创新实训(4)—— 问答系统完善(会话)
前期我们已经打通了基础的 LLM 对话和流式输出。接下来我们针对:AI 没有记忆,且用户只能在一个固定的窗口里聊天 问题进一步进行了优化。
为了让系统更加接近真实的商业级 AI 助手(比如 ChatGPT / 智谱清言),我这周对后端核心代码进行了重构,引入了多会话管理机制。
完整的会话管理机制
我们常用了豆包、deepseek一类大模型都会有会话管理,这样一方面可以防止某一个会话的内容过度影响使用,另一方面便于用户分门别类管理自己的问题。
于是,我设计了一套完整的会话 API 接口:
-
POST /sessions:创建新会话。 -
GET /sessions:支持按user_id拉取历史会话,并加入了keyword搜索功能。 -
PUT /sessions/{session_id}:支持对现有会话进行改名操作。 -
GET /sessions/{session_id}/messages:精准获取某个特定对话的历史聊天记录。
针对改名操作,我们为每个会话提供了会话名称的属性,并允许用户对该属性进行修改。针对改名操作,我们为每个会话提供了独立的名称属性。这一功能为后续实现“聊天内容与知识点全文检索”功能打下基础。
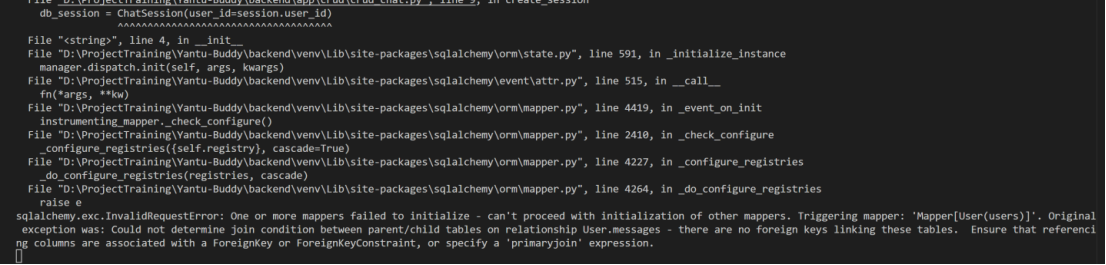
具体实现过程中,我们首先对后端进行了修改,并通过访问http://127.0.0.1:8000/docs对修改进行调试与验证,过程中遇到了500报错,终端输出报错检查,发现是由于未关联外键导致,针对此进行了修改,随后后端功能通过测试。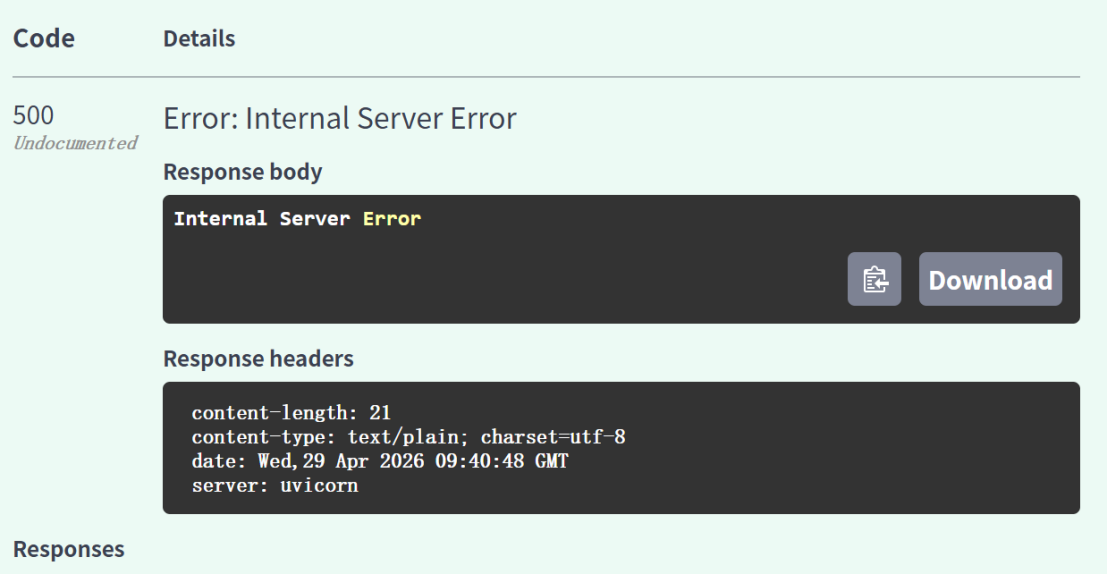
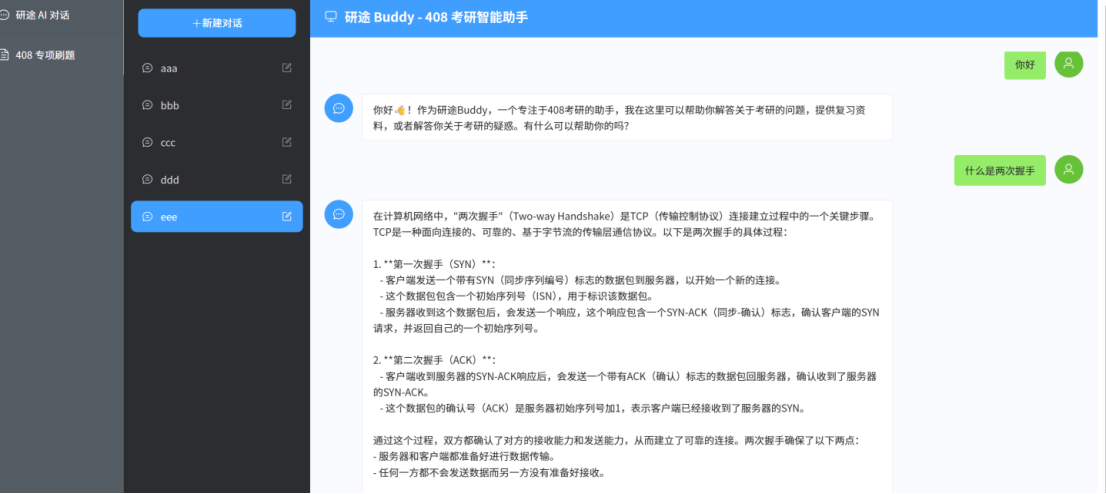
针对前端进行了分会话补充,最终问答界面暂时如下图所示。
记忆:上下文动态注入
现有的大模型API 本质上都是“无状态”的,如果不在本次请求中带上刚才的聊天记录,它根本不知道你上一句说了什么。因此,要想提高 AI 助手的可用性,必须由我们后端来手动实现“上下文记忆”的注入。
在着手写代码之前,我先去调研了目前主流的几种大模型记忆实现方案。总结下来,主要有以下四大流派:
-
全量历史注入
-
思路:把当前会话的所有历史记录原封不动地全部塞给大模型。
-
缺点:随着聊天轮数增加,Token 消耗会呈指数级爆炸。
-
-
文本摘要浓缩
-
思路:当历史记录达到一定长度时,调用一次大模型,让它把之前的对话总结成一段简短的摘要(例如:“用户刚才询问了TCP三次握手,并理解了SYN包的作用”),然后以后只带上这个摘要和最新问题。
-
缺点:会丢失对话的细节信息,且需要额外消耗一次生成摘要的 API 调用。
-
-
向量数据库检索 RAG
-
思路:把每一条聊天记录都向量化后存入 Milvus 等向量数据库。用户发新问题时,先去数据库里检索最相关的几条历史记录注入。
-
缺点:架构太重,适合做“数字分身”或长期陪伴型 Agent。
-
-
滑动窗口截断法
