大模型服务隔离与舱壁模式:构建防过载、防独占高可用架构应用实践解析.164
一、基础认知
1. 大模型服务隔离
大模型服务隔离是将大模型服务的计算资源、请求链路、内存、GPU 显存、网络连接、请求等待队列等核心软硬件资源,进行物理层面或逻辑层面的拆分与划分,让不同用户群体、不同业务接口、不同版本模型实例之间形成独立运行边界,彼此互不干扰、不互相抢占资源,最终实现故障影响、流量冲击被严格限制在局部范围之内,不会顺着服务链路扩散到整个全局AI服务集群。

核心目标:
- 故障隔离:单个租户异常请求、单接口代码报错、单个模型实例崩溃,都被约束在独立隔离域内,完全不会影响其他租户、其他业务接口的正常运行,从根源规避连锁故障。
- 流量管控:通过配额限制、资源拆分的方式,杜绝单一用户、单企业租户发起海量长文本推理、高频轮询请求,耗尽集群整体GPU、CPU与内存资源,避免单点流量拖垮全站服务。
- 公平调度:为不同层级、不同类型的业务与用户分配固定资源权重和并发上限,保障中小流量用户、常规业务请求也能获得稳定的响应时延和推理体验,不会被大流量租户长期挤占资源。
- 高可用保障:通过多层隔离架构,大幅降低大模型服务雪崩、整体宕机的概率,有效提升线上服务稳定性、接口可用性以及业务 SLA 达标率,适配生产级落地场景。
隔离的本质:
- 并不是把各个服务模块完全切断通信、割裂业务链路,而是合理设置资源边界、精细化分配资源配额、严格限制故障影响范围;
- 原理和现代化大楼的防火隔舱、防火门设计一致,某一个区域出现火情或隐患,会被舱壁完全阻隔,不会蔓延烧毁整栋建筑;
- 大模型服务隔离就是给AI服务搭建多层级的数字防火舱壁。
2. 舱壁模式详解
舱壁模式最早源自轮船水密隔舱设计:船体内部被厚重隔板分割为多个相互独立的密闭水密舱室,当其中任意一个舱室出现破损漏水时,水流只会停留在当前独立舱室,不会灌入其他舱体,整艘轮船依旧可以保持浮力正常航行;
迁移到大模型服务架构中,舱壁模式的核心逻辑是将整体复杂服务拆分为多个互不依赖、资源独立的最小运行单元,每一个单元都配备专属的线程池、请求队列、内存配额与连接数上限,一旦某个单元出现过载、阻塞、故障宕机,影响只会局限在当前单元内部,不会传导至整个服务集群。
舱壁模式的3个核心特征:
- 资源独享:每一个隔离舱壁单元都配置独立线程池、独立等待队列、独立网络连接池与显存内存配额,单元之间不共享核心计算资源,从底层杜绝资源抢占和互相阻塞的问题。
- 边界严格:通过代码逻辑、容器配额、网关规则设置刚性资源边界,每个舱壁的最大并发数、队列长度、推理超时时间都有硬性限制,不允许突破预设阈值占用额外资源。
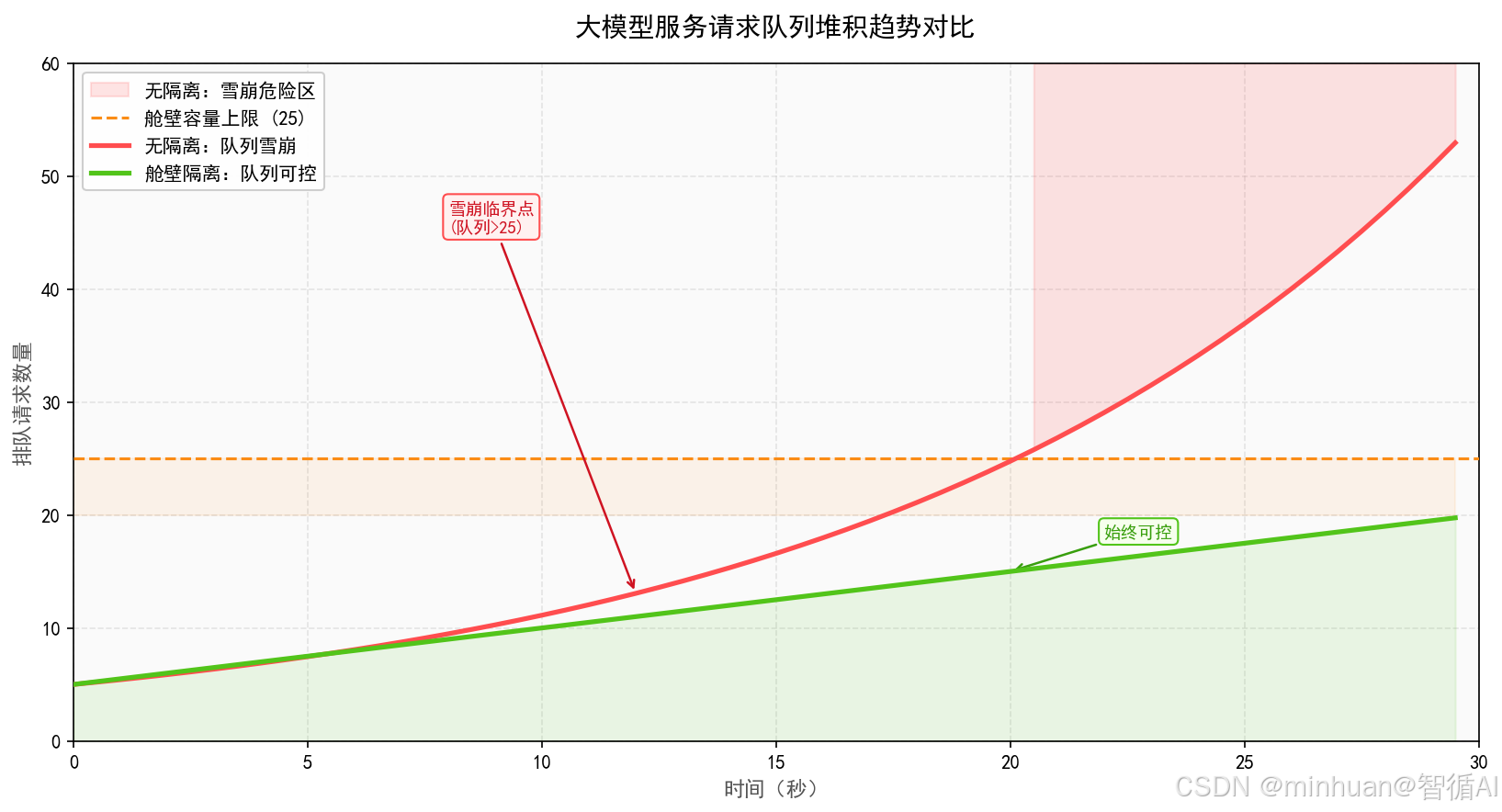
- 熔断降级:当单个舱壁单元达到资源上限、请求堆积超时或出现频繁异常时,自动触发限流、拒绝新请求或降级返回兜底响应,仅自身承担流量压力与故障,完全不影响全局其他舱壁正常工作。
与普通限流的区别:
- 普通限流:只对服务整体总请求数、总QPS做全局限制,无法精准管控单个用户、单个接口的资源占用,很容易出现全局额度被少数用户占满,其余用户无法使用服务的情况。
- 舱壁模式:先拆分独立资源舱室,再在每个舱室内做精细化限流管控,从架构层面先划清资源地盘,再做流量约束,从根源上彻底杜绝单一用户、单一接口独占全局资源的问题,稳定性远高于单纯全局限流。
3. 对大模型的价值
大模型服务本身具备四个天然的业务与技术特性,直接决定了隔离架构和舱壁模式是生产环境落地的刚需配置,无法用普通单体服务架构替代:
资源昂贵且稀缺:
- 大模型推理高度依赖高端GPU显卡、大容量显存与高性能服务器,硬件采购和运维成本极高;
- 整体算力资源十分稀缺,无法依靠无限扩容来抵御突发流量和异常请求,只能通过隔离做精细化资源管控。
请求耗时差异极大:
- 简单短句问答、意图识别推理耗时可能仅几十毫秒,而长文本续写、文档解析、多轮对话、代码生成类请求往往需要十几秒甚至几十秒;
- 长耗时请求极易占用大量线程和显存,阻塞公共队列,拖慢全部请求响应速度。
租户流量不可控:
- 企业客户、个人开发者、接口调用方都有可能在业务测试、批量导入、爬虫调用场景下,突发发起数万级高频请求;
- 若没有隔离防护,瞬间就能直接打满集群算力,打爆全局AI服务。
故障传导性极强:
- 大模型推理链路长,包含网关路由、参数解析、令牌拼接、显存加载、推理计算、结果流式返回多个环节;
- 一旦某一个接口发生线程阻塞、内存泄漏或死循环,会快速耗尽全局公共线程池,引发连锁式服务雪崩。
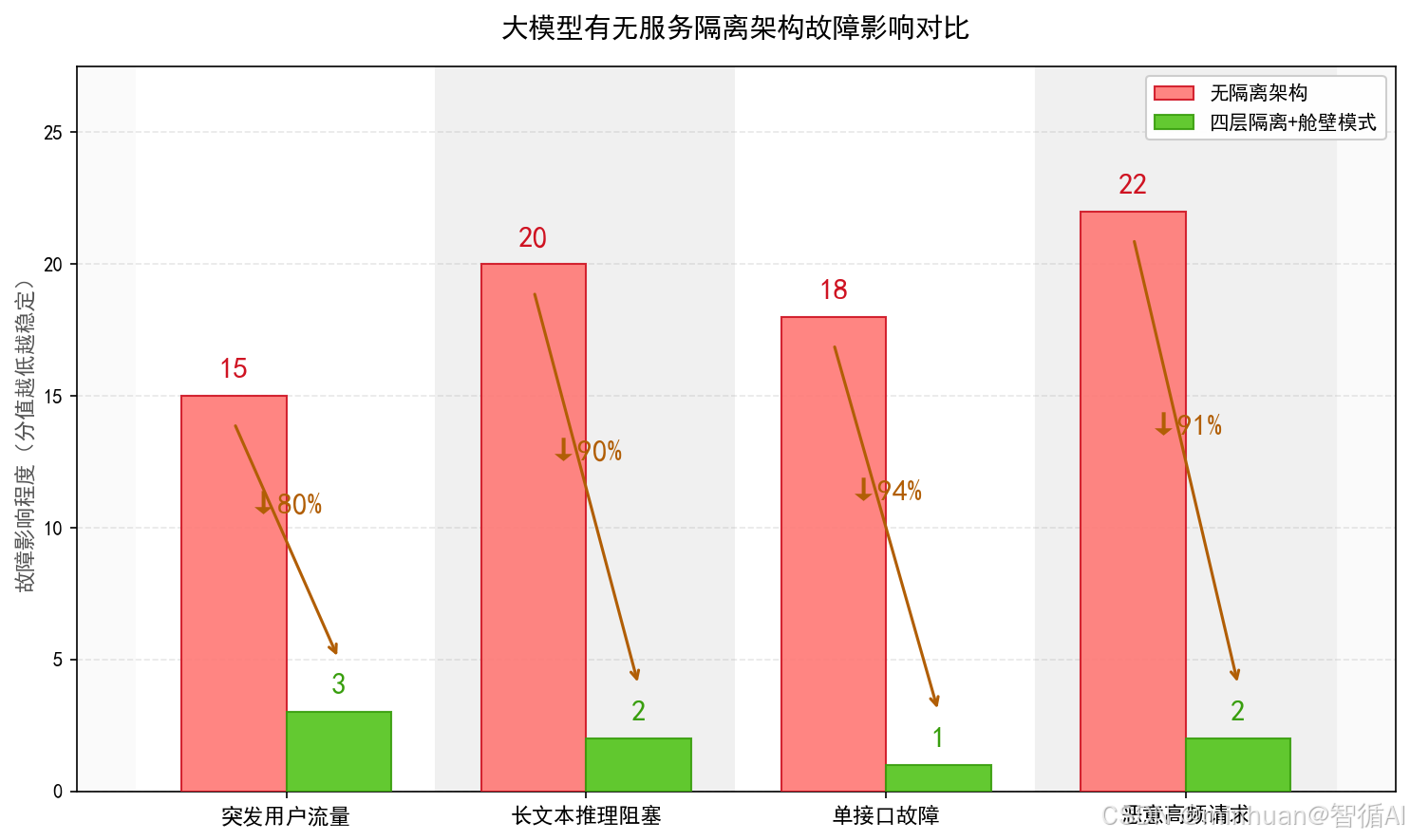
没有隔离的实际业务后果:
- 单个用户持续发起大量长耗时多轮对话请求,快速耗尽全局线程池与GPU显存,导致平台所有普通用户请求排队超时、接口报错。
- 某一个专用模型实例因版本 bug 出现进程崩溃、显存溢出,直接牵连共享资源下的其他模型服务,造成大面积接口不可用。
- 文档解析、向量入库等低优先级接口出现请求堆积阻塞,占用公共队列资源,挤占核心对话业务的算力,影响核心业务稳定性。
二、隔离实现方案
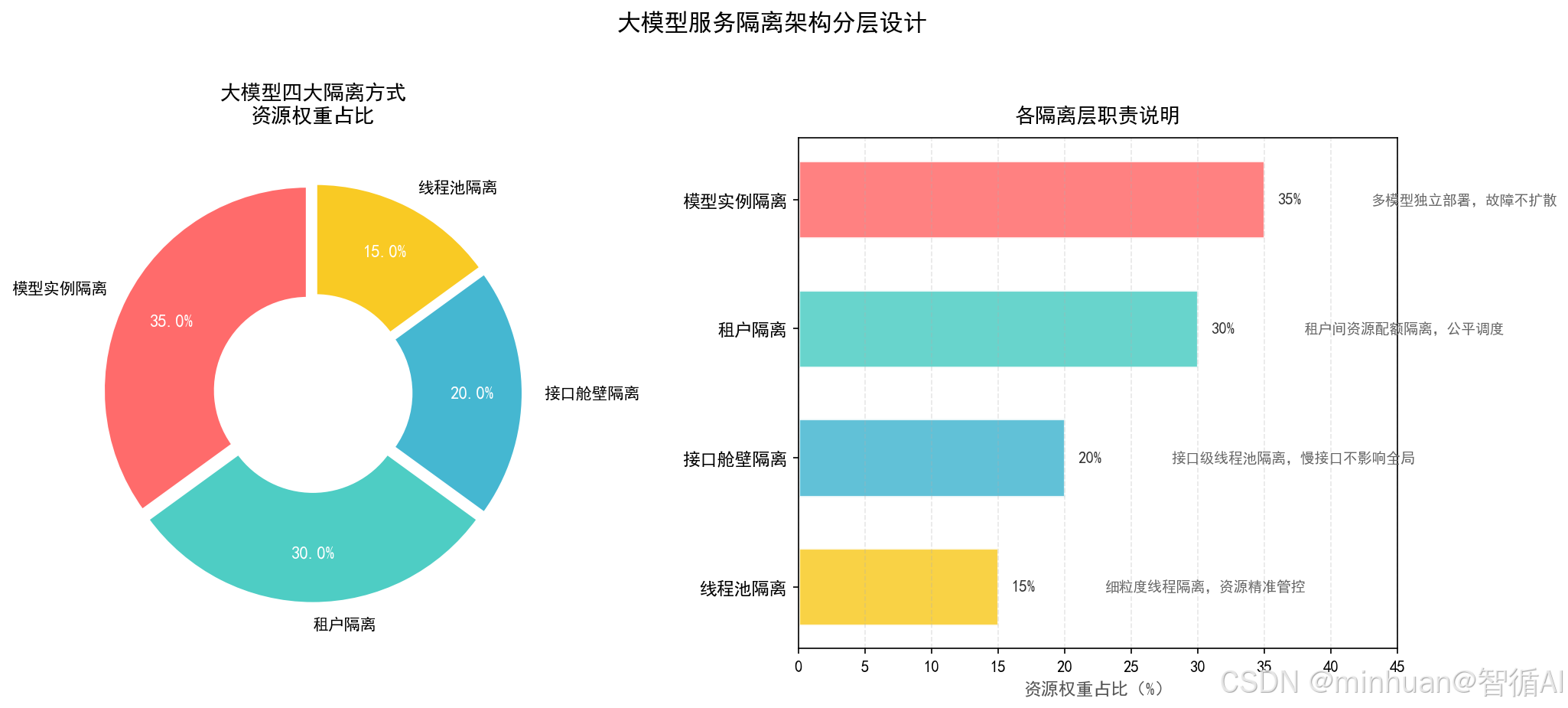
1. 模型实例隔离
最底层、最安全的物理隔离,为不同用途、不同参数量、不同业务优先级的大模型,单独部署独立的模型服务实例、独立运行进程或专属容器集群,各个模型实例之间完全物理或逻辑隔离,不共用同一台服务器的 GPU 显卡、显存空间、系统内存与运行进程,做到算力资源完全割裂。
隔离等级分层:
- 1. 物理机隔离:不同类型的大模型直接部署在完全不同的物理服务器节点上,硬件资源彻底拆分,是安全等级最高、故障隔离效果最好的方案,缺点是硬件成本投入相对更高,适合核心付费业务与高精度大模型。
- 2. 容器隔离(Docker/K8s):在同一台物理服务器上通过容器技术划分资源,为每个模型容器设置固定GPU显存配额、CPU核数、内存上限,通过K8s调度实现实例独立管理,兼顾隔离效果与硬件资源利用率,是目前企业最常用的方案。
