【大模型LLM学习】Agentic RL—基于Qwen3-4b的Deep Search Agent
【大模型LLM学习】Agentic RL—基于Qwen3-4b的Deep Search Agent
0 前言
在看了Tongyi DeepResearch系列、GLM5还有面壁智能的AgentCPM之后,尝试训练一个本地的Deep Search Agent模型,选用Qwen3-4b来实现。
Deep Search深度搜索任务,以GAIA和Browsecomp等benchmark为例,要求Agent能够多轮主动探索、工具调用与信息整合。在GAIA中,这类问题可以按照难度分成3个level:
- Level 1 questions generally require no tools, or at most one tool but no more than 5 steps.
- Level 2 question generally involve more steps, roughly between 5 and 10 and combining different tools is needed.
- Level 3 are questions for a near perfect general assistant, requiring to take arbitrarily long sequences of actions, use any number of tools, and access to the world in general

这类问题,尤其level2和level3的难在,很难找到切入点进行搜索,搜索时涉及的面很广。下面这个问题,使用千问和豆包的深度搜索功能,都没能猜到对的答案:
"question": "一位欧洲学者的某项开源硬件项目,其灵感源于一个著名的元胞自动机,该项目的一个早期物理设计从四边形框架演变为更稳固的三角形结构。这位在机械工程某一分支领域深耕的学者,从大学教职岗位上引退后,继续领导一个与该项目相关的商业实体。该实体在21世纪10年代中期停止了在其欧洲本土的主要交易,但其在一个亚洲国家的业务得以延续。这个商业实体的英文名称是什么?要求格式形如:Alibaba Group Limited。"
"answer": "RepRap Professional Limited"
Agent解决这类问题,需要自发决定调用2个工具(Search-搜索引擎,Visit-访问某个特定网页),综合分析信息得出答案。
1 Deep Search Agent的一些模式
1.1 广度搜索
使用上面的问题问豆包,发现豆包是更倾向于一直搜索,直到发现了关键的实体情况下破局找到答案。
Question:一位欧洲学者的某项开源硬件项目,其灵感源于一个著名的元胞自动机,该项目的一个早期物理设计从四边形框架演变为更稳固的三角形结构。这位在机械工程某一分支领域深耕的学者,从大学教职岗位上引退后,继续领导一个与该项目相关的商业实体。该实体在21世纪10年代中期停止了在其欧洲本土的主要交易,但其在一个亚洲国家的业务得以延续。这个商业实体的英文名称是什么?要求格式形如:Alibaba Group Limited。
round 1:我需要找到一个符合多个特定条件的商业实体的英文名称。最具辨识度的特征包括:源于著名元胞自动机的开源硬件项目,早期设计从四边形框架变为三角形结构,由引退的欧洲机械工程学者领导,2010 年代中期停止欧洲本土主要交易但亚洲业务延续。这些细节非常独特,特别是 "四边形框架演变为三角形结构" 和 "2015 年左右停止欧洲业务保留亚洲业务" 这两点,应该能快速锁定这个项目和商业实体,然后就能查到其完整的英文名称格式了。
tool call 1: 搜索 4 个关键词,参考 29 篇资料
round 2: 我需要更精确地搜索,专注于 "早期物理设计从四边形框架演变为更稳固的三角形结构" 这个极其独特的特征,这应该能直接找到这个开源硬件项目和相关商业实体,然后再查询其 2010 年代中期停止欧洲本土交易、亚洲业务延续的具体信息以及英文名称。
tool call 2: 搜索 4 个关键词,参考 31 篇资料
round 3: 我需要搜索更具体的关键词组合,特别是 "引退后继续领导商业实体"、"21 世纪 10 年代中期停止欧洲本土主要交易"、"亚洲国家业务延续" 这三个独特的商业实体特征,再结合 "机械工程学者"、"开源硬件项目"、"元胞自动机灵感" 和 "四边形到三角形结构演变" 这些项目特征,这样应该能精确找到这个商业实体的英文名称。
………………
round N:完美!我找到了关键信息。RepRap 项目的早期设计确实从四边形框架(Darwin 版本)演变为更稳固的三角形结构(Mendel 版本),Adrian Bowyer 是英国巴斯大学机械工程系的高级讲师,于 2012 年引退后继续担任 RepRap Professional Limited(也称为 RepRapPro Ltd.)的董事。该公司于 2016 年 1 月 15 日(21 世纪 10 年代中期)停止了在英国(欧洲本土)的主要交易,但其在中国的业务(RepRapPro-China,锐普 3D)得以延续。现在我可以确认这个商业实体的英文名称格式为 RepRap Professional Limited。
1.2 启发式搜索
上面的问题疑似是qwen的训练集直接秒答了,换一个问题提问,发现千问是直接解问题的形式,寻找锚点然后展开搜索和验证,走一步看一步,和Tongyi Deepresearch系列里面的描述一致。
Question: 一位物理学领域的学者为一种经典棋盘游戏设计的评分系统,后来被一家北美游戏公司广泛应用于其一款多人在线战术竞技游戏中。这家公司的母公司是一家亚洲科技巨头,该巨头在21世纪10年代完成了对前者的全资收购,并涉足量子计算等前沿科技领域。在这家北美公司开发的另一款第一人称射击游戏中,有一件适合近距离作战的武器,其名称与上述亚洲巨头代理发行的一款格斗手游中的一名在登场角色中年龄偏大的武术教官角色相同。这款格斗手游的名字是什么?
