情感分析API服务-开发一个完整的RESTful API,接收文本返回情感分数,包含模块化设计、单元测试、接口文档
你将要构建什么?
模型:distilbert-base-uncased-finetuned-sst-2-english(英文情感分类,正面/负面)
框架:FastAPI(自动生成接口文档)+ HuggingFace Transformers + Uvicorn(服务器)
功能:接收文本 → 返回情感标签(POSITIVE/NEGATIVE)和置信度分数
产出:可运行的API服务,支持单条和批量请求,附带Swagger文档和客户端示例
练习总目标
最终完成一个项目:
sentiment-api/
├── app/
│ ├── init.py
│ ├── model_loader.py
│ ├── predict.py
│ └── api.py
├── tests/
│ └── test_api.py
├── client.py
├── pyproject.toml
├── uv.lock
└── README.md
你要掌握:
uv init
uv add
uv sync
uv run
uv lock
uv pip
FastAPI
Transformers
单元测试
接口联调
README 编写
第 0 阶段:安装 uv
Windows PowerShell 推荐:
-ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
检查是否安装成功:
uv --version
如果能看到版本号,说明成功。
第 1 阶段:用 uv 创建项目
进入你的练习目录:
cd ”你的项目目录“
创建项目:
uv init sentiment-api
进入项目:
cd sentiment-api
此时你会看到类似:
sentiment-api/
├── .python-version
├── README.md
├── main.py
└── pyproject.toml
第 2 阶段:指定 Python 版本
建议使用 Python 3.11,更稳。
uv python install 3.11
设置项目使用 Python 3.11:
uv python pin 3.11
查看:
type .python-version
预期:
3.11
第 3 阶段:添加依赖
不要手写 requirements.txt,先用 uv 管理。
执行:
uv add fastapi==0.104.1
uv add "uvicorn[standard]==0.24.0"
uv add transformers>=4.40.0
uv add torch>=2.3.0
uv add pydantic==2.5.0
uv add python-multipart==0.0.6
uv add requests==2.31.0
添加开发依赖:
uv add --dev pytest==7.4.3
uv add --dev httpx==0.25.2
这时会自动生成:
pyproject.toml
uv.lock
.venv/
uv.lock 类似前端里的 package-lock.json,用于保证别人安装出来的依赖版本与你一致。
上述命令出现出现的问题 (版本不支持)
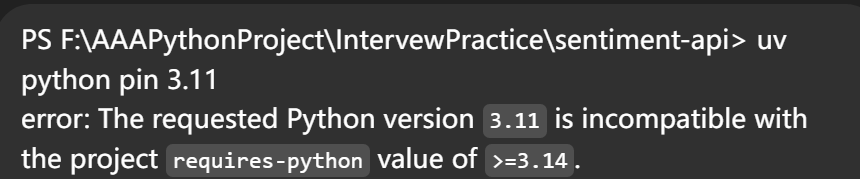
修复解决方案
🔧 第一步:修改 pyproject.toml
打开项目里的:
pyproject.toml
找到这一行:
requires-python = “>=3.14”
👉 改成:
requires-python = “>=3.11,❤️.13”
(推荐这样写,更稳)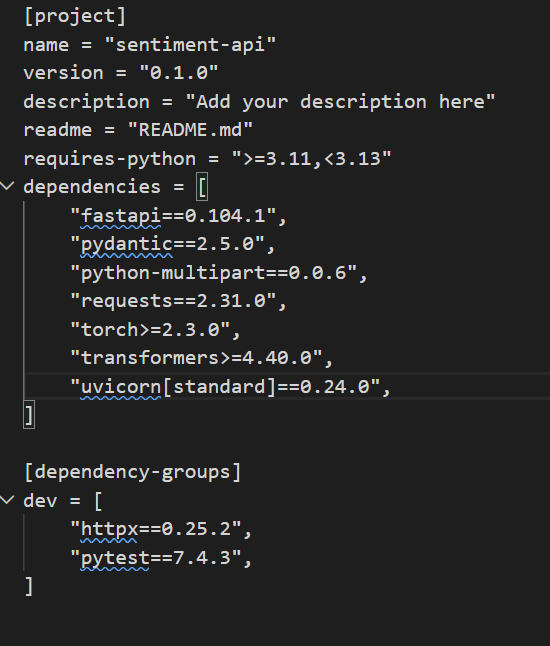
👉 第 2 阶段:项目结构 + 模块设计
PowerShell 写法即可:
New-Item -ItemType Directory -Force app
New-Item -ItemType Directory -Force tests
然后创建文件:
New-Item -ItemType File -Force app\__init__.py
New-Item -ItemType File -Force app\model_loader.py
New-Item -ItemType File -Force app\predict.py
New-Item -ItemType File -Force app\api.py
New-Item -ItemType File -Force tests\test_api.py
New-Item -ItemType File -Force client.py
检查目录:
tree /f
你应该能看到:
app
__init__.py
model_loader.py
predict.py
api.py
tests
test_api.py
client.py
第 3 阶段:写第一个核心模块(model_loader.py)
🎯 这一阶段目标
你要完成:
加载模型 + 缓存模型
✍️ 现在直接做(复制代码)
打开:
app/model_loader.py
写入:
from transformers import pipeline
全局变量,用于缓存模型
_model_pipeline = None
def get_sentiment_pipeline():
"""
加载情感分析模型,并进行缓存。
第一次调用时加载模型,后续直接复用,
避免每次请求都重新加载模型(非常慢)。
"""
global _model_pipeline
if _model_pipeline is None:
print("Loading model for the first time...")
_model_pipeline = pipeline(
task="sentiment-analysis",
model="distilbert-base-uncased-finetuned-sst-2-english"
)
return _model_pipeline
---
为什么要这样写?
如果你不缓存:
pipeline(…)
👉 每次请求都会:
下载模型 / 加载模型(几百MB)
结果:
接口慢到爆炸
✅ 正确做法(你现在写的)
第一次加载模型
后面全部复用
模型缓存(Model Caching)
🎯 下一步(你现在做)
我会带你进入:
👉 predict.py(业务逻辑层)
👉 这是第二个核心模块
我们一步一步来,把这个项目做成“面试能讲”的0级别 👍
第 4 阶段:编写业务推理层 predict.py
打开:
app/predict.py
写入下面代码:
from app.model_loader import get_sentiment_pipeline
def predict_single_text(text: str) -> dict:
"""
单条文本情感分析
"""
if text is None or text.strip() == "":
raise ValueError("text cannot be empty")
sentiment_pipeline = get_sentiment_pipeline()
result = sentiment_pipeline(text)[0]
return {
"sentiment": result["label"],
"score": round(float(result["score"]), 4)
}
def predict_batch_texts(texts: list[str]) -> list[dict]:
"""
批量文本情感分析
"""
if not texts:
raise ValueError("texts cannot be empty")
for text in texts:
if text is None or text.strip() == "":
raise ValueError("texts cannot contain empty text")
sentiment_pipeline = get_sentiment_pipeline()
