LightRAG安装与使用(windows),与常规rag对比区别
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
LightRAG安装与使用(windows),与常规rag对比区别
前言
随着大模型在智能客服、企业知识库、文档问答等场景广泛落地,检索增强生成(RAG) 已经成为解决模型幻觉、提升回答准确性的核心技术。但大家在实际使用中会发现:普通 RAG 只能做 “语义相似匹配”,遇到关联问题、多条件规则、跨文档知识时,经常答不全、逻辑断、容易乱。
为了解决这些问题,GraphRAG(知识图谱增强 RAG) 应运而生。它把知识变成 “实体 — 关系 — 实体” 的结构,让机器真正理解知识之间的联系。不过早期的 GraphRAG 方案(如微软 GraphRAG)太重、部署复杂、成本高、还不支持频繁更新,让很多人望而却步。
这时,LightRAG 出现了:轻量、快、省 token、支持增量更新、不用额外装图数据库,完美适配客服、活动规则、高频更新的知识库场景。
下面内容为
传统 RAG 差在哪 → GraphRAG 强在哪 → LightRAG 与微软 GraphRAG 怎么选 → 技术架构一目了然 → 快速上手对比。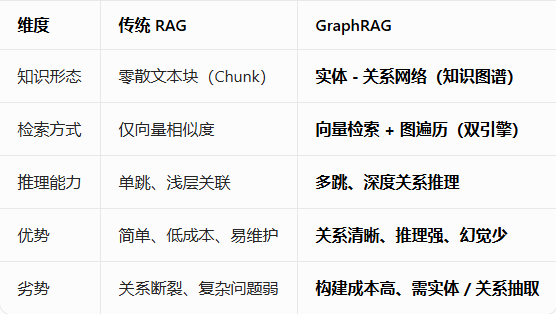
注意
此次是安装在windows,源码安装,调用商业大模型,
原因:这台我自己电脑,之后我会放在linux上面
然后为什么官方有docket等安装方式,而我源码安装是因为我这台电脑太烂启动docket,电脑基本就跑不动了,这也是我为什么悬着使用商业大模型,目前选择了deepseek的llm模型,以及glm的向量模型Embedding-3
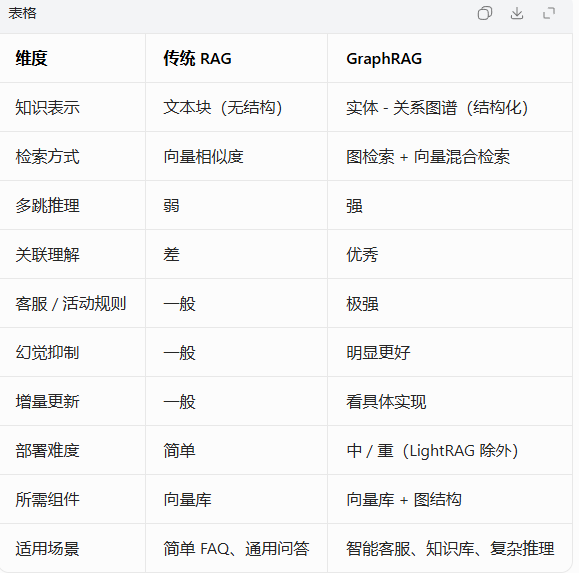
一、传统 RAG vs Graph RAG:从 “文本匹配” 到 “知识理解”
1.1传统 RAG(常规 RAG)是什么?
传统 RAG 是目前最常见的方案:把文档切块 → 生成向量 → 存入向量库 → 用户提问检索相似块 → 丢给 LLM 生成回答。
核心技术栈
文本分块:固定大小 / 按段落
向量模型:Embedding 模型
存储:向量库(Milvus、FAISS、Chroma、Pinecone)
