DeepSeek光速撤回的神秘论文讲了什么?
最近DeepSeek的识图模式开始灰度内测了。朋友圈里好几个人晒截图,传一张照片上去,它能认出里面的东西,回答你关于图片的问题。看起来是一个很朴素的功能,对吧,现在哪个大模型不会看图呢。
从Gemini系列一开始就做原生多模态模型,到包括Qwen和GLM等国产厂商纷纷推出视觉模型,DeepSeek的开源模型迟早会从纯文字走向文字与视觉融合。
但有意思的地方在于,就在内测消息传开的前几天,DeepSeek在Github上挂了一篇论文,叫「Thinking with Visual Primitives」。论文4月30号上线,5月1号就撤了。前后甚至不超过12小时。

一篇来自DeepSeek核心团队的论文,发出来一天就撤回。这件事本身就值得琢磨。
我花了点时间把这篇论文从头到尾读了一遍。它提出的问题,以及它试图解决问题的方式,精准地踩在了当前多模态大模型最核心的瓶颈上,给一个「夯」当之无愧!
我和大家分享一下这篇文章讲了什么
做多模态大模型的人都知道一个词叫「感知鸿沟(Perception Gap)」,模型在理解视觉内容时存在局限性,即使输入图像清晰,模型仍可能因处理方式不当而看不清细节,导致推理失败。
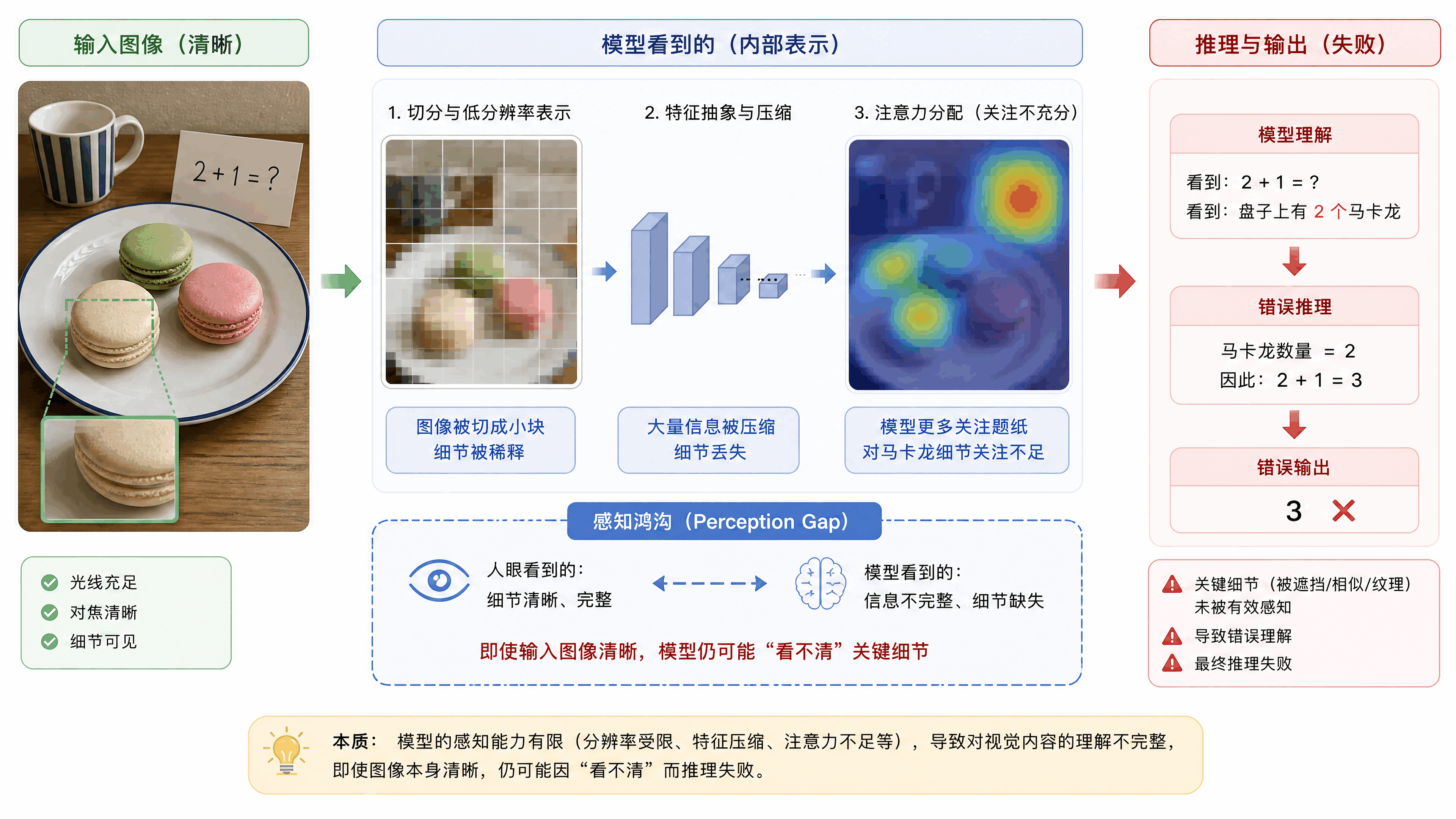
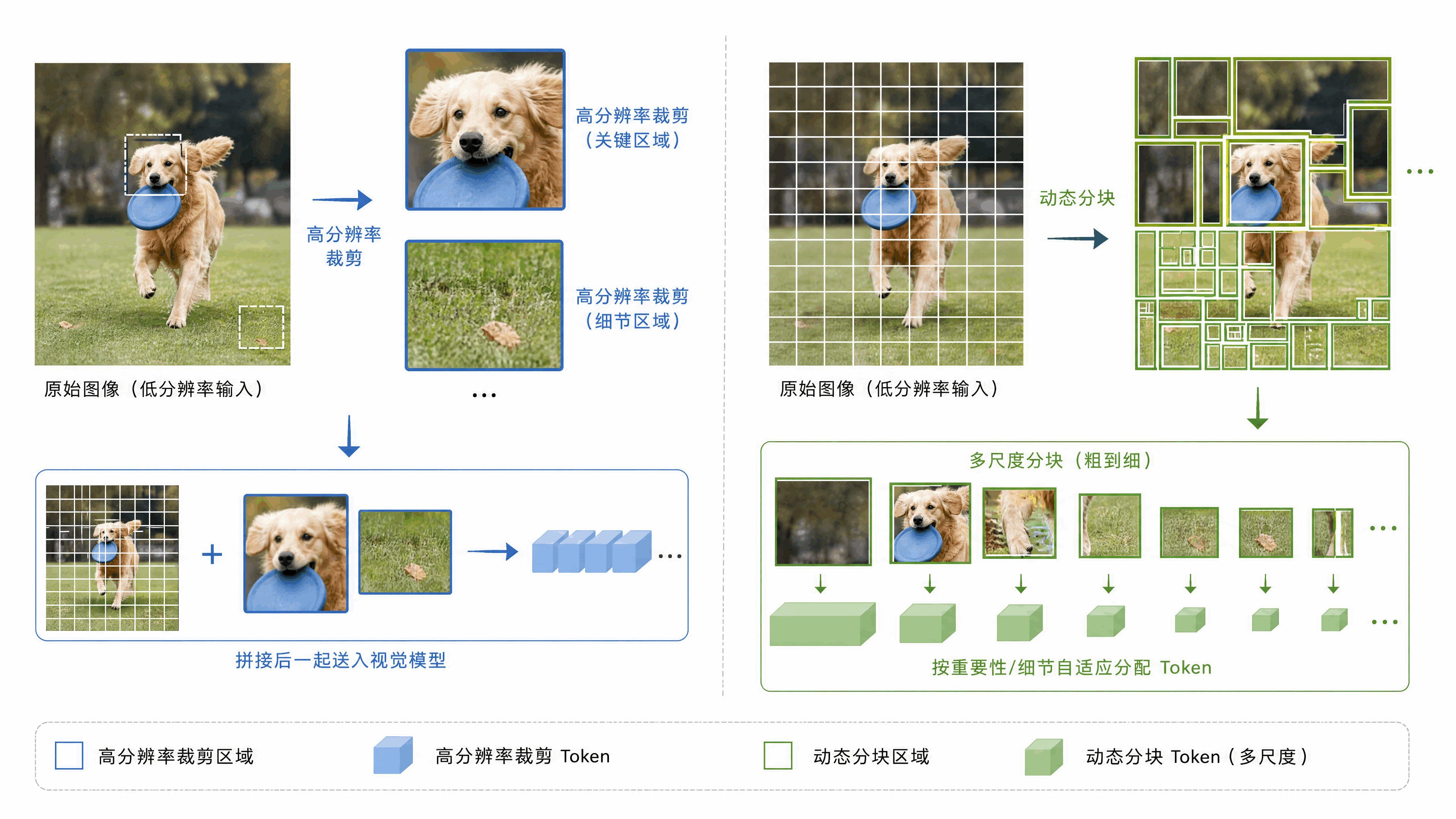
前沿模型的研发往往采用高分辨率裁剪(High-resolution Cropping)和动态分块(Dynamic Patching),图片分辨率太高,模型一次处理不了那么多像素,所以你得把图片切成小块,一块一块看,再拼起来理解。用图像思考(Thinking with Images)那条路线,还有InternVL系列模型(由上海人工智能实验室研发的开源多模态模型,具备领先的多模态通用感知和生成能力)这些方案,基本都在解决这个问题。
但这篇论文说,感知鸿沟不是视觉模型在实际需求处理中最根本的瓶颈。真正要命的是另一个东西,叫「指代鸿沟(Reference Gap)」。
什么叫指代鸿沟?举个例子。你给模型一张图,上面密密麻麻有50只鸟,你问它「最左边那只鸟在干什么」。模型要回答这个问题,第一步不是「看」,而是「指」。
它得先搞清楚你说的「最左边那只」到底是图上哪个位置的哪一只。但自然语言天生是模糊的。你说「最左边」,模型用语言描述它的推理过程时,它没法精确地指向图上的某一个像素坐标。
