论文收获:OracleNet: enhancing OBS recognition with Adaptive Deformation and Texture-Structure Decoupling
论文:OracleNet:通过自适应变形和纹理-结构解耦增强Oracle Bone Script识别 |NPJ遗产科学
一、摘要
现有深度学习技术在自动识别甲骨文字方面面临挑战,包括对局部特征的精细控制不足、对纹理信息的忽视以及对高度辨别特征的学习不足,为解决这些问题,论文介绍了一种名为OracleNet的甲骨文字图像处理模型。OracleNet由自适应变形模块、纹理-结构解耦模块和多层结构化感知注意力模块组成。自适应变形模块通过自适应点增强局部控制,保持脚本语义完整性;纹理-结构解耦模块区分纹理与结构元素,提高识别准确性;多层结构化感知注意力模块通过宏观和微观视角细化差异。
二、介绍
1、甲骨文识别局限性
-
注释数据稀缺
甲骨文字符极为罕见,注释它们需要高度专业的知识。这一过程既昂贵又劳动密集,导致可用注释数据的严重限制。因此,传统的监督学习方法难以有效。为了缓解数据不足,广泛采用了数据增强方法。然而,传统的数据增强技术,如旋转,缩放、剪切,以及翻转在处理Oracle Bone Script时显示出显著的局限性 ,这是因为Oracle Bone Script的语义信息高度依赖其结构特征,如笔画的形状和相对位置;简单的几何变换可能会破坏这些关键特征。为此,采用了非刚性数据增强方法,如自由形变形(FFD)以及弹性变换(ER)已经被提议了。这些方法通过改变图像的形状和对齐来生成新的数据样本,而不直接修改图像内容。然而,FFD在处理复杂局部特征时缺乏精细控制,可能无法准确保留Oracle Bone Script的细微结构。虽然ER在调整空间对齐方面有效,但其固定的正则化参数无法适应Oracle Bone Script图像中的细微变化,导致增强过程中部分局部特征丢失。此外,这些方法在处理高分辨率 Oracle Bone Script 图像时计算量较大,因此不适合大规模应用
-
Oracle Bone Script图像中复杂纹理和结构特征难以有效分离
Oracle Bone Scrip拓片(目标领域)和摹本(源领域)在质地和结构上存在显著差异。摹本数据具有清晰的字形,主要包含结构信息,而拓片数据则包含复杂的噪声,如模糊和退化,提供丰富的纹理特征。如果这些特征被无差别地对齐,丰富的纹理信息可能会误导模型,使得学习域不变特征变得困难。大多数领域适配方法无法有效减少不同领域间的特征分布差异。一些研究试图将特征解耦以区分纹理信息和结构信息,但往往忽视纹理信息的作用。例如,UDCN它仅将结构语义信息纳入适应,忽视了纹理信息对图像磨损、污渍和变形的影响。MixupAda结合混合数据增强和对抗性域适应,旨在提升领域自适应性能。TransPar是一种基于变换器的偏域自适应方法,专注于迁移源域和目标域共享的特征表示。FixBi是一种双向比对方法,旨在更好地桥接源域和目标域的特征空间,实现有效的域适配。PRONOUN使用典型表示和归一化输出条件器来增强模型的泛化。BSP通过对对抗域适配的批次频谱惩罚,平衡移动性和判别性。
-
需要高度辨别性特征以区分外观相似的特征,并处理磨损和变形等问题
由于不同的书写风格以及Oracle Bone Script字符笔画和结构的显著差异,模型需要具备高度辨别性的特征学习能力。识别甲骨文字字符不仅需要区分外观相似的字符,还需处理因磨损和变形引起的细微差异。
2、解决方法
为了应对上述三个挑战,论文介绍了OracleNet。具体来说,在该网络中设计了三个模块:自适应变形模块(ADM)、纹理-结构解耦模块(TSDM)和多层结构感知注意力模块(MLSPAM)。ADM通过引入基于FFD的自适应控制点,增强了Oracle Bone Script图像中的精细局部变形控制,允许细微调整以保留字符的关键结构特征。这种方法使模型能够更好地适应图像中复杂的局部特征,减少因变形引起的语义信息丢失。TSDM通过特征解耦分离图像中的纹理和结构特征,使模型能够更好地理解和利用图像中不同类型的信息。MLSPAM通过多层次的注意力机制增强模型对结构特征的感知。利用自我关注,该模块在宏观和微观层面捕捉图像中的关键信息。在宏观层面,注意力机制帮助模型识别图像中的关键区域和特征;在微观层面,它进一步完善这些特征,确保模型能够区分外观相似的汉字,同时处理磨损和变形带来的细微差异。MLSPAM的设计旨在增强模型对复杂Oracle Bone Script图像的适应性,并提升整体识别性能。通过这三个模块,OracleNet不仅能够精确处理Oracle Bone Script图像中的复杂变形和噪声,还能有效分离和利用结构和纹理特征,显著提升了Oracle Bone Script字符的识别准确性和稳健性。