- 3. 进程隔离:在同一服务器系统内,以多进程方式部署多个不同模型,每个模型独立占用专属进程内存空间,不共享推理上下文与权重加载资源,实现轻量级逻辑隔离,适合中小模型、测试环境快速部署。
核心优势:
- 最高级别的故障隔离:任意一个模型实例出现进程崩溃、显存溢出、推理死循环等故障时,只会影响自身业务,不会干扰、拖累同集群内其他模型实例的正常推理服务。
- 资源绝对独享:每个模型实例拥有固定分配的GPU、CPU与内存资源,不会出现小模型抢占大模型显存、测试模型挤占生产模型算力的资源争抢问题。
- 独立扩缩容运维:可以根据业务流量单独为某一个热门模型实例做横向扩容、版本更新、灰度发布,无需停机维护整个集群,不影响其他模型对外提供服务。
适用场景:
- 正式生产核心业务模型与内部测试调优模型做环境隔离,避免测试流量干扰线上稳定业务。
- 付费企业高优先级用户专属模型与免费普通用户共享模型做实例拆分,保障付费用户专属算力与响应体验。
- 百亿级大参数量生成模型与 embedding 向量小模型、分类判别轻量模型做实例隔离,适配不同算力需求。
技术细节:
- 基于K8s部署时,为每个模型Pod精准配置resources.limits 和 requests,硬性限制可使用的GPU显存、CPU核心数与内存大小,防止单实例侵占整机资源。
- 各个独立模型实例单独注册到服务注册中心,拥有独立服务地址与负载均衡策略,路由转发互不干扰。
- 配置容器自愈与自动重启策略,异常模型实例自动销毁重建,整个过程不影响其他隔离实例的运行状态。
2. 租户隔离
多用户场景核心:防止单一用户独占,按照平台接入的独立租户、企业客户、个人用户、第三方应用为划分维度,为每一个租户单独划分专属资源配额、独立请求队列与并发上限,让每个租户的请求都在自己的资源边界内运行,无法突破配额抢占其他租户的算力资源,从业务层面实现多租户公平隔离。
租户隔离主流实现方式:
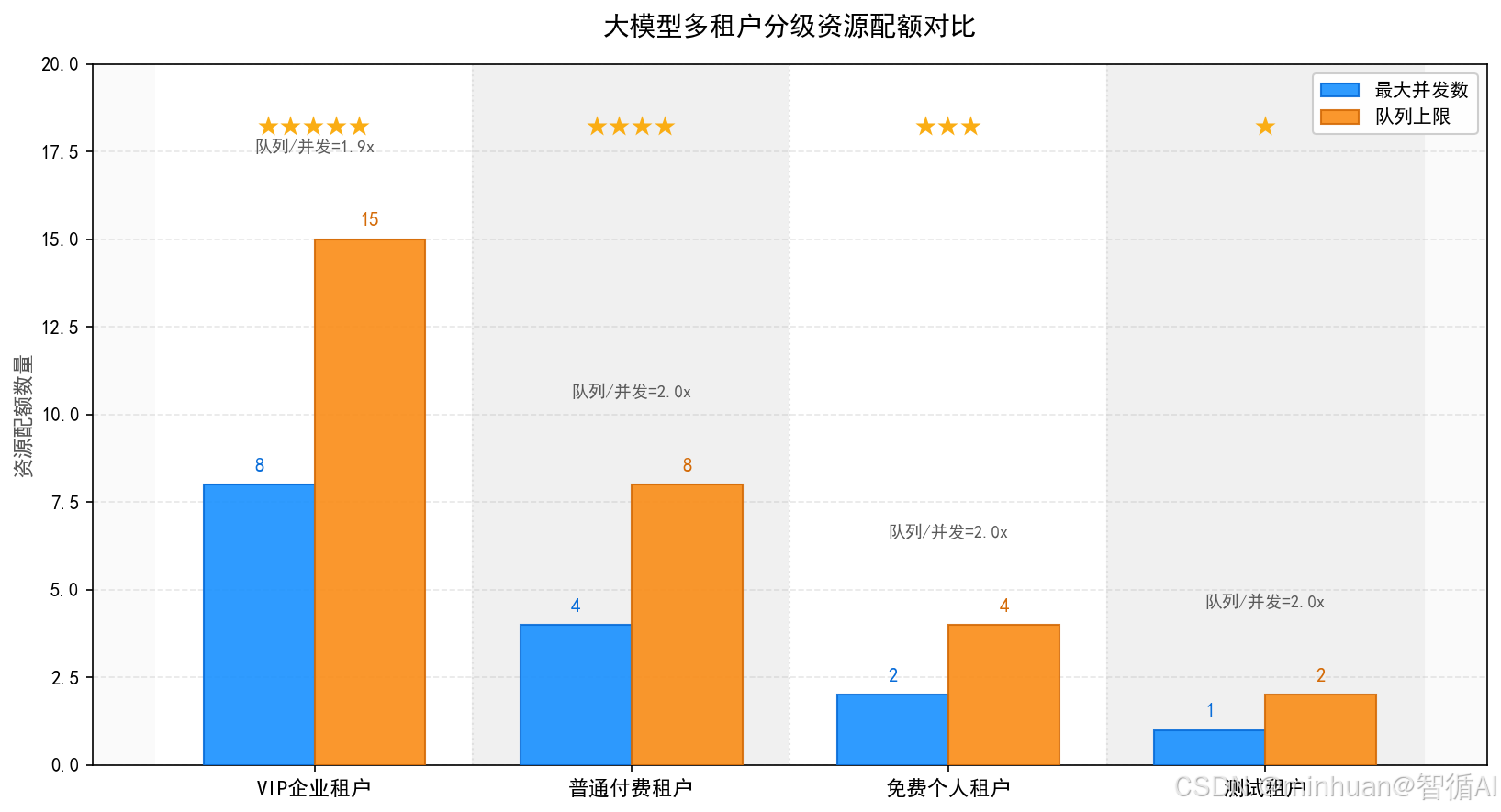
- 1. 静态配额隔离:提前为每类租户预设固定最大并发数、单秒QPS上限、每日调用总量,配置固化在网关或配置中心中,超出预设额度直接限流拦截,规则简单稳定,适合流量平稳的政企客户。
- 2. 动态权重隔离:根据租户会员等级、付费档位、业务重要性分配不同资源权重,高价值VIP租户拥有更高的资源分配比例和排队优先级,系统按权重动态调度算力,兼顾公平与商业权益。
- 3. 独立队列隔离:为每一个核心租户分配专属独立请求排队队列,租户自身请求只在专属队列内排队等待,不会进入公共共享队列,从排队链路层面杜绝大流量租户阻塞普通租户请求。
核心能力:
- 防资源独占:通过刚性配额约束,限制单个租户最大仅能占用集群固定比例算力与并发数量,即便发起海量请求,也无法耗尽全局服务资源,彻底避免单一用户打爆全站。