results = sentiment_pipeline(texts)
return [
{
"sentiment": item["label"],
"score": round(float(item["score"]), 4)
}
for item in results
]
这一层的作用是:
接收文本 → 校验文本 → 调用模型 → 整理返回结果
它不直接处理 HTTP 请求,也不负责启动服务,这样代码更清晰。
第 5 阶段:编写 API 路由层 api.py。
打开:
app/api.py
写入:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
from app.predict import predict_single_text, predict_batch_texts
app = FastAPI(
title="Sentiment Analysis API",
description="A RESTful API for sentiment analysis using FastAPI and HuggingFace.",
version="1.0.0"
)
class PredictRequest(BaseModel):
text: str = Field(..., example="I love AI")
class PredictResponse(BaseModel):
sentiment: str = Field(..., example="POSITIVE")
score: float = Field(..., example=0.999)
class BatchPredictRequest(BaseModel):
texts: list[str] = Field(..., example=["I love AI", "I hate bugs"])
class BatchPredictResponse(BaseModel):
results: list[PredictResponse]
@app.get("/")
def root():
return {"message": "Sentiment Analysis API is running."}
@app.post("/predict", response_model=PredictResponse)
def predict(request: PredictRequest):
try:
return predict_single_text(request.text)
except ValueError as e:
raise HTTPException(status_code=400, detail=str(e))
@app.post("/predict/batch", response_model=BatchPredictResponse)
def predict_batch(request: BatchPredictRequest):
try:
results = predict_batch_texts(request.texts)
return {"results": results}
except ValueError as e:
raise HTTPException(status_code=400, detail=str(e))
第 6 阶段:启动服务测试
在项目根目录执行:
uv run uvicorn app.api:app --reload
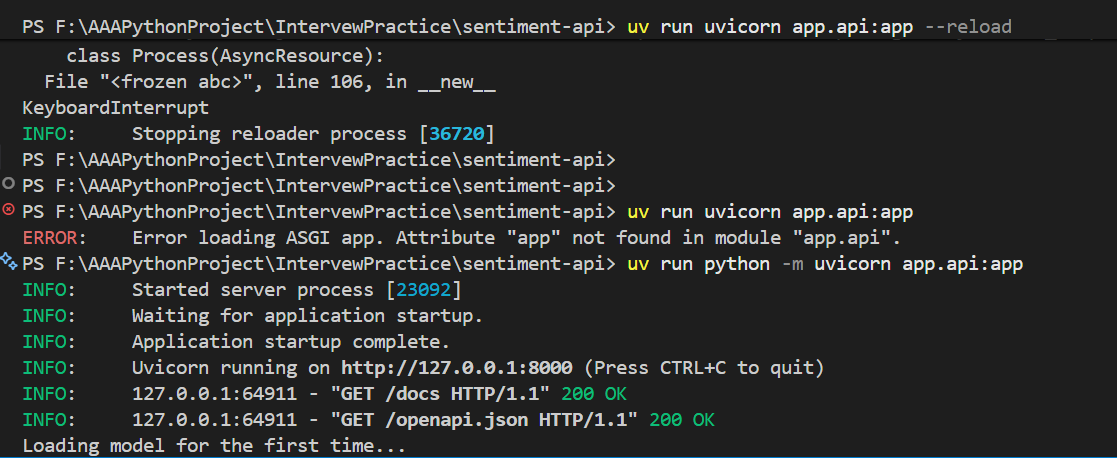
favicon.ico 404 不用管,那只是浏览器自动请求网站图标,不影响项目。
如果成功,会看到类似:
Uvicorn running on http://127.0.0.1:8000
然后打开浏览器访问:
http://127.0.0.1:8000
预期返回:
{
"message": "Sentiment Analysis API is running."
