RNN 循环神经网络模型解剖——核心机制与数学原理
打破「静止」,引入「时间」
想象一下,你给一个普通的图像识别网络看一张猫咪的照片——它只需要看这一帧,就能立刻告诉你"这是猫"。这种网络处理的是静止的、孤立的信息,每次决策都是独立完成的,不需要任何上下文。
但是,现实世界中有大量的数据并不是孤立的——它们是有顺序、有时间的序列。比如一部悬疑电影,如果你直接跳到第十分钟,你根本看不懂凶手是谁。只有从第一分钟的伏笔,到第五分钟的线索,再到第十分钟的揭秘,整个故事才能串联起来。

这就是传统网络的困境:它们只能看"照片",无法理解"电影"。
而RNN——循环神经网络——的超能力正在于此。它能够带着一个"记忆包",在时间轴上逐步处理序列数据,把每一步的信息积累起来,传递给下一步。因为记得第一分钟,才能看懂第十分钟!
这就是RNN 与传统网络最本质的区别:感知时间,理解顺序。接下来,我们就来看看RNN 究竟长什么样子。
结构可视化——折叠视图
好,现在我们来看RNN 最简洁的一种表示方式——折叠视图。
屏幕中央这个紫色的方块,就是一个RNN 单元。从左边进来的蓝色箭头,代表当前时刻的输入 xₜ——可以理解为我们当前喂给网络的这个词、这个字符、或这帧数据。从右边出去的橙色箭头,代表当前时刻的输出 yₜ,也就是网络给出的预测结果。
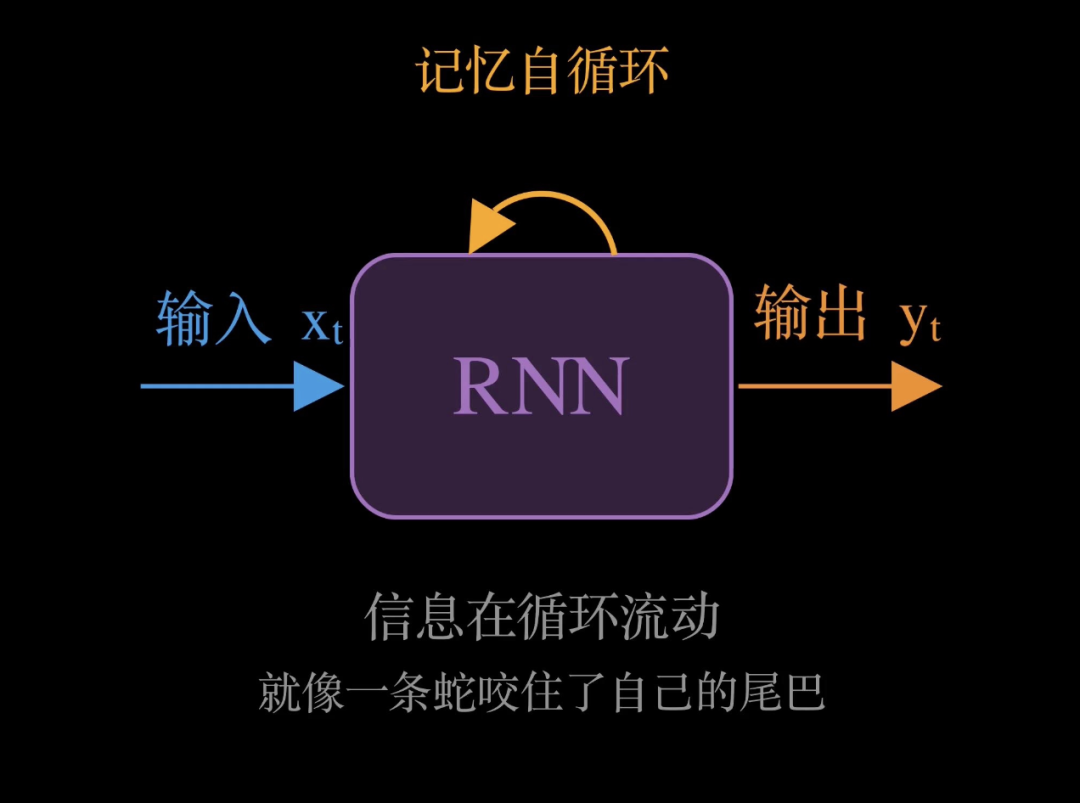
