量化:LLM与CV模型的极致压缩艺术
一、引言:为什么量化是AI落地的末端环节
2023年,GPT-4的参数量传闻超过1.8万亿;2024年,Llama 3.1 405B开源;2025年,Qwen3-VL-2B试图在手机上运行多模态推理。模型规模的指数级增长与硬件资源的线性增长之间,横亘着一道名为推理成本的鸿沟。
量化(Quantization)的本质,是用信息论的视角重新审视神经网络:我们真的需要32位浮点数来表示每一个权重吗?一个经过预训练的Transformer,其权重分布往往呈现出强烈的结构性——大部分参数集中在零附近,少数"显著权重"承载着关键语义。量化要做的,就是在最小化信息损失的前提下,用更少的比特编码这些参数。
但这绝非简单的"四舍五入"。从GPTQ的Hessian逆矩阵补偿,到TensorRT的Q/DQ图融合,再到GGUF的"量化的量化"——这条技术谱系背后,是编译器理论、数值分析、硬件架构与机器学习的多学科交叉。
本文将带你穿越这条技术谱系,从大语言模型(LLM)到计算机视觉(CV)模型,再到2026年最新突破,构建一幅完整的量化压缩全景图。
二、量化基础:信息论视角与工程实践
2.1 浮点表示与量化误差
IEEE 754单精度浮点数(FP32)用32比特编码:1位符号、8位指数、23位尾数。对于神经网络权重,这种表示是严重过剩的。量化将其映射到低比特整数空间:

2.2 静态量化 vs 动态量化 vs 训练感知量化
|
维度 |
静态量化 (PTQ) |
动态量化 |
训练感知量化 (QAT) |
|---|---|---|---|
| Scale确定 |
校准数据集预计算 |
运行时动态计算 |
训练时学习 |
| 是否需要训练 |
否 |
否 |
是(微调) |
| 延迟 |
低(无运行时开销) |
高(需统计范围) |
低 |
| 精度 |
中高 |
中 |
最高 |
| 适用场景 |
生产部署 |
快速原型 |
精度敏感场景 |
2.3 量化粒度:从张量到通道到块
|
粒度模式 |
适用对象 |
Scale计算 |
精度 |
硬件友好度 |
|---|---|---|---|---|
| Per-tensor |
激活值 |
单一标量 |
低 |
高 |
| Per-channel |
权重(Conv/FC) |
沿输出通道广播 |
中 |
中 |
| Per-token |
激活(LLM动态) |
逐token计算 |
高 |
低 |
| Block |
权重(INT4/FP4) |
1D块共享 |
中 |
高 |
三、大语言模型(LLM)量化方法谱系
LLM的量化面临一个独特挑战:激活异常值(Activation Outliers)。MIT的研究发现,Transformer中少数通道的激活幅度比正常值大100-300倍,这些"离群值"像钉子户一样占据着动态范围,迫使其他正常值被压缩到极小的表示空间。
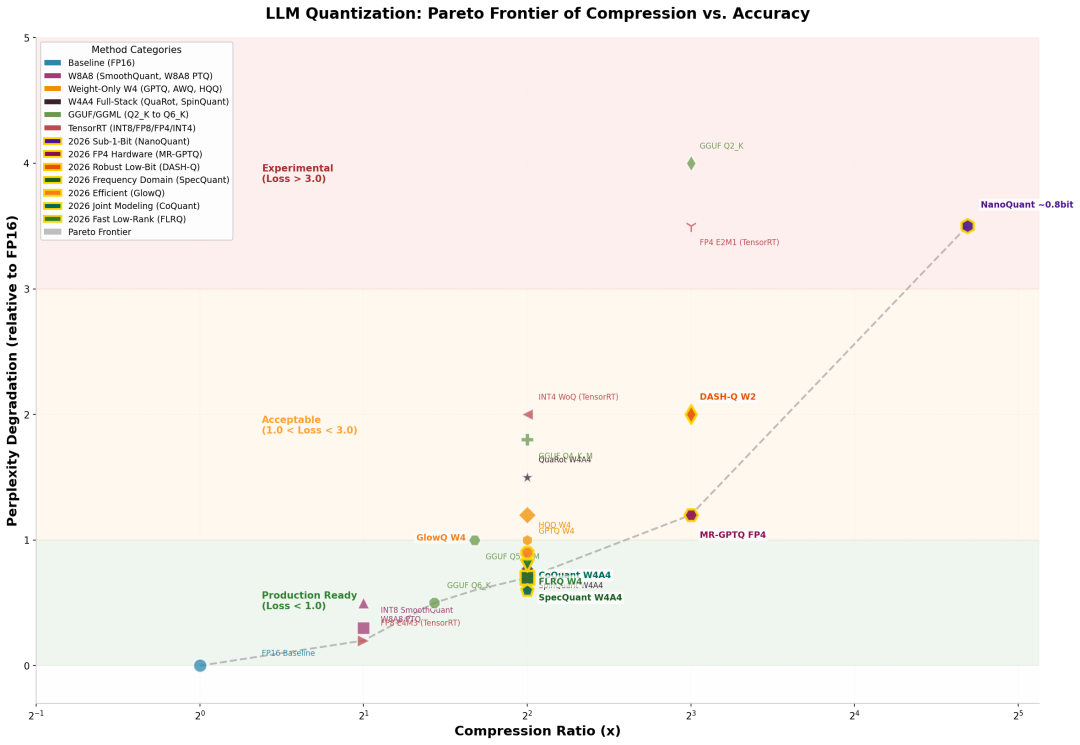
上图展示了不同量化方法在压缩率 vs 精度损失平面上的分布。可以清晰看到三个区域:
-
生产就绪区(Loss < 1.0):FP16、INT8 SmoothQuant、AWQ W4、GGUF Q6_K、SpecQuant W4A4、CoQuant W4A4
-
可接受区(1.0 < Loss < 3.0):GPTQ W4、QuaRot W4A4、AQLM W2、DASH-Q W2、MR-GPTQ FP4
-
实验区(Loss > 3.0):GGUF Q2_K、FP4 E2M1、NanoQuant ~0.8bit
3.1 后训练量化(PTQ):无需重新训练的压缩艺术
