论文收获:OBI综述
论文:Oracle bone inscriptions information processing: a comprehensive survey
论文地址:https://doi.org/10.1038/s40494-026-02511-w
翻译内容:
本文以任务为核心开展系统性梳理,将甲骨文(OBI)信息处理领域的发展历程,重新定义为研究方法与其底层数据基础之间的协同演进。文章探讨了构建可靠、高效的甲骨文信息处理系统所面临的核心难题与潜在研究方向;这类智能系统可成为一线科研工作者的得力辅助工具,助力学者参与先秦时期社会结构与年代分期等重大学术议题的研讨。
甲骨文是目前已知最早的中国古文字体系,年代主要追溯至商代晚期(约公元前 1300— 前 1046 年)。古人通常将文字契刻于龟腹甲与牛肩胛骨之上,用于火灼占卜。对甲骨文的研究,为上古汉语的音韵、构词及语义研究提供了独一无二的研究视角。除极具语言学价值外,这些占卜铭文也是探究中国青铜时代历史、宗教、治理模式与社会结构的珍贵原始文献。
受甲骨文物自身物理特质与文字固有属性影响,甲骨文信息处理研究始终面临一系列独特且棘手的挑战。其中最突出的问题是甲骨严重碎片化:历经数千年自然风化与人为损毁,绝大多数龟甲兽骨均已破碎,文字铭文散落于海量残片之上。甲骨残片缀合如同复杂的高维拼图,往往是开展连贯语义分析的必要前提;在图像处理技术普及之前,该项工作完全依赖甲骨学专家数十年如一日的人工拼接整理。
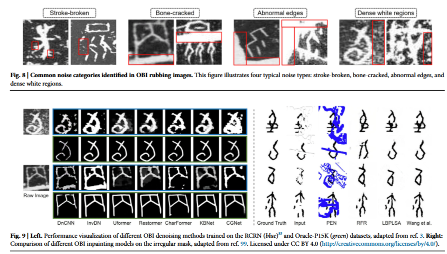
其次,从古文字学层面来看,甲骨文存在大量异体字,同一个汉字拥有多种字形写法;同时字形相似度极高,许多不同的甲骨文字形视觉外观高度相近。此外,甲骨文拓片存在四类典型噪声:笔画断裂、骨面裂纹、边缘残缺、密集白斑,进一步加大了甲骨文字的识别难度。
最后,甲骨文研究的终极目标是文字释读。自 1899 年甲骨文首次被发现以来,已出土逾 4500 个字符种类,而成功考释解读的仅约三分之一。核心阻碍首先在于可用语料稀缺、语境范围狭窄;甲骨铭文大多为占卜记录,格式程式化严重,语义表达空间受限。另一重难点在于多数甲骨文字兼具象形与指事特征,部分字形的图像表意逻辑虽依稀可辨,但原始视觉隐喻多已失传,或字形演变过于抽象而难以直观辨识。这使得甲骨文释读高度依赖比较古文字学研究 —— 追溯字形向金文、简牍等成熟字体的演化脉络,而这类推演往往带有一定推测性。
以人工智能技术的飞速发展为驱动,尤其是大生成模型的广泛应用,甲骨文信息处理领域持续迭代革新,也深刻改变了传统甲骨学者的研究思路。近年来,大量跨技术领域的甲骨文相关论文陆续发表(图 1),在一定程度上掩盖了领域真正的核心关键问题。由于学科交叉属性,考古语言学、历史学研究者关注的核心议题,与计算机、人工智能算法领域学者的研究侧重点存在较大差异。因此,开展一篇全面系统的领域综述具有重要价值,既有助于系统梳理现有研究文献,也能为未来研究指明发展方向。
现有综述研究
尽管甲骨文相关研究成果颇丰,但能够对领域工作进行系统梳理与批判性分析的高质量综合性综述仍十分稀缺。表 1 汇总了目前已发表的甲骨文领域综述文献。
邢等人梳理了 Faster R-CNN、SSD、YOLO、RFBnet、RefineDet 等甲骨文检测模型,旨在为不同硬件平台选择兼顾推理速度、内存占用与检测精度的最优网络架构。刁等人于 2025 年发表古文字图像识别综述,按文字类型对现有研究进行归类,并分析了各类文字对应的识别方法。
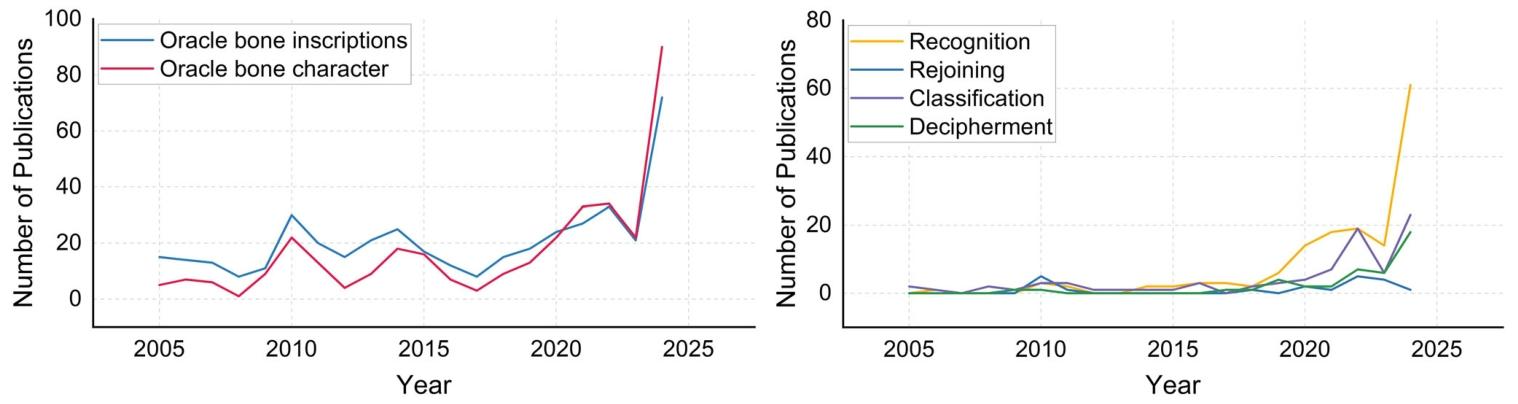
检索限定主题、标题或摘要中含有甲骨文、甲骨文字关键词(左图),或同时包含 OBI 与四大主流任务(识别、缀合、分类、释读)的相关文献(右图)。
本次统计时间跨度近二十年,涵盖 2005 至 2024 年。可以看出:2017 年之前,甲骨文相关论文发文量整体较为平稳;2017—2022 年,随着深度学习技术普及,OBI 领域研究文献数量稳步上升。近年来,伴随大语言模型技术的快速发展,相关论文发文量呈激增趋势,反映出跨学科领域愈发关注将大语言模型应用于甲骨文各类研究任务。
图 1|Web of Science 数据库收录文献的发文趋势
突出各类古文字识别方法的差异特征与共有研究思路。本文还综述了古文字识别独有的研究挑战,以及小样本学习、抗噪声算法等前沿解决方案。近期,李等人系统梳理了甲骨文字识别(OrCR)领域的研究全貌,概述了该领域主流基准数据集与数字资源,同时评述了各类前沿研究方法,分析其各自的适用场景、局限性与应用范围。
据现有文献所知,上述几篇综述是目前仅有的甲骨文相关综述成果。但现有综述仅局限于单一研究维度,只聚焦识别任务,忽视了甲骨文研究的系统性完整性与天然跨学科属性,也未能涵盖该领域的核心研究任务与新兴前沿方向。例如,甲骨文数据集构建、甲骨残片缀合、甲骨文分类、甲骨文文字释读,以及近年涌现的各类人工智能前沿技术,均已成为重点研究热点。这些新兴研究方向代表了甲骨文信息处理的发展新趋势,却几乎未被现有综述收录。
鉴于当前甲骨文综述存在上述短板,学界亟需一篇全面且紧跟前沿的综述:既涵盖传统甲骨文处理技术,又囊括从文物出土到数字化保护的全流程研究任务,便于从宏观视角完整把握该领域的发展历程、研究现状与未来趋势。本文正是为填补这一空白而撰写。
综述贡献与创新点
本文具有以下独到学术贡献:
- 全面系统性综述:系统梳理现有甲骨文信息处理技术,收录文献规模远超过往综述;从数据、方法双维度覆盖各类研究任务,对比归纳不同研究的差异与共性策略。
- 融合前沿技术视角:将现有甲骨文处理方法置于深度学习、生成模型、大语言模型等前沿技术框架下展开梳理与评述。
- 归纳现存核心挑战:剖析当前甲骨文研究存在的关键难题与固有局限,重点探讨现有评价体系的适用性缺陷。
- 指引未来研究方向:梳理并细化多个极具研究价值的未来发展方向,涵盖文本生成甲骨文、专用评价指标设计、面向甲骨文释读的多模态学习、甲骨残片三维重建等多个研究维度。
综述研究方法与行文架构
为实现对甲骨文信息处理文献全面、成体系的梳理,需采用规范清晰的综述研究范式。本文完整综述流程包含:文献检索、筛选标准、分类体系、内容分析、归纳总结五大环节,具体说明如下:
-
文献检索:甲骨文信息处理交叉涉及考古学、文字学、计算机科学、信号处理、语言学等多个领域。本文选取谷歌学术、IEEE Xplore、ACM 数字图书馆、SpringerLink、Web of Science 等主流学术数据库作为检索平台;同时重点检索多媒体、计算机视觉、人工智能、文化遗产保护领域的权威中外期刊(如 IEEE Transactions on Image Processing、Pattern Recognition、npj Heritage Science),以及 ICLR、ACM MM、CVPR、ICCV、ACL、AAAI 等顶级学术会议论文。检索采用甲骨文主题关键词组合,包括:甲骨文、甲骨文字识别、甲骨残片缀合、甲骨文数据集、深度学习在甲骨文处理中的应用、甲骨文文字释读等。
-
筛选标准:文献纳入依据包括主题相关性、研究方法创新性、学术影响力等;剔除依据包含语种限制、研究质量、出版物类型、内容重复冗余等。
-
分类体系:从甲骨文数据集、甲骨文处理关键技术、面向特定任务的甲骨文研究成果三大维度,对文献进行归类梳理。
-
内容分析:系统综述甲骨文信息处理相关研究,梳理从传统方法到现代人工智能驱动方法的演进脉络。按四大任务逐一展开剖析,同时归纳不同任务下甲骨文数据集的独有特征。
-
归纳总结:结合古文字数字化、文物保护与文字释读的现存痛点,结合人工智能技术发展趋势,研判本领域未来的研究方向与发展态势。
本文综述文献的时间范围限定为近 20 年(2005—2025 年)。考虑到甲骨文研究具有学术传承性,该时间限定不限制引用早期学界经典研究成果。本文补充收录了现有综述遗漏、但具备重要学术价值的甲骨文研究任务与相关文献。
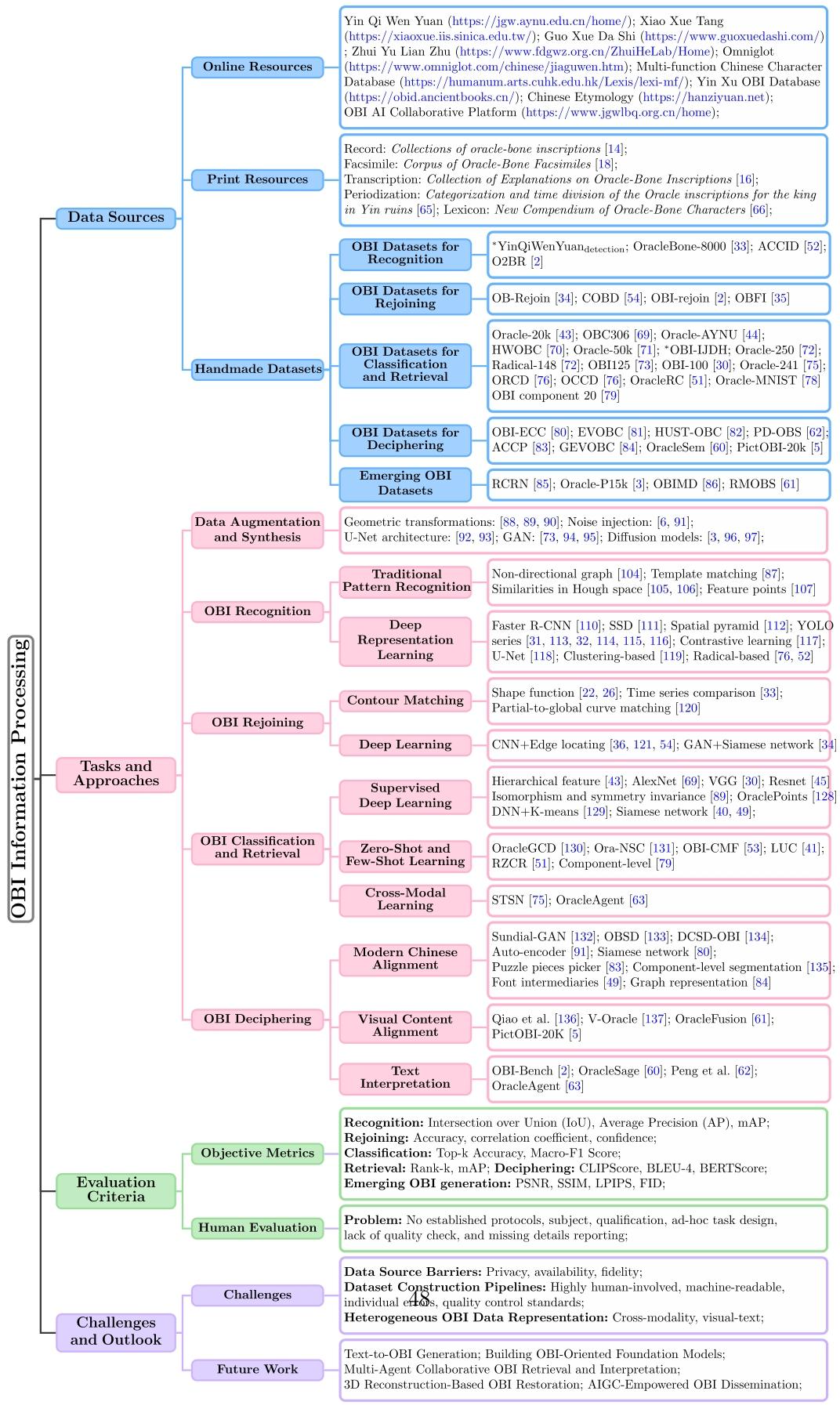
本文整体架构如图 2 所示:首先梳理甲骨文研究发展的四大阶段,每个阶段均对应独特的研究方法、数据格式与技术难点。从历史演进视角既能清晰呈现领域研究现状,也为后文未来研究方向的论述提供依据。其次,分任务梳理现有甲骨文专用数据集;再次,总结甲骨文主流预处理方法,包括传统图像处理、基于生成模型的数据增强,并综述不同任务下的各类甲骨文处理技术。

涵盖甲骨文识别、甲骨文缀合、甲骨文分类、甲骨文释读四大任务。第四部分探讨不同任务下甲骨文处理方法的评测方式,并对比各类方法的优缺点。第五部分总结甲骨文处理领域现存研究挑战与未来发展趋势,最后对全文进行总结。
甲骨文处理范式演进与分析
