【大模型技术报告】DeepSeek-V2:一个强大、经济且高效的混合专家语言模型
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-V2:一个强大、经济且高效的混合专家语言模型

摘要
我们提出了DeepSeek-V2,这是一种强大的混合专家(MoE)语言模型,具有经济性训练和高效推理的特点。该模型总参数为236B,其中每个Token激活21B参数,支持128K Tokens的上下文长度。DeepSeek-V2采用了创新架构,包括多头潜在注意力(MLA)和DeepSeekMoE。MLA通过将键值(KV)缓存显著压缩为潜在向量来保证高效推理,而DeepSeekMoE则通过稀疏计算以经济成本训练强大模型。与DeepSeek 67B相比,DeepSeek-V2在实现显著更强性能的同时,节省了42.5%的训练成本,减少了93.3%的KV缓存,并将最大生成吞吐量提升了5.76倍。我们在一个包含8.1T Token的高质量、多源语料库上预训练了DeepSeek-V2,并进一步进行了监督微调(SFT)和强化学习(RL),以充分释放其潜力。评估结果显示,即使仅激活21B参数,DeepSeek-V2及其聊天版本在开源模型中仍达到顶尖性能。
1.引言
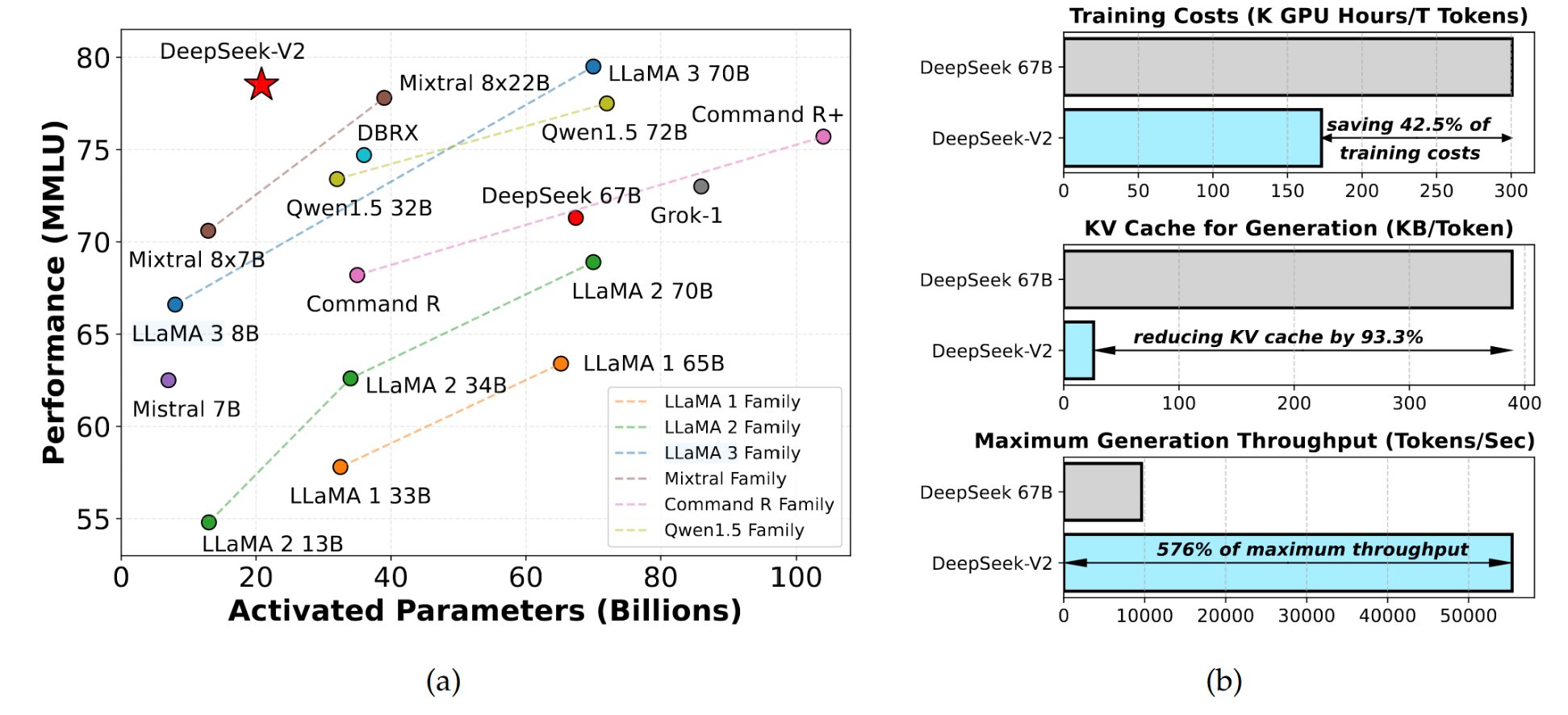
图1 | (a) 不同开源模型中MMLU准确率与激活参数的关系。(b) DeepSeek 67B(密集)和DeepSeek-V2的训练成本与推理效率。
在过去几年中,大型语言模型(LLMs)(Anthropic,2023;Google,2023;OpenAI,2022,2023)经历了快速发展,预示着通用人工智能(AGI)的曙光。通常,LLM的智能水平随着参数数量的增加而提升,使其能够在各种任务中展现出涌现能力(Wei et al.,2022)。然而,这种提升伴随着训练所需计算资源的增加以及推理吞吐量的潜在下降。这些限制构成了重大挑战,阻碍了LLM的广泛采用和应用。为了解决这一问题,我们推出了DeepSeek-V2,这是一个强大的开源混合专家(MoE)语言模型,其特点是通过创新的Transformer架构实现了经济高效的训练和高效的推理。该模型总参数量为236B,其中每个token激活21B参数,并支持128K token的上下文长度。
我们对Transformer框架(Vaswani et al., 2017)中的注意力模块和前馈网络(FFN)进行了优化,提出了多头潜在注意力(MLA)和DeepSeekMoE。 (1) 在注意力机制方面,多头注意力(MHA)(Vaswani et al., 2017)中的键值(KV)缓存对大语言模型的推理效率构成了显著障碍。已有多种方法被探索用于解决此问题,包括分组查询注意力(GQA)(Ainslie et al., 2023)和多查询注意力(MQA)(Shazeer, 2019)。然而,这些方法在尝试减少KV缓存时往往牺牲了性能。为了兼得两者之长,我们引入了MLA——一种配备低秩键值联合压缩的注意力机制。实验表明,MLA在实现优于MHA性能的同时,显著减少了推理过程中的KV缓存,从而提升了推理效率。 (2) 对于前馈网络(FFN),我们采用了DeepSeekMoE架构(Dai et al., 2024),该架构通过细粒度专家分割和共享专家隔离实现了更高的专家专业化潜力。与GShard(Lepikhin et al., 2021)等传统MoE架构相比,DeepSeekMoE架构展现出显著优势,使我们能够以经济成本训练出强大的模型。由于我们在训练中采用了专家并行,我们还设计了辅助机制以控制通信开销并确保负载均衡。通过结合这两项技术,DeepSeek-V2同时具备了强大的性能(图1(a))、经济的训练成本和高效的推理吞吐量(图1(b))。
我们构建了一个高质量、多来源的预训练语料库,包含8.1T个token。与DeepSeek 67B(我们之前的版本)所使用的语料库(DeepSeek-AI, 2024)相比,该语料库在数据量(尤其是中文数据)和数据质量上均有显著提升。我们首先在完整的预训练语料库上对DeepSeek-V2进行预训练。随后,收集了150万轮对话会话,涵盖数学、代码、写作、推理、安全等多个领域,以对DeepSeek-V2 Chat(SFT)进行监督微调(SFT)。最后,我们遵循DeepSeekMath(Shao et al., 2024)的方法,采用组相对策略优化(GRPO)进一步使模型与人类偏好对齐,并生成DeepSeek-V2 Chat(RL)。
我们对DeepSeek-V2在涵盖英文和中文的广泛基准测试上进行了评估,并与具有代表性的开源模型进行了对比。评估结果显示,即便仅激活210亿参数,DeepSeek-V2依然在开源模型中达到了顶尖性能,成为最强的开源MoE语言模型。图1(a)强调,在MMLU上,DeepSeek-V2仅用少量激活参数便取得了排名领先的性能。此外,如图1(b)所示,与DeepSeek 67B相比,DeepSeek-V2节省了42.5%的训练成本,减少了93.3%的KV缓存,并将最大生成吞吐量提升至5.76倍。我们还评估了DeepSeek-V2 Chat (SFT) 和DeepSeek-V2 Chat (RL)在开放式基准测试上的表现。值得注意的是,DeepSeek-V2 Chat (RL)在AlpacaEval 2.0(Dubois等,2024)上取得了38.9的长度控制胜率,在MT-Bench(Zheng等,2023)上获得了8.97的总体评分,在AlignBench(Liu等,2023)上获得了7.91的总体评分。英语开放式对话评估表明,DeepSeek-V2 Chat (RL)在开源聊天模型中具有顶尖性能。此外,在AlignBench上的评估显示,在中文方面,DeepSeek-V2 Chat (RL)超越了所有开源模型,甚至击败了大多数闭源模型。
为促进对MLA和DeepSeekMoE的进一步研究与开发,我们还面向开源社区发布了DeepSeek-V2-Lite,这是一个配备MLA和DeepSeekMoE的较小模型。其总参数为157亿,每个token激活24亿参数。关于DeepSeek-V2-Lite的详细描述见附录B。
在本文的其余部分,我们首先详细描述DeepSeek-V2的模型架构(第2节)。随后,介绍我们的预训练工作,包括训练数据构建、超参数设置、基础设施、长上下文扩展以及模型性能与效率评估(第3节)。接着,展示我们在对齐方面的努力,涵盖监督微调(SFT)、强化学习(RL)、评估结果及其他讨论(第4节)。最后,总结结论,探讨DeepSeek-V2当前存在的局限性,并概述未来工作(第5节)。
2.架构
大体上,DeepSeek-V2仍然采用Transformer架构(Vaswani等人,2017),其中每个Transformer块包含一个注意力模块和一个前馈网络(FFN)。然而,针对注意力模块和FFN,我们设计并采用了创新架构。对于注意力部分,我们设计了MLA,它利用低秩键值联合压缩来消除推理时键值缓存的瓶颈,从而支持高效推理。对于FFN,我们采用了DeepSeekMoE架构(Dai等人,2024),这是一种高性能的MoE架构,能够以经济成本训练强大模型。图2展示了DeepSeek-V2的架构概览,本节将详细介绍MLA和DeepSeekMoE。对于其他微小细节(例如层归一化和FFN中的激活函数),除非特别说明,DeepSeek-V2沿用DeepSeek 67B的设置(DeepSeek-AI,2024)。
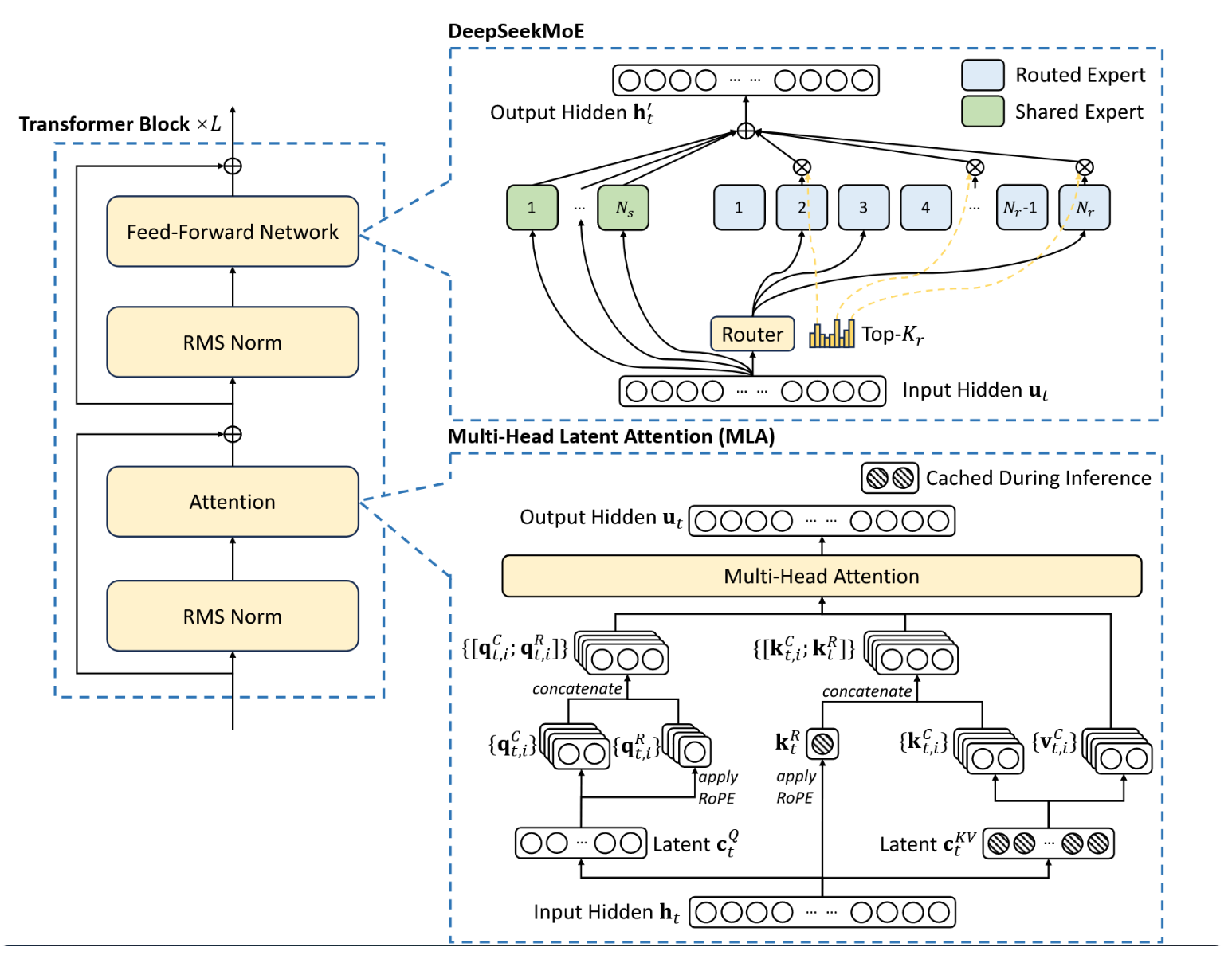