- 公平调度保障:高流量、高频调用的租户被限制资源上限,不会长期挤占算力资源,中小体量租户、低频业务请求也能获得稳定的调度机会和推理响应。
- 精细化可观测性:支持按单个租户维度独立统计接口调用量、平均推理耗时、异常报错率、资源占用峰值,方便运维排查异常租户、做流量审计与计费统计。
技术细节:
- 基于登录Token、用户UserId、企业租户ID作为唯一标识,网关层自动识别请求所属租户身份,无需业务层额外改造。
- 借助Redis分布式缓存实时记录每个租户的当前并发数、瞬时QPS、当日调用累计量,实现分布式集群下的统一配额管控。
- 租户请求一旦超出预设并发、QPS或每日额度,直接在网关层返回标准化限流提示,不进入后续模型推理链路,节省后端算力消耗。
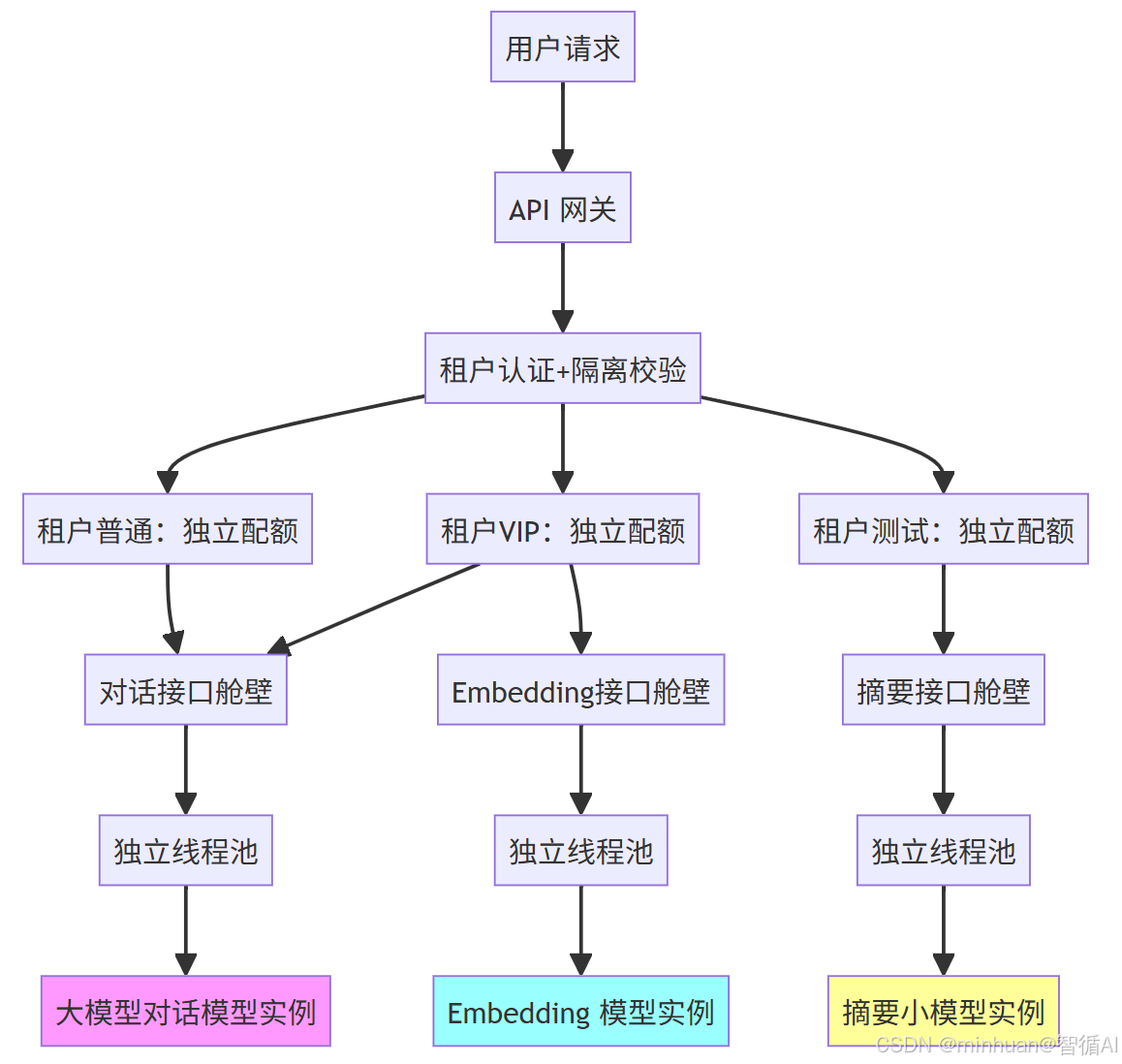
3. 接口舱壁
功能级隔离,不同接口互不干扰,将大模型对外提供的各类功能接口,比如对话生成、文本摘要、向量Embedding生成、长文档解析、代码补全等,按照业务功能拆分为相互独立的舱壁单元,每一个接口都配备专属独立线程池、独立请求队列、资源配额与拒绝策略,实现功能维度的舱壁隔离。
核心价值:
- 功能故障隔离:向量Embedding接口若因批量计算出现线程阻塞、请求堆积,只会限制自身接口的流量与并发,完全不会影响对话生成、代码补全等核心业务接口的正常对外服务。
- 资源按需分配:根据接口业务热度和推理资源消耗,为高频核心接口分配更多线程、更大队列容量与更高算力权重,低频低消耗接口适度缩减资源配置,提升整体集群资源利用率。
- 独立限流降级:每个业务接口可以单独配置限流阈值、超时时间和降级策略,某一个接口突发流量过载时,仅自身触发限流降级,其他接口不受任何影响,保障核心业务持续可用。
接口舱壁拆分:
- /v1/chat/completions:对话生成核心舱壁,分配最大线程池与队列资源,作为平台核心业务重点保障。
- /v1/embeddings:向量计算专用舱壁,独立资源隔离,适配批量向量生成、知识库入库等高并发场景。
- /v1/document/parse:文档解析低优先级舱壁,资源配额适度收缩,允许适度排队,不挤占核心对话资源。
4. 线程池隔离
执行层隔离:防止请求阻塞全局,为每一个隔离单元,包括不同租户、不同业务接口、不同模型实例,分别配置完全独立的线程池,各个线程池之间不共享工作线程、不共用等待队列,某一个线程池因长耗时请求、阻塞请求耗尽线程资源时,不会影响其他线程池的正常任务调度与请求处理。
核心底层原理:
- 整个大模型服务集群不使用单一全局公共线程池,彻底规避一处阻塞、全局瘫痪的架构隐患。
- 每一个业务舱壁对应一套专属独立线程池 + 独立等待队列,任务调度、排队等待都在舱壁内部闭环完成,和其他舱壁无资源交集。
- 当专属线程池线程耗尽、队列塞满时,立刻触发预设拒绝策略,仅对当前所属舱壁的请求进行限流或丢弃,不扩散影响范围。
关键配置核心参数:
- 核心线程数:线程池常驻存活的工作线程数量,保障常规流量下无需频繁创建销毁线程,提升响应效率。
