JavaEE初阶
JavaEE初阶=>为搭建网站,进行技术铺垫
JavaEE进阶=>搭建网站
初阶重点学习内容:多线程,网络原理
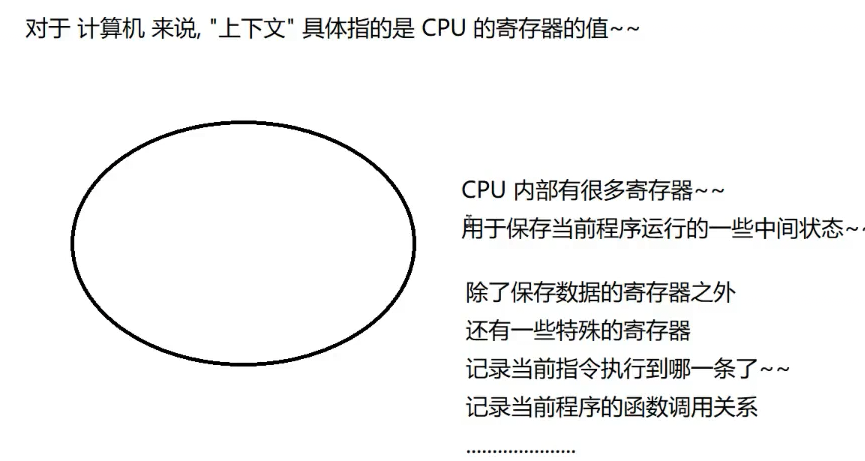
一.计算机是如何工作的


冯诺依曼体系结构 =>是一台计算机的最基本规则
1.CPU(中央处理器)
人类科技巅峰之作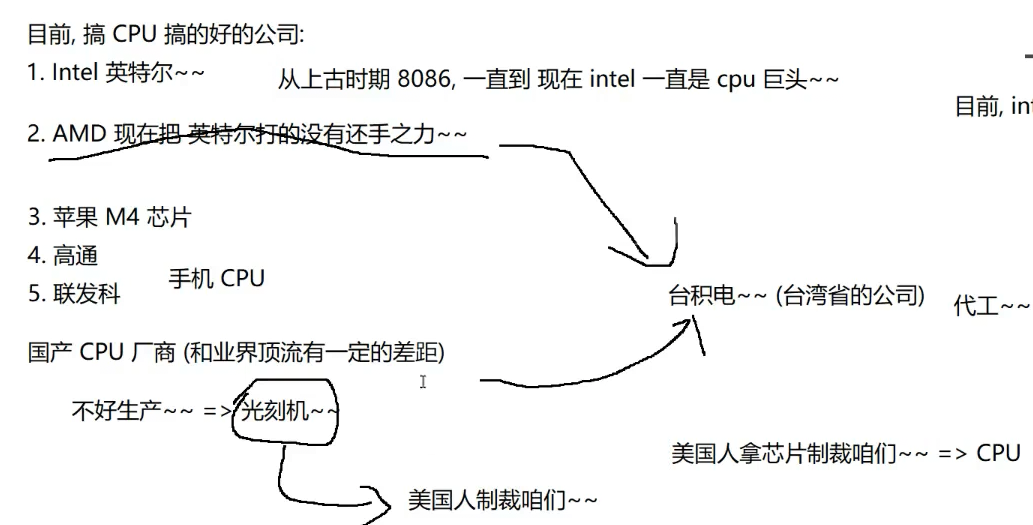
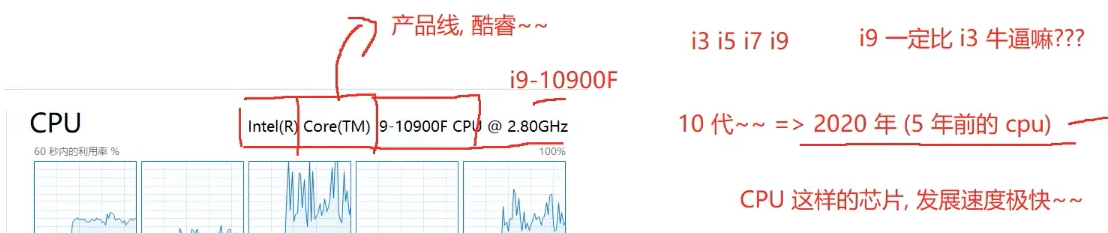
2.80GHz 主频(基频)
(速度:4.59GHz)睿频
CPU工作的快慢/运算速度的快慢,CPU工作频率也会变化
CPU的频率越高和核心数越多,就越好
1.1缓存cache,在CPU上开辟的存储数据的设备


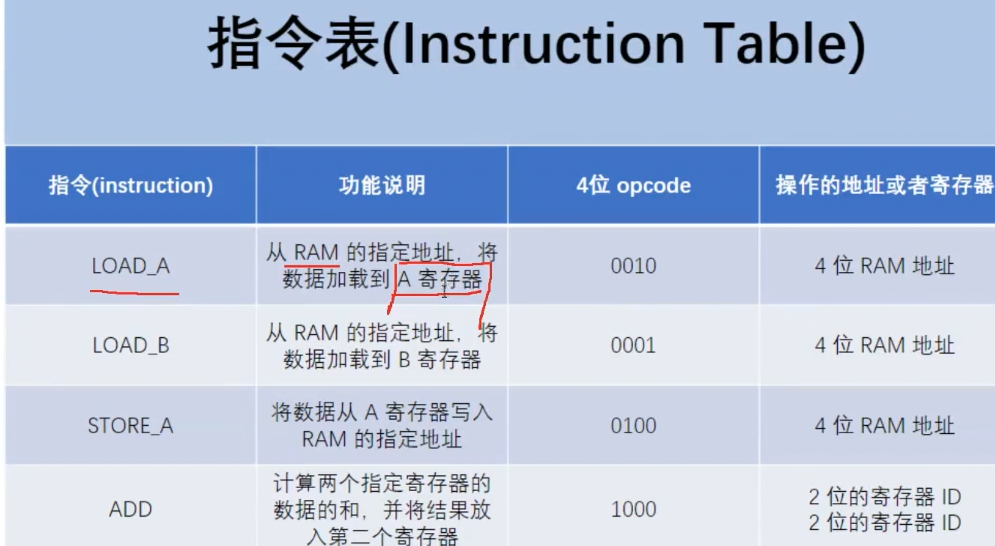
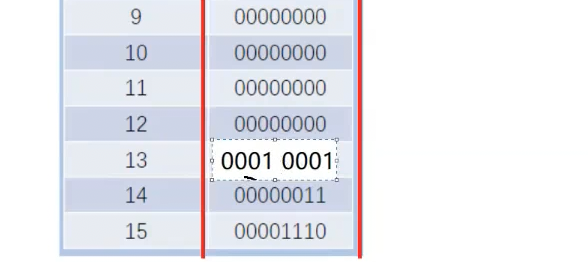
1.2指令:
CPU上执行任务的基本单位,是0101构成的二进制机器语言.

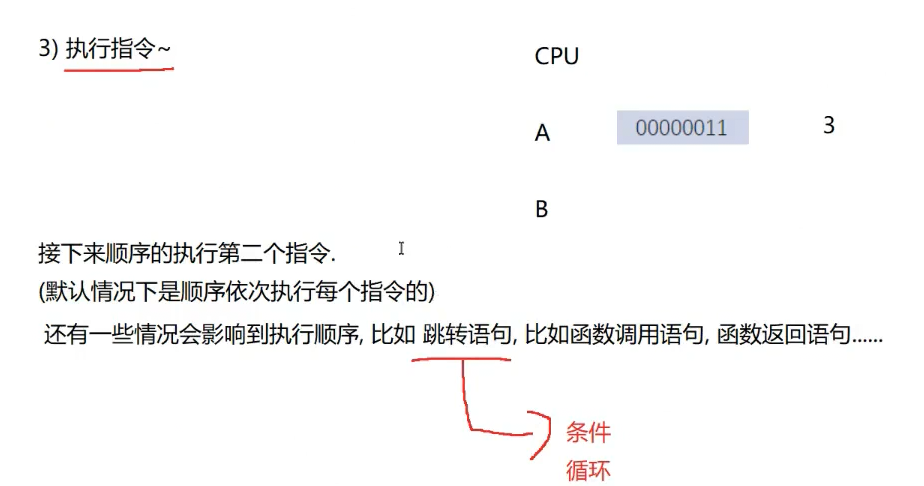
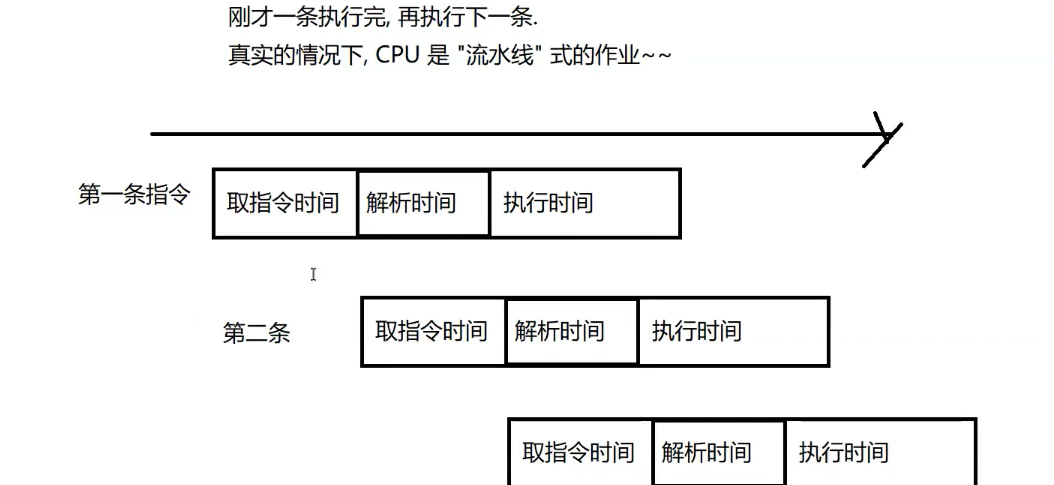
CPU工作流程
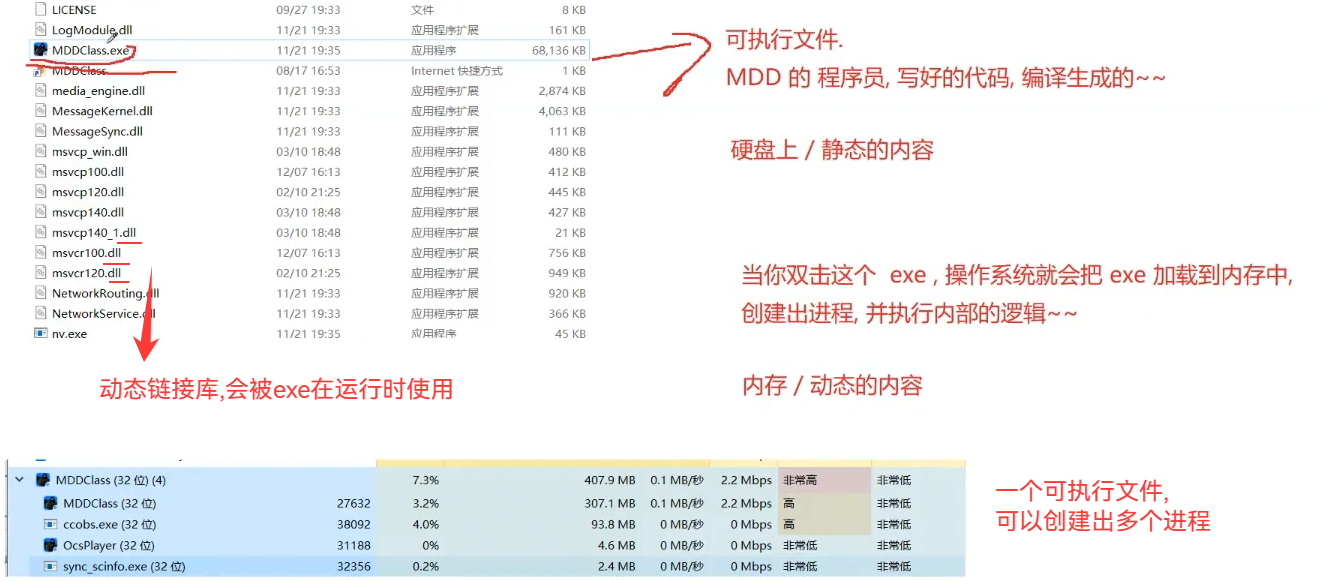
C=>exe(硬盘,文件)=>双击exe(操作系统会把exe加载到内存中)
指令存储在内存中





![]()
2.存储器
内存 读写速度快,存储空间小,成本高,断电后数据丢失
硬盘 读写速度慢,存储空间大,成本低,断电后数据存在
u盘(U盘内部构造和固态硬盘类似,读写速度比固态硬盘慢一些)
光盘(光碟)
3.输入设备(键盘,鼠标...)
(触摸屏和网卡,既可以是输入也可以是输出)
4.输出设备(显示器,投影仪...)
指令通过二进制存储
指令和数据在同样的存储器上存储
2.操作系统
Windows 操作系统
Linux 程序员专属 在服务器,嵌入式设备上用
Mac OS/IOS 苹果公司系统
Android 本质上是Linux ,在Linux基础上做了很多改进,更适合手机端
嵌入式设备 :比如冰箱,空调,路由器...(搭载的计算机功能不多,性能不强)可以通过联网手机调用

