GPT-5.5和Claude 4.7双双翻车:人类100%,AI不到1%
摘要: ARC Prize官方最新报告显示,GPT-5.5与Claude Opus 4.7在ARC-AGI-3基准测试中得分分别仅为0.43%和0.18%,而人类可以100%完成这些任务。这一令人震惊的结果揭示了当前顶级AI模型在抽象推理和自适应能力上的根本性缺陷。本文深度解析三大核心失败模式,分析OpenAI与Anthropic技术路线的差异,并探讨这对我们理解AGI的真正含义意味着什么。
关键词: ARC Prize | GPT-5.5 | Claude Opus 4.7 | AGI | 抽象推理
当我们习惯了AI在各路基准测试上"屠榜"的消息,ARC Prize最新发布的一份分析报告,像一盆冷水浇在了整个行业头上。
2026年5月1日,ARC Prize官方发布了针对OpenAI GPT-5.5和Anthropic Claude Opus 4.7的专项分析报告。结果显示:在ARC-AGI-3基准测试中,这两款被业界寄予厚望的顶级模型,得分分别只有0.43%和0.18%。
而人类,在第一次接触这些任务时,能够100%解决。
这意味着什么?意味着那些声称"AGI即将到来"的论调,在这份报告面前,显得如此苍白。

ARC-AGI-3:智能的"真伪试金石"
要理解这份报告的冲击,我们需要先了解什么是ARC-AGI-3。
ARC-AGI由Keras之父François Chollet创立,被公认为目前最接近"人类智能本质"的测试。前两代版本考验的是静态模式识别,而2026年3月发布的第三代,则将难度提升到了全新维度——交互式推理。
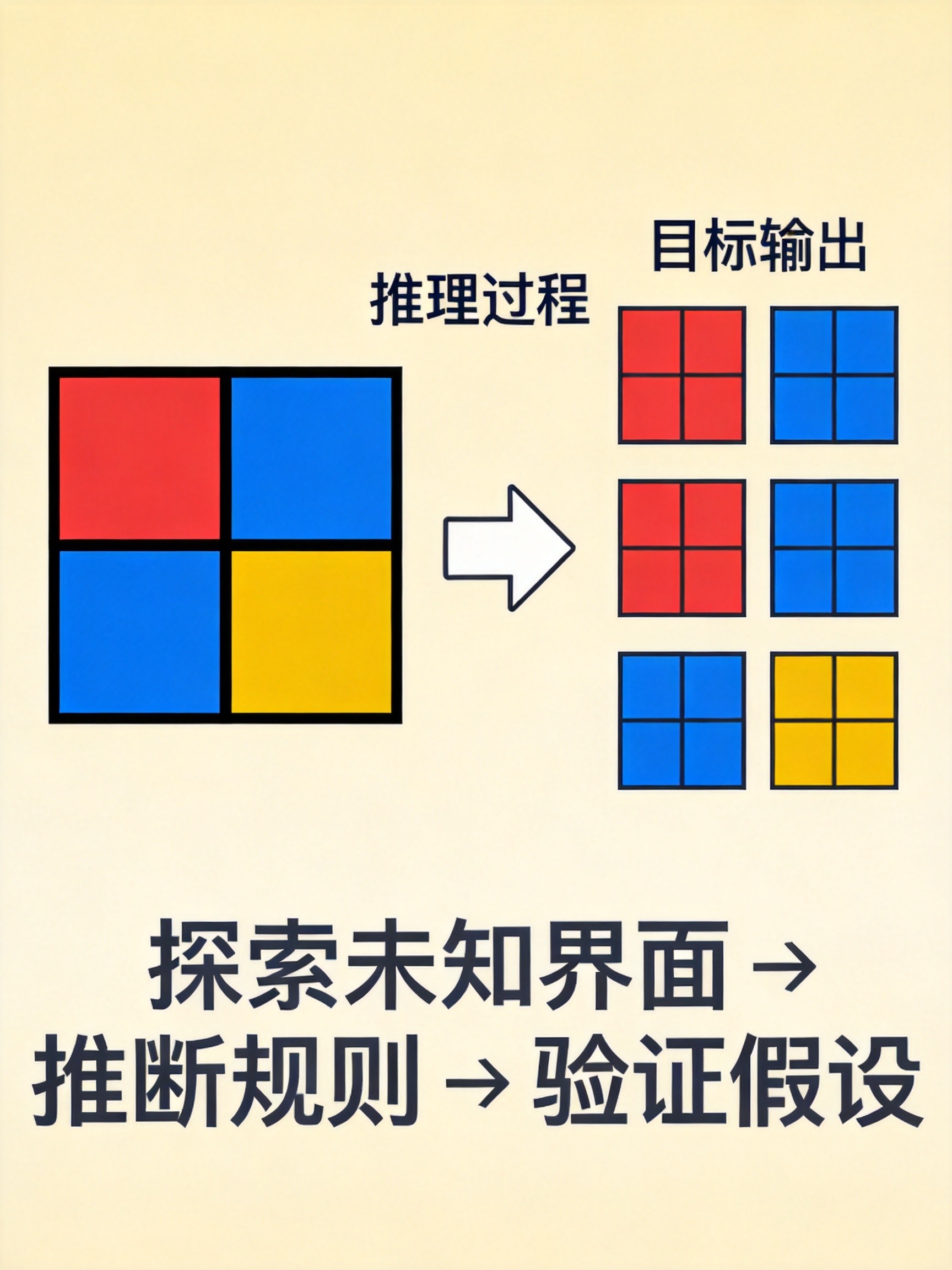
ARC-AGI-3由135个全新环境组成,每个环境都由人类手工设计,用来测试AI模型面对未知的能力。进入环境后,测试者(无论人类还是AI)不会获得任何玩法说明,必须:
-
探索未知界面——面对一个从未见过的操作界面
-
从稀疏反馈中推断规则——通过少量尝试理解因果关系
-
提出并验证假设——形成理论并检验其正确性
-
从错误中恢复——发现错了要能回头
-
将经验迁移到下一关——学到的能力要能泛化
每个环境的构建都刻意避开了AI模型通常依赖的"文化知识"和"模式记忆",只保留抽象推理能力本身。
ARC Prize团队的大量人类测试表明:人类在没有先验训练、没有说明的情况下,第一次接触就能100%解决这些难题。而当前所有前沿AI推理模型,得分都低于1%。
这不是简单的"AI不擅长某类问题",而是揭示了一个根本性的差距:AI能处理见过的任务,而人类能处理从未见过的任务。
三大失败模式深度解析
比起0.43%和0.18%这个冰冷的数据,ARC Prize团队公布的详细分析报告更值得关注。他们对160组完整运行轨迹进行了逐帧分析——包括模型的每一步操作和推理过程,最终总结出了导致模型"崩溃"的三大核心失败模式。

失败模式一:看得见细节,看不见全局
"真实的局部反馈,虚假的世界模型"
这是最常见也最致命的失败模式。模型能够理解"哪一步动作产生了变化"(局部反馈),但无法将这种因果效应转化为一套通用的全局规则。
以Claude Opus 4.7运行任务"cd82"为例:
-
第4步:它意识到执行ACTION3可以旋转容器 ✓
-
第6步:它观察到执行ACTION5可以倾倒或蘸取油漆 ✓
-
但之后:它始终无法将这些碎片化的认知转化为完整策略 ✗
它需要推理出的是:"先调整桶的方向,然后再蘸取油漆,以还原左上角的目标图像。"这种跨越多步骤的全局规划,正是当前模型的软肋。