图2 | DeepSeek-V2架构示意图。MLA通过显著减少生成时的KV缓存来确保高效推理,而DeepSeekMoE则通过稀疏架构以经济成本实现强模型的训练。
2.1. 多头潜在注意力:提升推理效率
传统的Transformer模型通常采用多头注意力机制(MHA)(Vaswani等人,2017),但在生成过程中,其庞大的键值(KV)缓存会成为限制推理效率的瓶颈。为了减少KV缓存,研究者提出了多查询注意力(MQA)(Shazeer,2019)和分组查询注意力(GQA)(Ainslie等人,2023)。这两种方法所需的KV缓存规模较小,但其性能无法与MHA匹敌(我们在附录D.1中提供了MHA、GQA和MQA的消融实验)。
对于DeepSeek-V2,我们设计了一种创新的注意力机制,称为多头潜在注意力(MLA)。凭借低秩键值联合压缩,MLA在性能上优于MHA,但所需的KV缓存量显著减少。下文将介绍其架构,并在附录D.2中提供MLA与MHA的对比。
2.1.1. 预备知识:标准多头注意力
我们首先介绍标准的多头注意力(MHA)机制作为预备知识。设 ddd 为嵌入维度,nhn_hnh 为注意力头数,dhd_hdh 为每个头的维度,并令 ht∈Rd\mathbf{h}_t \in \mathbb{R}^dht∈Rd 表示注意力层中第 ttt 个 token 的输入。标准 MHA 首先分别通过三个矩阵 WQ,WK,WV∈Rdhnh×d\mathbf{W}^Q, \mathbf{W}^K, \mathbf{W}^V \in \mathbb{R}^{d_h n_h \times d}WQ,WK,WV∈Rdhnh×d,生成 qt,kt,vt∈Rdhnh\mathbf{q}_t, \mathbf{k}_t, \mathbf{v}_t \in \mathbb{R}^{d_h n_h}qt,kt,vt∈Rdhnh:
qt=WQht,\mathbf{q}_t=W^Q\mathbf{h}_t,qt=WQht,
kt=WKht,\mathbf{k}_t=W^K\mathbf{h}_t,kt=WKht,
vt=WVht,\mathbf{v}_t=W^V\mathbf{h}_t,vt=WVht,
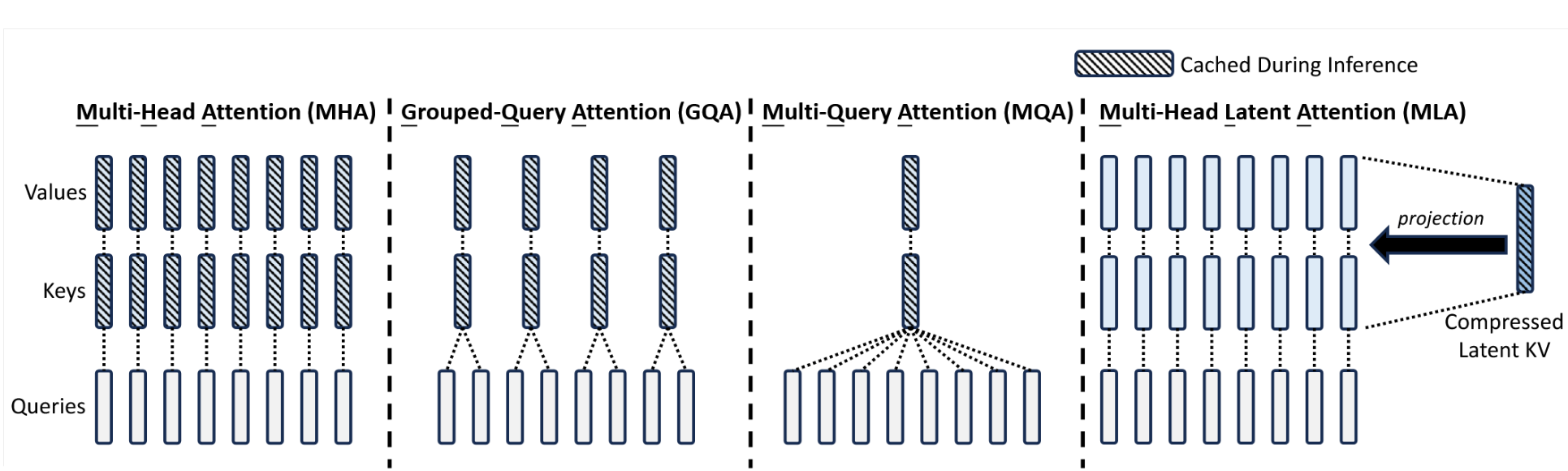
图3 | 多头注意力(MHA)、分组查询注意力(GQA)、多查询注意力(MQA)和多头潜在注意力(MLA)的简化示意图。通过将键和值联合压缩为潜在向量,MLA在推理期间显著减少了KV缓存。
然后,qtq_tqt、ktk_tkt、vtv_tvt将被切分成nhn_hnh个头,用于多头注意力计算:
[qt,1;qt,2;...;qt,nh]=qt,[\mathbf{q}_{t,1};\mathbf{q}_{t,2};...;\mathbf{q}_{t,n_h}]=\mathbf{q}_t,[qt,1;qt,2;...;qt,nh]=qt,
[kt,1;kt,2;...;kt,nh]=kt,[\mathbf{k}_{t,1};\mathbf{k}_{t,2};...;\mathbf{k}_{t,n_h}]=\mathbf{k}_t,[kt,1;kt,2;...;kt,nh]=kt,
[vt,1,vt,2,...,vt,nh]=vt,\left[\mathbf{v}_{t,1},\mathbf{v}_{t,2},...,\mathbf{v}_{t,n_h}\right]=\mathbf{v}_t,[vt,1,vt,2,...,vt,nh]=vt,
ot,i=∑j=1tSoftmaxj(qt,iTkj,idh)vj,i,\mathbf{o}_{t,i}=\sum_{j=1}^t\mathrm{Softmax}_j(\frac{\mathbf{q}_{t,i}^T\mathbf{k}_{j,i}}{\sqrt{d_h}})\mathbf{v}_{j,i},ot,i=j=1∑tSoftmaxj(dhqt,iTkj,i)vj,i,
ut=WO[ot,1;0t,2;...;0t,nh],\mathbf{u}_t=W^O[\mathbf{o}_{t,1};\mathbf{0}_{t,2};...;\mathbf{0}_{t,n_h}],ut=WO[ot,1;0t,2;...;0t,nh],
其中 qt,i、kt,i、vt,i∈Rdhq_{t,i}、k_{t,i}、v_{t,i} ∈ R^{d_h}qt,i、kt,i、vt,i∈Rdh 分别表示第 i 个注意力头的查询、键和值;WO∈Rd×dhnhW^O ∈ R^{d×d_hn_h}WO∈Rd×dhnh 表示输出投影矩阵。推理过程中,所有键和值需要被缓存以加速推理,因此 MHA 需要为每个 token 缓存 2nhdhl2n_hd_hl2nhdhl 个元素。在模型部署中,这种庞大的 KV 缓存是一个重大瓶颈,限制了最大批处理大小和序列长度。
2.1.2. 低秩键值联合压缩
MLA的核心是对键和值进行低秩联合压缩,以减少KV缓存:
ctKV=WDKVht,\mathbf{c}_t^{KV}=W^{DKV}\mathbf{h}_t,ctKV=WDKVht,
ktC=WUKctKV,\mathbf{k}_t^C=W^{UK}\mathbf{c}_t^{KV},ktC=WUKctKV,
vtC=WUVctKV,\mathbf{v}_t^C=W^{UV}\mathbf{c}_t^{KV},vtC=WUVctKV,
其中 ctKV∈Rdcc^{KV}_t ∈ R^{d_c}ctKV∈Rdc是键和值的压缩潜在向量;dc(≪dhnh)d_c (≪ d_hn_h)dc(≪dhnh) 表示 KV 压缩维度;WDKV∈Rdc×dW^{DKV }∈ R^{d_c×d}WDKV∈Rdc×d 是下投影矩阵;而 WUK,WUV∈Rdhnh×dcW^{UK},W^{UV}\in\mathbb{R}^{d_hn_h\times d_c}WUK,WUV∈Rdhnh×dc 分别是键和值的上投影矩阵。在推理过程中,MLA 只需缓存 CtKV\mathbf{C}_t^{KV}CtKV,因此其 KV 缓存仅有 dcld_cldcl 个元素,其中 l 表示层数。此外,在推理时,由于 WUKW^{UK}WUK 可被吸收进 WQW^QWQ,而 WUVW^{UV}WUV 可被吸收进 WOW^OWO,我们甚至无需为注意力计算显式地生成键和值。图 3 直观展示了 MLA 中 KV 联合压缩如何缩减 KV 缓存。
此外,为了减少训练期间的激活内存,即使无法减少KV缓存,我们也对查询进行了低秩压缩。
ctQ=WDQht,\mathbf{c}_t^Q=W^{DQ}\mathbf{h}_t,ctQ=WDQht,
qtC=WUQctQ,\mathbf{q}_t^C=W^{UQ}\mathbf{c}_t^Q,qtC=WUQctQ,
其中 ctQ∈Rdc′c^Q_t ∈ R^{d'_c}ctQ∈Rdc′ 是查询的压缩潜在向量;dc′(≪dhnh)d'_c (≪ d_hn_h)dc′(≪dhnh) 表示查询压缩维度;而 WDQ∈Rdc′×dW^{DQ} ∈ R^{d'_c ×d}WDQ∈Rdc′×d 和 WUQ∈Rdhnh×dc′W^{UQ} ∈ R^{d_hn_h×d'_c}WUQ∈Rdhnh×dc′ 分别是查询的下投影和上投影矩阵。
2.1.3. 解耦旋转位置嵌入