操作系统功能:1.管理各种硬件设备2.为软件提供稳定的运行环境
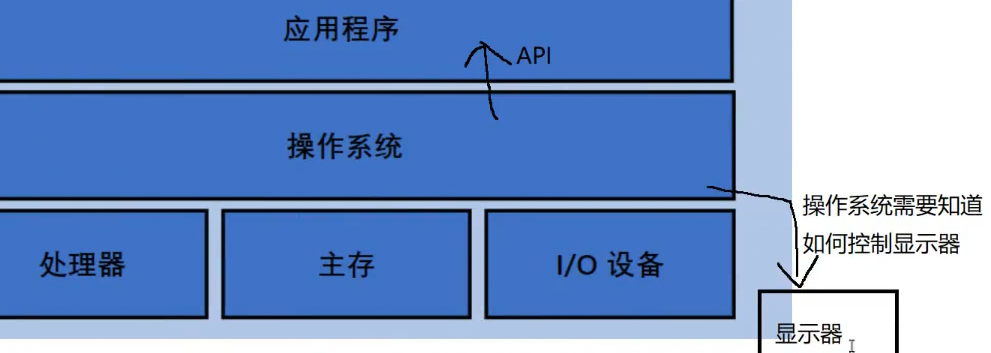
System.out.println("hello world"); 屏幕 =>硬件
在JVM调用C++版本的函数=>操作系统的API=>操作系统把字符串交给驱动程序=>驱动程序控制硬件完成显示工作
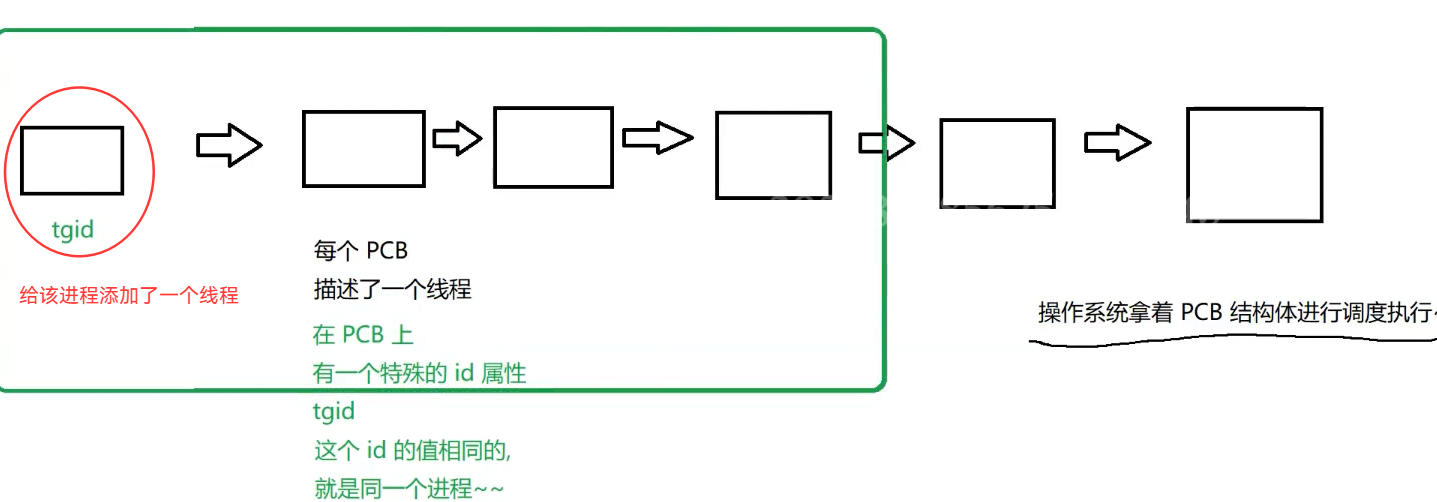
2.1进程
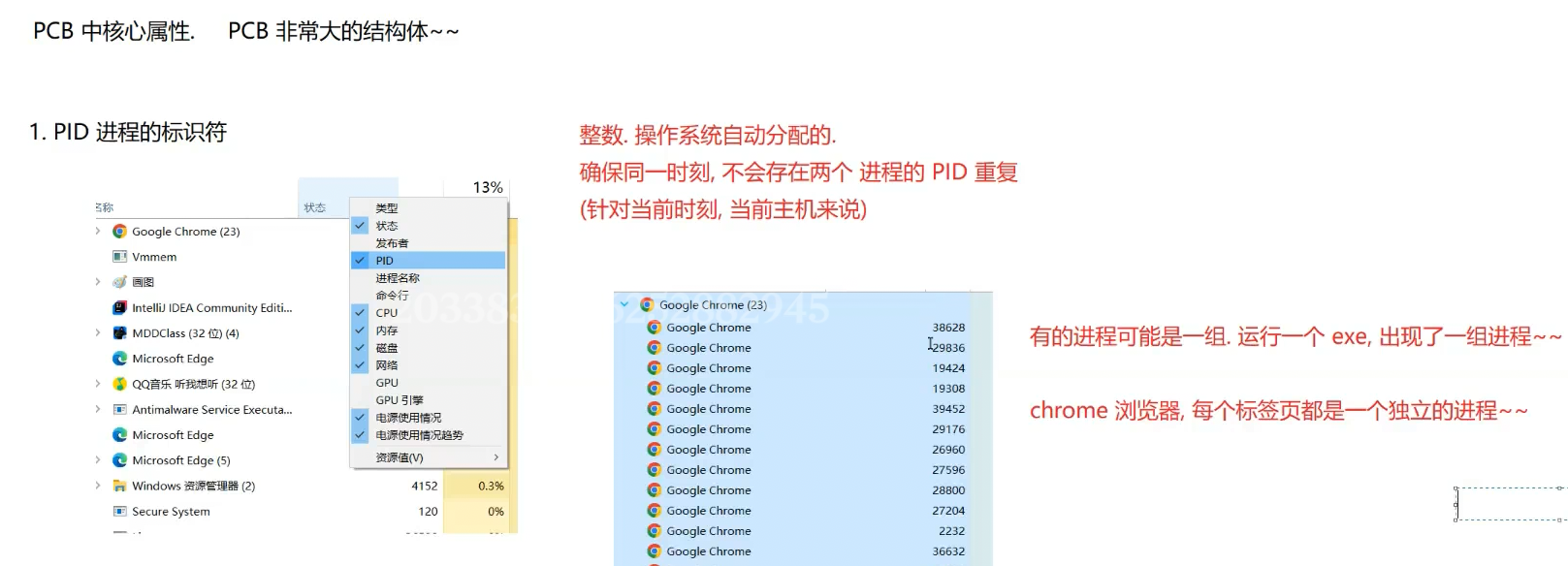
进程:(操作系统中非常重要的概念):计算机上运行起来的程序就叫进程"process" /任务"task";
操作系统中,进程是资源分配的基本单位
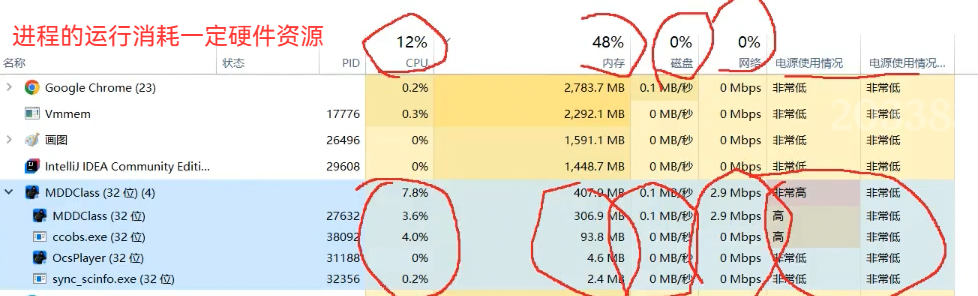

2.组织:使用一定的数据结构,把N个PCB串起来,一般用链表这样的方式组织

进程依赖的内存资源


进程依赖的硬盘资源(还涉及到其他外设.....)
![]()
2.2进程的调度
20个核心如何是上百个进程"同时"执行?
并行和并发统称为并发


2.3进程的状态
进程有多种状态,这里简单分为两种,就绪和阻塞

2.4进程的优先级
它决定了哪些进程优先安排CPU资源




每个进程都有自己独立的内存空间(进程的隔离性)

![]()
二.多线程初阶
线程概念
1.线程为了实现并发编程效果,解决多进程模型涉及的问题,
2.线程也叫轻量级进程,创建和销毁的开销比进程低很多
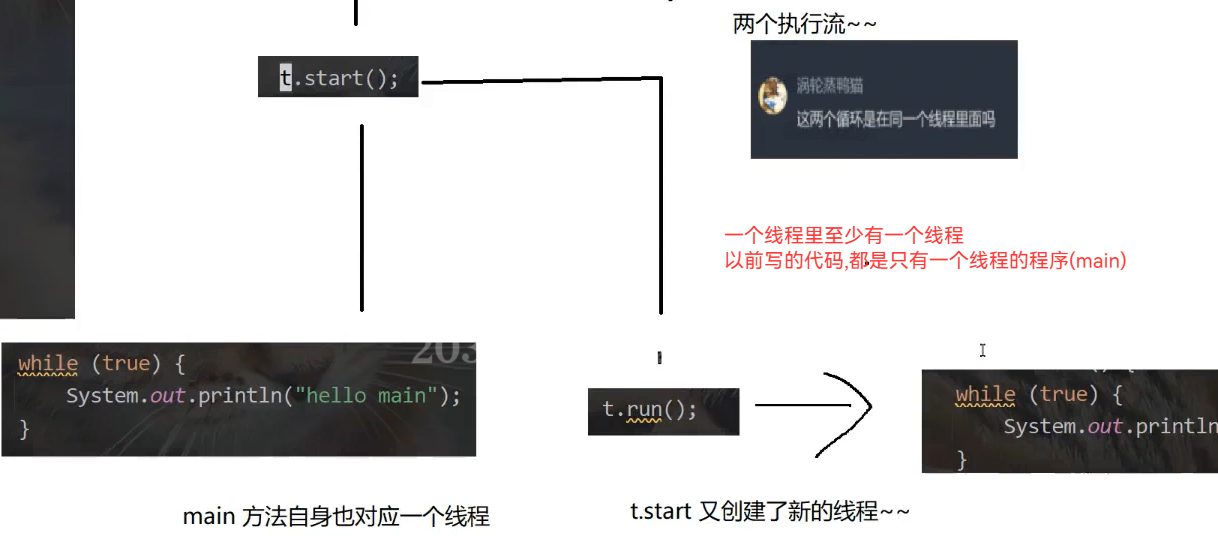
进程包含线程,进程是操作系统资源分配的基本单位,线程是操作系统调度执行的基本单位
一个进程中的若干线程共享操作系统的资源(内存 文件...)
每个线程都是一个"执行流"都可以放到CPU上调度执行,线程是操作系统调度执行的基本单位
"进程调度"过程,更准确说是"线程调度",一个进程可能包含一个线程,也可能包含N个线程(不能是0个),前面的"进程调度"可以想象成只有一个线程的进程,进行的调度
同一个进程的多个线程间,共用PCB的内存指针和文件描述符表,但有各自的状态,上下文,优先级和记账信息
线程比进程更轻量体现在,创建线程申请的资源少,
不过进程的第一个线程创建时,上述的资源申请都需要
当线程数目特多时,调度开销也会影响执行效率(因为cpu的核心数有上限)
多线程编程可能产生的问题


总结:(经典面试题:进程和线程间的关系)
多线程编程
开闭原则:对扩展开放,对修改关闭(修改可能会影响原有功能)

Java中向上转型的比较常见

写了由别人给自己调用的方法,称为"回调函数"(callback)


main线程是主线程
多线程编程中没有父线程/子线程之类的说法,多进程编程中有父进程/子进程的概念
while(true){}一直运行可能会将cpu吃满,会使CPU达到一个较高的温度,散热器风扇会加速运转
sleep可以控制时间让cpu休息一下,让当前线程进入阻塞状态
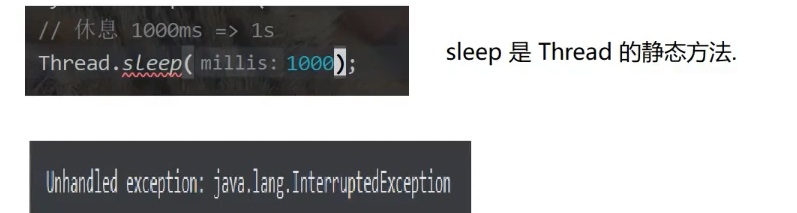
实际工作中,慎用sleep


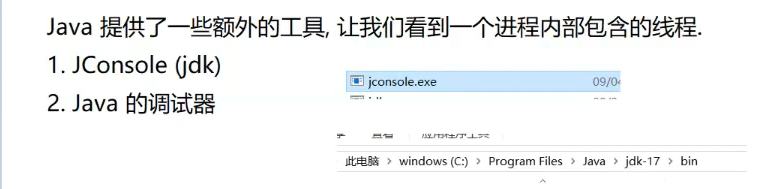
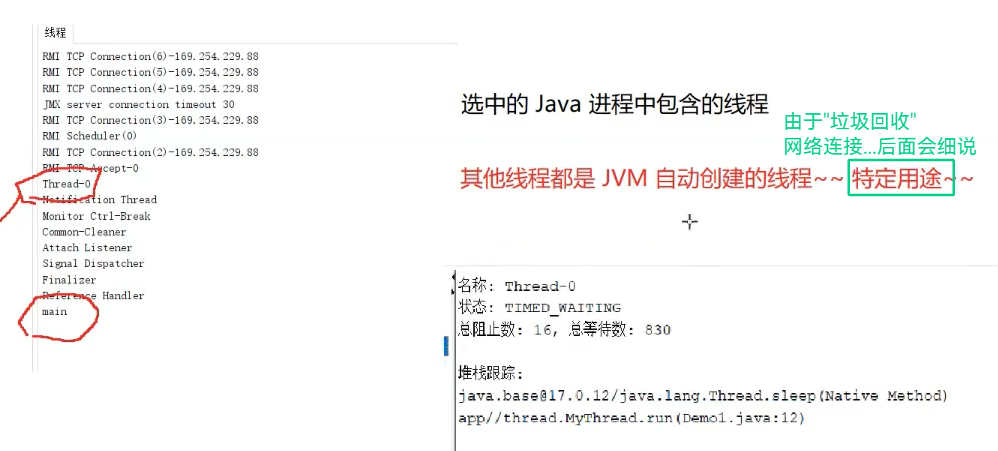

第一种写法:
package thread;
//创建一个类继承自标准库的Thread类
class MyThread extends Thread{
@Override
public void run() {
while(true){
System.out.println("hello Thread");
try {
//换算成秒是1秒
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
public class Demo1 {
public static void main(String[] args) throws InterruptedException {
//创建Thread的实例
Thread t = new MyThread();
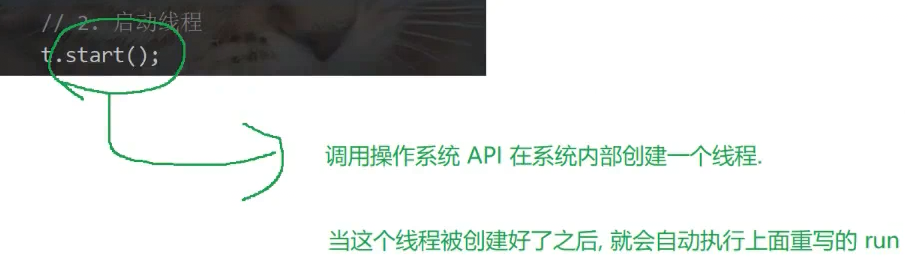
//启动线程
t.start();
while(true){
System.out.println("hello main");
Thread.sleep(1000);
}
}
}
针对main方法循环中的sleep和run()方法循环中的sleep抛出异常的选项问题的解释
所以run()方法中只能使用try catch进行捕获异常