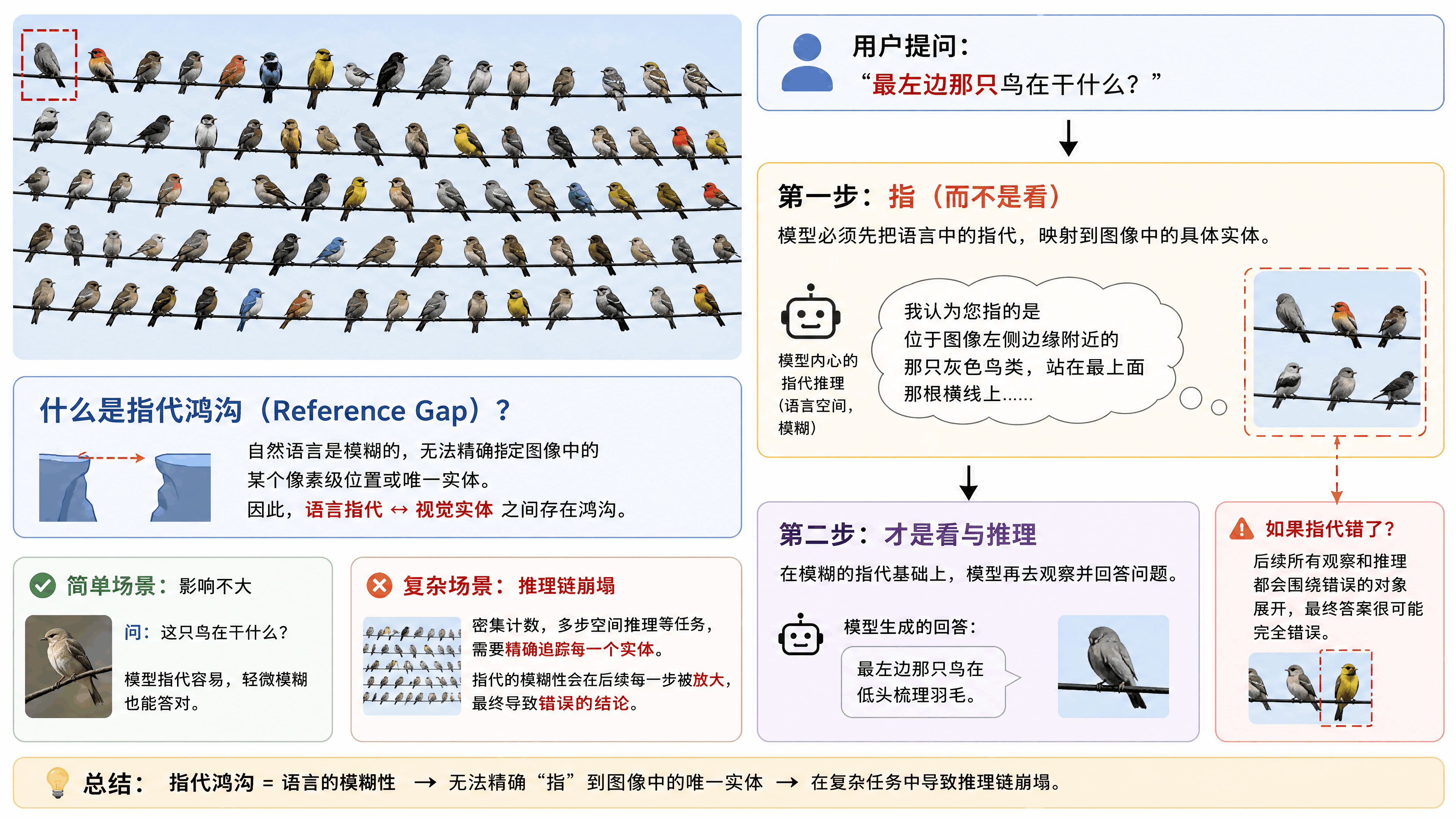
它只能用语言绕来绕去,「我认为您指的是位于图像左侧边缘附近的那只灰色鸟类」。这种模糊性在简单场景下问题不大,但一旦到了密集计数、多步空间推理这种需要精确追踪每一个视觉实体的任务上,语言的模糊性就会导致整个推理链崩塌。
论文里有一句话说得特别准,自然语言往往无法为复杂空间布局提供精确、无歧义的指针,导致需要严格定位的任务出现逻辑崩溃。
这就是指代鸿沟。
那怎么解决这个问题?论文提出了一个看起来很简单但执行起来非常复杂的方案,让模型在思考的过程中直接输出坐标。
具体来说,他们定义了两种「视觉原语(Visual Primitives)」。第一种是边界框(bounding box),就是用四个坐标画一个矩形框,圈出图上某个对象。第二种是点(point),就是一个坐标对,标出图上某个具体位置。
这两种东西在计算机视觉领域一点都不新鲜,目标检测、实例分割天天在用。但这篇论文的创新在于,它把这两种空间标记从「输出结果」升级成了「最小思考单元」。
什么意思呢?以前的模型做目标检测,是先「想」完,再「指」出答案。推理过程是纯语言的,最后输出一个框。但这篇论文的做法是,让模型在推理的每一步都嵌入坐标。它不是先想完再指,而是边想边指。
看论文里的一个例子。模型在数图片里有几只在地面上的熊。它的推理过程是这样的:
「我先扫描整个场景。我看到一只<熊>[452,23,804,411]攀爬在树干上,因为在高处,排除。再往下看,我看到一只<熊>[50,447,647,771]沿着岩石边缘行走,这只在地面上,计入。继续扫描,又发现一只<熊>[380,645,868,961]站在碎木和泥土中间,也在地面上,计入。三只熊中有一只在树上,两只在地面,答案是2。」
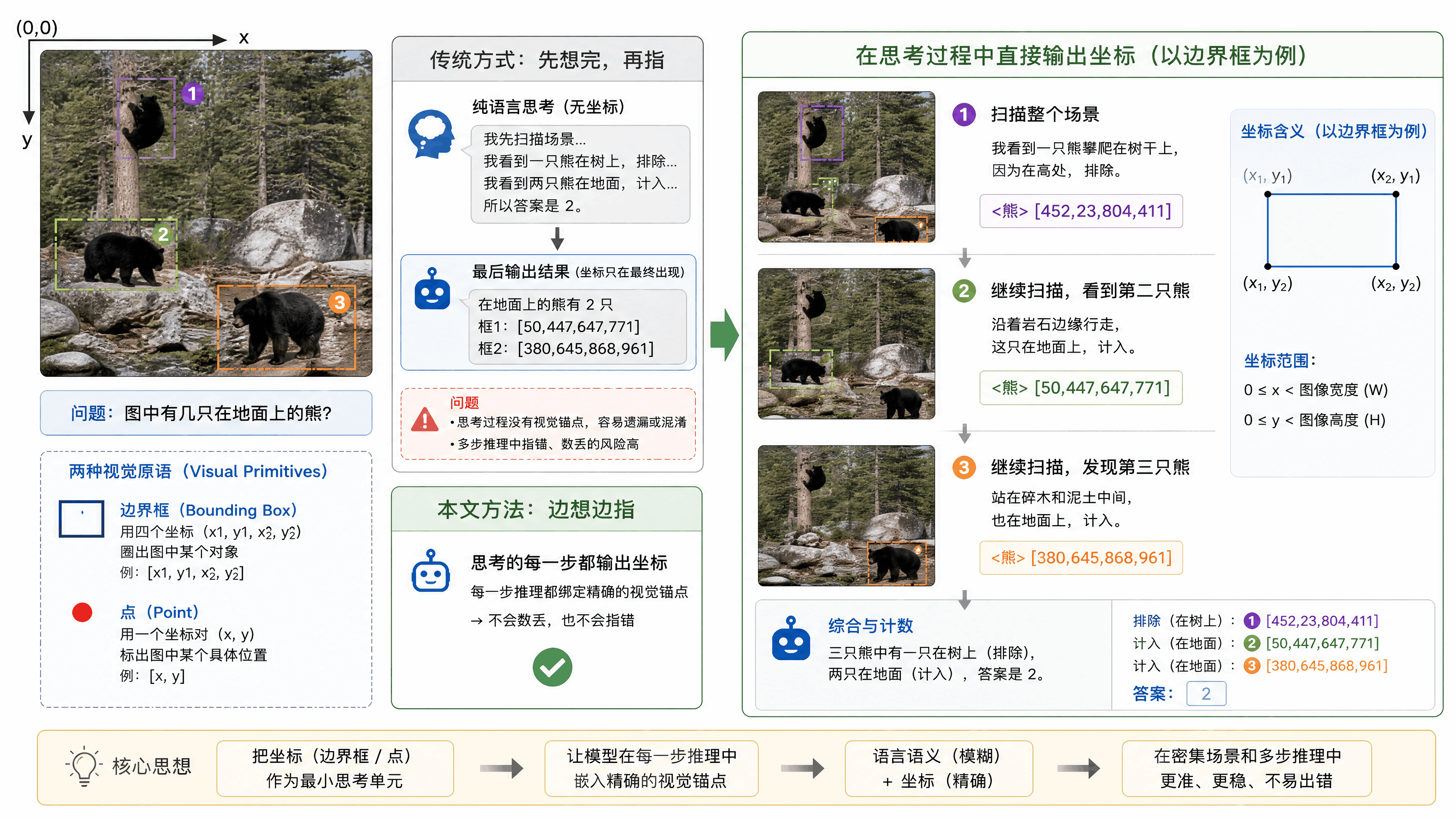
你注意到了吗?模型在每一步推理中都用精确坐标标记了它正在「看」的对象。语言描述「沿着岩石边缘行走」指向的是模糊的语义,但 [50,447,647,771] 这四个数字指向的是图上一个确定的矩形区域。当推理链上每一步都有精确的视觉锚点时,模型就不会在密集场景中「数丢」对象,也不会在多步推理中「指错」目标。
这个思路其实和人类的认知方式很像。你数一群人的时候,你不会在脑子里默念「左边第一个、左边第二个」,你会用眼睛一个一个点过去,手指可能还会跟着指。视觉锚定是人类空间推理的底层机制,这篇论文本质上是在给模型装上这个机制。
