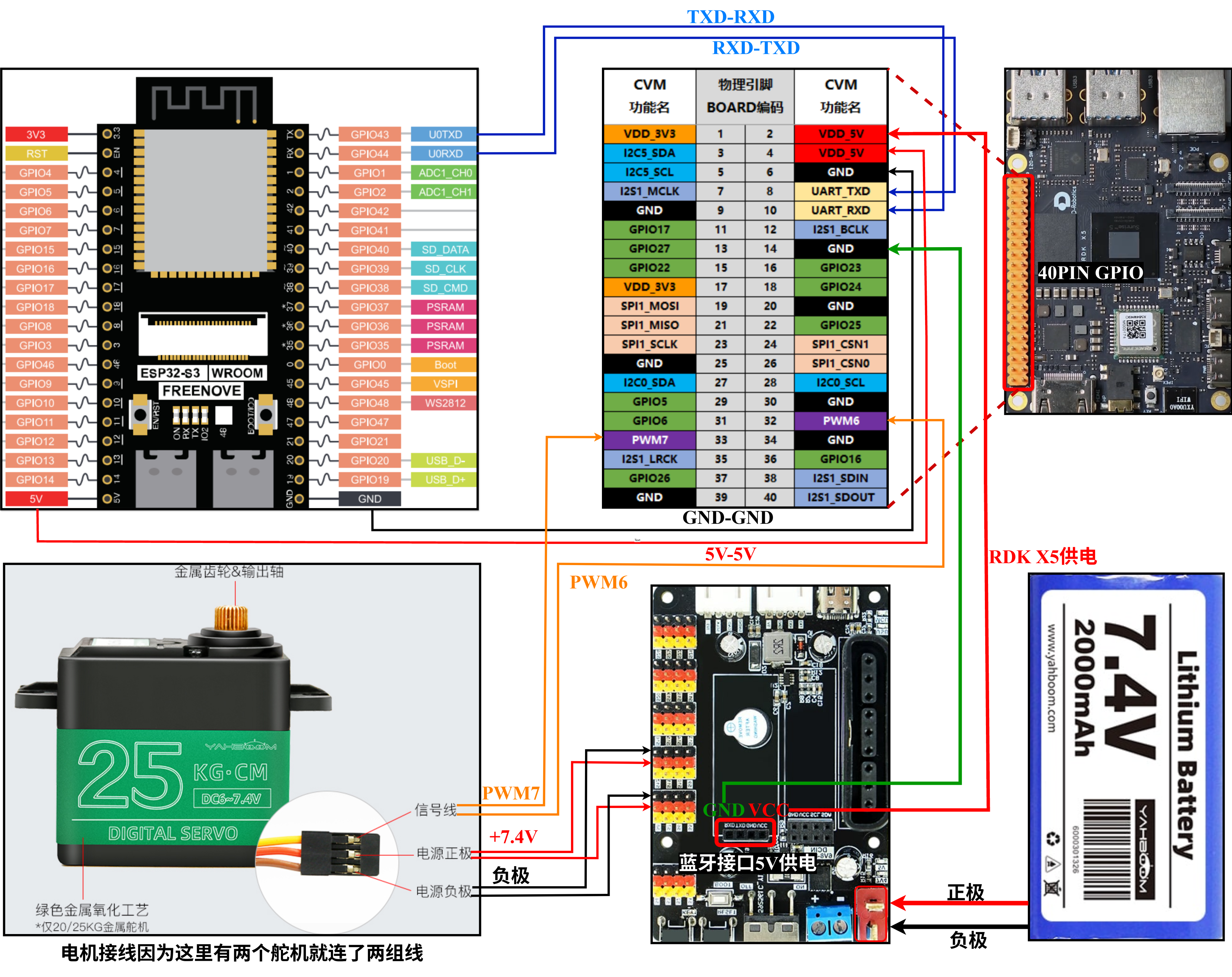
在我的实际接线中,RDK X5 的 PWM6 用来控制俯仰舵机,也就是抬头和低头;PWM7 用来控制水平舵机,也就是左右旋转。UART 使用 RDK X5 40Pin Header 上的 8 和 10 引脚。

Tips:上述所有配件都可在亚博产品中心找到,除了ESP32S3语音控制模块。
亚博-产品中心![]() https://www.yahboom.com/store
https://www.yahboom.com/store
三、人脸追踪部分 tracking-face 的整体逻辑
1.USB 摄像头识别和验证
最开始项目使用过 MIPI 摄像头,后来改成了 USB 摄像头。改成 USB 摄像头以后,第一件事不是直接写代码,而是先确认RDK是否真的识别到了摄像头。
在终端执行:
lsusb可以看到摄像头设备:
Bus 001 Device 015: ID 1b3f:2002 Generalplus Technology Inc. 808 Camera这说明 USB 总线上已经发现了摄像头硬件。这里的 1b3f:2002 是 USB 设备的厂商 ID 和产品 ID,后面的 Generalplus Technology Inc. 808 Camera 是设备名称。
但是 lsusb 只能说明 USB 层面识别到了设备,还不能说明它已经可以作为视频设备使用。所以还需要看 /dev/video*:
ls -l /dev/video*系统中出现了:
/dev/video0 /dev/video1这说明RDK X5已经创建了视频设备节点。然后继续执行:
v4l2-ctl --list-devices输出里可以看到:
GENERAL WEBCAM: GENERAL WEBCAM (usb-xhci-hcd.2.auto-1.4): /dev/video0 /dev/video1 /dev/media0这里可以确认 USB 摄像头对应的是 /dev/video0 和 /dev/video1。在当前项目中,实际使用的是 /dev/video0。
在人脸追踪程序里,摄像头默认参数是:
摄像头设备:/dev/video0 分辨率:640x360 帧率:30 FPS 编码格式:MJPG选择 640x360 是一个比较实用的折中。分辨率太高会增加 OpenCV 检测压力,让舵机响应变慢;分辨率太低又会影响人脸检测准确率。640x360 对 RDK X5 来说压力比较小,画面比例也适合做人脸跟踪和上传大模型识别。
编码格式使用 MJPG,是因为很多 USB 摄像头在 MJPEG 模式下可以比较稳定地输出 30 FPS。如果使用默认的 YUYV,在某些摄像头上可能帧率会下降,导致画面延迟和云台跟随变慢。
2.人脸追踪脚本
主脚本是:
/home/sunrise/Desktop/tracking-face/tracking_face.py#!/usr/bin/env python3
import argparse
import os
import signal
import sys
import time
from dataclasses import dataclass
from pathlib import Path
from typing import Optional, Tuple
import cv2
def add_rdk_system_python_paths() -> None:
py_ver = f"{sys.version_info.major}.{sys.version_info.minor}"
for path in [
f"/usr/local/lib/python{py_ver}/dist-packages",
f"/usr/lib/python{py_ver}/dist-packages",
"/usr/lib/python3/dist-packages",
]:
if os.path.isdir(path) and path not in sys.path:
sys.path.append(path)
add_rdk_system_python_paths()
try:
import Hobot.GPIO as GPIO
from Hobot.GPIO import gpio as HOBOT_GPIO_INTERNALS
except ImportError:
GPIO = None
HOBOT_GPIO_INTERNALS = None
@dataclass
class ServoConfig:
board_pin: int
min_angle: float
max_angle: float
center_angle: float
min_pulse_us: float
max_pulse_us: float
inverted: bool = False
class Servo:
def __init__(self, config: ServoConfig, frequency_hz: int = 50, dry_run: bool = False):
self.config = config
self.frequency_hz = frequency_hz
self.dry_run = dry_run
self.angle = config.center_angle
self.pwm = None
if not dry_run:
if GPIO is None:
raise RuntimeError("Hobot.GPIO is not available. Use --dry-run to test without servos.")
self.pwm = GPIO.PWM(config.board_pin, frequency_hz)
self.pwm.start(self._angle_to_duty(config.center_angle))
self._ensure_enabled()
def _angle_to_duty(self, angle: float) -> float:
angle = clamp(angle, self.config.min_angle, self.config.max_angle)
if self.config.inverted:
angle = self.config.max_angle - (angle - self.config.min_angle)
span_angle = self.config.max_angle - self.config.min_angle
ratio = (angle - self.config.min_angle) / span_angle if span_angle else 0.5
pulse_us = self.config.min_pulse_us + ratio * (self.config.max_pulse_us - self.config.min_pulse_us)
period_us = 1_000_000.0 / self.frequency_hz
return 100.0 * pulse_us / period_us
def move_to(self, angle: float) -> None:
self.angle = clamp(angle, self.config.min_angle, self.config.max_angle)
duty = self._angle_to_duty(self.angle)
if self.dry_run:
return
self.pwm.ChangeDutyCycle(duty)
self._ensure_enabled()
def move_by(self, delta: float) -> None:
self.move_to(self.angle + delta)
def center(self) -> None:
self.move_to(self.config.center_angle)
def stop(self) -> None:
if self.pwm is not None:
self.pwm.stop()
def _ensure_enabled(self) -> None:
if HOBOT_GPIO_INTERNALS is not None:
HOBOT_GPIO_INTERNALS._enable_pwm(self.config.board_pin)
class MotionAxis:
def __init__(self, servo: Servo, max_speed_dps: float, max_accel_dps2: float, target_smoothing: float):
self.servo = servo
self.target_angle = servo.angle
self.velocity = 0.0
self.max_speed = max(1.0, max_speed_dps)
self.max_accel = max(1.0, max_accel_dps2)
self.target_smoothing = clamp(target_smoothing, 0.0, 1.0)
def set_target(self, angle: float) -> None:
angle = clamp(angle, self.servo.config.min_angle, self.servo.config.max_angle)
alpha = self.target_smoothing
self.target_angle = alpha * angle + (1.0 - alpha) * self.target_angle
def reset(self) -> None:
self.target_angle = self.servo.angle
self.velocity = 0.0
def update(self, dt: float) -> None:
dt = clamp(dt, 0.001, 0.1)
error = self.target_angle - self.servo.angle
if abs(error) < 0.03 and abs(self.velocity) < 0.2:
self.velocity = 0.0
self.servo.move_to(self.target_angle)
return
direction = 1.0 if error > 0 else -1.0
stopping_distance = (self.velocity * self.velocity) / (2.0 * self.max_accel)
if abs(error) <= stopping_distance:
desired_velocity = 0.0
else:
desired_velocity = direction * self.max_speed
max_velocity_change = self.max_accel * dt
self.velocity = approach(self.velocity, desired_velocity, max_velocity_change)
step = self.velocity * dt
if abs(step) > abs(error):
step = error
self.velocity = 0.0
self.servo.move_by(step)
class FaceTracker:
def __init__(self, args: argparse.Namespace):
self.args = args
self.running = True
self.detector_name = "haar"
if args.show and not has_graphical_display():
print("No graphical display found, disabling --show preview window.")
