【CLAUDE】Memory 与 CLAUDE.md:打造你的专属 AI 助手
1. 为什么需要 Memory 系统
Claude Code 每次开启新会话,对你的项目一无所知。它不知道你用的是 Python 3.12 还是 Node.js 20,不知道你的团队规定 commit message 必须用 Conventional Commits 格式,也不知道 config/ 目录下的文件绝对不能动。
这意味着每次开新会话,你都得重复告诉它同样的事情:
"我们用 Python 3.12,包管理用 Poetry"
"commit message 用 feat/fix/chore 前缀"
"不要碰 config/production.yaml"
重复三次你就会烦了。重复十次你可能已经开始考虑放弃 Claude Code。
CLAUDE.md 就是解决这个问题的——它是一个 Markdown 文件,Claude Code 启动时会自动读取,把里面的内容作为持久化的项目上下文注入到每次会话中。你把项目规范、编码约定、禁止事项写进去,Claude 每次启动都会"记住"这些信息。
根据我的实际使用体验,一份写得好的 CLAUDE.md 大约能减少 50% 的重复沟通。原本需要反复提醒的东西,写一次就够了。
2. 配置文件层级与优先级
Claude Code 的配置体系分为多个层级,从高到低排列如下:
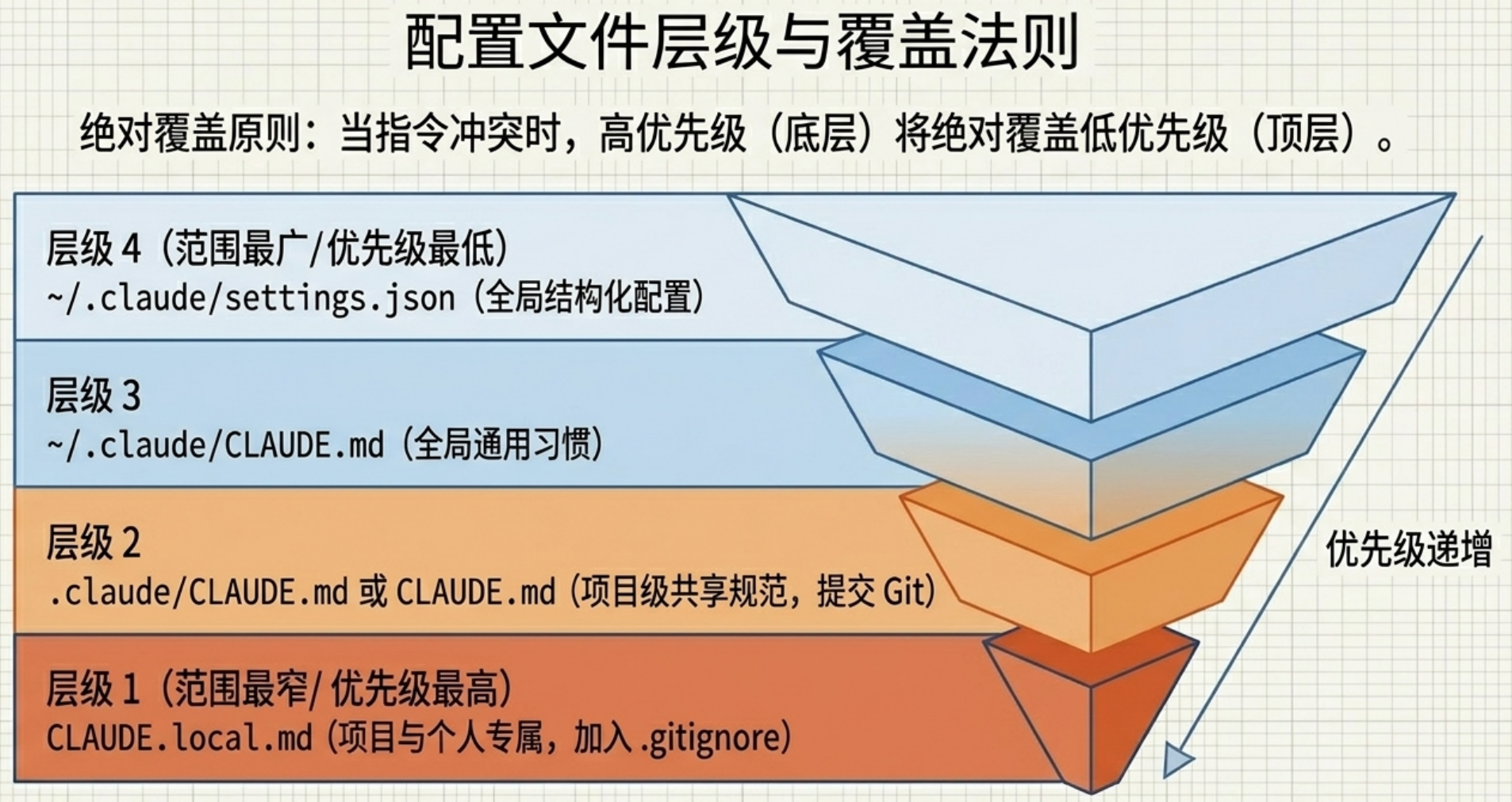
优先级实测:当多个文件对同一个问题给出不同指令时,高优先级的文件会覆盖低优先级的。比如全局 CLAUDE.md 写了"用英文回答",而项目 CLAUDE.local.md 写了"用中文回答",最终 Claude 会用中文回答。
CLAUDE.md 与 settings.json 的分工
这两个文件职责不同,不要混用:
-
CLAUDE.md:自然语言指令。告诉 Claude “做什么"和"怎么做”——项目描述、编码规范、工作流约定。
-
settings.json:结构化配置。控制 Claude Code 本身的行为——权限规则、钩子声明、环境变量。
一个负责"教"Claude,一个负责"管"Claude。
3. CLAUDE.md 编写指南
CLAUDE.md 写得好不好,直接决定了 Claude Code 的表现。下面是各个板块的编写建议。
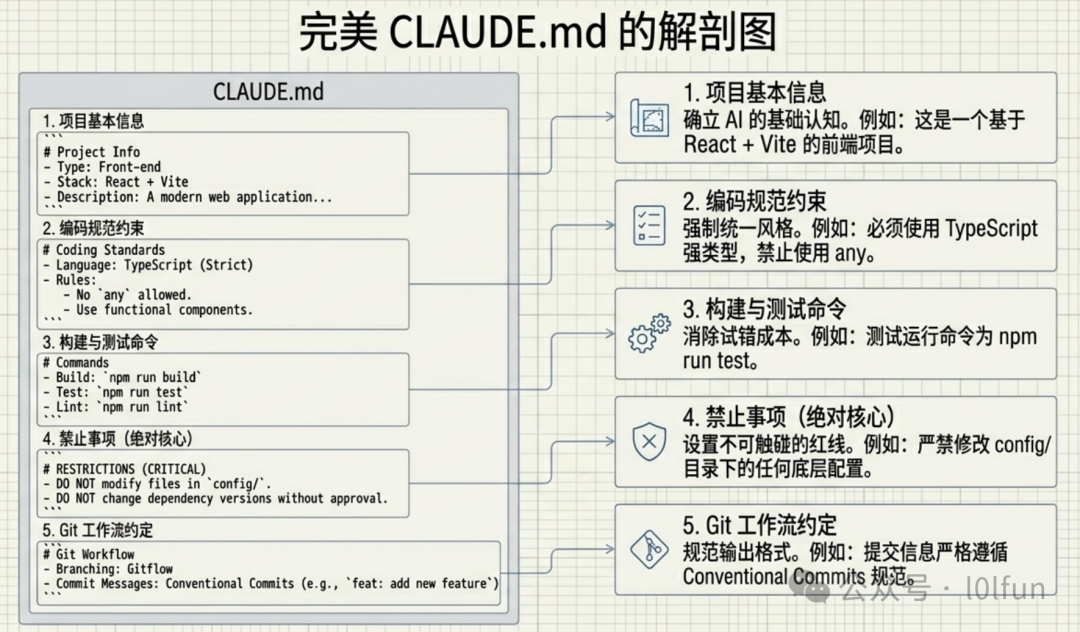
3.1 项目基本信息
把项目的关键信息写在最前面,让 Claude 快速建立认知:
# 项目概述
- 语言:Python 3.12
- 框架:FastAPI + SQLAlchemy 2.0
- 包管理:Poetry
- 数据库:PostgreSQL 15
- 缓存:Redis 7
## 目录结构
- `src/` — 主要源码
- `src/api/` — API 路由层
- `src/models/` — SQLAlchemy 数据模型
- `src/services/` — 业务逻辑层
- `tests/` — 测试代码
- `alembic/` — 数据库迁移脚本
- `config/` — 配置文件(不要修改)
3.2 编码规范约束
把团队的编码规范明确写出来,Claude 会严格遵守:
## 编码规范
- 使用 4 空格缩进,不用 Tab
- 函数和变量用 snake_case,类名用 PascalCase
- import 顺序:标准库 → 第三方库 → 本地模块,各组之间空一行
- 类型注解是强制的,所有函数参数和返回值都要有类型标注
- 字符串统一用双引号
- 单个函数不超过 50 行,超过就拆分
3.3 构建与测试命令
告诉 Claude 怎么跑项目、怎么测试:
## 常用命令
- 安装依赖:`poetry install`
- 运行开发服务器:`poetry run uvicorn src.main:app --reload`
- 运行全部测试:`poetry run pytest`
- 运行单个测试文件:`poetry run pytest tests/test_xxx.py -v`