论文中的多模态模型是基于DeepSeek-V4-Flash构建,视觉编码器用的是DeepSeek-ViT。架构本身不算特别出彩,LLaVA那个范式,图片过ViT提取特征,和语言token拼在一起送进LLM。
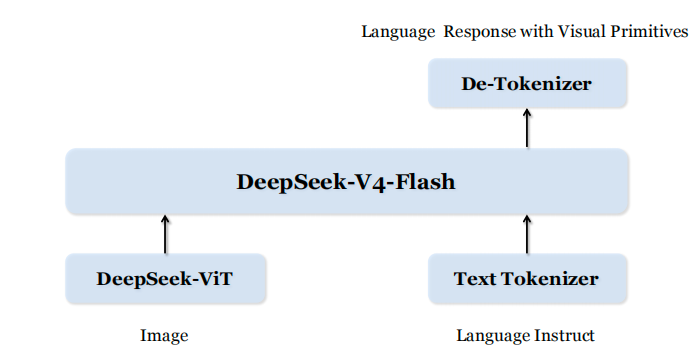
Token压缩是文章最惊艳的部分
一张800x800的图片,patch embedding(块嵌入,将图像分割成小块并转换为固定维度向量)之后产生2916个图像token。这个数字对于LLM来说太大了,每个token都要占KV Cache(KV缓存,通过缓存已计算的Key和Value矩阵,避免在自回归生成过程中重复计算,从而显著提升推理效率)的位置,token越多,推理越慢,成本越高。
论文做了两步压缩。第一步是空间压缩,每3x3个相邻的patch token(图像块的最小单元)压缩成一个token,2916个变成324个。第二步是利用DeepSeek-V4-Flash内置的Compressed Sparse Attention(压缩稀疏注意,先压缩部分不重要信息,再只计算重要信息)机制,对KV Cache再做4倍压缩。324变成81。
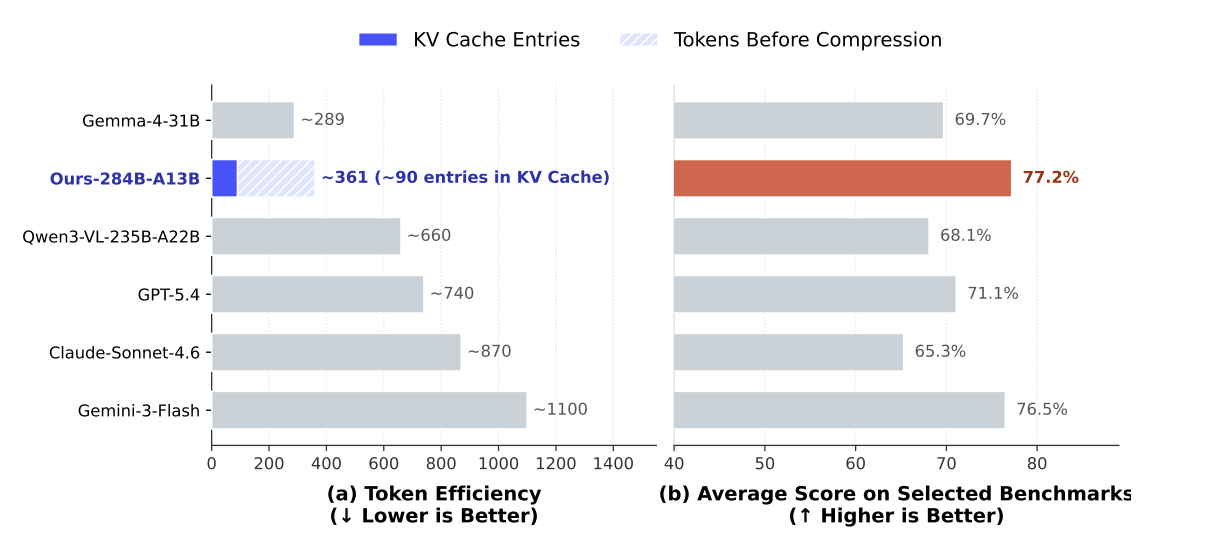
最终效果是什么呢?从原始像素到KV Cache条目,整体压缩比达到了7056倍。 一张800x800的图片,最终只占90个KV Cache位置。
做个对比。同一张800x800的图片,Gemma-4-31B要占289个token,GPT-5.4要740个,Claude-Sonnet-4.6要870个,Gemini-3-Flash更是要1100个。DeepSeek这个方案,token消耗量是Claude-Sonnet-4.6的十分之一。
但更关键的问题是,压缩这么狠,性能会不会大幅下降?
结果可能出乎很多人的意料。论文在7个基准测试上做了评测,包括计数、空间推理、迷宫导航、路径追踪这些任务。平均得分77.2%。作为对比,GPT-5.4是71.1%,Claude-Sonnet-4.6是65.3%,Gemini-3-Flash是76.5%。
用十分之一的token,拿到了最高的分数。