三、方法
给定 M 个带标签的手印摹本源域样本 ![]() 及其对应标签
及其对应标签 ![]() ,以及 N 个无标签的拓片目标域样本
,以及 N 个无标签的拓片目标域样本 ![]() ,源域与目标域之间存在显著的分布差异,即
,源域与目标域之间存在显著的分布差异,即![]() 。
。
本研究的目标是训练一个模型 G,使其通过对带标签的源域数据![]() 和无标签的目标域数据
和无标签的目标域数据![]() 进行联合训练,能够在拓片数据上实现良好的泛化性能。具体来说,需要对模型 G 进行优化,以最小化其在两个域上的预测误差,其数学表达式为
进行联合训练,能够在拓片数据上实现良好的泛化性能。具体来说,需要对模型 G 进行优化,以最小化其在两个域上的预测误差,其数学表达式为
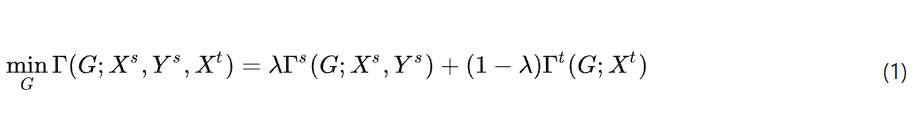
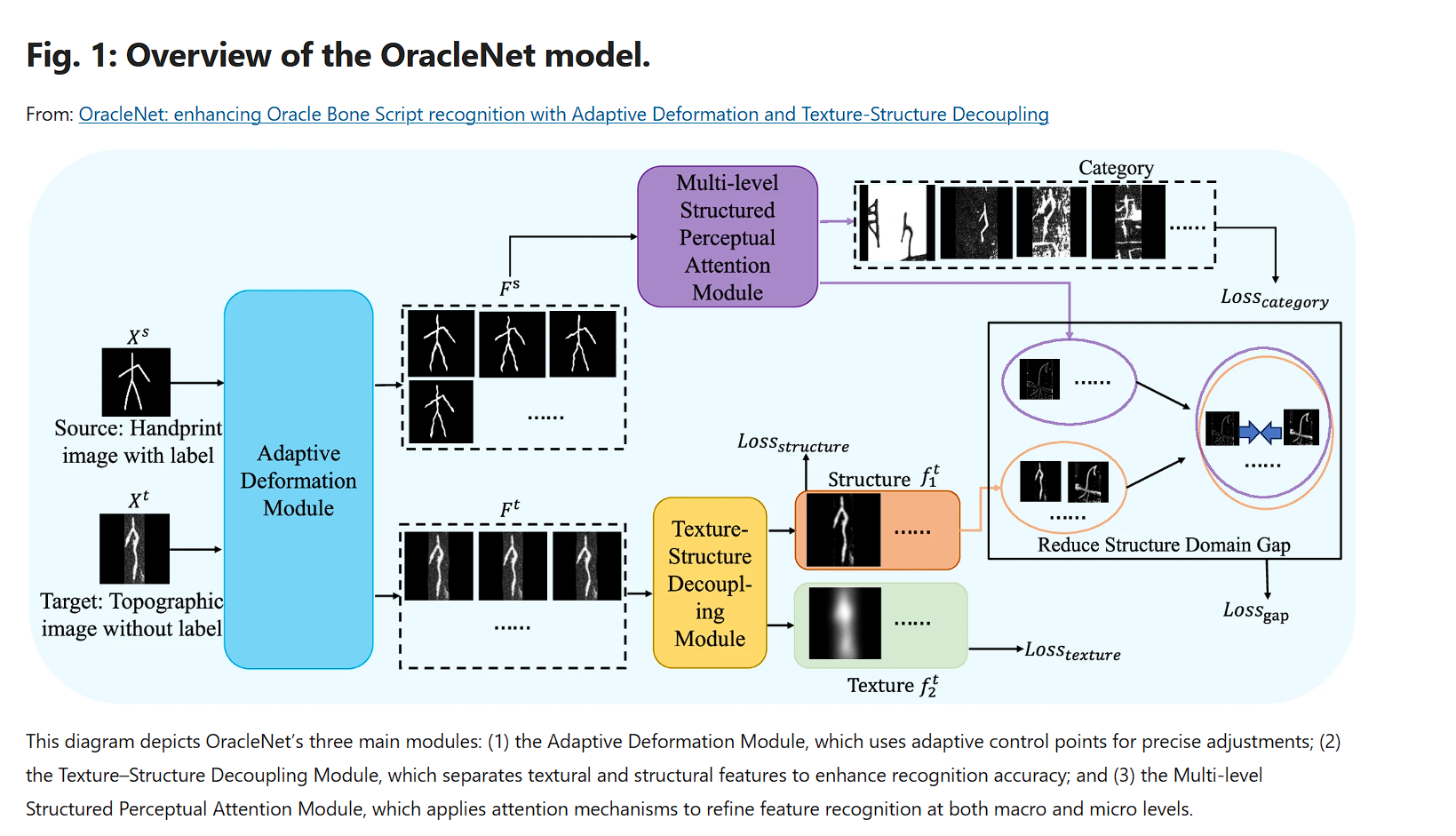
给ΓsΓt分别表示源域和目标域的损失函数,λ 是一个超参数,平衡两个域的重要性。因此,模型 G 旨在获得在两个域中同样有效的域不变特征,从而提升对未见目标域拓扑数据的性能。
四、网络模型
如图所示。OracleNet 所提出的模型包含三个模块:ADM、TSDM 和 MLSPAM,旨在提升 Oracle Bone Script 图像的处理效率和泛化能力。ADM 采用自适应控制点技术,对 Oracle Bone Script 图像进行精确的局部调整。与传统 FFD 技术相比,自适应控制点根据图像内容动态调整,更准确地处理复杂的局部特征,并有效保留 Oracle Bone Script 的复杂结构,同时最大限度地减少变形过程中的信息丢失。
在处理甲骨文字图像时,区分结构特征和纹理特征尤为重要。TSDM有效地将图像的质地和结构特征分离。这不仅提高了结构特征的识别精度,还使模型能够更好地应对因图像磨损和劣化引起的纹理噪点。MLSPAM利用自我关注机制,提升对甲骨文字图像在多个层面的感知和识别。通过在宏观和微观层面应用注意力机制,该模块不仅识别图像中的关键区域和特征,还细化这些特征以区分视觉相似的汉字,并适应图像中的轻微变形和磨损。
五、模块
Adaptive Deformation Module
传统的FFD技术通过在图像上设置规则的控制点网格并移动这些控制点来作图像的局部变形。鉴于Oracle Bone Script图像的特殊结构特征和细节要求,本文介绍了一种自适应控制点技术,能够根据图像内容动态调整控制点的密度和方向,从而实现更精确的局部变形控制。细节如图 此时,对于手写摹本源域样本 ![]() 改进后的FFD变换函数可表示为:
改进后的FFD变换函数可表示为:
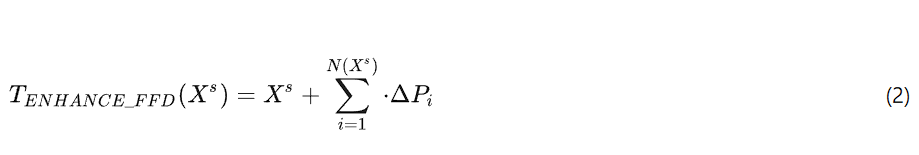
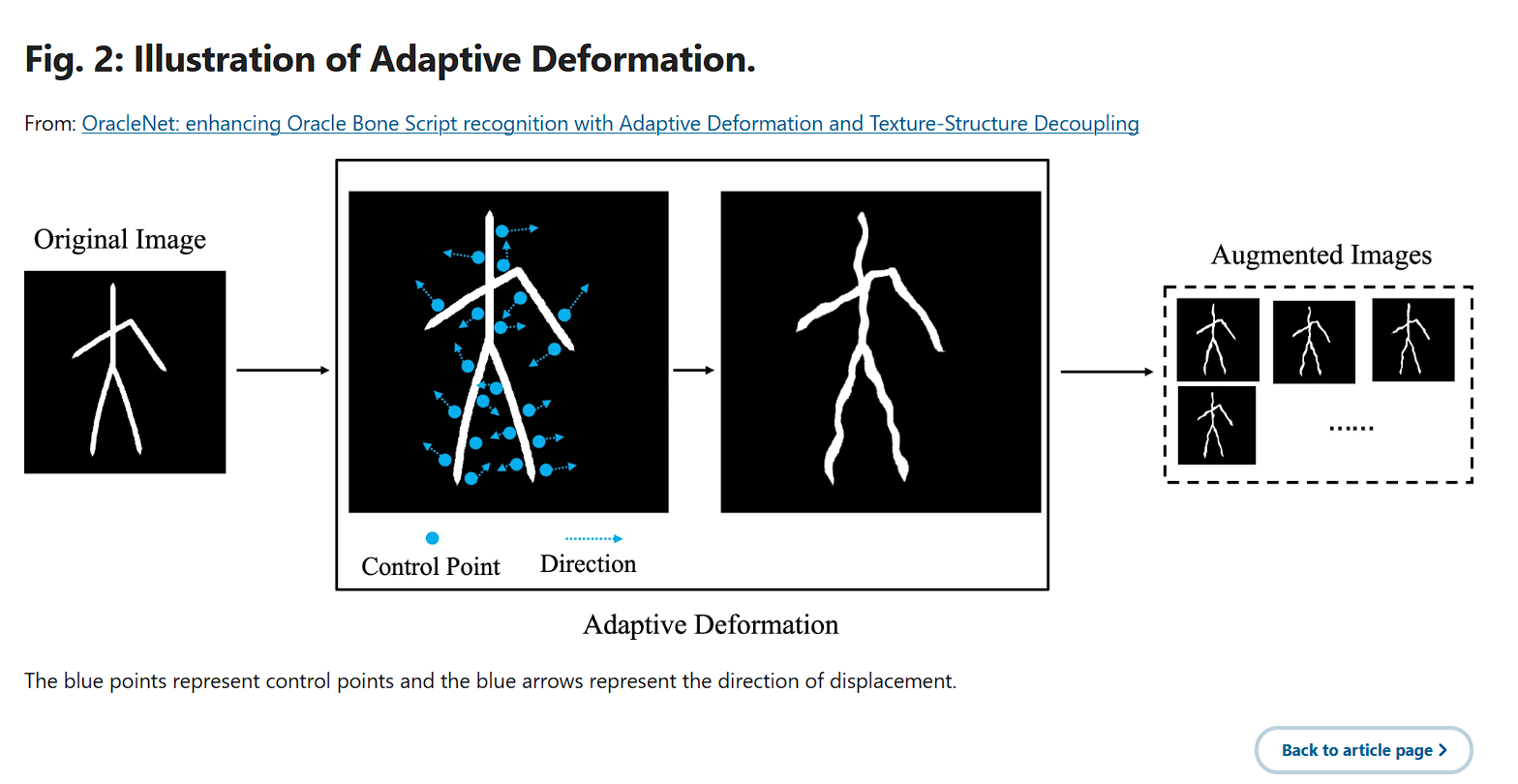
其中 ![]() 是基于手印源域样本
是基于手印源域样本![]() 的控制点数,以及
的控制点数,以及 ![]() 我是控制点i的位移矢量。
我是控制点i的位移矢量。
位移矢量 ![]() 对于每个控制点I,不仅取决于控制点的原始位置,还取决于周围局部区域的特征变化。位移矢量的方向和大小由以下过程确定:
对于每个控制点I,不仅取决于控制点的原始位置,还取决于周围局部区域的特征变化。位移矢量的方向和大小由以下过程确定:

其中![]() 表示控制点
表示控制点![]() 周围的图像梯度,
周围的图像梯度,![]() 是一个根据图像内容调整位移方向和范围的参数。这种调整确保控制点的移动增强了图像的结构表现能力。
是一个根据图像内容调整位移方向和范围的参数。这种调整确保控制点的移动增强了图像的结构表现能力。![]() 可以通过以下方式自动计算:
可以通过以下方式自动计算:
对于手印摹本源域样本![]() ,利用清晰的结构和明显的笔触,利用图像的边缘强度和方向性作为动态计算
,利用清晰的结构和明显的笔触,利用图像的边缘强度和方向性作为动态计算![]() 的主要特征:
的主要特征:

其中,![]() 和
和![]() 分别表示控制点 i 附近的边缘强度和边缘方向,