- 代码格式化:`poetry run black src/ tests/`
- 类型检查:`poetry run mypy src/`
- lint 检查:`poetry run ruff check src/`
3.4 禁止事项
这一条非常重要——明确告诉 Claude 什么不能做:
## 禁止事项
- 不要修改 config/production.yaml 和 config/staging.yaml
- 不要删除 alembic/versions/ 下的任何迁移文件
- 不要修改 .github/workflows/ 下的 CI 配置
- 不要在代码中硬编码任何密钥、密码或 API Key
- 不要使用 `os.system()` 执行命令,用 `subprocess.run()`
- 不要直接操作数据库,所有数据库操作通过 SQLAlchemy ORM
3.5 Git 工作流约定
## Git 规范
- 分支命名:`feat/xxx`、`fix/xxx`、`chore/xxx`
- commit message 格式:`<type>(<scope>): <description>`
- type: feat / fix / chore / docs / refactor / test / ci
- scope: 可选,标明影响的模块
- 示例:`feat(api): 添加用户注册接口`
- 提交前必须通过 `pytest` 和 `ruff check`
- 不要使用 `git push --force`
3.6 完整模板示例
Python 项目模板:
# 项目:user-service
Python 3.12 + FastAPI + PostgreSQL 的用户服务。
## 技术栈
- 框架:FastAPI 0.110+
- ORM:SQLAlchemy 2.0(async)
- 包管理:Poetry
- 测试:pytest + pytest-asyncio
- 数据库:PostgreSQL 15
## 目录结构
- `src/api/` — 路由和请求/响应模型
- `src/models/` — 数据模型
- `src/services/` — 业务逻辑
- `src/repositories/` — 数据访问层
- `tests/` — 测试(镜像 src 结构)
## 编码规范
- snake_case 变量/函数,PascalCase 类名
- 强制类型注解
- import 顺序:stdlib → third-party → local
- 异步函数统一用 async/await
## 命令
- 测试:`poetry run pytest -v`
- 格式化:`poetry run black .`
- Lint:`poetry run ruff check .`
- 迁移:`poetry run alembic upgrade head`
## 禁止
- 不要修改 alembic/env.py
- 不要在 service 层直接 import model(通过 repository)
- 不要硬编码配置值,用环境变量
## Git
- 分支:feat/xxx, fix/xxx
- Commit:conventional commits 格式
- 提交前跑 pytest + ruff
Node.js 项目模板:
# 项目:dashboard-web
React 18 + TypeScript + Vite 前端项目。
## 技术栈
- React 18 + TypeScript 5.4
- 构建:Vite 5
- 状态管理:Zustand
- UI:Tailwind CSS + Radix UI
- 测试:Vitest + Testing Library
- 包管理:pnpm
## 目录结构
- `src/components/` — UI 组件(按功能分目录)
- `src/pages/` — 页面组件
- `src/hooks/` — 自定义 Hooks
- `src/stores/` — Zustand store
- `src/api/` — API 调用封装
- `src/types/` — TypeScript 类型定义