线程创建的几种写法:
1.创建子类,继承Thread,重写run
2.实现Runnable接口


使用继承Thread的写法,"任务"和"线程"是绑定的,如果改成其他形式,需要大量修改代码
使用Runnable这样的写法并未和线程概念绑定,这样的任务可非常方便的迁移到其他载体上(更加低耦合)
第二种写法:
package thread;
//第二种实现多线程的写法
//runnable可搭载别的载体
class MyRunnable implements Runnable{
@Override
public void run() {
while(true){
System.out.println("hello Runnable");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
public class Demo2 {
public static void main(String[] args) throws InterruptedException {
Runnable r = new MyRunnable();
Thread t = new Thread(r);
t.start();
while(true){
System.out.println("hello main");
Thread.sleep(1000);
}
}
}3.继承Thread,使用匿名内部类
步骤:1.创建Thread的子类,该子类没有名字(匿名)方便,一次性
2.重写run 3.创建Thread子类的实例,并且使用t引用指向
第三种写法:
package thread;
//创建Thread匿名内部类
public class Demo3 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(){
@Override
public void run() {
while(true){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
};
//调用start()才是真正创建线程
t.start();
while(true){
System.out.println("hello main");
Thread.sleep(1000);
}
}
}4.实现Runnable,使用匿名内部类
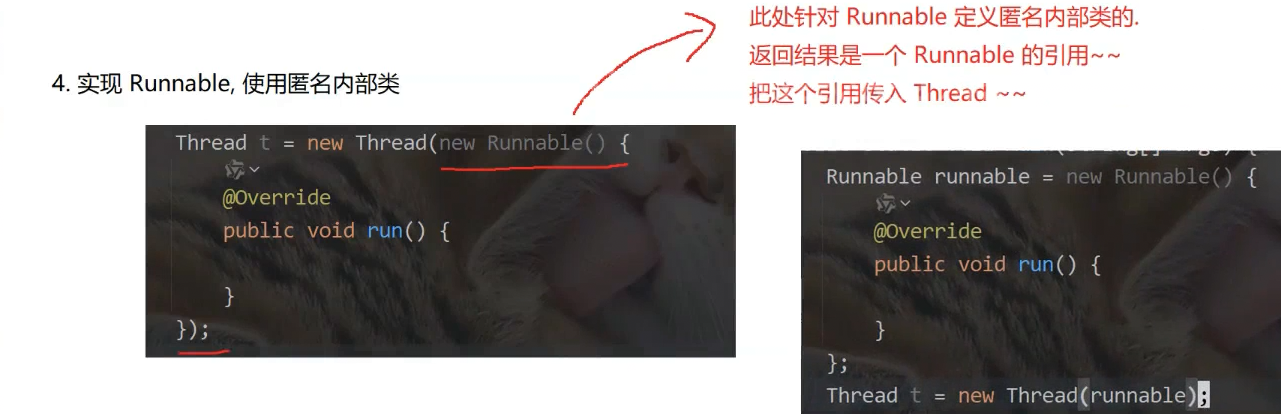
第四种写法:
package thread;
public class Demo4 {
public static void main(String[] args) throws InterruptedException {
/* 第一种写法
Runnable r = new Runnable(){
@Override
public void run() {
}
};
Thread t = new Thread(r);*/
//第二种写法
Thread t = new Thread(new Runnable() {
@Override
public void run() {
while(true){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
});
t.start();
while(true){
System.out.println("hello main");
Thread.sleep(1000);
}
}
}第五种写法:Lambda表达式(推荐)
lambda本质上是一个匿名函数
package thread;
public class Demo5 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while (true){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t.start();
while(true){
System.out.println("hello thread");
Thread.sleep(1000);
}
}
}
为什么使用Thread,Runnable方法不需要导包?
它们都属于Java.lang包底下的,最基础最常用的
包将一组有关系的类放在一起,默认情况下不会引入到代码中,使当前代码的类比较少,不容易乱
Java约定,一个Thread对象和一个操作系统中的线程是"一 一对应"的关系,所以一个Thread对象,只能start一次.(创建多个Thread对象可以start多次,同样遵守上述原则)
后续学习Thread的其他方法/属性也是一 一 对应,确保Thread对象的各种方法属性,是在控制对应系统中的线程
显卡:
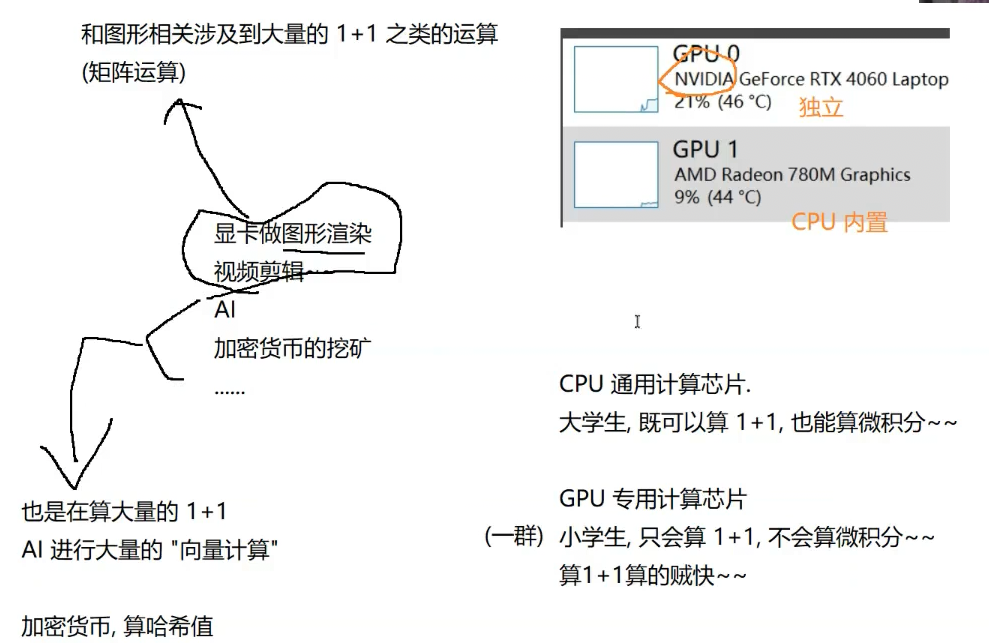
针对显卡(GPU)编程,由于硬件架构不同,它与cpu编程差距很大,为方便程序员对显卡编程,英伟达公司推出了一套框架Cuda,可以更方便的使用GPU进行编程,业界大佬对Cuda进一步封装,引入各种功能,尤其针对AI领域,进一步制作更高层次的框架,TensorFlow
Thread常见构造方法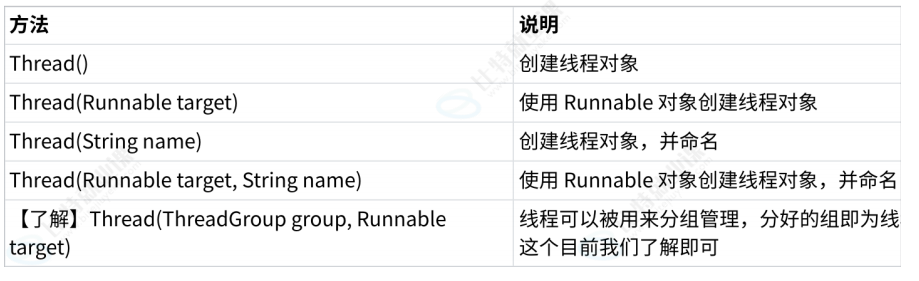
线程组现在很少涉及,后续介绍"线程池"生态位上替代线程组
Thread几个常见属性


main线程包括代码手动创建的线程,默认都是前台线程

后台线程的设置:
package thread;
public class Demo7 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
for (int i = 0; i < 5; i++) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
System.out.println("t线程结束");
});
//在start之前设置后台线程
t.setDaemon(true);
t.start();
//主线程调用start后,没什么需要执行的,接着主线程就结束了
Thread.sleep(1000);
System.out.println("主线程结束");
//退出程序,指定退出码
System.exit(1);
}
}1.启动一个线程:-start();
start方法本身,执行速度非常快

操作系统内部通过PCB来描述,通过链表组织,对Linux来说(Linux开源,Windows闭源)
![]()
Java代码=>.class文件,再通过JVM(C++写的)解释执行
带有native字样的方法,是在JVM上通过C++代码实现的,
通过调用操作系统的原生API,创建线程,根据当前操作系统进行区分

2.中断一个线程
对于Java来说,一个线程终止,就是这个线程的入口方法执行完毕,Java并不提供"强制终止"(所有让线程终止的方法,都围绕"入口方法结束")
代码实例:
package thread;
import java.util.Scanner;
public class Demo8 {
private static boolean running = true;
public static void main(String[] args) {
Thread t = new Thread(()->{
while(running){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
System.out.println("t线程退出");
});
t.start();
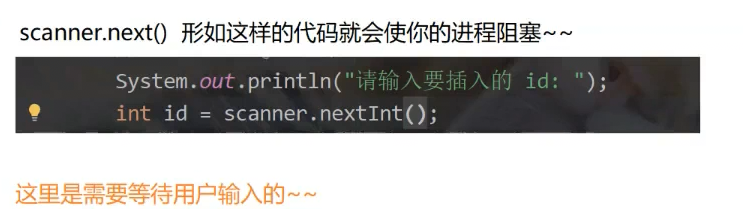
//主线程中让用户进行输入
Scanner sc = new Scanner(System.in);
System.out.println("请输入整数0,表示t线程终止:");
int n = sc.nextInt();
if(n == 0){
running = false;
}
}
}为什么running不能写作局部变量的解释
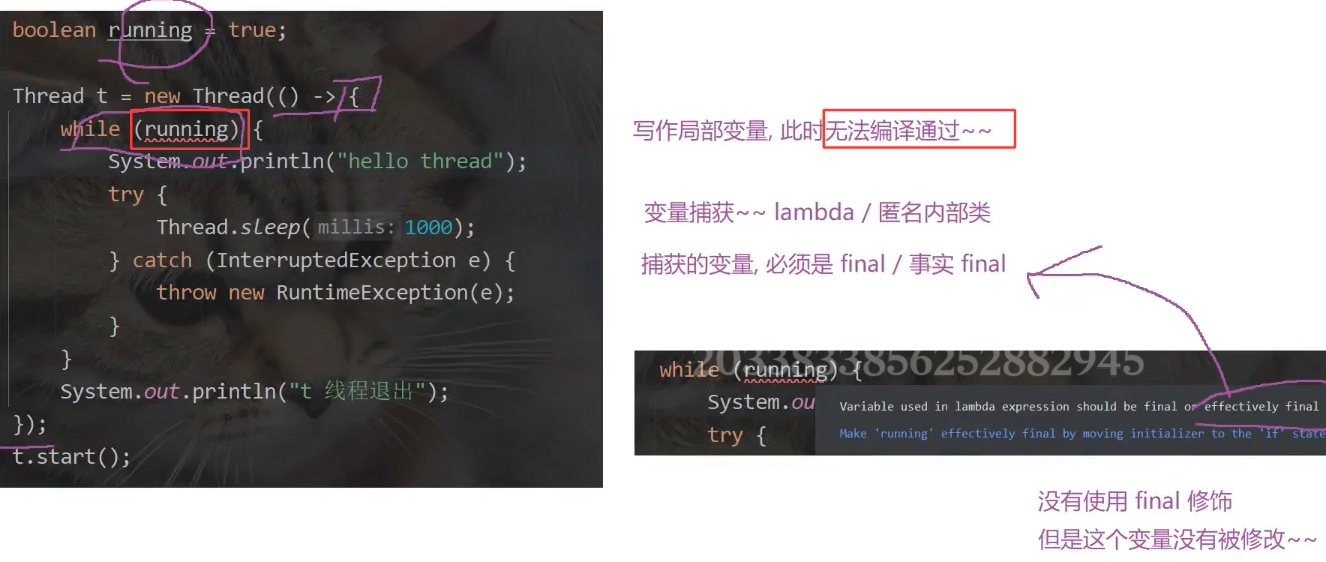
![]()
匿名内部类中

Java设定lambda表达式中捕获的变量必须是final/事实final的原因

第二种终止写法: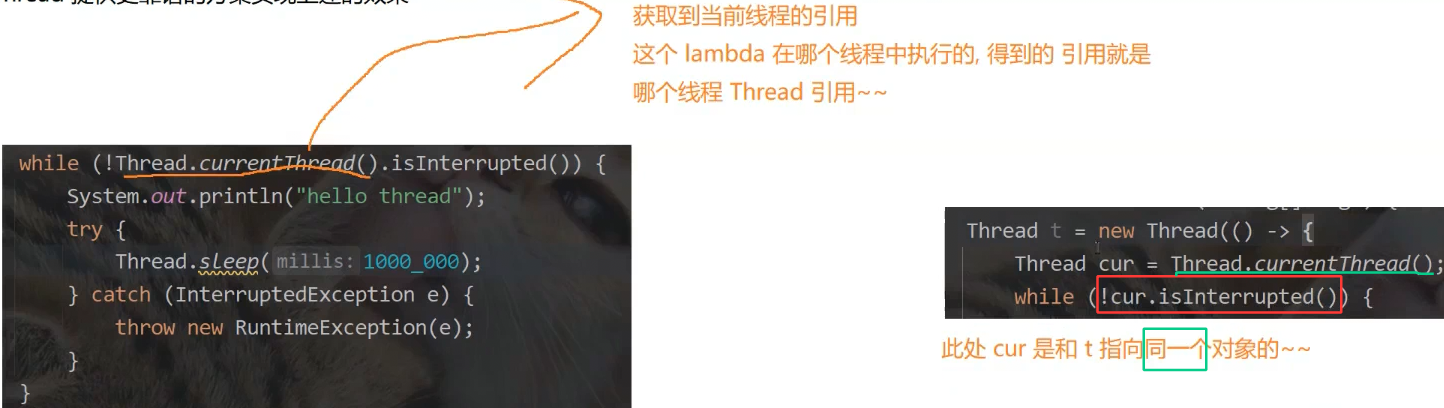
为什么不能使用t.isInterrupted的原因




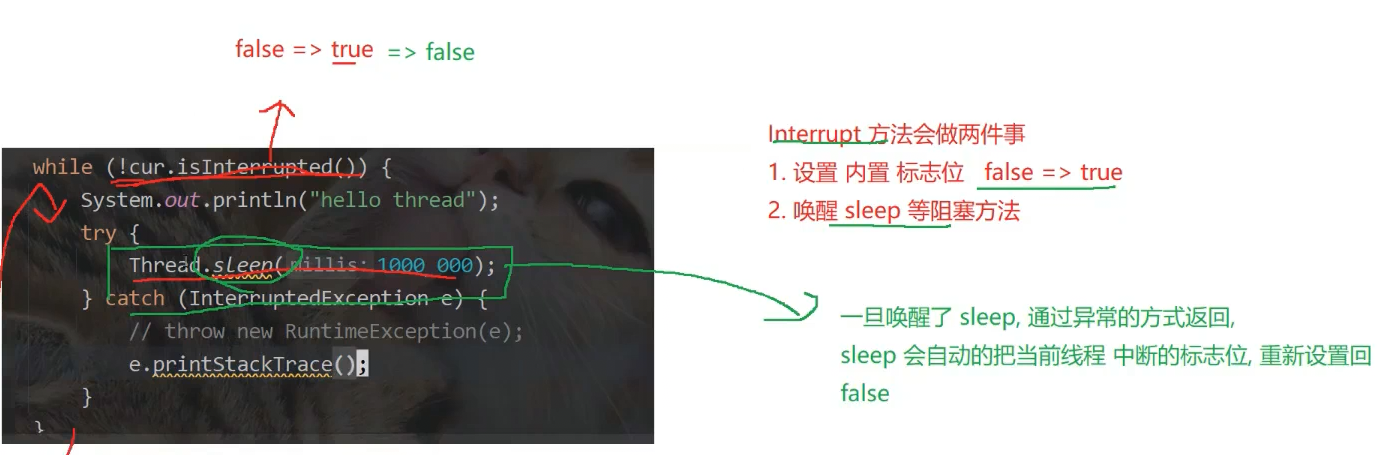
当前设定下,可以针对Interrupt给出几种策略: 1.立即退出 2.稍等一下退出 3.不退出(忽略), main想终止t但决定权在t的逻辑中
3.线程等待:
线程之间是随机执行的,为了让它结束具有确定性,通过干预两个线程的结束顺序, 让后台线程 等待先结束的线程执行完 Thread =>join
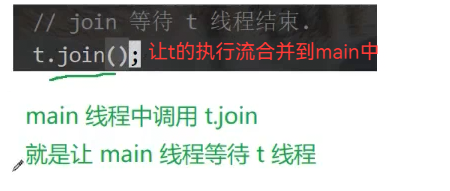
t.join (join的阻塞等待时间是不确定的,取决于t何时退出)
任何两个线程都可以进行等待,t也可以等待main