但最关键的,是这条金色的自循环箭头。它从RNN 单元的顶部出发,绕了一圈又回到自己。这个循环,代表的是记忆的回路——网络把自己上一时刻的状态,重新输入给自己,就像一条蛇咬住了自己的尾巴,信息在循环流动。
不过有一个问题:这个折叠视图虽然简洁,但在理解计算过程时非常抽象。这个"循环"究竟是什么意思?每个时间步发生了什么?我们需要把它"展开"才能看清楚。下一个场景,我们就来拆解这条"时间的链条"。
展开视图——时间的链条
现在,我们把刚才那个折叠的循环沿时间轴展开。
可以看到,同一个RNN 网络,在三个不同的时间步——t减1、t、t加1——分别处理了三个词:"I"、"love"、"AI"。每个时间步,网络都从下方接收当前的输入,从上方输出当前的预测结果。
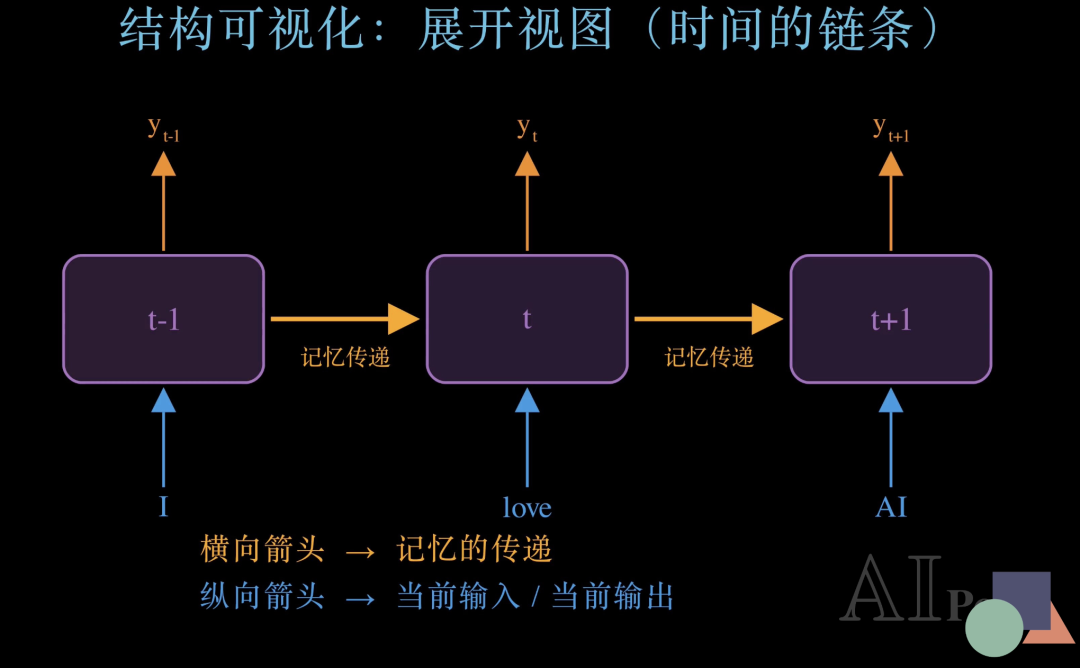
而真正体现RNN 核心思想的,是这些横向的金色箭头——它们代表记忆的传递。每个时间步处理完之后,都会生成一个隐藏状态 h,这个 h 就像一个"记忆包",被传递给下一个时间步,让下一步能够"知道"之前发生了什么。
横向是记忆的流动,纵向是当前的输入和输出——这两条轴共同构成了RNN 的计算骨架。
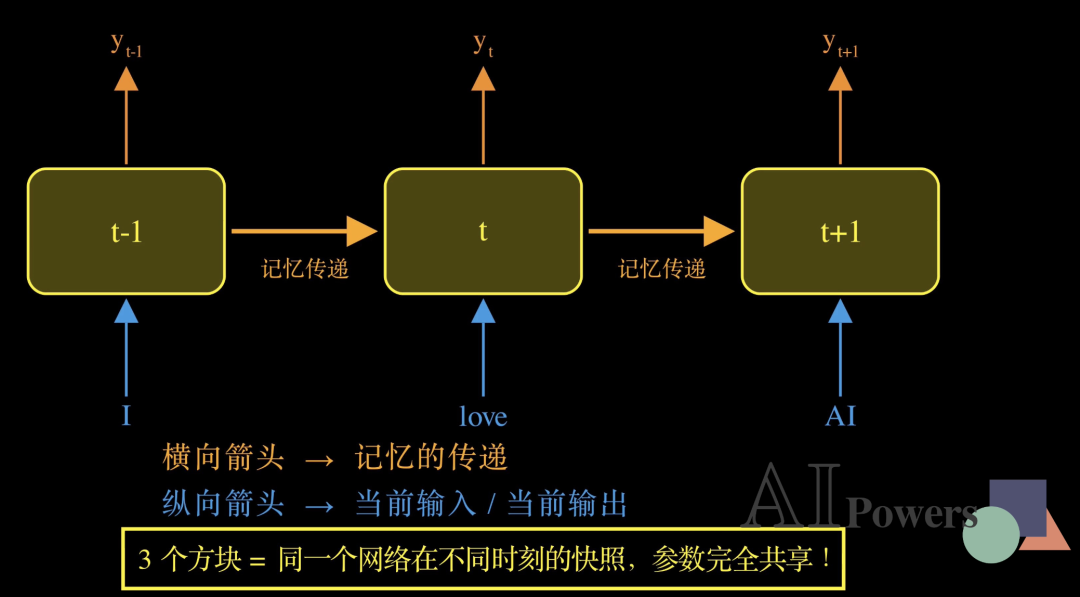
还有一个非常重要的细节:这三个方块,不是三个不同的网络,而是同一个网络在不同时刻的快照。它们共享完全相同的参数!这就是RNN 的"参数共享"机制,我们稍后会专门讲到。现在,先让我们深入理解驱动这一切的数学公式。
核心数学公式拆解
D1 — 认识变量