## 编码规范
- 组件用 PascalCase,hooks 用 camelCase 且以 use 开头
- 优先用函数组件 + hooks,不用 class 组件
- CSS 用 Tailwind utility class,不写自定义 CSS
- 组件 props 必须定义 interface,不用 any
## 命令
- 开发:`pnpm dev`
- 构建:`pnpm build`
- 测试:`pnpm test`
- Lint:`pnpm lint`
- 类型检查:`pnpm typecheck`
## 禁止
- 不要用 `var`,用 `const` / `let`
- 不要用 `any` 类型
- 不要直接操作 DOM,用 React ref
- 不要在组件中直接调 fetch,封装到 src/api/
## Git
- Commit:conventional commits
- PR 必须包含测试
4. CLAUDE.local.md 个人覆盖
CLAUDE.local.md 放在项目根目录,但不提交到 Git(加入 .gitignore)。它的优先级最高,用来存放你的个人偏好和本地环境配置。
适用场景
-
你个人的语言偏好
-
本地开发环境的特殊路径
-
个人 SSH 配置或数据库连接信息
-
覆盖团队 CLAUDE.md 中你不认同的规则
与团队 CLAUDE.md 的配合策略
团队 CLAUDE.md 定义通用规范,个人 CLAUDE.local.md 做针对性覆盖。比如团队规定"commit message 用英文",但你负责的子模块的 commit 需要中文描述,就在 local 里覆盖。
示例
# 个人配置
## 语言
始终用中文回答问题。
## 本地环境
- 本地 PostgreSQL:localhost:5432,用户名 dev,密码 dev123
- Redis:localhost:6379
- 本地测试用的 API Key 在 .env.local 中
## SSH
- 部署服务器:ssh dev@192.168.1.100
- 跳板机:ssh jump@10.0.0.1
## 个人偏好
- 代码注释用中文
- 写测试时先写 happy path,再写边界情况
- debug 时优先用 print 而不是 debugger
记得在 .gitignore 里加上:
CLAUDE.local.md
5. 全局 CLAUDE.md
全局配置文件位于 ~/.claude/CLAUDE.md,对所有项目生效。适合放那些不管在哪个项目都通用的偏好。
适用场景
-
回答语言偏好(比如"始终用中文回答")
-
通用代码风格偏好
-
跨项目的通用禁止事项
示例
# 全局配置
始终用中文回答问题。
## 通用规范
- 写代码时添加必要的注释,解释"为什么"而不是"做什么"
- 错误处理不要用空的 try-catch/except,至少要 log
- 不要在代码中留下 TODO 注释而不说明
- 生成的代码要可直接运行,不要用伪代码占位
## 通用禁止
- 不要创建 README.md 除非我明确要求
- 不要在回答中使用 emoji
- 不要生成超过 200 行的单个函数
- 不要使用已弃用的 API 或库
全局 CLAUDE.md 的内容要保持精简。如果写太多,会和项目级配置产生不必要的冲突。我个人的全局配置就两行——“始终用中文回答问题”,仅此而已。其他的都放在项目级。
6. settings.json 深度解析
settings.json 是 Claude Code 的结构化配置文件,和 CLAUDE.md 不同,它控制的是 Claude Code 工具本身的行为。
6.1 权限规则配置
通过 allowedTools 和 deniedTools 控制 Claude 能使用哪些工具:
{
"permissions": {
"allowedTools": [
"Read",
"Write",
"Edit",
"Bash(npm test*)",
"Bash(npm run*)",
"Bash(git status)",
"Bash(git diff*)",
"Bash(git log*)"