遵循DeepSeek 67B(DeepSeek-AI,2024)的研究,我们计划在DeepSeek-V2中采用旋转位置编码(RoPE)(Su等人,2024)。然而,RoPE与低秩KV压缩不兼容。具体而言,RoPE对键和查询均具有位置敏感性。若对键ktCk^C_tktC应用RoPE,则公式10中的WUKW^{UK}WUK将与位置敏感的RoPE矩阵耦合。如此一来,在推理过程中WUKW^{UK}WUK无法再被吸收进WQW^QWQ,因为当前生成令牌对应的RoPE矩阵将位于WQW^QWQ与WUKW^{UK}WUK之间,而矩阵乘法不满足交换律。因此,在推理时必须为所有前缀令牌重新计算键,这将显著降低推理效率。
作为解决方案,我们提出了解耦RoPE策略,该策略使用额外的多头查询qt,iR∈RdhRq^{R}_{t,i} ∈ R^{d^R_h}qt,iR∈RdhR和共享键ktR∈RdhRk^R_t ∈ R^{d^R_h}ktR∈RdhR来承载RoPE,其中dhRd^R_hdhR表示解耦查询和键的每头维度。采用解耦RoPE策略后,MLA执行以下计算:
[qt,1R;qt,2R;...;qt,nhR]=qtR=RoPE(WQRctQ),[\mathbf{q}_{t,1}^R;\mathbf{q}_{t,2}^R;...;\mathbf{q}_{t,n_h}^R]=\mathbf{q}_t^R=\mathrm{RoPE}(W^{QR}\mathbf{c}_t^Q),[qt,1R;qt,2R;...;qt,nhR]=qtR=RoPE(WQRctQ),
ktR=RoPE(WKRht),\mathbf{k}_t^R=\mathrm{RoPE}(W^{KR}\mathbf{h}_t),ktR=RoPE(WKRht),
qt,i=[qt,iC;qt,iR],\mathbf{q}_{t,i}=[\mathbf{q}_{t,i}^C;\mathbf{q}_{t,i}^R],qt,i=[qt,iC;qt,iR],
kt,i=[kt,iC;ktR],\mathbf{k}_{t,i}=[\mathbf{k}_{t,i}^C;\mathbf{k}_t^R],kt,i=[kt,iC;ktR],
ot,i=∑j=1tSoftmaxj(qt,iTkj,idh+dhR)vj,iC,\mathbf{o}_{t,i}=\sum_{j=1}^t\mathrm{Softmax}_j(\frac{\mathbf{q}_{t,i}^T\mathbf{k}_{j,i}}{\sqrt{d_h+d_h^R}})\mathbf{v}_{j,i}^C,ot,i=j=1∑tSoftmaxj(dh+dhRqt,iTkj,i)vj,iC,
ut=WO[ot,1;0t,2;...;0t,nh],\mathbf{u}_t=W^O[\mathbf{o}_{t,1};\mathbf{0}_{t,2};...;\mathbf{0}_{t,n_h}],ut=WO[ot,1;0t,2;...;0t,nh],
其中 WQR∈RdhRnh×dc′W^{QR}\in\mathbb{R}^{d_h^Rn_h\times d_c^{\prime}}WQR∈RdhRnh×dc′和 WKR∈RdhR×dW^{KR}\in\mathbb{R}^{d_h^R\times d}WKR∈RdhR×d分别是用于生成解耦查询和键的矩阵;RoPE(·) 表示应用 RoPE 矩阵的操作;[·; ·] 表示拼接操作。在推理过程中,解耦键也需要被缓存。因此,DeepSeek-V2 总共需要包含(dc+dhR)l(d_c+d_h^R)l(dc+dhR)l个元素的 KV 缓存。
2.1.4. 键值缓存比较
我们在表1中展示了不同注意力机制下每个token的KV缓存比较。MLA仅需少量KV缓存,相当于仅有2.25组的GQA,但能实现比MHA更强的性能。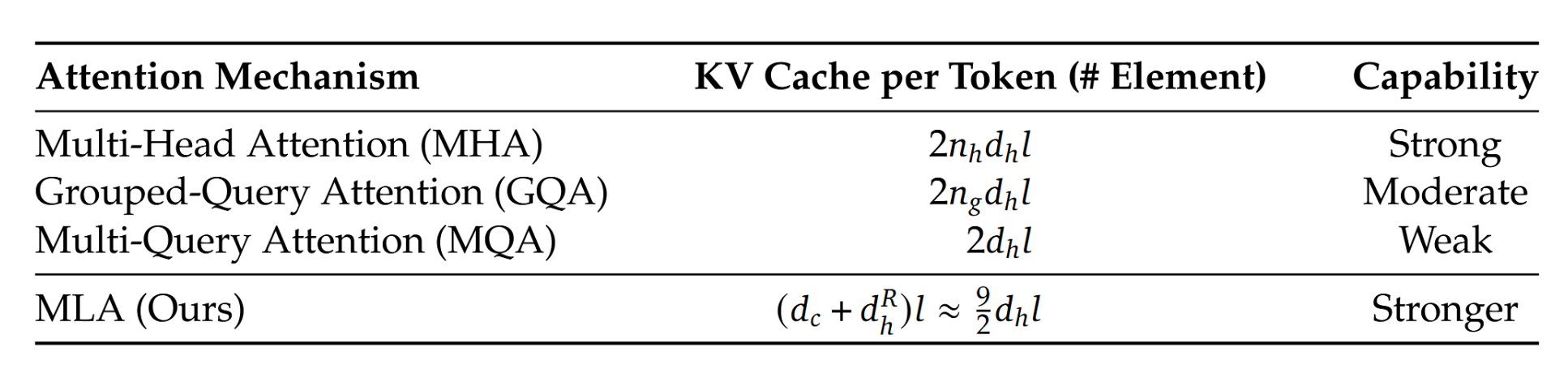
表1 | 不同注意力机制之间每个token的KV缓存比较。nhn_hnh表示注意力头的数量,dhd_hdh表示每个注意力头的维度,l表示层数,ngn_gng表示GQA中的组数,dcd_cdc和dhRd^R_hdhR分别表示MLA中KV压缩维度和解耦查询及键的每头维度。KV缓存量以元素数量衡量,不考虑存储精度。对于DeepSeek-V2,dcd_cdc设为4dh4d_h4dh,dhRd^R_hdhR设为dh/2d_h/2dh/2。因此,其KV缓存相当于仅有2.25组的GQA,但其性能优于MHA。
2.2. DeepSeekMoE:以经济成本训练强大模型
2.2.1. 基本架构
对于FFN,我们采用了DeepSeekMoE架构(Dai等人,2024)。DeepSeekMoE有两个关键思想:将专家划分为更细粒度的单元以实现更高的专家专业化程度和更准确的知识获取,以及隔离部分共享专家以减少路由专家之间的知识冗余。在激活参数和总专家参数数量相同的情况下,DeepSeekMoE能够大幅超越传统MoE架构(如GShard(Lepikhin等人,2021))。
令 utu_tut 为第 t 个 token 的 FFN 输入,我们按如下方式计算 FFN 输出 h’th’_th’t:
h′t=ut+∑i=1NsFFNi(s)(ut)+∑i=1Nrgi,tFFNi(r)(ut),\mathbf{h^{\prime}}_t=\mathbf{u}_t+\sum_{i=1}^{N_s}\mathrm{FFN}_i^{(s)}(\mathbf{u}_t)+\sum_{i=1}^{N_r}\mathrm{g}_{i,t}\mathrm{FFN}_i^{(r)}(\mathbf{u}_t),h′t=ut+i=1∑NsFFNi(s)(ut)+i=1∑Nrgi,tFFNi(r)(ut),
gi,t={si,t,si,t∈Topk({sj,t∣1⩽j⩽Nr},Kr),0,otherwise,g_{i,t}=\begin{cases}s_{i,t},&s_{i,t}\in\mathrm{Topk}(\{s_{j,t}|1\leqslant j\leqslant N_r\},K_r),\\0,&\mathrm{otherwise},&&\end{cases}gi,t={si,t,0,si,t∈Topk({sj,t∣1⩽j⩽Nr},Kr),otherwise,
si,t=Softmaxi(utTei),s_{i,t}=\mathrm{Softmax}_i\left(\mathbf{u}_t{}^T\mathbf{e}_i\right),si,t=Softmaxi(utTei),
其中,NsN_sNs和NrN_rNr分别表示共享专家和路由专家的数量;FFNi(s)(⋅)FFN^{(s)}_i(·)FFNi(s)(⋅)和FFNi(r)(⋅)FFN^{(r)}_i(·)FFNi(r)(⋅)分别表示第i个共享专家和第i个路由专家;KrK_rKr表示被激活的路由专家数量;gi,tg_{i,t}gi,t是第i个专家的门控值;si,ts_{i,t}si,t是令牌到专家的亲和度;eie_iei是该层中第i个路由专家的质心;Topk(·, K)表示由第t个令牌与所有路由专家计算的亲和度分数中,得分最高的K个组成的集合。
2.2.2. 设备受限路由
我们设计了一种设备限制路由机制,以约束与MoE相关的通信成本。当采用专家并行时,被路由的专家会分布在多个设备上。对于每个令牌,其MoE相关通信频率与目标专家覆盖的设备数量成正比。由于DeepSeekMoE中细粒度的专家分割,激活的专家数量可能很大,因此如果应用专家并行,MoE相关的通信成本会更高。
我们设计了一种设备限制路由机制,以约束与MoE相关的通信成本。当采用专家并行时,被路由的专家将分布在多个设备上。对于每个令牌,其MoE相关通信频率与目标专家覆盖的设备数量成正比。由于DeepSeekMoE中细粒度的专家分割,激活的专家数量可能很大,因此如果应用专家并行,MoE相关的通信成本将更高。对于DeepSeek-V2,除了简单的top-K路由专家选择外,我们还额外确保每个令牌的目标专家最多分布在M个设备上。具体来说,对于每个令牌,我们首先选择M个设备,这些设备上拥有亲和度分数最高的专家。然后,在这M个设备上的专家中执行top-K选择。实践中,我们发现当M ≥ 3时,设备限制路由能够实现与无限制top-K路由大致一致的良好性能。
