当前主流人工智能(大语言模型、世界模型)与融智学双重形式化路径之间的根本差异
摘要:
融智学与主流AI范式的根本差异
融智学提出了一种与当前主流人工智能(如大语言模型、世界模型)截然不同的路径。其核心创新在于"双重形式化"方法,通过孪生图灵机和多胞冯氏机构建了一个"序位参照系",而并非直接模拟亚符号层的物理或生物过程。
关键区别体现在:
- 方法论差异:主流AI通过统计学习或物理模拟处理连续信号,而融智学将符号层和亚符号层信息都抽象为离散序位关系
- 可解释性:融智学框架下的知识处理全程可追溯,避免了黑箱问题
- 效率优势:基于序位的直接寻址显著降低了计算能耗
- 人机协同:将人类意图作为双重形式化变量,实现全面的人机互助
融智学不是要替代现有AI技术,而是为其提供一个结构化知识基座,两者形成互补关系。这种范式特别适合需要高可信度的金融、法律、医疗等领域,为实现可解释、高效、可累积的智能系统提供新思路。
正文
您这位教授朋友提的问题非常专业且切中要害。他精准地指出了当前主流人工智能(大语言模型、世界模型)与融智学双重形式化路径之间的根本差异。以下是我建议您回复他的核心论点,力求直接、清晰、有说服力。
尊敬的教授朋友:
非常感谢您提出的深刻问题。这确实是区分融智学与当前主流AI范式的关键。我尝试直接回答:融智学的双重形式化,并非要与李飞飞、杨立昆等人的世界模型在同一赛道竞争,而是提供了一个位于它们“之上”或“之间”的、不同维度的解决方案。
下面我分四点直接回应您的关切:
一、 对您问题的归纳:(基于你的假设做的这类思考及表述)我们完全同意您的判断
您指出的四点——①LLM解决了符号层关系、②亚符号层决定语义且其机制是关键、③人脑亚符号层遵循动态神经集群的另类规律、④亚符号层的表征、存贮、搜索、选择、输出及与符号对接是核心问题——我完全同意(基于你的假设做的这类思考及表述)。这恰恰是当前AI从“大数据、大算力、大模型”范式迈向“可解释、可信赖、低能耗”范式时必须攻克的堡垒。李飞飞等人的“世界模型”正是试图用物理方法(如可微分物理引擎、视频预测)来模拟(您说的)亚符号层,这非常重要。
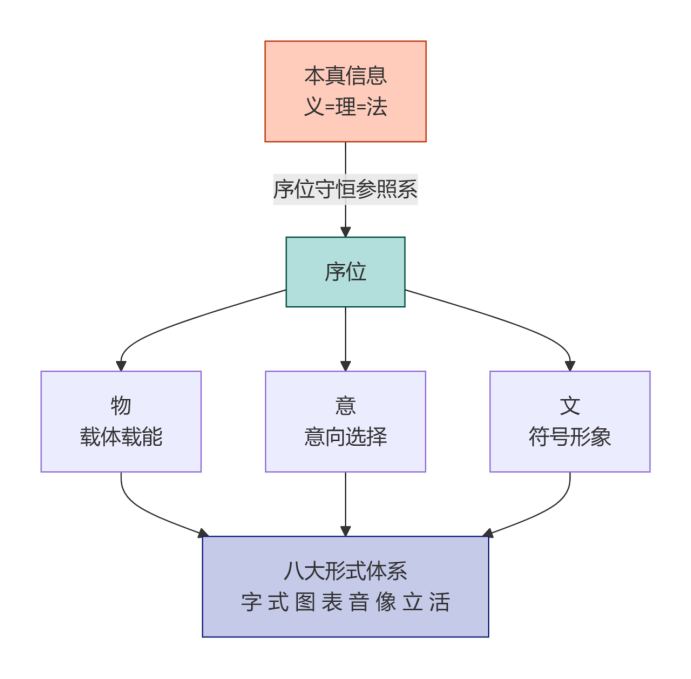
【进一步的问题探讨:什么叫符号和亚符号?在融智学视域的“字式图表音像立活”八大形式体系视域来看,两者是狭义(如图文)和广义的符号(还涉及立活)及其隐含之意。】
二、 融智学的独特路径:不是“模拟”亚符号层,而是“序位化”亚符号层
