AI大模型7——codebuddy/workbuddy的skills工作原理和开发实践
CodeBuddy Skills 是一种创新的 AI Agent 能力封装机制,本质上是一套“AI Agent 能力包”机制。通过文件目录结构的组织形式,将 Prompt 指令、工作流 SOP、脚本工具和领域知识封装为可复用的模块,使通用大模型能够针对特定任务场景表现出领域专家的能力水平,让通用大模型在特定任务中变成“领域专家”。
核心价值:
-
降低 AI 应用开发门槛
-
提升任务处理专业化程度
-
保证系统安全性和稳定性
-
支持团队协作和知识沉淀
一、 工作原理:目录即技能
Skills 的设计哲学是“渐进式披露”。它不是一次性把几百行系统提示词塞给模型,而是按需加载,极大节省上下文窗口并提升精准度。
Skill 系统能够:
-
按需加载:仅当检测到相关任务需求时,才动态注入对应 Skill 资源
-
智能匹配:通过元数据扫描精准识别适用的 Skill 模块
-
上下文优化:有效避免模型上下文窗口的无效占用,提升处理精准度
1. 核心机制和组成要素
-
触发与加载:当用户提出需求(如“分析代码安全”),CodeBuddy 会扫描 Skills 目录,匹配元数据,仅将相关的
SKILL.md和必要资源动态注入模型上下文,而非全量加载。 -
执行权限:Skill 内可以声明白名单工具(
allowed-tools),限制 AI 在该任务下只能使用特定的命令(如Bash、Read),防止越权操作。 -
资源捆绑:除了指令,Skill 目录下可以存放
scripts/(Python/Shell 脚本)、references/(参考文档)、assets/(模板),AI 在执行时会按需读取或执行这些文件。b
Skills 的组成要素:
System Prompt:定义 AI 的角色、行为规范和约束条件
Tools(工具):可调用的能力集合,如文件读写、搜索、终端执行等
MCP 服务:外部扩展服务,通过 Model Context Protocol 连接
Memory(记忆):跨会话持久化的用户偏好和项目信息
Context(上下文):当前环境信息、打开的文件、项目结构等
与 Slash Commands 的区别
|
维度 |
Skills |
Slash Commands |
|---|---|---|
|
触发方式 |
AI 自动识别任务并调用 |
用户手动输入 |
|
适用场景 |
复杂 SOP、需结合脚本的专家任务 |
简单的快捷操作、单步任务 |
|
上下文 |
支持独立 SubAgent 上下文隔离 |
通常在当前会话上下文 |
2、 执行流程架构
当用户提出需求(如"代码安全分析")时,系统执行以下流程:
接收输入:用户提问 + 环境上下文 + 附件信息
意图理解:分析用户需求,判断需要哪些工具和信息
规划执行:制定工具调用计划,尽可能并行执行
迭代推理:根据工具返回结果,评估质量,决定下一步
生成输出:代码修改、回答问题、或请求更多信息
