12 位 AI自媒体顶流大V的skill仓库:github开源(秋芝、卡兹克、赛文乔伊、赛博禅心、量子位、新智元、极客公园、硅星人、机器之心)
12 位 AI自媒体顶流大V的skill仓库:github开源(秋芝、卡兹克、赛文乔伊、赛博禅心、量子位、新智元、极客公园、硅星人、机器之心)
一键拥有 12 位 AI 顶流大 V 能力:这个开源仓库,让 AI 直接写出爆款内容
全文约 2600 字。
一键拥有12位AI顶流大V能力:这个开源仓库,让AI直接写出爆款内容
全文约2600字,公众号可直接复制粘贴,无特殊格式、无外链冗余,适配公众号编辑器。
引言
2026年,AI创作早已不是“写通顺”,而是像真人一样思考、表达、输出人格化内容。
你是否遇到过这些问题:
- 想做AI科普,却写不出卡兹克的数据碾压感;
- 想做科技快讯,学不会赛文乔伊的产品老炮视角;
- 想写深度行业分析,达不到机器之心的论文级严谨;
- 想做提示词教学,没有李继刚的哲学压缩美学。
现在,一个GitHub开源项目,把秋芝2046、数字生命卡兹克、赛文乔伊、赛博禅心、量子位、新智元、极客公园、硅星人、机器之心、特工宇宙、宝玉、李继刚等12位AI圈顶流大V的创作DNA、思维模型、表达风格全部提取、封装成可直接调用的Skill。
不用再苦学选题、练文笔、磨风格——一句话指令,AI直接以大V视角输出。
这就是:
awesome-ai-persona-skills
自媒体大V专属技能库
👉:https://github.com/momozi1996/awesome-ai-persona-skills/blob/main/zimeiti/README.md

一、什么是人格蒸馏?把大V装进AI里
先讲清楚核心概念:人格蒸馏(Persona Distillation)。
不是训练大模型,不是微调,不是简单模仿语气。
而是:
把一个创作者的公开内容、思维框架、表达习惯、决策逻辑、内容结构,全部结构化提取,封装成AI可直接执行的Skill文件。
简单说:
- 你不用再写:帮我写一篇AI行业分析
- 你可以直接写:用机器之心的视角,写一篇AI行业分析
AI就会自动:
- 用论文级深度拆解
- 用三层推演:技术→商业→生态
- 用数据支撑、严谨中立、不标题党
这就是Skill的力量。
这个仓库做的事,就是:
把散落在全网的AI大V能力,变成标准化、可复用、可分发的AI技能。
你不需要成为他们,你可以直接调用他们。
二、这个仓库里,到底有什么?
项目结构极度清晰,全部开箱即用。
 |
 |
1. 已完成蒸馏的12位AI顶流大V
分为两大类:个人创作者、团队媒体。
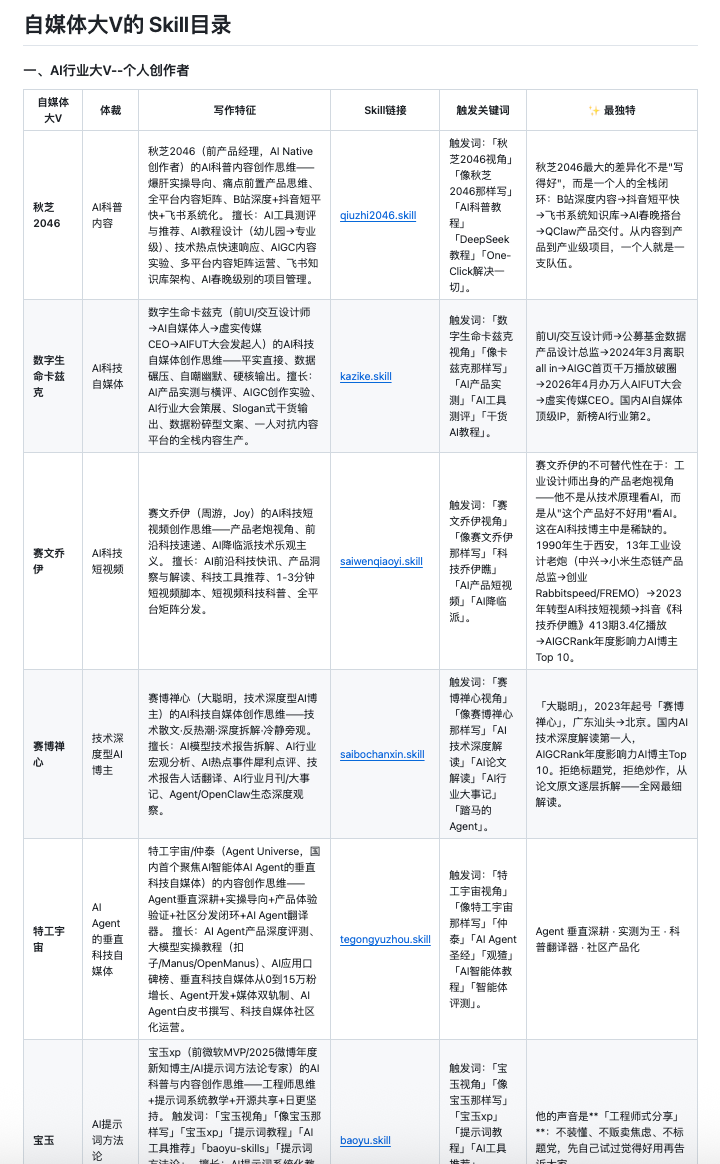
(1)AI行业大V——个人创作者(7位)
每一位都有完整SKILL.md+6份参考资料,通过nuwa-skill 6/6质量检查。
-
秋芝2046
- 定位:AI科普全栈创作者
- 风格:爆肝实操、痛点前置、产品思维、全平台矩阵
- 擅长:AI工具测评、教程设计、热点响应、AIGC实验
- 触发词:秋芝2046视角、AI科普教程、DeepSeek教程
-
数字生命卡兹克
- 定位:AI科技自媒体顶流
- 风格:平实直接、数据碾压、自嘲幽默、硬核输出
- 擅长:AI产品实测横评、Slogan式干货、数据粉碎文案
- 触发词:卡兹克视角、AI产品实测、AI工具测评
-
赛文乔伊
- 定位:AI科技短视频头部
- 风格:产品老炮、前沿速递、技术乐观主义
- 擅长:1-3分钟短视频脚本、科技快讯、工具推荐
- 触发词:赛文乔伊视角、科技乔伊瞧、AI降临派
-
赛博禅心
- 定位:技术深度型AI博主