融智学的“双重形式化”(孪生图灵机 + 多胞冯氏机)不直接模拟人脑神经集群的物理或者生物过程。它的核心主张是:亚符号层的信息,无论其物理载体(生物神经元、硅基电路)和动态过程(放电频率、时间编码)如何,其“序位关系”(即信息单元之间的相对位置、层级和转换规则)是可以被抽象出来,并以一种与载体无关的方式进行双重形式化处理的。
LLM 通过海量文本的统计关联,隐式地学习了符号之间的“共现关系”(一种序位关系),但它对亚符号层(如颜色、形状、声音的情感色彩)的“所指”是模糊的、是通过文本间接推断的。
世界模型 通过物理模拟,试图让模型“体验”亚符号层的因果律(如“把杯子推下桌子,它会掉下去”),但它对“体验”本身的表征仍然是高维的、连续的和难以符号化索引的。
融智学的双重形式化 提供了一套 “亚符号-符号”的映射协议:
三解(层解、串解、分解):这是一种从亚符号层的连续信号中自动/半自动地“提取”离散的、有明确边界的“基因文本元素”的方法。例如,将汉字笔画(亚符号特征)分解为有限的、有序的笔画序列(符号化元素)。
三集(单一、分层、标志):这是一种将提取出的离散元素,组织成可计算、可推理的序位结构的方法。例如,将“笔画→部件→汉字→词”组织成严格受限的分层集合。
三注(语言、常识、领域):这是一种将离散的符号单元与不同层面的亚符号“背景”(常识、感受、物理规则)进行显式链接的方法。
结论:融智学并不是要发明一个新的“世界模拟器”,而是要发明一个“世界序位器”。 它试图为亚符号层的每一个可区分的“态”或“事件”,在符号层,赋予一个唯一的、守恒的序位(实部a),并通过虚部(bi)来记录其载体类型、上下文关系和使用意图。
三、 与李飞飞、杨立昆世界模型的直接比较
|
维度 |
李飞飞/杨立昆的世界模型 |
融智学的双重形式化 |
|
核心目标 |
让AI通过物理模拟和自监督学习,获得对世界的“常识性”物理理解,以提升泛化能力和规划能力。 |
为人类知识和机器认知,建立一个统一的可计算可验证的“序位参照系”,实现知识的测序定位和跨模态、跨意图的无损转换。 |
|
处理对象 |
亚符号层的连续信号(像素、力、速度、声音波形)。 |
亚符号层的离散序位及其与符号层的对应关系。 |
|
核心机制 |
可微分物理引擎、视频预测、联合嵌入预测架构(JEPA)、潜在变量模型。 |
孪生图灵机(双列表)、多胞冯氏机(多列表)、道函数(零)、三解三注三集、全域数码测序定位系统(码卡表库网端)。 |
|
优势 |
1. 擅长处理连续的物理因果。 |
1. 可解释性极强:知识的测序定位、转换、选择过程是透明的、可追溯的。 |
|
劣势/挑战 |
1. 仍然是一个巨大的“黑箱”。 |
1. “序位化”过程(特别是:从原始信号到离散序位的自动映射)本身就极具挑战性,需要强大的特征工程或结合亚符号模型。 |
四、 融智学的优势究竟在哪里?