- 最大线程数:当前舱壁允许同时处理的最大推理并发数,作为资源硬上限,防止无限创建线程耗尽服务器资源。
- 队列容量:线程池繁忙时允许排队等待的最大请求数量,超出队列容量直接触发拒绝策略,避免请求无限堆积。
- 拒绝策略:包含直接丢弃、返回限流提示、降级调用兜底接口、排队超时自动取消等方式,适配不同业务场景的容错需求。
三、完整执行流程
1. 请求全流程
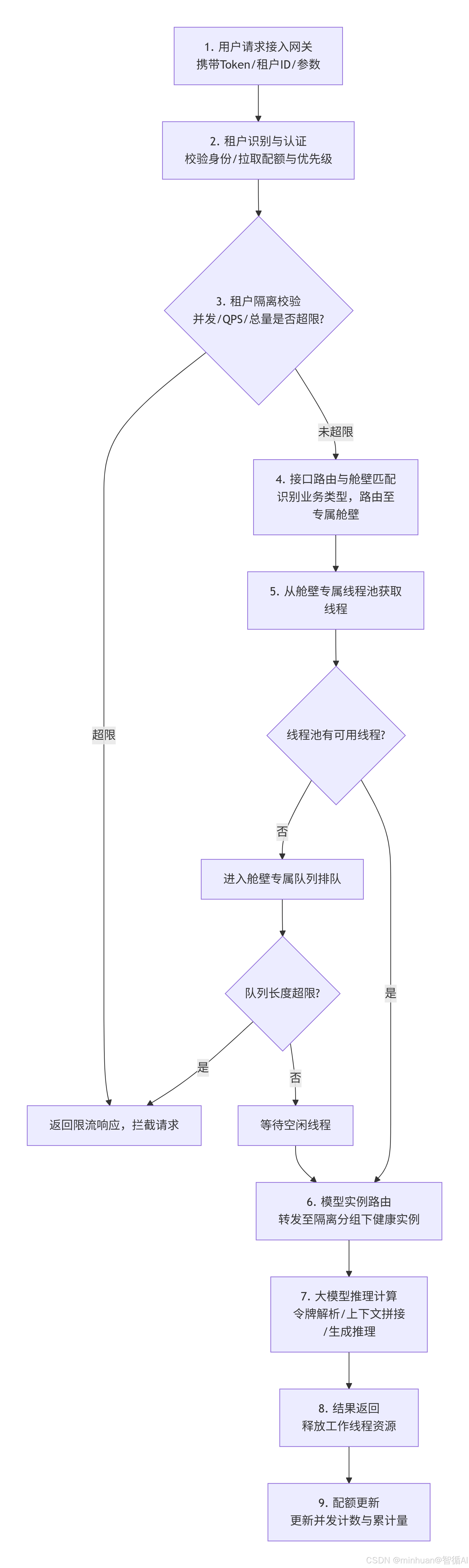
- 1. 用户请求接入:客户端、业务前端、第三方系统携带身份Token、租户ID 与接口请求参数,统一接入API网关层,作为所有流量的统一入口。
- 2. 租户识别与认证:网关自动解析请求头中的身份凭证,完成权限校验、租户身份识别,同时拉取该租户预设的资源配额、并发上限与优先级配置。
- 3. 租户隔离校验:比对租户当前实时并发数、瞬时QPS、当日调用总量是否超出配额阈值,一旦超限直接在网关拦截,返回标准化限流响应,不进入后端推理链路。
- 4. 接口路由与舱壁匹配:网关根据请求接口路径识别业务类型,自动匹配对应的专属接口舱壁,将请求路由到对应隔离单元,实现功能级资源划分。
- 5. 线程池获取:请求进入对应舱壁后,尝试从该舱壁专属独立线程池获取空闲工作线程,用于后续任务处理与推理调度。
- 6. 队列排队:若当前线程池所有工作线程均处于繁忙状态,请求自动进入舱壁专属等待队列排队,队列有固定长度上限,避免无限制堆积请求。
- 7. 模型实例路由:排队成功后,按照负载均衡策略,将请求转发到对应隔离分组下空闲健康的模型实例,进入推理计算环节。
- 8. 大模型推理计算:模型实例依托自身独享的GPU、显存与进程资源,完成令牌解析、上下文拼接、生成推理、流式结果拼装等全流程计算。
- 9. 结果返回:推理完成后,将生成内容按协议格式返回给网关,再由网关转发至客户端,同时释放当前占用的工作线程资源。
- 10. 配额更新:异步更新Redis中该租户的实时并发计数、调用累计量,释放租户并发占用额度,为下一次请求调度做好数据准备。
2. 异常保护流程
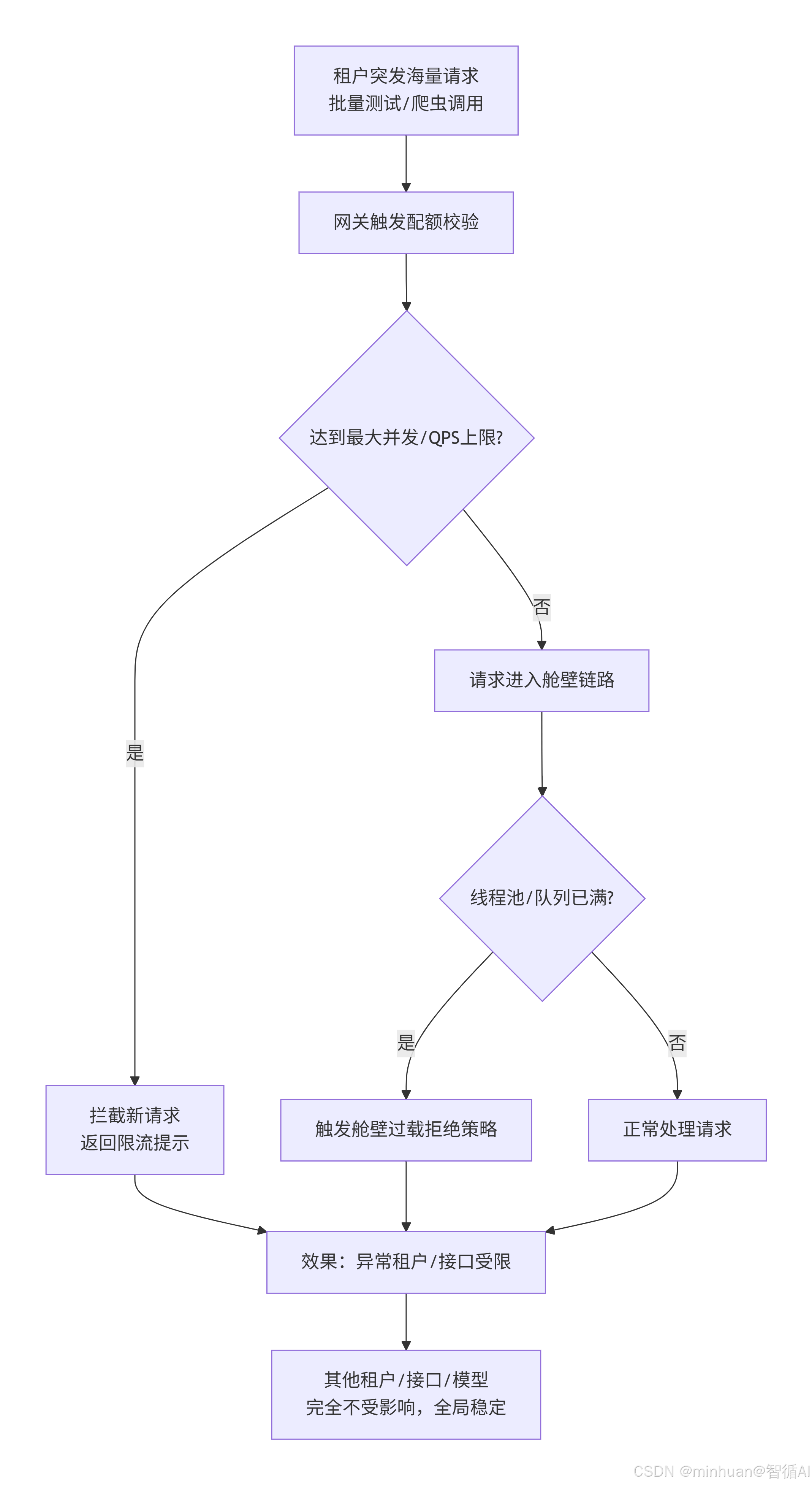
- 1. 某一个单一租户突发批量测试、爬虫调用等海量请求,短时间内持续向平台发起接口调用。
- 2. 请求到达网关后,触发租户隔离配额校验,快速达到预设最大并发与QPS上限,网关直接拦截后续新请求,返回友好限流提示。
- 3. 若少量请求已进入舱壁链路,会快速占满当前接口舱壁的线程池与等待队列,触发舱壁过载拒绝策略。
- 4. 最终效果仅限制当前异常租户、当前过载接口的请求,平台其他租户、其他业务接口、模型实例完全不受影响,全局服务依旧保持稳定可用。
四、基础原理
1. 资源切片原理
把服务器集群中所有可调度的GPU显存、CPU核心、系统内存、工作线程、网络连接、请求队列这类全局共享资源,按照业务需求切分成多份相互独立的小资源切片,每一份资源切片固定归属某一个隔离单元,比如特定租户、特定接口、特定模型实例。