检索:余弦相似度检索
图数据库:无
知识结构:无结构 / 半结构文本块
优点
简单、稳定、兼容性强
适合简单 FAQ、单段落问答
缺点
只看语义相似,不懂知识关系
跨文档、多跳问题答不好
规则类、活动类问答容易漏条件
上下文碎片化,逻辑不连贯
高频更新时索引维护麻烦
1.2 Graph RAG(知识图谱增强 RAG)是什么?
GraphRAG 在传统 RAG 基础上,加入知识图谱,把文本变成:实体 — 关系 — 属性 — 来源文档
系统不再只是 “找相似句子”,而是理解知识结构。
核心技术栈
实体抽取 / 关系抽取
知识图谱存储
向量库 + 图数据库混合检索
双层检索:图谱推理 + 向量召回
可做路径查询、多跳推理、关联解释
优点
回答更准、逻辑更强、幻觉更少
擅长关联问答、规则问答、多跳问答
知识可追溯、可可视化
适合客服、法律、医疗、政务等高要求场景
缺点(老方案)
重、部署成本高
索引耗 token
部分方案不支持增量更新
对比
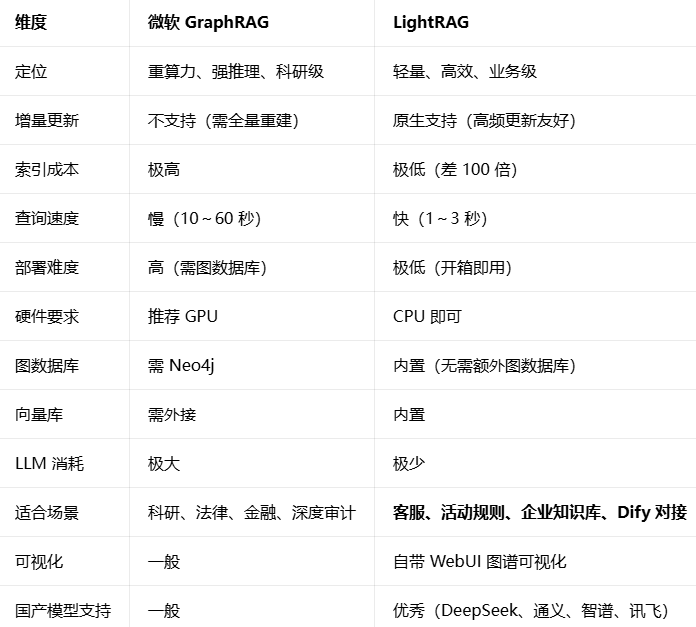
二、第二章 GraphRAG 两大主流方案:微软 GraphRAG vs LightRAG
目前最常用的两个 GraphRAG 开源项目:
1.微软 GraphRAG(microsoft/graphrag)