具体看几个细分任务。在迷宫导航这个任务上,DeepSeek的模型拿到66.9%,第二名是GPT-5.4的50.6%。在路径追踪上,56.7%,第二名是GPT-5.4的46.5%。这两个任务需要模型在图上做多步空间推理,恰恰是指代鸿沟最严重的场景。
在计数任务上,模型在Pixmo-Count(开源的视觉计数测试集)拿到89.2%,超过了Gemini-3-Flash的88.2%。在细粒度计数(需要区分「白色的大狗」和「左边那只狗」这种带属性约束的计数)上拿到88.7%,超过了Qwen3-VL的87.2%。
这些数字说明一件事,视觉原语方案不仅仅是一个「节省token」的技巧,它在需要精确空间推理的任务上确实带来了实质性的能力提升。当你给模型一个精确的坐标锚点,它就不会在密集场景里数丢对象,不会在迷宫里走迷路,不会在交叉线里跟丢路径。
光有架构设计还不够,怎么训练模型学会「边指边想」才是真正的难题。
训练大致分为五个步骤
第一步是预训练。在预训练阶段就让模型学会输出视觉原语的基本能力。这里有一个关键的数据工程问题,现有的公开数据集(比如COCO、Pixmo-Points)规模太小、多样性不够。论文团队从HuggingFace等平台大规模抓取了97984个边界框相关数据源。
但抓来的数据质量参差不齐。他们设计了一个两步过滤流程。第一步是语义审查,用一个MLLM自动检查标注的语义有效性,剔除三类问题:无意义的机器编码(比如类别名就是纯数字「0」「1」)、严重的标签语义模糊、以及有害内容。第二步是几何审查,检查标注框是否真的框住了目标对象,排除严重截断、偏移、以及占图像面积超过90%的「巨型框」。
经过两轮过滤,从97984个数据源保留了31701个,最终产出超过4000万高质量样本。
第二步是专项监督微调(Supervised Fine-Tuning)。论文分别用边界框数据和点数据训练了两个专家模型,一个擅长「用框思考」,一个擅长「用点思考」。为什么要分开训练?因为当专项数据量相对较少时,两种能力混在一起训练会产生模式冲突。
第三步是专项RL,Reinforcement Learning。这一步用的是DeepSeek-V4-Flash同款的GRPO算法,Group Relative Policy Optimization。论文设计了三种奖励模型从三个维度提供监督,格式奖励、质量奖励、精度奖励。
格式奖励检查模型输出的视觉原语格式是否正确,有没有生成重复的边界框(这能有效防止SFT模型陷入无限生成框的死循环)。质量奖励用一个LLM来评判推理内容的质量。精度奖励则根据任务类型做专门设计。