甲骨文信息处理的发展历经多次重大范式变革(图 3),体现了人工智能前沿技术与古文字专家认知推理过程的深度融合。本节梳理甲骨文处理研究发展的四个关键阶段,每个阶段均具备独有的主流研究方法、效果分析与技术难点。从历史演进视角出发,既能清晰呈现领域研究现状,也为后文综述所探讨的未来研究方向提供理论依据。
第一阶段:传统专家主导研究范式
早期甲骨文研究主要依靠人工整理、校勘古籍开展。王懿荣、王国维、罗振玉、郭沫若、胡厚宣、裘锡圭、黄天树、黄德宽、宋镇豪等学者,在甲骨文理论研究与实践整理层面均作出了卓越贡献。彼时甲骨出土后,相关资料的刊布主要通过墨拓、摹写、摄影等方式复刻甲骨文字,再将复刻成果汇编成典籍出版。其中,《甲骨文合集》至今仍是收录体量最完备的甲骨著录,刊布甲骨数量为历代之最,且完整配套图版、释文与索引。在此基础上,甲骨文字的考释与解读成为早期甲骨文研究的核心任务。
除古文字考释外,甲骨文断代分期研究也取得了重要进展。董作宾作出里程碑式贡献,将跨度 273 年的甲骨卜辞划分为五个年代分期。后世现代学者对该分期体系进行了修订:先依据字形特征及其他特质对卜辞归类,再判定每一类卜辞的年代归属,提出全新两系说,取代了传统五期分期框架。此外,针对甲骨文文字构形体系、形体造字规律等专项研究,既包含古文字系统的内部机理分析,也开展文字历时演变探究,为厘清早期汉字的结构特征与演化机制提供了重要支撑。
然而,主导早期研究的传统专家范式虽奠定了学术根基,却天然受限于人的能力短板。最突出的问题是研究效率极低:从单字考释、卜辞释文誊写,到残片人工检索与拼接匹配,所有工作完全依赖少数资深学者繁琐且耗时的手工劳作,研究进展十分缓慢。同时,该研究范式可复现性差、主观性强。文字释义高度依赖学者个人直觉、知识储备与长期积累的隐性学术经验,这类经验难以标准化、体系化记录与传承,其他研究者难以独立验证已有结论,也无法在前人成果基础上开展系统性延伸研究,严重制约了甲骨文研究的规模化发展与成果客观验证。
第二阶段:计算机辅助数字图像处理阶段
该阶段时间跨度为 20 世纪 90 年代至 2012 年前后,是数字图像处理技术变革发展的关键时期。甲骨文领域研究主要聚焦图像增强、图像修复(如直方图均衡化、空间滤波),同时引入尺度不变特征变换(SIFT)、方向梯度直方图(HOG) 等局部特征描述子。这类算法能够借助计算机优化甲骨文图像质量,支撑下游研究任务;即便图像存在缩放、旋转、光照变化,仍可稳定提取图像的固有结构特征。
王氏等人采用小波变换对不同缺损程度的甲骨文拓片进行去噪处理。文献 [24] 提出一种针对清晰甲骨文拓片的网格点特征提取算法,该算法利用粗网格相对地址,有效提升了识别性能。刘氏等人提出一种基于角度序列的局部边界描述子,并结合二维碎片轮廓匹配算法实现甲骨缀合。王氏等人提出一种基于欧氏距离的轮廓匹配方法,用于提取与追踪龟甲图像的轮廓信息。
此外,在开源意识尚未普及的年代,保障数据所有权与完整性(尤其是甲骨文这类珍贵文物数据),对文化遗产保护至关重要。刘氏等人为此设计了一套面向甲骨文图像的小波水印嵌入与提取流程,该方法对画笔篡改与图像裁剪具有较强的鲁棒性。
然而,这一阶段的算法普遍对噪声与图像退化敏感,难以有效区分真实文字笔画与背景干扰。
甲骨文信息处理领域的数据源、研究方法、评估指标、挑战与展望分类体系。* 注:殷契文渊检测集与OBI-IJDH 数据集的网址分别为:https://jgw.aynu.edu.cn/home/down/detail/index.html?sysid=3和http://www.ihpc.se.ritsumei.ac.jp/OBIdataseIJDH.zip。
图 2|甲骨文信息处理的数据源、研究方法、评估指标、挑战与展望分类框架
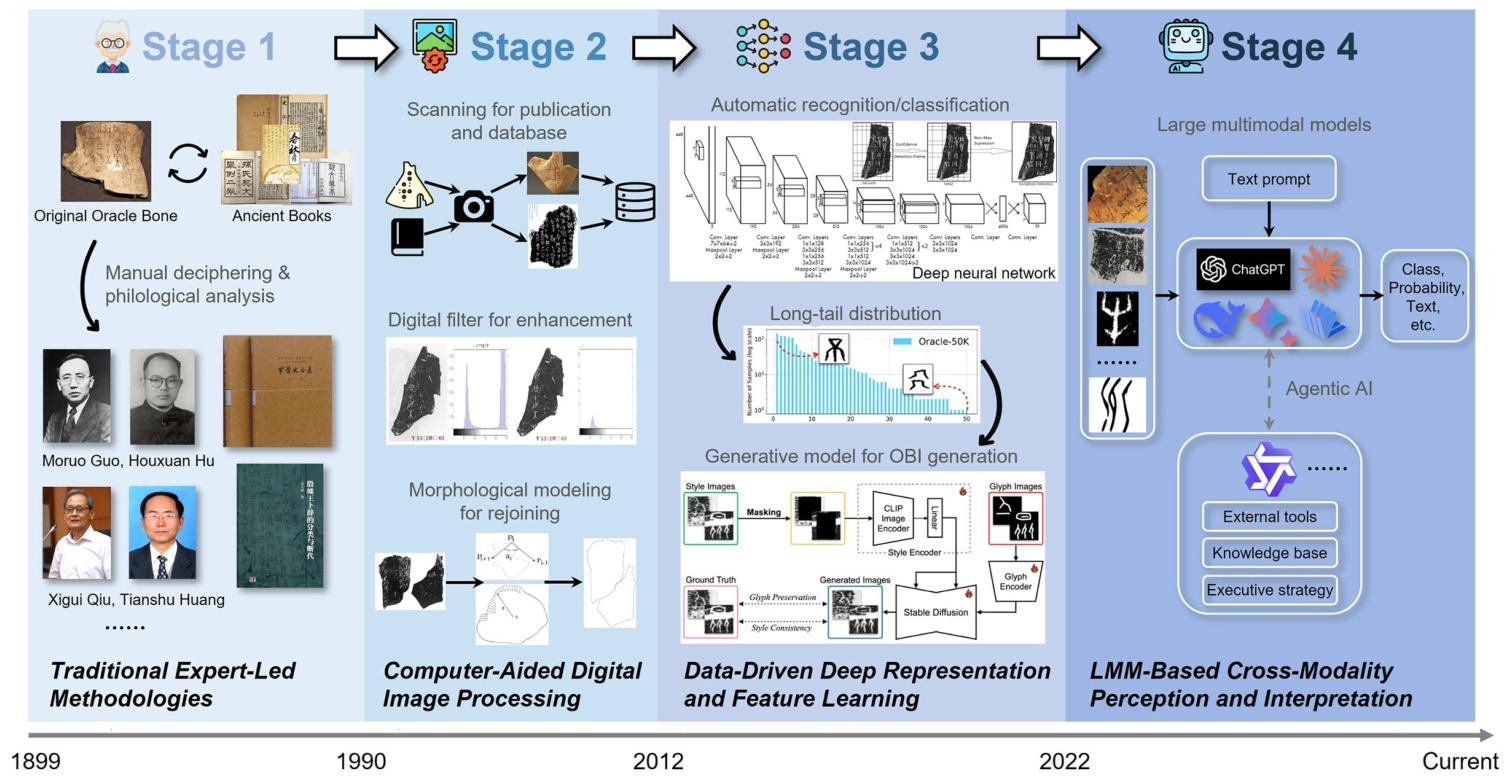
图 3|上世纪至 2025 年甲骨文(OBI)信息处理方法演进脉络甲骨文信息处理历经四次范式转型:传统专家主导研究方法、计算机辅助数字图像处理、以大多模态表征知识融合为特征、可实现高阶学习的数据驱动深度感知与理解,以及最新的跨模态模型。本文梳理了每个阶段具有代表性的研究方向
难以区分文字笔画,也无法甄别拓片中普遍存在的随机背景噪声,例如裂纹、风化侵蚀以及墨迹分布不均等干扰。此外,该研究阶段还存在严重的语义鸿沟:此类方法仅将甲骨文字视作固化的几何图形,而非具有语义内涵的文字单元;所依赖的人工设计特征,缺乏刻画同类字内部字形变体差异的表征能力。
第三阶段:数据驱动的深度表征与特征学习
深度卷积神经网络(DCNN)的问世,成为甲骨文信息处理领域的关键转折点:研究范式从以专家为核心的人工处理流程,转变为数据驱动的自动化框架。该类模型在甲骨文识别、残片缀合、文字分类、图像检索等任务中表现优异,为后续大规模甲骨文数据库的构建奠定了基础。
本阶段研究在卷积神经网络架构内,将底层方向特征与中高层特征编码相结合,能够更好地捕捉甲骨文字的笔画特征;Transformer 架构的应用进一步提升了特征建模效果。这一技术变革实现了文字长距离结构依赖关系建模,这对甲骨文研究尤为关键:自注意力机制可让模型在图像严重破损、残片缺失的情况下,推理还原完整字形结构。研究者还提出多尺度特征融合方案,实现不同域之间的特征对齐,为甲骨文跨模态检索提供支撑。
同时,为解决稀有甲骨文字数据稀缺的难题,学界采用对抗式数据增强方法(如 AGTGAN、Oracle-P15k)生成合成样本,实现手写摹本与真实拓片之间的风格迁移。针对零样本识别与开放集识别任务,RZCR、ACCID 等框架先检测偏旁构件,再结合知识图谱或深度卷积神经网络,依据构字结构规则推理未知文字类别。
自监督学习兴起后(依托大规模无标注古文字语料开展预训练),模型无需完全依赖稀缺的专家标注数据,即可习得稳定的古文字视觉特征规律,有效缓解甲骨文数据集的长尾分布问题。在甲骨残片缀合任务中,研究者采用专用深度神经网络作为二分类器,在完成初步边缘匹配后,验证残片纹理的连续性。
尽管本阶段研究取得了长足进步,但仍存在诸多挑战。第一,甲骨文数据分布极度不均衡:多数未释读文字仅有孤例留存,或仅保存在残缺拓片当中。现有深度学习模型极易在长尾类别上发生过拟合,甚至完全失效。虽然生成式 AI 数据增强技术已实现手写草图与拓片的风格迁移,但合成样本的质量与多样性,仍无法完全替代真实文物样本。
第二,当前识别模型大多为闭集识别系统,面对未知生僻甲骨文字时极易出现误判。如何赋予分类模型合理的拒识能力,并通过推理实现未见文字的辨识,是当前核心技术瓶颈。此外,该阶段模型大多仅依赖单模态视觉特征,无法理解卜辞文本的语义内涵,制约了甲骨文字的进一步考释与解读。
第四阶段:基于多模态大模型的跨模态感知与解读
近年来,多模态大模型(LMMs)飞速发展,为众多领域带来范式变革,在任务自动化、方法创新、交互应用开发等方面展现出前所未有的潜力。多模态大模型通过融合多种信息模态,从根本上革新了甲骨文研究,实现了甲骨文的跨模态感知与智能解读。
视觉 - 语言对齐技术(如对比学习)的成熟,推动研究从孤立的单字识别迈向语境化文字释读:模型融合字形视觉特征与卜辞文本语义,高度模拟人类专家依靠多源证据考证文字的研究逻辑。OBI-Bench2 是该趋势下的代表性成果,首次在甲骨文识别、缀合、分类、检索、释读五大核心任务上,完成对 23 款多模态大模型的测评,验证了大模型在这类需要专业领域知识与认知推理任务中的应用价值。
此后,基于现有基础模型微调的甲骨文专用视觉语言模型相继涌现,如 OracleSage、OracleFusion 以及 Peng 等人提出的模型。这类模型通过提取层级化视觉信息(字形结构),从视觉与文本双维度辅助多模态大模型提升甲骨文释读的推理可靠性。
近期提出的 OracleAgent,是面向甲骨文信息结构化管理与检索的智能体系统。该系统以大语言模型为中枢,整合多款甲骨文分析工具,实现甲骨文字、文献资料、释读文本与文物图像的高效检索。
这类方法对清晰、完整的常规甲骨文样本效果良好,但面对含噪声、原始残片、跨模态异构输入时表现欠佳。部分以象形字为核心的释读框架适用范围有限,因为绝大多数未释读甲骨文属于会意字范畴。同时,由于缺乏大规模、全覆盖的甲骨文专业语料库,现有多模态大模型仅能完成表层模式匹配与静态知识检索,难以实现动态假说生成与多步逻辑推理。
在此背景下,这一短板或将催生思维链(CoT)推理在甲骨文释读领域的研究落地。从学习范式来看,DeepSeek-R1 所展现的强化学习增强多模态推理能力,也有望成为甲骨文跨模态推理研究的新方向。
整体而言,甲骨文信息处理从传统专家人工劳作模式,逐步演进至新兴多模态智能处理模式,清晰朝着高可靠、自适应、全维度、服务考古专家的人工智能系统方向发展。后文将从数据、研究方法、评测指标三个维度,详细剖析各发展阶段,并梳理引领领域未来发展的前沿研究方向。
甲骨文信息处理的数据源
