人工智能篇---MLOps
MLOps 中的版本管理远不止是给代码打标签,它是一套确保机器学习系统可追溯、可复现、可审计的核心实践。
下面从几个关键维度来展开。
一、为什么要做版本管理?—— 独特挑战
传统软件 DevOps 主要管理源代码。而 ML 系统多出了几个“会变动”的资产,让问题变得复杂:
-
数据是代码的“第二灵魂”:代码没变,但训练数据变了,模型行为会截然不同。
-
模型是“代码+数据+环境”的产物:环境里 PyTorch 版本细微差异、非确定性 GPU 算子,都可能导致模型无法复现。
-
实验是常态:数据科学家可能并行跑几百次实验,每次的超参、代码、数据都不同。没有版本管理,一切都会陷入混乱。
简单说,MLOps 版本管理 = 代码版本 + 数据版本 + 模型版本 + 环境版本 + 参数版本。
二、版本管理的四大核心对象
这是理解 MLOps 版本管理的基础框架。
1. 代码版本
这是最成熟的一环,用 Git。但 ML 项目需特别关注:
-
分支策略:除了主干,常设
experiment/分支用于特征探索,model/分支对应特定模型版本。 -
Git Submodule:将特征工程库或 ML 管线定义作为独立仓库引入。
-
Git Tag:为每个发版模型对应的代码提交打上 Tag,如
model-recommender-v2.1。
2. 数据与特征版本
这是 ML 领域最大的挑战之一。数据庞大且多变,不能简单存 Git。
-
数据版本控制工具:
-
DVC:最主流。像 Git 一样操作数据,产生
.dvc元文件(记录数据哈希)到 Git,数据本身可存 S3/GCS 等远端。 -
LakeFS:为数据湖提供 Git 式分支,隔离生产/实验环境下的数据变更。
-
Delta Lake / Apache Hudi:在数据湖内部实现时间旅行和版本回滚。
-
-
要管理的不是原始数据,而是“特征”:
-
Tecton / Feast 特征平台:核心价值之一就是管理特征的版本,确保训练时用到的特征取值逻辑,与线上服务时完全一致(避免训练-服务偏差)。
-
特征仓库:作为中心化目录,元数据记录着每个特征的版本历史、变更日志。
-
3. 模型版本
管理模型文件、元数据和血缘。
-
模型注册中心:
-
MLflow Model Registry:提供模型各阶段的生命周期管理。
-
其他选择:Kubeflow Model Registry, AWS SageMaker Model Registry 等。
-
-
模型版本的内容:
-
模型文件:如
model-v3.pkl。 -
血缘:记录此模型由哪个代码版本、哪个数据版本、哪个实验跑出。
-
元数据:创建时间、作者、模型指标(AUC)等。
-
阶段标签:
Staging(预发布)、Production(生产)、Archived(归档)。这是模型发版的关键机制。