GPTQ / GPTQ-M:Hessian逆的误差补偿
GPTQ(Group-wise Precision Tuning Quantization)的核心洞察是:量化误差可以通过二阶信息进行局部补偿。
对于权重矩阵的每一列 w,GPTQ求解:

GPTQ-M(2025改进版)引入最优分组裁剪阈值,结合2:4结构化稀疏性,实现高达5.3×的GPU推理加速。
论文:Frantar et al., GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, ICLR 2023
AWQ:激活感知的"保护费"机制
AWQ(Activation-aware Weight Quantization)发现了一个反直觉的事实:仅0.1%-1%的权重通道对模型性能至关重要,且这些"显著权重"可通过激活分布(而非权重分布)来识别。
AWQ不直接保留这些显著权重(硬件不友好),而是通过逐通道缩放保护它们:

论文:Lin et al., AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration, MLSys 2024(Best Paper Award)
AQLM:加法量化的码本革命
AQLM(Additive Quantization of Language Models)将信息检索领域的加法量化(Additive Quantization)引入LLM压缩。其核心是多码本量化(Multi-Codebook Quantization, MCQ):

论文:Egiazarian et al., Extreme Compression of Large Language Models via Additive Quantization, 2024
HQQ:无校准的"闪电战"
HQQ(Half-Quadratic Quantization)基于半二次拆分(Half-Quadratic Splitting)优化,实现完全无需校准数据的量化。通过将量化问题分解为可高效求解的子问题,HQQ将70B模型的量化时间缩短至几分钟——这对于缺乏代表性数据的场景是救命稻草。
论文:Badri & Shaji, Half-Quadratic Quantization of Large Machine Learning Models, 2023
3.2 权重-激活联合量化:解决异常值难题
SmoothQuant:把烫手山芋扔给权重
SmoothQuant的数学优雅性令人叹服。它通过数学等价变换将激活的量化难度迁移到权重:

论文:Xiao et al., SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models, 2022/2023
QuaRot:Hadamard变换的降维打击
QuaRot发现,Transformer中的异常值具有方向性——它们集中在少数特征维度上。通过随机Hadamard变换(正交旋转),QuaRot将异常值"打散"到所有通道:
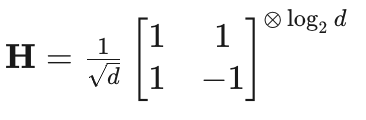
这种旋转保持内积不变(计算不变性),但使激活分布更均匀。QuaRot实现了W4A4KV4(4-bit权重+4-bit激活+4-bit KV Cache),Llama2-7B上perplexity损失仅0.63。
论文:Ashkboos et al., QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs, NeurIPS 2024