2.LightRAG(HKUDS/LightRAG)
两者定位完全不同,适用场景天差地别。
2.1 微软 GraphRAG
微软官方开源,是标准、重算力、强推理的 GraphRAG 标杆。
核心技术
全局社区聚类、社区摘要
多跳检索、全局理解能力极强
图存储:支持 Neo4j
向量库:支持多种
LLM 调用:多阶段、大量 token
优点
推理能力最强
跨文档理解最强
学术 / 工业标准方案
可解释性极强
缺点
不支持增量更新
索引极慢、极贵
查询延迟高(10 秒 +)
部署重、需要资源高
不适合客服 / 频繁更新场景
2.2 LightRAG
港大开源,轻量级、快、省成本、支持增量,专为真实业务场景设计。
核心技术
轻量级实体 - 关系抽取
双层检索:图谱检索 + 向量检索
内置存储:不需要 Neo4j、不需要 Milvus
增量更新:随时加 / 改文档
CPU 可跑
#优点
极快(查询 1~3 秒)
省 99% token
原生增量更新
部署极简、兼容国产模型
完美适配客服、活动规则、高频更新知识库
可直接对接 Dify、FastGPT
缺点
超深度全局推理略弱于微软 GraphRAG
对比
三.安装部署LightRAG
此次为windows
建议创建一个新环境,python=3.10