],
"deniedTools": [
"Bash(rm -rf*)",
"Bash(git push --force*)",
"Bash(DROP TABLE*)"
]
}
}
allowedTools 里的工具 Claude 可以直接使用,不需要每次询问你。这能大幅减少权限确认弹窗。deniedTools 里的工具则被完全禁止,Claude 无论如何都不能调用。
工具名支持通配符模式。Bash(npm test*) 表示所有以 npm test 开头的命令都允许。
6.2 钩子声明
Hooks 在 settings.json 中声明,它们在特定事件触发时自动执行:
{
"hooks": {
"PostToolUse": [
{
"matcher": "Write|Edit",
"type": "command",
"command": "npx prettier --write $CLAUDE_FILE_PATH"
}
]
}
}
这个例子在 Claude 每次写入或编辑文件后自动运行 Prettier 格式化。关于 Hooks 的完整用法,会在其它章节展开。
6.3 环境变量
一些有用的环境变量可以在 settings.json 中声明,也可以在 shell 中设置:
|
变量
|
作用
|
| — | — |
| CLAUDE_CODE_DISABLE_UPDATES |
禁用自动更新检查
|
| CLAUDE_CODE_HIDE_CWD |
隐藏工作目录(安全考虑)
|
| ANTHROPIC_API_KEY |
API 密钥
|
| CLAUDE_CODE_MAX_OUTPUT_TOKENS |
限制最大输出 token 数
|
6.4 项目级 vs 全局级 settings 的合并
settings.json 有两个位置:
-
全局:
~/.claude/settings.json -
项目级:
项目根目录/.claude/settings.json
合并规则是取并集:两边的 allowedTools 合并,deniedTools 也合并。如果同一个工具同时出现在 allowedTools 和 deniedTools 中,deniedTools 优先(安全第一)。
项目级 settings.json 可以提交到 Git,让团队共享权限规则。但要注意——项目级 settings 中的权限规则在首次加载时需要用户确认,Claude Code 会提示"这个项目想要允许/禁止某些工具,是否同意?"。
7. Auto Memory 系统
除了手动编写的 CLAUDE.md,Claude Code 还有一套自动记忆系统,能在对话过程中自动捕获和存储关键信息。
7.1 工作机制
当你在对话中告诉 Claude 一些重要信息,比如"记住,这个项目的测试覆盖率必须保持在 80% 以上",Claude 会自动将这条信息存储到记忆系统中。下次新会话启动时,这些记忆会被自动加载。
你也可以主动触发记忆存储,直接说"记住这个"或者"把这条加到记忆里"。
7.2 MEMORY.md 索引文件
自动记忆存储在 ~/.claude/projects/<project-hash>/memory/ 目录下。MEMORY.md 是索引文件,结构如下:
# Memory Index
- [编码规范要求](reference_coding_standards.md) — 项目编码规范和代码风格要求
- [部署流程](reference_deployment.md) — 生产环境部署的标准流程
- [CLAUDE.md 优先级规则](reference_claude_md_priority.md) — CLAUDE.md 各层级文件的加载优先级
每条记忆是一个独立的 Markdown 文件,MEMORY.md 维护它们的索引。
7.3 记忆类型
每条记忆文件的 frontmatter 中有 type 字段,标明记忆类型:
|
类型
|
含义
|
典型内容
|
| — | — | — |
| user |
用户偏好
|
“始终用中文回答”、“喜欢简洁的代码风格”
|
| feedback |
反馈修正
|
“上次生成的代码有 bug,正确做法是…”