self.args.show = False
if GPIO is not None and not args.dry_run:
GPIO.setwarnings(False)
GPIO.setmode(GPIO.BOARD)
self.face_detector = self._build_face_detector()
self.pan_servo = Servo(
ServoConfig(
board_pin=args.pan_pin,
min_angle=args.pan_min,
max_angle=args.pan_max,
center_angle=args.pan_center,
min_pulse_us=args.servo_min_us,
max_pulse_us=args.servo_max_us,
inverted=not args.normal_pan,
),
frequency_hz=args.servo_frequency,
dry_run=args.dry_run,
)
self.tilt_servo = Servo(
ServoConfig(
board_pin=args.tilt_pin,
min_angle=args.tilt_min,
max_angle=args.tilt_max,
center_angle=args.tilt_center,
min_pulse_us=args.servo_min_us,
max_pulse_us=args.servo_max_us,
inverted=args.invert_tilt,
),
frequency_hz=args.servo_frequency,
dry_run=args.dry_run,
)
self.pan_axis = MotionAxis(
self.pan_servo,
args.pan_max_speed,
args.pan_max_accel,
args.target_filter_alpha,
)
self.tilt_axis = MotionAxis(
self.tilt_servo,
args.tilt_max_speed,
args.tilt_max_accel,
args.target_filter_alpha,
)
self.filtered_error_x = 0.0
self.filtered_error_y = 0.0
self.has_filtered_error = False
def _build_face_detector(self):
if self.args.detector in {"yunet", "auto"}:
model_path = Path(self.args.yunet_model)
if model_path.exists() and hasattr(cv2, "FaceDetectorYN"):
try:
detector = cv2.FaceDetectorYN.create(
str(model_path),
"",
(self.args.camera_width, self.args.camera_height),
self.args.yunet_score_threshold,
self.args.yunet_nms_threshold,
self.args.yunet_top_k,
)
self.detector_name = "yunet"
print(f"Using YuNet face detector: {model_path}")
return detector
except Exception as exc:
if self.args.detector == "yunet":
raise RuntimeError(f"Failed to initialize YuNet detector: {exc}")
print(f"YuNet unavailable, fallback to Haar: {exc}")
elif self.args.detector == "yunet":
raise RuntimeError(f"YuNet model not found: {model_path}")
cascade_path = self.args.cascade or str(Path(cv2.data.haarcascades) / "haarcascade_frontalface_default.xml")
detector = cv2.CascadeClassifier(cascade_path)
if detector.empty():
raise RuntimeError(f"Failed to load Haar cascade: {cascade_path}")
self.detector_name = "haar"
print(f"Using Haar face detector: {cascade_path}")
return detector
def open_camera(self):
backend = cv2.CAP_V4L2 if sys.platform.startswith("linux") else cv2.CAP_ANY
cap = cv2.VideoCapture(self.args.camera_index, backend)
if not cap.isOpened():
raise RuntimeError(f"Failed to open camera /dev/video{self.args.camera_index}")
if self.args.camera_fourcc:
cap.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter_fourcc(*self.args.camera_fourcc[:4].ljust(4)))
cap.set(cv2.CAP_PROP_FRAME_WIDTH, self.args.camera_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, self.args.camera_height)
cap.set(cv2.CAP_PROP_FPS, self.args.camera_fps)
return cap
def select_face(self, faces) -> Optional[Tuple[int, int, int, int]]:
if len(faces) == 0:
return None
x, y, w, h = max(faces, key=lambda face: face[2] * face[3])
return int(x), int(y), int(w), int(h)
def detect_faces(self, frame):
if self.detector_name == "yunet":
h, w = frame.shape[:2]
self.face_detector.setInputSize((w, h))
_, detections = self.face_detector.detect(frame)
if detections is None:
return []
return detections[:, :4]
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray = cv2.equalizeHist(gray)
return self.face_detector.detectMultiScale(
gray,
scaleFactor=self.args.scale_factor,
minNeighbors=self.args.min_neighbors,
minSize=(self.args.min_face, self.args.min_face),
)
def track_face(self, frame, face: Tuple[int, int, int, int]) -> None:
h, w = frame.shape[:2]
x, y, fw, fh = face
face_cx = x + fw / 2.0
face_cy = y + fh / 2.0
error_x = (face_cx - w / 2.0) / (w / 2.0)
error_y = (face_cy - h / 2.0) / (h / 2.0)
error_x, error_y = self.filter_error(error_x, error_y)
if abs(error_x) > self.args.dead_zone:
self.pan_axis.set_target(self.pan_servo.angle + error_x * self.args.pan_gain)
if abs(error_y) > self.args.dead_zone:
self.tilt_axis.set_target(self.tilt_servo.angle + error_y * self.args.tilt_gain)
def filter_error(self, error_x: float, error_y: float) -> Tuple[float, float]:
alpha = clamp(self.args.error_filter_alpha, 0.0, 1.0)
if not self.has_filtered_error:
self.filtered_error_x = error_x
self.filtered_error_y = error_y
self.has_filtered_error = True
else:
self.filtered_error_x = alpha * error_x + (1.0 - alpha) * self.filtered_error_x
self.filtered_error_y = alpha * error_y + (1.0 - alpha) * self.filtered_error_y
return self.filtered_error_x, self.filtered_error_y
def draw_overlay(self, frame, face: Optional[Tuple[int, int, int, int]], fps: float) -> None:
h, w = frame.shape[:2]
cv2.line(frame, (w // 2 - 16, h // 2), (w // 2 + 16, h // 2), (255, 255, 255), 1)
cv2.line(frame, (w // 2, h // 2 - 16), (w // 2, h // 2 + 16), (255, 255, 255), 1)
if face is not None:
x, y, fw, fh = face
cv2.rectangle(frame, (x, y), (x + fw, y + fh), (0, 220, 0), 2)
cv2.circle(frame, (x + fw // 2, y + fh // 2), 4, (0, 220, 0), -1)
info = (
f"{self.detector_name} pan={self.pan_servo.angle:.1f}->{self.pan_axis.target_angle:.1f} "
f"tilt={self.tilt_servo.angle:.1f}->{self.tilt_axis.target_angle:.1f} fps={fps:.1f}"
)
cv2.putText(frame, info, (10, 24), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 220, 255), 2)
def maybe_publish_frame(self, frame, now: float) -> None:
if not self.args.publish_frame:
return
if now - self.last_publish_at < self.args.publish_interval:
return
publish_path = Path(self.args.publish_frame)
publish_path.parent.mkdir(parents=True, exist_ok=True)
quality = clamp(self.args.publish_jpeg_quality, 30, 95)
ok, encoded = cv2.imencode(".jpg", frame, [int(cv2.IMWRITE_JPEG_QUALITY), int(quality)])
if not ok:
return
tmp_path = publish_path.with_suffix(publish_path.suffix + ".tmp")
tmp_path.write_bytes(encoded.tobytes())
os.replace(tmp_path, publish_path)
self.last_publish_at = now
def run(self) -> None:
self.pan_servo.center()
self.tilt_servo.center()
time.sleep(self.args.center_delay)
cap = self.open_camera()
print(
f"Camera /dev/video{self.args.camera_index} opened at "
f"{int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))}x{int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))}"
)
print(f"PWM6 tilt: BOARD {self.args.tilt_pin}; PWM7 pan: BOARD {self.args.pan_pin}")
print(f"Face detector: {self.detector_name}")
last_loop_at = time.time()
self.last_publish_at = 0.0
fps = 0.0
try:
while self.running:
ok, frame = cap.read()
if not ok or frame is None:
print("Camera frame read failed, retrying...")
time.sleep(0.05)
continue
now = time.time()
dt = max(1e-6, now - last_loop_at)
fps = 0.9 * fps + 0.1 * (1.0 / dt) if fps else 1.0 / dt
last_loop_at = now
faces = self.detect_faces(frame)
face = self.select_face(faces)
if face is not None:
self.track_face(frame, face)
self.pan_axis.update(dt)
self.tilt_axis.update(dt)
self.maybe_publish_frame(frame, now)
if self.args.show:
self.draw_overlay(frame, face, fps)
cv2.imshow("RDK X5 face tracking", frame)
key = cv2.waitKey(1) & 0xFF
if key in (27, ord("q")):
break
if self.args.loop_sleep > 0:
time.sleep(self.args.loop_sleep)
finally:
cap.release()
cv2.destroyAllWindows()
self.pan_servo.center()
self.tilt_servo.center()
time.sleep(self.args.center_delay)
self.pan_servo.stop()
self.tilt_servo.stop()
if GPIO is not None and not self.args.dry_run:
GPIO.cleanup()
def clamp(value: float, low: float, high: float) -> float:
return max(low, min(high, value))
def approach(current: float, target: float, step: float) -> float:
if abs(target - current) <= step:
return target
return current + step if target > current else current - step
def has_graphical_display() -> bool:
return bool(os.environ.get("DISPLAY") or os.environ.get("WAYLAND_DISPLAY"))
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser(description="RDK X5 USB camera face tracker with PWM6/PWM7 servos.")