在推导公式之前,我们先来认识三个最核心的变量。不要被符号吓到,每一个字母都有非常直观的含义。
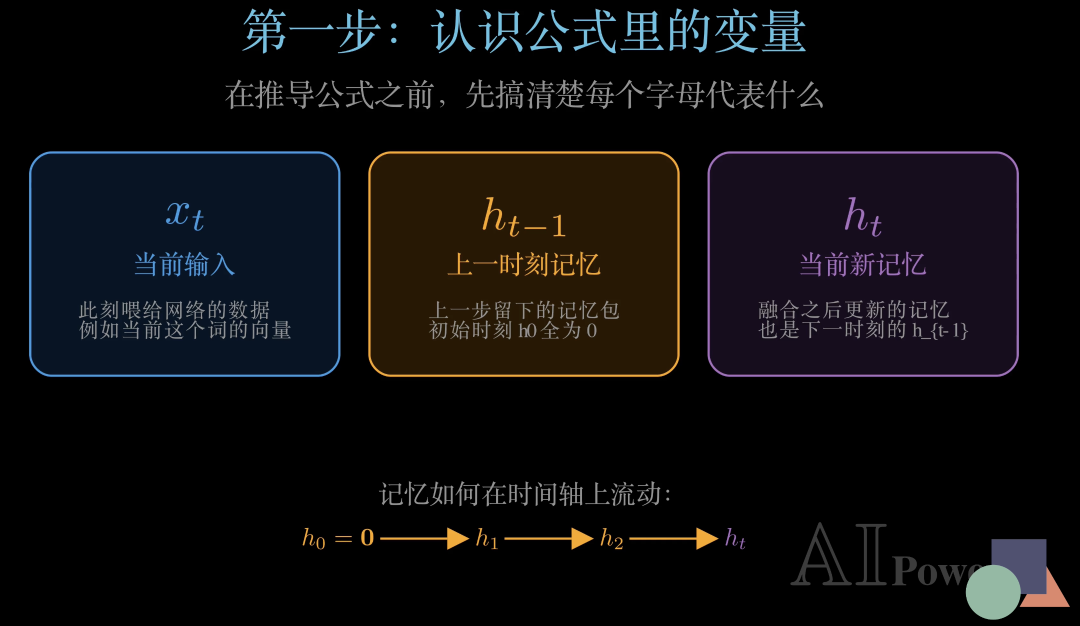
第一个是蓝色的 xt——它代表当前输入,也就是此刻我们喂给网络的数据,比如当前这个词的向量表示。
第二个是金色的h{t-1}——它代表上一时刻的记忆,也就是网络在处理上一个词之后留下的"记忆包"。需要注意的是,在最开始的第一步,这个 h0 全部初始化为零——网络从一片空白出发。
第三个是紫色的ht——它是当前新记忆,是RNN 把新输入和旧记忆融合之后生成的更新结果。它同时也会成为下一时刻的h{t -1},就这样一步一步地在时间轴上传递下去。
理解了这三个变量,公式就已经成功了一半。
D2 — 做菜类比
如何理解RNN 每一步在做什么?我们用一个做菜的类比来说明。
你可以把当前输入 xt理解为"新鲜食材"——今天刚采购回来的这个词。把上一时刻的记忆h{t-1}理解为"上锅的半成品"——之前所有词留下来的精华提炼。
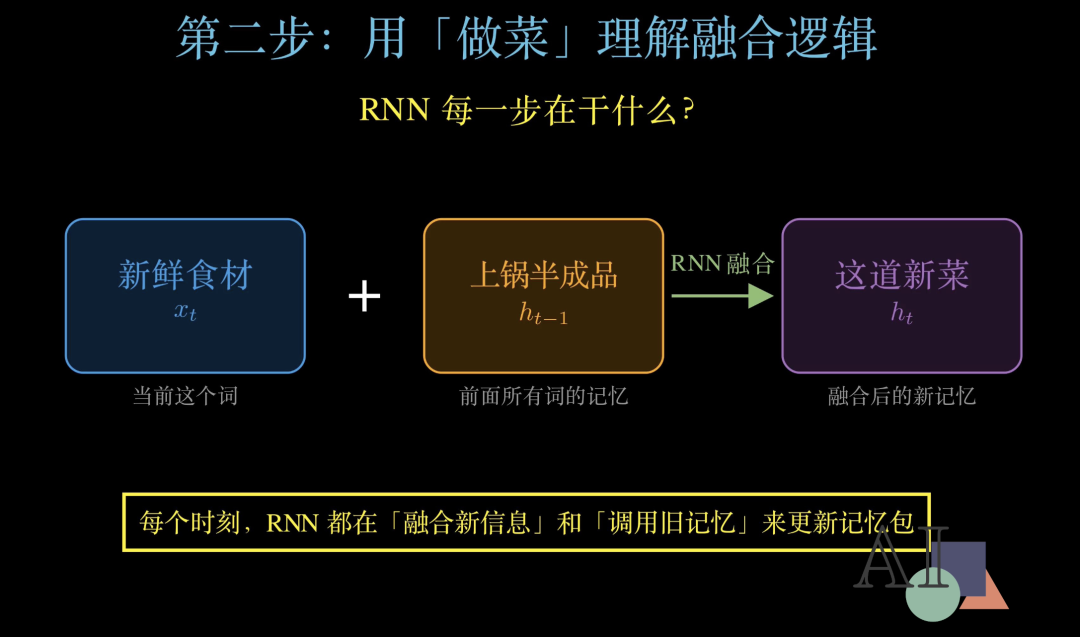
RNN 要做的事情,就是把这两样东西放进锅里一起融合,煮出一道新菜ht——更新后的记忆。
每个时间步,RNN 都在干同一件事:融合新信息,调用旧记忆,产出新的记忆包。这道"菜",既带着今天食材的鲜味,也保留了之前所有积累的火候与经验。
D3 — 公式全貌
现在,我们来看公式的完整面貌:

这就是RNN 的核心公式。别被它吓到,我们来逐项解读颜色:
紫色的ht——这是我们要求的结果,更新后的新记忆。
绿色的——激活函数,负责把数值压缩进安全范围。
蓝色的Wx 乘以xt——对新信息的处理,权重矩阵乘以当前输入。
金色的Wh 乘以h{t-1}——对旧记忆的调用,权重矩阵乘以上一时刻状态。
黄色的 b——偏置项,可学习的基准调节量。
这五个部分,各司其职,共同完成了RNN 的一步计算。接下来,我们逐项放大看清楚。
D4 — 逐项拆解
第一项:Wx 乘以 xt,处理新信息。
权重矩阵Wx决定了"我该多大程度地重视这个新词"。它就像在给食材调味——有些词要重点关注,有些可以轻描淡写。用具体数字举例:如果输入向量是[0.8, 0.2],经过Wx变换后得到[0.46, 0.26]。新信息就此被"提炼"出来。

第二项:Wh乘以h{t-1},回顾旧记忆。
权重矩阵Wh决定了"过去的经验对现在影响有多大"。就像厨师根据上一锅的经验,来调整这一锅的火候。旧记忆经过Wh 提炼后,得到[0.42, 0.44]——精华被保留下来了。

第三项:相加,融合新旧。
把处理后的新信息和提炼后的旧记忆直接相加——加法是最直接的信息融合方式,简单却有效。结果是[0.88, 0.70],等待激活函数处理。

第四项:偏置 b,调节基准。
b 是一个可学习的常数,它平移整个激活范围,让网络不必完全依赖输入,保留一定的"默认倾向"。加上偏置后,最终结果准备送入激活函数。

D5 — tanh 激活函数
现在我们来专门讲激活函数——为什么这个激活函数对RNN 来说不可或缺?
