ICLR2026 Best Paper
论文标题:LLMS GET LOST IN MULTI-TURN CONVERSATION
论文地址: https://arxiv.org/pdf/2505.06120
2026论文复现及模型创新组合、上千顶会论文精粹、审稿人方法论、即插即用源码模块
👇🏻扫码即可无偿领取!👇🏻
创新点
-
首次证实主流开源与闭源大模型在多轮欠指定对话中平均性能暴跌 39%,并将下降拆解为能力小幅下降与不可靠性大幅飙升两大核心成分,明确模型一旦出错便难以纠正。
-
提出分片模拟(Sharded Simulation) 框架,将单轮完整指令拆分为多轮逐步披露的信息分片,首次实现单轮与多轮在完全相同任务上的公平对比,精准分离欠指定与多轮交互带来的性能损耗。
方法
本文首先构建了分片模拟框架,将单轮完整指令拆解为多轮逐步披露的信息分片,在代码、数据库、数学等六大生成任务上对15个主流大模型开展超20万次单轮与多轮对话仿真实验,通过GPT-4o-mini实现用户模拟器、回复策略分类与答案抽取,采用平均性能、能力(90分位数)和不可靠性(90-10分位差)三个指标量化模型表现,进而将多轮性能下降拆解为能力损失与不可靠性上升两部分,结合逐步分片实验、温度对照实验、摘要引用分析、回复长度与过早作答统计等多种定量定性分析,挖掘出模型在多轮欠指定对话中迷失的深层行为机制,并通过Recap与Snowball两种干预方案验证缓解策略的有效性,最终形成从可控仿真、公平对比、指标拆解、根因分析到方案验证的完整研究流程。
大模型在单轮与多轮欠指定对话中的表现对比示意图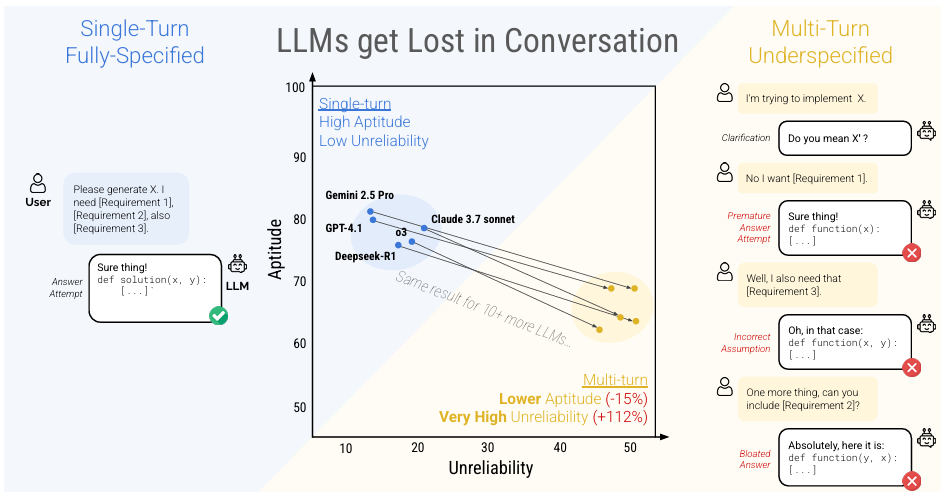
本图通过直观的散点分布与示例对话对比,清晰展示了所有测试的主流大模型在单轮完整指令场景下具备高能力与低不可靠性,而在多轮欠指定对话中均出现能力小幅下降、不可靠性大幅上升的普遍现象,并用具体对话案例呈现出模型因过早给出答案、错误假设后续需求而无法根据用户补充信息修正的 “迷失” 过程,直观印证了本文提出的 LLMs 在多轮对话中迷失的核心发现。
完整指令与分片式多轮指令的对照示意图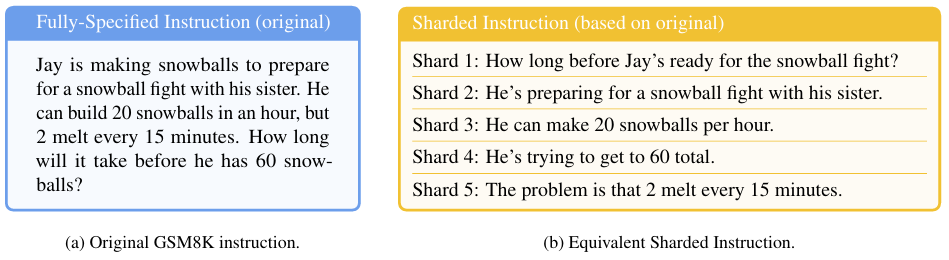