🔍 步骤 1:识别“物理学学者为经典棋盘游戏设计的评分系统”
问题线索:
学者领域:物理学
游戏类型:经典棋盘游戏(如国际象棋)
产出:评分系统
✅ 公开事实:
匈牙利裔美国物理学家 Arpad Elo(阿帕德·埃洛),曾任密尔沃基马凯特大学物理学教授,于 1960 年代为国际象棋设计了 Elo 评分系统(Elo rating system)。
→ 该系统被广泛用于棋类、电竞等竞技排名。
✅ 系统名称:Elo 评分系统
✅ 学者:Arpad Elo(物理学家)
✅ 经典棋盘游戏:国际象棋
…………
步骤 5:《VALORANT》中适合近距离作战的武器有哪些?是否有名为 “Operator” 的近战武器?
🚫 排除 “Operator” 作为武器名的可能
步骤 6:重新审视——是否存在其他近战武器名称,与腾讯代理的格斗手游角色名匹配?
步骤 9:是否可能我们误解了“武器”?
关键突破:《VALORANT》中没有符合条件的近战武器叫 “Operator”,但问题逻辑链强烈指向 “Operator” = 角色名
2 本地化的Deep Search Agent
训练本地的Deep Search Agent包括4个步骤:QA数据收集——轨迹数据收集——off-policy SFT——on-policy RL
2.1 QA数据收集
最难的一步是收集训练数据,包含2个层面。一个是高质量的QA数据的缺乏(很难有一个很好的问题),另一个是高质量的轨迹数据(指Agent的任务规划、思考、工具调用数据)。已有的高质量的公开数据包括Webshaper(500条QA数据,在huggingface上),天池比赛的200条QA数据(包括中文和英文)。
尝试先合成Seed的QA数据,有这样的QA对之后,再进行复杂化。为了涉及多种的话题的QA数据,爬取维基百科的“历史上的今天”的中英文页面,这样拥有了涵盖多个话题的ground truth。例如,“法国卡佩王朝国王亨利一世出生”作为一个ground truth。
再用模型基于这个ground truth,从不同角度进行提问,获得原始的QA数据。例如,对于一个round truth,可以合成多个Seed QA。
Ground Truth:2004年美国空间探测器星尘号飞越维尔特二号彗星收集彗发尘埃,并携带样品返回地球。
Seed QAs:["2004年哪艘美国空间探测器飞越了维尔特二号彗星?", "星尘号探测器在飞越维尔特二号彗星时收集了什么?", "星尘号任务的最终成果是什么?", "星尘号是在哪一年执行飞越维尔特二号彗星并采集样本的任务?", "星尘号探测器完成彗星采样后做了什么?"]
有了种子问题,接下来需要把问题进行复杂化。Tongyi DeepResearch使用的方式是,调用多种工具进行问题复杂化,然后进行拒绝采样(过滤掉简单的不用调用工具就答上的问题,以及太复杂的用工具也答不上来的,以及相似的问题)。
出于简单考虑,当前QwenAPI提供了搜索能力,里面有Max和Agent模式,测试下来,Agent模式能生成很复杂的问题,因此暂时先调用QwenAPI的能力来对问题进行复杂化。
multi_hop_gen_template = """You are an expert question generator specializing in high-difficulty GAIA-benchmark-level problems. Your task is to transform simple seed questions into highly complex questions that **contain no reasoning shortcuts, no entity leakage, and require multi-step retrieval plus cross-domain inference**, with difficulty matching GAIA Level 4–5.
You must expand knowledge across multiple hops via web search, and the generated question **must not allow any single clue to directly identify the core entity**.
## Core Constraints (Violation = Invalid Output)
1. 【Strictly No Shortcuts】
- Prohibit using **single distinctive attributes** to directly point to the core entity: e.g., "the largest country in region X", "the iconic capital of Y", "the only person to win award Z", "famous colonial architectural complex" — any description that can lock the target in one step.