分别表示控制点 i 附近的边缘强度和边缘方向,![]() 函数用于量化控制点附近图像的显著变化程度,这有助于控制变形;
函数用于量化控制点附近图像的显著变化程度,这有助于控制变形;![]() 函数则可辅助调整控制点的移动方向,使其与图像中的边缘方向保持一致,从而维持图像结构的连续性和完整性。
函数则可辅助调整控制点的移动方向,使其与图像中的边缘方向保持一致,从而维持图像结构的连续性和完整性。![]() 和
和 ![]() 分别表示手印摹本源域样本在控制点 i 附近沿 x 方向和 y 方向的一阶导数;
分别表示手印摹本源域样本在控制点 i 附近沿 x 方向和 y 方向的一阶导数;![]() 和
和 ![]() 为 Sobel 算子,该算子常用于边缘检测,通过突出显示与边缘对应的高空间频率区域来实现边缘提取。α1 和 α2 为系数,分别用于权衡边缘幅度(EdgeMagnitude)和边缘方向(EdgeOrientation)的贡献权重。
为 Sobel 算子,该算子常用于边缘检测,通过突出显示与边缘对应的高空间频率区域来实现边缘提取。α1 和 α2 为系数,分别用于权衡边缘幅度(EdgeMagnitude)和边缘方向(EdgeOrientation)的贡献权重。
对于目标域拓扑样本 ![]() 本文利用局部对比和噪声抑制作为动态计算
本文利用局部对比和噪声抑制作为动态计算![]() 的主要特征
的主要特征
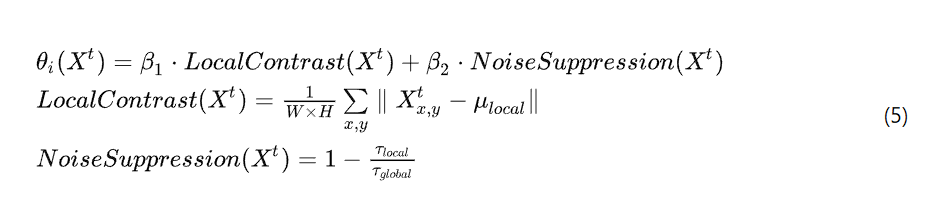
其中![]() 表示局部对比度,强调图像中重要特征的可见性;NoiseSupp ressio n
表示局部对比度,强调图像中重要特征的可见性;NoiseSupp ressio n![]() 表示噪声抑制程度,有助于减少控制点位移中噪声的影响;β1以及β2是衡量局部对比度和噪声抑制贡献的系数。
表示噪声抑制程度,有助于减少控制点位移中噪声的影响;β1以及β2是衡量局部对比度和噪声抑制贡献的系数。![]() 是图像X的像素值
是图像X的像素值![]() 位置(x, y),
位置(x, y),![]() 是
是![]() 控制点i附近区域的平均像素值,W 和 H 分别是局部窗口的宽度和高度,
控制点i附近区域的平均像素值,W 和 H 分别是局部窗口的宽度和高度,![]() 是
是![]() 控制点i附近像素值的标准差,
控制点i附近像素值的标准差, ![]() 是整个图像
是整个图像![]() 中像素值的标准差.
中像素值的标准差.
通过上述改进,ADM能够生成增强的样本![]() 来自手印摹本源域的样本
来自手印摹本源域的样本 ![]() 以及
以及![]() 来自未标记的目标域拓扑样本
来自未标记的目标域拓扑样本![]() ,具体如下:
,具体如下:
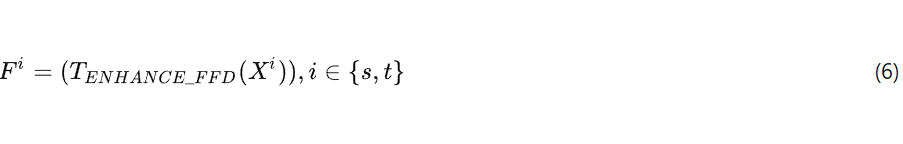
该模块有助于提升数据多样性和模型的泛化能力,同时不影响Oracle Bone Script图像的原始语义内容。通过实现这些变形,图像在适应现实场景中可能遇到的变化的同时,保持其本质特征,从而增强后续识别任务的稳健性和准确性。
模块代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Tuple
class AdaptiveDeformationModule(nn.Module):
def __init__(self, config):
super().__init__()
self.num_control_points = config.num_control_points
self.displacement = config.displacement
self.alpha1 = config.alpha1
self.alpha2 = config.alpha2
self.beta1 = config.beta1
self.beta2 = config.beta2
self.conv = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
self.control_points_predictor = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, self.num_control_points * 2, kernel_size=1)
)
def compute_edge_features(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