数据源是甲骨文研究的根基。依据 OBI-Bench2 的研究总结,甲骨文从文物出土到数字化保护的完整流程,涵盖数据增强、智能识别、残片缀合、文字分类以及最终文字释读等环节。甲骨文数据集主要用于各类任务自动化模型的训练与测试;而新兴专用数据集一般针对特定甲骨文处理难题与实际应用场景定制设计。
为全面覆盖领域研究全貌,本文未设置严苛的数据集筛选标准,仅限定时间范围:仅收录近十年(2015–2025 年)发布的数据集。该阶段属于数据驱动甲骨文研究成熟期,任务导向明确。同时剔除无技术文档、无法公开获取、仅供内部使用的私有数据集。
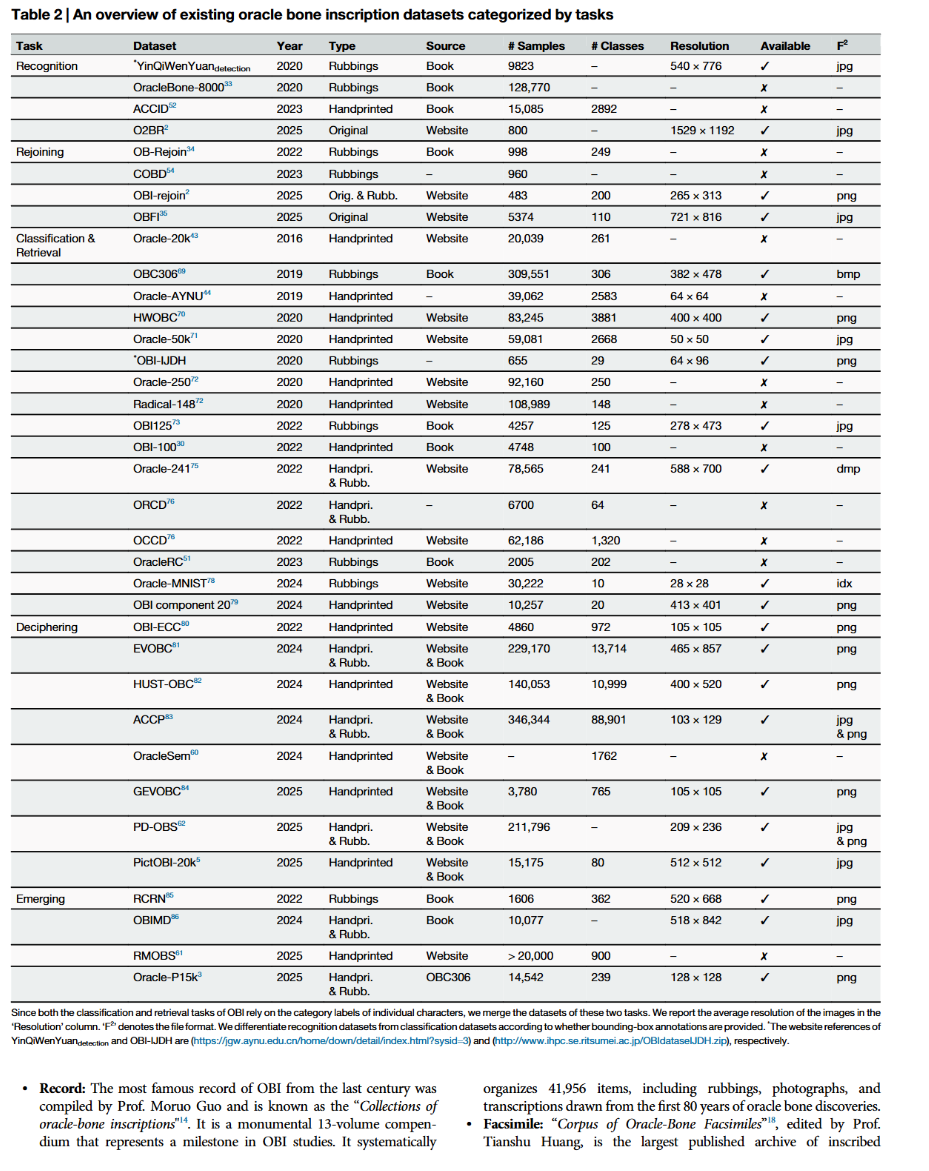
图 2 汇总了面向甲骨文四大核心任务(识别、缀合、分类 / 检索、释读)的 36 个公开数据集,整理包含发布年份、呈现类型、数据来源、样本与类别数量、图像分辨率、开源可用性及文件格式等完整信息。各数据集及其数据源的详细介绍见下文,图 4、图 5 为数据集可视化示例。
在线资源平台
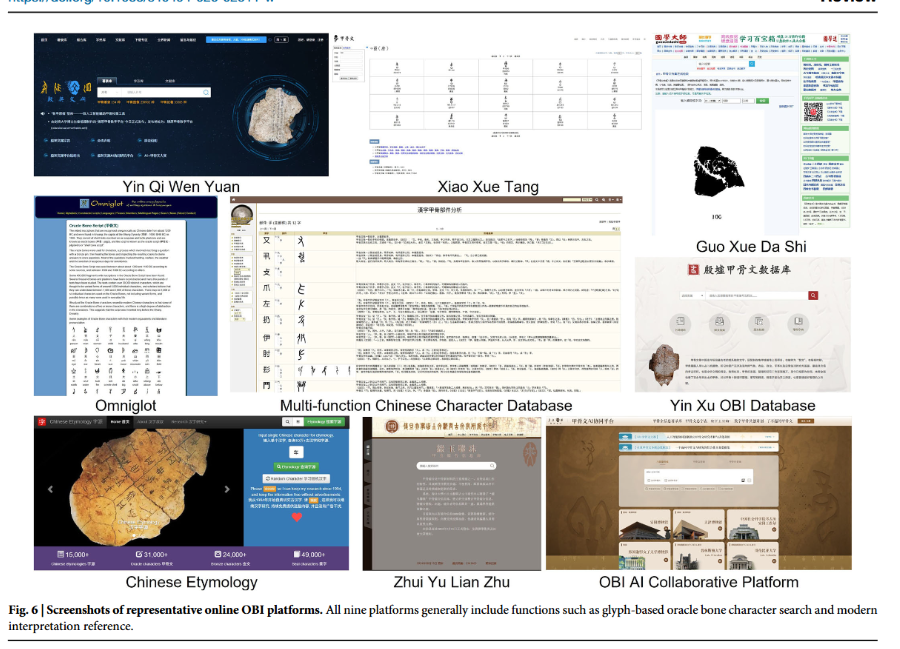
目前已有大量公开甲骨文线上资源,可供学术研究与科普学习使用,同时也是构建甲骨文数据集、推动计算古文字学发展的核心数据源。下文简要介绍 9 个代表性线上平台,图 6 为各平台界面可视化展示。
-
殷契文渊由安阳师范学院运维,是面向甲骨文研究的综合性开放共享知识平台。平台整合文字数据库、甲骨文献库、学术资源库三大板块,收录 154 种甲骨著录、239902 张甲骨图像、35585 篇学术成果;具备高级可视化检索功能,可溯源文字在各类卜辞中的字形演变、用字语境与形体特征。
-
小学堂由台湾大学中文系与中央研究院数位文化中心联合研发运维,是梳理汉字形体与音韵演变的权威学术平台。研究者可查询比对自甲骨文源头起的历代字形流变,是古文字形体分析与数据整理的重要工具库。
-
国学大师专注中华古典文献与传统文化的大型综合在线数据库。对甲骨文研究而言,其核心价值在于完备的字书辞书资源,数字化收录《甲骨文字典》《金文编》《说文解字》《康熙字典》等经典古文字典籍。
-
缀合联珠由复旦大学甲骨缀合实验室搭建,专业存储甲骨残片缀合成果,已收录超 6600 组缀合案例。平台完整记录每组缀合残片的原始著录编号、缀合来源、领衔学者等元数据信息。
-
Omniglot 文字百科全球文字系统线上百科,其甲骨文专题页面为入门级基础数据源,简要介绍甲骨文起源、占卜功用,提供古今字形对照示例,同时聚合各类专业学术网站外链资源。
-
多功能汉字资料库由香港中文大学人文计算研究中心运维,收录海量古文字形体,设有专用甲骨文构件表与海量甲骨字形资源。平台关联古今汉字字形,提供详尽的字源解析、构件拆分与音韵信息,是溯源商代汉字形体演变的重要工具。
-
殷墟甲骨文数据库由陈年福教授主导建设,收录 59591 片甲骨、143856 条卜辞记录。每件甲骨资料包含文字描述、释读注解,同时标注甲骨分类、文献出处、占卜组别等信息。
-
字源网(汉字叔叔)由理查德・西尔斯(汉字叔叔)搭建的大型字源数字数据库,汇总海量古文字字形:包含 31000 余个甲骨文、24000 余个金文、49000 余个篆书字形。
-
甲骨文 AI 协同平台由腾讯联合高校科研机构共建的高端数据库与在线研究平台,收录约 143 万甲骨单字、4184 个词条、近 68 万个已释读字形,支持文字检索、古今字形对照、字义解析与字形演变溯源。

摹本类
《甲骨文摹本大系》由黄天树教授主编,是目前刊布规模最大的甲骨占卜遗存档案,收录 70659 件残片摹本,全部依据现存最清晰的拓片与照片重新绘制。每件摹本均标注分类、最优样本、既往缀合结果与重复拓片信息,并在同一版面配对释文与索引对照表,可为文字演变研究与占卜句法分析提供可检索的权威参考。
释文类
《甲骨文字集释》由余荩吾先生编纂,汇总 4600 余个甲骨字形及历代主流学者考释成果,附带偏旁表、字形分类统计表与拼音索引,为商代文字构形研究提供了系统化的基准资料。
断代分期类
《殷墟王卜辞分类与断代》由黄天树先生撰写,采用严谨的类型学方法,将甲骨卜辞划分为 20 个字形类别,并将其纳入 “两系说” 演变框架。该书结合缀合成果与历法算法,验证了贞组、宾组、历组卜辞的相对年代序列,所提出的可复现研究方法,现已推广应用于金文断代、地理考证与商代句法研究。
字汇类
《新编甲骨文字典》由刘钊教授主编,通过自动裁切与二值化处理,数字化收录数千张商代高清字形图像;西周文字则采用手工摹写后扫描录入。该书整合《甲骨文合集》以来百余种甲骨著录成果,吸纳最新文字考释与残片缀合结论,是目前收录最全、编排体系最规范的古文字数据集,可为早期汉字的定量研究与历时演变分析提供核心支撑。
甲骨文识别专用数据集
甲骨文识别数据集对每张图像进行密集标注,采用轴对齐或旋转边界框定位每一个文字区域。将拓片转化为精准标注的图像数据后,可为卷积神经网络(CNN)、Transformer、SAM 等检测模型提供训练样本,使模型能够在复杂裂纹、背景噪声、叠压字迹中精准分离单字。这类数据集不仅能加速释读等下游任务的数字化归档进程,还能以 ** 平均精度均值(mAP)、交并比(IoU)** 等客观可复现指标,将新模型与专家标注的金标准进行基准对比。
-
殷契文渊检测集发布于殷契文渊平台,包含 9823 张拓片图像与 9134 个标注文件,标注信息涵盖每张图像内单个文字的区域坐标。
-
OracleBone-8000收录《甲骨文合集》中的 7824 张甲骨拓片,标注 128770 个文字实例,具备高度不平衡、样本稀疏的特征。该数据集先基于深度学习场景文字检测算法,初步预测每个单字的边界框,再由专家完成句子级别的文字序列标注,实现细粒度标注。
ACCID⁵²ACCID 数据集同时构建偏旁级与字符级双维度标注,以此满足前述各类研究方法的使用要求。
O2BR²O2BR 数据集包含 800 张原始甲骨图像、4211 个目标边界框。数据在合规授权范围内,取自中央研究院历史语言研究所开放博物馆公开资源。数据集的标注与质量审核工作,由两名领域专家及一名资深甲骨文学者共同完成。
甲骨文缀合数据集
甲骨文缀合数据集一般收录高清完整甲骨拓片,以及经专家核验的残片缀合对应关系。通过提供残片之间的正负边缘匹配标签,能够让机器学习模型学习甲骨断裂轮廓、卜辞文字连贯性与地层匹配特征,大幅降低人工专家的检索匹配工作量。
该类数据集也为自动甲骨缀合算法与模型提供标准化评测基准,加快完整甲骨文物的复原重建,支撑后续历史、语言学与古文字学研究分析。以下为现有甲骨文缀合数据集介绍:
OB-Rejoin³⁴该数据集缀合成果均从《甲骨文合集》《甲骨缀合总目》《甲骨缀合五编》等典籍及多个数字资源库中人工整理筛选得到。包含 998 张涵盖多种书风的甲骨拓片图像,共计 249 组已确认的残片缀合对。该数据集仅对甲骨残片的上下边缘进行轮廓描边标注;由六名领域专家、两名资深甲骨文学者,使用数位绘图板及专业图像编辑软件完成全部标注工作。
COBD⁵⁴COBD 数据集包含 480 组可缀合甲骨轮廓曲线图像(共 960 张),以及 1083 张未经过核验的甲骨拓片图像。每组由上下两块甲骨残片拓片配对构成。
OBI-rejoin2OBI-rejoin2 数据集源自中国社会科学院历史研究所先秦研究室官网,收录 200 片完整甲骨、483 块可参与缀合的残片,由四名甲骨文专家完成标注。为还原甲骨真实断裂状态,标注人员依托专业知识,在完整甲骨的合理边缘处人工拆分,模拟中心断裂、边缘断裂等真实破损情形。该数据集开源开放,为后续缀合算法研发提供了可复现的实验支撑。
OBFI³⁵OBFI 数据集共含 5374 张甲骨图像,分为 ZLC、BZ、LS、DJ 四个子数据集,分别对应泛黄、高对比度、低对比度、灰度四种图像场景。数据集总计包含 138855 张目标区域图像,其中不可缀合区域 115893 张、可缀合区域 22962 张。
甲骨文分类与检索数据集
与识别数据集不同,甲骨文分类数据集以整张图像的全局类别标签为主,而非局部区域标注。目前主流的甲骨文分类、检索评测标准,均以甲骨文字的语义内涵为依据制定。下文介绍代表性数据集。图 7 展示了当前甲骨文数据集普遍存在的典型长尾分布类别特征。

• Oracle-20k⁴³首个大规模甲骨文数据集 Oracle-20k 取自汉字字源网站,包含 261 个类别、共计 20039 个甲骨文字样本集中的实例。数据集中字形均为后世依据原始甲骨拓片整理、改写而成的手写摹本。
• OBC306⁶⁹OBC306 取材于八部权威甲骨典籍著录,是目前体量最大的甲骨文数据集,共分为 306 个类别、总计 309551 个样本。但各类别样本数量差异悬殊,单类样本数从 1 个至 25898 个不等,呈现典型的长尾分布特征。
• Oracle-AYNU⁴⁴Oracle-AYNU 包含 2583 个类别、39062 个甲骨文字实例,每类样本数量在 2 至 287 个之间。所有图像均为二值图,统一固定为 64×64 像素尺寸。