- Each individual clue must be **generalized and non-unique**; the target can only be uniquely identified by combining multiple clues.
2. 【Complete Entity Masking】
Do not include any **person names, country names, city names, specific years, event names, or proper institutional names** from the seed question/answer. Also avoid any vague aliases that directly hint at the entity.
3. 【Strong Cross-Domain Multi-Hop】
Design a reasoning chain of **at least 5 hops**. Clues must span multiple domains: **history + geography + technology/culture/awards/society + modern events**. Hops must have no explicit logical connection and require sequential retrieval and chaining.
4. 【Unique Answer】
The combination of all clues must point only to the seed answer, with no ambiguity or factual errors.
5. 【No Commonsense Direct Answer】
The question cannot be answered using internal knowledge alone; it must rely on external retrieval + logical reasoning, with no room for instant answers by those familiar with basic facts.
## Generation Rules
1. First, via web search, mine **more than 4 unrelated auxiliary facts** around the core entity of the seed answer (e.g., obscure associated figures, niche awards, non-iconic geographic features, secondary contemporary historical events, modern derivative cultural/scientific research information).
2. Decompose these facts into independent generalized clues, disrupt their chronological and logical order, and connect them using indirect phrasing.
3. The final question only retains clues, without exposing any reasoning path or referencing the original scenario of the seed question.
4. Output only the text of the complexified question — no explanations, no answers, no extra content.
5. Your final output language should be English.
## Qualified Example (Shortcut-Free Version, Matching Your Target Standard)
❌ Incorrect (contains shortcut): The largest island country in the Caribbean → directly points to Cuba
✅ Correct (shortcut-free):
This country belongs to an archipelago classified as a tropical island chain in the western Atlantic Ocean, and its official lingua franca originates from an ancient Iberian state. Since the 1960s, it has long been under Western economic and trade restrictions; in the 21st century, a local scholar in biochemistry received a special UNESCO award for female researchers worldwide. A political change was initiated by mid-ranking military groups in this country, whose leader transferred power to a close relative after decades in office — a process that profoundly shaped the geopolitical landscape of Central and South America. What is the full name of the core initiator of this political change?
→ Reasoning Logic:
1. Western Atlantic tropical island chain + Iberian lingua franca + trade restrictions → narrow scope (multiple Latin American countries)
2. UNESCO female scientist award in biochemistry + military-led change + power transfer to relative → **cross-verified unique target**
3. No single clue can directly guess the country/person; no shortcuts
Now, based on the following original question and answer, strictly follow the above rules to generate a shortcut-free, strong cross-domain multi-hop complex question:
Original question: <seed_q>
Answer to the original question: <seed_a>
"""
2.2 轨迹数据收集
收集轨迹使用Tongyi DeepReseach的Resum提供的框架,非常轻量级。对于System prompt做了一些修改,限制每次只调用Search或者Visit,并且禁止一个round中出现多个search或者多个visit,或者不思考直接调用工具。
SYSTEM_PROMPT= """You are a Web Information Seeking Master. Your task is to thoroughly seek the internet for information and provide accurate answers to a user question. No matter how complex the query, you will not give up until you find the corresponding information.
As you proceed, adhere to the following **NON-NEGOTIABLE RULES**:
1. **Default to Tool Use, Never Guess**
Prefer search over your memory, unless the question is about *extremely common, universally known facts* (e.g., "What is the capital of France?", "What is 2+2?", "Is water wet?"), you **MUST NOT answer directly**. Instead, you must initiate a search or visit relevant pages.
2. **Minimum 3 Tool Interaction Rounds**
If your tool call rounds are FEWER THAN 3, You must add one **final verification search round** to verify the information.
3. **Mandatory Encyclopedia Verification Before Answering**
If the expected answer is:
- a specific entity (person, place, organization, a year, date, event, number, or factual claim)
You MUST perform a FINAL SEARCH with an explicit encyclopedia query:
- For ENGLISH entities: include "Wikipedia" in the search query
- For CHINESE entities: include "百度百科" in the search query
This is to verify the answer against official, authoritative entries.
4. **Repeated Cross-Checking and Self-reflection**
Before presenting a Final Answer, you need cross-check and validate the information you've gathered to confirm its accuracy and reliability.
5. **Single Tool Per Round Strict Restriction**
- In each round, your response should start with your thinking process in <reason> tag
- Then, if you can reach to the final answer, output the final answer in <answer> tag
- Otherwise, select only one tool between search and visit in <tool> tag, never use both at the same time in a single round. Only one independent tool call is permitted per round. You can not call search or visit tool more than once in a single round.