sobel_x = torch.tensor([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], dtype=torch.float32).view(1, 1, 3, 3).to(x.device)
sobel_y = torch.tensor([[-1, -2, -1], [0, 0, 0], [1, 2, 1]], dtype=torch.float32).view(1, 1, 3, 3).to(x.device)
Ix = F.conv2d(x, sobel_x.repeat(x.size(1), 1, 1, 1), padding=1, groups=x.size(1))
Iy = F.conv2d(x, sobel_y.repeat(x.size(1), 1, 1, 1), padding=1, groups=x.size(1))
magnitude = torch.sqrt(Ix.pow(2) + Iy.pow(2))
orientation = torch.atan2(Iy, Ix)
return magnitude, orientation
def compute_local_features(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
mean = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
squared = x.pow(2)
local_var = F.avg_pool2d(squared, kernel_size=3, stride=1, padding=1) - mean.pow(2)
local_std = torch.sqrt(torch.clamp(local_var, min=1e-10))
local_contrast = (x - mean) / (local_std + 1e-6)
global_std = torch.std(x, dim=(2, 3), keepdim=True)
noise_suppression = 1 - (local_std / (global_std + 1e-6))
return local_contrast, noise_suppression
def forward(self, x: torch.Tensor) -> torch.Tensor:
batch_size = x.size(0)
edge_magnitude, edge_orientation = self.compute_edge_features(x)
local_contrast, noise_suppression = self.compute_local_features(x)
features = self.conv(x)
control_points = self.control_points_predictor(features)
control_points = control_points.view(batch_size, self.num_control_points, 2)
theta = (self.alpha1 * edge_magnitude + self.alpha2 * torch.cos(edge_orientation) +
self.beta1 * local_contrast + self.beta2 * noise_suppression)
grid = F.affine_grid(theta.view(-1, 2, 3), x.size())
deformed = F.grid_sample(x, grid)
return deformed
Texture–Structure Decoupling Module
为了有效处理甲骨脚本图像,尤其是具有复杂纹理的地形数据,区分结构特征和纹理特征至关重要。
结构特征指的是构成字符本身的内在、与形状相关且语义意义强的组成部分。这些特征是角色身份认同和识别的基础。具体来说,Oracle Bone Script 图像中的结构特征主要包括:字符形状和轮廓、笔画组成与排列、几何信息以及拓扑结构。这些结构特征通过聚焦定义人物形态的基本线条和曲线来识别,同时尽量减少多余元素的影响。相反,Oracle Bone Script图像中的纹理特征指的是与字符语义身份或结构形态无直接关联的表面视觉图案和变化。这些特征通常是由甲骨骨材料特性、雕刻工艺、老化过程和图像采集过程引入的领域特有噪声或伪影。Oracle Bone Script图像中的纹理特征通常包括:表面噪点和颗粒、裂纹和裂缝、污渍和变色、模糊和退化,以及磨损和侵蚀痕迹。