可以用uv(官方推荐),也可以用conda,我是用的conda(因为我之前做一些东西用到conda,懒得再去uv了)
github的地址为:
可以拉取代码,也可以直接使用命令行下载
进入到目录复制这个env.example重命名为.env(这是配置文件)
然后在命令行输入:
依赖库(有三个,我选择的这个不需要本地模型)
pip install -r requirements-offline.txt
构建前端代码
pip install "lightrag-hku[api]"
再去修改配置文件.env,填上自己的key
可以用查找搜索LLM_BINDING=openai这个位置
默认是
#LLM_BINDING=openai
#LLM_BINDING_HOST=https://api.openai.com/v1
#LLM_BINDING_API_KEY=your_api_key
#LLM_MODEL=gpt-5-mini
这里可以改一下
比如我是deepseek
LLM_BINDING=openai
LLM_BINDING_HOST=https://api.deepseek.com/v1
LLM_BINDING_API_KEY=sk-xxxxxx
LLM_MODEL=deepseek-chat
LLM_TIMEOUT=180
OPENAI_LLM_MAX_TOKENS=8192
在去找向量模型
也是可以搜索EMBEDDING_BINDING=openai这个位置
默认这里是
### OpenAI compatible embedding
#EMBEDDING_BINDING=openai
#EMBEDDING_BINDING_HOST=https://api.openai.com/v1
#EMBEDDING_BINDING_API_KEY=your_api_key
#EMBEDDING_MODEL=text-embedding-3-large
#EMBEDDING_DIM=3072
#EMBEDDING_TOKEN_LIMIT=8192
#EMBEDDING_SEND_DIM=false
# EMBEDDING_USE_BASE64=true
然后我们改成glm的,或者你自己的
EMBEDDING_BINDING=openai
EMBEDDING_BINDING_HOST=https://open.bigmodel.cn/api/paas/v4
EMBEDDING_BINDING_API_KEY=xxxxx
EMBEDDING_MODEL=embedding-3
EMBEDDING_DIM=2048
EMBEDDING_TOKEN_LIMIT=8192