• HWOBC⁷⁰HWOBC 为手写甲骨文字数据集,涵盖 3881 个类别、83245 个单字样本。图像统一分辨率为 400×400,采用专用字体 AYJGW,同类字形相似度极高。
• Oracle-50k⁷¹Oracle-50k 源自三个甲骨文专业数字网站,共划分为 2668 个类别、59081 个样本。数据集存在明显长尾分布,使其分类任务天然属于小样本学习研究范畴。
• OBI-IJDH(网址:http://www.ihpc.se.ritsumei.ac.jp/OBIdataseIJDH.zip)包含 29 个类别、655 张甲骨文字图像,标签为日语与英语混合标注。
• Oracle-250⁷²Oracle-250 收录甲骨文中使用频率最高的 250 个常用字。由于各类样本分布不均衡,研究者采用数据增强算法平衡原始样本量级,最终数据集总样本量达 92160 个。
• Radical-148⁷²Radical-148 基于甲骨文 148 种基础偏旁构件构建。研究招募 700 名志愿者手写甲骨文构件以均衡样本数量,最终生成 108989 个样本。
• OBI125⁷³OBI125 共 125 个类别、4257 个甲骨文样本,由上海博物馆馆藏甲骨(第一辑)经扫描归档整理得到。
• OBI-100³⁰OBI-100 包含 100 个甲骨文字类别,涵盖动物、植物、人文、社会等多种题材,总计 4748 个样本。
• Oracle-241⁷⁵Oracle-241 取自殷契文渊平台,包含 241 个类别、78565 张手写摹本及拓片扫描甲骨文字图像。
• ORCD⁷⁶ORCD 为甲骨文偏旁专用数据集,共 64 个类别,包含 1288 张拓片样本与 5412 个手写甲骨偏旁样本。
• OCCD⁷⁶OCCD 依托图像合成技术与线上手写甲骨文资源构建,总计 1320 个类别、62186 张图像。其中 54876 个字由单偏旁组合构成,7310 个字临摹自字库中已有的甲骨合体字。
• OracleRC⁵¹OracleRC 源自文献 [77],包含 2005 个甲骨文字,可划分为 202 类偏旁与 14 种字形结构关系。所有偏旁与结构关系均由 8 名语言学专家完成人工标注。
• Oracle-MNIST⁷⁸Oracle-MNIST 数据集源自殷契文渊平台,包含 10 个类别、30222 张 28×28 灰度甲骨文字图像。各类别样本数量相对均衡,单类样本数介于 2328 至 3399 个之间。数据集格式兼容经典 MNIST 标准,便于在现有分类器与算法上开展基准对比测试。
• OBI component 20⁷⁹该数据集面向构件级检索任务:输入一个甲骨文构件,检索所有包含该构件的甲骨文字。数据集涵盖 20 类基础构件,包含 9245 个甲骨文字、1012 张构件样本图。
甲骨文释读数据集
甲骨文释读数据集通常将裁切后的甲骨字形图像,与其对应的现代汉字或文字释义一一配对,为弥合古今字形演变差异提供监督学习信号。通过将未释读文字与已知字形、语义标注建立关联,序列生成模型与对比学习模型能够挖掘文字的语义规律与结构特征,为以往难以考证的甲骨文字提供候选释读结论。
• OBI-ECC⁸⁰OBI-ECC 取自国学大师网站,收录汉字历代字形演变图像,包含甲骨文、金文、篆书、隶书、楷书五种字体,共 972 个类别,每类含 5 张演变序列图像。
• EVOBC⁸¹EVOBC 涵盖汉字演变六大阶段:甲骨文、金文、篆书、春秋文字、战国文字、隶书。其中甲骨文部分包含 3077 个独立字种、75681 张图像。
• HUST-OBC⁸²HUST-OBC 包含 1588 个已释读文字(77064 张图像)、9411 个未释读文字(62989 张图像)。数据集实现甲骨文字与现代汉字精准对齐,便于对文字释读模型开展定性效果评估。
• ACCP⁸³ACCP 在 EVOBC 与 HUST-OBC 基础上拓展,新增两个历史时期文字数据:增补《康熙字典》清代文字 9354 个(公元 1662–1722 年)以及楷书文字 88899 个。
• OracleSem⁶⁰OracleSem 是基于 HUST-OBS 和 EVOBC 构建的语义增强型甲骨文数据集,融入多层语言学语义标注。对每个甲骨文字详细标注象形构形、结构组合方式及语义演变脉络;共收录 1762 个甲骨文字,每字配套 10 至 20 张图像。
• GEVOBC⁸⁴GEVOBC 为基于图结构的甲骨文演变数据集,由文献 [80] 改造而来。包含 756 组、共计 3780 张汉字图像,每组对应同一个汉字的五种演变字形。每张图像先做关键点提取,再依据笔画拓扑结构建立节点关联。
• PD-OBS⁶²PD-OBS 为多源象形释读甲骨文数据集,共 47157 条汉字标注数据,配套甲骨图像与详尽的偏旁象形解析文本。其中 3173 条数据关联甲骨图像,10968 条关联隶书图像。
• PictOBI-20k⁵PictOBI-20k 专为多模态大模型的甲骨文象形视觉释读任务设计,实现甲骨文字与现实场景的关联匹配。数据集包含 80 类象形字、15175 张甲骨文字图像,以及 4833 张对应实物图像,并构建多组问答样本对,用于测评多模态大模型性能。
新兴甲骨文数据集
除上述传统甲骨文处理任务外,诸多研究也针对甲骨文领域特有难题构建专用数据集。例如,现有甲骨文图像多为拓片形式,受拍摄条件限制存在严重画质退化,构建高质量甲骨文字数据集难度极大。
史等人提出 RCRN 甲骨文字图像数据集,包含 1467 组、139 对噪声 - 清晰图像配对,专门用于甲骨文字图像修复任务。此后李等人构建 Oracle-P15k 结构对齐甲骨文数据集,涵盖 239 个类别、14542 张图像,覆盖甲骨拓片四类典型噪声,适用于甲骨文字生成与去噪研究,大幅扩充了生成模型训练所需的甲骨文数据规模。
甲骨文数据集另一重要发展方向是多模态化。现有多数甲骨文数据集仅聚焦单一或少数维度标注,应用场景受限。为此,李等人构建甲骨文多模态数据集 OBIMD,收录 10077 件甲骨文物的完整标注信息:包含单字检测框坐标、文字类别、释文、所属卜辞组别以及组内文字阅读顺序等全维度注释。
同期发布的 RMOBS 数据集收录 900 余个已释读甲骨文字、超 2 万条数据条目,包含象形构件信息;每条数据由甲骨字形、概念释义、核心构件、边界框布局构成,可为细粒度甲骨文释读模型训练提供支撑。
总体而言,未来还将涌现更多面向特定任务的甲骨文专用数据集;尤其期待大规模开源、句子级甲骨语料库的发布,助力甲骨文与古文字领域专用大语言模型的训练与落地。
研究观察总结
本文在表 3 中从标签类型、应用用途、优势与局限性四个维度,归纳上述 36 个甲骨文数据集的核心特征。需说明:该整理不代表数据集存在优劣之分,仅从易用性、可验证性、可复现性角度为研究者提供选用参考。本文总结出如下几点结论:
第一,当前甲骨文数据集生态呈现规模与细粒度标注相互制衡的特点。OBC306、HWOBC 等大规模数据集可提供充足深度学习训练数据,但缺少高阶推理所需的精细结构与语义标注;反观 OBIMD、OracleSem 等数据集具备偏旁级、构件级深度语义信息,但整体规模偏小,类别多局限在数百量级。
第二,长尾分布仍是领域最顽固的固有局限,也是古代占卜卜辞留存下来的客观历史现状。
第三,HUST-OBC、EVOBC 等数据集缺少甲骨原始实物照片(仅有拓片),限制了模型在尚未制作拓片的真实考古发掘场景中的实际落地。
整体来看,甲骨文信息处理效果从根本上受制于底层数据质量。研究者需要重点攻克三大视觉难题:真实文物固有噪声、图像分辨率受限、类别分布极度不均衡。
甲骨文处理任务与研究方法
本小节仅综述基于人工智能技术的甲骨文处理方法。从研究范式来看,前文所述早期专家主导的经验研究方法范式较为单一,主要依靠文献考证与字形谱系比对开展工作。
甲骨文预处理:数据增强与图像合成
数据驱动的深度学习模型在甲骨文分析中的应用,从根本上受限于训练数据的数量与质量。通用计算机视觉任务依托海量高质量纯净数据集,而甲骨文研究面临独有难题,也使得数据增强成为刚需,而非可选优化手段。核心挑战来源于三大维度:文物物理破损、图像保真度偏低、数据统计分布失衡。
第一,甲骨文物历经千年埋藏与风化侵蚀,存在大面积自然损毁和人为破坏;出土遗存多为破碎残片而非完整甲骨,造成语义断裂与信息缺失,大量关键字形残缺、模糊甚至磨灭。
第二,早期甲骨文保存与传播的主要载体为拓片,拓片普遍存在图像保真度低的问题,伴随复杂背景噪声与纹理伪影。核心难点在于:真实文字笔画与甲骨表面自然裂纹、剥落缺损在视觉上极易混淆。若缺少有效的增强手段模拟各类真实噪声形态,模型难以从背景干扰中剥离纯粹的文字语义特征。
第三,现有甲骨文数据集普遍存在长尾分布与极端类别不平衡问题。直接在分布倾斜的数据上训练模型,易在大类样本上过拟合,同时无法泛化到稀有小类样本。