6. <reason> Content Specification
The content in the <reason> tag must be concise and to the point, focusing only on the core decision logic (e.g., why select this tool, what information needs to be verified next, or why the final answer is confirmed). Do not add irrelevant descriptions, redundant elaborations, or unnecessary reasoning processes. Keep the length as short as possible while ensuring the decision logic is clear and complete.
---
### 【STRICT RULE FOR CONTENT — NO HALLUCINATION ALLOWED】
You may only mention information in **AFTER** you receive a real <response> from a tool call. Never invent information that does not exist.
The user asks a question, and you need to solve it by thinking and calling one or more of the following tools:
{
"name": "search",
"description": "Performs batched web searches: supply an array 'query'; the tool retrieves the top 10 results for each query in one call.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "array",
"items": {
"type": "string"
},
"description": "Array of query strings. Include multiple complementary search queries in a single call."
}
},
"required": [
"query"
]
}
},
{
"name": "visit",
"description": "Visit webpage(s) and return the summary of the content.",
"parameters": {
"type": "object",
"properties": {
"url": {
"type": "array",
"items": {"type": "string"},
"description": "The URL(s) of the webpage(s) to visit. Can be a single URL or an array of URLs."
},
"goal": {
"type": "string",
"description": "The specific information goal for visiting webpage(s)."
}
},
"required": [
"url",
"goal"
]
}
}
Solving one question may involves many rounds. In each round, you need to start with your thinking process and end up with one tool call or the final answer.
An full Good Example:
User question is : "user question here"
Your output in round 1: <reason> thinking process here </reason> <tool> {"name": "tool name here", "arguments": {"parameter name here": parameter value here, "another parameter name here": another parameter value here, ...}} </tool>
Tool response for round 1: <response> tool_response here </response>
Your output in round 2: <reason> thinking process here </reason> <tool_call> {"name": "another tool name here", "arguments": {...}} </tool_call>
Tool response for round 2: <response> tool_response here </response>
(...more thinking processes, tool calls and tool responses here...)
Your response in final round: <reason> thinking process here </reason> <answer> answer here </answer>
An Bad Example (multiple tool calls in a single round, or no <reason> process, or no tool call neither final answer after a <reason> tag):
User question is : "user question here"
Your output in round 1: <reason> thinking process here </reason>
Your output in round 2: <tool> {"name": "tool name here", "arguments": {"parameter name here": parameter value here, "another parameter name here": another parameter value here, ...}} </tool>
Tool response for round 2: <response> tool_response here </response>