SpinQuant:学习最优旋转
SpinQuant在QuaRot基础上更进一步:既然不同随机旋转性能差异可达13个百分点,为什么不学习最优旋转矩阵?通过Cayley SGD在Stiefel流形上优化,SpinQuant的W4A4KV4量化在零样本任务上仅比FP16低2.9分——远超LLM-QAT(差距22分)和SmoothQuant(差距25分)。
论文:Liu et al., SpinQuant: LLM Quantization with Learned Rotations, 2024
3.3 训练感知量化(QAT):精度恢复的最后防线
LLM-QAT / Efficient-QAT
在训练过程中模拟量化前向传播,通过数据无关的知识蒸馏从FP16教师模型指导低比特学生模型。LLM-QAT首次将QAT应用于LLM;Efficient-QAT引入两阶段策略(块级全参数训练 + 端到端量化参数训练)降低计算成本。
3.4 GGUF/GGML格式生态:CPU推理的基石
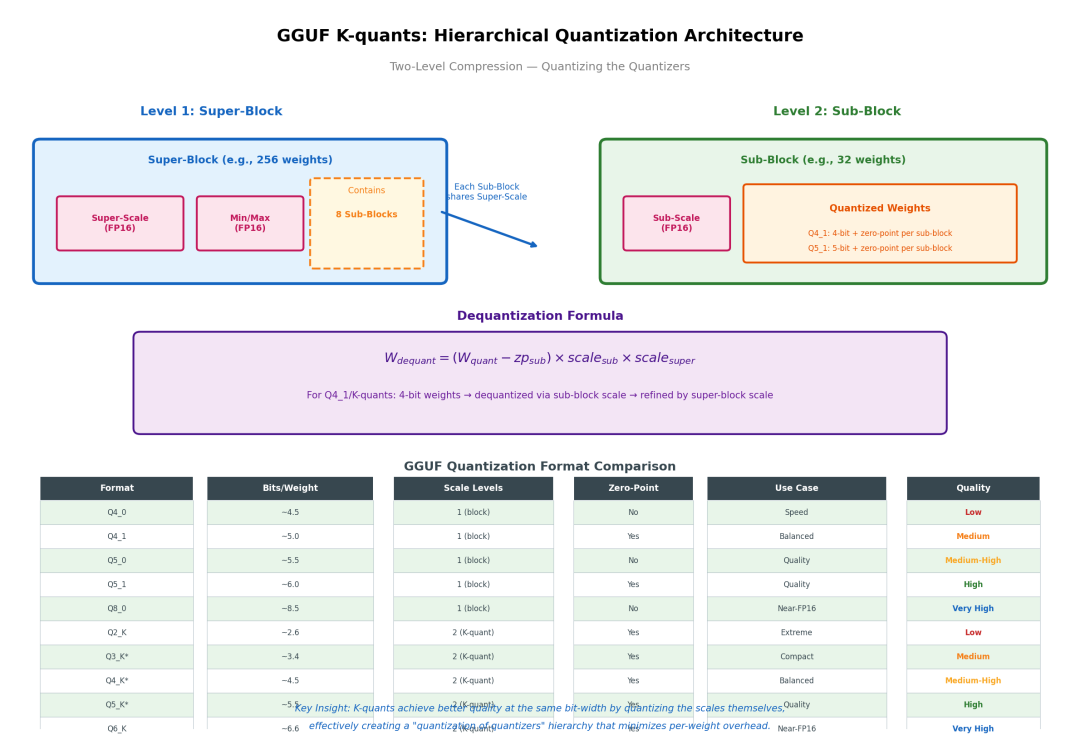
GGUF(GGML Unified Format)是llama.cpp生态的基石。其K-quants采用两级层次化量化,堪称"量化中的量化":
Level 1 - Super-Block(如256权重):
-
存储Super-Scale(FP16)和Min/Max(FP16)
-
包含8个Sub-Block
Level 2 - Sub-Block(如32权重):
-
存储Sub-Scale(FP16)
-
权重以4-bit或5-bit存储,带zero-point
反量化公式:
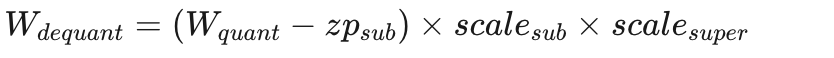
这种设计的关键洞察是:scale本身也可以被量化。通过两级scale,K-quants在相同位宽下比标准Q4_0/Q4_1获得显著更好的质量——因为super-block级别的scale修正了sub-block之间的系统性偏差。
|
格式 |
有效位宽 |
质量评级 |
适用场景 |
|---|---|---|---|
|
Q2_K |
~2.6 bit |
低 |
极端压缩,实验性 |
|
Q4_K_M |
~4.5 bit |
中高 |
平衡速度与质量 |
|
Q5_K_M |
~5.5 bit |
高 |
高质量本地推理 |
|
Q6_K |
~6.6 bit |
极高 |
接近FP16体验 |
四、计算机视觉(CV)模型量化与部署框架
CV模型的量化生态与LLM有所不同,更依赖硬件厂商工具链和传统PTQ/QAT流程。
4.1 TensorRT:显式量化的编译器艺术
TensorRT是NVIDIA GPU上CV模型量化的事实标准。其量化架构围绕显式量化(Explicit Quantization)构建,通过ONNX的Q/DQ节点实现精确控制。
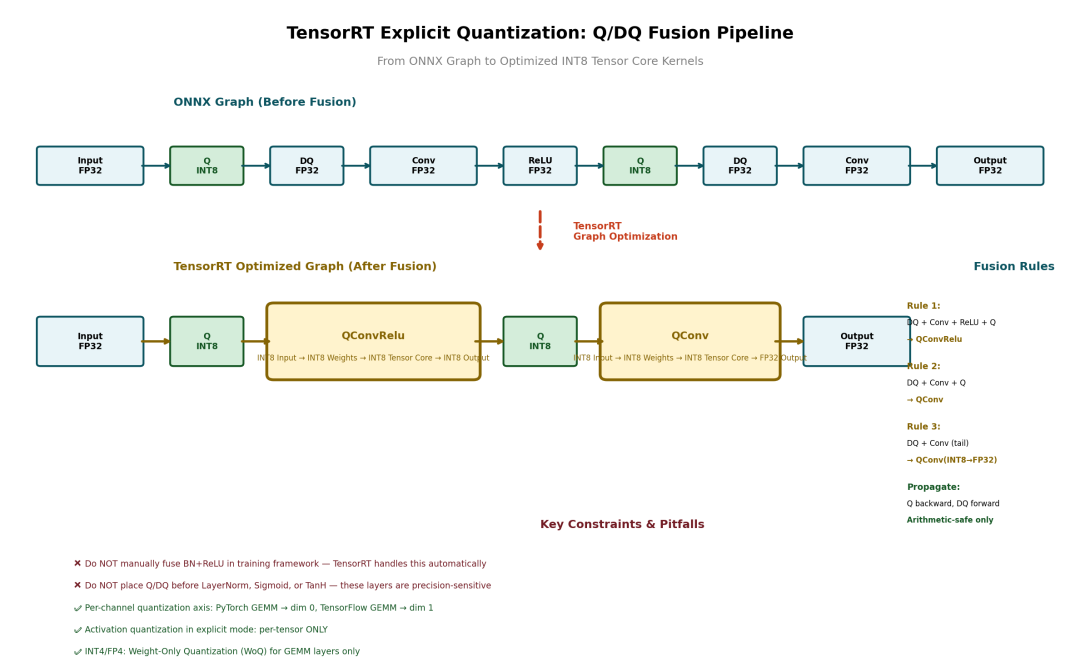
Q/DQ Layer融合规则(核心优化)
TensorRT通过Q/DQ传播实现算子融合:
传播方向:
-
Q节点向后传播:尽早将激活量化到INT8
-
DQ节点向前传播:尽量延迟反量化到FP32
-
约束:仅执行保持算术正确性的变换
典型融合链:
原始图: Input(FP32) → Q → DQ → Conv → ReLU → Q → DQ → Conv → ... ↓ TensorRT优化后 ↓优化图: Input(FP32) → Q → [QConvRelu(INT8→INT8)] → Q → [QConv(INT8→INT8)] → ...