先看不加激活函数会怎样:每个时间步的数值都在累乘,从 1.0 开始,一步步膨胀到 11.4……这就是所谓的"梯度爆炸"。网络训练会完全失控,根本无法收敛。
再看加了激活之后:无论输入多大多小,输出始终被压缩在负1 到 1的范围内。曲线平滑,梯度稳定,训练得以正常进行。
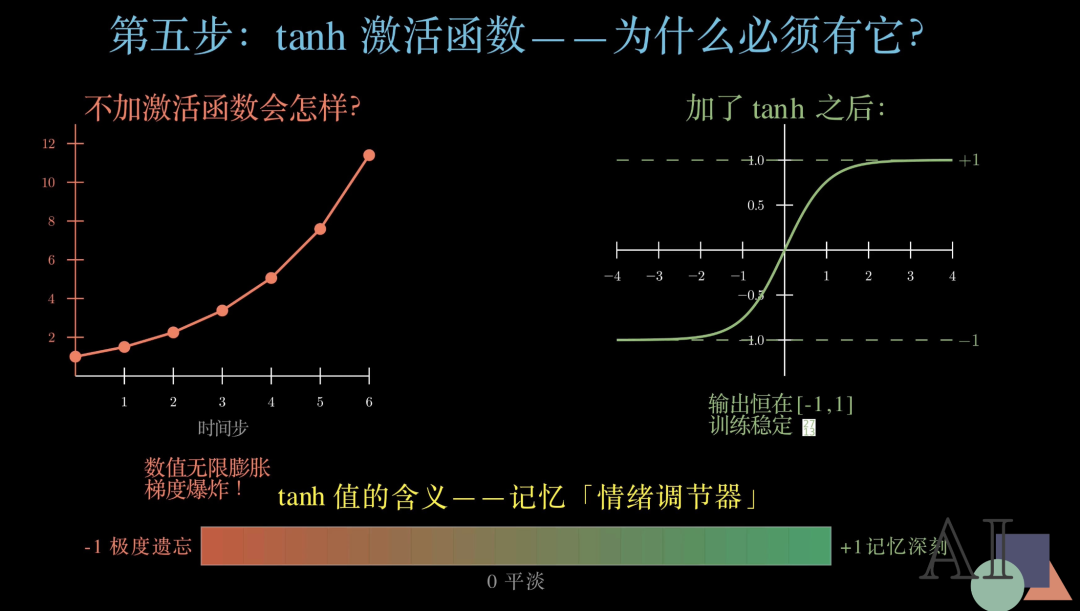
我们还可以给激活的输出赋予一层直觉意义——把它理解为记忆的"情绪调节器":接近负1 意味着极度遗忘这条信息;接近 0 意味着平淡处理;接近1 意味着深刻记住、高度重视。激活让网络学会了"有所取舍"。
D6 — 输出层与完整数据流
有了新记忆ht,我们怎么得到最终的预测结果呢?