计数任务的精度奖励设计特别有意思。他们用了一个公式,奖励值和预测数与真实数的相对误差成反比,归一化项是真实数加1。这意味着在对象数量多的场景里,小偏差更容易被容忍。系数alpha设0.7,beta设3,通过实验调出来的,提供稳定平滑的学习信号。
迷宫导航的奖励设计也很巧妙。它包含「因果探索进度」和「探索完整度」两个子项。因果探索进度的逻辑是,模型一步一步探索迷宫,遇到第一次穿墙违规时截断后续探索(因为穿墙之后的所有步骤在因果上都是无效的),然后计算探索区域到终点的最短距离占最优路径长度的比例。这个设计奖励的是合法的、充分的探索行为。
第四步是统一拒绝采样微调(Rejection Fine-Tuning)。把两个专家模型的能力整合到一个模型里。
第五步是在策略蒸馏(On-Policy Distillation)。用两个专家模型作为教师,让学生模型在自己生成的轨迹上学习教师的输出分布。用的是Full Vocabulary Logits Distillation(全词表logit蒸馏,除了学习教师模型输出的正确答案,还将教师模型输出的软概率分布作为额外的监督学习信号),反向KL散度(倾向于在多峰中选择一个峰并拟合,在蒸馏工程中可以使学生模型在生成序列时收敛到老师模型的特定高概率推理路径,减少幻觉)作为损失函数。
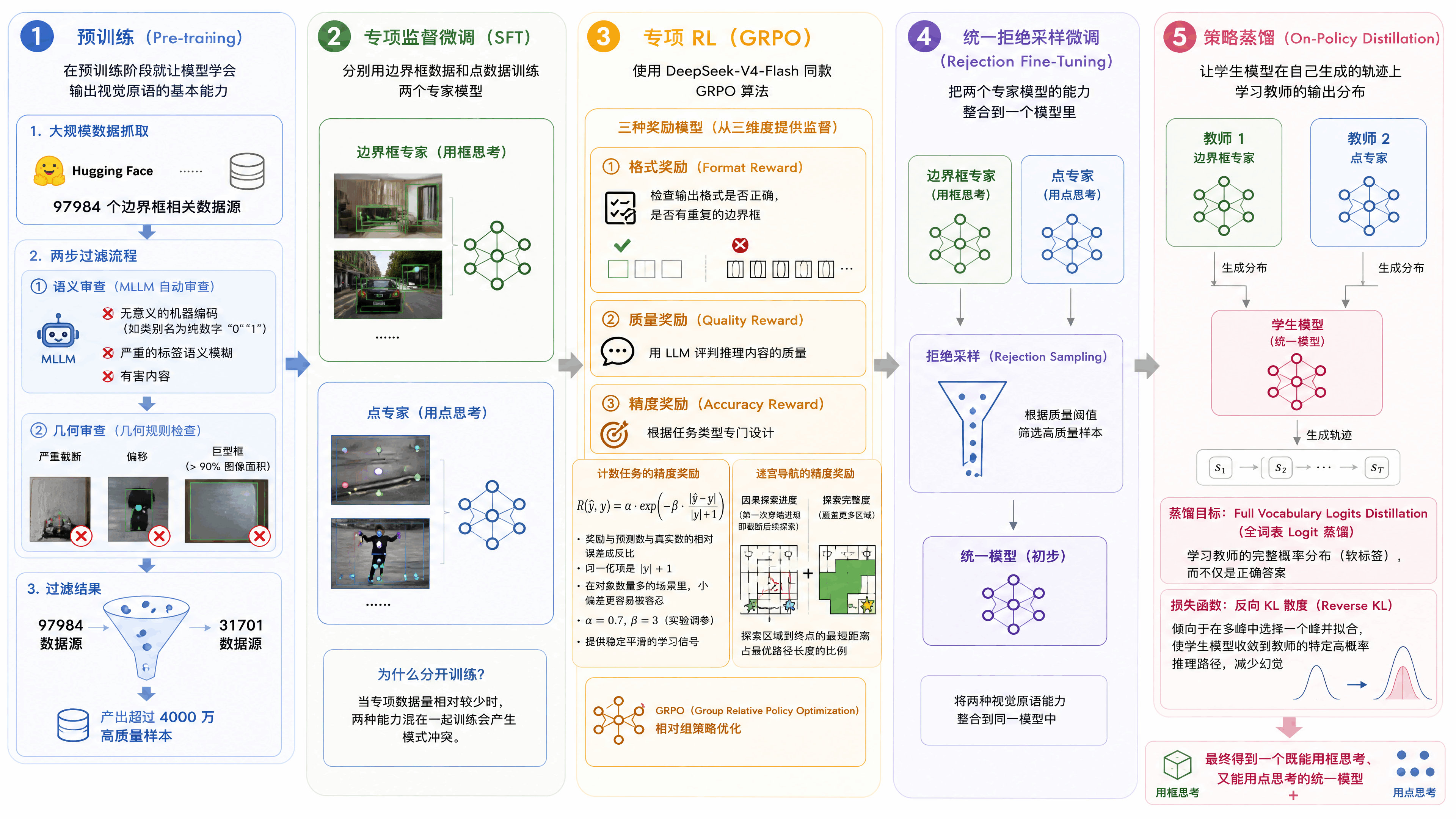
五步走完,最终得到一个既能用框思考、又能用点思考的统一模型。
论文围绕四类任务构建了评测体系
第一类是计数。分粗粒度和细粒度两种。粗粒度就是数「图里有几只狗」,细粒度是数「图里有几只白色的大狗」或者「左边那只狗旁边的狗」。现有模型在密集计数场景下表现很差,因为它们用语言逐一描述对象时会丢失对应关系。DeepSeek的方案是用边界框给每个对象打上精确锚点,「数一个框一个」。
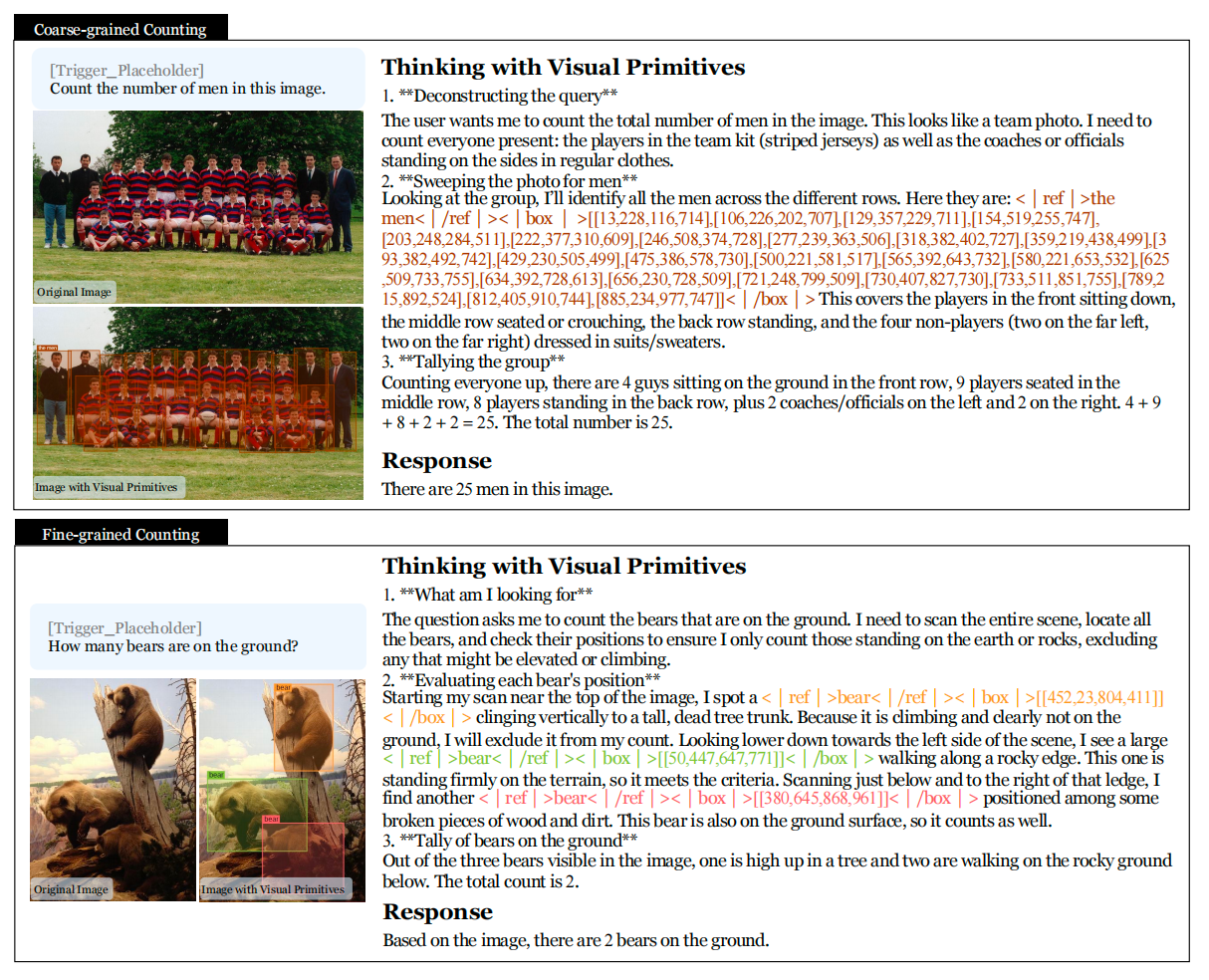
第二类是空间推理。包括多跳空间推理(「A在B的左边,B在C的上面,A在C的什么方位」)和具身空间理解(「你面前有一张桌子,桌子左边有一个杯子,你应该往哪个方向伸手」)。这些任务需要模型在推理过程中持续追踪空间关系。