然后在命令行输入
lightrag-server
注意上面显示 http://localhost:9621,但是我我们要输入http://127.0.0.1:9621/进入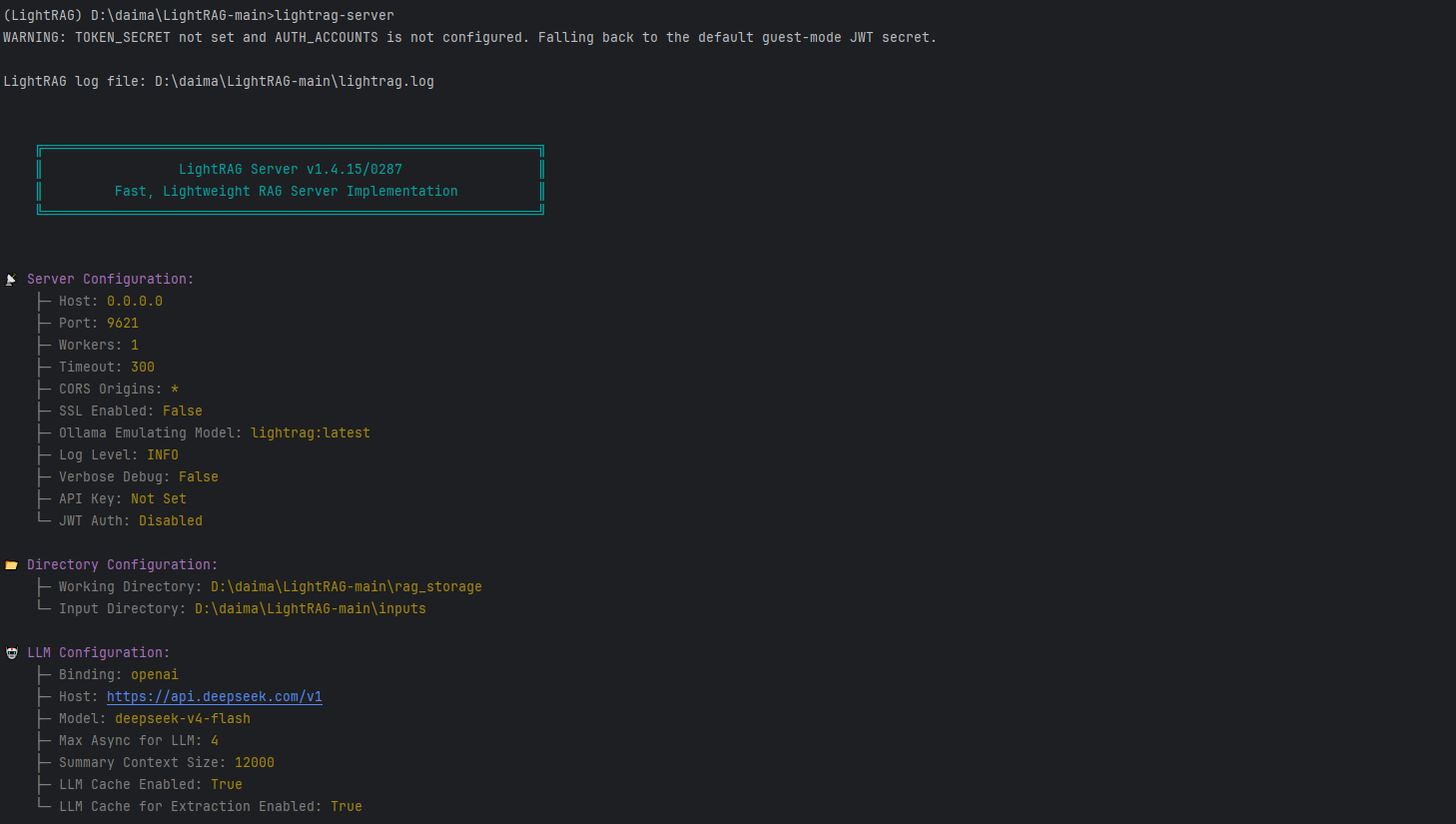
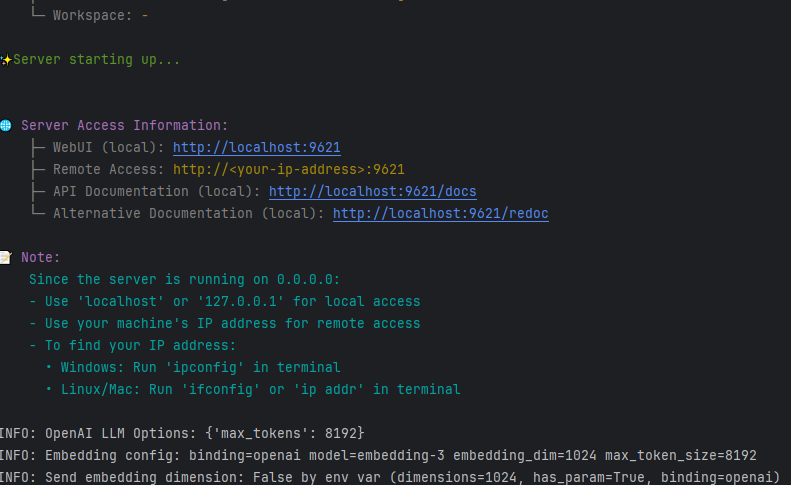
需要改成中文可以点击这里(在右上角)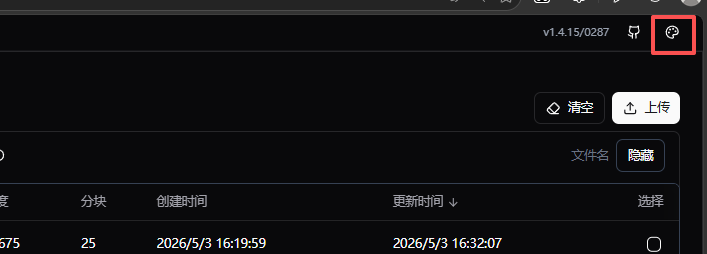
可以选择上传一个简单文档测试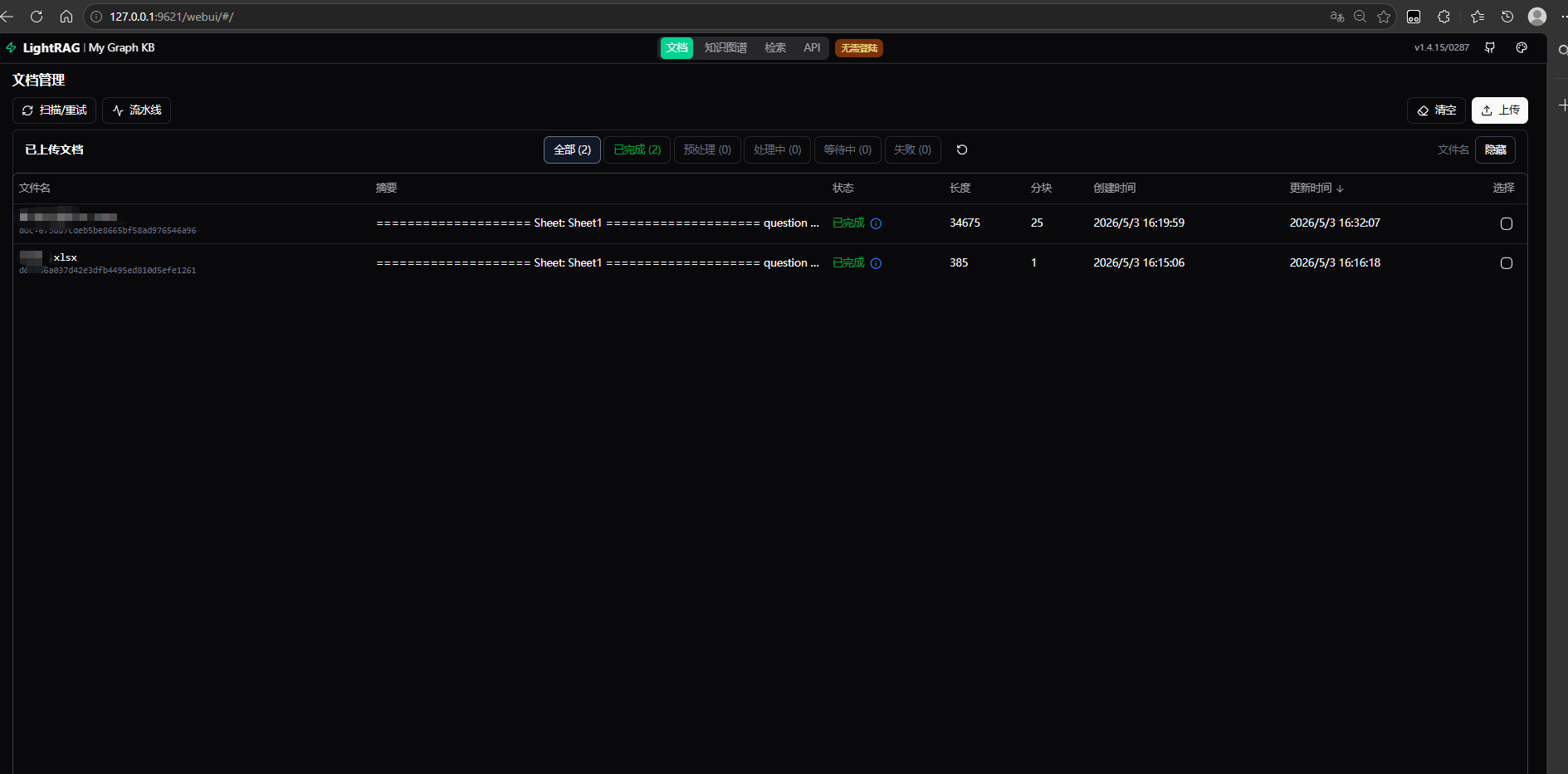
这里可以查看图谱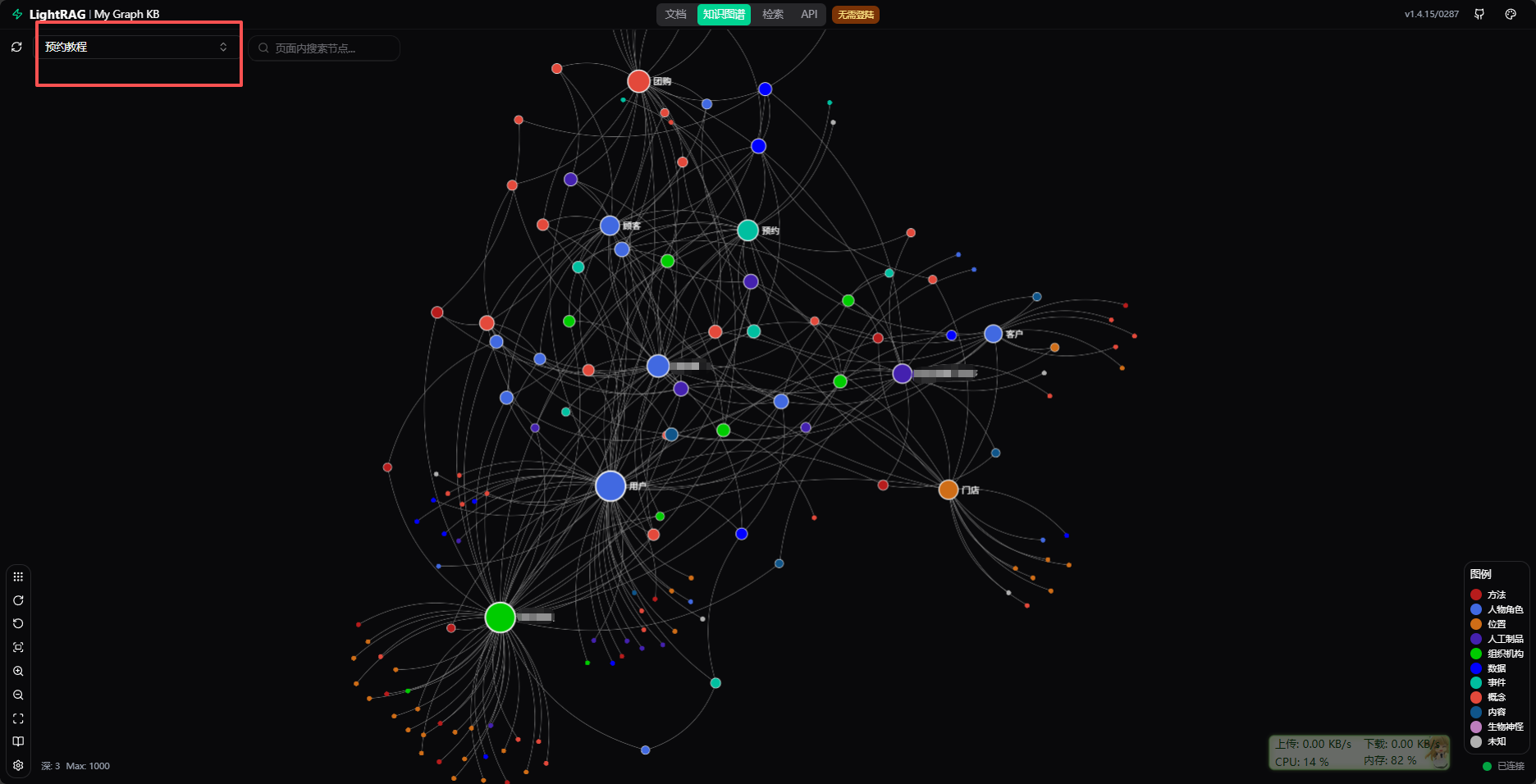
可以进行问问题回答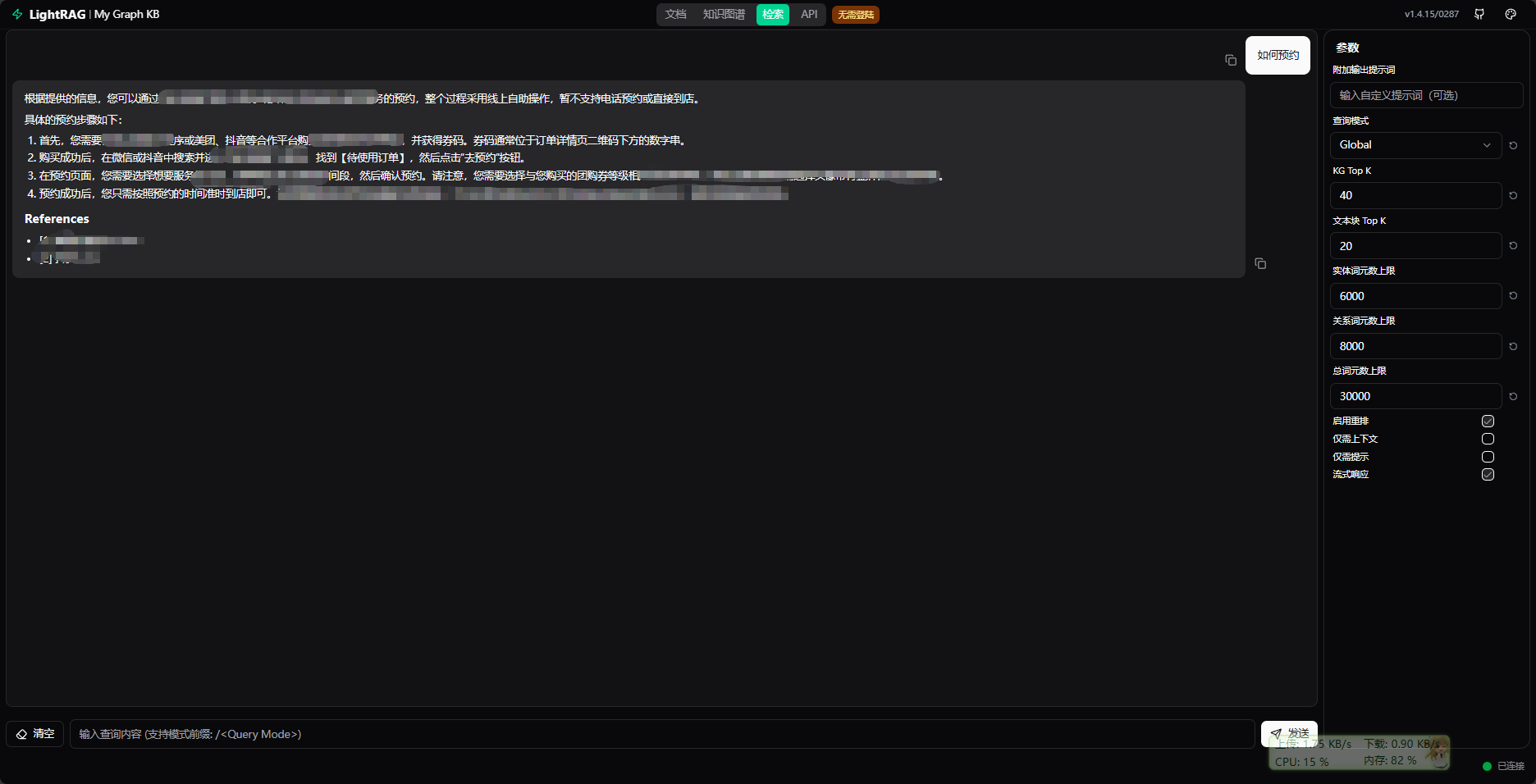
四.调用LightRAG
可以直接用下面代码,也是ai写的,可以直接用
import requests
import json
BASE_URL = "http://127.0.0.1:9621"
def ask_question(query):
"""
调用 LightRAG 接口提问
"""
url = f"{BASE_URL}/query"
payload = {
"query": query
}
headers = {
"Content-Type": "application/json"
}
try:
response = requests.post(url, json=payload, headers=headers, timeout=30)
response.raise_for_status()
result = response.json()
return result
except Exception as e:
return {"error": str(e)}
# ==================== 主程序 ====================
if __name__ == "__main__":
print("=" * 50)
print(" LightRAG 本地问答测试工具")
print("=" * 50)
while True:
user_input = input("\n请输入你的问题(输入 q 退出):")
if user_input.strip().lower() == "q":
print("退出程序...")
break
if not user_input.strip():
print("请输入有效问题!")