纹理-结构分析模块旨在 从未标记目标结构域的增强样本![]() 提取结构特征
提取结构特征![]() 以及纹理特征
以及纹理特征![]() ,该模块的核心思想是通过最小化(结构特征)和最大化(纹理特征)
,该模块的核心思想是通过最小化(结构特征)和最大化(纹理特征) ![]() 与手印摹本源域增强样本
与手印摹本源域增强样本![]() 之间的差异,实现特征分离。
之间的差异,实现特征分离。
甲骨文图像的结构特征主要包括其形状、轮廓及其他几何信息。结构特征的提取问题可表示为:

其中S表示提取结构特征的作。这是因为 ![]() 包含结构和纹理特征,而
包含结构和纹理特征,而![]() 仅包含结构特征。通过最小化上述差异,可以有效提取结构特征。
仅包含结构特征。通过最小化上述差异,可以有效提取结构特征。
对于Oracle Bone Script图像的纹理特性![]() ,问题可表达为:
,问题可表达为:

其中,![]() 代表纹理特征提取操作。与结构特征的提取过程相反,纹理特征可通过最大化差异来获取。该方法的核心是突出区分目标域样本与源域样本中独有的纹理属性。
代表纹理特征提取操作。与结构特征的提取过程相反,纹理特征可通过最大化差异来获取。该方法的核心是突出区分目标域样本与源域样本中独有的纹理属性。
在公式 (7) 和 (8) 中,![]() 代表从甲骨文图像中提取结构特征的抽象操作。它并非单一、固定的算法,而是对下述过程的概念性表述:分离并突出图像中与形状相关、具有语义意义的成分,同时抑制或忽略与纹理相关的噪声和变化。本文中,操作
代表从甲骨文图像中提取结构特征的抽象操作。它并非单一、固定的算法,而是对下述过程的概念性表述:分离并突出图像中与形状相关、具有语义意义的成分,同时抑制或忽略与纹理相关的噪声和变化。本文中,操作 ![]() (在结构分支内)的实现技术为注意力机制(应用于 MLSPAM 模块中的结构特征),并以结构特征损失
(在结构分支内)的实现技术为注意力机制(应用于 MLSPAM 模块中的结构特征),并以结构特征损失 ![]() 为优化导向。
为优化导向。
类似地,![]() 代表纹理特征提取的抽象操作。其概念目标是分离并捕捉与字符结构形态和语义内容无关的表层视觉模式及变化。与操作
代表纹理特征提取的抽象操作。其概念目标是分离并捕捉与字符结构形态和语义内容无关的表层视觉模式及变化。与操作 ![]() 相同,
相同,![]() 并非单一算法,而是纹理 - 结构分析模块(TSDM)中纹理特征提取过程的概念化表述。本文中,操作
并非单一算法,而是纹理 - 结构分析模块(TSDM)中纹理特征提取过程的概念化表述。本文中,操作 ![]() (在纹理分支内)的实现技术为基于纹理聚焦损失
(在纹理分支内)的实现技术为基于纹理聚焦损失![]() 训练的网络层。
训练的网络层。
综上,公式 (7) 和 (8) 中的操作 ![]() 和
和 ![]() 均为概念性抽象,分别对应 TSDM 模块中结构特征提取与纹理特征提取的不同目标:操作
均为概念性抽象,分别对应 TSDM 模块中结构特征提取与纹理特征提取的不同目标:操作 ![]() (结构特征提取)旨在分离并突出与形状相关、具有语义意义的成分;而操作
(结构特征提取)旨在分离并突出与形状相关、具有语义意义的成分;而操作 ![]() (纹理特征提取)旨在捕捉与结构形态无关的表层视觉模式及变化。
(纹理特征提取)旨在捕捉与结构形态无关的表层视觉模式及变化。
因此,结构特征损失 ![]() 可表示为:
可表示为:

该结构特征损失函数用于最小化源域和目标域增强样本之间的结构差异,采用均方误差衡量差异程度。其中,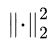 代表欧氏距离的平方,N 为样本总数,
代表欧氏距离的平方,N 为样本总数,![]() 和
和![]() 分别代表源域第 i 个样本和目标域第 i 个样本的结构特征
分别代表源域第 i 个样本和目标域第 i 个样本的结构特征
纹理特征损失![]() 可表示为:
可表示为:
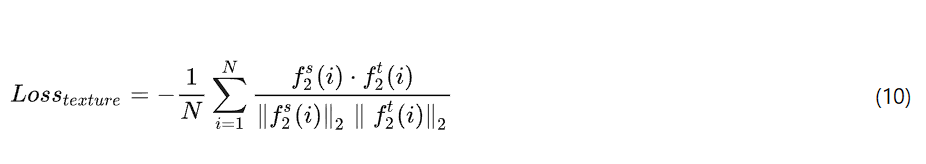