parser.add_argument("--camera-index", type=int, default=0, help="USB camera index, usually /dev/video0.")
parser.add_argument("--camera-width", type=int, default=640)
parser.add_argument("--camera-height", type=int, default=360)
parser.add_argument("--camera-fps", type=int, default=30)
parser.add_argument("--camera-fourcc", default="MJPG")
parser.add_argument("--cascade", default="", help="Optional OpenCV Haar cascade XML path.")
parser.add_argument("--detector", choices=("auto", "yunet", "haar"), default="auto")
parser.add_argument("--yunet-model", default=str(Path(__file__).resolve().parent / "models" / "face_detection_yunet_2023mar.onnx"))
parser.add_argument("--yunet-score-threshold", type=float, default=0.85)
parser.add_argument("--yunet-nms-threshold", type=float, default=0.3)
parser.add_argument("--yunet-top-k", type=int, default=5000)
parser.add_argument("--show", action="store_true", help="Show preview window. Press q or Esc to quit.")
parser.add_argument("--dry-run", action="store_true", help="Run camera and face detection without servo PWM output.")
parser.add_argument("--publish-frame", default="/tmp/rdk_shared_camera/latest.jpg", help="Write latest camera frame for other programs.")
parser.add_argument("--publish-interval", type=float, default=0.2, help="Minimum seconds between published frames.")
parser.add_argument("--publish-jpeg-quality", type=int, default=80)
parser.add_argument("--tilt-pin", type=int, default=32, help="PWM6 physical BOARD pin for up/down tilt servo.")
parser.add_argument("--pan-pin", type=int, default=33, help="PWM7 physical BOARD pin for left/right pan servo.")
parser.add_argument("--servo-frequency", type=int, default=50)
parser.add_argument("--servo-min-us", type=float, default=500.0)
parser.add_argument("--servo-max-us", type=float, default=2500.0)
parser.add_argument("--pan-min", type=float, default=20.0)
parser.add_argument("--pan-max", type=float, default=160.0)
parser.add_argument("--pan-center", type=float, default=90.0)
parser.add_argument("--tilt-min", type=float, default=35.0)
parser.add_argument("--tilt-max", type=float, default=145.0)
parser.add_argument("--tilt-center", type=float, default=90.0)
parser.add_argument("--normal-pan", action="store_true", help="Use non-inverted pan servo direction.")
parser.add_argument("--invert-tilt", action="store_true", help="Reverse tilt servo direction.")
parser.add_argument("--pan-gain", type=float, default=2.2, help="Degrees per normalized horizontal error.")
parser.add_argument("--tilt-gain", type=float, default=1.8, help="Degrees per normalized vertical error.")
parser.add_argument("--dead-zone", type=float, default=0.08, help="Ignore small normalized face-center errors.")
parser.add_argument("--error-filter-alpha", type=float, default=0.38, help="EMA factor for face-center error. Lower is smoother.")
parser.add_argument("--target-filter-alpha", type=float, default=0.82, help="EMA factor for servo target angle. Lower is smoother.")
parser.add_argument("--pan-max-speed", type=float, default=190.0, help="Maximum pan speed in degrees per second.")
parser.add_argument("--tilt-max-speed", type=float, default=150.0, help="Maximum tilt speed in degrees per second.")
parser.add_argument("--pan-max-accel", type=float, default=700.0, help="Maximum pan acceleration in degrees per second squared.")
parser.add_argument("--tilt-max-accel", type=float, default=560.0, help="Maximum tilt acceleration in degrees per second squared.")
parser.add_argument("--center-delay", type=float, default=0.3)
parser.add_argument("--loop-sleep", type=float, default=0.005)
parser.add_argument("--scale-factor", type=float, default=1.12)
parser.add_argument("--min-neighbors", type=int, default=5)
parser.add_argument("--min-face", type=int, default=60)
return parser.parse_args()
def main() -> int:
args = parse_args()
tracker = FaceTracker(args)
def stop(_signum, _frame):
tracker.running = False
signal.signal(signal.SIGINT, stop)
signal.signal(signal.SIGTERM, stop)
try:
tracker.run()
except Exception as exc:
print(f"tracking_face error: {exc}", file=sys.stderr)
return 1
return 0
if __name__ == "__main__":
raise SystemExit(main())
它做了四件核心事情:
1.打开 USB 摄像头 /dev/video0,持续读取画面。
2.使用 OpenCV 检测画面中的人脸。
3.根据人脸中心和画面中心的偏差,计算舵机应该转动的方向和角度。
4.通过 RDK X5 的 PWM6 和 PWM7 输出 PWM 信号,控制两个舵机运动。
这个脚本还额外做了一件非常重要的事情:它会把当前摄像头画面发布到共享路径:
/tmp/rdk_shared_camera/latest.jpg这样 Qwen-ai 项目就不需要再直接打开摄像头,而是读取这张共享图片,从而解决两个程序同时抢占同一个 USB 摄像头的问题。
3.OpenCV 人脸检测:从 Haar 到 YuNet
一开始用 OpenCV 自带的 Haar Cascade 做人脸检测。Haar Cascade 的优点是使用简单,不需要额外模型文件,OpenCV 自带就能跑。但它的缺点也很明显:对光照、角度、脸部大小比较敏感,很多情况下识别不到人脸,尤其是人脸有偏转、画面比较暗、距离比较远时。
后来项目改成优先使用 OpenCV YuNet 人脸检测模型。模型文件放在:
/home/sunrise/Desktop/tracking-face/models/face_detection_yunet_2023mar.onnxYuNet 是 OpenCV Zoo 里提供的人脸检测模型,适合轻量级实时人脸检测。当前脚本的逻辑是:如果模型文件存在,并且当前 OpenCV 支持 cv2.FaceDetectorYN,就使用 YuNet;如果不可用,再回退到 Haar Cascade。
当前 YuNet 参数如下:
score threshold:0.85 NMS threshold:0.3 top_k:5000(1)score threshold 可以理解成检测置信度阈值。设置为 0.85,意思是模型认为足够像人脸时才认为检测成功。这个值太低会误检,太高会漏检。当前项目中 0.85 是比较平衡的值。
(2)NMS threshold 是非极大值抑制阈值。简单理解,如果模型在同一张脸附近框出了多个框,NMS 会帮我们保留最合适的那个框。
(3)top_k 是最多保留多少个候选检测结果。这里设置为 5000,对普通单人或少人场景已经足够。
在人脸选择上,程序采用了最简单也最稳定的策略:如果画面中检测到多张脸,就选择面积最大的那张脸。代码逻辑相当于:
x, y, w, h = max(faces, key=lambda face: face[2] * face[3])这意味着机器人会优先跟踪离摄像头最近、画面中最大的人脸。对于一个桌面机器人或者车载监管机器人来说,这个策略非常实用,因为通常需要关注的是最靠近设备的那个人。
Tips:Yunet模型仓库地址:opencv_zoo/models/face_detection_yunet at main · opencv/opencv_zoo![]() https://github.com/opencv/opencv_zoo/tree/main/models/face_detection_yunet
https://github.com/opencv/opencv_zoo/tree/main/models/face_detection_yunet
4.PWM 舵机控制基础
这个项目中直接用 RDK X5 的 40Pin Header 输出 PWM 信号控制,使用PWM6和PWM7,RDK X5硬件接口说明图:
PWM 的全称是 Pulse Width Modulation,中文叫脉冲宽度调制。舵机并不是靠电压大小决定角度,而是靠周期性脉冲里的“高电平持续时间”决定目标角度。
常见舵机使用 50Hz PWM 信号。50Hz 的意思是每秒输出 50 个周期。一个周期时间是:
1 / 50 = 0.02 秒 = 20 毫秒 = 20000 微秒
在这 20ms 里,高电平持续时间通常在 500us 到 2500us 之间变化。这个高电平宽度就叫脉宽。
在本项目中,舵机参数是:
PWM 频率:50Hz 最小脉宽:500us 最大脉宽:2500us 中心角度:90 度程序里把角度转换成 PWM 占空比。占空比就是高电平时间占整个周期的比例。
计算方式是:
占空比 = 脉宽 / 周期 * 100%
由于 50Hz 的周期是 20000us,所以:
500us 对应占空比:500 / 20000 * 100% = 2.5%
1500us 对应占空比:1500 / 20000 * 100% = 7.5%
2500us 对应占空比:2500 / 20000 * 100% = 12.5%
也就是说,舵机的角度其实是由大约 2.5% 到 12.5% 之间的占空比控制的。程序里会把目标角度先映射成对应脉宽,再转换成占空比,最后通过 Hobot.GPIO.PWM 输出到指定引脚。
5.RDK X5 40Pin 接线:PWM6、PWM7 和 UART
(1)人脸追踪使用两个 PWM 引脚:
PWM6:BOARD 32,用于俯仰舵机,也就是抬头/低头
PWM7:BOARD 33,用于水平舵机,也就是左右旋转
(2)UART 控制使用两个串口引脚:
BOARD 8:UART_TXD BOARD 10:UART_RXD
UART 接线一定要注意交叉连接:
ESP32S3 TX -> RDK X5 RX,也就是 BOARD 10 ESP32S3
RX -> RDK X5 TX,也就是 BOARD 8 ESP32S3 GND -> RDK X5 GND
也就是说,一个设备的发送端 TX 要接到另一个设备的接收端 RX,不能 TX 接 TX、RX 接 RX。两个板子之间还必须共地,否则串口电平没有共同参考点,通信会不稳定甚至完全无法通信。
这里使用的是 TTL 串口电平。ESP32S3 是 3.3V 逻辑电平,RDK X5 的 40Pin UART 也是面向板级连接的 UART,具体接线图如下:
6.舵机角度范围和方向反转
机械云台装好以后,经常会遇到一个问题:程序认为应该向左转,但摄像头实际向右转;程序认为应该抬头,但摄像头实际低头。这不是代码逻辑错误,而是舵机安装方向、连杆结构、舵盘安装角度造成的。
所以程序里给水平轴和俯仰轴都保留了方向反转能力。
当前默认参数是:
水平舵机 pan: BOARD 33
最小角度:20 度
最大角度:160 度
中心角度:90 度
默认方向:反向
俯仰舵机 tilt: BOARD 32
最小角度:35 度
最大角度:145 度
中心角度:90 度
默认方向:正常水平舵机默认反向,是因为实际测试时发现水平控制方向反了,所以程序默认把 pan 方向反过来。如果以后更换云台结构,发现水平又反了,可以运行时加参数:
python3 tracking_face.py --normal-pan如果俯仰方向反了,可以运行:
python3 tracking_face.py --invert-tilt7.人脸中心偏差如何转换成舵机运动
人脸追踪的核心思想很简单:让人脸中心尽量靠近画面中心。
程序每一帧检测到人脸后,会得到人脸框:
x, y, w, h其中 x 和 y 是人脸框左上角坐标,w 是宽度,h 是高度。人脸中心坐标为:
face_cx = x + w / 2 face_cy = y + h / 2画面中心坐标为:
frame_cx = frame_width / 2 frame_cy = frame_height / 2然后计算归一化误差:
error_x = (face_cx - frame_width / 2) / (frame_width / 2) error_y = (face_cy - frame_height / 2) / (frame_height / 2)为什么要归一化?因为这样误差范围大致会落在 -1 到 1 之间。无论摄像头是 640x360 还是 1280x720,控制逻辑都可以使用类似的参数。
如果 error_x 是正数,说明人脸在画面右侧;如果是负数,说明人脸在画面左侧。如果 error_y 是正数,说明人脸在画面下方;如果是负数,说明人脸在画面上方。
程序再根据误差乘以增益,得到目标角度变化:
水平轴增益 pan_gain:2.2 俯仰轴增益 tilt_gain:1.8可以简单理解为:人脸偏得越多,舵机目标角度变化越大。水平轴的增益比俯仰轴稍大,是因为左右移动通常需要跟得更快;俯仰轴如果太灵敏,画面会更容易上下抖。
8.死区 dead zone
如果完全按照误差控制舵机,会出现一个很常见的问题:人脸明明已经在画面中心附近了,舵机还是不停地微微抖动。这是因为人脸检测框每一帧都会有一点点变化,哪怕人不动,检测框的位置也不是绝对固定的。
为了解决这个问题,程序加入了死区:
dead_zone:0.08意思是:如果人脸中心偏差小于画面半宽或半高的 8%,就认为已经足够居中,不再调整舵机。
这对舵机稳定性非常重要。没有死区时,舵机会不停追逐检测框的小抖动;有了死区以后,人脸只要在画面中心附近,云台就会保持不动,看起来更稳。
可以把 dead zone 理解成“容忍范围”。不是每一次误差都要修正,只有偏差真的明显时才修正。
9.低通滤波:让检测误差不要一跳一跳
OpenCV 检测出来的人脸框不是完全平滑的。即使人脸不动,检测框也可能每帧跳动几个像素。如果把这种跳动直接传给舵机,舵机就会跟着抖。
所以程序对人脸中心误差做了一阶低通滤波,也可以叫 EMA 滤波,指数移动平均滤波。
当前参数是:
error_filter_alpha:0.38滤波公式可以理解为:
新的滤波误差 = alpha * 当前误差 + (1 - alpha) * 上一次滤波误差当 alpha 越大,系统越相信当前检测结果,响应越快,但可能更抖。当 alpha 越小,系统越依赖历史结果,运动更平滑,但会有一点延迟。
当前使用 0.38,是一个偏平衡的值。它不会像 0.8 那样过于敏感,也不会像 0.1 那样跟得太慢。
这个滤波只处理“视觉检测误差”,相当于先把 OpenCV 输出的人脸位置变得更平滑,再交给后面的舵机运动控制。
10.目标角度滤波:不要让舵机目标突然跳变
除了检测误差滤波,程序还对舵机的目标角度做了平滑处理。
当前参数是:
target_filter_alpha:0.82当检测到人脸偏移后,程序不会把目标角度瞬间改成一个很远的新值,而是用滤波的方式逐渐更新目标角度。这样可以减少舵机突然大幅度改变目标造成的机械冲击。
这里要注意:error_filter_alpha 和 target_filter_alpha 不是同一个东西。
error_filter_alpha 处理的是人脸检测结果,也就是“人脸在哪里”。
target_filter_alpha 处理的是舵机目标角度,也就是“舵机想去哪里”。
这两层滤波叠加以后,可以让画面跟随更稳定。前一层减少视觉抖动,后一层减少控制目标突变。
11.梯形速度曲线:舵机不能直接一步到位
如果每次检测到人脸偏移后,直接让舵机跳到新角度,舵机会出现明显顿挫。因为普通 PWM 舵机内部虽然有自己的控制器,但外部目标角度变化太突然时,它仍然会快速冲向目标,造成画面抽动、结构晃动、电流突增。
为了让舵机动作更自然,程序里加入了 MotionAxis 控制类,用类似梯形速度曲线的方式控制运动。
所谓梯形速度曲线,可以想象成汽车起步和刹车:
第一阶段,加速。舵机从静止开始,不是瞬间达到最大速度,而是按最大加速度逐渐加速。
第二阶段,匀速。如果目标还比较远,舵机会以最大速度附近移动。
第三阶段,减速。快到目标角度时,舵机会提前减速,避免冲过头。
当前参数是:
水平轴最大速度 pan_max_speed:190 度/秒
俯仰轴最大速度 tilt_max_speed:150 度/秒
水平轴最大加速度 pan_max_accel:700 度/秒²
俯仰轴最大加速度 tilt_max_accel:560 度/秒²水平轴速度更高,是因为人脸左右移动通常更频繁,水平跟踪需要更快。俯仰轴稍慢一些,可以让抬头低头动作更稳,不容易造成画面上下晃。
四、Qwen-ai 驾驶行为主动监管模块
1.摄像头共享
这个项目中的两个脚本(tracking-face.py+driver_safety_supervisor.py)都需要摄像头画面:
一个是人脸追踪程序,它需要高频读取摄像头,用来控制云台实时跟随人脸。
另一个是 Qwen-ai 驾驶行为监管程序,它需要定期获取画面,上传给大模型分析驾驶状态。
问题在于,很多 Linux USB 摄像头在 V4L2 下不能被两个进程同时稳定打开。也就是说,如果 tracking-face 已经打开了 /dev/video0,Qwen-ai 再去打开 /dev/video0,就会失败,或者两个程序互相影响。
最终采用的方案是:让 tracking-face 独占 USB 摄像头,然后把最新画面写成共享 JPEG 文件。Qwen-ai 不直接打开摄像头,而是读取这个共享 JPEG 文件。
共享路径是:
/tmp/rdk_shared_camera/latest.jpgtracking-face 默认每隔:
publish_interval:0.2 秒发布一张最新画面,也就是大约每秒 5 张共享图。JPEG 质量为:
publish_jpeg_quality:80写文件时没有直接覆盖 latest.jpg,而是先写临时文件:
latest.jpg.tmp写完以后再使用 os.replace() 原子替换成:
latest.jpg这样做的好处是,Qwen-ai 读取图片时不会读到一张只写了一半的坏图。对于两个进程共享文件来说,这个细节很重要。
2.Qwen-ai 主动监管
主脚本是:
/home/sunrise/Desktop/Qwen-ai/driver_safety_supervisor.py#!/usr/bin/env python3
import base64
import glob
import json
import os
import random
import re
import shutil
import subprocess
import sys
import threading
import time
from dataclasses import dataclass
from datetime import datetime
from pathlib import Path
from typing import List, Optional, Tuple
import cv2
import requests
from dotenv import load_dotenv
@dataclass
class AppConfig:
api_key: str
vision_model: str
camera_source: str
camera_index: int
camera_probe_max: int
camera_width: int
camera_height: int
camera_fps: int
camera_fourcc: str
camera_drain_frames: int
capture_thread_interval_sec: float
interval_sec: float
upload_width: int
upload_height: int
upload_jpeg_quality: int
request_connect_timeout_sec: float
request_timeout_sec: float
infer_min_interval_sec: float
thinking_enabled: bool
api_base_url: str
shared_frame_path: Path
shared_frame_wait_sec: float
runtime_dir: Path
tts_dir: Path
def env_bool(name: str, default: bool) -> bool:
raw = os.getenv(name)
if raw is None:
return default
value = raw.strip().lower()
return value in {"1", "true", "yes", "on"}
def load_config() -> AppConfig:
load_dotenv()
api_key = os.getenv("DASHSCOPE_API_KEY", "").strip()
if not api_key:
raise RuntimeError("Missing DASHSCOPE_API_KEY in environment.")