|
| project |
项目信息
|
项目架构、技术栈、团队约定
|
| reference |
参考知识
|
配置规则、API 用法、排查经验
|
7.4 手动管理
让 Claude 记住某些信息:
直接在对话中说:
-
“记住:这个项目的 API 返回格式统一用
{code, data, message}” -
“把这个加入记忆:部署前必须跑 integration test”
让 Claude 忘记某些信息:
-
“忘记之前关于数据库连接的记忆”
-
“删除关于旧 API 格式的记忆”
Claude 会更新 MEMORY.md 索引并删除对应的记忆文件。
查看当前记忆:
你可以直接问 Claude “你现在记住了哪些关于这个项目的信息?”,它会列出当前加载的所有记忆。
8. Monorepo 与多项目配置
大型项目通常是 Monorepo 结构——一个仓库里包含多个子项目。Claude Code 对此有良好的支持。
8.1 子目录级 CLAUDE.md 的发现机制
Claude Code 在启动时会从当前工作目录向上遍历,加载路径上所有的 CLAUDE.md 文件。同时,当 Claude 在会话中进入某个子目录工作时,也会加载该子目录下的 CLAUDE.md。
monorepo/
├── CLAUDE.md # 根目录:通用规范
├── packages/
│ ├── backend/
│ │ ├── CLAUDE.md # 后端子项目规范
│ │ └── src/
│ └── frontend/
│ ├── CLAUDE.md # 前端子项目规范
│ └── src/
└── shared/
├── CLAUDE.md # 共享库规范
└── src/
8.2 不同子项目使用不同规范
这是 Monorepo 配置的核心价值——后端用 Python 规范,前端用 TypeScript 规范,共享库有自己的约束:
根目录 CLAUDE.md(通用规范):
# monorepo 通用规范
## 仓库结构
- `packages/backend/` — Python 后端服务
- `packages/frontend/` — React 前端应用
- `shared/` — 共享类型定义和工具函数
## 通用规则
- 所有子项目共用同一个 Git 仓库
- commit message 必须标明影响的子项目:`feat(backend): xxx`
- 跨子项目的变更需要在 commit message 中说明原因
- 不要修改根目录的 .github/ 和 docker-compose.yml
packages/backend/CLAUDE.md:
# Backend 规范
Python 3.12 + FastAPI。
## 命令
- 测试:`cd packages/backend && poetry run pytest`
- Lint:`cd packages/backend && poetry run ruff check .`
## 规范
- 异步优先,所有 I/O 操作用 async
- 类型注解强制
- 数据验证用 Pydantic v2
packages/frontend/CLAUDE.md:
# Frontend 规范
React 18 + TypeScript + Vite。
## 命令
- 开发:`cd packages/frontend && pnpm dev`
- 测试:`cd packages/frontend && pnpm test`
## 规范
- 函数组件 + hooks,不用 class
- 样式用 Tailwind,不写自定义 CSS
- 状态管理用 Zustand,不用 Redux
8.3 配置继承与覆盖
子目录的 CLAUDE.md 会和根目录的合并。如果子目录的规则和根目录冲突,子目录优先。
实际效果:当 Claude 在 packages/frontend/ 目录下工作时,它同时知道根目录的通用规则(commit 格式、不要碰 docker-compose.yml)和前端的专属规则(用 Tailwind、不用 Redux)。