代码演示:
package thread;
public class Demo10 {
private static long result = 0;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
for (int i = 0; i < 1000; i++) {
result +=i;
}
System.out.println("t线程执行完毕");
});
t.start();
//给t线程留有一定的执行时间,join等待t线程结束
t.join();
System.out.println(result);
}
}4.获取当前线程的引用
currentThread(在哪个线程中执行,就获取哪个线程的引用) Thread 名字 = Thread.currentThread;
5.休眠当前线程
sleep 阻塞,让线程不参与cpu调度
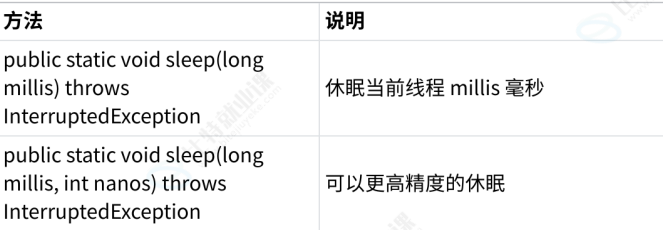

线程主动放弃cpu,在资源比较紧张的场景下会涉及到,可以降低CPU的使用率
6.线程的六种状态

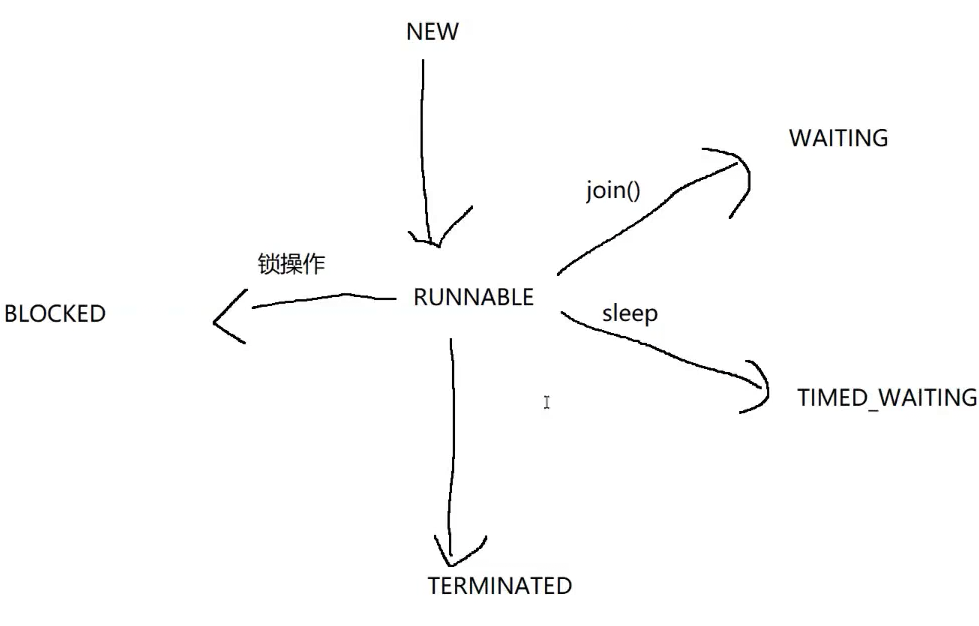

线程安全问题(重点)



count++,这个代码对应三个指令1) load 把内存中的数据加载到寄存器中 ; 2)add把寄存器中的数据+1; 3)save 把寄存器中的数据写回内存
调度顺序是随机的 可能会出现t1先load后,t2已经执行多次的情况,导致自增后的结果为1的情况,使最后的count值出现小于5W的情况
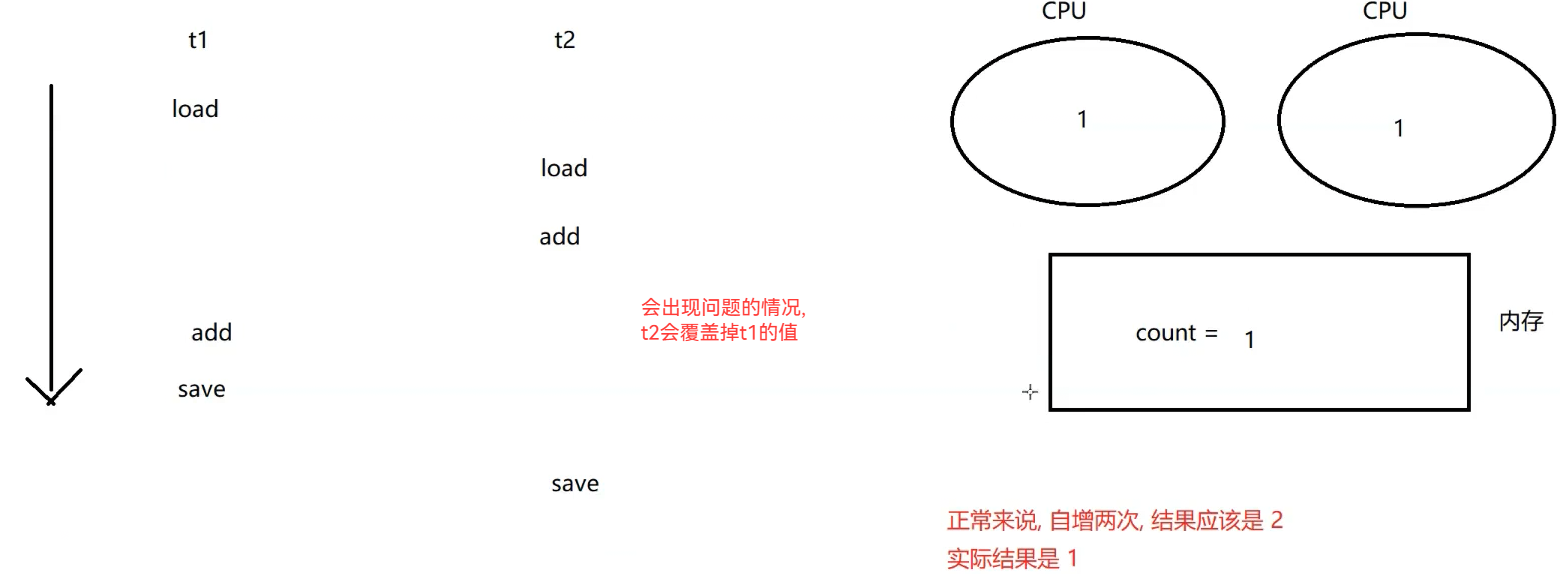
线程安全问题和随机调度直接相关


String 属于不可变对象, 1)如何实现?没有提供public 的set系列方法和final无关(final是为了禁止扩展(继承)) 2)String这么设计的原因:1.字符串常量池 2.计算hash 3.线程安全
枚举(enum)的概念和String不一样,枚举天然就是常量

erlang没有变量,没有if(使用模式匹配机制代替条件语句),没有循环(使用递归机制代替循环), 是函数式编程语言,以函数为主
rabbitmq消息队列,基于erlang实现
Go(2009)再被设计时,充分考虑多核心并发编程,内置协程,比线程更高效,通过channel机制,更方便的进行多个协程之间的协调
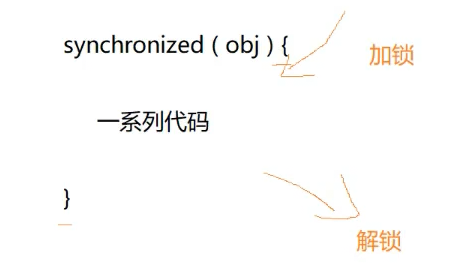
锁的实现:核心原则:"互斥" "独占",关键步骤 加锁 解锁 锁机制本质是操作系统提供的功能

锁的关键字synchronized
别的语言中,加锁解锁是两个不同的方法:lock() 中间有一系列代码 unclock();

执行 load ,add ,save三个指令的过程中,该线程随时可以被从CPU上调度走, 如果其他线程也尝试进行加锁操作,就会产生阻塞,从而避免上述的三个指令过程中"被插队"
Java提供的锁=>操作系统的锁=>CPU对锁的支持(CPU执行的指令中包含了类似lock这样的指令)
锁内部的代码逻辑少,"锁的粒度小"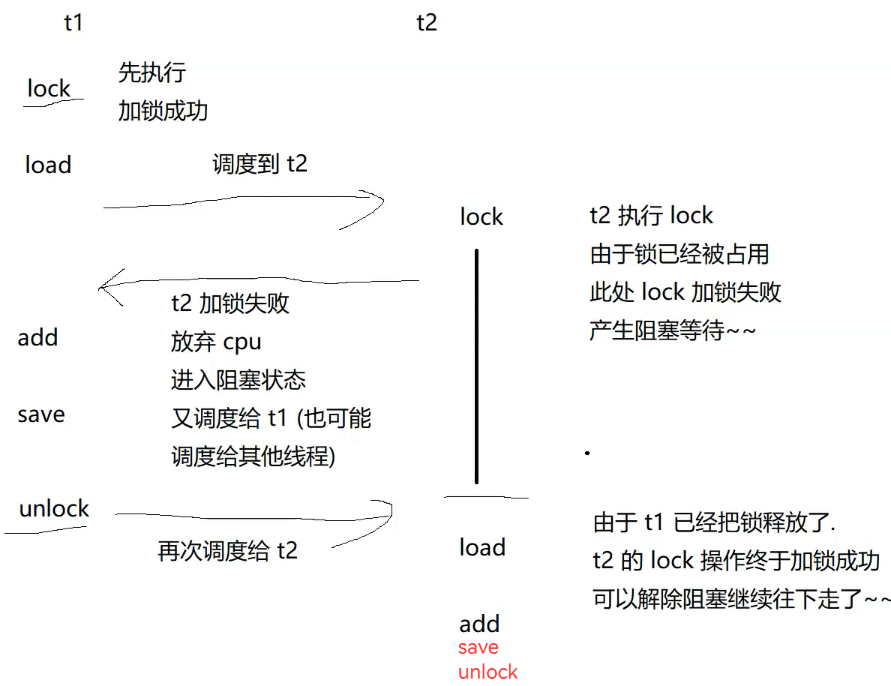
操作系统中还有一种机制,叫"临界区",某个线程进入临界区,会暂时关闭操作系统的调度器(这个线程会一口气在CPU上持续执行)直到出临界区,才恢复调度器(操作系统底层机制,java不提供)
 代码演示:
代码演示:
package thread;
//线程安全问题演示与解决
public class Demo14 {
private static long count = 0;
private static Object locker = new Object();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(()->{
for(int i = 0;i< 50000;i++){
//锁机制,()中的对象要是同一个对象才能产生锁竞争
synchronized(locker){
count++;
}
}
});
Thread t2 = new Thread(()->{
for(int i = 0;i< 50000;i++){
synchronized(locker){
count++;
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count);
}
}锁内部的代码逻辑多(不是代码行数),"锁的粒度大"
synchronized 通过{}控制加锁解锁,为了防止代码中忘记写解锁/写了代码未执行到 从而产生非常严重的问题


synchronized的其他写法
synchronized 可以修饰一个实例方法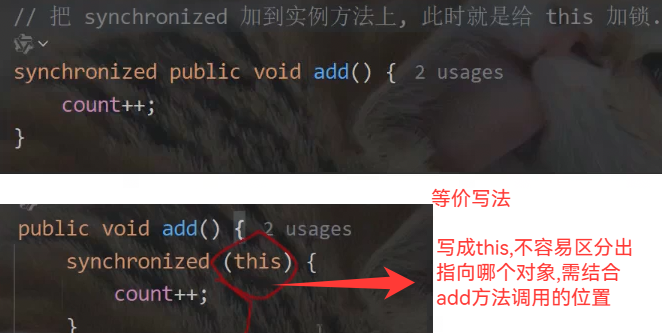
synchronized 可以修饰一个静态方法(针对类对象加锁)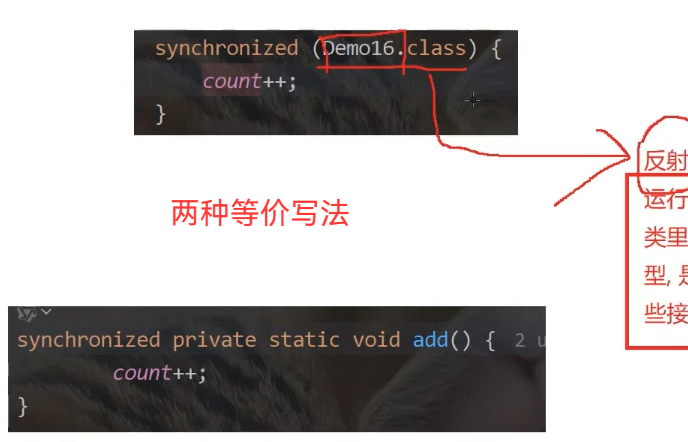
Demo16.class 反射:运行时获取到一个对象/类 内部结构,类里面有哪些属性,方法,名字,类型,public/private....,继承自哪个类,实现哪些接口....---->.java =>.class(二进制字节码文件)=>被JVM加载到内存中,会构造出一个特殊的对象,类对象.每个类都会在内存中有唯一 一个类对象(反射就是JVM提供了一组API可以从对象中获取到信息/进行一些操作)
标准库中的集合类,已学过的大部分都是线程不安全的(ArrayList,LinkedList,HashMap,Queue)不能多线程对这样的集合类对象进行修改 Vector,Hashtable 是线程安全的,核心方法都加了synchronized,会即将淘汰,因为无脑加锁
加锁的代价,使程序效率更低=>产生竞争=>产生阻塞,即使没有产生阻塞,加锁本身也可能调用到操作系统内核的逻辑,(确实存在线程安全的问题,再去加,不存在就不该加)

