人工智能篇---CLIP&BLIP
一、多模态的核心问题:模态鸿沟
在 CLIP 出现之前,视觉模型和文本模型基本是割裂的。视觉模型在 ImageNet 的封闭类别里打转,无法理解开放世界的文本概念。要连接二者,传统做法是:
-
图像标注:极其昂贵且受限于预定义的类别。
-
各自为战:NLP 和 CV 各用各的模型架构。
CLIP 的出现,用对比学习在十亿级别的图像-文本对上,把图像和文本首次拉到了同一个语义向量空间,彻底改变了游戏规则。
二、CLIP:打破模态壁垒的先行者
CLIP 由 OpenAI 在 2021 年初提出,全称是 Contrastive Language-Image Pre-training。它的核心理念简单却震撼:让模型直接在海量的网络图文对上进行预训练,学会图像和文本的对应关系。
1. 架构与训练原理
CLIP 由两个编码器组成,结构非常对称:
-
图像编码器:早期用 ResNet,后来用 ViT,负责把图像映射成一个高维向量。
-
文本编码器:使用一个标准的 Transformer 架构,负责把文本也映射到同一个维度的向量空间。
对比学习的核心是:在一个训练批次内,同时计算所有图文对的余弦相似度,构成一个相似度矩阵。训练目标就是让对角线上真正匹配的图文对的相似度最大化,而与批次内其他所有不匹配的对的相似度最小化。
这种方法让 CLIP 从几十亿个有噪声的图文对中,无监督般高效地学到了可迁移性极强的视觉语义特征。
2. 颠覆性的能力:零样本分类
CLIP 最惊艳的能力是零样本分类。它根本不需要在特定数据集上微调,就能直接进行分类。
-
操作方式:不再用固定的类别编号。比如做猫狗分类,就写出“一张猫的照片”、“一张狗的照片”这样的纯文本描述,把待分类图片和这些文本描述分别编码后,计算图片与哪个描述的相似度更高,就归为哪一类。
-
意义:这彻底告别了固定类别,模型的能力可以泛化到任何能用语言描述的开放世界概念上。
3. 影响与局限
-
影响:它的成功直接催生了 Stable Diffusion、DALL·E 2 等文生图模型,它们都用 CLIP 来理解文本并引导图像生成。
-
局限:
-
固守在“匹配”层面,不理解细粒度图像关系,难以直接进行看图说话或视觉问答。
-
对文本的编码方式比较简单,理解复杂长句和组合逻辑的能力偏弱。
-
三、BLIP:从匹配到生成的统一框架
BLIP 出自 Salesforce,全称 Bootstrapping Language-Image Pre-training。如果说 CLIP 是“判断图文是否匹配”,那 BLIP 系列就是“不仅判断,还能根据图像生成文本,并根据文本生成图像”,它是一个更统一的框架。
1. BLIP-1:多任务融合与数据清洗
BLIP-1 在架构上实现了三个功能的统一:
-
单模态编码器:一个图像编码器、一个文本编码器,与 CLIP 相同,但文本编码器使用更复杂的 BERT 结构,能更好地理解文本。
-
图文融合编码器:在自注意力中引入额外的交叉注意力层,让文本特征去深度融合图像信息,做精细的“图文匹配”判断。
-
图像描述解码器:用交叉注意力从图像特征中解码出描述文本,实现了“看图说话”的能力。
BLIP-1 的独门绝技是 CapFilt:
它先用有噪声的网络图文数据训练一版模型,然后用这个模型去“清洗”数据——为图片生成高质量描述作为额外“软标签”,同时对带噪声的文本描述进行过滤。用清洗后的高质量数据重新训练模型,效果获得巨大提升。这本质上是一种模型自主的数据增强与提纯。
2. BLIP-2:大模型的视觉适配器
BLIP-2 的核心贡献是引入 Q-Former,解决了一个关键工程问题:如何把一个预训练好的、参数冻结的视觉大模型和一个参数冻结的文本大模型高效地连接起来?