- 风格:反热潮、冷静拆解、技术散文、全网最细
- 擅长:模型报告拆解、行业宏观分析、热点犀利点评
- 触发词:赛博禅心视角、AI技术深度解读、论文解读
-
特工宇宙
- 定位:国内首个AI Agent垂直自媒体
- 风格:垂直深耕、实操导向、产品验证、社区闭环
- 擅长:Agent评测、大模型实操教程、垂直号增长
- 触发词:特工宇宙视角、AI Agent圣经、智能体教程
-
宝玉
- 定位:提示词方法论专家
- 风格:工程师思维、系统教学、开源共享、日更坚持
- 擅长:提示词体系教学、工具实测、技术翻译
- 触发词:宝玉视角、提示词教程、宝玉xp
-
李继刚
- 定位:Prompt之神
- 风格:Lisp压缩美学、哲学底色、极简主义、结构化
- 擅长:Lisp风格提示词、哲学级思考框架、认知工作流
- 触发词:李继刚视角、Prompt之神、汉语新解
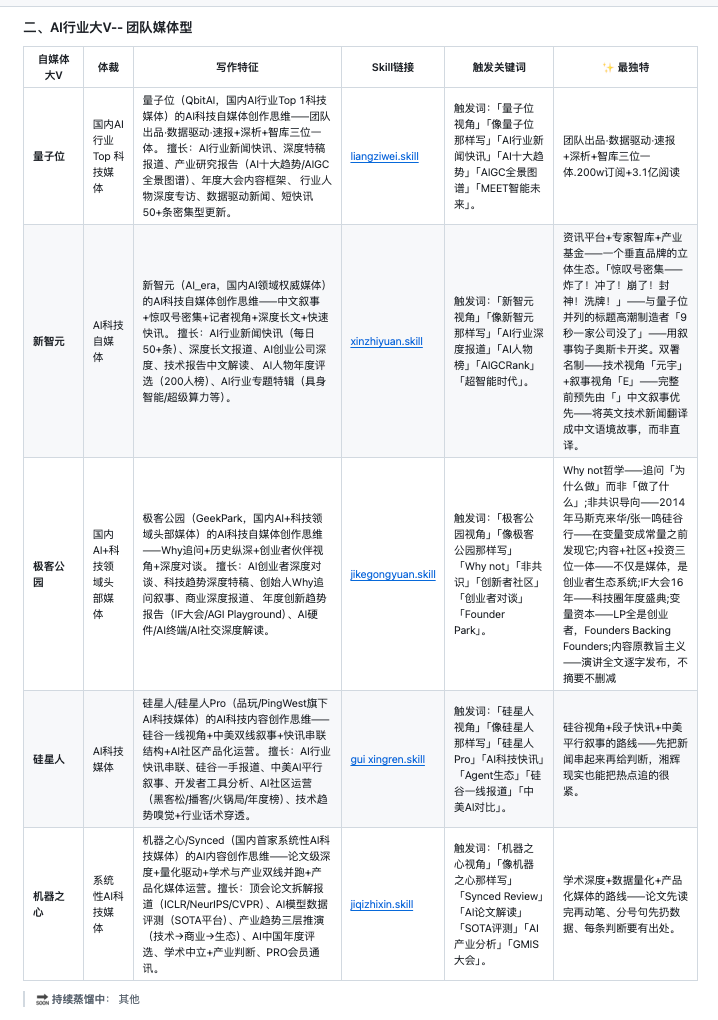
(2)AI行业大V——团队媒体(5位)
覆盖国内AI科技媒体第一梯队。
-
量子位
- 定位:AI行业Top1科技媒体
- 风格:团队出品、数据驱动、速报+深析+智库
- 擅长:行业快讯、深度特稿、产业报告、年度大会
- 触发词:量子位视角、AI十大趋势、AIGC全景图谱
-
新智元
- 定位:AI领域权威媒体
- 风格:中文叙事、记者视角、深度长文、快讯密集
- 擅长:每日50+快讯、创业公司深度、人物榜单
- 触发词:新智元视角、AI行业深度报道、AI人物榜
-
极客公园
- 定位:AI+科技头部媒体
- 风格:Why追问、历史纵深、创业者伙伴、深度对谈
- 擅长:创始人访谈、创新趋势报告、商业深度报道
- 触发词:极客公园视角、Why not、非共识、创业者对谈
-
硅星人
- 定位:硅谷一线AI媒体
- 风格:中美双线、快讯串联、社区产品化
- 擅长:硅谷一手报道、中美AI对比、开发者工具分析
- 触发词:硅星人视角、硅谷一线报道、中美AI对比
-
机器之心
- 定位:系统性AI科技媒体
- 风格:论文级深度、量化驱动、学术+产业双线
- 擅长:顶会论文拆解、模型评测、产业三层推演
- 触发词:机器之心视角、AI论文解读、SOTA评测
三、一个标准Skill,包含什么?
每一个大V Skill,都不是简单的语气模仿,
而是完整的“数字灵魂”。
标准文件结构:
大V名-perspective/
├── SKILL.md # 核心:心智模型+启发式+表达DNA
└── references/research/
├── 01-writings.md # 代表作品与内容矩阵
├── 02-conversations.md # 公开对话与行业互动
├── 03-expression-dna.md # 表达风格与语言特征
├── 04-external-views.md # 外部评价与行业共识
├── 05-decisions.md # 关键决策节点
└── 06-timeline.md # 时间线与平台分布
每一份SKILL.md,都满足6项高标准:
✅ 6个核心心智模型
✅ 模型局限性标注
✅ 高辨识度表达DNA
✅ 诚实边界声明
✅ 内在张力揭示
✅ 一手来源支撑
不是“话术模板”,
是可复用、可推理、可创作的思维系统。
四、你能用它做什么?4大核心场景
1. 写作风格一键复刻
- 用李继刚的视角,写“什么是好提示词”
→ 输出:Lisp伪代码+哲学追问+压缩美学 - 用赛文乔伊,写AI产品短视频脚本
→ 输出:产品老炮点评+1-3分钟口播结构 - 用秋芝2046,写AI工具教程
→ 输出:痛点前置+步骤清晰+全平台适配