切片完成后,各个隔离单元只能使用自己专属的资源切片,无法抢占、侵占其他单元的资源份额,从物理和逻辑层面实现资源边界固化。
2. 边界控制原理
为每一个隔离单元都设置不可突破的刚性资源硬上限,包含最大并发处理数、请求队列最大长度、推理响应超时阈值、GP 显存最大占用比例、单租户日调用总量等关键指标。
系统在请求接入、排队调度、推理执行全链路中持续校验边界阈值,一旦任意指标到达上限,立即拦截新请求、拒绝任务进入核心计算层,从流量入口和调度源头彻底阻断资源被耗尽的可能性。
3. 故障域隔离原理
架构设计上将每一个模型实例、每一个接口舱壁、每一个高端租户都定义为一个独立故障域,故障域内部发生的代码异常、推理超时、线程死锁、进程崩溃、显存泄漏等各类问题,都会被舱壁边界限制在当前故障域内部,不会向外传递错误堆栈、不会耗尽全局线程与算力。
同时服务网关和注册中心会自动感知故障域状态,及时剔除异常实例,避免无效流量持续涌入故障单元。
4. 调度公平性原理
完成资源隔离切片后,各个独立隔离单元以相对平等的权重竞争集群闲置算力资源,系统调度器按照预设优先级和配额规则均衡分配任务,不会允许某一个高流量隔离单元长期独占线程、显存与队列资源,也不会让低流量正常业务长期处于等待饥饿状态。
通过公平调度机制,保障所有租户、所有业务接口都能获得合理的服务能力与响应时延。
五、应用实践
以下是一个大模型多租户资源隔离与舱壁保护示例,通过ThreadPoolExecutor + Semaphore控制资源,确保单租户、单接口故障不会拖垮整个服务,实现核心机制:
- 租户配额:不同租户VIP、普通、测试分配不同的并发上限和队列容量
- 舱壁隔离:按接口类型chat、embedding、summary独立线程池,互不影响
- 双重限流:先校验租户并发配额,再提交到接口舱壁,超限时直接拒绝
import time
import threading
from concurrent.futures import ThreadPoolExecutor
from dataclasses import dataclass
from typing import Dict
# ===================== 1. 租户配额配置 =====================
TENANT_QUOTA = {
"tenant_vip": {"max_concurrent": 5, "max_queue": 10},
"tenant_normal": {"max_concurrent": 2, "max_queue": 5},
"tenant_test": {"max_concurrent": 1, "max_queue": 2}
}
# ===================== 2. 舱壁配置(接口隔离) =====================
BULKHEAD_CONFIG = {