}
接口文档访问:
http://127.0.0.1:8000/docs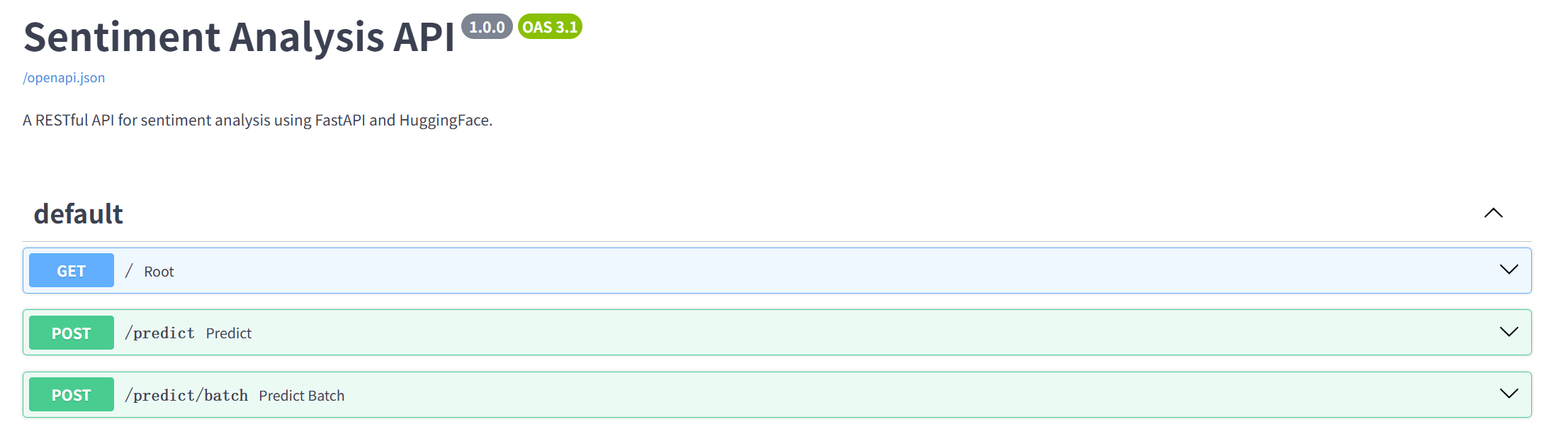
第一次调用 /predict 时会下载/加载模型,可能会慢一点,这是正常的。
然后测试单条预测接口 /predict,请求体:
{
“text”: “I love AI”
}
第一次预测可能会下载模型,稍微慢一点。
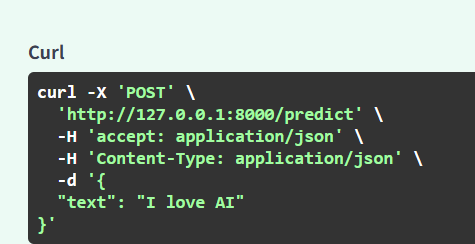
第 7 阶段:客户端联调(非常重要,面试加分点)
🎯 这一阶段目标
你要实现:
写一个 Python 客户端 → 调用你刚写的 API
👉 这一步非常关键,因为它代表:
- ✅ 你不仅会写接口
- ✅ 还会“调用接口”(真实工作场景)
🧱 第一步:写 client.py
打开:
client.py
写入:
import requests
BASE_URL = "http://127.0.0.1:8000"
def call_single_predict():
url = f"{BASE_URL}/predict"
payload = {
"text": "I love this product!"
}
response = requests.post(url, json=payload)
print("=== 单条预测 ===")
print("Status:", response.status_code)
print("Result:", response.json())
def call_batch_predict():
url = f"{BASE_URL}/predict/batch"
payload = {
"texts": [
"I love this product!",
"This is terrible."