runtime_dir = Path(os.getenv("RUNTIME_DIR", "runtime")).resolve()
runtime_dir.mkdir(parents=True, exist_ok=True)
tts_dir = Path(os.getenv("TTS_DIR", "tts")).resolve()
return AppConfig(
api_key=api_key,
vision_model=os.getenv("VISION_MODEL", "qwen3.6-plus"),
camera_source=os.getenv("CAMERA_SOURCE", "usb").strip().lower(),
camera_index=int(os.getenv("CAMERA_INDEX", "0")),
camera_probe_max=int(os.getenv("CAMERA_PROBE_MAX", "6")),
camera_width=int(os.getenv("CAMERA_WIDTH", "640")),
camera_height=int(os.getenv("CAMERA_HEIGHT", "360")),
camera_fps=int(os.getenv("CAMERA_FPS", "30")),
camera_fourcc=os.getenv("CAMERA_FOURCC", "MJPG").strip().upper(),
camera_drain_frames=int(os.getenv("CAMERA_DRAIN_FRAMES", "8")),
capture_thread_interval_sec=float(os.getenv("CAPTURE_THREAD_INTERVAL_SEC", "0.03")),
interval_sec=float(os.getenv("CAPTURE_INTERVAL_SEC", "1")),
upload_width=int(os.getenv("UPLOAD_WIDTH", "640")),
upload_height=int(os.getenv("UPLOAD_HEIGHT", "360")),
upload_jpeg_quality=int(os.getenv("UPLOAD_JPEG_QUALITY", "55")),
request_connect_timeout_sec=float(os.getenv("REQUEST_CONNECT_TIMEOUT_SEC", "0.8")),
request_timeout_sec=float(os.getenv("REQUEST_TIMEOUT_SEC", "2.5")),
infer_min_interval_sec=float(os.getenv("INFER_MIN_INTERVAL_SEC", "3")),
thinking_enabled=env_bool("THINKING_ENABLED", False),
api_base_url=os.getenv("DASHSCOPE_BASE_URL", "https://dashscope.aliyuncs.com/compatible-mode/v1"),
shared_frame_path=Path(os.getenv("SHARED_FRAME_PATH", "/tmp/rdk_shared_camera/latest.jpg")).resolve(),
shared_frame_wait_sec=float(os.getenv("SHARED_FRAME_WAIT_SEC", "5")),
runtime_dir=runtime_dir,
tts_dir=tts_dir,
)
def log(message: str) -> None:
now = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"[{now}] {message}", flush=True)
def frame_to_data_url(config: AppConfig, frame) -> str:
target_w = max(1, config.upload_width)
target_h = max(1, config.upload_height)
if frame.shape[1] != target_w or frame.shape[0] != target_h:
frame = cv2.resize(frame, (target_w, target_h), interpolation=cv2.INTER_AREA)
quality = min(95, max(30, config.upload_jpeg_quality))
ok, encoded = cv2.imencode(".jpg", frame, [int(cv2.IMWRITE_JPEG_QUALITY), int(quality)])
if not ok:
raise RuntimeError("Failed to encode frame to JPEG.")
b64 = base64.b64encode(encoded.tobytes()).decode("ascii")
return f"data:image/jpeg;base64,{b64}"
def extract_json_text(raw_text: str) -> str:
raw_text = raw_text.strip()
fenced = re.search(r"```(?:json)?\s*(\{.*?\})\s*```", raw_text, re.S)
if fenced:
return fenced.group(1)
direct = re.search(r"\{.*\}", raw_text, re.S)
if direct:
return direct.group(0)
return raw_text
def normalize_category(raw_category: str) -> str:
category = raw_category.strip().lower()
mapping = {
"normal": "normal",
"angry": "angry",
"eyes_closed": "eyes_closed",
"phone_use": "phone_use",
"drinking": "drinking",
"愤怒": "angry",
"生气": "angry",
"闭眼": "eyes_closed",
"疲劳": "eyes_closed",
"玩手机": "phone_use",
"看手机": "phone_use",
"喝水": "drinking",
}
return mapping.get(category, "normal")
def analyze_driver_status(config: AppConfig, frame, session: requests.Session) -> Tuple[bool, str, str]:
data_url = frame_to_data_url(config, frame)
system_prompt = (
"判断驾驶行为类别,只能是 normal、angry、eyes_closed、phone_use、drinking。"
"仅输出 JSON。"
)
user_prompt = '{"category":"normal|angry|eyes_closed|phone_use|drinking"}'
payload = {
"model": config.vision_model,
"temperature": 0.1,
"messages": [
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": [
{"type": "text", "text": user_prompt},
{"type": "image_url", "image_url": {"url": data_url}},
],
},
],
}
if not config.thinking_enabled:
payload["enable_thinking"] = False
headers = {
"Authorization": f"Bearer {config.api_key}",
"Content-Type": "application/json",
}
url = f"{config.api_base_url}/chat/completions"
resp = session.post(
url,
headers=headers,
json=payload,
timeout=(config.request_connect_timeout_sec, config.request_timeout_sec),
)
resp.raise_for_status()
body = resp.json()
raw_content = body["choices"][0]["message"]["content"]
if isinstance(raw_content, list):
# Compatibility for models returning structured content blocks.
raw_text = "\n".join(
block.get("text", "") if isinstance(block, dict) else str(block)
for block in raw_content
)
else:
raw_text = str(raw_content)
parsed_text = extract_json_text(raw_text)
category = "normal"
try:
parsed = json.loads(parsed_text)
category = normalize_category(str(parsed.get("category", "normal")))
except json.JSONDecodeError:
fallback_mapping = [
("angry", ["愤怒", "生气", "angry"]),
("eyes_closed", ["闭眼", "疲劳", "eyes_closed"]),
("phone_use", ["玩手机", "看手机", "phone_use"]),
("drinking", ["喝水", "drinking"]),
]
for name, keys in fallback_mapping:
if any(k in raw_text for k in keys):
category = name
break
abnormal = category != "normal"
return abnormal, category, raw_text
def choose_local_audio(config: AppConfig, category: str) -> Path:
category_dir = config.tts_dir / category
if not category_dir.exists() or not category_dir.is_dir():
raise RuntimeError(f"Audio category directory not found: {category_dir}")
audio_files: List[Path] = []
for pattern in ["*.mp3", "*.wav", "*.m4a", "*.ogg"]:
audio_files.extend(sorted(category_dir.glob(pattern)))
if not audio_files:
raise RuntimeError(f"No audio files in category directory: {category_dir}")
return random.choice(audio_files)
def play_audio(audio_path: Path) -> None:
player_cmds = [
["ffplay", "-nodisp", "-autoexit", "-loglevel", "error", str(audio_path)],
["mpg123", "-q", str(audio_path)],
["mpv", "--no-video", "--really-quiet", str(audio_path)],
["cvlc", "--play-and-exit", str(audio_path)],
["aplay", str(audio_path)],
["paplay", str(audio_path)],
]
for cmd in player_cmds:
if shutil.which(cmd[0]):
subprocess.run(cmd, check=False)
return
log("No audio player found (ffplay/aplay/paplay). Alert audio saved but not played.")
def save_snapshot(config: AppConfig, frame) -> Path:
snap_path = config.runtime_dir / "latest.jpg"
cv2.imwrite(str(snap_path), frame)
return snap_path
def get_camera_candidates(config: AppConfig) -> List[int]:
candidates: List[int] = []
available_video_nodes = {
int(m.group(1))
for p in glob.glob("/dev/video*")
for m in [re.search(r"/dev/video(\d+)$", p)]
if m
}
if config.camera_index >= 0 and config.camera_index in available_video_nodes:
candidates.append(config.camera_index)
for dev_path in sorted(glob.glob("/dev/video*")):
matched = re.search(r"/dev/video(\d+)$", dev_path)
if not matched:
continue
idx = int(matched.group(1))
if idx not in candidates:
candidates.append(idx)
if available_video_nodes:
for idx in range(max(0, config.camera_probe_max)):
if idx not in candidates and idx in available_video_nodes:
candidates.append(idx)
return candidates
def describe_video_nodes() -> str:
nodes = sorted(glob.glob("/dev/video*"))
if not nodes:
return "none"
return ", ".join(nodes)
class UsbCameraSource:
def __init__(self, cap):
self.cap = cap
def read(self, drain_frames: int = 1):
# Drain buffered frames first, so retrieve() returns the most recent image.
for _ in range(max(0, drain_frames - 1)):
if not self.cap.grab():
break
return self.cap.read()
def release(self) -> None:
self.cap.release()
class SharedJpegFrameSource:
def __init__(self, frame_path: Path, wait_sec: float):
self.frame_path = frame_path
self.wait_sec = max(0.0, wait_sec)
self.last_mtime_ns = -1
def read(self, drain_frames: int = 1):
deadline = time.time() + self.wait_sec
while True:
try:
stat = self.frame_path.stat()
if stat.st_size > 0 and stat.st_mtime_ns != self.last_mtime_ns:
frame = cv2.imread(str(self.frame_path))
if frame is not None:
self.last_mtime_ns = stat.st_mtime_ns
return True, frame
except FileNotFoundError:
pass
if time.time() >= deadline:
return False, None
time.sleep(0.03)
def release(self) -> None:
return
def open_usb_camera(config: AppConfig):
errors: List[str] = []
candidates = get_camera_candidates(config)
if not candidates:
raise RuntimeError(
"No /dev/video* candidates available for USB camera. "
"The camera is visible on USB only after the kernel creates a video device. "
"Check: ls -l /dev/video*; v4l2-ctl --list-devices; dmesg | grep -iE 'uvc|video|1b3f|2002'."