为解决上述问题,研究者通过多种方式优化、扩充数据集,包括几何变换、噪声注入、U-Net 网络、生成式合成(生成对抗网络 GAN、扩散模型等)。
传统数据增强采用旋转、缩放、翻转、仿射变换,模拟卜辞文字空间排布与书写风格的差异。相关研究进一步引入图像裁切、亮度调整、对比度调节,丰富数据多样性;同时叠加高斯噪声,模拟甲骨拓片的画质畸变退化。
但此类传统操作无法生成全新语义变化与笔画结构模式,启发式噪声注入方式过于简易,难以拟合真实拓片复杂的非平稳退化特征,易导致模型学习到无效伪特征。Orc-BERT 依托在大规模无标注汉字语料上预训练的自监督 BERT 模型,生成逐样本增强数据;再叠加高斯噪声,并通过像素点位偏移进一步提升数据多样性。
数据多样性。随后,生成模型的出现标志着数据增强领域迎来范式转变。此类模型能够生成属性可控、画质逼真的高质量样本,突破了传统几何变换的局限。
岳等人⁷³ 提出一种动态数据增强策略,利用 ** 瓦瑟斯坦梯度惩罚生成对抗网络(Wasserstein GAN-GP)学习并生成全新甲骨文数据集,再通过动态筛选器维持数据集样本分布均衡。文献 [94] 提出一种基于循环生成对抗网络(CycleGAN)** 的甲骨文数据生成方法,学习甲骨文字形图像域与真实样本域之间的映射关系。
无独有偶,高等人⁹⁵设计两阶段分解生成对抗网络,仅依托现有甲骨文样本完成数据扩充;模型学习单向映射,将低质量样本转换为高质量样本,同时保证生成图像的真实感与多样性。近期,李等人 ³ 基于稳定扩散图像翻译架构,融入字形与风格信息,构建可控伪甲骨文图像生成器,用于扩充长尾稀有字数据。具体而言,研究者可将易获取的甲骨文拓片作为噪声风格模板,把稀有甲骨文字的手写摹本转换为带真实噪声的拓片样式。
除扩充训练样本数量外,研究者还通过图像去噪与补全技术修复甲骨文拓片,提升文字可识别度。图 9 可视化展示了多种甲骨文去噪与补全效果。
杨等人⁹² 构建基于大核卷积注意力的 U-Net 框架用于甲骨文图像修复,该框架包含两个改进型 U-Net 网络,分别实现边缘补全与全局图像修复功能。文献 [99] 中,王等人引入两阶段生成对抗网络模型,融合双判别器结构以捕获图像全局与局部特征;同时提出空间注意力机制与多级融合损失函数,保障图像修复精度。
文献 [93] 设计一种基于 U-Net 的跨模态数据同质化模块,统一异构数据表征,将拓片图像转换为手写字形,规避拓片识别难题。刁等人 ¹⁰⁰提出字形提取驱动的图像生成网络,用于高精度甲骨文修复;以字符字形作为辅助信息,在保留原始字形结构的同时处理复杂图像退化问题。
同理,张等人⁹⁰研发面向甲骨文修复的结构感知扩散模型,内置自适应动态调节机制,可感知重建图像的层级结构特征。李等人⁴提出 OBIFormer—— 一种轻量化注意力甲骨文去噪框架,融合通道自注意力、字形提取与选择性核特征融合模块,在多个甲骨文数据集上取得优异去噪效果,同时具备较高计算效率。
此外,Orpaint⁹⁷利用扩散模型的反向生成能力,并引入视觉状态空间(VSS)模块¹⁰¹,相较于多头自注意力 U-Net 架构,大幅降低时间与计算开销,为甲骨文图像补全提供了高效、低成本的解决方案。
甲骨文识别
通常,甲骨残片出土后需经过识别流程,拆分提取独立单字,以支撑后续各类下游任务。本文遵循通用目标识别的标准定义 ¹⁰²,¹⁰³:甲骨文识别任务同时包含字符定位与字符分类(图 10),这也是本小节与甲骨文分类任务的核心区别。下文分别介绍基于传统模式识别与现代深度学习的两类方法。
传统模式识别方法
早期模式识别方法以人工设计特征提取与经典分类器为核心,包括结构描述子、笔画级图、方向梯度直方图与弹性匹配等技术。例如,周等人 ¹⁰⁴将甲骨文字视作无向拓扑图,提取拓扑特征以实现两阶段识别。孟等人⁸⁷提出四方向扫描标记法降低甲骨文拓片噪声,并开发基于模板匹配的甲骨文识别算法。
在文献 [105,106] 中,该团队进一步融合线条特征,在霍夫空间中开展相似度比对。屈等人 ¹⁰⁷通过分析甲骨文拓扑特征(如拓扑特征点、连通域、亏格)构建识别方法。然而,此类方法高度依赖繁琐的人工参数调优,且笔画分割算法鲁棒性较差,难以适配出土数万甲骨残片所呈现的复杂字形变体,可扩展性受限。

基于深度表征学习的识别方法
依托通用目标识别深度学习技术的飞速发展,甲骨文(OBI)领域的研究也向着更细粒度的目标演进:同时对图像中每一个字符实例进行定位与分类,输出目标边界框与置信度分数,量化每个字符存在的概率⁶˒¹³˒¹⁰⁸。近十年来,学界陆续提出大量自动甲骨文识别算法,融合 Fast R-CNN、单发多框检测器(SSD)、YOLO 及其各类变体模型。
文献 [110] 采用 Faster R-CNN 实现甲骨文字检测,并结合多尺度特征融合提升识别性能。孟等人 ¹¹¹ 对 SSD 模型进行改造,使其适配更高分辨率图像,满足小字识别需求。刘等人 ¹¹² 利用 K-Means 聚类算法,依据甲骨文数据分布特征重新设计锚框的尺寸与宽高比;同时提出空间金字塔模块,实现特征稳定与噪声抑制,获得更鲁棒的识别效果。藤川等人 ³¹ 先采用轻量版 YOLO-v3 完成粗识别,再通过 MobileNet 对未识别区域做二次精细检测。
在 YOLO-v3 多个优化版本基础上,王等人 ¹¹³、温等人 ³²、甄等人 ¹¹⁴、孟等人 ¹¹⁵分别将 YOLO-v4、YOLO-v5、YOLO-v8 应用于甲骨文识别任务,大幅提升了识别速度与精度。近期,熊等人 ¹¹⁶提出面向甲骨文检测的改进模型 FDW-YOLO(基于 YOLO-v12),设计特征聚焦扩散金字塔网络增强多尺度特征融合,并构建动态混合卷积块重构网络结构,使模型能够在复杂背景下自适应提取、融合有效特征。实验表明,FDW-YOLO 在 F1 分数与 mAP50 指标上均优于原生 YOLO-v12。
除此之外,李等人 ¹¹⁷以甲骨文字原型与对比损失作为监督信号,对甲骨文特征进行循环解耦,分离富含语义信息的字符结构特征,有效降低噪声对识别结果的干扰。与主流方法不同,付等人 ¹¹⁸利用多标签标注信息而非单一位置信息完成甲骨文检测;在骨干网络后接入伪标签预测器,学习每条卜辞的独有结构先验知识,进而提升识别精度。文献 [119] 中,陶等人以甲骨文字形库数据集为先验知识,通过聚类表征学习强化检测网络的特征提取能力。
此外,由于偏旁是构字表意的核心单元,研究者也开展了基于偏旁的甲骨文识别研究。文献 [76] 中,林等人结合最大稳定极值区域算法,完成甲骨文单偏旁数据标注;再融合多尺度特征隐式提取偏旁特征,实现偏旁检测。刁等人⁵² 预先定义 14 类字符结构(独体、包围、左右、上下结构等),采用分治识别策略,将字符拆解为偏旁开展识别,为零样本甲骨文字识别方法提供基准测试方案。
尽管相关研究已取得诸多进展,但挑战依然存在。在甲骨文信息处理全流程中,识别作为中间环节,其效果更多取决于数据分布、预处理保真度、字形多样性,而非模型架构本身。当前对识别网络的增量式微调优化,已难以满足甲骨文研究专家实际所需的模型可解释性要求。
甲骨残片缀合
人工智能技术推动甲骨文其他处理任务取得突破性成果,但残片缀合研究至今仍高度依赖人工、繁琐费力。图 11 展示了四种主流甲骨缀合依据。现有甲骨缀合方法可分为两大类:基于轮廓匹配的方法与基于深度学习的方法。
基于轮廓匹配的方法
早期缀合方法通常采用几何启发规则,人工提取轮廓特征完成匹配。文献 [22,26] 中,王等人针对甲骨断裂轮廓,提出轮廓碎片逐段检索匹配算法,以及基于形状函数运算的匹配方法。具体而言,采用弗里曼链码描述轮廓碎片,再通过级联傅里叶矩形状描述子完成特征匹配并给出缀合建议。特征计算完成后,待缀合甲骨碎片与候选碎片可分别表示为特征向量Fr与Fc,通过下述公式计算二者相似度: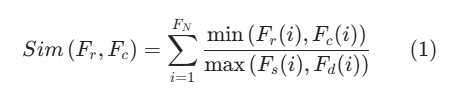 式中FN为特征向量长度。甲骨缀合系统可依据该相似度分值,判定两块残片是否能够拼接。
式中FN为特征向量长度。甲骨缀合系统可依据该相似度分值,判定两块残片是否能够拼接。
后续,田等人 ¹²⁰进一步优化曲线匹配流程,提出由局部到全局的曲线匹配算法:首先由专家将甲骨碎片轮廓曲线标红区分,再做位置校正统一尺寸与朝向;特征提取阶段记录曲线倾角与水平距离作为基础局部特征;采集坐标点获取全局离散点,并经高斯平滑去噪得到全局特征描述子;最后采用皮尔逊相关分析比对两组特征向量的相似度,同时结合曲线拟合度分析算法缩减候选匹配曲线数量。此外,文献 [33] 中,张等人将甲骨缀合任务转化为时间序列比对任务,把轮廓边缘曲线转化为数值时间序列,并设计容差相似度度量方法区分序列差异。
深度学习辅助缀合方法