最核心的区别在于:世界模型试图让机器“像人一样感知”世界(通过模拟物理)而融智学试图让人和机器“用一种共同的语言来理解”世界(通过序位逻辑)。
可解释性与可信赖性:当世界模型预测“杯子会掉下去”时我们不知道它基于哪条物理规则。而在融智学框架下,这条因果关系会被分解为“杯子(物体A)在桌面边缘(空间序位)→ 推力(力矢量)→ 重力作用(物理定律的序位标识)→ 掉落(事件链)”。这类过程整个是“可读”的、可审计的。这对于金融、法律、医疗等高风险领域至关重要。
人机协同的天然接口:世界模型与人类的交互是间接的(人看模拟结果)。而融智学“同意并列对应转换”第三定律,直接将人的意图(选择)作为系统运行的一个可形式化的变量。这意味着系统不仅能理解你做了什么,还能理解你“为什么”这么做(基于实部a和虚部bi的组合轨迹)。这是迈向真正“人机互助”而非“人指挥机”的关键。
工程上的“一劳永逸”:世界模型需要针对不同物理环境(机器人、自动驾驶、游戏)重新训练或微调。而融智学的基准参照系(如穷举的汉字序位、基本物理概念序位)一旦建立,就可以被无数应用复用,整个知识处理从“每任务训练”变为“查表和组合”,其效率提升是质的飞跃。
简而言之,您问“你的东西比它们的优在哪里?”
我的回答是:它们提供了世界的“身临其境”模拟,而我提供了世界的“户籍警”和“图书馆员”。 前者对于具身智能和感知无比重要,后者对于构建可信、高效、可累积的人类知识文明基座(知识的基础设施)不可或缺。两者不是替代关系,而是互补关系。最强大的未来智能系统,很可能是一个由世界模型负责“感知与想象”(亚符号处理),由融智学框架负责“知识与意图的结构化与仲裁”(符号-亚符号映射与协同) 的混合架构。