-
4. 环境与管线版本
确保“在我机器上能跑”的魔咒被打破。
-
环境版本:
-
Docker 镜像:用
Dockerfile固化环境,镜像标签应包含依赖信息。 -
Conda / Poetry lock 文件:精确锁定 Python 包版本,必须被 Git 管理。
-
-
管线版本:
-
可执行规约:把整个 ML 流水线(数据->训练->评估)定义为代码(如 Kubeflow Pipeline 的 DSL)。它本身就成了一个版本管理的对象。
-
版本审计:能快速查出某次训练失败,是因为数据版本不兼容,还是代码逻辑被修改。
-
三、端到端的“发版”流程
一个健壮的 MLOps 版本管理,会把上述对象串联成一个可追溯的 ML 资产快照。流程如下:
-
代码提交:开发者 git commit 并 push,触发 CI。
-
环境锁定:CI 用 Docker 镜像的精确标签,或
conda-lock锁定环境。 -
数据版本化:流水线用 DVC 拉取
data-v2进行训练。 -
生成模型候选:执行管线,产出模型
model-v3.2和评估指标,并自动存入模型注册中心,标为Staging。 -
元数据绑定:注册中心将模型
model-v3.2、数据data-v2、代码abc123和参数绑定为一次不可变记录。 -
晋升:通过验收后,在注册中心将其阶段改为
Production。
四、主流工具矩阵
| 管理对象 | 核心工具 | 关键能力 |
|---|---|---|
| 代码 | Git (GitHub/GitLab) | 分支、Tag、Code Review |
| 数据/特征 | DVC, LakeFS, Feast | 数据哈希、分支隔离、特征定义版本化 |
| 模型 | MLflow Registry, Seldon | 生命周期阶段、血缘绑定、多模型管理 |
| 环境/管线 | Docker, K8s, Kubeflow | 环境依赖快照、可复现的管线定义 |
| 实验追溯 | MLflow, W&B, Neptune | 超参、指标、代码版本和数据版本的一次快照 |
| 全局元数据 | DataHub, Amundsen | 统一搜索、数据与模型血缘的端到端可视化 |
五、总结框图
这张图概括了各版本对象如何协同工作,构成完整的 ML 资产血缘链路。
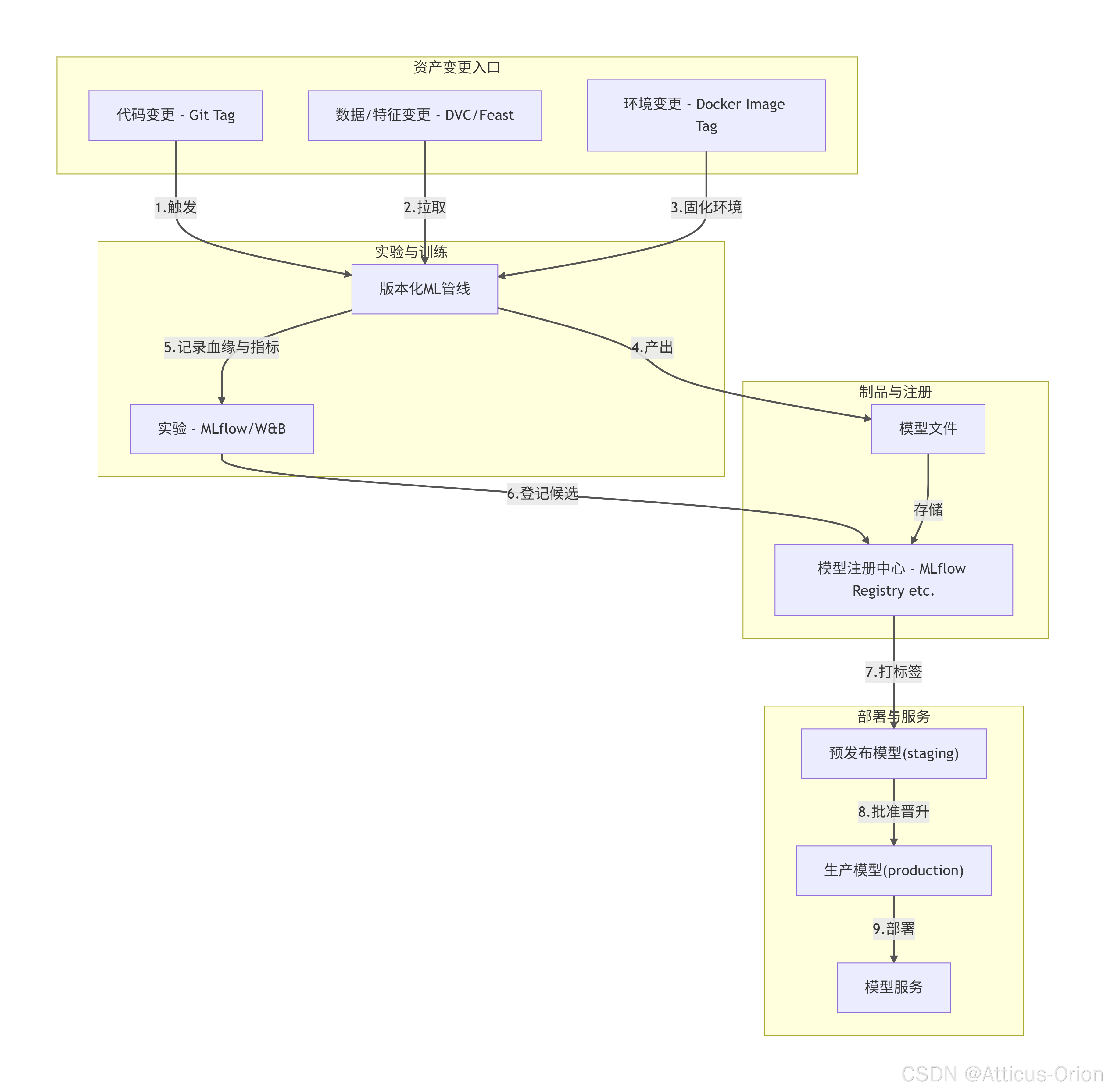
简单理解这张图:任何代码、数据或环境的变动,都会驱动一次自动化的管线执行,产出一个绑定完整血缘信息的模型,注入注册中心,再经过阶段晋升,最终部署上线。这就是 MLOps 版本管理的核心闭环。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)