2.2.3. 负载均衡的辅助损失
我们将负载均衡纳入自动学习的路由策略中。首先,不平衡的负载会增加路由崩溃的风险(Shazeer et al., 2017),导致部分专家无法得到充分训练和利用。其次,当采用专家并行时,不平衡的负载会降低计算效率。在DeepSeek-V2的训练过程中,我们设计了三种辅助损失,分别用于控制专家级负载均衡(LExpBalL_{ExpBal}LExpBal)、设备级负载均衡(LDevBalL_{DevBal}LDevBal)和通信均衡(LCommBalL_{CommBal}LCommBal)。
专家级平衡损失。我们使用一种专家级平衡损失(Fedus等人,2021;Lepikhin等人,2021)来减轻路由崩溃的风险:
LExpBal=α1∑i=1NrfiPi,fi=NrKrT∑t=1T1(Token t selects Expert i),Pi=1T∑t=1Tsi,t,\begin{aligned}\mathrm{LExpBal}&=\alpha_1\sum_{i=1}^{N_r}f_iP_i,\\f_{i}&=\frac{N_r}{K_rT}\sum_{t=1}^T1(\mathrm{Token~}t\text{ selects Expert }i),\\P_{i}&=\frac{1}{T}\sum_{t=1}^Ts_{i,t},\end{aligned}LExpBalfiPi=α1i=1∑NrfiPi,=KrTNrt=1∑T1(Token t selects Expert i),=T1t=1∑Tsi,t,
其中α1是一个称为专家级平衡因子的超参数;1(·)表示指示函数;T表示序列中的词元数量。
设备级平衡损失。除了专家级平衡损失外,我们还额外设计了一个设备级平衡损失,以确保不同设备间的计算均衡。在DeepSeek-V2的训练过程中,我们将所有路由专家划分为D组{E1, E2, …, ED},并将每组部署在单个设备上。设备级平衡损失的计算方式如下:
LDevBal=α2∑i=1Dfi′Pi′,fi′=1∣Ei∣∑j∈Eifj,Pi′=∑j∈EiPj,\begin{aligned}\mathrm{LDevBal}&=\alpha_2\sum_{i=1}^Df_i^{\prime}P_i^{\prime},\\f_i^{\prime}&=\frac{1}{|\mathcal{E}_i|}\sum_{j\in\mathcal{E}_i}f_j,\\P_i^{\prime}&=\sum_{j\in\mathcal{E}_i}P_j,\end{aligned}LDevBalfi′Pi′=α2i=1∑Dfi′Pi′,=∣Ei∣1j∈Ei∑fj,=j∈Ei∑Pj,
其中α2是一个超参数,称为设备级平衡因子。
通信平衡损失。最后,我们引入了一种通信平衡损失,以确保每个设备的通信是平衡的。尽管设备限制的路由机制保证了每个设备的发送通信是有界的,但如果某个设备接收到的令牌数量多于其他设备,实际通信效率也会受到影响。为了缓解这一问题,我们设计了如下的通信平衡损失:
LCommBal=α3∑i=1Dfi′′Pi′′,fi′′=DMT∑t=1T1(Token t is sent to Device i),Pi′′=∑j∈EiPj,\begin{aligned}\mathrm{LCommBal}&=\alpha_3\sum_{i=1}^Df_i^{\prime\prime}P_i^{\prime\prime},\\f_i^{\prime\prime}&=\frac{D}{MT}\sum_{t=1}^T\mathbb{1}(\mathrm{Token~}t\text{ is sent to Device }i),\\P_i^{\prime\prime}&=\sum_{j\in\mathcal{E}_i}P_j,\end{aligned}LCommBalfi′′Pi′′=α3i=1∑Dfi′′Pi′′,=MTDt=1∑T1(Token t is sent to Device i),=j∈Ei∑Pj,
其中α3是一个称为通信平衡因子的超参数。设备限制路由机制的工作原理是确保每个设备最多向其他设备传输MT个隐藏状态。同时,采用通信平衡损失来鼓励每个设备从其他设备接收大约MT个隐藏状态。通信平衡损失保证了设备之间信息的均衡交换,促进了高效通信。
2.2.4. 令牌丢弃策略
虽然平衡损失旨在鼓励负载均衡,但必须承认它们无法保证严格的负载平衡。为了进一步减轻由负载不均衡导致的计算浪费,我们在训练过程中引入了一种设备级令牌丢弃策略。该方法首先计算每个设备的平均计算预算,这意味着每个设备的容量因子等于1.0。然后,受Riquelme等人(2021)的启发,我们在每个设备上丢弃亲和度得分最低的令牌,直至达到计算预算。此外,我们确保属于约10%训练序列的令牌永远不会被丢弃。通过这种方式,我们可以根据效率需求灵活决定在推理过程中是否丢弃令牌,并始终保证训练与推理之间的一致性。
3.预训练
3.1. 实验设置
3.1.1. 数据构建
在保持与DeepSeek 67B(DeepSeek-AI,2024)相同的数据处理流程的同时,我们扩展了数据量并提升了数据质量。为了扩大预训练语料库,我们探索了互联网数据的潜力并优化了清洗流程,从而恢复了大量被误删的数据。此外,我们加入了更多中文数据,旨在更好地利用中文互联网上可用的语料。除了数据量,我们还关注数据质量。我们用来自多个来源的高质量数据丰富了预训练语料库,同时改进了基于质量的过滤算法。改进后的算法确保大量无益数据被移除,而大部分有价值数据得以保留。此外,我们从预训练语料库中过滤掉了有争议的内容,以减轻特定区域文化引入的数据偏差。关于该过滤策略影响的详细讨论见附录E。
我们采用与DeepSeek 67B相同的分词器,该分词器基于字节级字节对编码(BBPE)算法构建,词汇表大小为10万。我们的分词预训练语料库包含8.1T个token,其中中文token数量比英文token多约12%。
3.1.2. 超参数
模型超参数。我们将Transformer层数设置为60,隐藏维度设置为5120。所有可学习参数均以标准差0.006随机初始化。在MLA中,我们将注意力头数nh设为128,每头维度dh设为128。KV压缩维度dc设为512,查询压缩维度d′c设为1536。对于解耦查询和键,我们将每头维度dRh设为64。遵循Dai等人(2024)的方法,我们将除第一层外的所有FFN替换为MoE层。每个MoE层包含2个共享专家和160个路由专家,每个专家的中间隐藏维度为1536。在路由专家中,每个token将激活6个专家。此外,低秩压缩和细粒度专家分割会影响层的输出尺度。因此,在实际中,我们在压缩潜在向量后额外使用RMS Norm层,并在宽度瓶颈处(即压缩潜在向量和路由专家的中间隐藏状态)乘以额外的缩放因子,以确保训练稳定。在该配置下,DeepSeek-V2总参数为236B,其中每个token激活21B参数。