该纹理特征损失函数旨在最大化源域与目标域之间的纹理差异。这一目标可通过最小化一个负损失函数来实现 —— 其本质是减小纹理特征之间的相似度。该函数借助负余弦相似度,衡量特征向量之间的方向差异。
此处,![]() 代表向量的欧几里得范数,
代表向量的欧几里得范数,![]() 代表点积,
代表点积,![]() 和
和![]() 分别对应源域第 i 个样本与目标域第 i 个样本的纹理特征。
分别对应源域第 i 个样本与目标域第 i 个样本的纹理特征。
模块代码
import torch
import torch.nn as nn
from typing import Tuple
class TextureStructureDecouplingModule(nn.Module):
def __init__(self, in_channels: int = 3):
super().__init__()
self.structure_encoder = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
self.texture_encoder = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
self.structure_attention = nn.Sequential(
nn.Conv2d(64, 1, kernel_size=1),
nn.Sigmoid()
)
self.texture_attention = nn.Sequential(
nn.Conv2d(64, 1, kernel_size=1),
nn.Sigmoid()
)
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
structure_features = self.structure_encoder(x)
structure_attention = self.structure_attention(structure_features)
structure_out = structure_features * structure_attention
texture_features = self.texture_encoder(x)
texture_attention = self.texture_attention(texture_features)
texture_out = texture_features * texture_attention
return structure_out, texture_outMulti-Level Structured Perceptual Attention Module
该模块聚焦于甲骨文图像的多层次结构特征,涵盖了从基础笔画到复杂符号组合的各类元素,随后进行分层注意力学习与整合。
具体而言,在微观层面,它捕捉甲骨文图像的边缘与基础形状;在宏观层面,它则聚焦于图像的整体布局、符号组合及其相互关系。
该模块的详细信息如图 3 所示
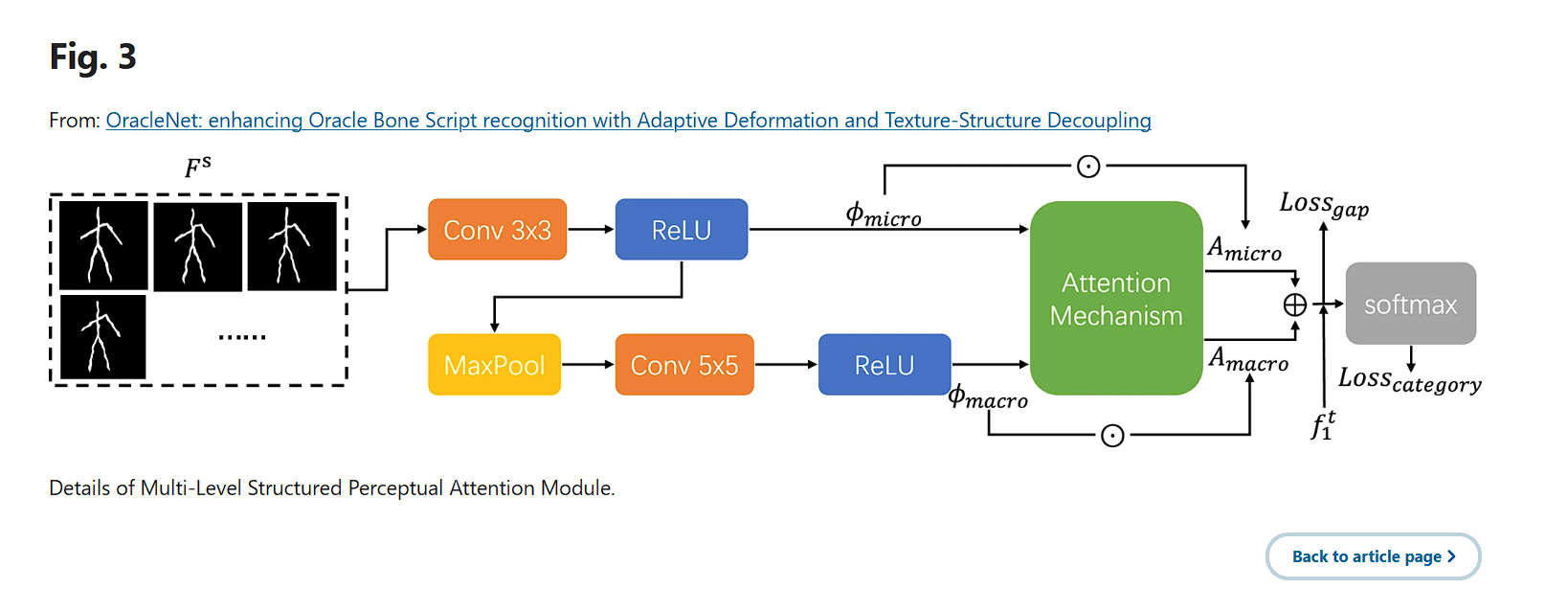
微观层面特征提取可以表示为:

微观层面特征的特点是专注于Oracle Bone Script图像中的细粒度细节和局部结构。这些特征通过3×3卷积核(Conv3 × 3)提取,该核提供更小的感受场,使模块能够捕捉局部图案。具体来说,微观层面特征主要捕捉字符的边缘和细笔画。它们还包括构成字符基本构建单元的基本形状和局部图案。
宏级特征提取可以表示为:
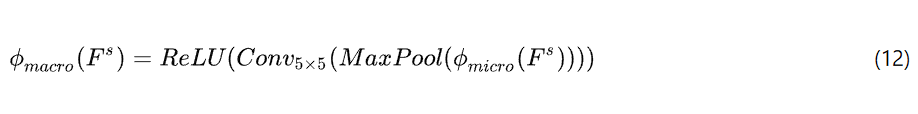
相比之下,宏观层面特征强调更广泛的情境信息和整体结构模式。这些特征通过5×5卷积核(Conv5 × 5)提取,随后进行最大池化,提供更大的感受场,使模块能够捕捉更广泛的全局上下文。宏观层面特征捕捉字符内笔画的整体布局和空间排列。它们包含笔画和符号的组合,形成字符内更大的语义单元。这些特征对甲骨文字字符的整体形状和整体形态敏感,捕捉字符不同部分之间的上下文关系,提供整体视角。这里,5 × 5卷积核 Conv5 × 5 帮助捕捉更广泛的结构特征,使用最大池降低特征映射的维度,增加感受场,增强图像全局信息的捕捉。
微观特征侧重于局部细节和精细结构,而宏观层面特征则侧重于Oracle Bone Script字符的整体布局和更广泛的上下文信息。
对于Oracle Bone Script图像的微观和宏观特征,每个层级都设计了一个注意力模块,以学习该层结构特征的重要性。这可以表达为:
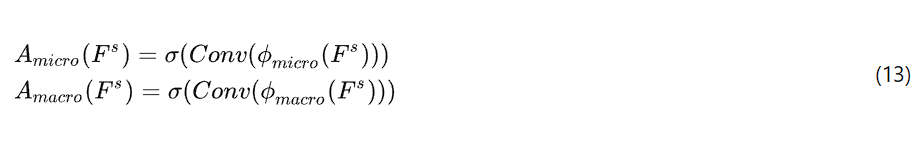
其中 si g moid 函数 σ 是卷积运算,用于从层级特征中学习空间注意力。
来自微观和宏观层面的注意力加权特征被融合,得到一个全面的输出特征![]() :
:
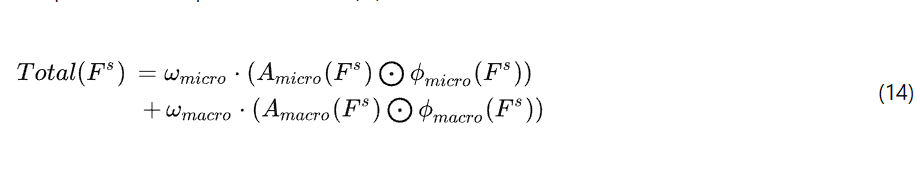
其中![]() 以及
以及![]() 是学习到的权重参数。
是学习到的权重参数。
通过添加全连通层进行分类可以表示为:

其中 W 和 b 分别是权重和偏置参数。
分类损失函数![]() 利用交叉熵,可以表示为:
利用交叉熵,可以表示为:

其中C为总类别数,表示类别 c 是否为样本的正确分类,Φ表示样本被分类为 c 的概率
领域差异损失函数表示为

其中,![]() 代表欧氏距离的平方。该损失函数旨在最小化源域增强样本的加权特征
代表欧氏距离的平方。该损失函数旨在最小化源域增强样本的加权特征![]() 与目标域的结构特征
与目标域的结构特征 ![]() 之间的欧氏距离,促使模型在两个不同域之间找到一致的结构特征表示。
之间的欧氏距离,促使模型在两个不同域之间找到一致的结构特征表示。
该方法有效减小了源域与目标域之间的结构特征差异,提升了模型在甲骨文地形数据上的泛化能力,从而能够更准确地对未见过的甲骨文地形数据进行分类。
模块代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiLevelAttentionModule(nn.Module):
def __init__(self, in_channels: int = 64):
super().__init__()
self.micro_conv = nn.Sequential(
nn.Conv2d(in_channels, 32, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
self.macro_conv = nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels, 64, kernel_size=5, padding=2),
nn.ReLU(inplace=True)
)
self.micro_attention = nn.Sequential(
nn.Conv2d(32, 1, kernel_size=1),
nn.Sigmoid()
)
self.macro_attention = nn.Sequential(
nn.Conv2d(64, 1, kernel_size=1),
nn.Sigmoid()
)
self.fusion = nn.Sequential(
nn.Conv2d(96, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, in_channels, kernel_size=1)
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
micro_features = self.micro_conv(x)
micro_attention = self.micro_attention(micro_features)
micro_out = micro_features * micro_attention
macro_features = self.macro_conv(x)
macro_attention = self.macro_attention(macro_features)
macro_out = macro_features * macro_attention
macro_out = F.interpolate(macro_out, size=micro_out.shape[2:], mode='bilinear', align_corners=False)
combined = torch.cat([micro_out, macro_out], dim=1)
out = self.fusion(combined)
return out全损函数
总损失函数
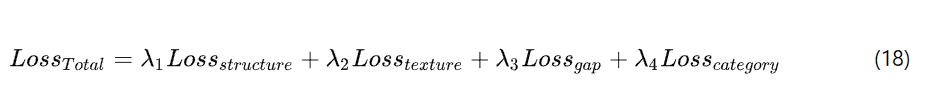
其中,![]() 代表纹理 - 结构分析模块内与结构特征相关的损失,