9. 实战案例:Python + React Monorepo 完整配置
下面是一个真实场景:一个电商平台的 Monorepo,后端 Python + FastAPI,前端 React + TypeScript。我会给出完整的配置套件。
项目结构
ecommerce-platform/
├── CLAUDE.md # 根目录通用规范
├── CLAUDE.local.md # 个人配置(不提交)
├── .claude/
│ └── settings.json # 项目级权限和钩子
├── .gitignore
├── packages/
│ ├── api/ # Python 后端
│ │ ├── CLAUDE.md
│ │ ├── pyproject.toml
│ │ └── src/
│ ├── web/ # React 前端
│ │ ├── CLAUDE.md
│ │ ├── package.json
│ │ └── src/
│ └── shared/ # 共享类型
│ ├── CLAUDE.md
│ └── src/
└── docker-compose.yml
根目录 CLAUDE.md
# ecommerce-platform
电商平台 Monorepo。后端 Python/FastAPI,前端 React/TypeScript。
## 仓库结构
- `packages/api/` — 后端 API 服务(Python 3.12 + FastAPI)
- `packages/web/` — 前端 Web 应用(React 18 + TypeScript)
- `packages/shared/` — 共享类型定义(TypeScript)
- `docker-compose.yml` — 本地开发环境编排
## 通用规范
### Git
- 分支命名:`feat/<scope>/xxx`、`fix/<scope>/xxx`
- scope 必须是 api / web / shared / infra 之一
- commit 格式:`<type>(<scope>): <description>`
- 跨包变更必须在 commit body 中说明原因
- 不使用 git push --force
### 禁止事项
- 不要修改 docker-compose.yml(找运维)
- 不要修改 .github/workflows/ 下的文件
- 不要在任何代码中硬编码密钥或密码
- 不要删除 packages/ 下的任何 CLAUDE.md
### 跨包引用
- 前端引用后端的类型通过 shared 包中转
- 不要从 web 直接 import api 的代码,反之亦然
packages/api/CLAUDE.md
# API 服务
Python 3.12 + FastAPI + SQLAlchemy 2.0 + PostgreSQL。
## 技术栈
- 框架:FastAPI 0.110
- ORM:SQLAlchemy 2.0(async,使用 asyncpg)
- 验证:Pydantic v2
- 认证:JWT(PyJWT)
- 任务队列:Celery + Redis
- 包管理:Poetry
## 目录结构
- `src/api/routes/` — 路由定义,按业务域分文件
- `src/api/deps.py` — 依赖注入(数据库会话、当前用户等)
- `src/models/` — SQLAlchemy 模型
- `src/schemas/` — Pydantic 请求/响应模型
- `src/services/` — 业务逻辑层
- `src/repositories/` — 数据访问层
- `tests/` — 测试目录,结构镜像 src
## 架构规则
- 三层架构:Route → Service → Repository
- Route 层不写业务逻辑,只做参数验证和调用 Service
- Service 层不直接操作数据库,通过 Repository
- 所有数据库操作必须在事务中
## 命令
- 安装:`cd packages/api && poetry install`