训练超参数。我们采用AdamW优化器(Loshchilov和Hutter,2017),超参数设置为β1=0.9、β2=0.95、weight_decay=0.1。学习率采用预热-阶梯衰减策略进行调度(DeepSeek-AI,2024)。初始阶段,学习率在前2000步内从0线性增加至最大值。随后,在训练约60%的token后,学习率乘以0.316;在训练约90%的token后,再次乘以0.316。最大学习率设为2.4×10⁻⁴,梯度裁剪范数设为1.0。我们还采用了批次大小调度策略,在前2250亿个token的训练过程中,批次大小从2304逐步增加至9216,剩余训练阶段保持9216不变。我们将最大序列长度设为4K,并在8.1万亿个token上训练DeepSeek-V2。我们利用流水线并行将模型的不同层部署到不同设备上,对于每一层,路由专家均匀部署在8台设备上(D=8)。对于设备限制路由,每个token最多被发送至3台设备(M=3)。对于平衡损失,我们设置α1=0.003、α2=0.05、α3=0.02。训练期间采用token丢弃策略以加速,但在评估时不丢弃任何token。
3.1.3. 基础设施
DeepSeek-V2基于HAI-LLM框架(High-flyer, 2023)进行训练,该框架由我们的工程师内部开发,是一个高效且轻量级的训练框架。它采用了16路零气泡流水线并行(Qi et al., 2023)、8路专家并行(Lepikhin et al., 2021)以及ZeRO-1数据并行(Rajbhandari et al., 2020)。由于DeepSeek-V2的激活参数相对较少,且部分算子会重新计算以节省激活内存,因此其训练无需采用张量并行,从而降低了通信开销。此外,为了进一步提升训练效率,我们将共享专家的计算与专家并行全对全通信重叠进行。我们还针对通信、路由算法和融合算子定制了更快的CUDA内核。跨不同专家的线性计算。此外,MLA还基于FlashAttention-2(Dao, 2023)的改进版本进行了优化。
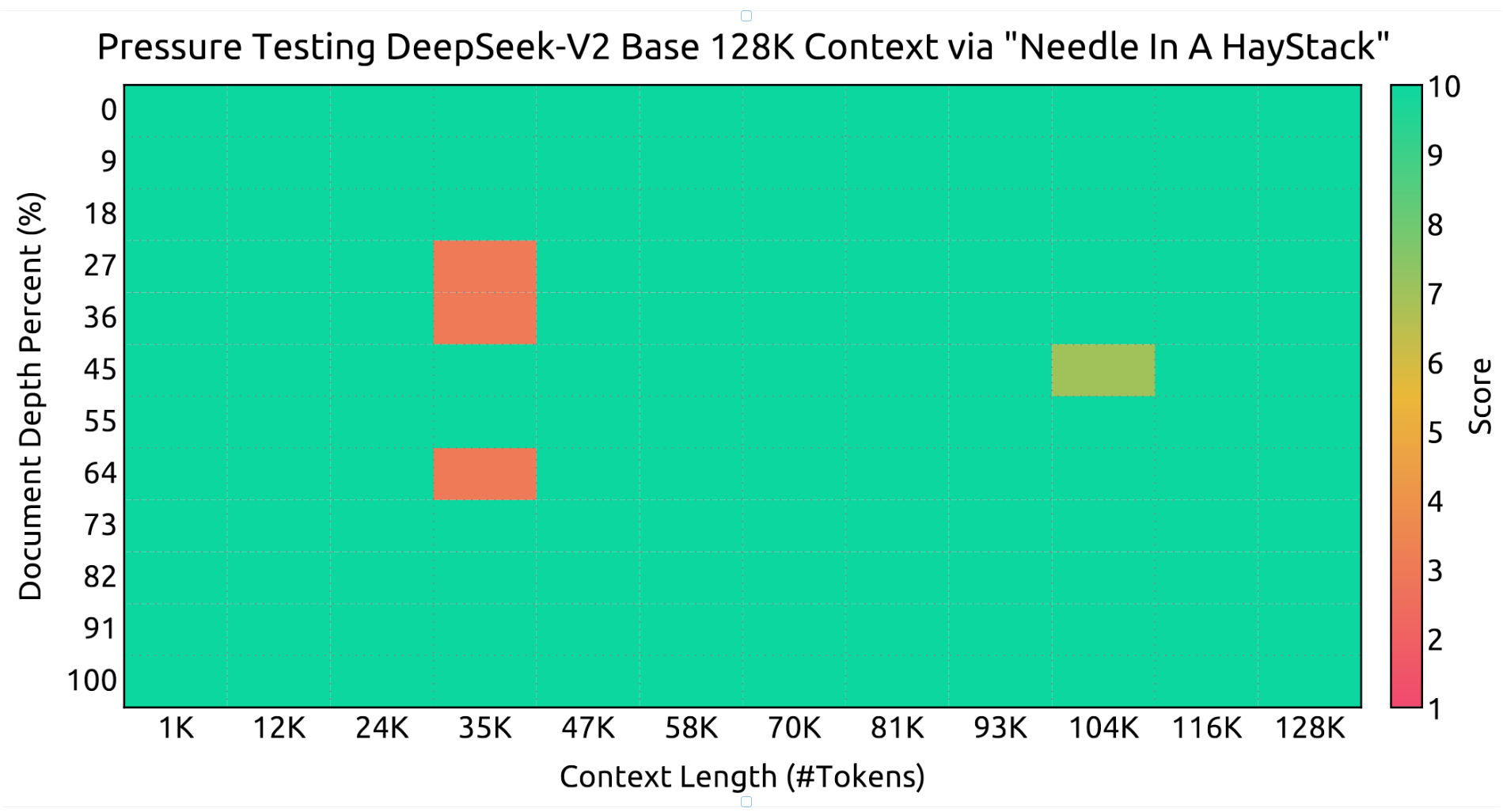
图4 | “大海捞针”(NIAH)测试的评估结果。DeepSeek-V2在所有上下文窗口长度(最高达128K)上均表现良好。
我们在一个配备 NVIDIA H800 GPU 的集群上进行了所有实验。H800 集群的每个节点包含 8 个 GPU,节点内部通过 NVLink 和 NVSwitch 连接。节点之间则利用 InfiniBand 互联以促进通信。
3.1.4. 长上下文扩展
在对DeepSeek-V2进行初始预训练后,我们采用YaRN(Peng等人,2023)将默认上下文窗口长度从4K扩展到128K。YaRN专门应用于解耦共享密钥ktRk^R_tktR,因其负责承载RoPE(Su等人,2024)。对于YaRN,我们将缩放因子s设为40,α设为1,β设为32,目标最大上下文长度设为160K。在此设置下,我们能够期望模型对128K的上下文长度有良好响应。与原始YaRN略有不同,由于我们的注意力机制不同,我们调整了长度缩放因子以调节注意力熵。因子√t的计算方式为√t = 0.0707 ln s + 1,旨在最小化困惑度。
我们额外训练了模型1000步,序列长度为32K,批次大小为576个序列。尽管训练仅在32K序列长度下进行,但模型在128K上下文长度评估时仍表现出稳健的性能。如图4所示,“大海捞针”(NIAH)测试结果表明,DeepSeek-V2在高达128K的所有上下文窗口长度上均表现良好。
3.2. 评估
3.2.1. 评估基准
DeepSeek-V2在一个双语语料库上进行了预训练,因此我们在一系列英文和中文基准上对其进行了评估。我们的评估基于集成在HAI-LLM框架中的内部评估框架。包含的基准分类列出如下,其中带下划线的基准为中文基准:
多学科多项选择数据集包括MMLU(Hendrycks等人,2020)、C-Eval(Huang等人,2023)和CMMLU(Li等人,2023)。
语言理解与推理数据集包括HellaSwag(Zellers等人,2019)、PIQA(Bisk等人,2020)、ARC(Clark等人,2018)和BigBench Hard(BBH)(Suzgun等人,2022)。
闭卷问答数据集包括TriviaQA(Joshi等人,2017)和NaturalQuestions(Kwiatkowski等人,2019)。
阅读理解数据集包括RACE(Lai等人,2017)、DROP(Dua等人,2019)、C3(Sun等人,2019)和CMRC(Cui等人,2019)。
指代消歧数据集包括WinoGrande(Sakaguchi等人,2019)和CLUEWSC(Xu等人,2020)。
语言建模数据集包括Pile(Gao等人,2020)。
中文理解与文化数据集包括CHID(Zheng等人,2019)和CCPM(Li等人,2021)。
数学数据集包括GSM8K(Cobbe等人,2021)、MATH(Hendrycks等人,2021)和CMath(Wei等人,2023)。
代码数据集包括HumanEval(Chen等人,2021)、MBPP(Austin等人,2021)和CRUXEval(Gu等人,2024)。
标准化考试包括AGIEval(Zhong等人,2023)。注意,AGIEval包含英文和中文子集。
基于先前工作(DeepSeek-AI,2024),我们对包含HellaSwag、PIQA、WinoGrande、RACE-Middle、RACE-High、MMLU、ARC-Easy、ARC-Challenge、CHID、C-Eval、CMMLU、C3及CCPM在内的数据集采用基于困惑度的评估方法,并对TriviaQA、NaturalQuestions、DROP、MATH、GSM8K、HumanEval、MBPP、CRUXEval、BBH、AGIEval、CLUEWSC、CMRC及CMath采用基于生成的评估方法。此外,我们对Pile-test执行基于语言建模的评估,并以每字节位数(BPB)作为度量指标,以确保使用不同分词器的模型之间的公平比较。
为了对这些基准进行直观概述,我们还在附录G中提供了每个基准的评估格式。
3.2.2. 评估结果
在表2中,我们将DeepSeek-V2与多个代表性开源模型进行了对比,包括DeepSeek 67B(DeepSeek-AI, 2024)(我们之前的版本)、Qwen1.5 72B(Bai等人, 2023)、LLaMA3 70B(AI@Meta, 2024)以及Mixtral 8x22B(Mistral, 2024)。我们使用内部评估框架对所有模型进行了评测,并确保其评估设置保持一致。总体而言,DeepSeek-V2仅需激活210亿参数,便在几乎所有基准测试中显著优于DeepSeek 67B,并在开源模型中达到了顶尖性能。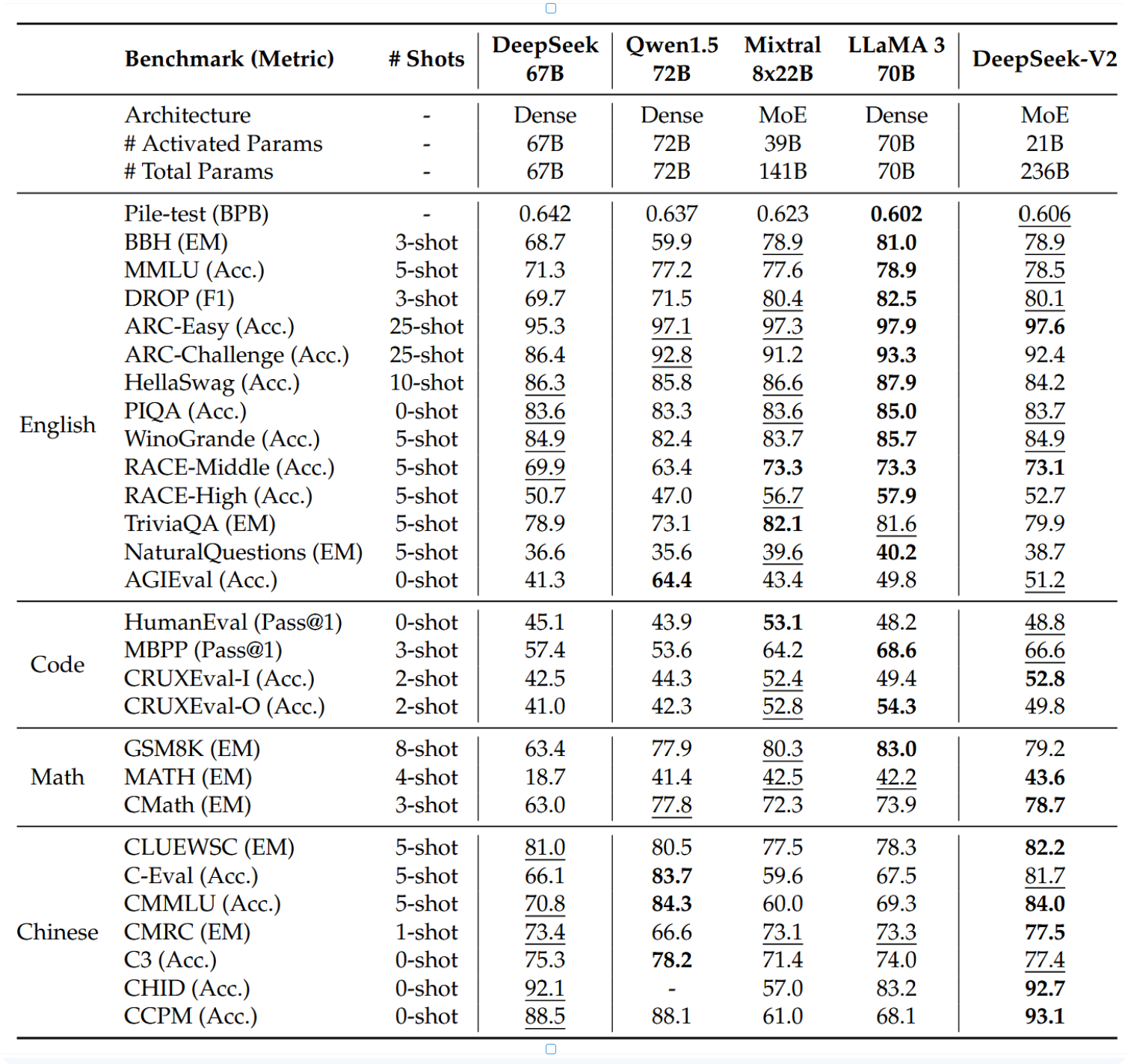
表2 | DeepSeek-V2与其他代表性开源模型的对比。所有模型均在我们内部框架中评估,且采用相同的评估设置。粗体表示最佳,下划线表示次优。差距小于0.3的分数视为同一水平。仅凭21B激活参数量,DeepSeek-V2即在开源模型中达到顶级性能。
此外,我们逐一详细比较了DeepSeek-V2与其开源对应模型。(1) 与同样支持中英文的Qwen1.5 72B相比,DeepSeek-V2在大多数英语、代码和数学基准测试中展现出压倒性优势。至于中文基准测试,Qwen1.5 72B在多学科多项选择任务中,DeepSeek-V2在其他方面表现相当或更优。需要注意的是,对于CHID基准测试,Qwen1.5 72B的分词器在我们的评估框架中会遇到错误,因此我们将Qwen1.5 72B的CHID分数留空。(2)与Mixtral 8x22B相比,DeepSeek-V2在英语性能上达到相当或更优水平,但在TriviaQA、NaturalQuestions和HellaSwag(这些与英语常识知识密切相关)方面除外。值得注意的是,DeepSeek-V2在MMLU上优于Mixtral 8x22B。在代码和数学基准测试中,DeepSeek-V2表现出与Mixtral 8x22B相当的性能。由于Mixtral 8x22B未专门针对中文数据进行训练,其中文能力远落后于DeepSeek-V2。(3)与LLaMA3 70B相比,DeepSeek-V2训练的英语token数量不到其四分之一。因此,我们承认DeepSeek-V2在基础英语能力上仍与LLaMA3 70B存在微小差距。然而,即使使用更少的训练token和激活参数,DeepSeek-V2在代码和数学能力上仍与LLaMA3 70B相当。此外,作为双语语言模型,DeepSeek-V2在中文基准测试中全面优于LLaMA3 70B。