答案是再加一层输出变换:Softmax函数。首先用权重矩阵 Wy对ht做线性变换,然后通过Softmax 函数,把结果转化为词表中每个词的概率分布,概率最高的那个词,就是本时刻的预测输出。
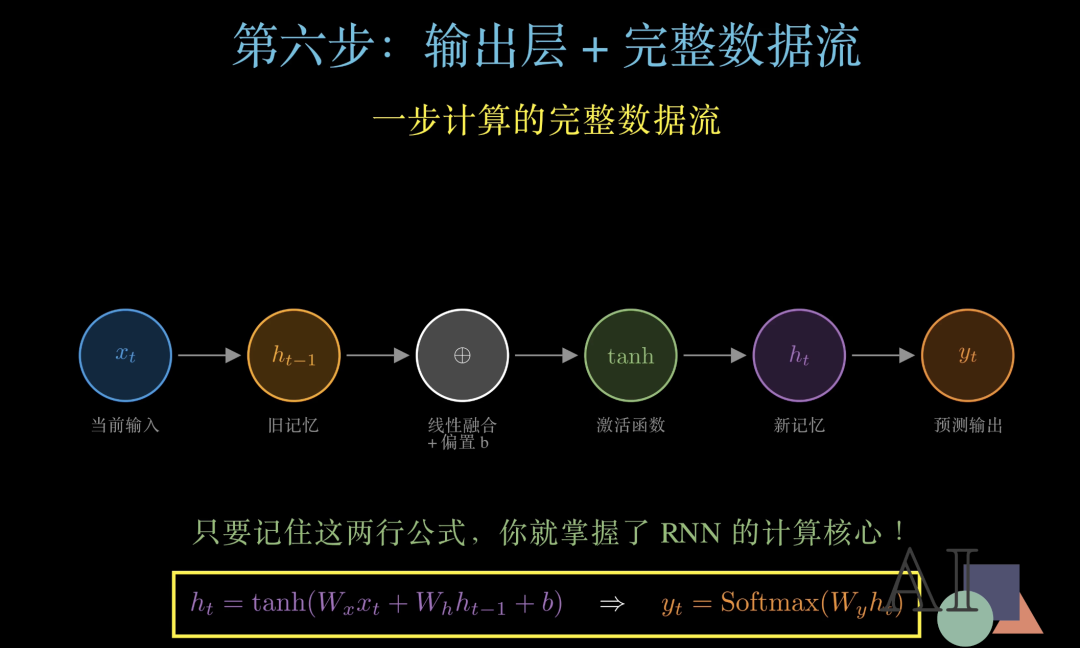
现在把所有环节串联起来:xt进入→和h{t -1} 线性融合→加偏置 b →通过激活函数→得到新记忆ht→最后经过Softmax 输出 yt。
只要记住这两行公式,你就掌握了RNN 的全部计算核心!接下来,我们用一个真实的语言预测案例,把这个流程走一遍。
案例——预测下一个词
理论讲完了,现在来看一个生动的实际案例:用RNN 逐词处理句子"I am a student",预测下一个词。
第一步,t等于1,输入"I":
此时网络的记忆包 h0 全为零——它刚出生,一无所知。RNN 融合"I"和零向量,生成了第一个隐藏状态 h1,里面主要包含"主语I"的信息。根据这个状态,网络预测下一个词最可能是"am"。