continue
print("\n正在查询知识库...\n")
# 调用接口
result = ask_question(user_input)
# 输出结果
if "response" in result:
print("【AI 回答】:")
print(result["response"])
elif "error" in result:
print("【出错了】:", result["error"])
else:
print("【返回结果】:")
print(json.dumps(result, ensure_ascii=False, indent=2))
效果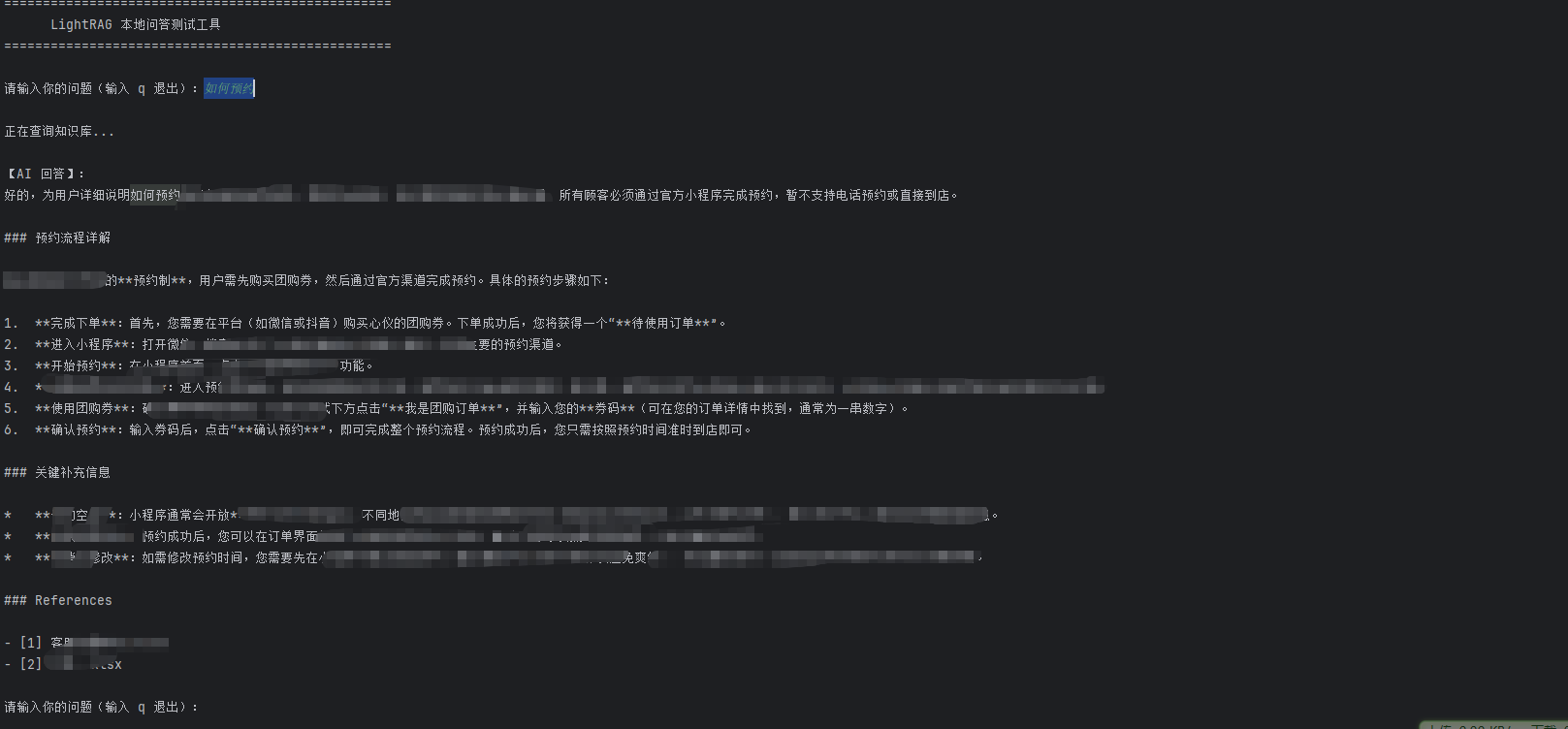
总结
以上就是今天要讲的内容,本文介绍了常规RAG和Graph RAG区别,以及LightRAG部署使用,之后会移动到linux系统上面,以及做多用户使用,现在是只有一个单用户使用的,修改workspace不同实例,做到多用户使用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)