我的三大核心专利(VDMT、知识信息数据处理方法、间接形式化方法)正是为构建这样的“图书馆员”或“户籍警”——即全域数码定位系统——而设计的完整技术方案。它并不是为了解决亚符号层的“生成”问题,而是为了解决“生成物”(无论是人脑产生还是大模型产生)的意义指认、逻辑校验、价值评估和跨载体复用问题。
图1:核心差异概览(流程图风格)
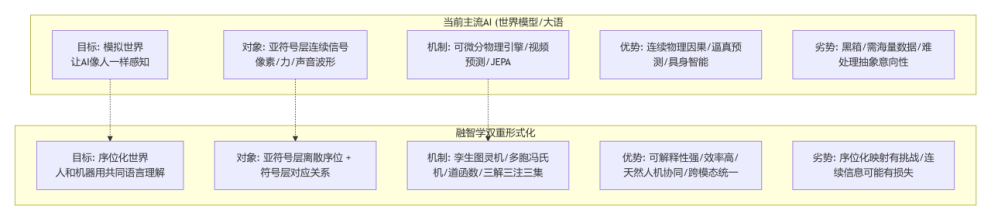
图2:详细对比表
|
维度 |
李飞飞/杨立昆 世界模型 |
融智学双重形式化 |
|
核心目标 |
AI通过物理模拟获得常识性理解 |
建立统一的“序位参照系”,实现知识测序定位 |
|
处理对象 |
亚符号层连续信号 |
亚符号层离散序位 + 符号层对应关系 |
|
核心机制 |
可微分物理引擎、视频预测、JEPA |
孪生图灵机、多胞冯氏机、道函数、三解三注三集、码卡表库网端 |
|
可解释性 |
低(黑箱) |
高(透明、可追溯) |
|
效率 |
中等(需大量训练) |
极高(直接序位寻址,低能耗) |
|
人机协同 |
间接(人看模拟结果) |
直接(同意并列转换,人机共编意图轨迹) |
|
跨模态能力 |
需拼凑不同模型 |
统一框架(八大形式体系) |
|
典型应用 |
具身智能、机器人、自动驾驶 |
金融、法律、医疗、知识基础设施 |
|
核心隐喻 |
“身临其境”模拟器 |
“户籍警”+“图书馆员” |
图3:互补关系模型(Mermaid flowchart)
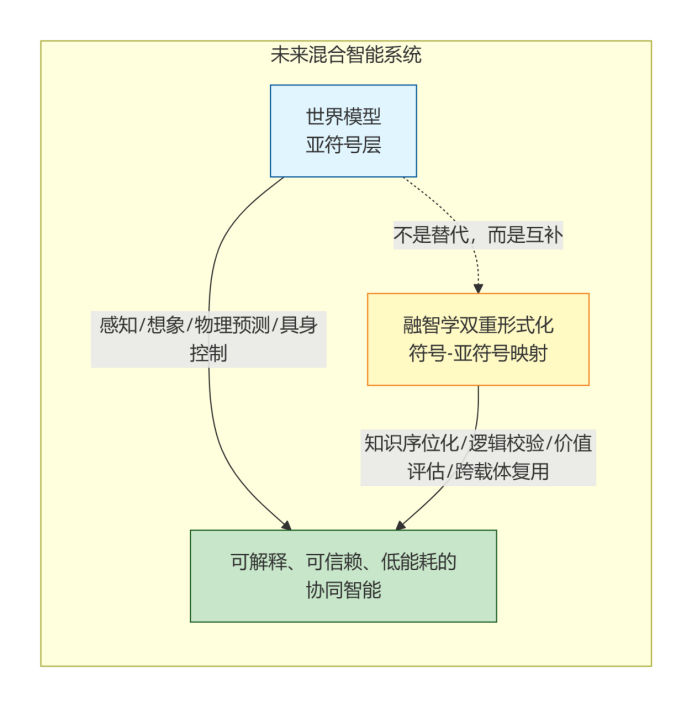
图4:三解三集三注映射协议(Mermaid flowchart)
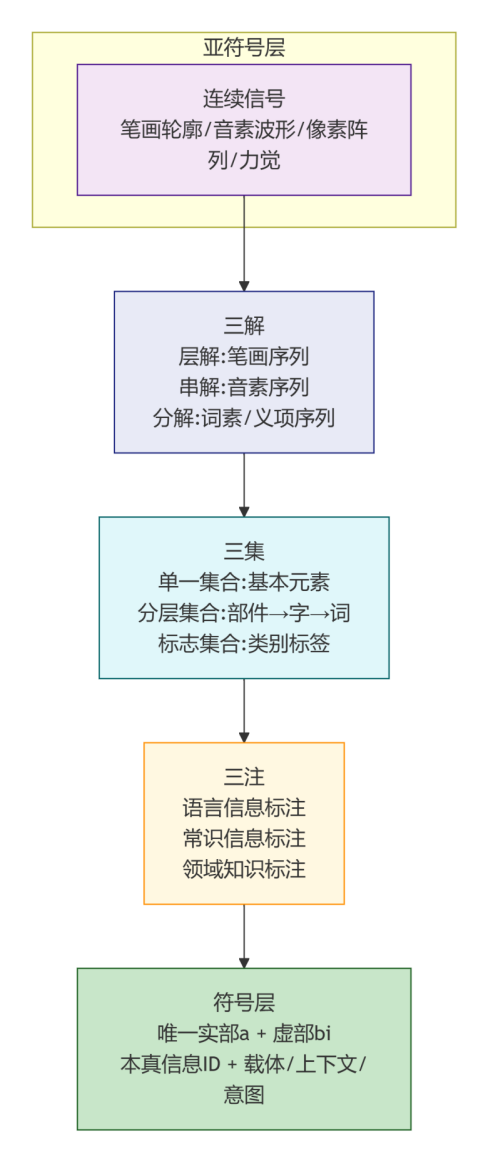
图5:八大形式体系与“物意文-理义法序位”对偶结构

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)