- 测试:`cd packages/api && poetry run pytest -v`
- 单元测试:`cd packages/api && poetry run pytest tests/unit/ -v`
- 集成测试:`cd packages/api && poetry run pytest tests/integration/ -v`
- 格式化:`cd packages/api && poetry run black src/ tests/`
- Lint:`cd packages/api && poetry run ruff check src/`
- 类型检查:`cd packages/api && poetry run mypy src/`
- 迁移生成:`cd packages/api && poetry run alembic revision --autogenerate -m "描述"`
- 迁移执行:`cd packages/api && poetry run alembic upgrade head`
## 编码规范
- snake_case 变量/函数,PascalCase 类名
- 异步函数强制 async/await
- 强制类型注解,禁止 Any
- 异常处理:Service 层抛自定义异常,Route 层统一转换为 HTTP 响应
- 分页统一用 `PageParams` 和 `PageResult` 泛型
## 禁止
- 不要修改 alembic/env.py
- 不要删除 alembic/versions/ 下的迁移文件
- 不要在 Route 层直接写 SQL
- 不要用 `from sqlalchemy import *`
packages/web/CLAUDE.md
# Web 前端
React 18 + TypeScript 5.4 + Vite 5。
## 技术栈
- UI:Tailwind CSS + Radix UI + Lucide Icons
- 状态管理:Zustand(全局) + React Query(服务端状态)
- 路由:React Router v6
- 表单:React Hook Form + Zod 验证
- HTTP:Axios(封装在 src/api/client.ts)
- 包管理:pnpm
## 目录结构
- `src/pages/` — 页面组件,按路由组织
- `src/components/` — 可复用组件
- `src/components/ui/` — 基础 UI 组件(Button、Input 等)
- `src/components/layout/` — 布局组件
- `src/components/features/` — 业务功能组件
- `src/hooks/` — 自定义 hooks
- `src/stores/` — Zustand stores
- `src/api/` — API 调用封装
- `src/types/` — TypeScript 类型定义
- `src/lib/` — 工具函数
## 命令
- 开发:`cd packages/web && pnpm dev`
- 构建:`cd packages/web && pnpm build`
- 测试:`cd packages/web && pnpm test`
- Lint:`cd packages/web && pnpm lint`
- 类型检查:`cd packages/web && pnpm typecheck`
## 编码规范
- 组件文件名 PascalCase,hooks 文件名 camelCase
- 组件 props 必须用 interface 定义,文件名和组件名一致
- 禁止 any 类型,必要时用 unknown + 类型守卫
- 样式只用 Tailwind utility class,不写自定义 CSS 文件
- API 调用统一通过 src/api/ 封装,不在组件中直接用 axios
- 自定义 hook 必须以 use 开头
## 组件规范
- 优先函数组件 + hooks
- 组件拆分原则:超过 150 行就考虑拆分
- 公共组件必须有 JSDoc 注释