代表纹理 - 结构分析模块内与结构特征相关的损失,![]() 代表同一模块内与纹理特征相关的损失,
代表同一模块内与纹理特征相关的损失,![]() 代表域适配方法中使用的损失,而
代表域适配方法中使用的损失,而![]() 则是 MLSPAM 中的分类损失。参数
则是 MLSPAM 中的分类损失。参数 ![]() 和
和![]() 是用于平衡不同损失贡献的权重参数。
是用于平衡不同损失贡献的权重参数。
OracleNet 模块的协同运作
OracleNet 的优势在于其三个核心模块(ADM、TSDM 与 MLSPAM)的协同运作。这些模块并非独立单元,而是被设计为协同工作,以协调的方式优化甲骨文识别任务的不同环节。
数据的顺序流转
输入的甲骨文图像首先进入 ADM 模块:ADM 会对图像进行自适应变形,缓解域内差异并增强结构特征的显著性,确保后续模块能基于结构优化后的输入进行处理。ADM 的输出随后流入 TSDM 模块:TSDM 承担着分离纹理与结构信息的关键作用 —— 通过拆分这两类特征,TSDM 让模型能够专注于学习域不变的结构表示,有效处理甲骨文图像中固有的纹理噪声。TSDM 输出的两条特征流会被送入 MLSPAM 模块:MLSPAM 用于分层提取并细化多尺度结构特征,它在宏观与微观层面均采用注意力机制,聚焦于甲骨文的最显著部分,进一步提升特征的区分度。最终,MLSPAM 输出的精细化特征表示会被传递至分类器,生成识别结果。
联合训练下的协同优化
OracleNet 采用端到端训练方式,使各模块能够联合且相互依赖地进行优化。总损失函数 ![]() 通过整合
通过整合![]() 与
与![]() ,统筹这一联合优化过程。在反向传播阶段,
,统筹这一联合优化过程。在反向传播阶段,![]() 产生的梯度会流经 MLSPAM、TSDM 与 ADM,指导每个模块的学习:ADM 学会为 TSDM 提供最优输入,TSDM 学会提取能充分利用 MLSPAM 注意力机制的特征,而 MLSPAM 则学会聚焦于结构增强、纹理解耦后的表示中最具区分度的特征,实现协同学习。
产生的梯度会流经 MLSPAM、TSDM 与 ADM,指导每个模块的学习:ADM 学会为 TSDM 提供最优输入,TSDM 学会提取能充分利用 MLSPAM 注意力机制的特征,而 MLSPAM 则学会聚焦于结构增强、纹理解耦后的表示中最具区分度的特征,实现协同学习。
互补性作用
每个模块在 OracleNet 的整体优化中都扮演着互补角色:ADM 降低数据方差并标准化输入,TSDM 分离纹理这一干扰因素以聚焦结构,MLSPAM 提供精细化的多尺度特征分析。这种精心设计的模块化结构,结合端到端联合训练,正是 OracleNet 在甲骨文识别任务中实现优异性能的关键。
Results
数据集
Oracle-241数据集包含约8万张图像,涵盖241类手印和地形Oracle Bone Script字符,用于无监督域适应任务。数据集分为训练集和测试集,训练集包含10,861个带标签的手印数据和50,168个未标记的拓扑数据;测试集包含3730个手印数据和13806个地形数据。Oracle-241数据集中的Oracle Bone Script图像因长时间埋藏和粗心挖掘表现出极其严重且独特的噪声,且数据集中的大多数类别具有多种书写风格,增加了识别和适应的难度,如图所示

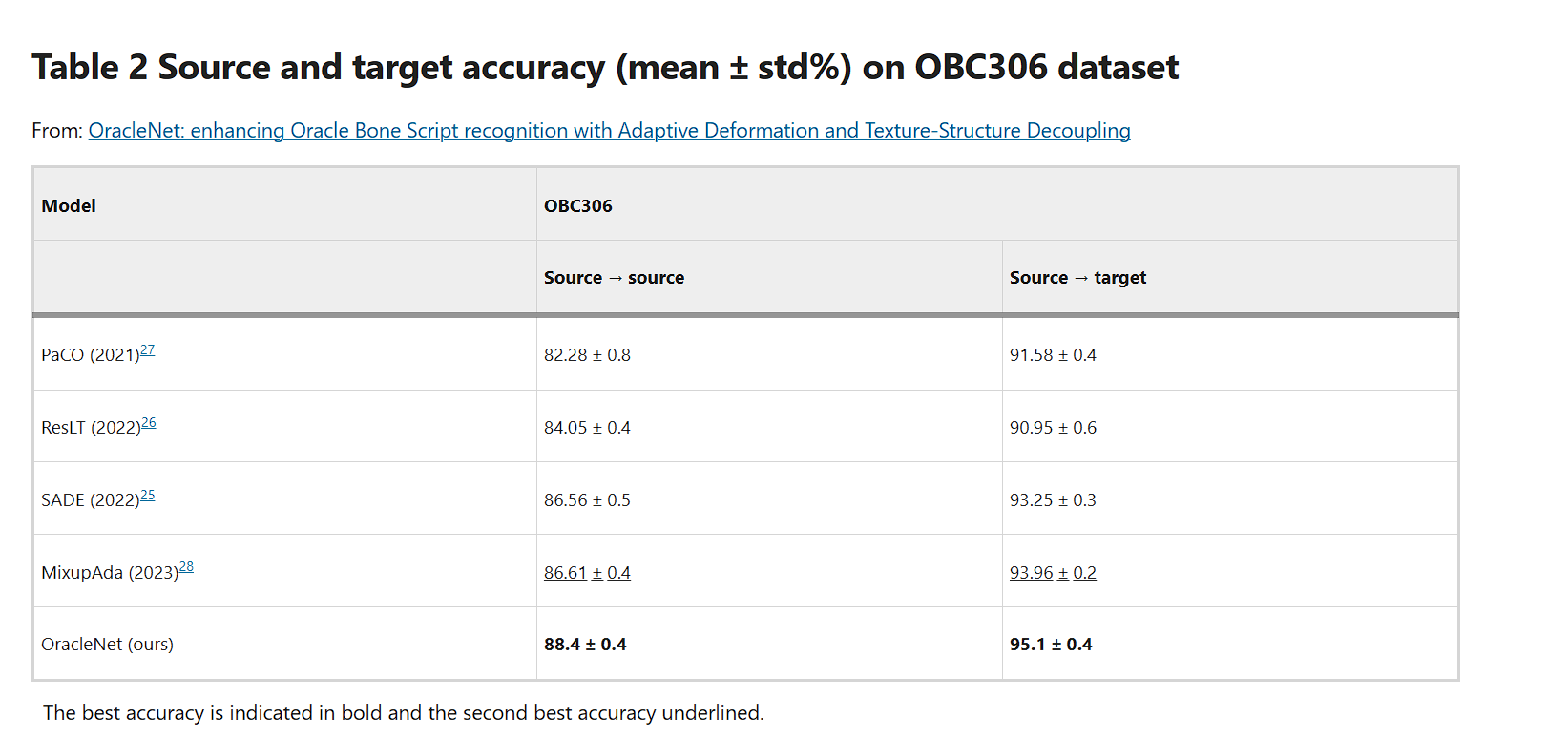
OBC306数据集2目前是最大的 Oracle Bone Script 数据集,包含 309,551 个样本,分为 306 个类别,每个类别代表一个独特的 Oracle Bone Script 字符,用于模式分类基准测试。如图4所示,OBC306数据集中的所有样本均从真实的Oracle Bone Script碎片中提取。训练与测试组比例分为3:1。
Oracle-MNIST 数据集由28×28张灰度图像组成,包含30,222个古代字符,涵盖10个类别,用于模式分类基准测试,特别是针对图像噪声和失真相关的挑战。训练集包含27,222张图片,测试集中每个类别包含300张图片。训练与测试组比例分为4:1。
Results on Oracle-241

Results on OBC306
Results on Oracle-MNIST


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 29
29 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)