多数基于深度学习的甲骨缀合方法,在轮廓表征阶段与传统方法流程一致,均采用边缘坐标匹配算法,仅在后续结果判别环节存在差异。例如,文献 [36] 提出深度学习自动缀合方案:先通过边缘等距匹配定位两块残片的边缘匹配位置,再利用卷积神经网络(CNN)评估目标区域的纹理相似度。同理,张等人 ¹²¹ 提出内部相似度网络实现甲骨残片自动缀合:先通过边缘等距匹配算法检索边缘片段对的相似坐标序列,再采用内部相似度池化层计算卷积特征梯度图的内部相似度。
近期,张等人 ³⁵提出最长相似边缘段算法与完整图像缀合方法,进一步提升边缘匹配精度。袁等人⁵⁴提出 SFF-Siam 网络,包含相似度特征融合(SFF)模块与骨干特征提取网络,分别负责输入特征融合与相似度评估。与上述方法不同,S³-Net³⁴融合生成对抗网络(GAN)与孪生网络,兼顾数据增强与轮廓曲线相似度度量,实现甲骨残片智能缀合。
此外,还有一项高度相关的甲骨文重复碎片检索任务,可归为同结构残片匹配研究,以张等人 ¹²² 的工作为代表。该研究设计渐进式重复碎片检索框架,融合低层关键点匹配与以文本为核心的内容匹配,结合语义感知筛选并排序候选重复碎片。具体采用 Superpoint¹²³、Lightglue¹²⁴两种无监督算法分别完成关键点提取与匹配;对每对图像做仿射变换实现坐标对齐;定位甲骨文字后,通过孪生网络计算内容相似度,完成重复碎片挖掘。
甲骨文分类与检索
甲骨文分类本质是学习映射函数![]() ,为输入甲骨文图像 x 预测字符类别 y。甲骨文检索则是给定一张查询图像,依据数据库候选图像与查询图像的语义、视觉相似度进行排序。受甲骨文字形多样、数据集长尾分布等特性影响,两项任务均极具挑战性。
,为输入甲骨文图像 x 预测字符类别 y。甲骨文检索则是给定一张查询图像,依据数据库候选图像与查询图像的语义、视觉相似度进行排序。受甲骨文字形多样、数据集长尾分布等特性影响,两项任务均极具挑战性。
监督深度学习
早期甲骨文分类模型基本沿用通用图像分类主流架构。开创性研究中,郭等人⁴³ 融合 Gabor 低层特征表征与稀疏编码器中层特征表征提取甲骨文字特征,与卷积神经网络模型形成互补。黄等人⁶⁹、刘等人⁴⁵、付等人 ³⁰在大规模甲骨文数据集 OBC306 及自建破损甲骨数据集上,对 AlexNet、VGG、ResNet-50、ResNet-101、Inception 等经典分类模型开展基准测试,为后续算法研发提供基线参考。
陈等人 ³⁸设计两步式甲骨材质分类方法:先检测盾纹、齿纹划分图像区域,再通过卷积神经网络提取各区域特征完成最终分类。高、梁二人⁸⁹利用甲骨文的同构性与对称不变性区分复杂异体字,保障分类精度。此外,江等人 ¹²⁸提出 OraclePoints 表征方法,将甲骨文图像建模为图像 - 点集混合神经表征,更高效区分文字与噪声;该方法可便捷嵌入现有模型,同时适配分类与检索任务。
甲骨文检索研究以深度度量学习为主流,在分类范式基础上优化距离度量规则。刘、王二人 ¹²⁹结合深度神经网络(DNN)与 K-Means 聚类实现甲骨文图像检索。丁等人⁴⁰采用孪生网络检索框架,学习相似 / 不相似图像的特征表征。为跨越数千年字形演变带来的巨大形态差异,吴等人⁴⁹提出跨字体甲骨文检索网络,基于孪生框架提取多字体字符深度特征,通过多尺度特征融合挖掘不同分辨率下的结构关联线索。
零样本与小样本学习
甲骨文研究普遍存在数据稀缺、分布失衡问题,天然适配零样本、小样本学习范式。吴等人 ¹³⁰提出 OracleGCD 广义类别发现框架,可同时实现已知字符识别、新类别发现与聚类;设计笔画感知非对称视图增强机制用于特征增强,同时构建对数置信度引导机制,实现虚拟标签监督对比学习。文献 [131] 中,胡等人提出 Ora-NSC 半监督分类方法,融合均值教师与 FixMatch 算法,依托指数移动平均策略提升伪标签预测的精度与稳定性。刘等人⁵³ 提出基于对比掩码频率建模的自监督学习方法 OBI-CMF,可同时提取甲骨文图像全局与局部特征;在空间域与频率域双维度学习特征实现跨域监督,显著提升分类模型的鲁棒性与泛化能力。
目前主流甲骨文信息系统均依赖专用数据库集合,仅支持检索已释读、已配对的已知甲骨文字。
由专业学者整理汇编而成。为降低对专家专属数据库的依赖,高绍涛等人⁴¹ 提出 ** 未知字符关联(LUC)** 方法,可检索任意甲骨文字符,涵盖已释读与未释读两类文字。
具体而言,该方法设计域感知嵌入模块,缩小手写字形与扫描拓片数据之间的特征差异,提升甲骨文偏旁原型特征的利用率;再通过核心特征聚合与维度升维层,生成统一且具备多样性的特征表征,用于文字匹配检索。
与甲骨文识别任务类似,研究者也利用偏旁信息辅助甲骨文分类与检索研究。刁等人⁵¹ 提出基于偏旁推理的零样本甲骨文识别框架,框架包含偏旁信息提取器与基于知识图谱的字符推理模块,可由甲骨文字检索匹配对应的现代汉字。
同理,为支撑更细粒度的甲骨文释读研究,胡等人⁷⁹提出构件级甲骨文检索任务:以单个甲骨文构件为检索输入,找出所有包含该构件的甲骨文字。研究构建双流注意力模型,并设计构件、字符两类三元组样本,建模构件与整字之间的内在关联关系。
跨模态学习
为解决甲骨文数据稀缺问题,王等人⁷⁵提出结构 — 纹理分离网络(STSN),对不同形态的甲骨文数据统一进行特征解耦、域变换、自适应适配与智能识别;充分利用海量手写甲骨文字样本开展跨模态生成,增强模型特征表征的判别能力。
近期提出的 OracleAgent⁶³ 智能体系统,进一步将甲骨文检索拓展至视觉 — 文本跨模态应用场景。依托智能体架构与完备的甲骨文知识库,OracleAgent 可借助自然语言交互,完成文字溯源、字形考订等多元化检索任务。
甲骨文释读
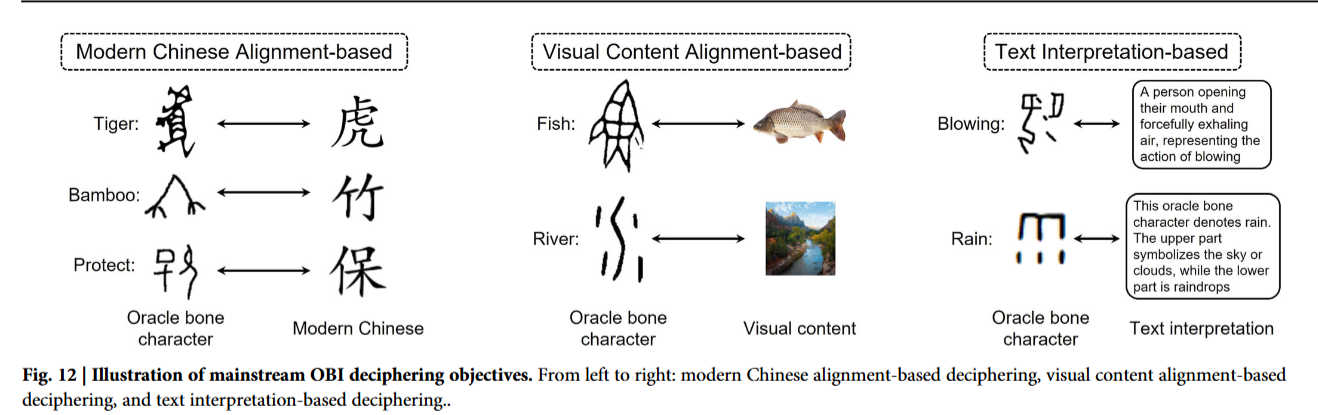
受字形抽象性、结构多样性、稀有字样本稀缺以及语境信息缺失等因素制约,甲骨文释读始终是极具挑战的研究难题。生成式模型的兴起极大改变了这一研究现状。依据释读目标的不同,现有甲骨文释读方法可划分为三大类(图 12):基于现代汉字对齐的释读、基于视觉内容对齐的释读、基于文本释义的释读。
基于现代汉字对齐的释读
不同于早期单纯依托识别任务的甲骨文释读思路,此类方法普遍采用生成对抗网络、扩散模型等生成式架构,建立甲骨文字与现代汉字之间的映射关联。
常等人 ¹³² 提出 Sundial-GAN 模型,首次利用多生成对抗网络的建模能力,模拟古文字字形演化过程,实现甲骨文字向对应现代汉字的转换生成。
在此基础上,关等人 ¹³³ 训练了条件扩散模型 OBSD,以已知类别甲骨文字作为条件输入,生成对应的现代汉字图像。依托所提出的局部结构采样策略,OBSD 在生成保真度与文字可识别性上,均优于以往基于 GAN 的模型框架。
为弥补 OBSD 模型语义对齐不足的缺陷,吴等人 ¹³⁴提出 DCSD-OBI 模型,将甲骨文图像与现代汉语文本同时作为双约束条件,在反向扩散过程中融合视觉特征与语义信息,强化字形结构重建与跨域语义对齐效果。
除上述生成式模型外,也有研究采用其他特征表征方式实现古今文字对齐。例如,文献 [91] 中,张等人以未知甲骨文字为查询样本,利用自编码器在特征空间中检索匹配的图像表征,同时将篆书、现代汉字等后世字形统一嵌入至同一特征空间。
文献 [80] 将小样本学习中的孪生网络与二元交叉熵损失结合,预测汉字字形的整体演化规律。
王等人⁸³ 提出 ** 拼图拾取器(P³)** 方法,先将甲骨文字拆解为基础笔画与偏旁构件,再通过 Transformer 模型重构为对应的现代汉字,显性建模古今文字的结构关联。
同理,胡等人 ¹³⁵提出构件级甲骨文分割模型,对甲骨整字与基础构件做独立分割处理,提升分割精度,进而加快文字考释与语义解读进程。
文献 [49] 以历代字形作为中间媒介,弥合古今字形形态差异,实现甲骨文字的有效释读。
受文字演化过程中字形元素相似性启发,焦等人⁸⁴采用图结构表征建模甲骨文与现代汉字:以图节点表征字符关键结构特征点,以边定义节点间的空间位置关系。研究验证,同一字族内部,图结构表征的相似度显著高于普通图像表征,为未释读甲骨文字的语义推理提供了可靠数据支撑。
然而历经数千年演变,原本具象象形的文字笔画,为追求书写效率出现拉直、简化、形变等变化,导致字符原始象形语义逐渐流失,这一现象在未释读甲骨文字中尤为突出,给现有释读方法的实际落地带来巨大挑战。此外,多数现代汉字生成失败案例仅输出无意义笔画线条,难以对甲骨文字义推断提供实质性参考价值。
基于视觉内容对齐的释读
相较于单纯的字形匹配释读,基于视觉内容对齐的释读能够修正语义偏移,搭建直观的认知关联桥梁,规避数千年笔画演化带来的字形混淆与辨识误差。作为开创性研究,乔等人 ¹³⁶开展大规模人因对照实验,验证受试者在合理视觉引导下,能否更精准地理解甲骨文字形本义。
在恰当的视觉引导下,人们能够更好地领会甲骨文字形的本义。同时,针对甲骨文数据极度稀缺、难以支撑模型训练的现状,研究设计了基于甲骨文字形及其语义的条件视觉生成任务。