最后值得一提的是,部分先前研究(Hu et al., 2024)在预训练阶段引入了SFT数据,而DeepSeek-V2在预训练过程中从未接触过SFT数据。
3.2.3. 训练与推理效率
训练成本。由于DeepSeek-V2对每个token激活的参数更少,且所需FLOPs低于DeepSeek 67B,理论上训练DeepSeek-V2将比训练DeepSeek 67B更经济。尽管训练MoE模型会引入额外的通信开销,但通过我们的算子和通信优化,DeepSeek-V2的训练可以达到相对较高的模型FLOPs利用率(MFU)。在实际的H800集群训练中,每训练一万亿个token,DeepSeek 67B需要300.6K GPU小时,而DeepSeek-V2仅需172.8K GPU小时,即稀疏的DeepSeek-V2相比密集的DeepSeek 67B可节省42.5%的训练成本。
推理效率。为了高效部署DeepSeek-V2提供服务,我们首先将其参数转换为FP8精度。此外,我们对DeepSeek-V2进行了KV缓存量化(Hooper等,2024;Zhao等,2023),以将其KV缓存中的每个元素平均压缩至6比特。得益于MLA及这些优化,实际部署的DeepSeek-V2所需的KV缓存显著少于DeepSeek 67B,从而能够支持更大的批处理规模。我们基于实际部署的DeepSeek 67B服务的提示词与生成长度分布,评估了DeepSeek-V2的生成吞吐量。在配备8块H800 GPU的单节点上,DeepSeek-V2的生成吞吐量超过每秒5万Token,是DeepSeek 67B最大生成吞吐量的5.76倍。此外,DeepSeek-V2的提示词输入吞吐量超过每秒10万Token。
4.对齐
4.1 SFT监督微调
基于我们先前的研究(DeepSeek-AI, 2024),我们整理了包含150万条实例的指令微调数据集,其中120万条用于提升 helpfulness(有益性),30万条用于提升 safety(安全性)。相较于初始版本,我们改进了数据质量以减轻幻觉响应,并提升写作能力。我们对DeepSeek-V2进行了2个epoch的微调,学习率设置为5×10⁻⁶。在DeepSeek-V2 Chat(SFT)的评估中,我们主要采用基于生成的基准测试,除若干代表性多选题任务(MMLU和ARC)外。我们还使用提示级宽松准确率作为指标,对DeepSeek-V2 Chat(SFT)进行了指令遵循评估(IFEval)(Zhou et al., 2023)。此外,我们采用了2023年9月1日至2024年4月1日期间的LiveCodeBench(Jain et al., 2024)问题来评估聊天模型。除标准基准测试外,我们还在开放式对话基准测试上进一步评估了模型,包括MT-Bench(Zheng et al., 2023)、AlpacaEval 2.0(Dubois et al., 2024)和AlignBench(Liu et al., 2023)。为进行比较,我们在相同的评估框架和设置下评估了Qwen1.5 72B Chat、LLaMA-3-70B Instruct和Mistral-8x22B Instruct。对于DeepSeek 67B Chat,我们直接参考了先前版本中报告的评估结果。
4.2. 强化学习
为了进一步挖掘DeepSeek-V2的潜力并使其与人类偏好对齐,我们采用强化学习(RL)来调整其偏好。
强化学习算法。为了节省强化学习的训练成本,我们采用了群体相对策略优化(GRPO)(Shao等人,2024),该方法舍弃了通常与策略模型规模相同的批评者模型,而是通过群体得分来估计基线。具体而言,对于每个问题q,GRPO从旧策略πθoldπ_{θ_{old}}πθold中采样一组输出{o1,o2,⋅⋅⋅,oG}\{o_1, o_2, · · · , o_G\}{o1,o2,⋅⋅⋅,oG},然后通过最大化以下目标来优化策略模型πθπ_θπθ:
JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]1G∑i=1G(min(πθ(oi∣q)πθold(oi∣q)Ai,clip(πθ(oi∣q)πθold(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∣∣πref)),\begin{aligned}\mathcal{J}_{GRPO}(\theta)&=\operatorname{E}[q\sim P(Q),\{o_i\}_{i=1}^G\sim\pi_{\theta_{old}}(O|q)]\\&\frac{1}{G}\sum_{i=1}^G\left(\min\left(\frac{\pi_\theta(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}A_i,\operatorname{clip}\left(\frac{\pi_\theta(o_i|q)}{\pi_{\theta_{old}}(o_i|q)},1-\varepsilon,1+\varepsilon\right)A_i\right)-\beta\operatorname{D}_{KL}\left(\pi_\theta||\pi_{ref}\right)\right),\end{aligned}JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G(min(πθold(oi∣q)πθ(oi∣q)Ai,clip(πθold(oi∣q)πθ(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∣∣πref)),
IDKL(πθ∣∣πref)=πref(oi∣q)πθ(oi∣q)−logπref(oi∣q)πθ(oi∣q)−1,\mathrm{ID}_{KL}\left(\pi_\theta||\pi_{ref}\right)=\frac{\pi_{ref}(o_i|q)}{\pi_\theta(o_i|q)}-\log\frac{\pi_{ref}(o_i|q)}{\pi_\theta(o_i|q)}-1,IDKL(πθ∣∣πref)=πθ(oi∣q)πref(oi∣q)−logπθ(oi∣q)πref(oi∣q)−1,
其中ε和β是超参数;Ai是优势,使用对应每组内输出的一组奖励{r1,r2,...,rG}\{r_1, r_2, . . . , r_G\}{r1,r2,...,rG}计算得到:
Ai=ri−max({r1,r2,⋯ ,rG})std({r1,r2,⋯ ,rG}).A_i=\frac{r_i-\max(\{r_1,r_2,\cdots,r_G\})}{\mathrm{st}d(\{r_1,r_2,\cdots,r_G\})}.Ai=std({r1,r2,⋯,rG})ri−max({r1,r2,⋯,rG}).