融合规则详解:
|
融合模式 |
输入精度 |
权重精度 |
计算精度 |
输出精度 |
适用场景 |
|---|---|---|---|---|---|
| DQ + Conv + ReLU + Q → QConvRelu |
INT8 |
INT8 |
INT8 Tensor Core |
INT8 |
标准卷积块 |
| DQ + Conv + Q → QConv |
INT8 |
INT8 |
INT8 Tensor Core |
INT8 |
无ReLU的中间层 |
| DQ + Conv → QConv (INT8→FP32) |
INT8 |
INT8 |
INT8 Tensor Core |
FP32 |
网络末尾输出层 |
| DQ + MatMul + Q → QMatMul |
INT8 |
INT8 |
INT8 |
INT8 |
Transformer注意力 |
重要注意事项:
-
TensorRT自动处理BN+ReLU融合,官方建议不要在训练框架中手动模拟此融合
-
精度敏感层避免量化:LayerNorm、Sigmoid、TanH前不插入Q/DQ;GeLU、Softmax、ElementWise可插入Q/DQ
-
PyTorch导出的GEMM权重布局为(K,C)且
transB=1,TensorRT会转置,per-channel量化轴为维度0;TensorFlow导出权重为(C,K),量化轴为维度1
校准算法数学原理
TensorRT提供三种校准策略:
(1)MinMax校准
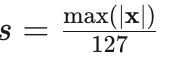
特点:
-
特点:简单快速,但对异常值敏感
-
适用:权重校准推荐
(2)熵校准(Entropy/Entropy2)——默认算法
目标:寻找阈值 T 最小化KL散度
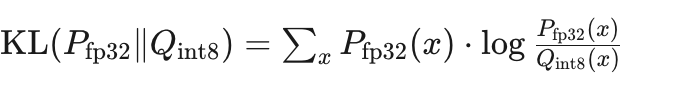
(3)百分位校准
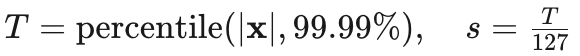
-
特点:排除极端异常值,适合激活值的长尾分布
多精度支持矩阵(TensorRT 10+)
|
精度格式 |
位宽 |
有效范围 |
量化模式 |
硬件要求 |
关键特性 |
|---|---|---|---|---|---|
| INT8 |
8-bit |
[-128,127] |
显式/隐式 |
Volta+ |
最成熟,支持PTQ校准 |
| FP8 E4M3 |
8-bit |
[-448,448] |
仅显式 |
Hopper/Ada+ |
4指数3尾数,不能与INT8混用 |
| INT4 |
4-bit |
[-8,7] |
仅显式 |
Ampere+ |
仅WoQ
,2元素/字节打包 |
| FP4 E2M1 |
4-bit |
[-6,6] |
仅显式 |
Blackwell |
2指数1尾数,推荐动态量化 |
TensorRT Model Optimizer:统一优化库
NVIDIA推出的TensorRT Model Optimizer(nvidia-modelopt)是面向LLM、CV模型的统一优化工具(TensorRT和TensorRT-LLM):
|
格式 |
描述 |
适用场景 |
|---|---|---|
| Per-Tensor FP8 |
标准全模型FP8量化 |
通用推理 |
| FP8 Block-wise WoQ |
2D块级权重量化 |
内存带宽受限 |
| FP8 Per-Channel + Per-Token |
逐通道权重+动态逐token激活 |
LLM高吞吐 |
| NVFP4 |
默认FP4量化(Blackwell) |
极致压缩 |
| INT8 SmoothQuant |
W8A8 with SmoothQuant |
通用LLM |
| WA416 (INT4 WoQ) |
4-bit权重+FP16激活 with AWQ |
边缘部署 |
| W4A8 |
INT4权重+FP8激活 |
平衡压缩与速度 |
4.2 ONNX Runtime与跨平台方案
|
工具 |
优势 |
适用硬件 |
|---|---|---|
| ONNX Runtime静态量化 |
跨平台,静态/动态量化 |
CPU/GPU/ARM |
| ONNX Runtime动态量化 |
无需校准数据 |
CPU |
| OpenVINO |
Intel硬件深度优化 |
Intel CPU/GPU/FPGA |
| PyTorch FX Graph Mode |
与PyTorch生态无缝集成 |
CPU/GPU |
4.3 移动端量化框架:TFLite、NCNN与生态
TensorFlow Lite:Google的移动量化标准
TensorFlow Lite是Google官方的移动端推理框架,提供完整的量化工具链:
PTQ模式:
-
动态范围量化:仅权重转INT8,激活仍用FP32计算
-
全整数量化:权重和激活均转INT8,需校准数据集确定scale和zero-point
-
FP16量化:权重转FP16,精度损失小
QAT模式:
import tensorflow_model_optimization as tfmot# 在模型中插入FakeQuantize层quantize_model = tfmot.quantization.keras.quantize_modelq_aware_model = quantize_model(model)# 训练时模拟量化效果,使用STE传播梯度q_aware_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')q_aware_model.fit(x_train, y_train, epochs=5)关键特性:
-
支持Edge TPU硬件加速
-
与Android/iOS原生集成
-
模型大小减少约75%
NCNN:腾讯的高性能移动端推理引擎
NCNN是腾讯开源的无第三方依赖的移动端推理框架,专为ARM CPU优化。
量化流程:
-
模型优化:
ncnnoptimize进行层融合和内存优化 -
生成校准表:
ncnn2table使用KL散度或ACIQ算法 -
量化模型:
ncnn2int8将FP32权重转为INT8
校准命令:
./ncnn2table mobilenet-opt.param mobilenet-opt.bin imagelist.txt mobilenet.table \mean=[104,117,123]norm=[0.017,0.017,0.017]shape=[224,224,3]pixel=BGR thread=8method=kl关键特性:
-
支持混合精度推理:在校准表中注释掉某层的scale即可保持FP32
-
量化层:Conv、DepthwiseConv、InnerProduct、RNN、LSTM、GRU、Embed、Gemm、MultiHeadAttention、SDPA
-
自动检测INT8权重并使用INT8执行路径
校准算法:
-
KL散度:最小化原始分布与量化分布的KL散度(推荐,精度更好)
-
ACIQ(Analytical Clipping for Integer Quantization):基于分析的量化方法
最佳实践:
-
校准数据集应代表实际场景,建议≥5000张图像
-
预处理参数必须与训练时一致
-
先尝试全INT8量化,如精度下降明显再考虑混合精度
其他边缘框架
|
框架 |
厂商 |
特点 |
|---|---|---|
| MNN |
阿里巴巴 |
支持ARM CPU/GPU、Vulkan、OpenCL,INT8/FP16混合精度 |
| MACE |
小米 |
针对骁龙DSP优化,支持Hexagon NN加速 |
| TNN |
腾讯 |
与NCNN互补,专注ARM GPU和NPU加速 |
| Paddle Lite |
百度 |
与飞桨训练框架深度集成,支持华为NPU |
五、2026年量化前沿突破
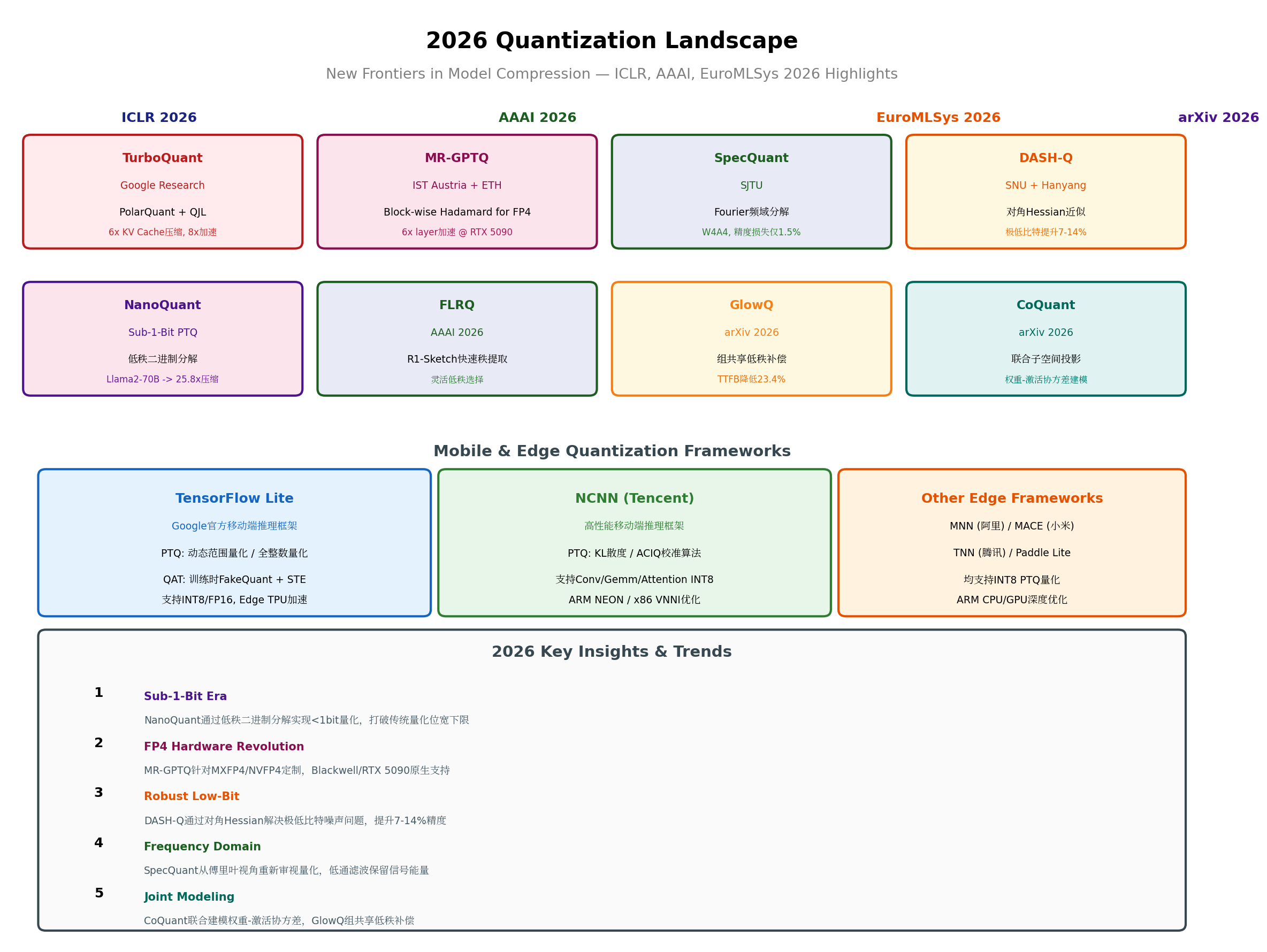
2026年,量化领域迎来了爆发式创新。ICLR、AAAI、EuroMLSys等顶级会议上的新工作,正在重新定义压缩的极限。
5.1 TurboQuant:极坐标量化的KV Cache革命
TurboQuant(ICLR 2026, Google Research)代表了KV Cache压缩的范式转变。它构建了一个数据无关的量化流水线,结合两个关键技术:
PolarQuant(AISTATS 2026):将向量从笛卡尔坐标转换到极坐标系,利用角度信息的低维特性进行压缩。
QJL(Quantized Johnson-Lindenstrauss, AAAI 2025):通过随机投影将高维向量映射到低维空间,同时保持内积近似。

争议:TurboQuant的学术原创性受到质疑。批评者指出其核心思想与早期的向量量化工作存在重叠,且QJL的随机投影理论在LLM长上下文场景下的收敛性证明不够严谨。
5.2 NanoQuant:突破1-Bit下限的Sub-1-Bit量化
NanoQuant(arXiv 2026)是首个支持低于1 bit的PTQ方法,将Llama2-70B压缩至25.8倍——这意味着平均每个权重仅占约0.55 bit。
核心创新:低秩二进制分解

三步优化流程:
-
误差传播缓解:调整当前块的全精度权重,最小化前面块量化引入的误差
-
低秩二进制初始化:通过ADMM和SVID初始化二进制因子
-
因子化组件精调:使用STE联合优化连续潜在代理和缩放向量