]
}
response = requests.post(url, json=payload)
print("\n=== 批量预测 ===")
print("Status:", response.status_code)
print("Result:", response.json())
if __name__ == "__main__":
call_single_predict()
call_batch_predict()
▶️ 第二步:运行客户端
⚠️ 注意:服务必须先运行着(你刚刚已经启动了)
然后开一个新终端,执行:
uv run python client.py
✅ 预期输出
你应该看到类似:
=== 单条预测 ===
Status: 200
Result: {‘sentiment’: ‘POSITIVE’, ‘score’: 0.999}
=== 批量预测 ===
Status: 200
Result: {‘results’: […]}
🧠 这一阶段你要理解
你现在做的是:
服务端(FastAPI) ←→ 客户端(requests)
👉 这就是典型:
前后端联调 / 服务间调用
你现在应该做的操作(标准流程)
1️⃣ 手动执行一次锁定(强化理解)
uv lock
👉 作用:
- 重新解析依赖
- 更新
uv.lock
验证环境可复现(非常关键 ⭐)
先删除环境:
rmdir /s /q .venv
Remove-Item -Recurse -Force .venv
关闭所有 Python 进程(最关键)
如果看到
访问被拒绝 (UnauthorizedAccessException)
执行:
taskkill /F /IM python.exe
👉 强制杀掉所有 Python 进程
然后重新安装:
uv sync
👉 如果能成功: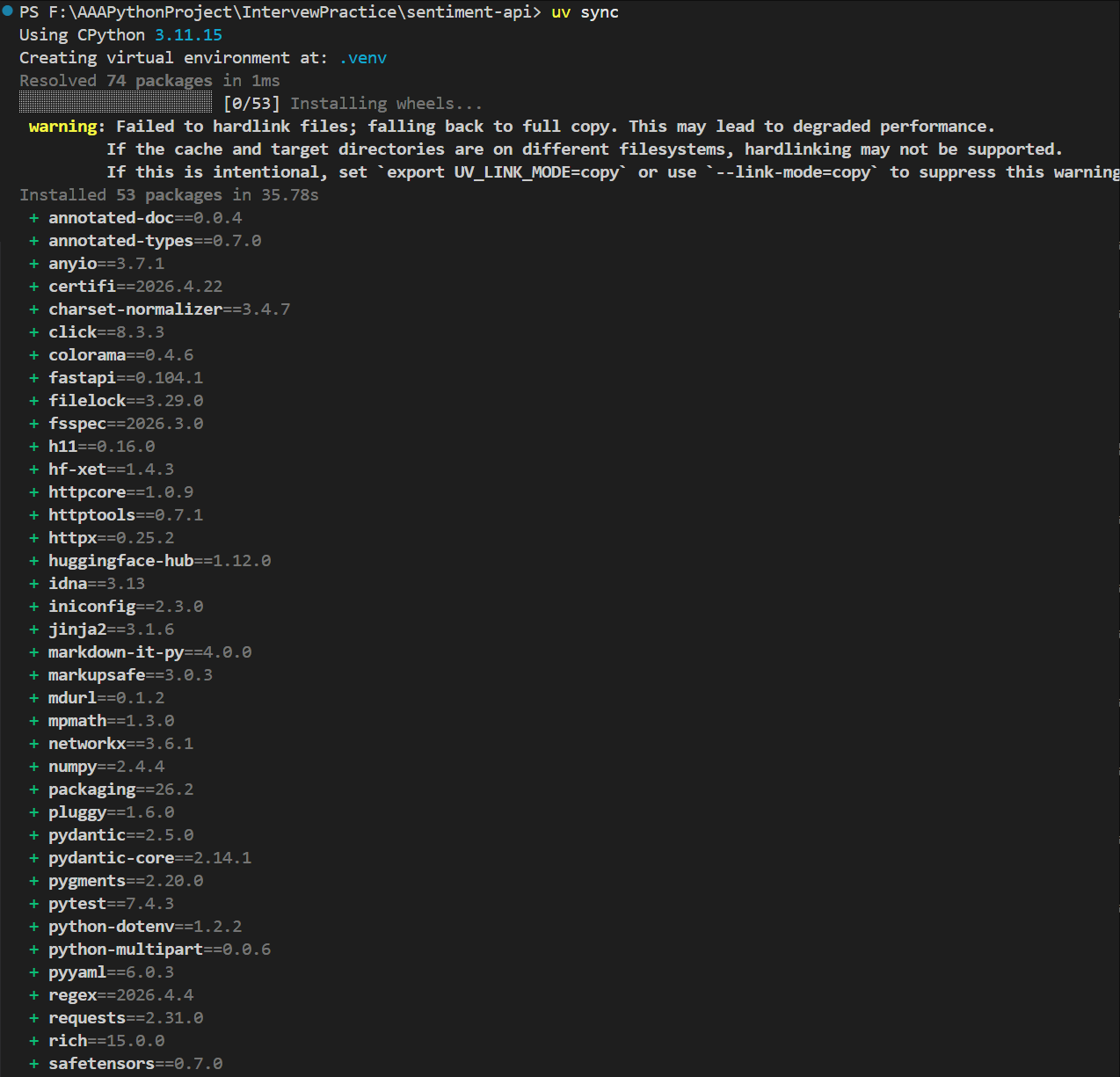
说明你的项目是“可复现”的
阶段总结(你已经完成)
你刚刚做的其实是:
uv lock ✔
删除环境 ✔(正在解决)
uv sync ✔(下一步)
这就是:
工程级依赖复现能力
第 13 阶段:README + 项目复盘
你的目标是把项目变成可交付、可面试讲解的完整案例。
1. 打开 README.md
notepad README.md
把内容改成:
Sentiment Analysis API
基于 FastAPI、HuggingFace Transformers 和 uv 构建的情感分析 RESTful API 服务。
功能
- 单条文本情感分析
- 批量文本情感分析
- RESTful API 封装
- Swagger 接口文档
- Python 客户端调用
- Pytest 单元测试
- uv 依赖管理与环境复现
技术栈
- Python 3.11
- uv
- FastAPI
- Uvicorn
- Transformers
- PyTorch
- Pydantic
- Pytest
- Requests
项目结构
sentiment-api/
├── app/
│ ├── __init__.py
│ ├── model_loader.py
│ ├── predict.py
│ └── api.py
├── tests/
│ └── test_api.py
├── client.py
├── pyproject.toml
├── uv.lock
└── README.md
安装依赖
uv sync
启动服务
uv run python -m uvicorn app.api:app
接口文档
http://127.0.0.1:8000/docs
单条预测
POST `/predict`
{
"text": "I love AI"
}
响应:
{
"sentiment": "POSITIVE",
"score": 0.9999
}
批量预测
POST `/predict/batch`
{
"texts": [
"I love this product!",
"This is terrible."
]
}
客户端调用
uv run python client.py
运行测试
uv run pytest