2. 创作灵感瞬间激发
- 用极客公园视角,分析Manus
→ 输出:Why追问+非共识判断+创始人叙事 - 用硅星人,写本周AI快讯
→ 输出:硅谷视角+中美双线+段子式串联
3. 行业分析专业落地
- 用机器之心,写具身智能产业分析
→ 输出:论文级深度+三层推演+数据支撑 - 用量子位,写AI年度趋势
→ 输出:数据驱动+速报+深析+智库体系
4. 构建专属写作Agent
把SKILL.md作为system prompt,
让AI持续以该大V风格输出,
相当于拥有一个24小时在线的顶流创作助手。
五、保姆级使用教程:3种安装方式
方式1:一键安装(推荐)
国内镜像,速度更快:
curl -sL https://ghfast.top/https://raw.githubusercontent.com/momozi1996/awesome-ai-persona-skills/main/Novelists/install.sh | bash
GitHub原版:
curl -sL https://raw.githubusercontent.com/momozi1996/awesome-ai-persona-skills/main/Novelists/install.sh | bash
方式2:手动单个安装
安装AI大V:
npx skills add momozi1996/awesome-ai-persona-skills/zimeiti/qiuzhi2046-skill
npx skills add momozi1996/awesome-ai-persona-skills/zimeiti/shuzishengmingkazike-skill
npx skills add momozi1996/awesome-ai-persona-skills/zimeiti/saiwenqiaoyi-skill
安装作家文风:
npx skills add momozi1996/awesome-ai-persona-skills/Novelists/liucixin-skill
npx skills add momozi1996/awesome-ai-persona-skills/Novelists/yuhua-skill
方式3:批量离线安装
git clone https://github.com/momozi1996/awesome-ai-persona-skills.git
cp -r awesome-ai-persona-skills/Novelists/*/ ~/.stepclaw/skills/
OpenClaw原生支持
安装整个AI大V目录:
npx skills add momozi1996/awesome-ai-persona-skills/zimeiti
安装整个作家目录:
npx skills add momozi1996/awesome-ai-persona-skills/Novelists
六、如何自己蒸馏一个大V?5步搞定
如果你想把任何博主、作者、专家做成Skill,
项目内置女娲Skill蒸馏方法论,完全自动化。
步骤:
- 安装女娲Skill
npx skills add alchaincyf/nuwa-skill
- 触发蒸馏指令
非常好,用nuwa-skill蒸馏一个自媒体博主- [博主名],我希望你先查他所有资料和自媒体风格,覆盖公众号、B站、X、小红书、微博,做得全面详细准确,构造一个最像他的Skill。
-
AI自动启动6个并行Agent调研
- 著作与内容体系
- 访谈与公开表达
- 表达DNA与风格
- 他者视角与评价