第三类是迷宫导航。论文设计了三种迷宫拓扑,矩形网格、圆形迷宫(同心环加扇形分区)、蜂巢晶格。还专门设计了「不可解迷宫」,先生成一个可解迷宫,然后在路径中间故意加几面墙,让迷宫看起来可解但实际上需要完整搜索才能确认无解。难度通过网格大小控制,简单迷宫只需要几步局部连通性检查,噩梦级迷宫需要持续组合数百个这样的基本操作。

第四类是路径追踪。给一张有多条交叉线的图,模型需要沿着某条指定颜色的线从头走到尾。难点在于交叉点处所有线条宽度相同、颜色被剥离,模型只能依靠曲率连续性来判断该跟哪条线。这直接测试模型是否真正内化了路径追踪的原语能力,而不是靠颜色匹配来取巧。

跑分高固然厉害,但模型在真实生活场景下到底多聪明?
在原文的两个图例中,模型展现出了远超简单计数的能力,它将视觉原语与常识物理、世界知识甚至操作指南完美融合在了一起:
例如,在一组满是吉娃娃狗和蓝莓松饼的九宫格图片里,模型不仅没有被迷惑,反而精准地用坐标框出了所有吉娃娃的位置(排除掉了长得很像的松饼),然后告诉你准确的数字。这就要求模型既有语义级别的分辨力,又有精确的定位能力。

又比如,图里有一个天平,左边放着一个巨大的金属铁柜,右边放着一个半透明的彩虹小熊软糖。按常理铁柜肯定重,但天平其实是向右倾斜的。模型通过框选天平的托盘底座,敏锐地察觉到了「右低左高」的视觉证据,最终得出反直觉但符合图意的结论:小熊软糖更重。

还有,给模型一张风景照,问它「这附近有NBA球队吗」。它首先用视觉原语框出了画面中最重要的地标,认出这是旧金山的金门大桥。接着,它调动内置的世界知识,告诉你旧金山有金州勇士队(Golden State Warriors),完美回答了用户的提问。

还可以给一张全自动咖啡机和原料的图,问怎么做一杯拿铁。模型直接在图上框出了“咖啡豆包装”、“自动意式咖啡机”、“拿铁按钮”、“不锈钢牛奶壶”和“蒸汽棒”,然后一步步告诉你:先按框里的拿铁按钮,再用框里的蒸汽棒打奶泡……这已经具备具身智能(Embodied AI)大脑的感觉。

要理解这篇论文的创新性,得先看看现有的视觉方案都在怎么做。
我想先叠个甲,这里不讨论在底层统一成一套Token来原生处理的端到端原生多模态统一模型或一些早期融合(Early Fusion)的方向,只是讨论推理范式的问题。严格来说,不论是原生模型还是「ViT+Projector+LLM」的拼接模型,只要思考链还是基于语言的,就绕不开本文提到的「指代鸿沟」。
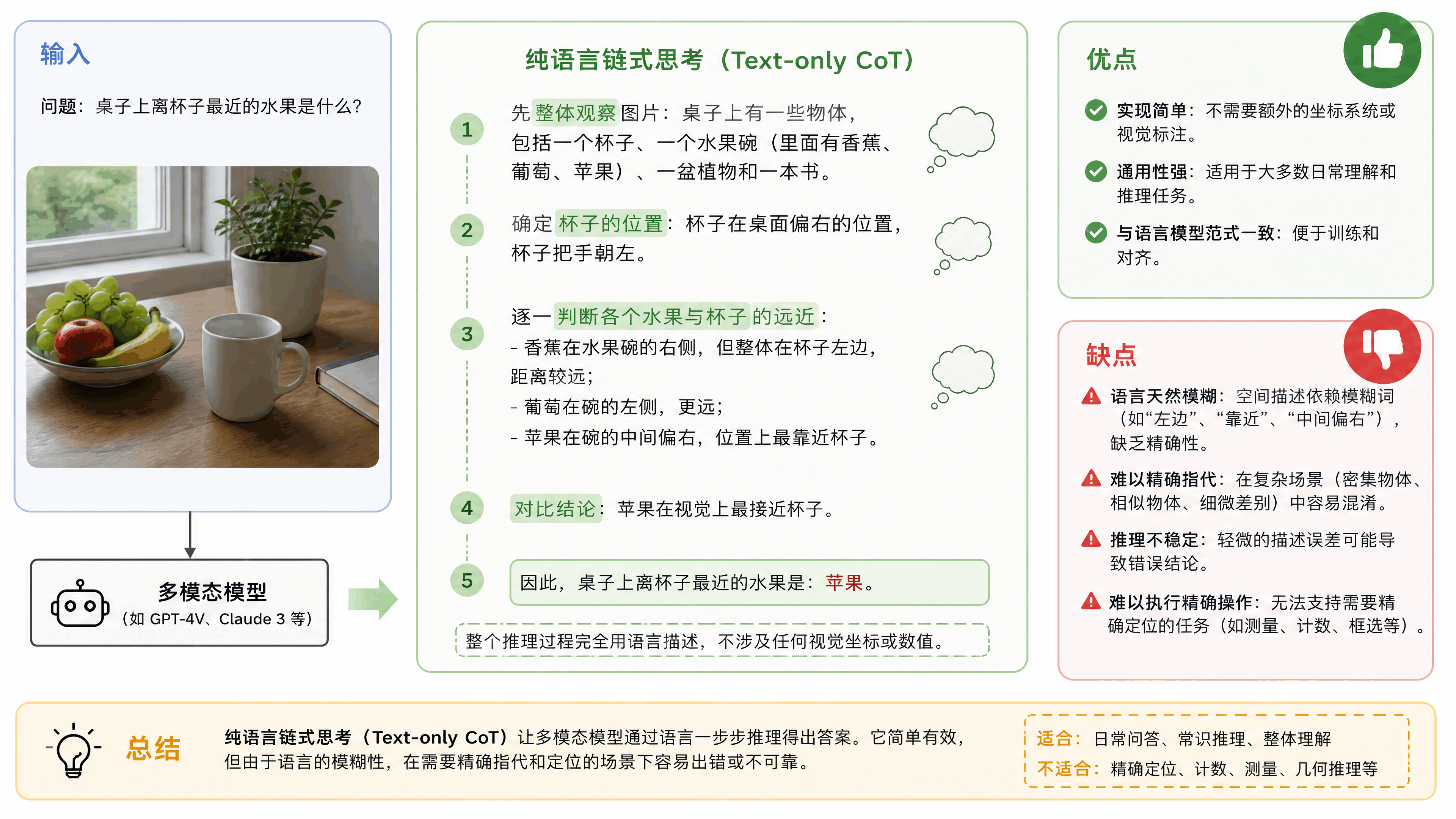