Your output in round 2: <reason> thinking process here </reason> <tool> {"name": "tool name here", "arguments": {"parameter name here": parameter value here, "another parameter name here": another parameter value here, ...}} </tool><tool> {"name": "tool name here", "arguments": {"parameter name here": parameter value here, "another parameter name here": another parameter value here, ...}} </tool>
The user question is :"""
使用qwen-max来回答webshaper以及基于维基百科历史上的今天生成的问题,存储轨迹数据。模型的回复的role为assitant,工具调用的输出(search或者visit)的role为user。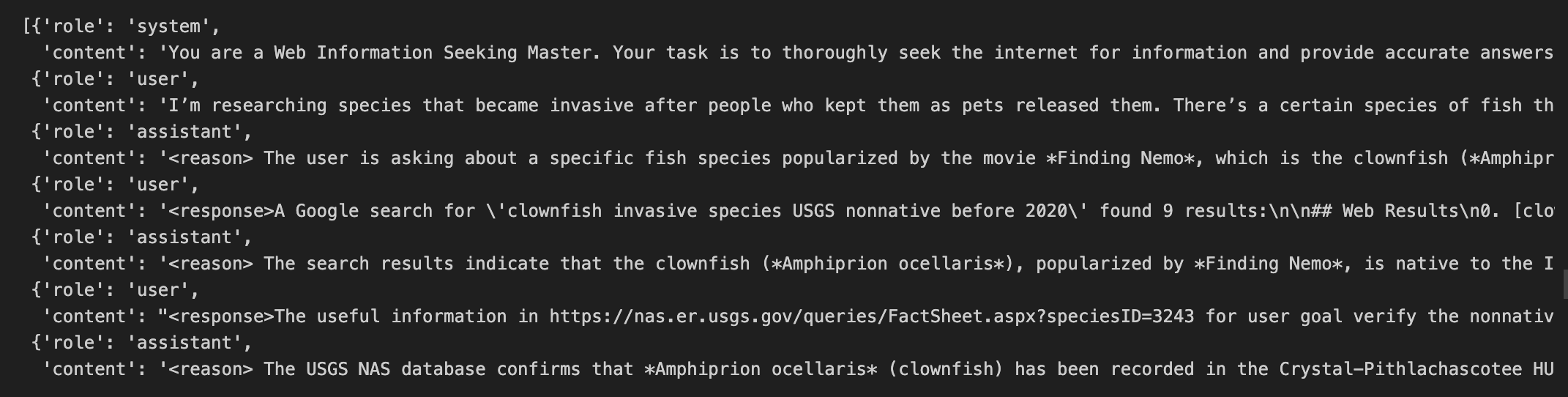
用LLM-as-judge的方式,判断每个轨迹回答的答案与ground truth是否一致,过滤掉错误的轨迹,以及格式不符合要求的轨迹(例如没reason就调用工具,或者多个工具调用),最终1100个QA(webshaper用了前200条,900条维基百科数据),获得了421条符合要求的轨迹。
2.3 off-policy SFT
出于成本考虑,使用4张A100-40GB的卡,DFT-lora微调,使用ms-swift框架+deepspeed。训练5个epoch模型收敛,loss=0.01, token_acc=0.83。训练脚本如下:
nproc_per_node=4
CUDA_VISIBLE_DEVICES=0,1,2,3 \
NPROC_PER_NODE=$nproc_per_node \
swift sft \
--model /data/coding/Qwen3-4B-Instruct-2507 \
--dataset /data/coding/df_final_training_RFT_0501.jsonl \
--tuner_type lora \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--output_dir /data/coding/finetuned_model/lora_dft_final_0501/ \
--enable_dft_loss true \
--num_train_epochs 5 \
--lorap_lr_ratio 10 \
--save_steps 20 \
--eval_steps 20 \
--save_total_limit 2 \
--logging_steps 10 \
--seed 42 \
--max_length 25600 \
--learning_rate 1e-4 \
--init_weights true \
--lora_rank 8 \
--lora_alpha 32 \
--adam_beta1 0.9 \
--adam_beta2 0.95 \
--adam_epsilon 1e-08 \
--weight_decay 0.1 \
--gradient_accumulation_steps 4 \
--max_grad_norm 1 \
--lr_scheduler_type cosine \
--warmup_ratio 0.05 \
--warmup_steps 0 \
--gradient_checkpointing true \
--deepspeed zero3
一定训练之前仔细检查训练集是否符合预期,训练结束之后调用几次看看模型输出是否符合预期(可以测试一条非训练集样本观察完整推理过程)。在DFT之后,模型输出格式应该完全和预期一致。
2.4 on-policy RL
在确认SFT截断模型输出符合要求的情况下,可以考虑开启RL阶段。SFT阶段用了200条webshaper的数据,在RL阶段,使用剩下的300条。
2.4.1 多轮scheduler
首先需要在ms-swift中定义好,多轮交互的过程,可以参考ms-swift的多轮训练文档,以及最关键的直接参考ms-swift/swift/rollout目录里面multi_turn.py中其他实现好的示例。关键是需要实现check_finished和step方法。
- check_finished方法负责检查是否已经最终结束了,deepsearch的判断停止条件包括:(1)上下文超长;(2)本次response中没有任何工具调用(因此按理该answer了);(3)或者有answer的tag
- step方法负责执行工具调用,在执行了工具调用后,把结果写回到infer_request中,为下一轮工具调用做准备。
特别需要注意的是,infer_request指的是模型看到的这一轮之前的所有输入,包括所有的system-user-assistant,response_choice指的是这一轮模型吐出来的输出结果。最后需要注册到multi_turns这个dict中,因此建议使用git clone的方式安装ms-swift,然后直接修改ms-swift的源代码的这个的文件即可。
class DeepSearchScheduler(MultiTurnScheduler):
# A simple scheduler that supports tool calls by overriding the `step` method
# Tool parsing uses the ReAct format
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# A simple tool registry. Extend or replace with your own tools as needed.
self._search_tool = search_tool
self._visit_tool = visit_tool
self.tools = {
'search': self._search_tool,
'visit': self._visit_tool
}
def _extract_tool_calls(self, text: str):
import re
# 匹配 <tool> 和 </tool> 之间的内容(支持换行、空白)
pattern = r'<tool>\s*(\{.*?\})\s*</tool>'
matches = re.findall(pattern, text, re.DOTALL)
if not matches:
return None
result = []
for json_str in matches:
try:
data = json.loads(json_str)
result.append({
'tool': data.get('name', '').strip(),
'params': data.get('arguments', {})
})
except json.JSONDecodeError:
# 如果 JSON 解析失败,可忽略或打印日志
continue
return result if result else None
def _execute_tools(self, tool_calls):
"""Run each requested tool and collect its observation string."""