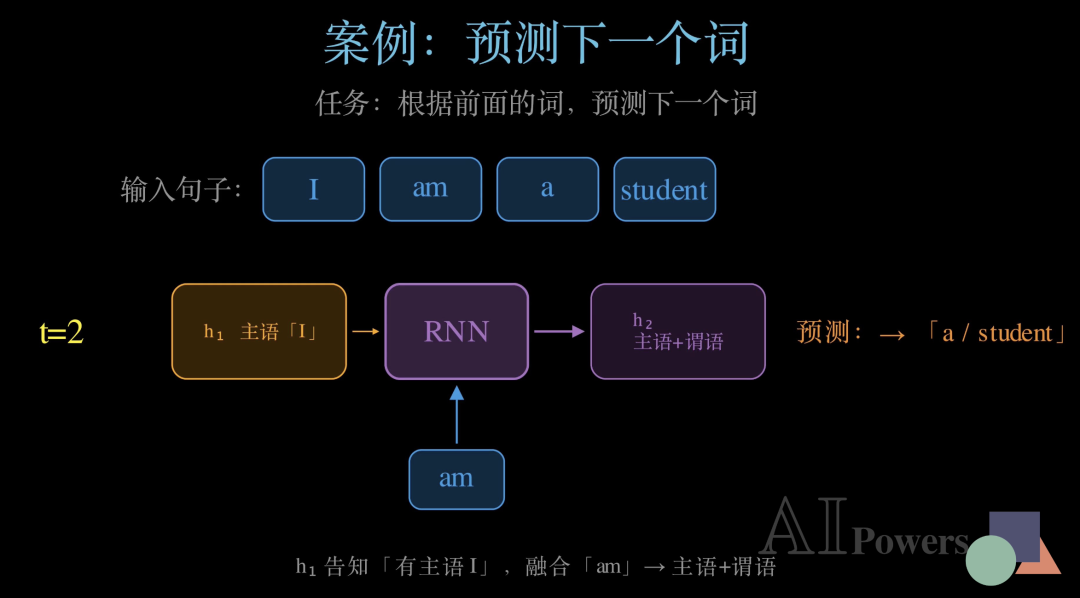
第二步,t等于2,输入"am":
这次记忆包 h1带着"主语I"的信息参与融合。RNN 把"am"的输入和"主语信息"合并,生成 h2——里面现在有了"主语+谓语"的完整语境。预测结果变成了"a"或"student",已经相当准确!
第三步,t等于3,输入"a":
h2告诉网络前面已经有了"主语+谓语",现在再加上冠词"a",h3 已经积累了完整的语境信息。网络非常有把握地预测:下一个词是"student"。
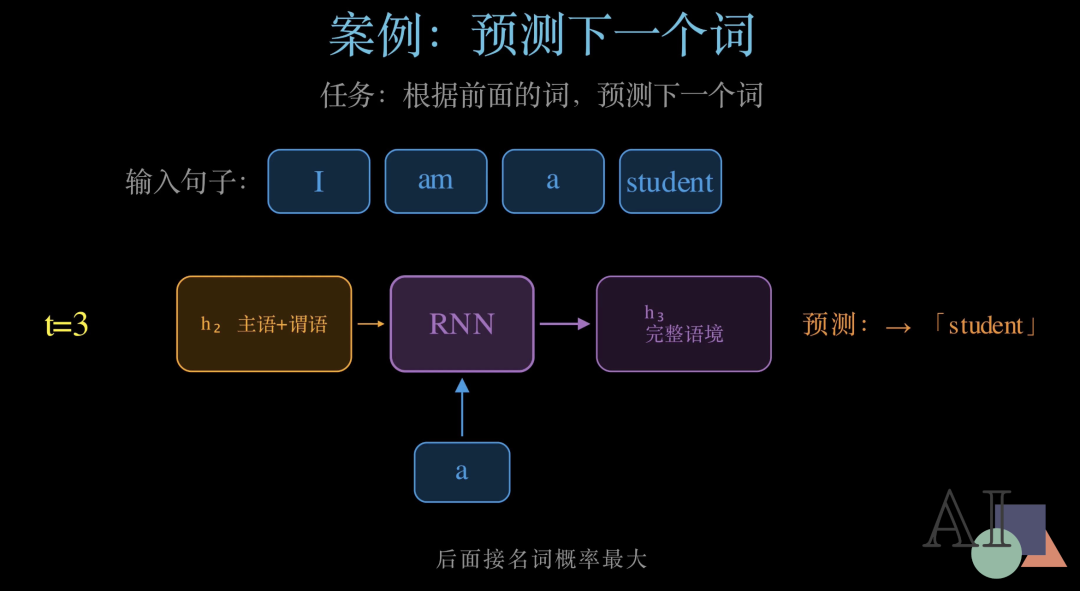
这个案例完美地展示了RNN 的工作方式:正是因为每一步都记得之前的内容,才能做出越来越准确的预测。关键在于Wh 乘以h{t-1} 这一项——它是RNN "记忆"的物理实现。接下来我们来看RNN 一个非常优雅的设计——权值共享。

权值共享——极简美学
这里有一个问题:处理"I"和处理"am"的网络,它们的参数Wx、Wh是同一套吗?
答案是:完全一样!