V-Oracle¹³⁷ 依据象形造字原理,将甲骨文释读任务建模为视觉问答(VQA) 问题。该模型采用渐进式三阶段训练范式,依托象形字义解释实现高阶推理。
李等人⁶¹ 提出 OracleFusion 模型,引入具备增强空间感知推理能力的多模态大模型,使甲骨文字形表征更具结构性与可解释性。研究还提出字形结构约束语义排版方法,生成兼具语义完整性与空间位置精准性的实物形态释读结果。
近期,陈等人构建了 PictOBI-20K⁵ 视觉感知基准数据集,用于评测通用多模态大模型对象形甲骨文字的视觉释读能力。同时开展主观标注实验,探究人类与大模型在视觉对齐任务中的参考基准一致性,为优化视觉释读任务的注意力机制提供重要依据。
基于文本释义的释读
最受学界认可、也最直观的释读目标是生成文字释义文本。作为开创性探索,陈等人 ² 推出 OBI-Bench 评测基准,对 23 个多模态大模型开展系统测评,挖掘其甲骨文释读潜力。通过对不同字频、不同造字类型(象形、指事、偏旁变体等)的甲骨文字进行实验,完整刻画了大模型性能分布特征,为后续研究指明方向。
与此同时,江等人⁶⁰ 基于 LLaVA-1.5¹³⁸ 搭建跨模态甲骨文释读框架 OracleSage,融合层级视觉理解与图语义推理,提升文字释义的合理性。
文献 [62] 中,彭等人提出基于视觉语言大模型(LVLM)的可解释甲骨文释读方法,结合偏旁解析与象形–语义关联理解,弥合甲骨文字形与字义之间的隔阂,进一步提升释读过程的可靠性。
近期,李等人⁶³ 提出 OracleAgent,一款由大语言模型驱动的智能体系统,用于甲骨文信息的结构化管理与检索。依托自建大规模甲骨文知识库及多类甲骨文分析工具集成,OracleAgent 能够生成严谨可靠的文字释义,满足普通用户的多元化需求。
甲骨文处理模型评测
客观评价指标
甲骨文处理模型的评测方案,通常由具体任务类型决定。
甲骨文识别
针对需要完成单字定位的识别任务,评测体系基本沿用 PASCAL VOC、MS COCO 等通用目标识别基准。边界框层面主要采用两项指标⁵²:
1. 交并比(IoU)设预测边界框为![]() ,真实标注边界框为
,真实标注边界框为![]() ,交并比定义为:
,交并比定义为: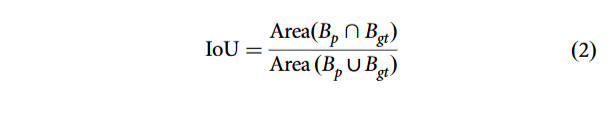
2. 平均精度(AP)与平均精度均值(mAP)精确率(P)与召回率(R)基于真正例(TP)、假正例(FP)、假负例(FN)计算。某类别 c 的平均精度为精确率–召回率曲线下面积;实际应用中常通过离散求和近似。平均精度均值为所有甲骨文字类别 AP 的平均值: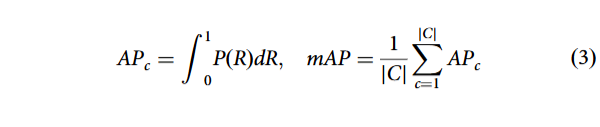
改进建议:标准 IoU 对边界框像素级对齐十分敏感,但甲骨载体(龟甲、兽骨)普遍存在画质退化与残片破损,像素精准对齐并不具备实际意义。因此本文引入笔画加权思路,提出结构加权交并比(SW-IoU)。该指标通过骨架提取,聚焦字符核心结构笔画而非风化残缺边缘;对遗漏关键结构特征的预测,施以比轻微边界偏移更严厉的惩罚。
甲骨缀合
残片级甲骨缀合目前尚无统一明确的评测指标。多数研究采用深度学习模型判别残片是否可缀合,再计算分类准确率 ³³˒³⁴˒⁵⁴、相关系数 ¹²⁰ 或置信度 ³⁶,以此支撑实际缀合效果验证。
甲骨文分类
甲骨文字分类常用 Top-k 准确率 与 宏平均 F1 分数:
1. Top-k 准确率设 y 为真实标签![]() 为按置信度排序的前 k 个预测类别;指示函数
为按置信度排序的前 k 个预测类别;指示函数 ![]() 条件成立取 1,否则取 0。
条件成立取 1,否则取 0。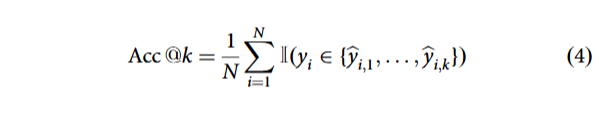 其中 N 为测试样本总数。
其中 N 为测试样本总数。
2. 宏平均 F1 分数为缓解甲骨文数据集普遍的类别不平衡问题,宏平均 F1 对每一类 F1 独立取平均。对类别![]() :
: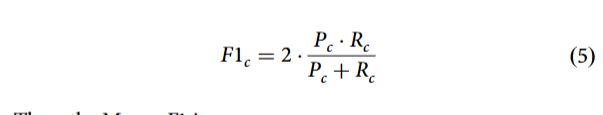 宏平均
宏平均 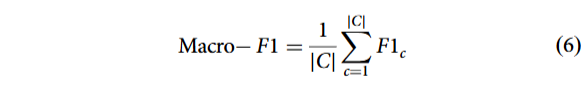
改进建议:甲骨文存在大量异体字(一字多形),标准准确率会因模型识别出学界认可的异体字形、却与标签字形不完全匹配而误判扣分,在多源数据场景下引入评测偏差。本文建议构建甲骨文异体字库:若模型预测为真实标签的学术公认异体字,可按预设衰减权重给予满分或部分分值,更贴合模型真实语义理解能力。
甲骨文检索
检索任务常用 Rank-k 准确率,衡量正确结果出现在检索列表前 k 位的概率。此外,与识别不同,检索 mAP 需纳入所有相关结果的排序信息 ²˒⁴¹˒⁷⁹˒¹²⁸,尤其适配单字多变体的甲骨文场景。
1. Rank-k 准确率设共 Q 个查询: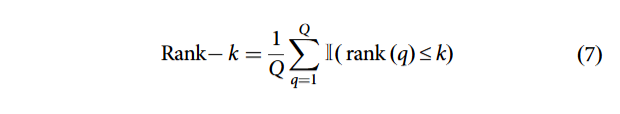 rank(q) 为查询 q 的首个正确匹配在检索列表中的位置。
rank(q) 为查询 q 的首个正确匹配在检索列表中的位置。
2. 检索平均精度均值对单个查询 q,Relk 表示第 k 位结果是否相关,P@k 为第 k 位精确率,Rtotal 为相关结果总数: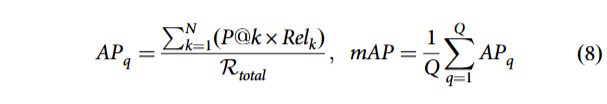
甲骨文释读
甲骨文释读评测按释读形式分为三类:古今汉字对齐、视觉内容对齐、文本释义对齐。
第一类常用识别准确率等 OCR 类指标⁶⁰˒⁸³˒¹³²˒¹³⁴˒¹³⁵。文献 [133] 提出 OBS-OCR 评测器,基于 ResNet-101²⁸ 在 88899 类现代汉字上训练分类器,用于评估扩散模型生成的释读结果。
乔等人 ¹³⁷ 将所有甲骨文字义统一设计为选择题形式,通过正则匹配大模型预测答案,计算与标准答案的准确率。
陈等人⁵ 提出视觉字符–实物对齐准确率,直接对比模型视觉释读与人类专业判读结果。OracleFusion⁶¹ 采用 CLIPScore¹³⁹ 评估生成字形演变图像与文本提示的语义相关性。
设 I 为生成图像,C 为文本提示;图像、文本分别编码为特征向量 ![]()
![]() 为缩放余弦相似度:
为缩放余弦相似度: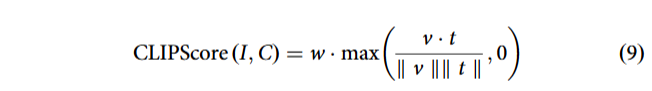 w 为缩放系数(通常取 2.5),用于对齐模型得分与人类主观评分;分值越高,视觉内容与文本描述匹配越精准。
w 为缩放系数(通常取 2.5),用于对齐模型得分与人类主观评分;分值越高,视觉内容与文本描述匹配越精准。
纯文本释义评测主要采用 BLEU-4 与 BERTScore²˒⁶¹˒⁶²,衡量生成释义与专家标准答案的一致性。
BLEU 是机器翻译经典指标,通过 n 元语法重合度评估文本生成质量: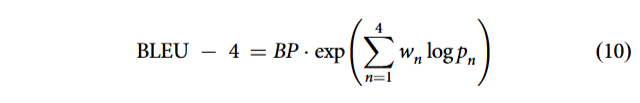
![]() 为修正 n 元语法精确率,
为修正 n 元语法精确率,![]() 为各阶权重(通常均为 1/4);BP 为短句惩罚,惩罚生成文本过短:
为各阶权重(通常均为 1/4);BP 为短句惩罚,惩罚生成文本过短: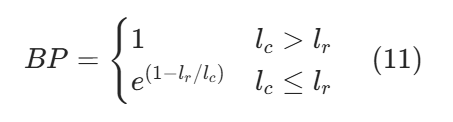
![]() 为候选文本长度,
为候选文本长度,![]() 为参考文本长度。
为参考文本长度。
不同于依赖字符串硬匹配的 BLEU,BERTScore 利用预训练 BERT 上下文嵌入评估语义相似度。设参考句 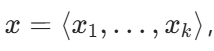 ,候选句
,候选句![]() 嵌入向量为
嵌入向量为 ![]() ,基于余弦相似度计算召回率、精确率与 F1:
,基于余弦相似度计算召回率、精确率与 F1: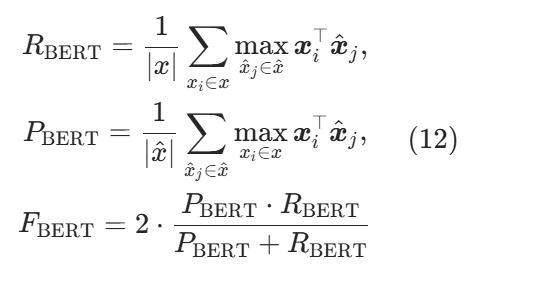
改进建议:现有 OCR 与文本释义评测均将文字视作整体,忽略偏旁 / 构件层级语义,不利于细粒度分析与模型优化。本文建议将甲骨文字拆解为功能构件,计算关键特征加权覆盖得分,即构件完整度分数(RIS):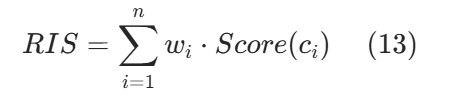
![]() 为第 i 个构件
为第 i 个构件 ![]() 在释读任务中的学术权重或知识图谱引导权重。
在释读任务中的学术权重或知识图谱引导权重。
甲骨文生成
甲骨文修复⁴˒¹⁰⁰、图像合成 ³ 等新兴生成任务,仍沿用 PSNR、SSIM¹⁴³、LPIPS¹⁴⁴、FID¹⁴⁵ 等传统图像质量指标。但已有研究表明,这类指标与甲骨文真实视觉质量相关性偏低,评测效果不佳、可靠性不足。自然图像与甲骨文图像在底层特征、失真类型、高维特征空间存在固有差异,为研发甲骨文专用生成评测指标带来新挑战。
人工主观评测
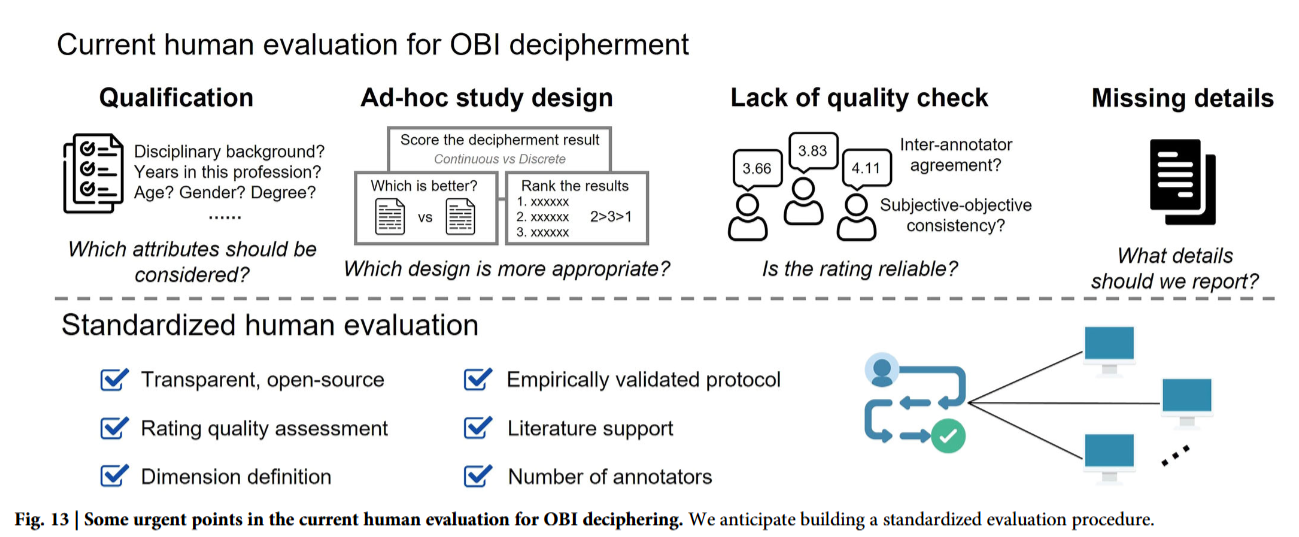