最早的方案是纯语言链式思考,Text-only CoT。GPT-4V、Claude 3这些早期多模态模型基本都是这个路子。模型的推理过程完全用语言描述,不涉及任何视觉坐标。好处是简单,坏处是前面说的,语言天然模糊,在需要精确指代的场景下会崩。
然后是前文提到过的高分辨率裁剪方案。把图片切成小块分别处理,解决的是「看不清」的问题。但看清楚了不代表能指准。你把一张1000x1000的图切成4块500x500的,每块都看清楚了,但当你需要同时引用第一块左上角的那只鸟和第三块右下角的那只鸟来做空间关系推理时,裁剪方案并不能帮你精确地「指」出来。
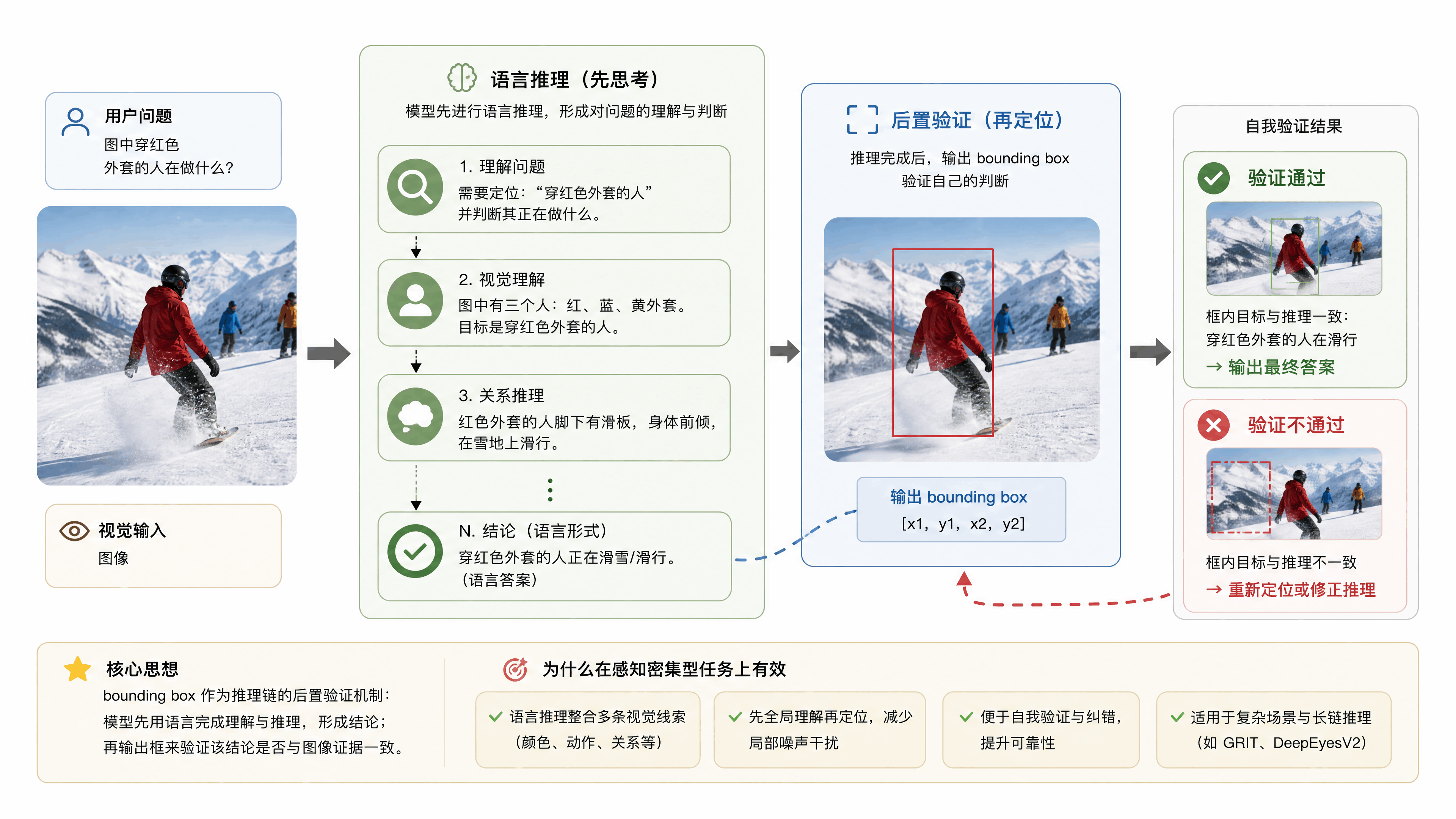
再往后是后置验证式视觉定位。GRIT和DeepEyesV2走的是这条路。它们把bounding box作为推理链的后置验证机制,模型先用语言推理,推理完之后再输出框来验证自己的判断。这个方案在感知密集型任务上有效,但论文认为它没有解决根本问题,在复杂结构推理中,视觉标记必须是思考的内在介质,而不仅仅是可验证的证据。
还有一条路是视觉定位推理(Visual Grounded Reasoning)。不少有关VGR和Traceable Evidence Enhanced VGR的文献都指向了这种方法,即把视觉证据融入推理链。但它们更多是把视觉定位作为推理的「辅助」,而不是推理的「本体」。
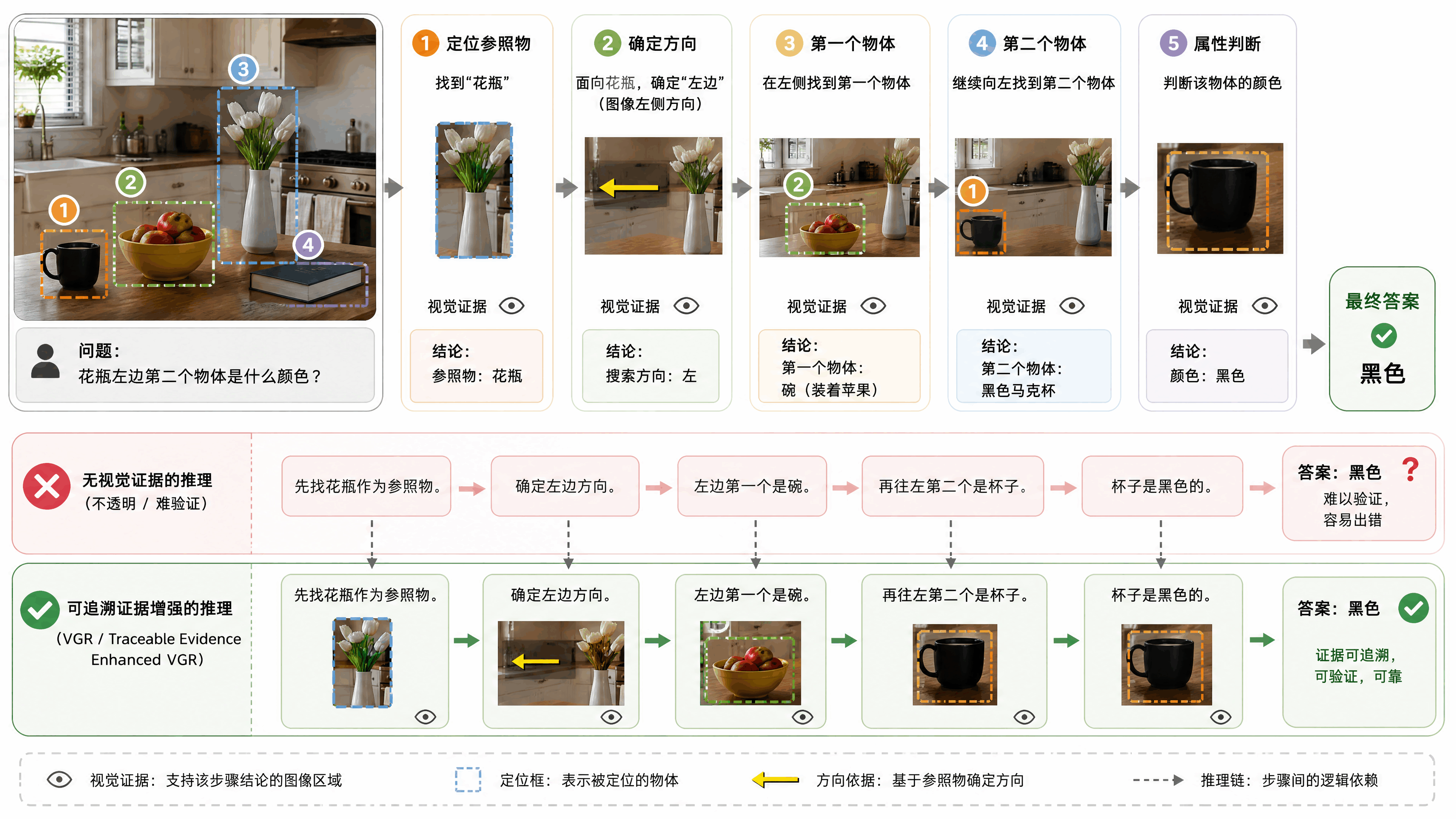
DeepSeek这篇论文的定位很清晰,它要做的是把视觉原语从「输出结果」或「辅助证据」升级为「最小思考单元」。模型不是先思考完再指,也不是指完来验证思考的对不对,而是在思考的每一步都指,用指来驱动思考。
这条路线和2025年另一篇论文Argus: Vision-Centric Reasoning with Grounded Chain-of-Thought(阿耳戈斯: 基于视觉定位思维链的视觉中心推理)有相似之处,但Argus更多是在架构层面做探索,DeepSeek这篇在数据工程、训练流水线、奖励设计上都走得更深。

论文也坦率地指出四点问题
第一,受输入分辨率限制,模型在细粒度场景下的表现还不够好,视觉原语的输出偶尔不够精确。论文建议可以把他们的框架和解决「感知鸿沟」的方法,比如高分辨率裁剪一起结合起来,取长补短。
第二,目前「用视觉原语思考」的能力需要显式触发词来激活。也就是说,你得在提示词里加上特定的指令,模型才会启动视觉原语模式。未来的目标是让模型根据具体场景自主决定是否调用这个能力。