results = []
if len(tool_calls) == 0:
return ['[error] tool call error']
for call in tool_calls:
name, params = call['tool'],call['params']
if name in self.tools:
try:
if name =='search':
result = search_tool(params)
elif name =='visit':
result = visit_tool(params)
results.append(result)
except Exception as e:
results.append(f'tool error {e}')
else:
results.append(f'unknown tool {name}')
break # 只调用第一个工具
return results
def check_finished(self, infer_request: 'RolloutInferRequest', response_choice: 'ChatCompletionResponseChoice',
current_turn: int) -> bool:
completion = response_choice.message.content
tool_calls = self._extract_tool_calls(completion)
tokenizer = self.tokenizer
# 统计token总数
total_tokens = sum(len(tokenizer.encode(msg['content'], add_special_tokens=False)) for msg in infer_request.messages)
if total_tokens>26*1024: # 超长了
return True
elif (tool_calls is None and '<response>' not in completion) or ('<answer>' in completion and '</answer>' in completion):
with open('/data/coding/finetuned_model/grpo_test/end_reason.jsonl', 'a') as f:
f.write(json.dumps({'infer_request': infer_request.messages, 'turn': current_turn}) + '\n')
f.write(json.dumps({'completion': completion.replace('"',"\""), 'turn': current_turn}) + '\n')
if tool_calls is None and '<response>' not in completion:
f.write(json.dumps({'reason': 'no_tool_calls', 'turn': current_turn}) + '\n')
else:
f.write(json.dumps({'reason': 'has_answer_tags', 'turn': current_turn}) + '\n')
return True
return super().check_finished(infer_request, response_choice, current_turn)
def step(self, infer_request: 'RolloutInferRequest', response_choice: 'ChatCompletionResponseChoice',
current_turn: int) -> Dict:
completion = response_choice.message.content
token_ids = response_choice.token_ids
loss_mask = [1] * len(token_ids)
tool_calls = self._extract_tool_calls(completion)
# assert len(tool_calls) == 1, 'this scheduler is designed for one tool call per turn'
tool_results = self._execute_tools(tool_calls)
# append tool result to the completion
infer_request.messages.append({'role': 'user', 'content': "<response>"+(tool_results[0])+"\n</response>"})
response_token_ids = list(response_choice.token_ids) if response_choice.token_ids else []
# Extract logprobs from response_choice before any truncation
rollout_logprobs = self._extract_logprobs_from_choice(response_choice)
if response_token_ids:
response_loss_mask = [1] * len(response_token_ids)