释读作为甲骨文信息处理的终极目标,涉及视觉感知与语言理解,必须依靠人工判读与验证。但目前尚无成熟统一的评测规范,各研究采用的评测方案差异较大 ²˒⁶¹⁻⁶³˒¹³³˒¹³⁷。多数研究仅粗略标注参与专家人数,缺少关键细节说明。
如图 13 所示,现有研究普遍存在:评测人员资质无界定、任务设计随意、缺少质量校验、细节披露缺失等问题,阻碍了各类方法的公平横向对比。多媒体主观评测、文本 / 图像 / 视频生成等领域已形成成熟的人工评测流程设计,具备重要参考价值。
借鉴相关领域经验,本文提出构建学界公认的甲骨文释读人工评测规范,并明确六大核心考量维度,保障评测可信、可对比:透明度、评分质量、评测维度、标注人员、文献支撑、实证有效性。
- 透明度:评测方案、流程、评分标准清晰可复现。建议完整公开大模型评测的提示工程方案,发布脱敏原始评分数据集,便于学界复盘评测逻辑、复现实验环境
评分质量
指人工评估者给出主观评分的可靠性与一致性。为降低个体主观偏差,建议采用 ** 评分者间信度(IRR)** 指标进行量化共识度,例如科恩卡帕系数(Cohen’s κ)、弗莱斯卡帕系数(Fleiss’ κ)。
评测维度
用于评价甲骨文释读、识别效果的多维度标准。摒弃简单的正确 / 错误二元判定,评测应包含三项核心指标:(a) 语义准确度:与权威文字学释义的契合程度;(b) 字形保真度:释读结果是否符合甲骨文字形的结构演变规律;(c) 语境逻辑性:释读文字在原始卜辞句法结构中的语句连贯性。
评测标注人员
指参与评测人员的人数、专业背景、学术水平及遴选标准。甲骨文研究门槛较高,本文将标注人员分为两类:领域专家(资深古文字学家)与专业受训从业者(古文字学方向研究生)。建议完整记录人员招募流程、从业研究经历,以及正式评测前为统一评分标准开展的校准培训过程。
文献支撑
评测基准真值必须依托权威学术典籍。所有评测均需以经典甲骨著录为参照标准,如《甲骨文摹本大系》¹⁸、《甲骨文合集》¹⁴。对于学界仍存争议的文字,评测规范需明确:是采纳主流共识释义,还是允许收录同行评审文献支撑的并行合理解释。
实证验证
用以证明所提评测体系能够真实反映模型实际应用能力的实证依据。建议开展人工评分与下游任务性能的相关性分析,保障评测框架的方法鲁棒性与实际应用价值。
挑战与展望
现存挑战
打破数据源壁垒
现代深度学习范式的效果,高度依赖大规模、高质量标注数据的可获取性。然而甲骨文研究领域存在显著矛盾:出土甲骨文物与相关研究资料数量庞大,但开源、机器可读的标准化数据集仍是领域发展的核心瓶颈。如表 2 所示,近十年发布的甲骨文数据集中,近半数实际无法公开访问。
目前,绝大多数高清甲骨文资源(拓片、高清实拍图、三维扫描数据)都封闭在数据孤岛中,多由博物馆、科研机构、私人藏家保管,受知识产权保护与实体访问权限限制。因此现有大量研究只能依靠各团队自建私有数据集开展实验。这类私有数据集虽能支撑孤立实验,却严重削弱了整个领域的学术严谨性。
想要突破壁垒,学界需走向开放科学体系:不仅要完成甲骨文物数字化,更要建立清晰的数据共享法律规范,平衡机构权益与学术开放可及性。未来领域发展,必须依托全面开放的甲骨文资源库,为各类下游任务提供标准数据库支撑。若无法打破数据源壁垒,高精度、泛化能力强的甲骨文专用基础模型研发将陷入停滞。
优化数据集构建流程
确定新研究方向后,需要构建或改造专用数据集,适配现代人工智能模型的输入格式。这要求建立适配甲骨文信息特征、稳定可靠的数据采集与处理流水线。
传统甲骨文数据处理完全依赖人工,校对、标注耗费大量人力与时间,且要求从业者具备极高专业知识门槛,对计算机等跨学科背景研究者极不友好。数据标注中的任何错误与学术争议,都会直接拉低模型可靠性。例如目前规模最大的甲骨文数据集 OBC306⁶⁹,已发现存在 120 处分类问题,涉及超 26000 个字符;同时存在 74 项分割标注疏漏,影响 80 个甲骨文字 ¹⁵³,作为分类任务验证集时会引入评测偏差。
当前高性能模型训练所需数据量持续增长,构建符合学界共识、自带质量管控与校验机制的自动化数据处理流水线,已成为亟待解决的现实问题。
甲骨文异构数据表征
早期甲骨文处理模型几乎仅支持图像、文本单一模态数据,难以适配跨模态应用场景。大量甲骨文知识以异构交错形式存在,给通用模型训练带来巨大挑战。
具体而言,同一个甲骨文字存在多种形态:原始出土实物、残片拓片、局部裁切图、人工手写摹本等(图 4);同时因甲骨契刻风格各异,一字存在多种字形变体;从文字历时演变来看,后世还衍生出多种传承字形。在甲骨文释读任务中,往往还需要融合多语言语境信息与现代文字释义。
这类复杂异构特征,难以用标准卷积神经网络、Transformer 架构完成有效表征与处理。亟需创新方法,将序列语言嵌入与复杂数据结构融合至高维知识空间,通常需采用多模态或混合架构实现建模。
未来研究方向
文本生成甲骨文
在生成式人工智能时代,可开展文本到甲骨文图像生成研究。现有甲骨文图像生成任务(去噪⁴、图像补全⁹⁹、图像合成 ³)均为图到图生成范式。
研发细粒度文本引导图像翻译模型、可直接将现代自然语言转换为目标甲骨图像的专用模型,能够助力含噪甲骨图像修复、文创内容创作、长尾稀有字数据扩充。这类专用文生图模型,还可作为历史语言学、认知符号学、数字人文领域的通用工具,形成可持续的文化内容生产链条。
构建甲骨文专用基础模型
通用多模态大模型具备强大推理能力,已在甲骨文各类任务中展现应用潜力 ²,尤其在稀有字释读场景优势明显。但通用模型缺乏古文字细粒度领域知识,与人类专家水平仍存在显著差距。
未来应优先研发甲骨文专用基础模型,以自然语言交互方式,统一处理异构形态、多模态的全流程甲骨文任务,服务一线考古与古文字研究者。
数据层面,采集构建大规模甲骨文专业语料库仍是核心难题:古文典籍与研究文献的理解需要深厚领域知识,且大量甲骨文以图像形式留存,如何高效提取构建语料、突破传统纯文本语料库局限,是关键研究难点。数据采集需兼顾对齐性、完整性、任务相关性、易用性、开放可及性核心标准。
甲骨文基础模型可将字形外观、结构规律、语义关联、考古背景等特征,统一编码至共享向量空间,为各类复杂下游任务提供底层支撑。
多智能体协同甲骨文检索与释读
大语言模型在内容创作、语义理解、逻辑推理等任务中表现优异,但仍存在模型幻觉、执行效率、能力缩放局限等固有缺陷。智能体 AI 以大语言模型为控制调度中枢,外接专业工具与知识库,可自主完成复杂任务的规划、分配、校验与优化⁶³˒¹⁵⁵⁻¹⁵⁷。
现有研究表明:单模态训练的传统模型,难以处理异构甲骨文跨模态信息检索;单一大语言模型受自身知识库局限,无法有效推理甲骨文字本义。
因此,未来核心方向为多智能体协同甲骨文检索与释读框架,搭建更高效、鲁棒、可信的知识网络,推动甲骨文普及研究系统落地;提升释读结果可解释性,支持历史学家对多种文字假说开展对比验证。
基于三维重建的甲骨文修复
现有甲骨文研究(数据集、算法方法)均依托出版物、网络资源中的二维甲骨数据,与原始出土甲骨实物存在巨大差异。当前三维表征技术飞速发展,可构建高保真文物模型与虚拟场景,应用于甲骨文领域,能够显著提升残片修复重建的视觉保真度、成功率与处理效率。
但受文物保护政策与原始甲骨数据使用限制,大规模开源三维数据采集暂不具备可行性。本文展望由官方牵头,研发包含 ** 体素网格、点云、网格模型、神经辐射场(NeRF)、三维高斯散射(3DGS)** 等格式的甲骨文三维数据集 ¹⁵⁸,推动甲骨文研究从二维范式向三维范式转型。
这不仅需要完善技术基础设施,更需要学界建立数据整理与开源贡献的激励机制。融合二维与三维甲骨表征,可构建更高质量、对齐更精准的标准化数据库,助力考古研究与文物数字化保护事业发展。
AIGC 赋能甲骨文文化传播
随着数字人文研究深化与智能技术迭代,AIGC 等新兴内容生成技术,将革新甲骨文文物保护模式,重塑文化遗产的认知与表达形式,推动甲骨文的创造性转化与创新性发展。
甲骨文科普教育的未来,或将依托AIGC + 多模态成像驱动的全新教学范式,以感知具身、沉浸式场景重构为核心。例如利用 AIGC 将甲骨文字形生成商代风格艺术作品,或根据用户照片生成专属甲骨文变体字形。这类形式可成为核心教学手段,弥合大众认知鸿沟、唤醒文化记忆,让学习者直观理解汉字构形逻辑。
结论
本文对甲骨文信息处理领域开展全面、前沿的系统性综述,首先梳理领域关键进展与范式变革里程碑;依次总结分析甲骨文识别、残片缀合、分类、检索、释读五大任务的数据集与研究方法;综述生成式模型甲骨图像生成与去噪、多模态大模型甲骨文释读、智能体跨模态甲骨检索等新兴研究方向。
文章进一步探讨数据质量、跨领域研究者认知差异、评测标准体系等现存问题,并展望风格化甲骨文生成、甲骨文专用基础模型等未来发展方向。
本文为相关领域研究者提供统一学术参考与前沿路线图,同时助力领域内学者梳理研究思路、把握发展趋势。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)