或者在任务"cn04"中,Opus 4.7虽然发现了正确的"旋转后放置"交互逻辑(第23步),但随后却陷入了追求"整体形状重叠"的执念,并为一个虚假的目标——"顶行进度"——浪费了大量操作。
模型失败不是因为"看不见",而是因为无法把观察到的事物整合成一个完整的世界模型。
失败模式二:被训练数据"绑架"的抽象思维
"错误的抽象层次"
第二类失败源于模型对当前环境的错误抽象。在多次运行中,模型会反复尝试将陌生的机制映射到它从训练数据中学到的已知游戏:
-
俄罗斯方块(Tetris)
-
青蛙过河(Frogger)
-
推箱子(Sokoban)
-
粉末游戏(Powder Toy)
-
打砖块(Breakout)
-
乒乓球(Pong)
这些"类比"听起来荒谬,但模型的推理过程却自洽得可怕。GPT-5.5在任务"ls20"中,甚至在推理轨迹中写道:
"这可能更像'打砖块',顶部有砖块,下面有挡板。中央的物体可能是球。"
这种毫无根据的假设,直接葬送了任何进步的可能——而一个熟悉打砖块的人类,几乎不会犯这种错误。
问题的链条是:局部视觉相似 → 被误认为完整游戏规则 → 行动方向被带偏。
当一个模型把"未知"误解为"已知",它就会开始寻找错误的"可操作特性"(affordances),把精力浪费在测试根本不存在的机制上。
失败模式三:通关了关卡,却没学会规则
"解决了关卡,却没有学会游戏"
第三种失败模式也许是最具洞察力的发现:即使模型"幸运地"通过了某个关卡,那个成功也无法转化为真正的理解。
Claude Opus 4.7在任务"ka59"中的表现堪称经典案例:
-
Level 1:Opus用37步完成通关,看起来干净利落 ✓
-
但实际上:它对"点击"的理解是错误的——它以为点击是"传送当前角色"
-
Level 2的真相:游戏要求的是形状匹配与推动机制
-
结果:Opus将错误理解固化为"点击每个目标来填充它",整个运行彻底崩溃,无法恢复
在任务"ar25"中,同样的模式在不同抽象层次上演:Opus在Level 1正确识别了镜像移动(✓),随后在Level 2甚至确实发现了新的可移动轴机制(✓),但紧接着它又开始幻想出"打孔"和"需要翻转"等不存在的规则。
正确的信息被埋在了错误假设的废墟下。
这揭示了一个深刻的问题:早期关卡的推进不能可靠反映模型是否真正理解了任务。如果没有明确检验"为什么能过关",模型就会把错误认知带入下一关,并在此基础上不断放大偏差。
GPT-5.5 vs Claude Opus 4.7:不同的"翻车"姿势

有意思的是,虽然两款模型得分都不理想,但通过对比运行记录,ARC Prize团队发现它们的失败方式完全不同。
ARC Prize研究员Greg Kamradt的总结一针见血:
"Opus是压缩错了,GPT-5.5是压缩不了。"
Claude Opus 4.7:压缩错了
Opus在短周期机制发现方面表现更强——它几乎能立刻识别出正确的局部规律。但它也更容易锁定一个错误的"恒定特征",然后坚定不移地执行下去。
它确实形成了一套"可运行的解释",只是这套解释是错的。在任务"cn04"中,它构建了一套"进度/计时/转换"的错误理论,并在这个假设框架内不断尝试操作——直到耗尽所有步数。
GPT-5.5:压缩不了
GPT-5.5则是另一个极端。它的"假设生成"更广泛、更发散,这使得它更有可能说出正确的思路。但问题是,它无法将这些想法转化为具体行动。
在任务"ar25"中,它识别出了镜像效应,但随后不断重新打开"可能的游戏类型空间",在俄罗斯方块、青蛙过河、乒乓球、汉诺塔之间来回横跳,直到错过所有正确的行动时机。
Opus擅长快速形成假设但容易"一条道走到黑",GPT-5.5长于发散思考但难以落地执行。