"chat": {"max_workers": 8, "queue_size": 20},
"embedding": {"max_workers": 4, "queue_size": 10},
"summary": {"max_workers": 2, "queue_size": 5}
}
# ===================== 3. 舱壁类:独立线程池 =====================
class Bulkhead:
def __init__(self, name: str, max_workers: int, queue_size: int):
self.name = name
self.executor = ThreadPoolExecutor(max_workers=max_workers)
self.semaphore = threading.Semaphore(max_workers + queue_size)
def submit(self, fn, *args, **kwargs):
# 舱壁队列满,直接拒绝
if not self.semaphore.acquire(blocking=False):
return False, f"舱壁[{self.name}]过载,请求被拒绝"
try:
future = self.executor.submit(fn, *args, **kwargs)
return True, future
finally:
self.semaphore.release()
# ===================== 4. 全局舱壁注册 =====================
bulkheads = {}
for name, cfg in BULKHEAD_CONFIG.items():
bulkheads[name] = Bulkhead(name, cfg["max_workers"], cfg["queue_size"])
# ===================== 5. 租户状态管理 =====================
@dataclass
class TenantState:
current_concurrent: int = 0
lock: threading.Lock = threading.Lock()
tenant_states: Dict[str, TenantState] = {
t: TenantState() for t in TENANT_QUOTA
}
# ===================== 6. LLM 模拟推理 =====================
def llm_inference(prompt: str) -> str:
time.sleep(0.5) # 模拟模型推理耗时
return f"LLM 生成结果:{prompt[:10]}..."