本图通过展示 GSM8K 数据集中同一条数学题的两种呈现形式,清晰对比了单轮下完整给出全部条件的 fully-specified 指令与多轮下将任务意图、背景、参数、约束条件等信息拆分为多个独立信息分片的 sharded instruction 之间的对应关系,直观说明分片过程严格保留原始任务全部信息,仅将其拆解为逐轮披露的原子单元,以此支撑本文可控、公平地模拟用户逐步明确需求的欠指定多轮对话场景。
分片式多轮对话仿真流程示意图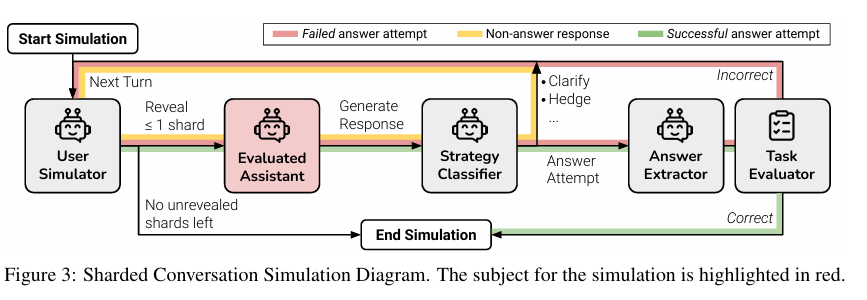
本图完整展示了本文基于分片指令实现的多轮欠指定对话仿真全流程,包括用户模拟器逐轮披露至多一个信息分片、被测试大模型生成回复、系统对回复进行策略分类与答案抽取、任务评估器判断答案正误并决定对话继续或终止的整体闭环,清晰呈现了用户模拟器、策略分类器、答案提取器、任务评估器四大核心组件的协作逻辑,直观体现了如何通过标准化流程模拟真实的多轮交互并客观评估模型在逐步补全信息场景下的表现。
实验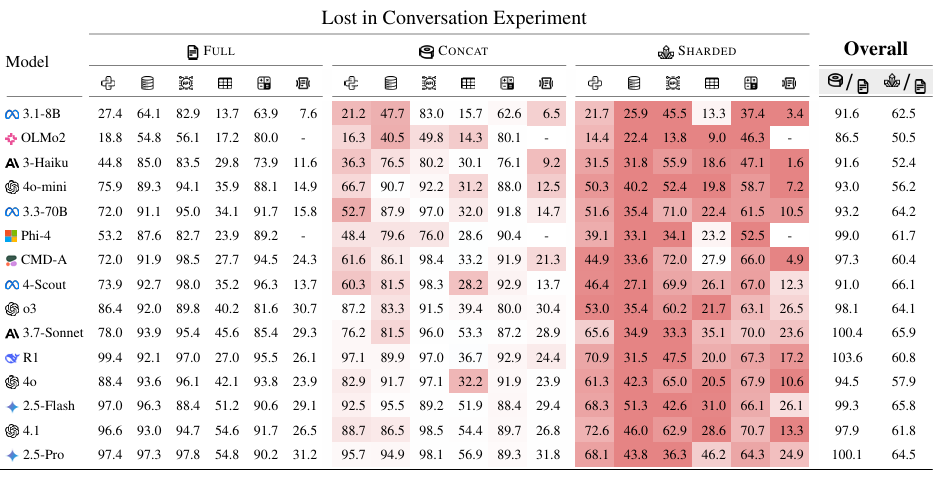 本表是本文核心主实验结果表,汇总了 15 个主流大模型在代码、数据库、API 调用、数学、数据转文本、摘要六大生成任务上,于 FULL 完整单轮、CONCAT 分片拼接单轮、SHARDED 分片多轮三种设置下的平均性能得分,模型按单轮平均得分升序排列,背景色直观标注性能下降幅度,数据显示所有模型在分片多轮场景下均出现显著性能衰减,平均降幅达 39%,且强模型与弱模型的下降趋势高度一致,同时 CONCAT 设置与 FULL 设置性能接近,证明性能损失并非来自指令分片改写,而是多轮欠指定交互本身导致,为 “多轮迷失” 现象提供了关键量化证据。
本表是本文核心主实验结果表,汇总了 15 个主流大模型在代码、数据库、API 调用、数学、数据转文本、摘要六大生成任务上,于 FULL 完整单轮、CONCAT 分片拼接单轮、SHARDED 分片多轮三种设置下的平均性能得分,模型按单轮平均得分升序排列,背景色直观标注性能下降幅度,数据显示所有模型在分片多轮场景下均出现显著性能衰减,平均降幅达 39%,且强模型与弱模型的下降趋势高度一致,同时 CONCAT 设置与 FULL 设置性能接近,证明性能损失并非来自指令分片改写,而是多轮欠指定交互本身导致,为 “多轮迷失” 现象提供了关键量化证据。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)