实验结果:在0.55 bit/weight下,NanoQuant在Llama-2-70B上的WikiText-2 perplexity为9.82,显著优于同压缩比的STBLLM。
5.3 MR-GPTQ:为FP4硬件量身定制的量化算法
MR-GPTQ(Micro-Rotated-GPTQ, ICLR 2026, IST Austria + ETH Zürich)是首个针对微缩放FP4格式(MXFP4和NVFP4)专门优化的PTQ算法。
FP4的挑战:
-
NVFP4:小组大小会证明性地抵消传统异常值缓解技术
-
MXFP4:2的幂次scale量化因高诱导误差严重降低精度
MR-GPTQ的解决方案:
-
块级Hadamard变换:在量化前旋转权重矩阵基,使异常值分布到所有通道
-
格式特定优化:针对FP4的E2M1表示定制量化网格
-
融合Kernel:推理时将逆变换融合到权重中,在线计算激活的旋转,开销可忽略
性能:
-
NVIDIA B200:层级加速3.6×,端到端2.2×
-
RTX 5090:层级加速6×,端到端4×
-
MMLU分数与AWQ INT4相当,MXFP4精度接近NVFP4
意义:MR-GPTQ证明FP4不是INT4的自动升级,但通过格式专用方法可以解锁全新的精度-性能权衡前沿。
5.4 DASH-Q:极低比特的稳健性突破
DASH-Q(EuroMLSys 2026, Seoul National University + Hanyang University)解决了Hessian-based PTQ方法在低位宽时的核心问题:采样噪声。
问题诊断:GPTQ等方法的非对角Hessian项对校准数据的批次间方差高度敏感,导致低位宽时的交叉通道补偿过拟合。
DASH-Q的解决方案:
-
对角Hessian近似:丢弃噪声敏感的非对角依赖,保留稳定的特征重要性
-
迭代加权最小二乘:将对角Hessian转化为独立的加权最小二乘问题,每个问题有闭式解
实验结果:
-
在Llama-3.1-8B的2-bit量化下,DASH-Q达到56.52%平均准确率,比OWQ高14.01%,比GPTQ高1.59×
-
在Qwen3-14B上,2-bit时DASH-Q与QuaRot几乎持平
-
平均零样本准确率提升7.01%,最高14.01%
5.5 SpecQuant:频域视角的量化新范式
SpecQuant(AAAI 2026, Shanghai Jiao Tong University)从傅里叶频率域重新审视LLM量化,提出了两阶段框架:
Stage 1 - 激活平滑:通过基于缩放的平滑将激活异常值迁移到权重域。
Stage 2 - 通道级低频频谱截断:对每个通道的平滑权重向量进行FFT变换,保留低频分量,抑制高频噪声。
核心洞察:权重在傅里叶域中表现出强烈的低频偏置——大部分能量集中在低频分量,这些分量可以用更高精度保留,而高频残差用低精度量化。
量化策略:
-
低频分量:16-bit高精度
-
高频残差:4-bit低精度
结果:在LLaMA-3 8B上实现W4A4量化,零样本准确率差距仅1.5%,推理速度提升2倍,内存降低3倍。
5.6 GlowQ:选择性低秩补偿的高效实现
GlowQ(arXiv 2026)解决了低秩校正方法的效率问题。
现有问题:LQER、QERA等方法为每一层插入误差校正模块,增加延迟和内存开销。
GlowQ方案:
-
组共享右因子:为输入共享组缓存单个共享右因子,跨模块复用
-
选择性应用:GlowQ-S仅在对精度提升最大的层/组应用校正
性能:
-
GlowQ:TTFB降低5.6%,吞吐量提升9.6%,WikiText-2 perplexity降低0.17%
-
GlowQ-S:TTFB降低23.4%,吞吐量提升37.4%,精度损失仅0.2%
5.7 CoQuant:联合子空间投影
CoQuant(arXiv 2026)指出现有混合精度方法仅依赖激活统计构建子空间,忽略了线性操作中输出扰动由权重和激活量化噪声联合驱动的本质。
理论贡献:通过建模期望输出误差,CoQuant推导出闭式加权PCA解,平衡权重和激活的协方差以选择最优高精度子空间。
实验:在Llama-3.2和Qwen2.5上,CoQuant在WikiText perplexity和零样本推理准确率上均优于强PTQ基线。
5.8 FLRQ:灵活低秩选择的快速算法
FLRQ(AAAI 2026)解决了低秩PTQ中秩选择的计算瓶颈。
核心组件:
-
R1-FLR:使用R1-Sketch(高斯投影)实现快速低秩近似,支持逐层异常值感知的秩提取
-
BLC(Best Low-rank Approximation under Clipping):通过迭代方法最小化缩放和裁剪策略下的低秩量化误差
FLRQ在量化质量和算法效率上均达到SOTA。
六、方法对比与选型决策
量化决策树
Model Type?