不管是第 t减1 步、第 t 步,还是第 t加1 步,所有时间步用的都是同一套参数。这就是RNN 的"权值共享"机制。
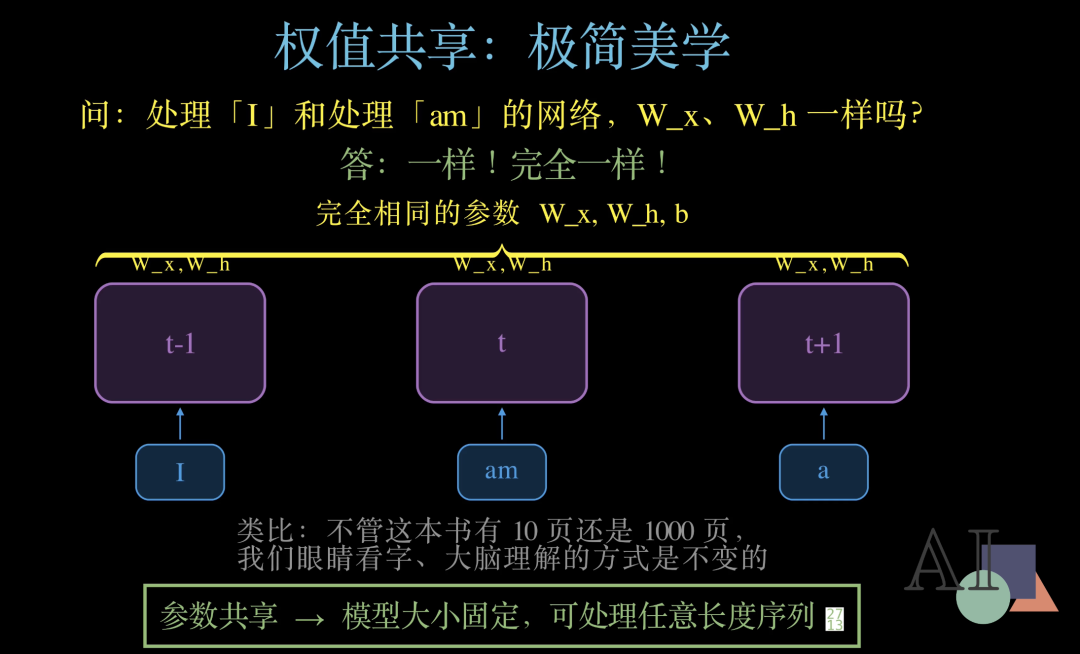
用一个类比来理解:不管一本书有 10 页还是 1000 页,我们眼睛看字、大脑理解文字的方式是不变的。同样,不管输入序列有多长,RNN 处理每个时间步的方式——也就是那套参数——始终如一。
这个设计有什么好处呢?
模型大小固定,可以处理任意长度的序列。无论句子是 5 个词还是 500 个词,RNN 的参数量不会随序列长度增长。这是传统全连接网络无法做到的——想象一下,如果每个时间步都用独立的参数,处理长文本的模型将会大得无法承受。
权值共享,是RNN 设计中一种真正的极简美学。而搞懂了这一点,RNN 的核心就已经完全在你掌握之中了。
总结——四句口诀记住RNN
好,我们来做一个全面的总结。把整个RNN 的核心,压缩成四句话。
再看一眼这个公式:

第一句:一入一出藏状态。 RNN 的每一步,都有一个输入 x,一个输出 y,但最核心的是中间流动的隐藏状态 h——它是记忆的载体。
第二句:当前过去加一块。 Wx乘以xt处理当前输入,Wh乘以h{t减1} 调用过去记忆,两者相加融合——这是RNN 运转的核心动作。
第三句:激活函数要把范围盖。激活函数把计算结果压缩到负1 到1 之间,防止数值爆炸,让训练保持稳定。
第四句:参数共享真不赖。无论序列多长,都用同一套参数处理,模型大小固定,泛化能力强。
这四句话,就是RNN 的完整精髓。
不过,RNN 也有它的局限性——当序列非常长时,早期的记忆会随着时间步的增加逐渐淡化,这就是所谓的"长期依赖问题"。而解决这个问题的,是下一个重要角色:LSTM——长短时记忆网络,它引入了"门控机制",让记忆的遗忘与保留变得更加智能。
我们下一节见!
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)