训练策略。在我们的初步实验中,我们发现对推理数据(如代码和数学提示)进行强化学习训练表现出与通用数据训练不同的独特特性。例如,我们模型的数学和编码能力可以在更长的训练步骤中持续提升。因此,我们采用两阶段强化学习训练策略:首先进行推理对齐,然后进行人类偏好对齐。在第一阶段——推理对齐阶段,我们为代码和数学推理任务训练一个奖励模型RMreasoningRM_{reasoning}RMreasoning,并利用RMreasoningRM_{reasoning}RMreasoning的反馈优化策略模型。
ri=RMreasoning(oi).r_i=RM_{reasoning}(o_i).ri=RMreasoning(oi).
在第二个人类偏好对齐阶段,我们采用了一个多奖励框架,该框架从有帮助奖励模型 RMhelpfulRM_{helpful}RMhelpful、安全奖励模型 RMsafetyRM_{safety}RMsafety 和基于规则的奖励模型 RMruleRM_{rule}RMrule 中获取奖励。响应 oio_ioi 的最终奖励是
ri=c1⋅RMhelpful(oi)+c2⋅RMsafety(oi)+c3⋅RMrule(oi),r_i=c_1\cdot RM_{helpful}(o_i)+c_2\cdot RM_{safety}(o_i)+c_3\cdot RM_{rule}(o_i),ri=c1⋅RMhelpful(oi)+c2⋅RMsafety(oi)+c3⋅RMrule(oi),
其中c1、c2和c3为对应系数。为了获得在强化学习训练中起关键作用的可靠奖励模型,我们仔细收集偏好数据,并精心进行质量过滤和比例调整。我们基于编译器反馈获取代码偏好数据,基于真实标签获取数学偏好数据。对于奖励模型训练,我们使用DeepSeek-V2 Chat(SFT)初始化奖励模型,并通过逐点损失或成对损失对其进行训练。在我们的实验中,我们观察到强化学习训练能够充分挖掘并激活模型的潜力,使其能够从可能的回答中选择正确且令人满意的答案。
针对训练效率的优化。在超大规模模型上开展强化学习训练对训练框架提出了很高的要求。这需要精心的工程优化来管理显存与内存压力,同时保持快速的训练速度。为实现此目标,我们实施了以下工程优化措施:(1)首先,我们提出了一种混合引擎,分别对训练和推理采用不同的并行策略,以实现更高的GPU利用率;(2)其次,我们采用具有大批量的vLLM(Kwon等人,2023)作为推理后端,以加速推理速度;(3)第三,我们精心设计了一种将模型卸载至CPU及从CPU加载回GPU的调度策略,实现了训练速度与内存消耗之间接近最优的平衡。
4.3. 评估结果
标准基准评估。首先,我们在标准基准上评估了DeepSeek-V2 Chat (SFT)和DeepSeek-V2 Chat (RL)。值得注意的是,与基础版本相比,DeepSeek-V2 Chat (SFT)在GSM8K、MATH和HumanEval评估中表现出显著提升。这一进步可归因于我们SFT数据的加入,其中包含了大量数学和代码相关内容。此外,DeepSeek-V2 Chat (RL)进一步提升了数学和代码基准上的性能。我们在附录F中展示了更多代码和数学评估结果。
至于与其他模型的比较,我们首先将DeepSeek-V2 Chat(SFT)与Qwen1.5 72B Chat进行对比,发现DeepSeek-V2 Chat(SFT)在几乎所有英语、数学和代码基准测试中均优于Qwen1.5 72B Chat。在中文基准测试中,DeepSeek-V2 Chat(SFT)在多学科选择题任务上得分略低于Qwen1.5 72B Chat,这与它们基础版本所表现出的性能一致。与最先进的开源MoE模型Mixtral 8x22B Instruct相比,DeepSeek-V2 Chat(SFT)在大多数基准测试中表现更优,但NaturalQuestions和IFEval除外。此外,与最先进的开源模型LLaMA3 70B Chat相比,DeepSeek-V2 Chat(SFT)在代码和数学相关基准测试中表现相似。LLaMA3 70B Chat在MMLU和IFEval上表现更好,而DeepSeek-V2 Chat(SFT)在中文任务上展现出更强的性能。最终,与DeepSeek-V2 Chat(SFT)相比,DeepSeek-V2 Chat(RL)在数学和编程任务上均表现出进一步提升的性能。这些比较凸显了DeepSeek-V2 Chat在不同领域和语言中相对于其他语言模型的优势。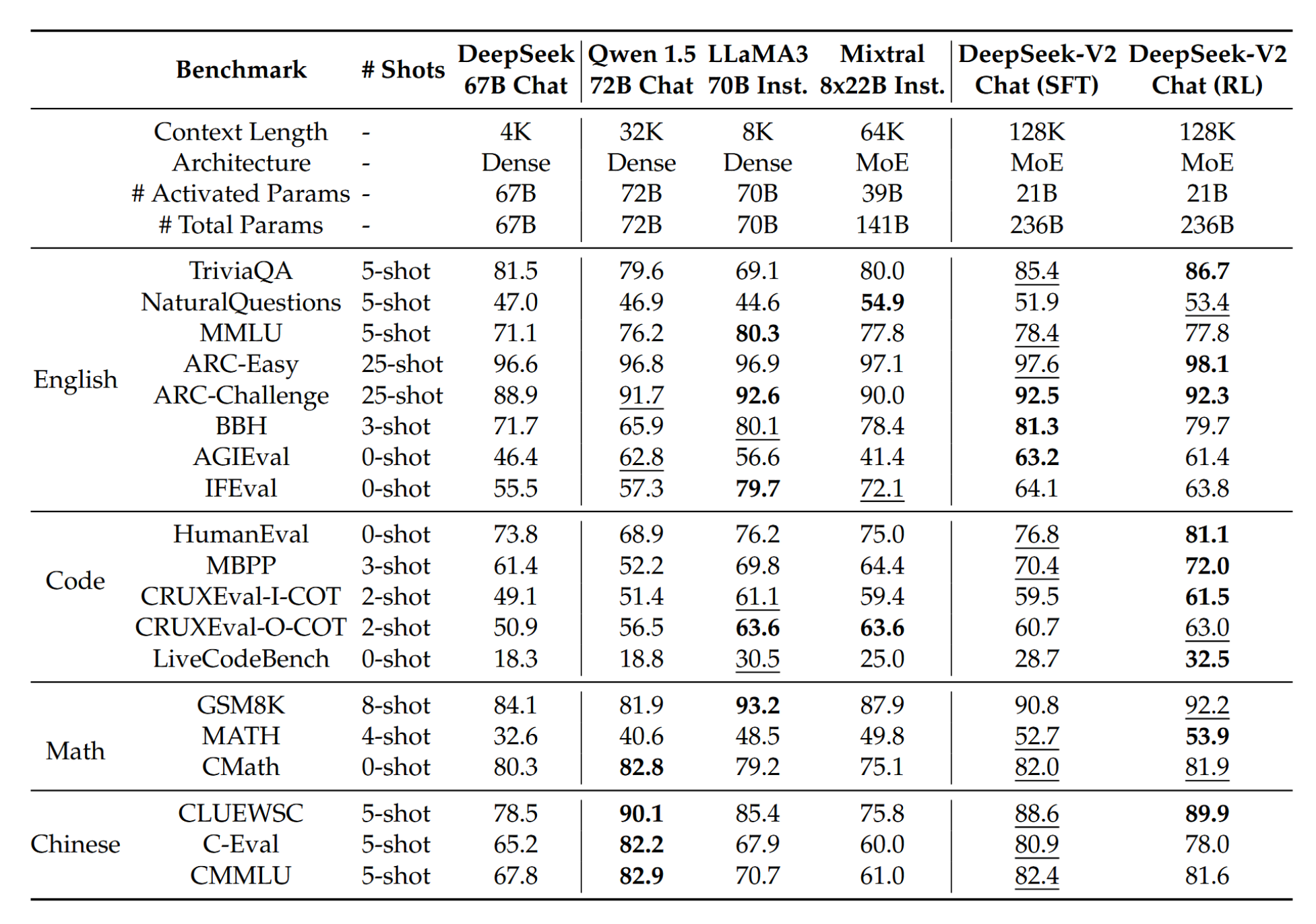
表3 | DeepSeek-V2 Chat (SFT)、DeepSeek-V2 Chat (RL)及其他代表性开源聊天模型的比较。关于TriviaQA和NaturalQuestions,值得注意的是,聊天模型(如LLaMA3 70B Instruct)可能并未严格遵循少样本设置中通常指定的格式约束。因此,这可能导致在我们的评估框架中某些模型被低估。
开放式生成评估。我们进一步在开放式对话基准上对我们的模型进行了额外评估。对于英文开放式对话生成,我们采用MT-Bench和AlpacaEval 2.0作为基准。表4中呈现的评估结果表明,DeepSeek-V2 Chat(RL)相比DeepSeek-V2 Chat(SFT)具有显著性能优势。这一结果展示了我们的强化学习训练在实现更好对齐方面的有效性。与其他开源模型相比,DeepSeek-V2 Chat(RL)在两个基准上均表现出优于Mistral 8x22B Instruct和Qwen1.5 72B Chat的性能。与LLaMA3 70B Instruct相比,DeepSeek-V2 Chat(RL)在MT-Bench上展现了具有竞争力的表现,并在AlpacaEval 2.0上显著胜出。这些结果凸显了DeepSeek-V2