)
backend = cv2.CAP_V4L2 if sys.platform.startswith("linux") else cv2.CAP_ANY
for idx in candidates:
log(f"Trying USB camera /dev/video{idx}...")
cap = cv2.VideoCapture(idx, backend)
if not cap.isOpened():
errors.append(f"/dev/video{idx}: open failed")
cap.release()
continue
if config.camera_fourcc:
fourcc = cv2.VideoWriter_fourcc(*config.camera_fourcc[:4].ljust(4))
cap.set(cv2.CAP_PROP_FOURCC, fourcc)
if config.camera_width > 0:
cap.set(cv2.CAP_PROP_FRAME_WIDTH, config.camera_width)
if config.camera_height > 0:
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, config.camera_height)
if config.camera_fps > 0:
cap.set(cv2.CAP_PROP_FPS, config.camera_fps)
ok = False
for _ in range(5):
ok, _ = UsbCameraSource(cap).read(drain_frames=1)
if ok:
break
time.sleep(0.1)
if ok:
actual_w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
actual_h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
actual_fps = cap.get(cv2.CAP_PROP_FPS)
log(f"USB camera /dev/video{idx} opened at {actual_w}x{actual_h}@{actual_fps:.1f}.")
return UsbCameraSource(cap), f"usb:{idx}"
errors.append(f"/dev/video{idx}: opened but read failed")
cap.release()
raise RuntimeError(
f"No readable USB camera found. visible_nodes={describe_video_nodes()}; "
f"candidates={candidates}; errors={'; '.join(errors)}"
)
def open_working_camera(config: AppConfig):
if config.camera_source in {"shared", "shared_jpeg", "file"}:
return SharedJpegFrameSource(config.shared_frame_path, config.shared_frame_wait_sec), f"shared_jpeg:{config.shared_frame_path}"
return open_usb_camera(config)
def main() -> int:
try:
config = load_config()
except Exception as exc:
print(f"Configuration error: {exc}", file=sys.stderr)
return 1
log("Starting driver safety supervisor...")
log(
f"Vision model: {config.vision_model} | Camera: USB | "
f"Camera source: {config.camera_source} | "
f"Camera target: /dev/video{config.camera_index}, "
f"Shared frame: {config.shared_frame_path} | "
f"{config.camera_width}x{config.camera_height}@{config.camera_fps}, fourcc={config.camera_fourcc or 'default'} | "
f"Drain frames: {config.camera_drain_frames} | "
f"Capture thread interval: {config.capture_thread_interval_sec}s | "
f"Upload: {config.upload_width}x{config.upload_height}@q{config.upload_jpeg_quality} | "
f"Req timeout: {config.request_timeout_sec}s | Infer interval: {config.infer_min_interval_sec}s | "
f"Thinking enabled: {config.thinking_enabled} | Local audio dir: {config.tts_dir}"
)
try:
camera, camera_desc = open_working_camera(config)
log(f"Using camera: {camera_desc}")
except Exception as exc:
print(f"Failed to open camera: {exc}", file=sys.stderr)
return 1
state_lock = threading.Lock()
latest_capture_frame: Optional[object] = None
latest_capture_ts: float = 0.0
latest_frame: Optional[object] = None
latest_frame_ts: float = 0.0
stop_event = threading.Event()
def capture_worker() -> None:
nonlocal camera, camera_desc, latest_capture_frame, latest_capture_ts
while not stop_event.is_set():
ok, frame = camera.read(drain_frames=max(1, config.camera_drain_frames))
if not ok:
if config.camera_source in {"shared", "shared_jpeg", "file"}:
log("No fresh shared frame available yet.")
stop_event.wait(0.3)
continue
log("Camera frame capture failed in capture thread, trying to reopen camera.")
camera.release()
try:
camera, camera_desc = open_working_camera(config)
log(f"Camera reopened successfully: {camera_desc}")
except Exception as exc:
log(f"Camera reopen failed in capture thread: {exc}")
stop_event.wait(0.3)
continue
with state_lock:
latest_capture_frame = frame
latest_capture_ts = time.time()
pause = max(0.0, config.capture_thread_interval_sec)
if pause > 0:
stop_event.wait(pause)
def inference_worker() -> None:
nonlocal latest_frame, latest_frame_ts
session = requests.Session()
last_infer_at = 0.0
while not stop_event.is_set():
frame = None
frame_ts = 0.0
now = time.time()
min_gap = max(0.0, config.infer_min_interval_sec)
if now - last_infer_at < min_gap:
stop_event.wait(min(0.05, min_gap - (now - last_infer_at)))
continue
with state_lock:
if latest_frame is not None:
frame = latest_frame
frame_ts = latest_frame_ts
latest_frame = None
if frame is None:
stop_event.wait(0.02)
continue
try:
last_infer_at = time.time()
abnormal, category, reason_text = analyze_driver_status(config, frame, session)
latency = time.time() - frame_ts
log(f"Vision result abnormal={abnormal}; category={category}; latency={latency:.2f}s; raw={reason_text}")
if abnormal:
audio = choose_local_audio(config, category)
log(f"Abnormal detected: {category}, playing: {audio.name}")
play_audio(audio)
else:
log("No abnormal state, no speech generated.")
except requests.Timeout:
log(f"Vision request timed out (> {config.request_timeout_sec}s), skipped this frame.")
except Exception as exc:
log(f"Model request failed: {exc}")
session.close()
worker = threading.Thread(target=inference_worker, name="vision-worker", daemon=True)
capture = threading.Thread(target=capture_worker, name="capture-worker", daemon=True)
capture.start()
worker.start()
try:
while True:
start_ts = time.time()
sampled_frame = None
sampled_ts = 0.0
with state_lock:
if latest_capture_frame is not None:
sampled_frame = latest_capture_frame.copy()
sampled_ts = latest_capture_ts
if sampled_frame is None:
log("No captured frame available yet, skipping this sampling cycle.")
else:
snap = save_snapshot(config, sampled_frame)
log(f"Captured frame: {snap}")
with state_lock:
latest_frame = sampled_frame
latest_frame_ts = sampled_ts
elapsed = time.time() - start_ts
sleep_time = max(0.0, config.interval_sec - elapsed)
time.sleep(sleep_time)
except KeyboardInterrupt:
log("Interrupted by user.")
finally:
stop_event.set()
capture.join(timeout=2.0)
worker.join(timeout=2.0)
camera.release()
return 0
if __name__ == "__main__":
raise SystemExit(main())
它的目标是对摄像头画面进行行为识别,判断当前驾驶员或被监管对象是否处于异常状态。当前识别类别包括:
normal:正常 angry:愤怒 eyes_closed:闭眼 phone_use:玩手机 drinking:喝水如果识别结果是 normal,程序不会播放提醒语音。如果识别结果不是 normal,就从本地对应分类的 TTS 音频目录里随机选择一条语音播放。
因为是直接将图片上传给云端做视觉分析所以识别类别可以非常灵活,包括吸烟、应用场景也可以很灵活,不只是驾驶员状态监测还可以是老人陪护,儿童玩具等。
本地语音目录结构:
tts/ angry/ eyes_closed/ phone_use/ drinking/每个分类目录中可以放 .mp3、.wav、.m4a、.ogg 等音频文件。程序会随机选择其中一个播放,这样提醒语音不会每次都完全一样。
3.Qwen-ai 如何调用大模型
Qwen-ai 使用 DashScope 的 OpenAI-compatible 接口,调用路径:
https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions程序会把当前画面编码成 JPEG,然后转成 base64 data URL,作为图片输入传给模型。
系统提示词非常克制,只要求模型判断类别,这样做就是为了提高模型的响应速度,因为采样频率非常高每隔1上传一次,模型回复太慢会导致消息队列堆积和明显的延迟。
判断驾驶行为类别,只能是 normal、angry、eyes_closed、phone_use、drinking。仅输出 JSON。用户提示则要求返回:
{"category":"normal|angry|eyes_closed|phone_use|drinking"}这样做的目的是让模型输出尽量稳定,不要返回长篇解释。程序后面只需要解析 JSON 里的 category 字段即可。
如果模型返回的是中文,比如“闭眼”“疲劳”“玩手机”“喝水”,程序也做了映射:
愤怒 / 生气 -> angry 闭眼 / 疲劳 -> eyes_closed 玩手机 / 看手机 -> phone_use 喝水 -> drinking如果解析失败,程序还会在原始文本里搜索关键词,尽量兜底判断。
Tips:记得关闭视觉模型的思考模式不然回复会非常非常慢,至于阿里云api key的申请可以前往:
大模型服务平台百炼控制台![]() https://bailian.console.aliyun.com/cn-beijing/#/home
https://bailian.console.aliyun.com/cn-beijing/#/home
4.Qwen-ai 的多线程结构
Qwen-ai 不是简单地“读取一张图、请求一次模型、等待返回、再读下一张图”。那样会导致摄像头采集和网络请求互相阻塞。
当前脚本使用了两个线程:
(1)采集线程 capture_worker:它负责不断从共享 JPEG 读取最新画面,并保存到内存变量中。
(2)推理线程 inference_worker:它负责按照最小间隔取出一帧画面,上传给 Qwen 模型分析。
主循环则每隔:
CAPTURE_INTERVAL_SEC=1从最新采集画面里取样一次,并保存快照到:
runtime/latest.jpg这种结构的好处是,即使某一次云端请求变慢,也不会完全阻塞画面采集。采集线程和推理线程分离以后,程序整体响应更稳定。
在读取共享 JPEG 时,程序还会检查文件修改时间 mtime。只有发现共享图片有更新,才认为读到了新帧。如果一直没有新图片,会等待最多:
SHARED_FRAME_WAIT_SEC=5超过 5 秒还没有新图,就返回失败,并打印日志。
Tips:这里提到了主循环每个1s就会上传一次,这对大模型调用来说频率非常高但是这样才能保证驾驶员安全监测的实时性,如果你没有这样高要求的采样场景可以10s或者20s采样一次,因为请求太快-token消耗也快-钱包消耗更快~

实测:100w tokens大概能够连续使用1h(1s上传一次)
五、UART 控制模块:ESP32S3 控制 RDK X5
1.UART控制脚本
主脚本是:
/home/sunrise/Desktop/uart-control/uart_control.py#!/usr/bin/env python3
import argparse
import os
import signal
import subprocess
import sys
import time
from pathlib import Path
from typing import Optional
import serial
TRACKING_DIR = Path("/home/sunrise/Desktop/tracking-face")
QWEN_DIR = Path("/home/sunrise/Desktop/Qwen-ai")
TRACKING_SCRIPT = TRACKING_DIR / "tracking_face.py"
QWEN_SCRIPT = QWEN_DIR / "driver_safety_supervisor.py"
QWEN_VENV_ACTIVATE = QWEN_DIR / ".venv" / "bin" / "activate"
SHARED_FRAME = Path("/tmp/rdk_shared_camera/latest.jpg")
class ScriptManager:
def __init__(self, args: argparse.Namespace):
self.args = args
self.tracking_proc: Optional[subprocess.Popen] = None
self.qwen_proc: Optional[subprocess.Popen] = None
def start_all(self) -> None:
self.start_tracking()
self.wait_for_shared_frame()
self.start_qwen()
def stop_all(self) -> None:
self.stop_qwen()
self.stop_tracking()
def start_tracking(self) -> None:
if self.is_running(self.tracking_proc):
log("tracking-face already running.")