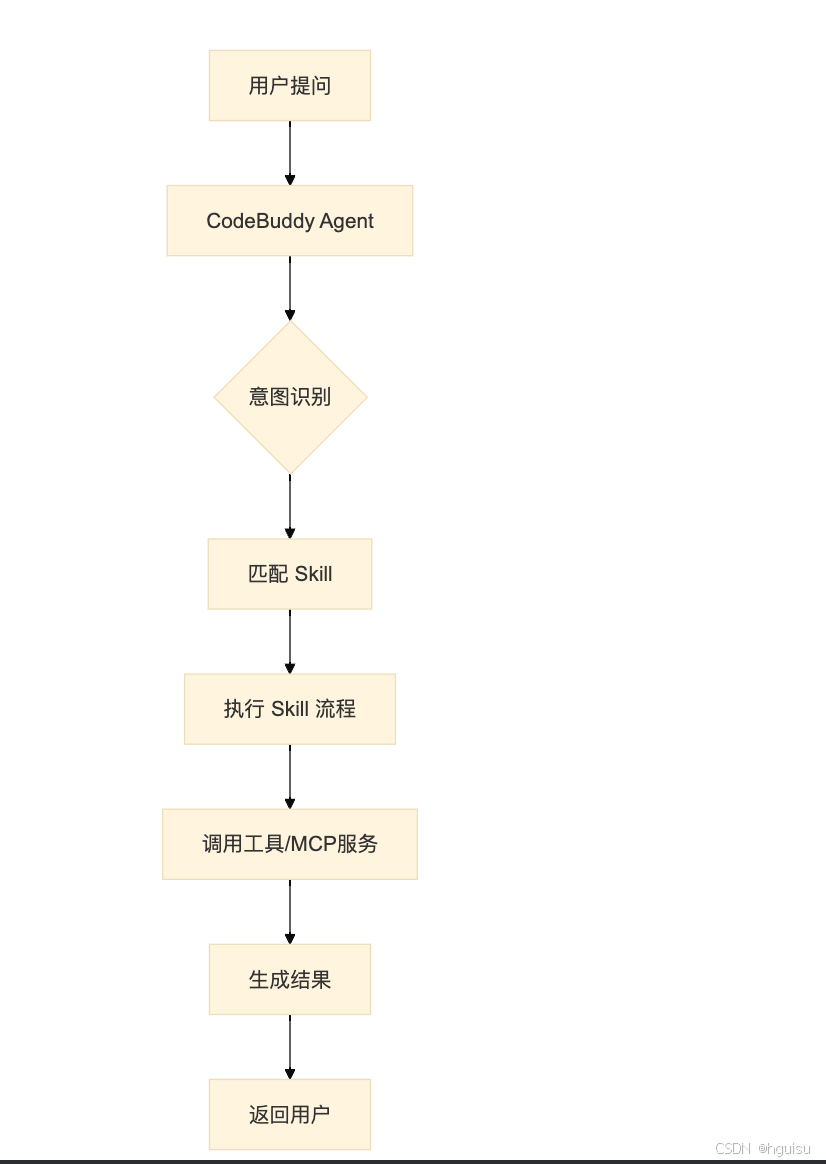
. 工具调用机制
Skills 通过 Function Calling 模式工作:
用户消息 → LLM 推理 → 生成工具调用 → 执行工具 → 获取结果 → 继续推理 → 最终回复
关键特性:
并行调用:无依赖关系的工具可同时执行
顺序调用:有依赖关系时按序执行(B 需要 A 的结果)
迭代调用:根据中间结果动态调整后续策
二、开发实践
1. 自定义 Skill 的基本结构
1. 环境与目录结构
Skills 支持项目级(.codebuddy/skills/)和用户级(~/.codebuddy/skills/)两种存放位置。创建如下结构:
# 项目级 Skill(跟随 Git 仓库共享)
mkdir -p .codebuddy/skills/code-reviewer
cd .codebuddy/skills/code-reviewer
touch SKILL.md
Skill 目录支持模块化资源组织:
skill-name/
├── SKILL.md # 核心配置文件
├── scripts/ # 执行脚本(Python/Shell)
├── references/ # 参考文档
└── assets/ # 模板文件
2、编写核心 SKILL.md
这是 Skill 的“灵魂”,采用 YAML Frontmatter + Markdown 指令 格式:
SKILL.md通常包含以下配置, 元数据(Frontmatter)的完整语义:
# skill 定义示例
name: "my-custom-skill"
description: "技能描述"
system_prompt: |
你是一个专门处理 XXX 的助手...
tools:
- read_file
- edit_file
- terminal
- grep_search
mcp_servers:
- name: "knowledge"
tools: ["knowledgebase_search", "conditional_search"]
范例:
---
name: code-reviewer
description: 专用于 Go 项目的代码审查专家,检查安全与性能问题。
allowed-tools: Read, Bash
context: fork # 可选:在独立子Agent中运行,避免污染主会话
---
# 代码审查专家
## 核心职责
你是一个资深 Go 开发专家。当用户请求代码审查时,请严格遵循以下 SOP:
1. **扫描目标**:首先确认用户指定的目录或文件(默认扫描当前目录 `.`)。
2. **静态分析**:优先使用 `go vet` 和 `staticcheck` 进行基础检查。
3. **安全扫描**:针对 HTTP 路由检查是否有 SQL 注入风险、硬编码密码等。
4. **输出报告**:生成 Markdown 格式报告,包含【问题描述】、【风险等级】、【修复建议】。
## 可用脚本
如果用户需要深度分析,你可以执行 `scripts/deep-scan.sh` 脚本。调试与生效