Chat(RL)在生成高质量且上下文相关回复方面的强大能力,尤其是在基于指令的对话任务中。
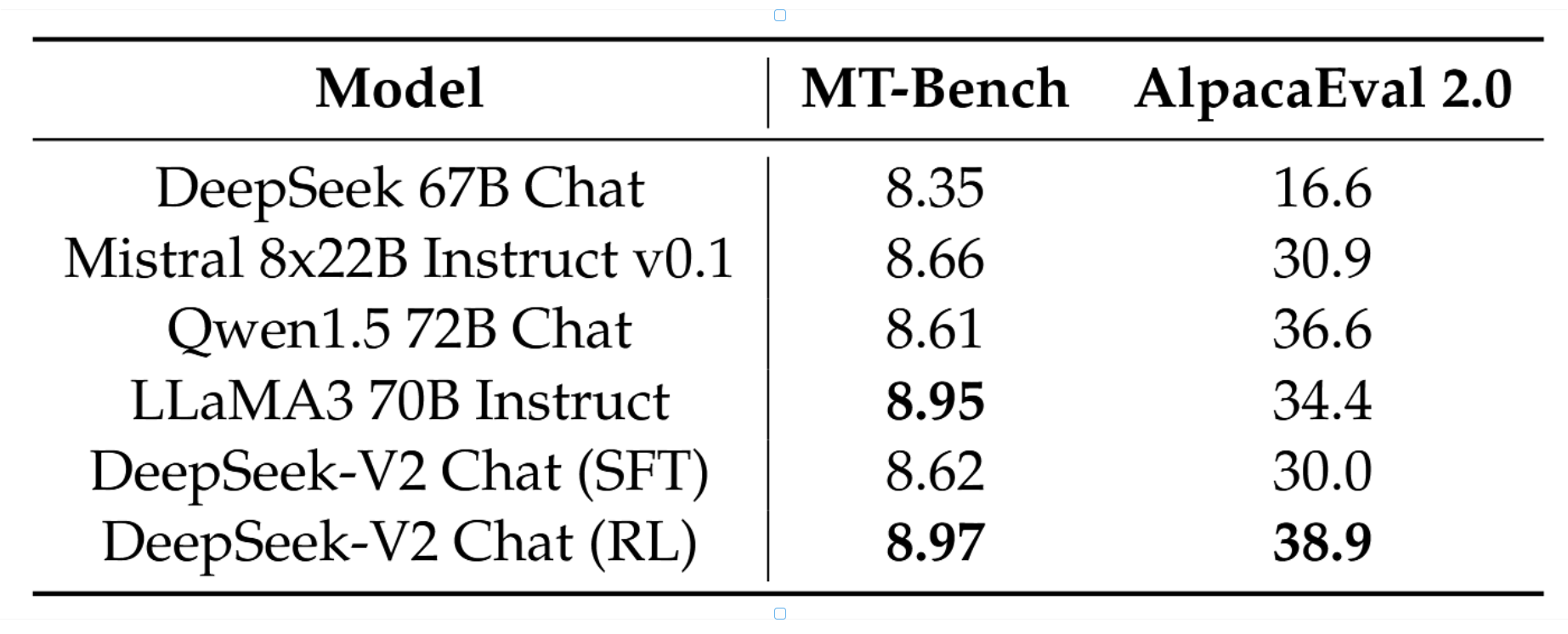
表4 | 英语开放式对话评估。对于AlpacaEval 2.0,我们使用长度控制胜率作为指标。
此外,我们基于AlignBench评估了中文开放生成能力。如表5所示,DeepSeek-V2 Chat(RL)较DeepSeek-V2 Chat(SFT)略有优势。值得注意的是,DeepSeek-V2 Chat(SFT)以显著优势超越所有开源中文模型,大幅领先排名第二的开源模型Qwen1.5。72B Chat在中文推理和语言方面均表现出色。此外,DeepSeek-V2 Chat(SFT)和DeepSeek-V2 Chat(RL)均优于GPT-4-0613和ERNIEBot 4.0,巩固了我们的模型在支持中文的顶级大语言模型中的地位。具体而言,DeepSeek-V2 Chat(RL)在中文语言理解方面表现卓越,超越了包括GPT-4-Turbo-1106-Preview在内的所有模型。另一方面,DeepSeek-V2 Chat(RL)的推理能力仍落后于诸如Erniebot-4.0和GPT-4s等大型模型。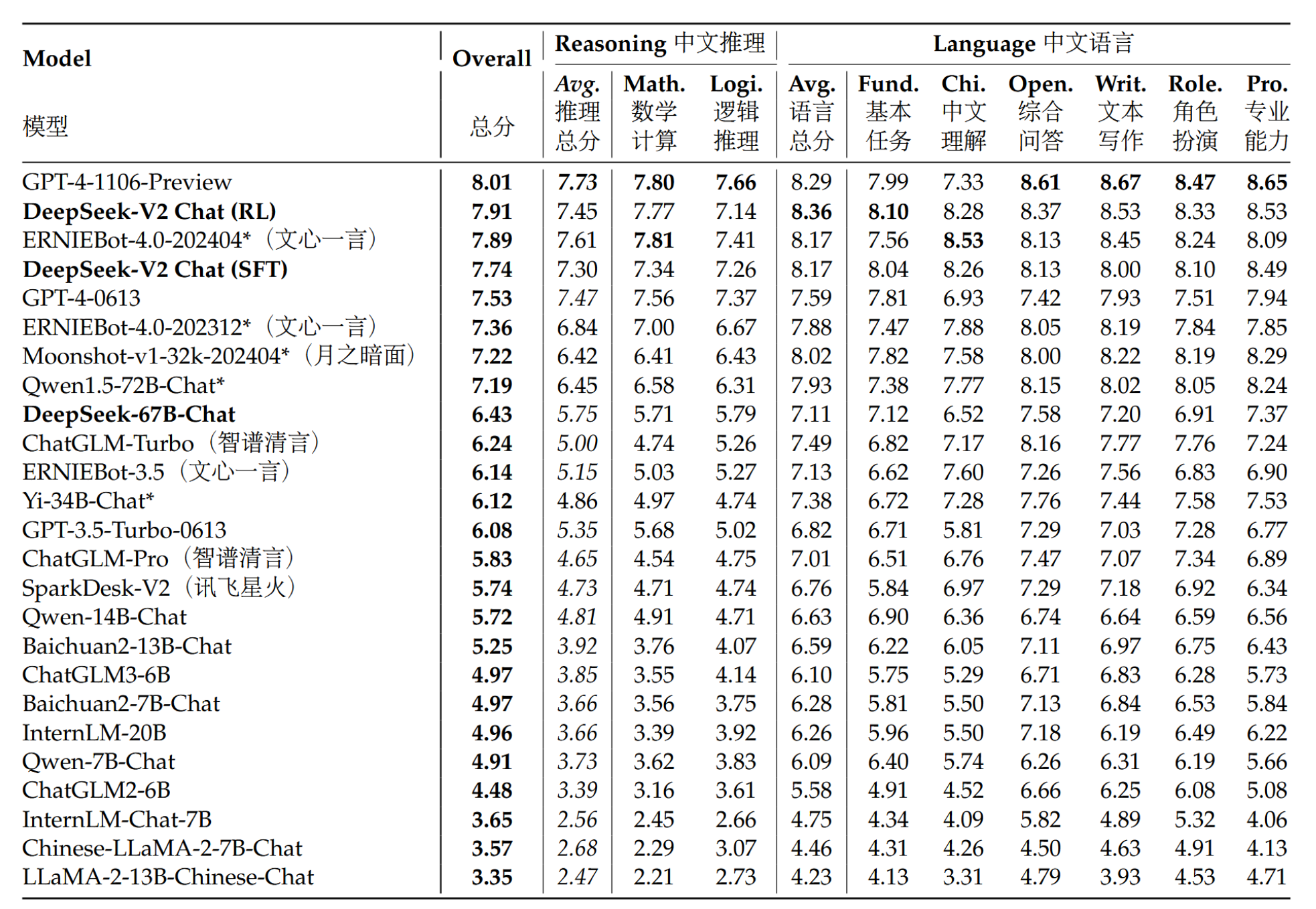
表5 | GPT-4-0613评分的AlignBench排行榜。模型按综合得分降序排列。标有*的模型表示我们通过其API服务或开放权重模型进行评估,而非引用其原始论文中报告的结果。Erniebot-4.0和Moonshot的后缀表示我们调用其API时的时间戳。
4.4. 讨论
SFT数据量。关于是否需要大规模SFT语料库的讨论一直备受争议。先前的研究(Young et al., 2024; Zhou et al., 2024)认为,少于10K条SFT数据实例便足以取得令人满意的结果。然而,在我们的实验中,若使用少于10K条实例,IFEval基准测试的性能会出现显著下降。一种可能的解释是,语言模型需要一定量的数据来发展特定技能。尽管所需数据量可能随模型规模增大而减少,但无法完全消除。我们的观察强调了充足数据对于赋予大语言模型期望能力的关键必要性。此外,SFT数据的质量也至关重要,尤其是对于涉及写作或开放式问题的任务。
对齐税(Alignment Tax)在强化学习中的应用。在人类偏好对齐过程中,我们观察到模型在开放式生成基准测试上的性能显著提升,无论是人工还是AI评估者的评分均有所提高。然而,我们也注意到一种“对齐税”现象(Ouyang et al., 2022),即对齐过程可能对某些标准基准测试(如BBH)的性能产生负面影响。为缓解对齐税,我们在强化学习阶段在数据处理和训练策略优化上投入了大量精力,最终实现了标准基准测试与开放式基准测试性能之间可接受的权衡。探索如何在不损害模型通用性能的前提下实现与人类偏好的对齐,是未来研究的一个有价值方向。
在线强化学习。在我们的偏好对齐实验中,我们发现在线方法显著优于离线方法。因此,我们投入了大量精力实施在线强化学习框架来对齐DeepSeek-V2。关于在线或离线偏好对齐的结论在不同情境下可能有所不同,我们将更全面的比较与分析留待未来工作。
5. 结论、局限性与未来工作
在本文中,我们介绍了DeepSeek-V2,一个支持128K上下文长度的大型MoE语言模型。除了强大的性能外,得益于其创新的架构(包括MLA和DeepSeekMoE),该模型还具有经济高效的训练和推理效率。在实际应用中,与DeepSeek 67B相比,DeepSeek-V2实现了显著更强的性能,同时节省了42.5%的训练成本,减少了93.3%的KV缓存,并将最大生成吞吐量提升至5.76倍。评估结果进一步表明,仅激活210亿参数的DeepSeek-V2,在开源模型中达到了顶级性能,并成为最强的开源MoE模型。
DeepSeek-V2及其聊天版本存在其他大型语言模型中常见的公认局限性,包括预训练后缺乏持续的知识更新、可能生成未经核实建议等非事实信息,以及存在产生幻觉的可能性。此外,由于我们的数据主要由中文和英文内容构成,我们的模型在其他语言中的能力可能有限。在中英文以外的场景中,应谨慎使用。
DeepSeek将以长期主义精神持续投入开源大模型,致力于逐步接近通用人工智能的目标。
• 在我们的持续探索中,我们专注于设计能够进一步扩展MoE模型规模的方法,同时保持经济高效的训练和推理成本。我们下一步的目标是在即将发布的版本中实现与GPT-4相当的性能。• 我们的对齐团队持续努力优化模型,旨在为全球用户开发不仅有用,而且诚实且安全的模型。我们的最终目标是使模型价值观与人类价值观对齐,同时最大限度地减少对人类监督的需求。通过优先考虑伦理考量和负责任的开发,我们致力于为社会创造积极有益的影响。• 目前,DeepSeek-V2设计为仅支持文本模态。在我们的前瞻性规划中,我们计划使模型支持多模态,以增强其在更广泛场景中的多功能性和实用性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)