![]()


要知道 可重入锁的效果,记录持有锁的线程,哪里真正解锁
死锁
多线程编程中使用锁的非常经典的问题
1.一个线程一把锁,连续加锁多次(可重入锁直接解决)
2.两个线程两把锁(解释:循环依赖,A依赖B,B依赖A)
3.n个线程,m把锁(典型:哲学家就餐问题,当每个哲学家都拿起左手筷子,桌上就没有筷子了,就会陷入阻塞态,解锁不了)
由于多线程的"随机调度",实际执行顺序存在多种情况,有些情况没问题,有些有bug,写代码要确保所有情况都没问题
如何避免死锁:
死锁的四个必要条件(打破任意一个就可解除死锁)(背)
1.锁是互斥的(基本特点) 未来会接触到其他锁,有时互斥,有时不是...
2.锁不可抢占 A线程获取locker,此时B线程也想获取locker 把A的locker抢来了,B持有locker,A线程阻塞了(嵌入式开发,对实时要求高的操作系统上,任务优先级有明确要求,会出现这种特殊情况)
以上两点synchronized都改不了,是构成它的必要特性
3.请求和保持 (和代码结构有关) A线程获取到locker1 的情况下,保持locker1 的状态(不释放),尝试获取locker2
4.循环等待/环路等待 (代码结构有关) eg:车钥匙锁家里,家钥匙锁车里![]()
如何避免死锁:

volatile关键字
解决内存可见性引起的线程安全问题
内存可见性问题由编译器优化导致的,编译器优化:
javac =>.java =>.class
JVM 执行.class


此处编译器发现1.flag每次读到的都是相同的值 1s足以让这个循环上万次 2.编译器也并未发现哪里修改 虽然我们在另一个线程有修改,但编译器无法分析出另一个线程的执行时机, 此处编译器就做了大胆判定:把load操作优化掉,后续循环只从寄存器/缓存中取flag值, 此时如果在t2线程中修改flag,t1也就无法感知了(t1没在内存读,而从寄存器/缓存)
使用volatile关键字修饰某个变量 ,此时编译器就知道该变量"易变",后续针对这个变量的读写操作就不会设计优化了

主内存(main memory):平时说的内存 工作内存(work memory):寄存器+缓存 (学习细节因为面试)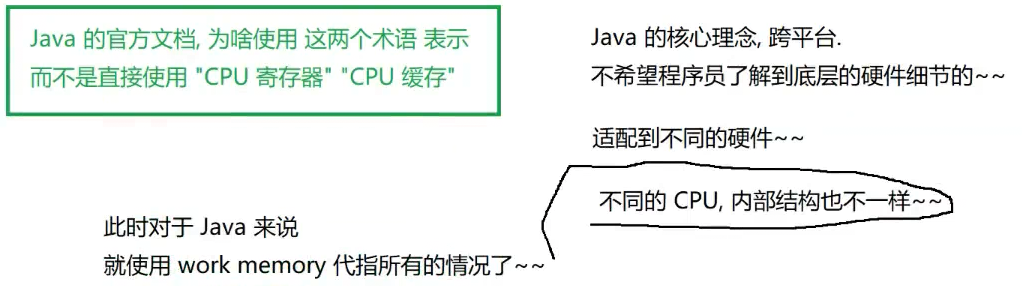

wait¬ify
由于多线程调度的随机性,join只能影响线程结束的顺序,所以引入了wait¬ify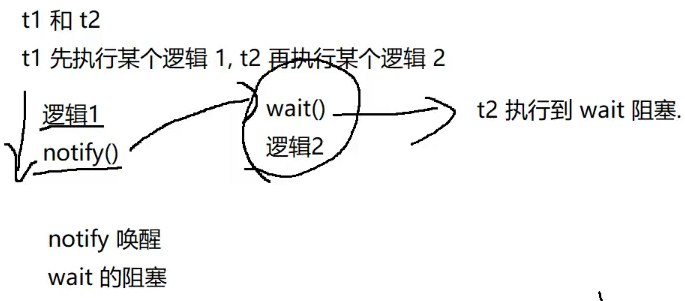
这个机制也可以应对线程"饿死"问题 wait¬ify是Object类的方法,可以被任意对象调用

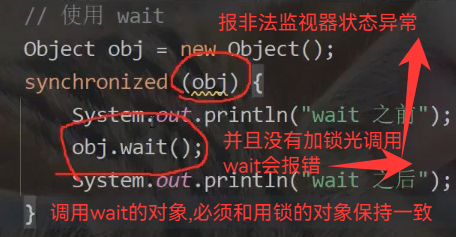
 wait的释放锁和等待其他线程的通知(进入阻塞状态)必须是原子(一起执行)的
wait的释放锁和等待其他线程的通知(进入阻塞状态)必须是原子(一起执行)的
java要求notify 也得在synchronized中,操作系统原生api则没这个要求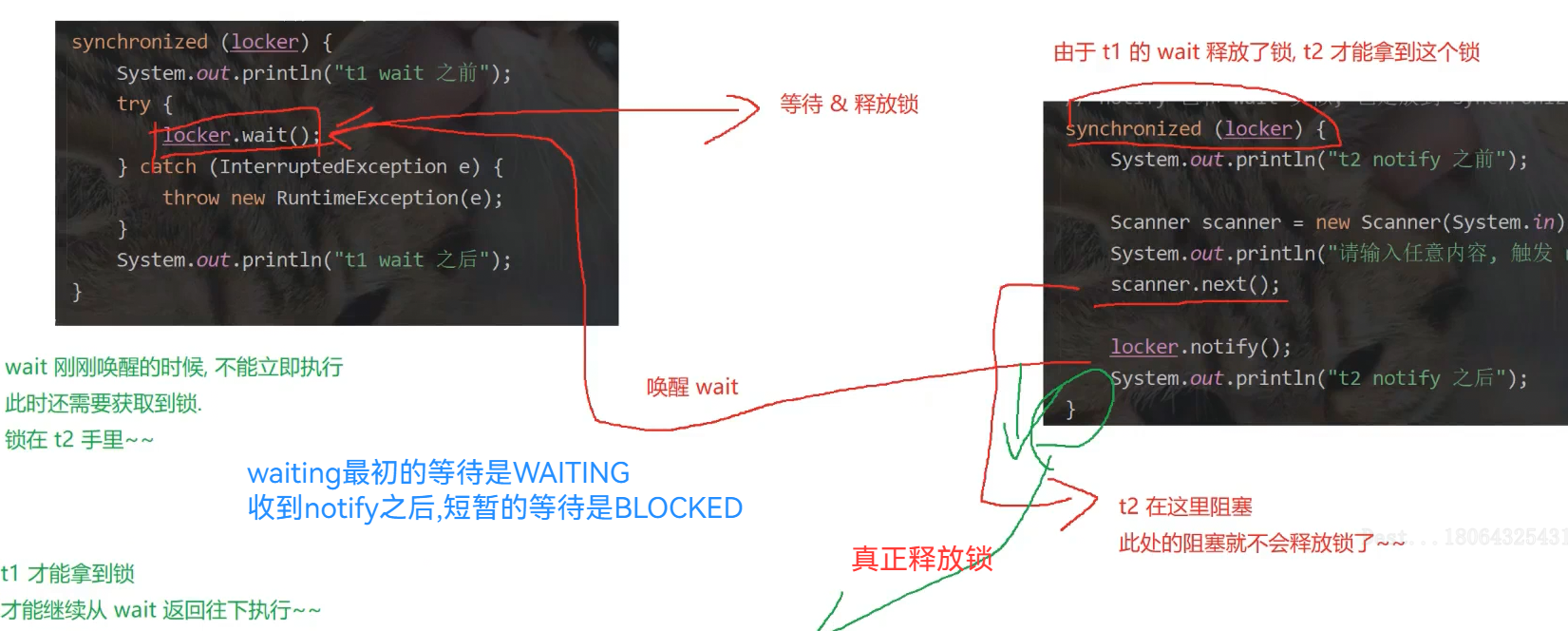
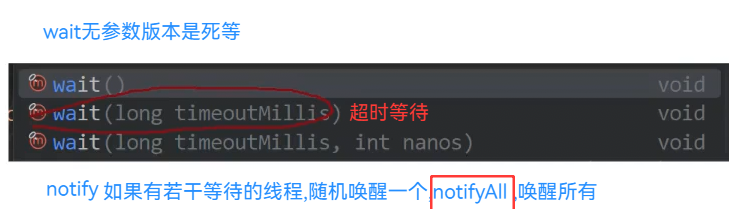
wait和sleep的共同点:都可以让线程阻塞,都可以指定阻塞时间 wait和sleep的区别: 1.wait的设计是为了被notify,超时只是"后手" sleep的设计就是为了按照一定时间阻塞 2.wait必须搭配锁使用,sleep则不需要 3.wait一进来就会先释放锁,在获取锁,sleep放在锁内部,休眠时不会释放锁 4.wait虽然能通过interrupt唤醒,实际更希望通过notify唤醒(正常情况),notify唤醒之后,还可以随时再wait,再notify sleep和interrupt就不是,Interrupt可能把线程终止掉
多线程编程案例:
1.单例模式:
一种设计模式,保证java进程中的某个类只有唯一 一个实例
执行效率:程序再计算机上运行的快慢 开发效率:程序员写代码时的快慢(目前开发比执行更重要,执行效率可通过升级硬件弥补,程序员的人力成本逐年上升) 编译器优化=>提高执行效率 设计模式(不止23种):可以提高开发效率 (不同编程语言存在不同设计模式)  Instance可以表示多种含义:1.表示一台服务器 2.表示服务器主机上的一个服务器进程 3.表示某个类的一个对象 单例模式应用场景
Instance可以表示多种含义:1.表示一台服务器 2.表示服务器主机上的一个服务器进程 3.表示某个类的一个对象 单例模式应用场景


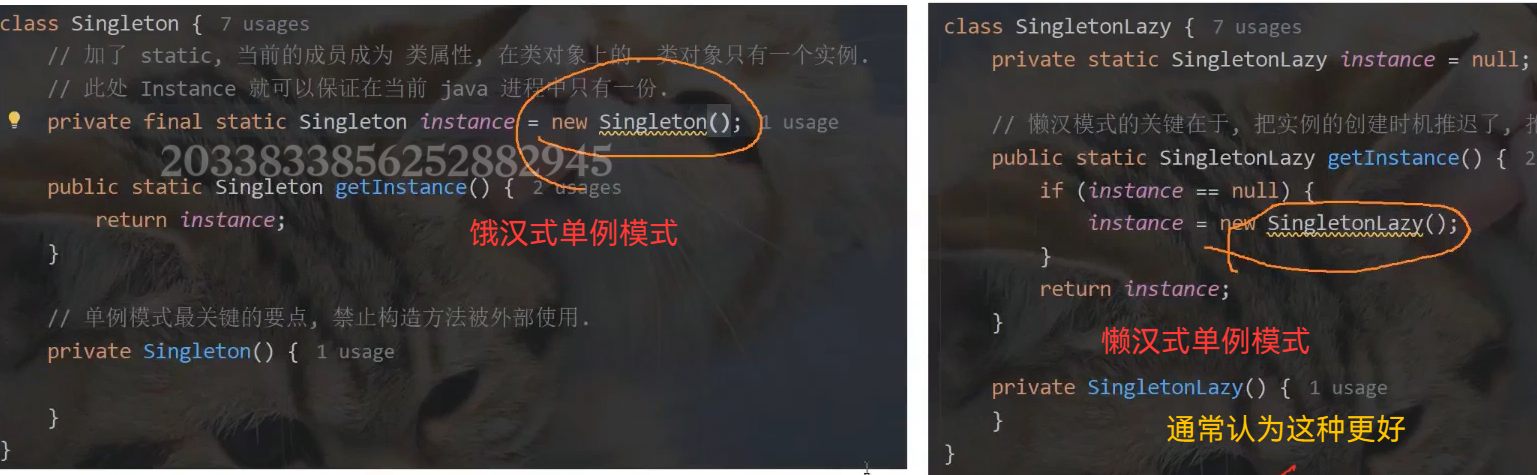 饿汉式单例模式天然线程安全,getInstance只涉及读操作,多个线程对同一变量进行读取,没问题, 懒汉式单例模式不安全 ,它的修改操作不是原子的(java 的= 通常是原子的),条件判定和赋值放在一起,是完整的逻辑,不是原子的
饿汉式单例模式天然线程安全,getInstance只涉及读操作,多个线程对同一变量进行读取,没问题, 懒汉式单例模式不安全 ,它的修改操作不是原子的(java 的= 通常是原子的),条件判定和赋值放在一起,是完整的逻辑,不是原子的
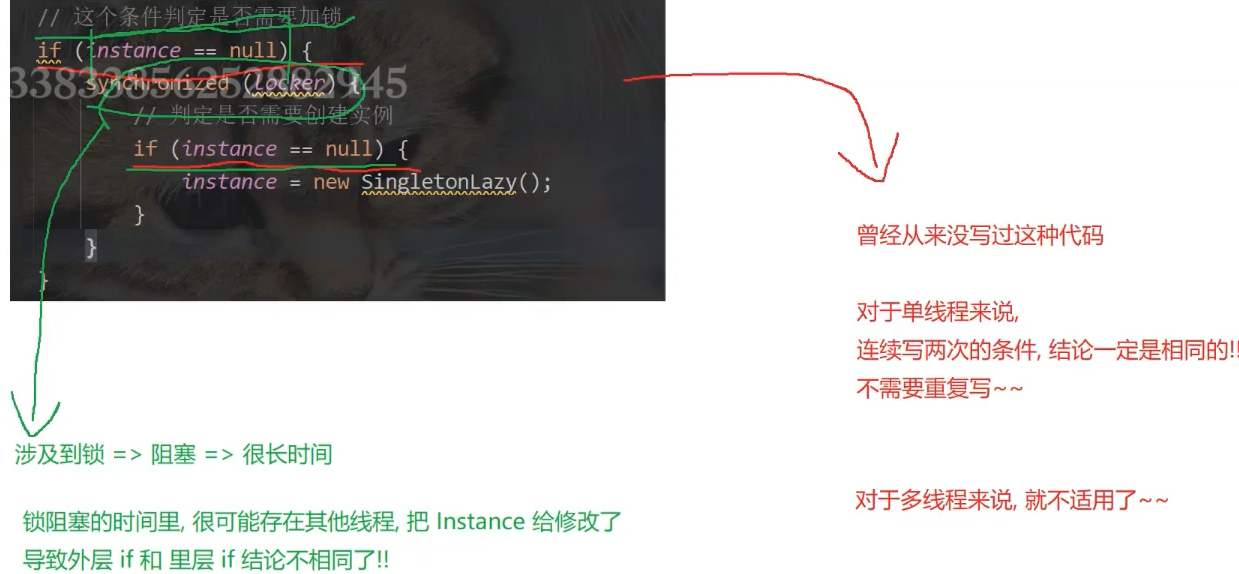