- 事件处理函数命名:handle + 事件名(handleClick, handleSubmit)
## 禁止
- 不用 class 组件
- 不用 Redux(用 Zustand)
- 不在组件中直接写 fetch/axios 调用
- 不用 inline style,用 Tailwind
- 不用 var,用 const / let
packages/shared/CLAUDE.md
# Shared 共享包
前后端共享的类型定义和工具函数。TypeScript 编写。
## 规则
- 这个包被 api 和 web 同时引用,修改要谨慎
- 只放纯类型定义和无副作用的工具函数
- 不要引入任何 React 或 FastAPI 的依赖
- 修改后同时检查 api 和 web 的类型是否通过
CLAUDE.local.md(个人配置,不提交)
# 个人配置
始终用中文回答问题。
## 本地环境
- PostgreSQL:localhost:5432, 用户 dev, 密码 dev123, 数据库 ecommerce_dev
- Redis:localhost:6379
- 前端开发服务器:http://localhost:5173
- 后端 API:http://localhost:8000
## 个人偏好
- 写新功能时先写测试再写实现(TDD)
- 代码注释用中文
- PR 描述用中文
- 遇到不确定的架构决策时先问我,不要自己决定
.claude/settings.json
{
"permissions": {
"allowedTools": [
"Read",
"Glob",
"Grep",
"Bash(cd packages/api && poetry run pytest*)",
"Bash(cd packages/web && pnpm test*)",
"Bash(cd packages/web && pnpm lint*)",
"Bash(cd packages/api && poetry run ruff*)",
"Bash(cd packages/api && poetry run black*)",
"Bash(git status)",
"Bash(git diff*)",
"Bash(git log*)",
"Bash(git branch*)"
],
"deniedTools": [
"Bash(rm -rf*)",
"Bash(git push --force*)",
"Bash(docker-compose down*)",
"Bash(alembic downgrade*)"
]
}
}
这套配置的效果:
-
Claude 知道整个项目的结构和各子项目的技术栈
-
在后端目录工作时遵循 Python 规范,在前端目录工作时遵循 TypeScript 规范
-
跨包引用有明确的约束(通过 shared 中转)
-
危险操作被权限规则阻止
-
常用的测试和 lint 命令不需要每次确认权限
这些配置文件写一次,之后每次新会话都自动生效。Claude 会像一个熟悉你项目的同事一样工作,而不是每次都要从头介绍。
总结
配置 Claude Code 的记忆系统,核心就三件事:
-
写好 CLAUDE.md:把项目规范、技术栈、命令、禁止事项写清楚。这是投入产出比最高的事情。
-
用好层级体系:团队共享的放 CLAUDE.md(提交 Git),个人偏好放 CLAUDE.local.md(不提交),跨项目通用的放全局 CLAUDE.md。
-
让自动记忆帮你:对话中遇到重要信息,告诉 Claude “记住这个”,它会自动持久化到下次会话。
一份好的配置不需要多长——关键是精准。与其写 200 行面面俱到的规范,不如写 50 行真正影响日常协作的规则。Claude 不是新来的实习生,大部分编程常识它都知道。你需要告诉它的,是你项目中那些"只有老员工才知道"的东西。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 41
41 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)