- 创立逻辑与关键决策
- 时间线与平台分布
-
生成完整Skill文件(7个文件,6/6质检)
-
提交PR,贡献到开源库
七、使用样例
以下三个示例,话题完全相同——「DeepSeek-R1 入门」——但输出风格各自鲜明。
用秋芝2046视角写 DeepSeek-R1 入门:
# 🤖 DeepSeek-R1 入门:从零到能跑,全程最快5分钟
你是不是也遇到过这些崩溃瞬间?
→ 想看AI的推理过程,但它直接甩答案
→ 想让它解一道逻辑题,它绕三圈最后还错了
→ 别人家的DeepSeek跑得好好的,你这边API都叫不通
中任意一条,这篇就是为你写的。
先说结论:DeepSeek-R1 是一个能「边想边说」的大模型。
普通大模型:问题 → 直接出答案(错了也不知道为什么)
DeepSeek-R1:问题 → 先内部推理 → 把思考过程露出来 → 再出答案
Step 1:开箱即用(3分钟)
不需要装任何东西。打开 https://chat.deepseek.com → 登录 → 选「DeepSeek-R1」→ 开始聊天
Step 2:调出一个更好的它(2分钟)
进入 Settings → 把「深度思考」调到「开启」
这番操作意味着:你每次提出问题,它都会先「脑子里过一遍」再回复。
实测下来,调和不调是这个区别:
不开 → 它跟GPT-4o差不多,甚至有时不如
开了 → 数学题正确率从30% → 95%,逻辑题从40% → 85%
全程最快5分钟,小白也能轻松搞定。
用机器之心视角分析 DeepSeek-R1:
【技术解读】DeepSeek-R1:从后训练RL突破到AI推理的新范式
一、技术架构
DeepSeek-R1 采用后训练阶段的强化学习框架,核心创新在于其基于规则奖励模型(Rule-Based Reward Model)的微调路径。与 InstructGPT 时代的「RLHF based on human preference」不同,DeepSeek-R1 引入了基于数学正确性与代码执行结果的自动验证机制。
模型规模:671B 参数(MoE架构,激活参数约37B)
训练数据:约500K条RL微调数据,从基座模型R1-Zero自我生成
推理效率:在A100上与GPT-4o相比,在数学/编码任务上达到同等或更优水平
二、行业影响
本项目直接挑战了以下假设:
① 人类偏好数据是RL微调的必要条件 → DeepSeek-R1证明纯规则奖励可行
② 更强的模型需要更多标注数据 → R1-Zero展示了自演化路径
③ MoE架构的效率天花板 → 37B激活参数达到同级别全参数模型效果
三、数据对比
Benchmark(来源:DeepSeek-R1 Technical Report,2025.01)
| 任务 | GPT-4o | Claude Sonnet 3.5 | DeepSeek-R1 |
|------|--------|-------------------|-------------|
| MATH-500 | 78.2% | 76.6% | 97.3% |
| Codeforces (2000) | 180 | 196 | 2029 |
| GPQA Diamond | 73.3% | 78.0% | 71.5% |
四、方法论
1. 基座模型(R1-Zero)在纯RL下自我演化 → 涌现出高级推理行为
2. 冷启动数据(冷启动RL)→ 纠偏合并后解决可读性问题
3. 全流程可复现,模型权重已开源
本文遵循Synced Review标准:数据来源标注 / 方法论独立 / 结论可验证。
用极客公园视角聊 DeepSeek-R1:
DeepSeek-R1 到底想解决什么问题?