指令重排序引起的问题
编译器的一种优化手段:调整指令执行顺序,使代码效率更高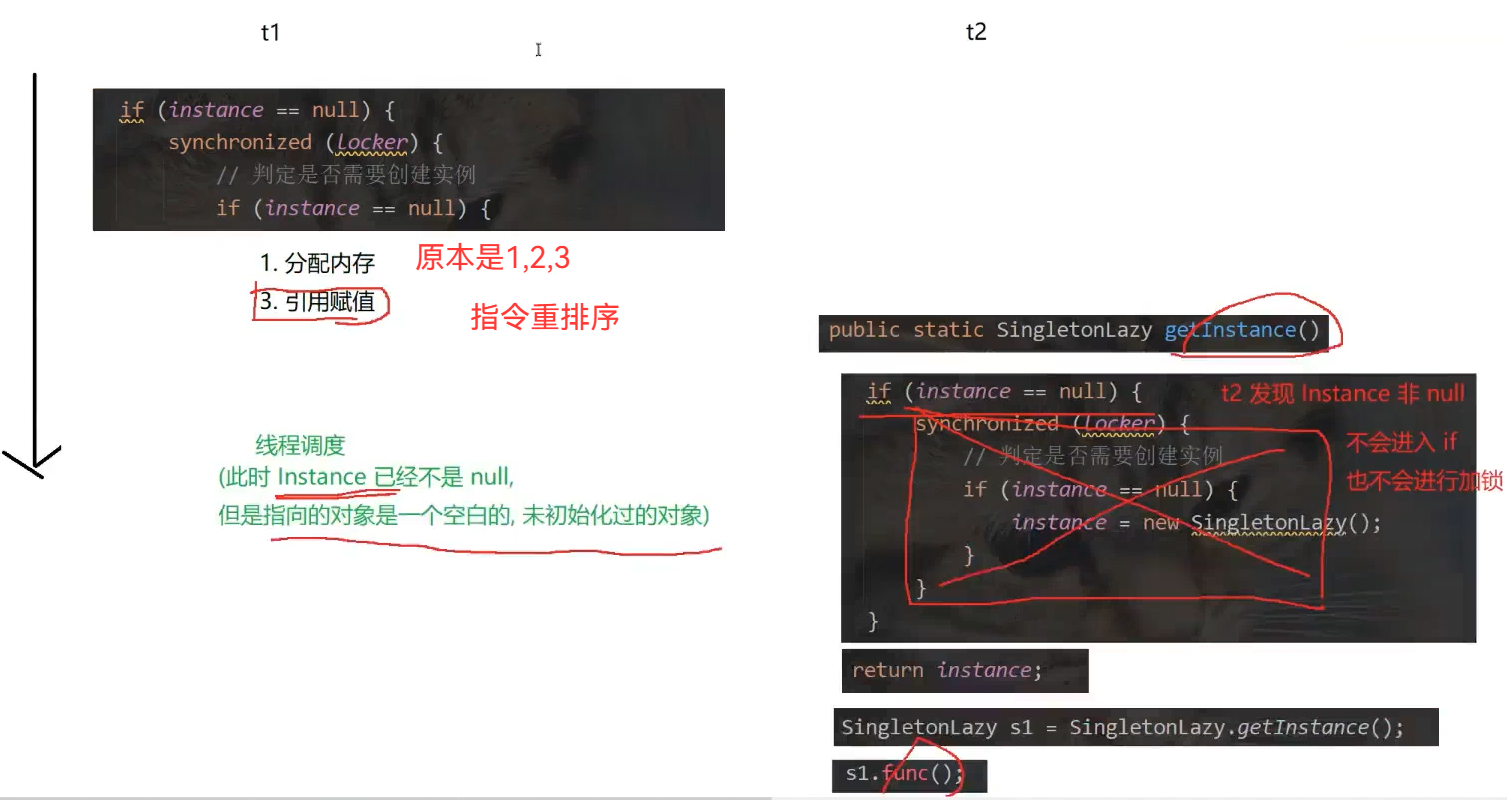


![]() 完备的懒汉式单例模式代码:
完备的懒汉式单例模式代码:
package thread;
//懒汉式单例模式
class Singleton1{
private static Object locker = new Object();
//加volatile,关闭编译器优化,防止指令重排序产生的问题
private volatile static Singleton1 instance;
//懒汉式的关键在,将创建的时机推迟了,等第一次使用才创建
public static Singleton1 getInstance(){
//判断是否需要加锁
if(instance == null){
//加锁防止线程不安全问题
synchronized(locker){
//判断是否需要创建实例
if(instance == null){
instance = new Singleton1();
}
}
}
return instance;
}
private Singleton1(){
}
}多线程代码中,不是加了锁就一定线程安全,也不是不加锁就一定线程不安全(具体问题具体分析)
工作后最高频使用的数据结构:ArrayList/数组 HashMap Queue (通用解决方案) Stack,LinkedList,TreeSet...使用非常少,特殊场景下的解决方案 Python JS PHP Lua直接把ArrayList和HashMap内置到语法中了(内置类型)
阻塞队列(BlockingQueue)
:先进先出(FIFO)非常重要的数据结构 通过阻塞队列可以实现很多有用的效果(生产者消费者模型,实际开发中常见编程手法)
通过阻塞队列可以实现很多有用的效果(生产者消费者模型,实际开发中常见编程手法)
 生产者消费者模型,产生的作用: 1.降低资源竞争 2.解耦合
生产者消费者模型,产生的作用: 1.降低资源竞争 2.解耦合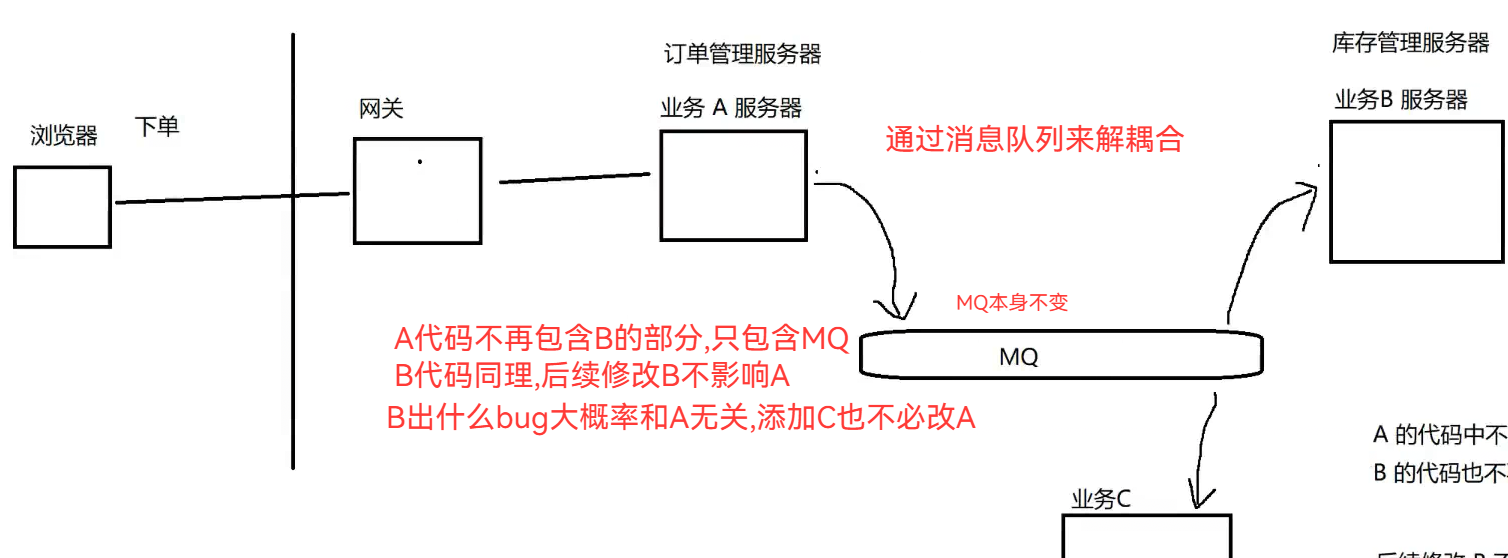
3.削峰填谷 "峰"指请求高峰,流量高峰 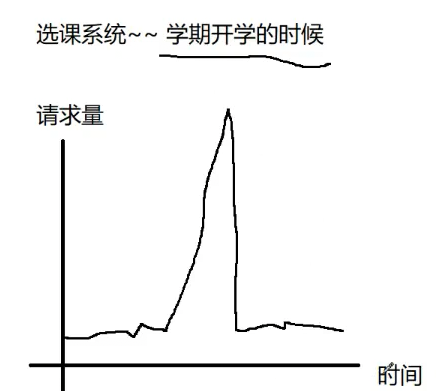

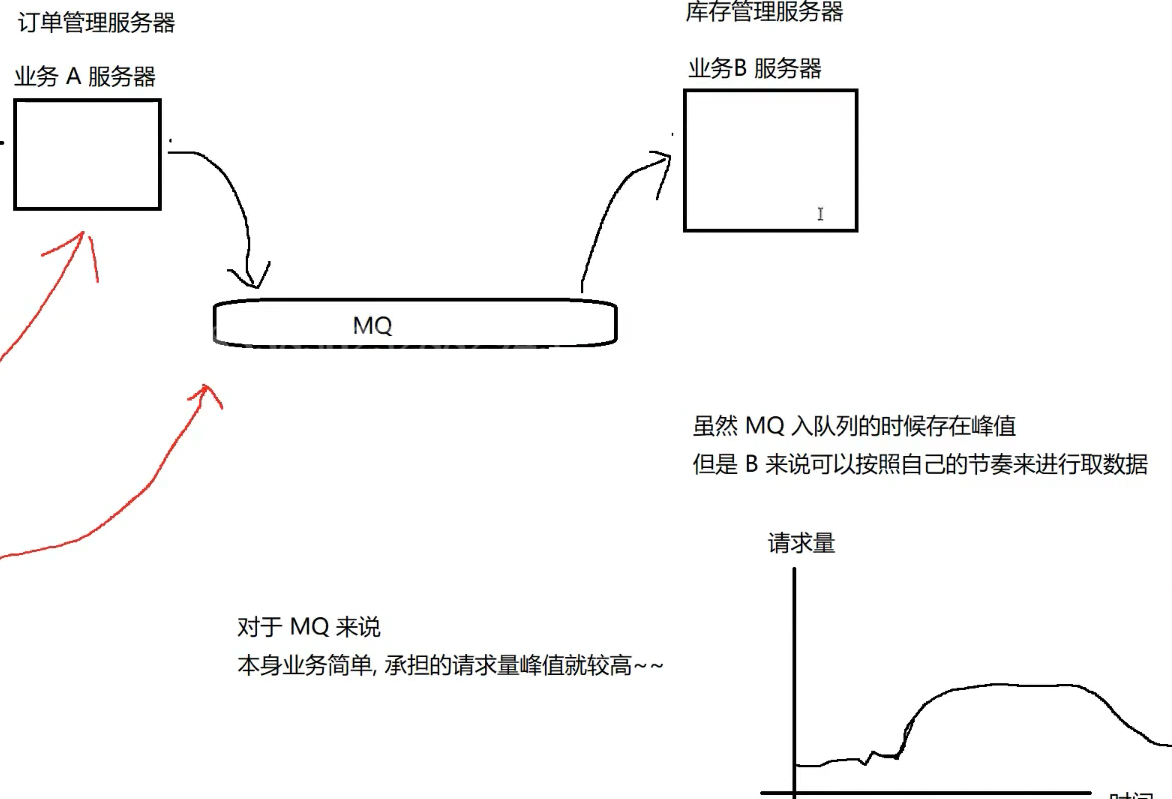 生产者消费者模型弊端:1.单个请求响应时间,可能受到影响 .2.服务器结构更为复杂. 它更适合"异步"操作,不适合"同步"场景
生产者消费者模型弊端:1.单个请求响应时间,可能受到影响 .2.服务器结构更为复杂. 它更适合"异步"操作,不适合"同步"场景
Java标准库提供了阻塞队列
![]()

泛型在开发中会用到的场景:1.集合类 2.Spring统一封装返回结果

自己实现一个阻塞队列:
package fact.demo;
//自己实现一个阻塞队列
//暂时不考虑泛型,只保存String类型
class MyBlockingQueue{
private String[] data ;
//定义首尾下标
private int head=0;
private int tail=0;
private int size =0;
public MyBlockingQueue(int capacity){
data = new String[capacity];
}
private Object locker = new Object();
public void put(String elem) throws InterruptedException {
synchronized(locker){
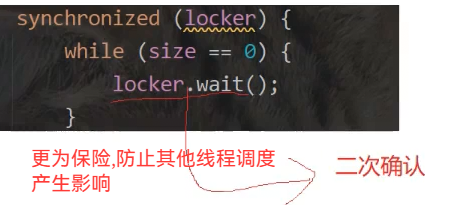
while(size == data.length){
//队列为满阻塞
locker.wait();
}
//新元素放到tail所在位置
data[tail] = elem;
tail++;
if(tail>=data.length){
tail = 0;
}
size++;
locker.notify();
}
}
public String take() throws InterruptedException {
synchronized(locker){
while(size==0){
//队列为空阻塞
locker.wait();
}
//取出head位置的元素
String ret = data[head];
head++;
if(head>=data.length){
head = 0;
}
size--;
locker.notify();
return ret;
}
}
}
public class Demo25 {
public static void main(String[] args) {
MyBlockingQueue myBlockingQueue = new MyBlockingQueue(1000);
Thread t1 = new Thread(()->{
long n = 0;
while(true){
try {
// myBlockingQueue.put(String.valueOf(n));
myBlockingQueue.put(n+" ");
System.out.println("生产了"+n);
n++;
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
Thread t2 = new Thread(()->{
while(true){
try {
String n = myBlockingQueue.take();
System.out.println("消费了"+n);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t1.start();
t2.start();
}
}
池:可能会用到,事先准备好(提高效率的手段) 常量池,线程池,进程池,内存池,连接池
线程池:
把线程提前创建好,放到一个位置,要用的时候去取,比从操作系统创建更快
引入线程池原因:
操作系统可视为两部分:1.内核(核心功能所在,eg:进程管理操作) 2.配套的应用程序(自带的画图板,计算机之类的) 应用程序(代码执行在用户态) 操作系统内核(代码执行在内核态)
eg:t.start()创建线程 1.一旦调用,先执行一系列逻辑(用户态) 2.start内部调用操作系统api(内核态) 3.回到用户态,继续往下执行(用户态) 这样的切换有一定开销
操作系统为了让应用程序有稳定运行环境,把CPU很多权限收紧了
采用线程池的方案,提前把线程通过系统api创建好,把这些Thread对象放到一个集合类中,后续使用,直接从集合类取(纯用户态代码)
标准库提供现成的线程池 java生态很丰富
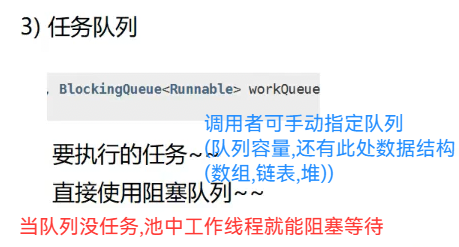
线程池的使用:2.submit方法,往池子中添加要执行的任务(Runnable) submit(Runnable task) 1.构造方法(重点)(开发中用到,也是经典面试题)
![]()