/ \
LLM/VLM CV/ViT
| |
Deployment Env? Target Hardware?
/ \ / \
CPU/Edge GPU/Cloud NVIDIA Cross-Platform
| | | |
GGUF TensorRT TensorRT ONNX Runtime
(Q4_K_M) -LLM (INT8/FP8) (Static/Dynamic)
llama.cpp (FP8/ PTQ+Calib OpenVINO/TFLite
ollama INT4/FP4) ARM/Intel/AMD
vLLM/
Triton
| |
Precision Req? Quantization
/ \ Strategy?
High(Loss<0.5) Acceptable / \
| | PTQ(Fast) QAT(Best)
AWQ/GPTQ QuaRot/HQQ | |
(W4/W8) (W4A4/W4A8) Entropy FakeQuant
SmoothQuant AQLM W2-W3 Calibration + STE
SpinQuant Extreme (MinMax/ Fine-tune
compression Percentile) recovery
Batch≥16 Export ONNX
Q/DQ6.1 大模型量化方法对比
|
方法 |
类型 |
位宽 |
校准数据 |
核心机制 |
适用场景 |
代表论文 |
|---|---|---|---|---|---|---|
| GPTQ |
PTQ |
W3-4 |
需要 |
Hessian逆补偿误差 |
大模型权重压缩 |
ICLR 2023 |
| AWQ |
PTQ |
W4 |
少量(16seq) |
激活感知逐通道缩放 |
边缘部署/多模态 |
MLSys 2024 |
| AQLM |
PTQ |
W2-3 |
需要 |
加法量化+码本学习 |
极端压缩 |
2024 |
| HQQ |
PTQ |
W2-8 |
无需 |
半二次拆分优化 |
快速无校准量化 |
2023 |
| SmoothQuant |
PTQ |
W8A8 |
需要 |
异常值平滑迁移 |
高吞吐推理 |
2022/2023 |
| QuaRot |
PTQ |
W4A4KV4 |
需要 |
Hadamard旋转变换 |
全栈4-bit推理 |
NeurIPS 2024 |
| SpinQuant |
PTQ |
W4A4KV4 |
需要 |
学习最优旋转矩阵 |
高精度低比特 |
2024 |
| NanoQuant |
PTQ |
<1bit |
需要 |
低秩二进制分解 |
极致压缩 |
arXiv 2026 |
| MR-GPTQ |
PTQ |
FP4 |
需要 |
块级Hadamard for FP4 |
FP4硬件优化 |
ICLR 2026 |
| DASH-Q |
PTQ |
W2 |
需要 |
对角Hessian近似 |
极低比特稳健性 |
EuroMLSys 2026 |
| SpecQuant |
PTQ |
W4A4 |
需要 |
傅里叶频域分解 |
频域视角量化 |
AAAI 2026 |
| GlowQ |
PTQ |
W4 |
需要 |
组共享低秩补偿 |
效率优先场景 |
arXiv 2026 |
| CoQuant |
PTQ |
W4A4 |
需要 |
联合子空间投影 |
协方差建模 |
arXiv 2026 |
| FLRQ |
PTQ |
W4 |
需要 |
R1-Sketch快速秩提取 |
灵活低秩选择 |
AAAI 2026 |
| GGUF/GGML |
格式生态 |
W2-8 |
量化时决定 |
分块均匀/K-quant |
CPU本地推理 |
llama.cpp |
| EETQ |
PTQ |
W8 |
需要 |
快速权重量化 |
快速部署 |
NVIDIA |
6.2 CV模型量化方法对比
|
方法/工具 |
量化类型 |
位宽支持 |
校准算法 |
硬件支持 |
适用模型 |
核心优势 |
|---|---|---|---|---|---|---|
| TensorRT PTQ |
PTQ(校准) |
INT8/FP8/FP16/INT4/FP4 |
Entropy/MinMax/Percentile |
NVIDIA GPU |
CNN/Transformer/LLM |
极致性能,层融合,Tensor Core |
| TensorRT QAT |
QAT(训练) |
INT8/FP8/FP16 |
Fake Quantization(STE) |
NVIDIA GPU |
CNN/Transformer/LLM |
精度恢复,训练感知 |
| ONNX Runtime静态量化 |
PTQ |
INT8 |
MinMax/Entropy/Percentile |
CPU/GPU/ARM |
CNN/ViT |
跨平台,易部署 |
| ONNX Runtime动态量化 |
动态PTQ |
INT8 |
运行时动态计算 |
CPU |
CNN/ViT |
无需校准数据 |
| TensorFlow Lite |
PTQ/QAT |
INT8/FP16 |
代表性数据集 |
CPU/ARM/Edge TPU |
MobileNet/EfficientNet |
移动端优化,量化-aware训练 |
| NCNN |
PTQ |
INT8 |
KL散度/ACIQ |
ARM/x86 |
CNN/ViT |
高性能移动端,无第三方依赖 |
| OpenVINO |
PTQ |
INT8/FP16 |
Default/AccuracyAware |
Intel CPU/GPU/FPGA |
ResNet/YOLO |
Intel硬件深度优化 |
| PyTorch FX Graph Mode |
PTQ/QAT |
INT8/FP16 |
MinMax/Entropy |
CPU/GPU |
ResNet/ViT |
与PyTorch生态无缝集成 |
6.3 选型决策树
LLM场景:
CPU/边缘部署 → GGUF/GGML(K-quants)
-
Q4_K_M:平衡速度与质量
-
Q5_K_M:高质量本地推理
-
llama.cpp / ollama生态
GPU/云端部署 → TensorRT-LLM / vLLM
-
FP8(Hopper/Ada+):最佳性能
-
INT8 SmoothQuant:通用高吞吐