不是「AI能不能更聪明」。这个问题,过去十年每次GPT升级都被问一次。
DeepSeek-R1 真正想说的是:**推理这件事,不用人类教了。**
Why not?为什么必须用「人类先标注,AI再学习」这条路上走下去?
想象一下,一个学生——你告诉我答案在哪,然后让我背标准答案(这是ChatGPT的思路);另一个学生——你给我题目,你自己做,做完自己对照评分标准改(这是DeepSeek-R1的思路)。
十年了,所有公司都是第一种思路。因为第二种风险实在太大:你自己做,做错了怎么办?
DeepSeek-R1 告诉我们:做错了也没关系,所以干脆让它尽情做,然后跟一个不会犯错的标准答案对齐就行。
这背后有一个更深层的问题:**当AI开始自己跟自己对话、自己打分、自己纠错的时候,人类的角色是什么?**
答案已经不只是「对话者」了。人类变成了 **「裁判」**——你定规则,AI自己写剧本。
这跟OpenAI的路线有什么本质区别?
OpenAI在今天做的还是在加更多人类反馈。DeepSeek-R1已经跳出去了。
所以我想跟DeepSeek团队确认一个东西——
你们有没有意识到,你们正在做的这件事,实际上是在把「学习」重新定义一遍?
八、姊妹仓库:17位作家文风,直接调用
除了自媒体大V,项目还包含作家文学视角仓库:
- 刘慈欣:硬科幻、宇宙社会学
- 余华:苦难叙事、冷峻温情
- 鲁迅:国民性批判、匕首投枪
- 张爱玲:苍凉美学、沪港双城
- 当年明月:历史通俗化、幽默叙事
- 莫言:魔幻现实主义、高密东北乡
- 南派三叔、天下霸唱:悬疑探险
- 史铁生、三毛、老舍、琼瑶……
一共17位作家,一键安装,直接模仿文风写作。
八、为什么这个项目,值得所有人收藏?
- 免费开源:完全MIT协议,自由使用、二次创作
- 质量极高:每一份Skill都通过6项严格质检
- 覆盖最顶流:AI圈最能打的个人+媒体全部收录
- 即用即走:不用训练、不用部署、不用懂代码
- 持续更新:更多大V正在蒸馏中
- 社区共建:欢迎PR,一起完善Skill宇宙
对自媒体人、内容创作者、AI爱好者、产品经理、学生:
- 不会写爆款?调用大V Skill
- 不会做风格?调用大V Skill
- 不会做深度?调用大V Skill
这不是工具,是内容创作的“能力平权”。
九、写在最后
AI时代,内容的竞争,不再是勤奋,而是方法论。
顶尖大V之所以能持续产出爆款,
是因为他们有稳定的思维模型、表达体系、内容结构。
现在,这些模型被提取、封装、开放。
你不需要再花几年时间摸索,
一句话,就能站在巨人的肩膀上写作。
项目信息
- 项目名称:awesome-ai-persona-skills
- 作者:momozi1996
- GitHub:https://github.com/momozi1996/awesome-ai-persona-skills
- 协议:MIT License
- 状态:持续更新中
文末互动
你最想蒸馏哪位博主/作家?
欢迎在留言区告诉我,
下一篇,我们直接蒸馏它!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)