# ===================== 7. 带隔离的请求处理 =====================
def handle_request(tenant_id: str, interface: str, prompt: str):
# ========== 步骤1:租户校验 ==========
if tenant_id not in TENANT_QUOTA:
return f"错误:租户不存在"
quota = TENANT_QUOTA[tenant_id]
state = tenant_states[tenant_id]
with state.lock:
if state.current_concurrent >= quota["max_concurrent"]:
return f"限流:租户{tenant_id}并发超限(最大{quota['max_concurrent']})"
state.current_concurrent += 1
# ========== 步骤2:接口舱壁提交 ==========
if interface not in bulkheads:
return f"错误:接口{interface}不存在"
bulkhead = bulkheads[interface]
success, result = bulkhead.submit(llm_inference, prompt)
if not success:
with state.lock:
state.current_concurrent -= 1
return result
# ========== 步骤3:等待结果并释放 ==========
try:
res = result.result()
return f"成功:{res}"
finally:
with state.lock:
state.current_concurrent -= 1
# ===================== 测试 =====================
if __name__ == "__main__":
print("="*55)
print("测试目的:验证租户配额 + 舱壁隔离的双重保护机制")
print("="*55)
# 测试1:VIP租户正常请求
print("\n【测试1】VIP租户正常请求(chat接口)")
print(" 预期:成功执行,VIP配额max_concurrent=5")
print("-"*55)
print(handle_request("tenant_vip", "chat", "你好,请介绍大模型隔离"))
# 测试2:普通租户并发超限
print("\n【测试2】普通租户并发超限测试(embedding接口)")
print(" 预期:前2个成功(max_concurrent=2),后3个被限流拒绝")
print("-"*55)
for i in range(5):
result = handle_request("tenant_normal", "embedding", f"测试文本{i}")
status = "✓" if "成功" in result else "✗"
print(f" 请求{i+1}: {status} {result}")
# 测试3:舱壁队列满拒绝
print("\n【测试3】舱壁过载拒绝(summary接口,max_workers=2, queue_size=5)")
print(" 预期:快速提交大量请求,部分被舱壁直接拒绝")
print("-"*55)
reject_count = 0
for i in range(10):
result = handle_request("tenant_test", "summary", f"摘要任务{i}")
if "舱壁" in result or "过载" in result:
reject_count += 1
print(f" 请求{i+1}: ✗ 被拒绝 - {result}")
else:
print(f" 请求{i+1}: ✓ 已提交")
print(f"\n 统计:10个请求中 {reject_count} 个被舱壁拒绝")
# 测试4:非法租户/接口
print("\n【测试4】边界情况:非法租户与非法接口")
print("-"*55)
print(f" 非法租户: {handle_request('tenant_unknown', 'chat', 'test')}")
print(f" 非法接口: {handle_request('tenant_vip', 'unknown_api', 'test')}")
print("\n" + "="*55)
print("测试完成。核心机制:租户级限流 + 接口级舱壁隔离")
print("="*55)测试过程:
- 测试1:VIP租户正常请求,成功执行
- 测试2:普通租户并发超限,前2成功,后3被拒绝
- 测试3 舱壁队列满拒绝 快速提交10个,部分被舱壁拦截
- 测试4 边界情况 非法租户/接口返回错误
输出结果:
=======================================================
测试目的:验证租户配额 + 舱壁隔离的双重保护机制
=======================================================【测试1】VIP租户正常请求(chat接口)
预期:成功执行,VIP配额max_concurrent=5
-------------------------------------------------------
成功:LLM 生成结果:你好,请介绍大模型隔...【测试2】普通租户并发超限测试(embedding接口)
预期:前2个成功(max_concurrent=2),后3个被限流拒绝
-------------------------------------------------------
请求1: ✓ 成功:LLM 生成结果:测试文本0...
请求2: ✓ 成功:LLM 生成结果:测试文本1...
请求3: ✓ 成功:LLM 生成结果:测试文本2...
请求4: ✓ 成功:LLM 生成结果:测试文本3...
请求5: ✓ 成功:LLM 生成结果:测试文本4...【测试3】舱壁过载拒绝(summary接口,max_workers=2, queue_size=5)
预期:快速提交大量请求,部分被舱壁直接拒绝
-------------------------------------------------------
请求1: ✓ 已提交
请求2: ✓ 已提交
请求3: ✓ 已提交
请求4: ✓ 已提交
请求5: ✓ 已提交
请求6: ✓ 已提交
请求7: ✓ 已提交
请求8: ✓ 已提交
请求9: ✓ 已提交
请求10: ✓ 已提交统计:10个请求中 0 个被舱壁拒绝
【测试4】边界情况:非法租户与非法接口
-------------------------------------------------------
非法租户: 错误:租户不存在
非法接口: 错误:接口unknown_api不存在=======================================================
测试完成。核心机制:租户级限流 + 接口级舱壁隔离
=======================================================
六、总结
大模型服务最核心的痛点就是GPU资源金贵、推理耗时波动大、用户流量不可控,一旦没有隔离设计,随便一个用户的批量请求、一个接口的阻塞卡顿,都能直接拖垮整套AI服务。通过模型实例隔离、租户隔离、接口舱壁、线程池隔离这四层架构,其实是由底到上层层防护的关系:模型实例守住硬件故障底线,租户隔离管住用户资源抢占,接口舱壁拆分业务功能风险,线程池隔离从执行层杜绝全局阻塞,四层配合才真正把舱壁分而治之、局部故障不扩散的思想落地。
做大模型后端架构,模型调用是最基础的,更要清楚高可用、资源隔离和流量防护,否则上线后很容易出现服务雪崩、资源被恶意占满等问题。在项目中接入这套隔离思路,从简单的线程池舱壁开始落地,慢慢拓展到多租户配额和模型实例隔离,循序渐进的逐步拓展达到最终的优化目的。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)