-
Q-Former 像是一个可学习的“翻译官”,它内部有一组少量可训练的“查询向量”,专门从图像编码器中提取与文本相关的信息,再转译成文本大模型能直接使用的向量。
-
这让 BLIP-2 只训练极少参数,就能站在 ViT 和 LLM(如 OPT、T5)两个巨人的肩上,实现了极强的零样本看图说话和视觉问答能力。
四、二者对比与演进关系
| 维度 | CLIP | BLIP |
|---|---|---|
| 核心范式 | 对比学习 | 对比 + 生成 + 过滤 统一框架 |
| 任务能力 | 图文匹配 (零样本分类) | 图文匹配、看图说话、视觉问答、图像检索 |
| 文本理解 | 基线级别 | 更强 (使用BERT类结构) |
| 关键技术 | 海量图文对对比 | CapFilt 数据清洗 (BLIP-1),Q-Former 高效连接 (BLIP-2) |
| 历史地位 | 多模态启蒙者,定义了图文对齐 | 多模态统一者,连接了视觉大模型与语言大模型 |
演进脉络:
CLIP 开创了双塔对比学习的范式,证明了海量图文对的有效性。BLIP 系列则站在 CLIP 的肩膀上,一面引入生成任务和数据闭环(BLIP-1),一面用 Q-Former 巧妙地撬动了大语言模型,让图文理解与推理能力发生质变(BLIP-2)。我们今天看到的 GPT-4V、Gemini 等模型,无不是这条技术路线的延伸。
五、总结框图
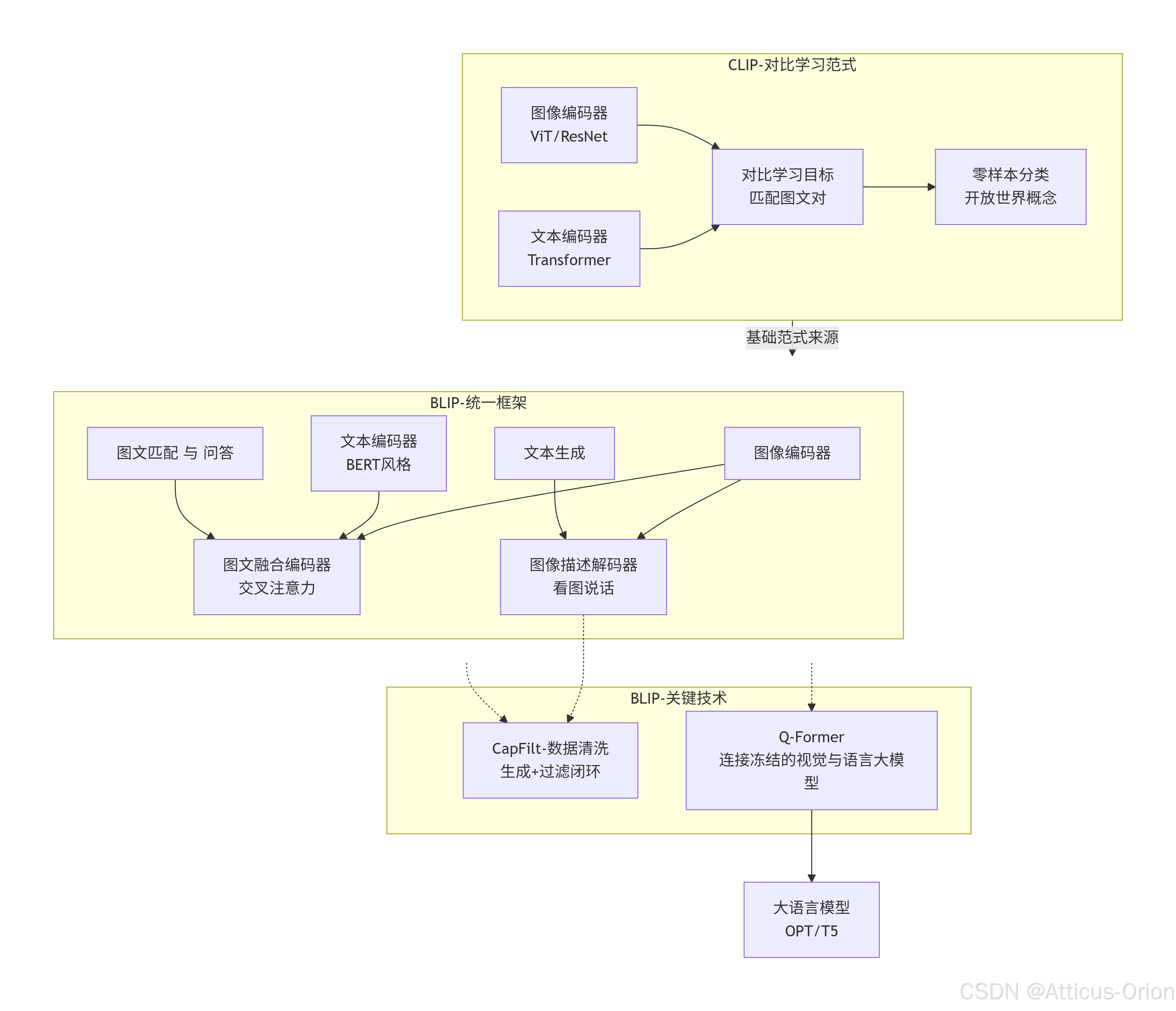
这张图清晰地展示了 CLIP 和 BLIP 的内在逻辑:CLIP 奠定了图文对齐的双塔基础,而 BLIP 在此基础上融合了生成、问答、数据闭环,并通过 Q-Former 把大语言模型引入,将多模态理解推向了推理与生成的新高度。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)