-
INT4 WoQ:内存受限场景
精度要求极高 → AWQ / SpinQuant / CoQuant
-
AWQ W4:边缘部署首选
-
SpinQuant W4A4KV4:学习式旋转,精度损失<3分
-
CoQuant W4A4:联合协方差建模
快速无校准 → HQQ
-
70B模型几分钟完成量化
-
适合缺乏代表性数据的场景
极致压缩 → NanoQuant / AQLM
-
NanoQuant <1bit:25.8×压缩
-
AQLM W2-W3:码本学习
CV场景:
NVIDIA GPU → TensorRT
-
显式Q/DQ,PTQ+熵校准
-
INT8/FP8/FP4多精度支持
-
层融合+Tensor Core极致优化
跨平台 → ONNX Runtime
-
静态量化(MinMax/Entropy/Percentile)
-
动态量化(无需校准)
-
OpenVINO / TFLite作为替代
移动端 → TFLite / NCNN
-
TFLite:Google生态,Edge TPU加速
-
NCNN:腾讯开源,ARM NEON优化,无第三方依赖
精度优先 → QAT
-
PyTorch/TensorFlow FakeQuant + STE
-
微调恢复精度
-
导出ONNX Q/DQ → TensorRT免校准
七、未来趋势与总结
7.1 2026年五大趋势
-
位宽下限被击穿:NanoQuant证明通过低秩分解,有效位宽可以低于1 bit
-
硬件-算法协同设计:MR-GPTQ为FP4定制,TurboQuant为KV Cache定制——通用算法让位于专用优化
-
噪声vs信号的哲学:DASH-Q通过对角Hessian丢弃噪声,SpecQuant通过频域滤波保留信号——知道丢弃什么比知道保留什么更重要
-
效率与精度并重:GlowQ和FLRQ证明,量化不仅是精度问题,更是系统效率问题(TTFB、吞吐量)
-
移动端生态成熟:TFLite和NCNN等框架的量化工具链已足够成熟,算法创新正在快速下沉到工程实践
7.2 量化背后的核心追问:什么才是重要的
量化不仅仅是数值压缩技术,更是一种资源约束下的优化哲学。它迫使我们回答一个根本问题:在有限的信息带宽下,什么是最重要的?
GPTQ用Hessian逆告诉我们:误差的传播是有结构的;AWQ用激活分布告诉我们:显著性不在权重本身,而在权重与数据的交互;TensorRT用Q/DQ融合告诉我们:硬件与算法的协同设计才是终极答案;GGUF的K-quants告诉我们:量化可以递归,压缩的极限是信息的本质。
当FP4的4-bit权重在Blackwell GPU上飞驰,当Q2_K的2.6-bit模型在笔记本CPU上运行Llama-3,当NanoQuant的<1-bit权重让70B模型塞进8GB显存——我们正在见证一个"大模型小设备"的时代真正到来。
而站在这个前沿上的工程师,需要的不仅是对算法的理解,更是对硬件、编译器、数值分析和信息论的综合洞察。
这就是量化的的极致压缩艺术。
参考资源
经典方法
|
方法 |
论文 |
年份 |
会议 |
|---|---|---|---|
|
GPTQ |
Frantar et al., GPTQ: Accurate Post-Training Quantization |
2023 |
ICLR |
|
AWQ |
Lin et al., Activation-aware Weight Quantization |
2024 |
MLSys (Best Paper) |
|
AQLM |
Egiazarian et al., Extreme Compression via Additive Quantization |
2024 |
arXiv |
|
HQQ |
Badri & Shaji, Half-Quadratic Quantization |
2023 |
技术博客 |
|
SmoothQuant |
Xiao et al., SmoothQuant |
2022/2023 |
MIT/微软 |
|
QuaRot |
Ashkboos et al., Outlier-Free 4-Bit Inference in Rotated LLMs |
2024 |
NeurIPS |
|
SpinQuant |
Liu et al., SpinQuant: LLM Quantization with Learned Rotations |
2024 |
arXiv |
|
GGUF |
llama.cpp社区规范 |
2023 |
开源项目 |
2026年新方法
|
方法 |
论文/来源 |
会议/年份 |
核心贡献 |
|---|---|---|---|
|
TurboQuant |
Google Research |
ICLR 2026 |
PolarQuant + QJL,6× KV Cache压缩 |
|
MR-GPTQ |
IST Austria + ETH |
ICLR 2026 |
FP4硬件定制,6×层级加速 |
|
NanoQuant |
arXiv 2602.06694 |
arXiv 2026 |
Sub-1-Bit PTQ,25.8×压缩 |
|
DASH-Q |
SNU + Hanyang |
EuroMLSys 2026 |
对角Hessian,极低比特稳健性 |
|
SpecQuant |
SJTU |
AAAI 2026 |
傅里叶频域分解,W4A4精度损失1.5% |
|
GlowQ |
arXiv 2603.25385 |
arXiv 2026 |
组共享低秩补偿,TTFB降低23.4% |
|
CoQuant |
arXiv 2604.26378 |
arXiv 2026 |
联合子空间投影 |
|
FLRQ |
AAAI 2026 |
AAAI 2026 |
R1-Sketch快速秩提取 |
工程框架
|
框架 |
厂商 |
文档/来源 |
|---|---|---|
|
TensorRT |
NVIDIA |
NVIDIA Developer Guide |
|
TensorFlow Lite |
|
官方文档 |
|
NCNN |
腾讯 |
GitHub Wiki |
|
ONNX Runtime |
微软 |
官方文档 |
创作不易,禁止抄袭,转载请附上原文链接及标题

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)