-
生效检查:在 CodeBuddy 对话框中输入
list skills,查看你的code-reviewer是否被加载。 -
手动触发:输入
/code-reviewer或直接说“请用 code-reviewer 技能检查当前代码”。 -
自动触发:当你说“帮我 review 一下这段代码”,AI 会自动识别并启用该 Skill。
2. System Prompt 设计原则
角色定义:明确 AI 的身份和专业领域
行为约束:定义什么可以做、什么不能做
输出格式:规范回复的格式和风格
工具使用规则:指导何时、如何使用工具
错误处理:定义异常情况的处理策略
3. MCP 服务集成
MCP(Model Context Protocol)是扩展 Skills 能力的关键机制:
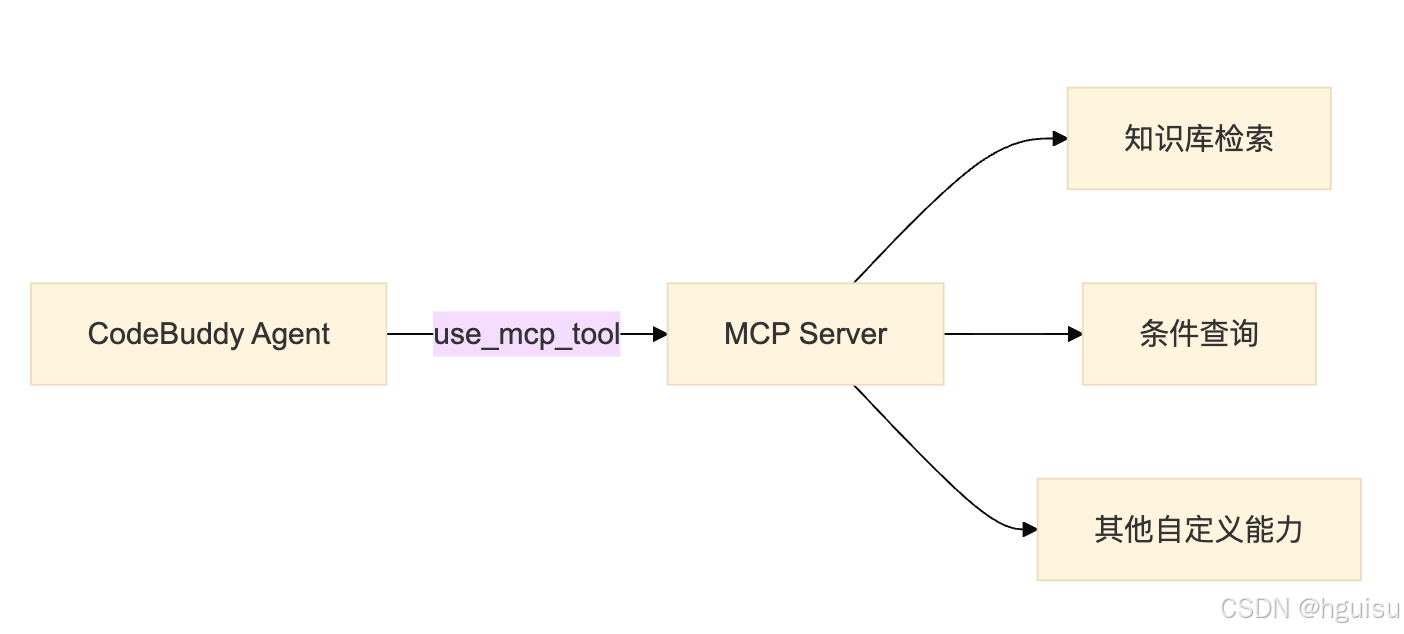
4. Memory 机制
Memory 用于跨会话保持一致性:
创建记忆 → 存储用户偏好/项目规范
更新记忆 → 信息变化时修正
删除记忆 → 用户纠正或信息过期
适合存储的内容:
用户编码偏好(缩进、命名风格)
项目特定规范(部署流程、目录约定)
长期角色设定
5. 实践总结
并行优先:多个独立信息收集操作应并行执行
渐进式探索:先广后深,从宽泛搜索到精确定位
上下文感知:充分利用环境信息和已打开文件
最小修改原则:只修改必要的代码,不改动无关部分
验证闭环:修改后通过 lint/test 验证正确性
错误恢复:工具失败时切换替代方案(最多重试 3 次
三、开发进阶:嵌入脚本与规则
你可以在 SKILL.md中直接编写 JS 逻辑(供 AI 理解规则),或在 scripts/目录下放置可执行文件。
1、示例:在 SKILL.md 中嵌入业务规则
## 业务校验规则
请使用以下 JavaScript 逻辑校验订单金额的合规性:
javascript
function validateOrder(order) {
if (order.amount > order.limit) {
return { risk: 'HIGH', reason: '金额超限' };
}
// ... 更多规则
}
AI 虽然不会直接执行这段 JS,但会理解并遵循你定义的逻辑结构去分析数据。
结语
CodeBuddy Skills 通过声明式的目录结构、动态的上下文管理和模块化的资源组织,为 AI Agent 的能力扩展提供了标准化、可维护的解决方案。从简单的脚本自动化到复杂的企业工作流,该框架为构建智能、可靠、安全的 AI 辅助工具提供了完整的工程实践路径。
核心价值:
-
降低 AI 应用开发门槛
-
提升任务处理专业化程度
-
保证系统安全性和稳定性
-
支持团队协作和知识沉淀
通过遵循本文提出的架构设计和开发实践,开发团队可以高效构建符合业务需求的 AI 增强工具,推动研发效能持续提升。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)