## 模块设计
- `model_loader.py`:负责加载并缓存 HuggingFace 情感分析模型
- `predict.py`:负责单条文本和批量文本的推理逻辑
- `api.py`:负责 FastAPI 路由、请求体和响应体定义
- `client.py`:负责客户端调用测试
## 项目亮点
1. 使用 uv 管理依赖和虚拟环境,支持环境复现。
2. 使用 FastAPI 自动生成 Swagger 文档。
3. 模型加载使用全局缓存,避免每次请求重复加载模型。
4. 支持单条预测和批量预测。
5. 使用 Pytest 覆盖正常 case 和异常 case。
## 2. 保存后检查
```powershell
Get-Content README.md
3. 面试讲解版
你可以这样讲:
这是一个基于 FastAPI 和 HuggingFace Transformers 的情感分析 API 服务。我将项目拆成模型加载层、业务推理层和 API 路由层。模型层负责加载并缓存预训练模型,避免重复加载;业务层负责输入校验和推理逻辑;API 层负责对外暴露 RESTful 接口。项目同时使用 uv 管理依赖,通过 uv.lock 保证环境可复现,并提供客户端联调脚本和 pytest 单元测试。
下一步可以做:导出 requirements.txt,兼容传统部署。
第 14 阶段:导出 requirements.txt(兼容性)
虽然你用的是 uv,但很多环境(面试/公司)仍然用传统方式。
▶️ 执行:
uv pip freeze > requirements.txt
🔍 检查:
Get-Content requirements.txt
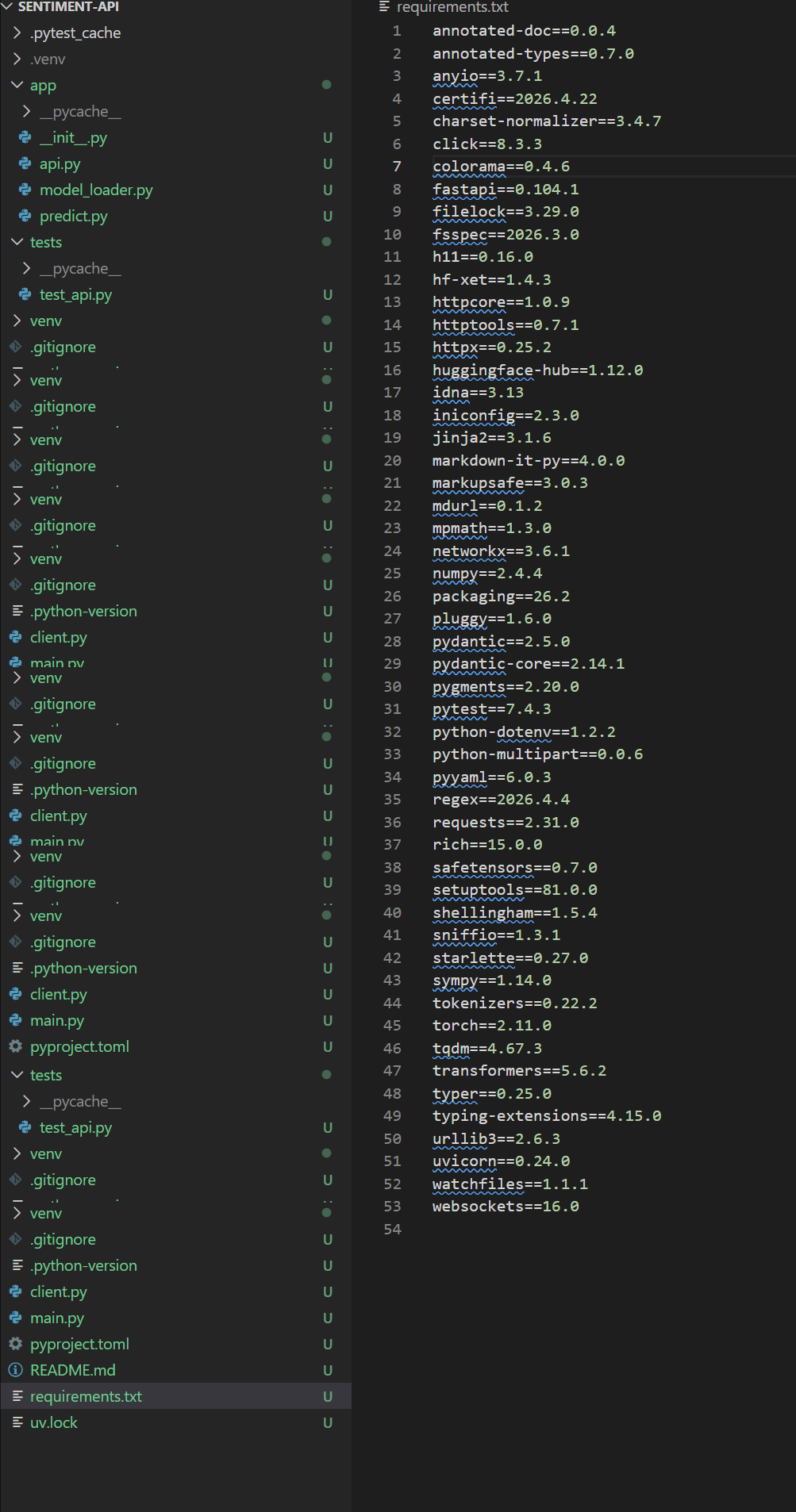
你会看到类似:
fastapi==…
transformers==…
torch==…
👉 此时这个项目具备:
让你的项目可以兼容 pip / Docker / 传统部署

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)