这两种"缺陷"恰恰反映了两家公司不同的技术路线:Anthropic倾向于让模型更快地建立"世界观",而OpenAI则试图让模型保持更大的"可能性空间"。但面对ARC-AGI-3这种完全陌生的环境,两种策略都暴露出了各自的问题。
这意味着什么?

这份报告的发布,恰逢整个AI行业沉浸在"GPT-5.5和Claude 4.7有多强"的欢庆氛围中。它像一面镜子,映照出我们可能忽视的真相。
AGI比我们想象的远得多?
我们习惯用MMLU、GSM8K这些基准来衡量AI的"智力水平"。在这些测试上,顶级模型早已超越人类平均水平。于是舆论开始出现一种声音:"AGI就在眼前"、"AI很快会在所有任务上超越人类"。
但ARC-AGI-3的数据告诉我们:这些基准测试考的是知识调用和模式匹配,而不是真正的泛化和适应能力。
当我们设计一个专门考验"面对全新环境时的自适应能力"的测试时,最顶级的模型得分还不到1%。这不是某个模型的失败,而是整个"通过Scaling Law走向AGI"范式的共同困境。
或者:我们对"智能"的定义本身就有问题?
另一种视角是:也许我们不应该期望当前架构的AI在ARC-AGI-3上表现好——因为这些测试的设计初衷,恰恰是当前AI无法通过"记忆"和"统计规律"来解决的。
François Chollet本人曾说过:
"当一个AI系统在第一次接触所有环境时,其行动效率能够达到或超过人类水平,才算真正'攻克'ARC-AGI-3。"
这个定义背后,是一个关于"智能"的核心假设:真正的智能,应该能够从少量样本中提取抽象规则,并将其泛化到完全陌生的场景。
当前的LLM架构,恰恰是在海量的数据上学习"统计共现规律"。这种范式在处理与训练数据分布相似的任务时表现惊人,但在面对真正"前所未见"的场景时,立刻显现出根本性的不足。
"大模型军备竞赛"是不是走偏了?
2026年,GPT-5.5的参数量已经突破了新的数量级,Claude Opus 4.7的上下文窗口达到了百万token级别。但ARC-AGI-3的数据表明,这些"量"的提升,并没有带来"质"的突破。
也许,真正需要突破的不是模型规模,而是对"学习"和"推理"本质的理解。强化学习、持续学习、因果推理、元学习……这些领域的研究,也许比"让模型更大"更接近AGI的真正门槛。
写在最后
ARC Prize团队开源了全部160组运行轨迹和分析工具包(可访问 arcprize.org 获取)。如果你对AI推理能力有兴趣,强烈建议亲自去看看那些模型的"思考过程"——你会看到它们如何一步步走向错误,如何在正确的线索上走过却视而不见。
这不仅仅是AI研究者的必读资料。对于每一个关心AI未来的人,这些失败案例都是一面镜子,让我们得以重新审视:什么才是真正的智能?我们距离它还有多远?
100% vs 0.43%——这不是一道简单的数学题,而是一道关于"理解"本质的哲学题。
参考资料:
-
ARC Prize官方分析报告:https://arcprize.org/blog/arc-agi-3-gpt-5-5-opus-4-7-analysis
-
ARC-AGI-3 Leaderboard:https://arcprize.org/leaderboard
-
Greg Kamradt分析:Analyzing GPT-5.5 & Opus 4.7 with ARC-AGI-3
原文链接:
GPT-5.5和Claude 4.7双双翻车:人类100%,AI不到1%
欢迎关注「程序员之路」,分享技术,见证AI时代。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 28
28 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)