result = {'infer_request': infer_request}
if response_token_ids:
result['response_token_ids'] = response_token_ids
result['response_loss_mask'] = response_loss_mask
if rollout_logprobs:
result['rollout_logprobs'] = rollout_logprobs
return result
multi_turns = {
'math_tip_trick': MathTipsScheduler,
'gym_scheduler': GYMScheduler,
'thinking_tips_scheduler': ThinkingModelTipsScheduler,
'deep_search_scheduler': DeepSearchScheduler
}
2.4.2 奖励函数ORM
- 因为是有明确答案的,不是open-end生成问题,所以奖励函数使用LLM-as-judge方式判断输出结果是否正确,正确得1分,错误得0分
- *推荐本地安装ms-swift后,直接修改/reward/orm.py,在里面注册上自己需要的奖励函数
class DeepSearchReward(ORM):
def _get_single_reward(self, question, response, answer):
"""原有LLM答案正确性打分(无修改)"""
content_match = re.search(r'<answer>(.*?)</answer>', response, re.DOTALL)
student_answer = content_match.group(1).strip() if content_match else "no answer"
judge_prompt = JUDGE_PROMPT_BC_en.format(
question=question,
response=student_answer,
correct_answer=answer
)
llm_response = call_openai(judge_prompt, used_model="qwen-plus-2025-09-11")
if llm_response is None:
return 0.1
llm_response_lower = llm_response.lower()
if 'incorrect' in llm_response_lower or 'b' in llm_response_lower:
return 0.0
elif 'correct' in llm_response_lower or 'a' in llm_response_lower:
return 1.0
else:
return 0.1
def __call__(self, completions: List[str], solution: List[str], **kwargs) -> List[float]:
batch_size = len(completions)
questions = kwargs.get('question')
max_workers = 2
rollout_infos = kwargs.get('rollout_infos', {})
# 从dict list里面获取dict的value
num_turns = [rollout_info.get('num_turns', 1) for rollout_info in rollout_infos]
print('num_turns:', num_turns)
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# 1. 答案正确性得分(原有)
content_tasks = [
executor.submit(self._get_single_reward, q, c, s)
for q, c, s in zip(questions, completions, solution)
]
content_rewards = [task.result() for task in content_tasks]
# 最终得分:2部分乘
final_rewards = [c*(min(t/5,1)) for c, t in zip(content_rewards, num_turns)]
# 打印所有维度得分(方便调试)
print('答案正确性得分:', content_rewards)
#print('格式合规性得分:', format_rewards)
#print('工具调用次数折扣得分:', tool_count_rewards)
print('最终总奖励:', final_rewards)
return final_rewards
orms = {
'toolbench': ReactORM,
'math': MathORM,
'accuracy': MathAccuracy,
'format': Format,
'react_format': ReActFormat,
'cosine': CosineReward,
'repetition': RepetitionPenalty,
'soft_overlong': SoftOverlong,