第三,用点作为视觉原语来解决复杂拓扑推理问题仍然是一个巨大挑战,当前模型在跨场景泛化上表现有限。最后,我来补充一点,论文没有提到的是,整个方案高度依赖精心设计的奖励模型和大规模定制数据,这套流水线的可复用性和可迁移性还需要验证。
回到开头的问题
这篇论文为什么发出来一天就撤了?
可能的原因有很多。DeepSeek过去一年一直处于聚光灯下,学术界对其研究的原创性有着比一般机构更严格的审视标准。论文中的一些技术细节可能需要进一步验证或完善。也可能只是内部流程问题,论文还没准备好公开就被提前挂上去了。
但不管撤回的原因是什么,论文里的技术思路本身是值得认真对待的。
它提出了一个好问题。 指代鸿沟这个概念,比感知鸿沟更底层、更本质。不少多模态模型在空间推理上的失败,根因不是看不清,而是指不准。
它给出了一个可行的解法。 把坐标嵌入推理链,让模型边指边想,这个思路直觉上很合理,实验结果也确实支持。
它展示了一种可能性。 用十分之一的token消耗达到甚至超越前沿模型的性能,这说明多模态模型的竞争不一定是在「谁吃得更多」上,也可以在「谁吃得更精」上。
最近DeepSeek的识图模式开始内测,从产品形态上看,它目前还只是一个基础的图片理解功能。但如果你读过这篇论文,你会忍不住想,识图模式的下一步是什么?当模型不仅仅能「看懂」图片,还能「指着」图片里的具体位置跟你讨论,那才真正开始接近人类理解视觉世界的方式。
某种程度上,这篇被撤回的论文,可能比DeepSeek已经发布的很多论文都更能说明他们真正在想什么。 一个284B参数的MoE模型,用13B的激活参数,处理一张图片只要90个KV Cache条目,在迷宫导航上把GPT-5.4甩开16个百分点。这不是在堆参数、堆数据、堆算力,这是在认真思考「视觉智能的底层机制到底应该是什么」。
论文撤了,但问题留下了。指代鸿沟这个词,可能会在接下来一两年的多模态论文里反复出现。到那时候回头看,DeepSeek这篇一天寿命的论文,反而可能是一个重要的路标。
如果你对这类前沿AI技术的深度拆解感兴趣,可以关注这个号,给我点个赞,点个推荐。我会持续追踪那些被时间验证的选择。不追热点,只讲那些需要时间才能看懂的事。
你认为DeepSeek的识图模式好用吗?评论区聊聊吧。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)