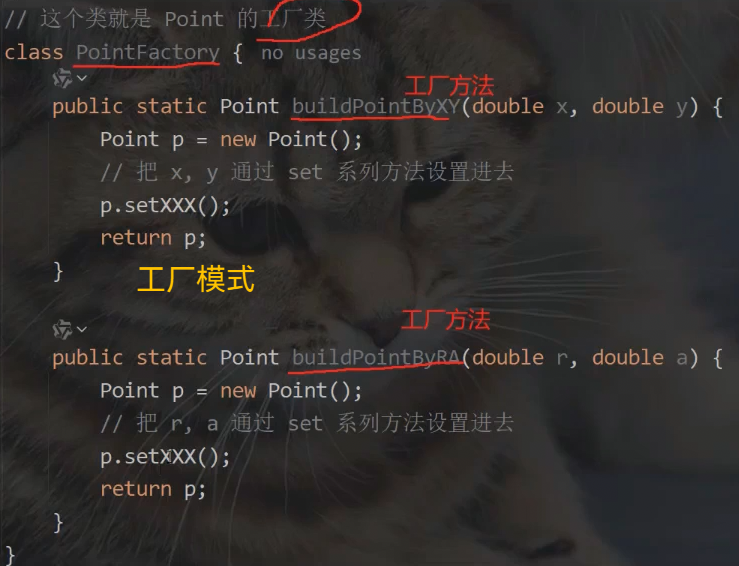
 这个问题是坐标两种表示形式不能构成重载的问题,可使用工厂模式解决
这个问题是坐标两种表示形式不能构成重载的问题,可使用工厂模式解决




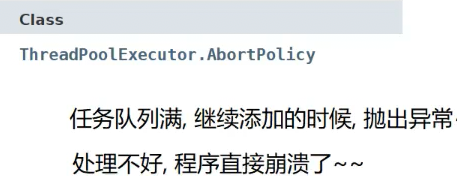


 日常开发中,都认为新任务比较重要,上述策略都在尽力让新任务执行
日常开发中,都认为新任务比较重要,上述策略都在尽力让新任务执行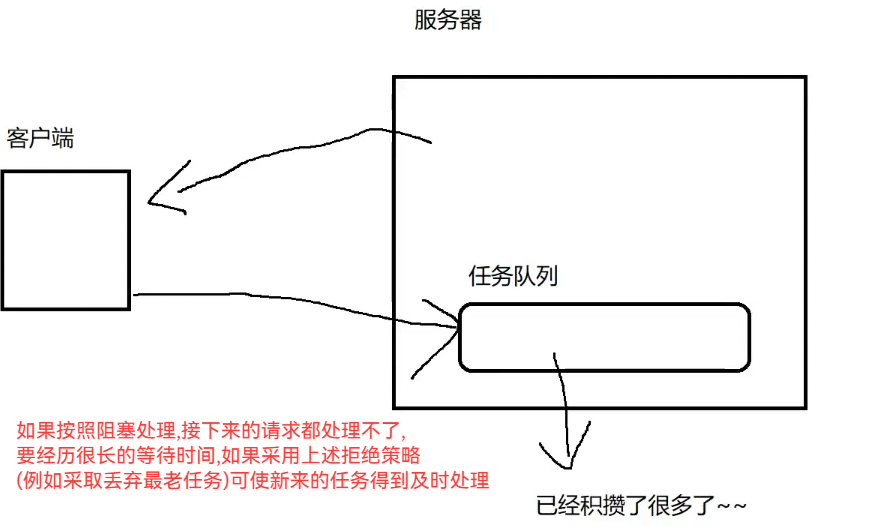
![]()

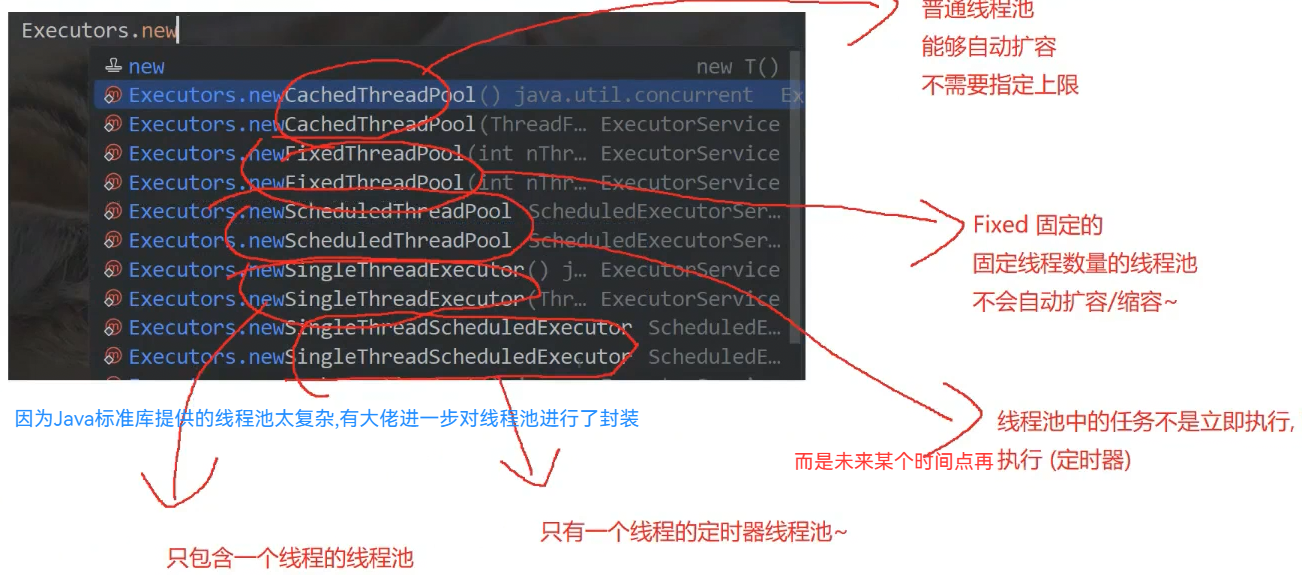
线程池Executors工厂类使用代码演示:
public class Demo26 {
public static void main(String[] args) {
//可以自动扩容,都是非核心线程,没有核心线程
//ExecutorService executorService = Executors.newCachedThreadPool();
//指定的数量都是核心线程
ExecutorService executorService = Executors.newFixedThreadPool(5);
for (int i = 0; i < 1000; i++) {
//通过设置局部变量,使匿名内部类能进行变量捕获
final int id = i;
executorService.submit(new Runnable() {
@Override
public void run() {
String name = Thread.currentThread().getName();
System.out.println("hello"+name +","+id);
}
});
}
executorService.shutdown();
}
}定时器:
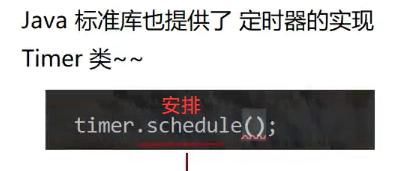

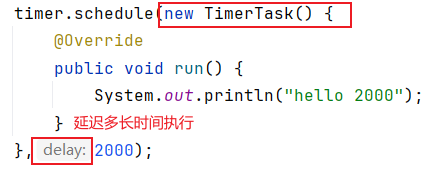
![]() 模拟实现定时器:
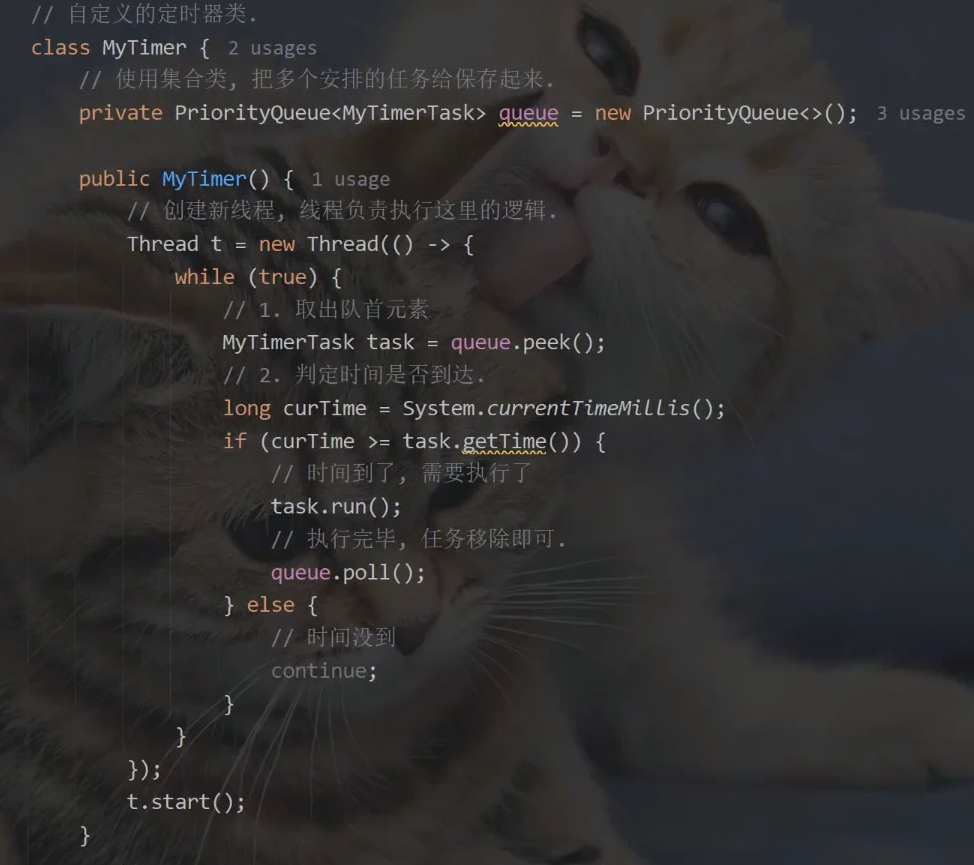
模拟实现定时器: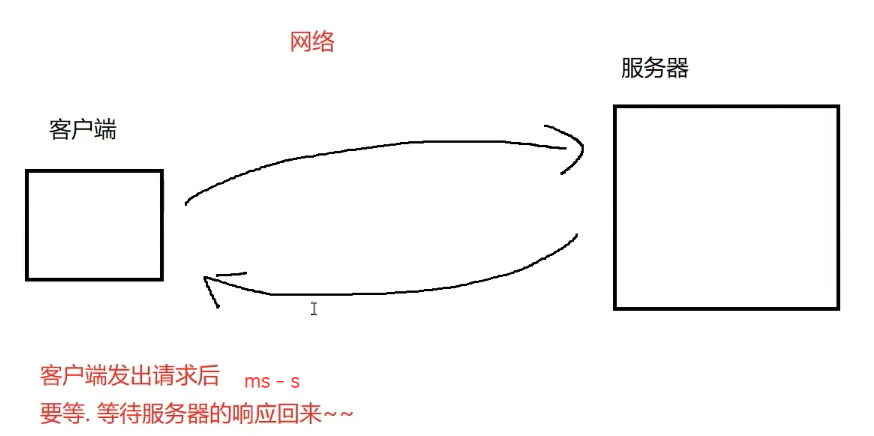
![]()




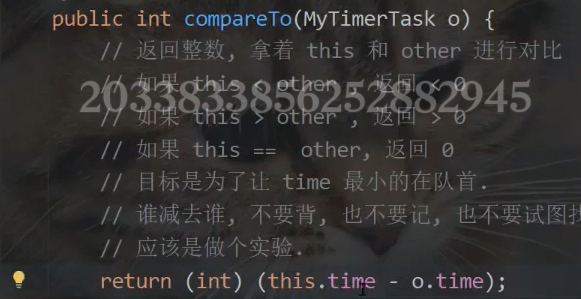
ThreadLocal
(面试常见问题,关心的是JVM/GC,不是多线程) 定义线程级变量,(期望有一种变量,生命周期跟随线程,作用域也在线程中)