return
if self.external_script_running("tracking_face.py"):
log("tracking-face is already running outside uart-control.")
return
cmd = [
sys.executable,
str(TRACKING_SCRIPT),
"--publish-frame",
str(SHARED_FRAME),
]
if self.args.show_tracking:
cmd.append("--show")
log(f"Starting tracking-face: {' '.join(cmd)}")
self.tracking_proc = subprocess.Popen(
cmd,
cwd=str(TRACKING_DIR),
start_new_session=True,
)
def start_qwen(self) -> None:
if self.is_running(self.qwen_proc):
log("Qwen-ai already running.")
return
if self.external_script_running("driver_safety_supervisor.py"):
log("Qwen-ai is already running outside uart-control.")
return
env = os.environ.copy()
env["CAMERA_SOURCE"] = "shared_jpeg"
env["SHARED_FRAME_PATH"] = str(SHARED_FRAME)
if not QWEN_VENV_ACTIVATE.exists():
raise RuntimeError(f"Qwen-ai virtualenv activate script not found: {QWEN_VENV_ACTIVATE}")
command = f"source '{QWEN_VENV_ACTIVATE}' && python '{QWEN_SCRIPT}'"
cmd = ["bash", "-lc", command]
log(f"Starting Qwen-ai: {' '.join(cmd)}")
self.qwen_proc = subprocess.Popen(
cmd,
cwd=str(QWEN_DIR),
env=env,
start_new_session=True,
)
def stop_tracking(self) -> None:
self.tracking_proc = self.stop_process(self.tracking_proc, "tracking-face")
self.stop_external_script("tracking_face.py", "tracking-face")
def stop_qwen(self) -> None:
self.qwen_proc = self.stop_process(self.qwen_proc, "Qwen-ai")
self.stop_external_script("driver_safety_supervisor.py", "Qwen-ai")
def wait_for_shared_frame(self) -> None:
deadline = time.time() + self.args.shared_frame_timeout
while time.time() < deadline:
if SHARED_FRAME.exists() and SHARED_FRAME.stat().st_size > 0:
return
time.sleep(0.1)
log(f"Shared frame not ready after {self.args.shared_frame_timeout:.1f}s; starting Qwen-ai anyway.")
def reap_exited(self) -> None:
if self.tracking_proc is not None and self.tracking_proc.poll() is not None:
log(f"tracking-face exited with code {self.tracking_proc.returncode}.")
self.tracking_proc = None
if self.qwen_proc is not None and self.qwen_proc.poll() is not None:
log(f"Qwen-ai exited with code {self.qwen_proc.returncode}.")
self.qwen_proc = None
@staticmethod
def is_running(proc: Optional[subprocess.Popen]) -> bool:
return proc is not None and proc.poll() is None
@staticmethod
def external_script_running(script_name: str) -> bool:
result = subprocess.run(
["pgrep", "-f", script_name],
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL,
check=False,
)
return result.returncode == 0
def stop_external_script(self, script_name: str, name: str) -> None:
result = subprocess.run(
["pgrep", "-f", script_name],
stdout=subprocess.PIPE,
stderr=subprocess.DEVNULL,
text=True,
check=False,
)
if result.returncode != 0:
return
own_pid = os.getpid()
managed_pids = {
proc.pid
for proc in [self.tracking_proc, self.qwen_proc]
if proc is not None
}
pids = [
int(line)
for line in result.stdout.splitlines()
if line.strip().isdigit()
and int(line) != own_pid
and int(line) not in managed_pids
]
if not pids:
return
log(f"Stopping external {name} process(es): {pids}")
for pid in pids:
try:
os.kill(pid, signal.SIGTERM)
except ProcessLookupError:
pass
deadline = time.time() + self.args.stop_timeout
while time.time() < deadline:
if not any(process_exists(pid) for pid in pids):
return
time.sleep(0.1)
for pid in pids:
if process_exists(pid):
try:
os.kill(pid, signal.SIGKILL)
except ProcessLookupError:
pass
def stop_process(self, proc: Optional[subprocess.Popen], name: str) -> Optional[subprocess.Popen]:
if not self.is_running(proc):
log(f"{name} is not running.")
return None
log(f"Stopping {name}...")
try:
os.killpg(proc.pid, signal.SIGTERM)
proc.wait(timeout=self.args.stop_timeout)
except subprocess.TimeoutExpired:
log(f"{name} did not stop in time, killing.")
os.killpg(proc.pid, signal.SIGKILL)
proc.wait(timeout=2)
return None
def parse_command(raw: bytes) -> Optional[int]:
for value in raw:
if value in {0x01, 0x02, 0x03}:
return value
text = raw.decode("ascii", errors="ignore").strip().lower()
if not text:
return None
if text.startswith("0x"):
text = text[2:]
try:
value = int(text, 16)
except ValueError:
return None
return value if value in {0x01, 0x02, 0x03} else None
def log(message: str) -> None:
now = time.strftime("%Y-%m-%d %H:%M:%S")
print(f"[{now}] {message}", flush=True)
def process_exists(pid: int) -> bool:
try:
os.kill(pid, 0)
except ProcessLookupError:
return False
except PermissionError:
return True
return True
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser(description="UART command controller for tracking-face and Qwen-ai.")
parser.add_argument("--port", default="/dev/ttyS1", help="UART device for BOARD pin 8 TXD and pin 10 RXD.")
parser.add_argument("--baudrate", type=int, default=115200)
parser.add_argument("--timeout", type=float, default=0.2)
parser.add_argument("--stop-timeout", type=float, default=5.0)
parser.add_argument("--shared-frame-timeout", type=float, default=5.0)
parser.add_argument("--show-tracking", action="store_true", help="Start tracking-face with preview window.")
return parser.parse_args()
def main() -> int:
args = parse_args()
manager = ScriptManager(args)
running = True
def stop(_signum, _frame):
nonlocal running
running = False
signal.signal(signal.SIGINT, stop)
signal.signal(signal.SIGTERM, stop)
log(f"Opening UART {args.port} @ {args.baudrate} baud.")
try:
uart = serial.Serial(args.port, args.baudrate, timeout=args.timeout)
except Exception as exc:
print(f"Failed to open UART {args.port}: {exc}", file=sys.stderr)
return 1
log("Ready. Commands: 0x01=start tracking then Qwen-ai, 0x02=stop both, 0x03=stop Qwen-ai only.")
try:
while running:
manager.reap_exited()
raw = uart.readline()
if not raw:
raw = uart.read(uart.in_waiting or 1)
command = parse_command(raw)
if command is None:
continue
log(f"Received command 0x{command:02X}.")