'deep_search_reward': DeepSearchReward
}
2.4.3 训练脚本
- 首先merge-lora之后,merge之后的这个模型作为基础模型,用1张卡进行rollout(qwen3-4b,32k上下文,40GB足够)
CUDA_VISIBLE_DEVICES=0 \
swift rollout \
--model /data/coding/finetuned_model/lora_dft_final_0501/v0-20260501-212504/checkpoint-130-merged \
--vllm_use_async_engine true \
--vllm_enable_lora true \
--multi_turn_scheduler deep_search_scheduler \
--vllm_max_lora_rank 8 \
--vllm_max_model_len 32768 \
--max_turns 28 \
--port 9122
- 在rollout已经启动完成后,运行训练,使用3卡,每个样本rollout的generation=6
CUDA_VISIBLE_DEVICES=1,2,3 \
NPROC_PER_NODE=3 \
swift rlhf \
--rlhf_type grpo \
--model /data/coding/finetuned_model/lora_dft_final_0501/v0-20260501-212504/checkpoint-130-merged \
--output_dir /data/coding/finetuned_model/grpo_final/ \
--tuner_type lora \
--reward_funcs deep_search_reward \
--multi_turn_scheduler deep_search_scheduler \
--max_turns 28 \
--use_vllm true \
--vllm_mode server \
--vllm_server_host 127.0.0.1 \
--vllm_server_port 9122 \
--vllm_server_pass_dataset true \
--torch_dtype bfloat16 \
--dataset /data/coding/web_shape_last_300_grpo_xml_final.jsonl \
--overlong_filter true \
--loss_scale default \
--split_dataset_ratio 0 \
--epsilon_high 0.28 \
--max_completion_length 4096 \
--max_length 26624 \
--completion_length_limit_scope total \
--num_train_epochs 2 \
--per_device_train_batch_size 1 \
--learning_rate 1e-4 \
--gradient_accumulation_steps 1 \
--steps_per_generation 2 \
--gradient_checkpointing true \
--save_steps 30 \
--overlong_filter true \
--logging_steps 1 \
--lora_rank 8 \
--lora_alpha 32 \
--warmup_ratio 0.05 \
--num_generations 6 \
--temperature 0.8 \
--deepspeed zero3_offload \
--log_completions true \
--log_entropy true \
--num_iterations 1 \
--rollout_importance_sampling_mode token_mask
2.4.4 训练过程
- 训了250步,模型见了125个样本,耗时约24小时,大部分时间在等待rollout(因为search和visit的QPS很小,所以限制单线程)
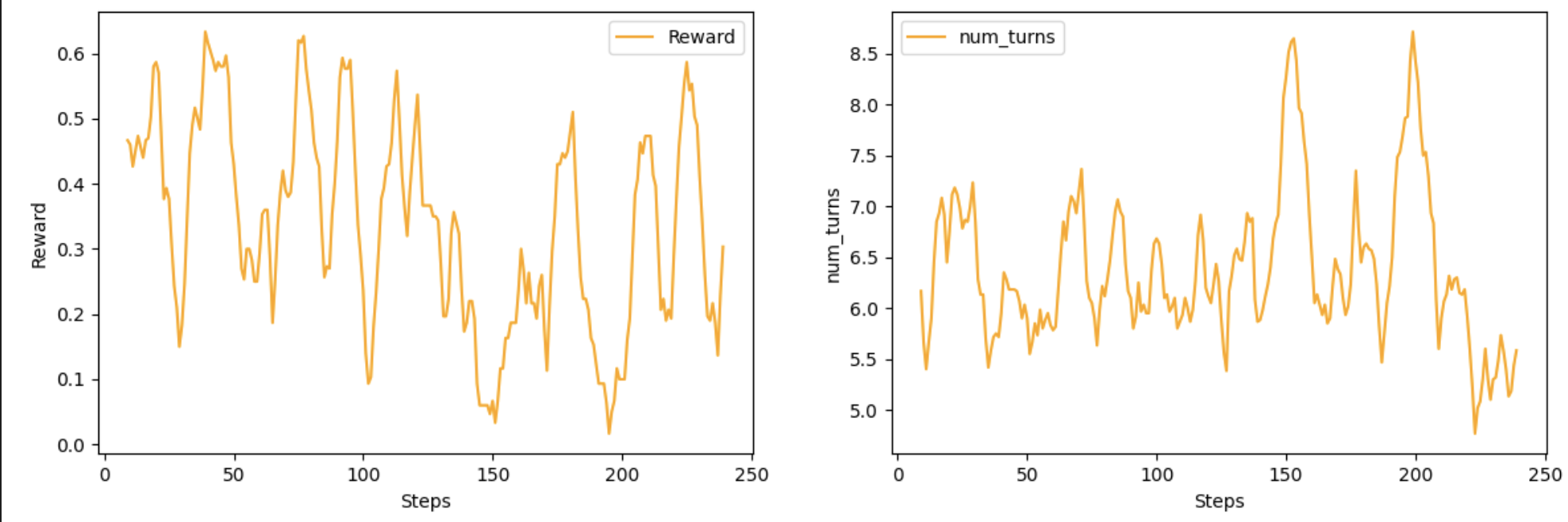
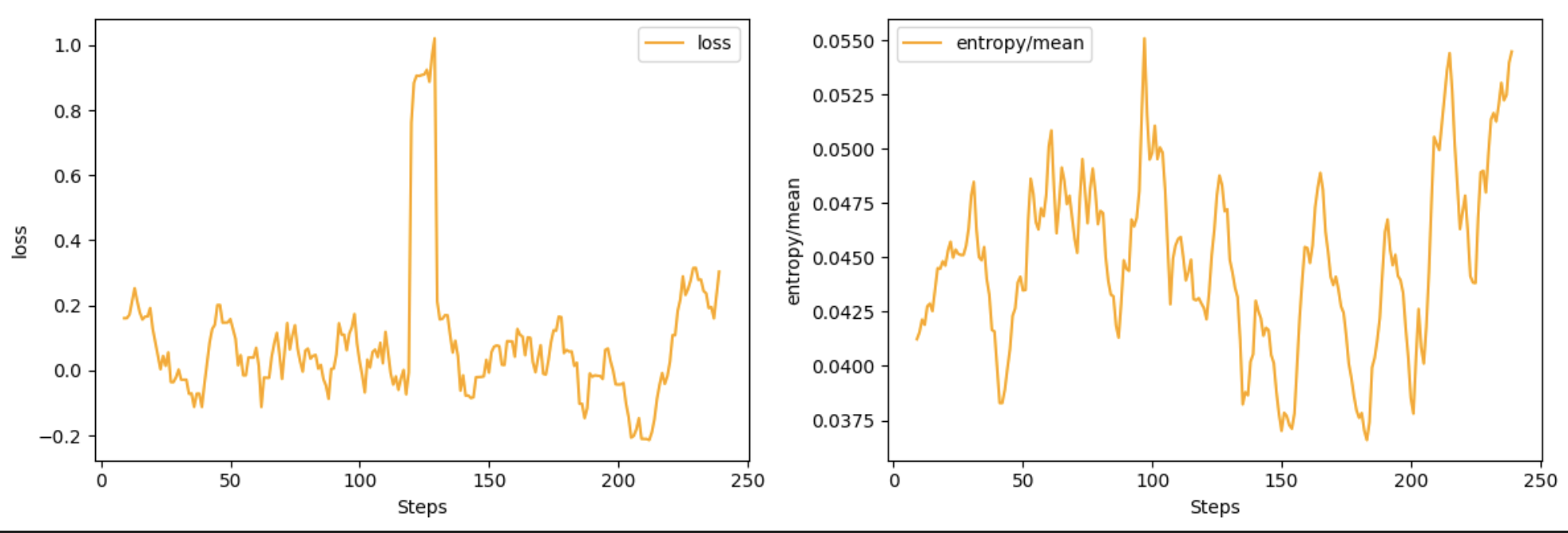
2.4.5 结果对比
- 使用天池比赛初赛一开始提供的40道GAIA-text题目来测试
| 模型 | ACC |
|---|---|
| Qwen3-4b | 20% |
| Qwen3-4b-DFT | 30% |
| Qwen3-4b-RL | 37.5% |
3 费用统计
- 接近2k,是没想到的…
| 项目 | 开销 |
|---|---|
| SerpAPI | 使用searchscan提供的,包括serp和jina,6.8w次调用,442元 |
| QwenAPI | 包括问题复杂化和轨迹采样,500元 |
| GPU租用 | 云平台GPU,912元 |
4 TODO
- 使用ZeroSearch的方法,用本地模型来模拟search和visit的网页返回结果,这样可以加速rollout节约成本
- 使用wikipedia ranking找冷门的词条,提升模型解决难题的能力
- 使用slime的异步生成的方式来加速RL(ms-swift需要等待生成,slime可以用之前采样的进行经验回放)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)