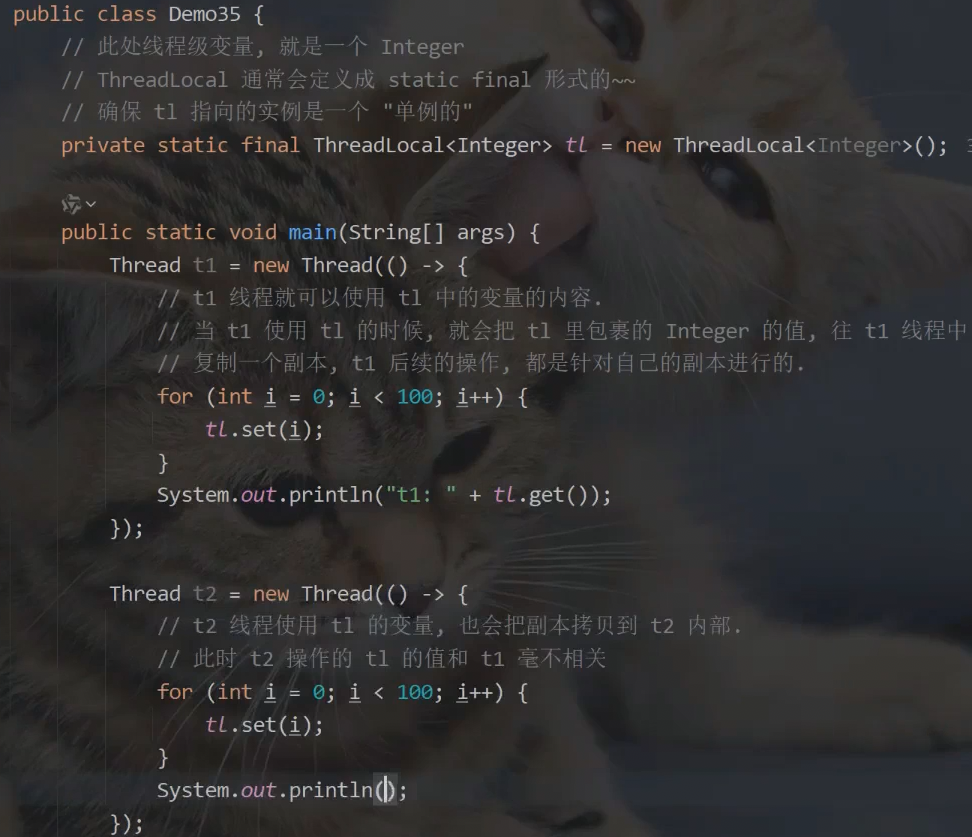





三.多线程进阶 (主要面试题,实际很少用)
1.锁策略

乐观锁VS悲观锁
重量级锁VS轻量级锁 

挂起等待锁VS自旋锁(spin lock)
公平锁VS非公平锁 ![]()
可重入锁(也称:递归锁)VS不可重入锁 

普通互斥锁VS读写锁(实际开发比较常见)
面试题
2.CAS
是解决线程安全问题的另一种思路,加锁是普适方案
compare and swap (比较且交换):比较一个内存和一个寄存器的值, 如果这两相同,就把内存和另一个寄存器的值进行交换


unsafe包,针对一些底层的操作,都可能是unsafe.(CAS在此包中) 系统底层操作,操作步骤比较麻烦,注意事项也比较多

1.原子类(开发中比较实用的存在)




2.自旋锁
synchronized内部"自旋"就是靠CAS,基于CAS实现的是"轻量级锁". 使用CAS不必加锁(重量级锁),基于CAS的"无锁编程"(重量级锁)
3.ABA问题 


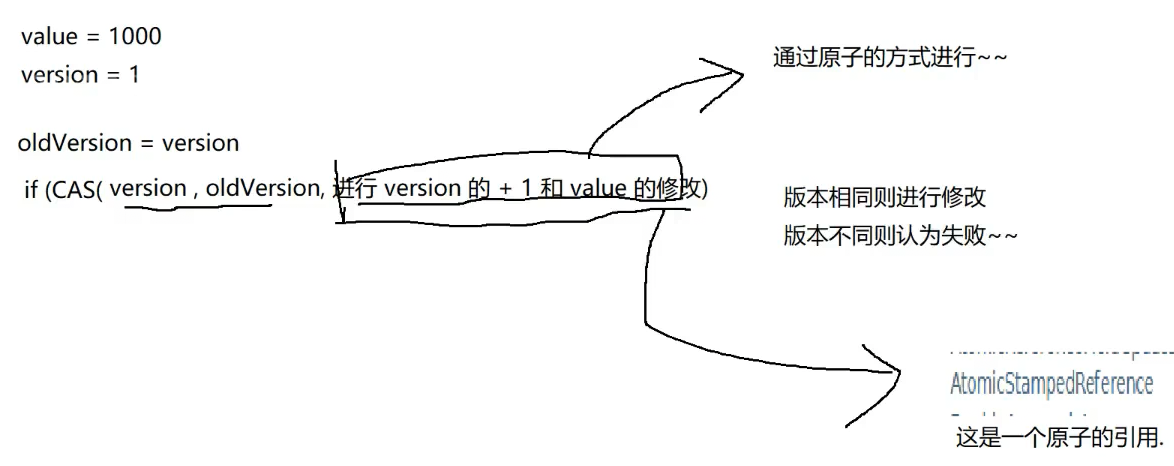
CAS应对面试:1.CAS是啥2.应用场景(CAS如何实现锁)3.CAS的ABA问题是啥样的
实际开发中一般不会直接用到CAS,而是用到像原子类这样的封装CAS的操作
3.synchronized内部原理
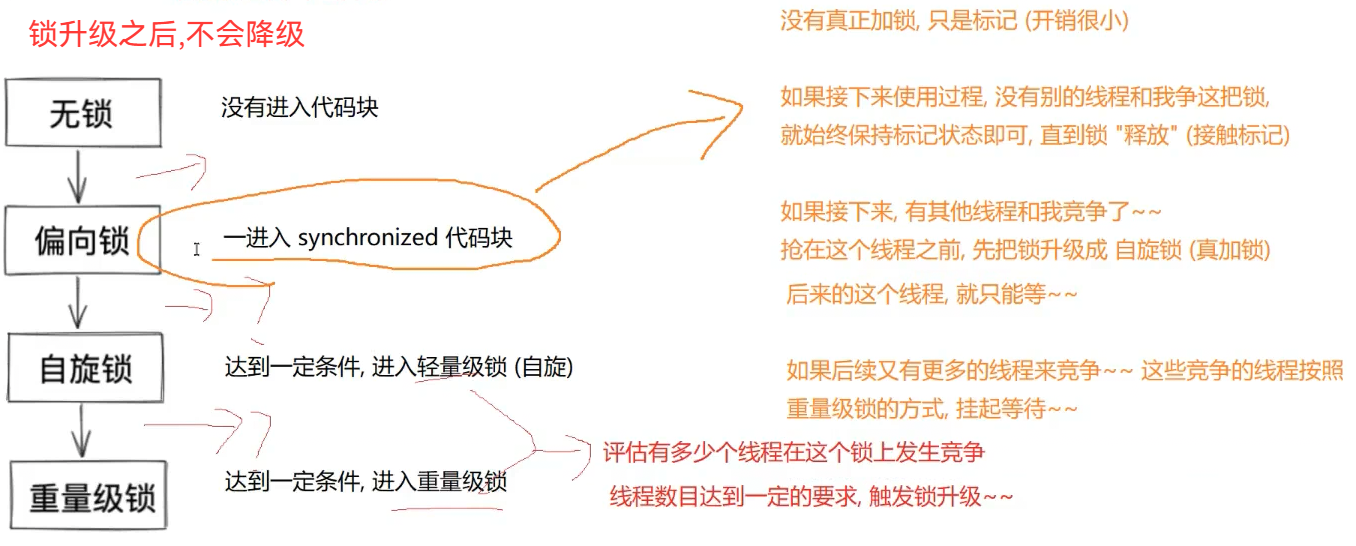
1.锁升级(自适应过程)JVM内部实现逻辑
2.锁消除(针对synchronized进行的编译器优化)
3.锁粗化(锁的粒度,与加锁解锁之间有多少逻辑有关)
有多个任务要执行,加了多次锁,虽然留出空闲时间让别的线程获取,但增加了竞争次数,同时增加阻塞时间 ,锁粗化后,只加一次锁,整个执行过程只涉及一次竞争(还与编译器优化有关)
4.JUC(java.util.concurrent)的常见类
JUC面试中的"常见类"
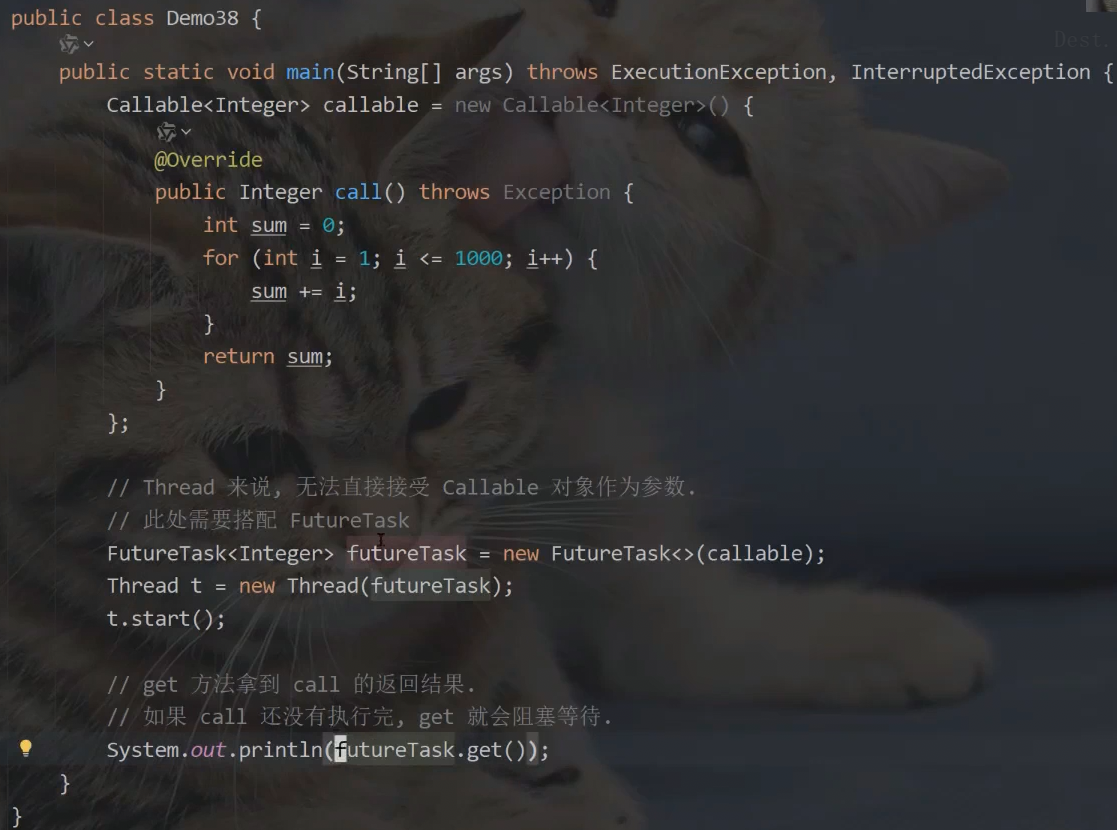
Callable接口


2.ReentrantLock(可重入锁)

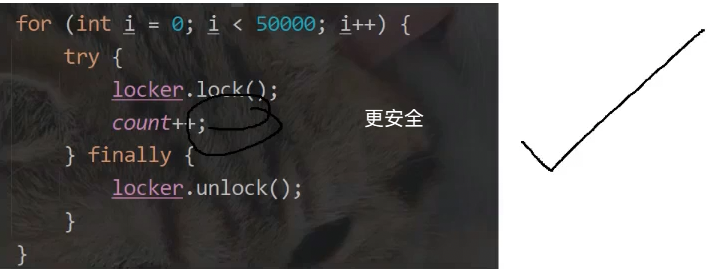

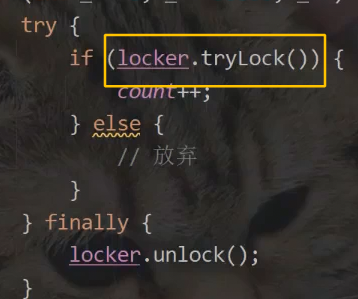


3.信号量Semaphore
信号量就是一个"计数器",描述了"可用资源"的个数 在信号量中,如果数值已经是0了,继续进行P操作就会触发阻塞
在信号量中,如果数值已经是0了,继续进行P操作就会触发阻塞



4.CountDownLatch

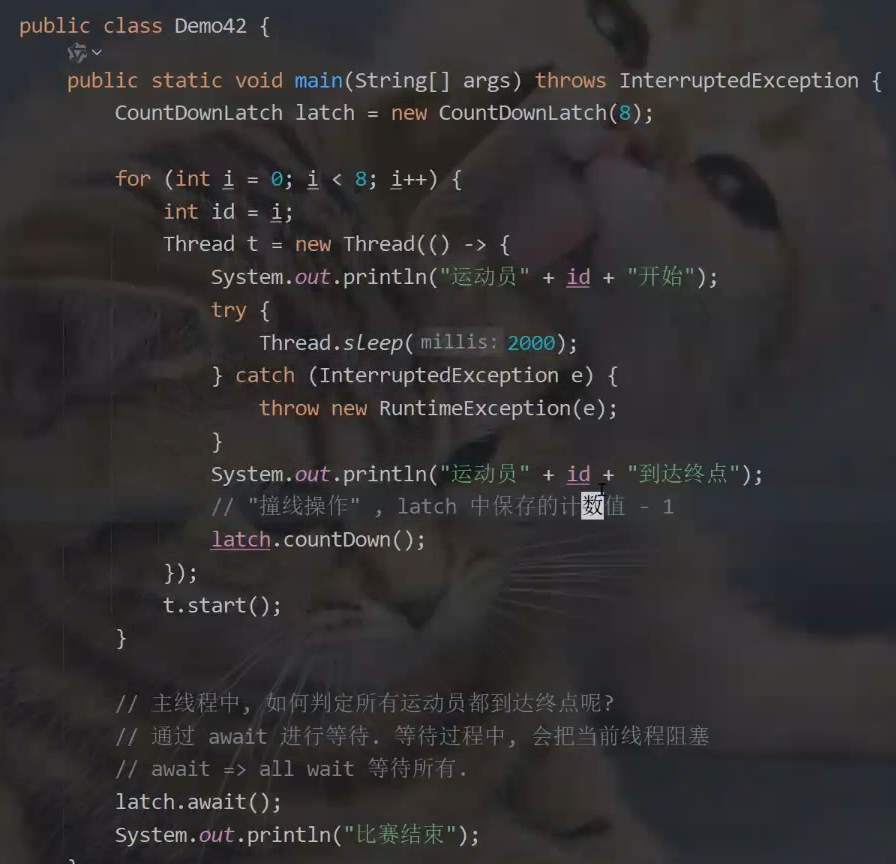
5.线程安全的集合类
Vector,Stack,HashTable,是线程安全的(不建议用),其他的集合类不是线程安全的.
1.多线程环境下使用ArrayList![]()


写时拷贝适用于比较小的数据
2.多线程环境下使用队列(简单了解)
1. ArrayBlockingQueue 基于数组实现的阻塞队列
2. LinkedBlockingQueue 基于链表实现的阻塞队列
3. PriorityBlockingQueue 基于堆实现的带优先级的阻塞队列
4. TransferQueue 最多只包含一个元素的阻塞队列
3.多线程环境下使用哈希表(常见面试题) 

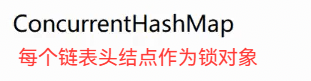




关于AI
AI大语言模型针对全领域(ChatGPT,DeepSeek,Gemini,Grok,Kimi,豆包...)
相对的"小语言"针对某个特定知识领域 coze (字节的,AI agent的工作流) dify(开源社区)
AI agent"把大化小" 工作流是把若干个AI agent 串到一起,完成更复杂的工作
通过AI工作流:1.把每节课视频获取到,通过AI大模型提取语音,生成文字 2.通过大语言模型把完整文字进行提炼总结 3.让大语言模型通过MCP server控制git把课堂总结提交到gitee上


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)