if command == 0x01:
manager.start_all()
elif command == 0x02:
manager.stop_all()
elif command == 0x03:
manager.stop_qwen()
finally:
uart.close()
manager.stop_all()
return 0
if __name__ == "__main__":
raise SystemExit(main())
这个脚本的职责非常明确:实时监听 UART 串口收到的命令,然后启动或停止 tracking-face 和 Qwen-ai。
默认串口参数是:
串口设备:/dev/ttyS1 波特率:115200 超时时间:0.2 秒波特率 115200 是嵌入式开发里最常用的串口速度之一,非常适合传输这种极短控制命令。
这里的 UART 命令设计得非常简单:
0x01:先启动人脸追踪 tracking-face,再启动 Qwen-ai
0x02:关闭 tracking-face 和 Qwen-ai
0x03:只关闭 Qwen-ai,人脸追踪保持运行脚本同时支持两种发送格式。
(1)原始字节,比如 ESP32S3 直接发送:
0x01(2) ASCII 文本,比如发送:
01或者:
0x01程序都会解析成同一个命令。
2.为什么 0x01 要先启动人脸追踪,再启动 Qwen-ai
收到 0x01 后,脚本执行顺序是:
start_tracking() wait_for_shared_frame() start_qwen()也就是说,它会先启动人脸追踪程序,然后等待共享图片 /tmp/rdk_shared_camera/latest.jpg 出现,最后再启动 Qwen-ai。
这样设计是为了解决摄像头共享链路的启动顺序问题。因为 Qwen-ai 现在不直接打开摄像头,而是读取 tracking-face 发布的共享图片。如果 Qwen-ai 先启动,它可能会发现共享图片还没准备好,然后一直等待或打印没有画面的日志。
所以正确启动顺序必须是:
USB 摄像头 -> tracking-face 打开摄像头 -> 发布 latest.jpg -> Qwen-ai 读取 latest.jpgUART 控制脚本里等待共享帧的超时时间是:
shared_frame_timeout:5 秒如果 5 秒内共享帧准备好了,就正常启动 Qwen-ai。如果 5 秒后还没准备好,脚本也会继续启动 Qwen-ai,但会打印提示日志。这是为了避免因为某些短暂异常导致整个控制流程卡死。
3.进程管理:如何避免重复启动和如何关闭
UART 控制脚本启动子程序时使用的是 subprocess.Popen。同时设置了:
start_new_session=True这样每个子程序会在新的进程组里运行,后面关闭时可以对整个进程组发送信号,而不是只杀掉一个父进程。
关闭逻辑是:
(1)先发送 SIGTERM,让程序正常退出。
(2)等待最多 5 秒。
(3)如果还没退出,再发送 SIGKILL 强制结束。
这个超时时间来自:
stop_timeout:5 秒程序还会用 pgrep -f 检查系统里是否已经有 tracking_face.py 或 driver_safety_supervisor.py 在运行。如果已经有外部启动的同名脚本,UART 控制脚本不会重复启动,避免出现多个程序抢资源。
收到 0x02 时: 先停止 Qwen-ai 再停止 tracking-face
收到 0x03 时: 只停止 Qwen-ai tracking-face 继续运行
这正好符合实际使用场景:有时候我们只想停止大模型行为监管,减少云端请求和语音提醒,但希望摄像头云台继续跟随人脸。
4.systemd 开机自启
UART 控制脚本需要一直监听串口,所以不能依赖用户手动打开终端运行。最终做法是写成 systemd 服务,让它开机自动启动。
服务文件路径是:
/home/sunrise/Desktop/uart-control/uart-control.service核心内容是:
[Unit]
Description=UART Control for Tracking Face and Qwen AI
After=multi-user.target
[Service]
Type=simple
User=sunrise
Group=sunrise
WorkingDirectory=/home/sunrise/Desktop/uart-control
ExecStart=/usr/bin/python3 /home/sunrise/Desktop/uart-control/uart_control.py
Restart=always
RestartSec=2
[Install]
WantedBy=multi-user.target这里有几个关键点。
(1)User=sunrise 表示服务以 sunrise 用户运行,而不是 root。这样更安全,也符合当前工程目录权限。
(2)WorkingDirectory 设置工作目录,避免脚本里相对路径出问题。
(3)ExecStart 是真正启动脚本的命令。
(4)Restart=always 表示如果脚本异常退出,systemd 会自动重启它。
(5)RestartSec=2 表示退出后等待 2 秒再重启,避免异常情况下疯狂重启。
安装服务的命令是:
sudo cp /home/sunrise/Desktop/uart-control/uart-control.service /etc/systemd/system/
sudo systemctl daemon-reload
sudo systemctl enable uart-control.service
sudo systemctl start uart-control.service查看状态:
systemctl status uart-control.service查看实时日志:
journalctl -u uart-control.service -f如果需要停止服务:
sudo systemctl stop uart-control.service如果不想开机自启:
sudo systemctl disable uart-control.service六、电源管理
做嵌入式时,最容易忽略电源。代码写对了,识别也成功了,但舵机一动,开发板重启;或者摄像头画面突然断掉;或者串口莫名其妙乱码。很多时候不是代码问题,而是电源问题。
本项目的电源分成三路:
RDK X5:5V 稳定供电 ESP32S3:5V 稳定供电 舵机:独立 7.4V 供电
舵机必须确认是支持 7.4V 的型号。如果是普通 5V 舵机,不能直接接 7.4V,否则可能烧毁。这里使用独立 7.4V 是为了给舵机足够的电流和扭矩,避免云台运动时电压下跌。
最重要的一点是:
RDK X5、ESP32S3、舵机电源必须共地
共地的意思是,所有模块的 GND 要连在一起。因为 PWM 信号和 UART 信号都是相对于 GND 的电平。如果不共地,RDK X5 输出的 PWM 对舵机来说可能没有明确的高低电平,舵机会抖动、不动,甚至乱动。
Tips:具体的连接方式可见开头的线路连接示意图
七、总结
1.整个系统开机后的流程
(1)RDK X5 上电,Linux 系统启动。
(2)systemd 自动启动 uart-control.service。
(3)uart_control.py 打开 /dev/ttyS1,波特率为 115200,开始监听 UART。
(4)ESP32S3 运行 xiaozhi-esp32 语音交互程序。
(5)用户通过语音触发某个控制意图。
(6)ESP32S3 通过 UART 发送命令,比如 0x01。
(7)RDK X5 收到 0x01。
(8)UART 控制脚本启动 tracking-face。
(9)tracking-face 打开 /dev/video0,开始人脸检测和舵机追踪。
(10)tracking-face 发布共享画面到 /tmp/rdk_shared_camera/latest.jpg。
(11)UART 控制脚本检测到共享画面准备好。
(12)UART 控制脚本激活 Qwen-ai 虚拟环境,并启动 driver_safety_supervisor.py。
(13)Qwen-ai 从共享 JPEG 读取画面,上传给 Qwen 视觉模型分析。
(14)如果识别到异常行为,就播放本地语音提醒。
(15)如果 ESP32S3 发送 0x03,RDK X5 停止 Qwen-ai,但人脸追踪继续运行。
(16)如果 ESP32S3 发送 0x02,RDK X5 停止 Qwen-ai 和 tracking-face。
2.调试过程中的几个关键命令
(1)检查 USB 摄像头:
lsusb
ls -l /dev/video*
v4l2-ctl --list-devices(2)单独测试人脸追踪,不显示窗口:
cd /home/sunrise/Desktop/tracking-face
python3 tracking_face.py(3)显示 OpenCV 调试窗口:
python3 tracking_face.py --show(4)只测试摄像头和人脸检测,不输出舵机 PWM:
python3 tracking_face.py --dry-run --show(5)启动 UART 控制脚本:
cd /home/sunrise/Desktop/uart-control
python3 uart_control.py(6)指定串口和波特率:
python3 uart_control.py --port /dev/ttyS1 --baudrate 115200(7)查看 UART 控制服务日志:
journalctl -u uart-control.service -f(8)查看 Qwen-ai 是否读取到了共享画面:
ls -l /tmp/rdk_shared_camera/latest.jpg如果这个文件一直不存在,说明 tracking-face 没有正常运行,或者摄像头没有正常打开。
3.常见问题和解决思路
(1)Hobot.GPIO is not available。
这通常是因为当前 Python 环境找不到 RDK X5 系统里的 GPIO 包。tracking-face 脚本已经补充了系统 Python 包路径,但如果仍然报错,可以先退出 Qwen-ai 的虚拟环境,再运行 tracking-face:
cd /home/sunrise/Desktop/tracking-face
python3 tracking_face.py(2)qt.qpa.xcb: could not connect to display。
这是因为在没有图形界面的终端里使用了 --show。如果是 SSH 或 systemd 服务环境,不要加 --show。只有在桌面终端中运行时才使用:
python3 tracking_face.py --show(3)水平控制方向反了。
可以使用:
python3 tracking_face.py --normal-pan或者在默认参数里调整 pan 方向。当前项目中水平轴已经默认反向,适配实际云台安装方向。
(4)识别不到人脸。
优先确认 YuNet 模型文件存在:
/home/sunrise/Desktop/tracking-face/models/face_detection_yunet_2023mar.onnx
如果模型文件不存在,程序会回退到 Haar Cascade,识别效果会差很多。建议使用 OpenCV Zoo 的 YuNet 模型。
(5)Qwen-ai 和 tracking-face 不能同时使用摄像头。
解决方法就是当前项目采用的共享图片机制。tracking-face 独占 /dev/video0,Qwen-ai 使用:
CAMERA_SOURCE=shared_jpeg
SHARED_FRAME_PATH=/tmp/rdk_shared_camera/latest.jpg(6)舵机抖动或顿挫。
先检查电源是否足够,舵机是否独立供电,是否共地。很多舵机抖动其实是供电问题。然后再调参数,比如降低增益、增大死区、调整滤波系数、降低最大速度和最大加速度。
(7)UART 没反应。
检查三件事:串口设备是否是 /dev/ttyS1,波特率是否是 115200,TX/RX 是否交叉连接。还要确认 ESP32S3 和 RDK X5 共地。
4.机器人展示
(1)完整实物:

机器人演示
(2)机器人各个部分实际线路连接:
a.理论连接图
b.舵机控制板(电源)与RDK X5连接
舵机控制板(电源)与RDK X5连接的线一共有图中3组
c.ESP32S3与RDK X5连接

ESP32S3与RDK X5连接的线一共有图中1组
d.拼合机器人-第一层

e.拼合机器人-第二层

f.拼合机器人-第三层

g.完整机器人
三层架构+云台舵机:

结语
这个项目最有意思的地方,是它不是单点技术的堆叠,而是一次完整的嵌入式 AI 系统整合。ESP32S3 负责语音交互,RDK X5 负责视觉计算和进程控制,OpenCV 负责本地人脸检测,Qwen 视觉模型负责驾驶行为判断,UART 负责跨板通信,PWM 负责真实物理运动,systemd 负责服务自启动,电源模块负责让整个系统稳定运行。
对于初学者来说,这个项目可以一次性学到很多真实工程中会遇到的问题:摄像头设备识别、Linux 视频设备、Python 虚拟环境、OpenCV 检测、PWM 舵机控制、UART 串口通信、systemd 服务、电源共地、进程启停、模型 API 调用、图像压缩上传等。
这个嵌入式项目真正难的地方,不是让某个模块单独跑起来,而是让所有模块长期稳定地一起工作。摄像头不能被两个程序抢占,舵机不能因为电源波动抖动,串口协议不能设计得太复杂,服务不能依赖手动启动,大模型请求也不能阻塞整个系统。把这些细节一项项处理好以后,项目才从“能跑的 demo”变成“能用的机器人”。

参考链接
- 本项目GitHub仓库:项目Github仓库
 https://github.com/yan-gd/Intelligent-Voice-Monitoring-Robot-Based-on-ESP32S3-RDK-X5.git
https://github.com/yan-gd/Intelligent-Voice-Monitoring-Robot-Based-on-ESP32S3-RDK-X5.git - xiaozhi-esp32 开源项目:https://github.com/78/xiaozhi-esp32https://github.com/78/xiaozhi-esp32
- 嘉立创开源广场PCB文件:https://oshwhub.com/yoyoyan/project_nkgaqghuhttps://oshwhub.com/yoyoyan/project_nkgaqghu

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)