-
思路:维护一个固定长度的队列(比如只保留最近的 N 条消息),像一个滑动窗口一样,旧的消息不断被丢弃,永远只把最新鲜的上下文喂给大模型。
-
我最终决定先采用“滑动窗口法”进行轻量级实现。
结合考研助手的业务场景——用户通常是针对某道特定的错题或知识点进行短期、高频的连续追问,一旦弄懂就会开启下一个话题(新建会话)。因此,长期记忆并不是刚需,但后续若能够实现长期记忆,或有利于更精细的刻画其学习方式,因此未来会对此方法进行进一步的改进与完善。
在核心的流式问答接口 /messages 中,我的具体实现逻辑如下:
通过前端传来的 session_id 拉取该会话的全部历史记录,但在组装发给大模型的 messages 列表时,强制限制只截取最近的 20 条消息注入到 AI 的上下文中。
# 从数据库拉取当前会话的所有历史记录
history_messages = crud_chat.get_messages_by_session(db=db, session_id=message.session_id)
# 构建发给大模型的基础 System Prompt
ai_messages = [{"role": "system", "content": "你是研途Buddy,一个专业的408考研智能助手。"}]
# 滑动窗口截断(只取列表最后 20 条)
for h in history_messages[-20:]:
ai_messages.append({"role": h.role, "content": h.content})
# 放入用户本次的新问题,发起请求
ai_messages.append({"role": "user", "content": final_user_content})滑动窗口一方面保证了对话的流畅,另一方面防止大量记忆导致Token爆炸,但针对此记忆方法,我们下一步仍会继续改进,进一步平衡对话连贯性与Token消耗之间的关系。
总结
接下来,我们将重点实现以下两个核心功能:
1. 全局知识点与聊天记录检索 考研是一个长期复习的过程,用户经常会遇到“我记得上个月问过一道关于二叉树的题,但找不到了”的场景。我们目前已经实现了会话的分类和改名,下一步我将引入 Elasticsearch 或基于数据库的全文检索机制,允许用户通过关键词,瞬间定位到历史会话中的某一个具体知识点解答。让 AI 助手真正成为用户的“个人专属知识库”。
2. 进阶版混合记忆机制 虽然当前的“滑动窗口法”解决了短期连续追问的问题,但若能实现长期记忆,将极大有利于 AI 更精细地刻画用户的“学习画像”(比如记住用户的薄弱点是操作系统,优势是数据结构)。 未来,我计划探索“滑动窗口(短期) + RAG向量检索(长期) + 核心标签抽取”的混合记忆机制。在保证 Token 消耗可控的前提下,让 AI 随着使用时间的增长,越来越懂用户的学习习惯,实现真正的个性化辅导。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)