小模型训练50题(1-10)
再次感谢乔木mq的真题分享。小模型训练技巧,比大模型更注重工程参数和模型细节。
1. 在使用 QLoRA 微调一个 7B 参数模型时,若将 LoRA rank 设为r=8 ,分析其对 Adam optimizer states 显存占用的压缩比,并推导梯度反向传播至低秩矩阵 和
和 的具体计算流程。
的具体计算流程。
QLoRA,是把主干权重的连续缓存,用int4,换成离散的档位存储起来,再向LoRA一样仅训练低秩矩阵A和B。这样对Adam optimizer States的显存,如果原始的权重矩阵是,比如d=4096,则原始W的训练需要缓存2*d*d=2
。QLoRA仅仅对LoRA的A和B进行微调,总的显存需求为2*(d*r+r*d)=4dr。因此,总的压缩比是4dr/2
=2r/d=2*8/4096=1/256。
在QLoRA里,微调输出函数满足,α是刻度因子,r是秩,
,
设损失函数为,梯度反向传播满足
,则对A、B的梯度满足
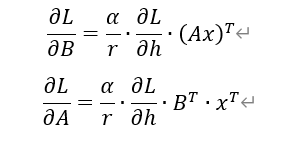
其中,是在反向传播过程当进入到QLoRA层后,直接输出的。
2. 对比直接训练一个 100M 参数小模型与从 7B 模型蒸馏得到的 100M 模型在收敛速度和最终性能上的差异。从损失曲面(loss landscape)的平滑性角度解释知识蒸馏为何能提供更优的优化路径。
100M直接训练和7B蒸馏
的损失函数的定义,其中q(y|x,θ)为真实状态的概率分布;
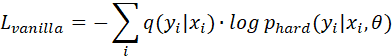
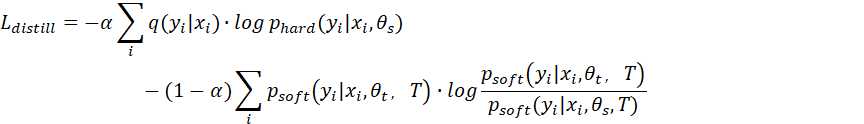
其中![]() 在T温度下输出的教师参数软标签的似然分布;
在T温度下输出的教师参数软标签的似然分布;![]() 是学生参数在T温度下、拟合教师软标签的似然分布,用于与
是学生参数在T温度下、拟合教师软标签的似然分布,用于与![]() 进行KL散度;soft代表软标签;
进行KL散度;soft代表软标签;![]() 代表学生模型对真实标签的分布似然;hard代表硬标签;α为权重系数;T是蒸馏温度;
代表学生模型对真实标签的分布似然;hard代表硬标签;α为权重系数;T是蒸馏温度;
可以看到Lvanilla直接训练时,损失函数仅受one-hot真实分布phard的硬标签监督,没有任何教师概率分布的指导影响,容易出现优化速度慢、噪声大;而知识蒸馏,则是在软标签部分,根据不同的温度,从教师参数里蒸馏出不同的学生参数θs,其中含有教师参数传递过来的概率分布。T越大,能够从老师参数里蒸馏出的知识点就越多。而hard和soft二者的混合结果,拉低了直接拟合的不确定性,逐渐趋近到最优解,从而起到了平滑稳定的调节作用。
题设是从7B大模型里蒸馏出100M的小模型,相当于从7B的教师参数里通过教师模型的概率分布,让学生模型拟合出1/70的学生参数,所以,实际训练里要充分考虑温度T的调节能力。
3.在 INT4 量化感知训练(QAT)中,若采用对称量化方案,推导权重W的量化误差 与其 Hessian 矩阵特征值分布的关系,并说明为何对敏感层(如 LayerNorm 前的线性层)应保留更高精度。
与其 Hessian 矩阵特征值分布的关系,并说明为何对敏感层(如 LayerNorm 前的线性层)应保留更高精度。
设权重W矩阵为m×n维度,损失函数为L,则:
![]() ,
,
则F-范数下的量化误差,即:,简称
![]()
![]() ,此处ΔW已被事先映射到m×n空间,与H的维度对齐;
,此处ΔW已被事先映射到m×n空间,与H的维度对齐;
,假定量化误差是平均分布的,则H不同特征值{λ1,λ2,...,λr}与
W各元素的乘积再求和的期望,就可以是矩阵的迹与
的直接乘积,
![]()
其中tr(H)是hessian的迹,d=m×n是维度。
对于int4的QAT及对称量化方案,是训练期间把浮点型参数w量化为一个区间内的整数再反量化,
,dequant(quant(w))=s.quant(w)
其中s是基于max|w|的刻度因子,则s/2≈max|w|/16是反量化后的权重因子上界,则
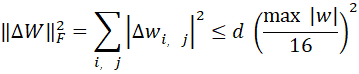
从的近似公式可以知道,损失函数的期望差与hessian矩阵特征值和(迹)成正比,而与F-范数的平方成正比。因为在QAT训练时,是每层逐渐将Fp16压缩成Int4的,所以不建议在linear&norm的linear层进行INT4的压缩,而是放到linear完成之后。原因是:linear层是对旧的参数重新进行线性变换,对于参数的Int4调整是最为敏感的,此时heissan矩阵的迹是最大的,导致损失函数的值也最大,提示波动性最大。所以要保证更高的精度。等到经过了linear层之后,再将Fp16的精度降低到int4,能够保证精度损失不在最敏感环节降得太快。
4.使用 FlashAttention-2 加速小模型训练时,由于序列长度较短(如L=512 ),传统 attention kernel 的带宽瓶颈不显著。分析在此场景下 FlashAttention-2 相比 naive implementation 的实际加速比,并讨论其适用边界。
L=512是极其短的序列,naive implementation显存开销O(512×512),而FlashAttention-2是O(512)。FlashAttention-2,直接在SRAM里算tiling,算完就丢;Naive implementation则是存储整个KV到HBM。此时FlashAttention-2、naive implementation的attention矩阵都是:
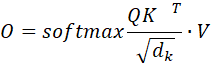
但前者有分块+不存整个的KV+cuda重写矩阵算法,后者存整个的KV。但是,由于L=512太小了,所以FlashAttention-2的优势几乎显现不出来,反而是分块和不存整个KV,速度还不如naive implementation。
在适用边界上,FlashAttention-2适用于单卡实战小模型,快速做预训练,且L=10-100k;naive implementation只适用于L≤1k。
5. 在 ZeRO-Stage 3 下训练一个 1.3B 参数模型,若每张 GPU 显存为 24GB,计算最大可支持的 batch size,并分析参数分片、梯度分片和 optimizer states 分片三者的通信时机与带宽需求。
L=1.3B,每张24GB。ZeRO-Stage 3把所有的参数模型进行全量分片后,如果有4片GPU,参数占显存=1.3B*2/4=0.65B=0.61GB,梯度占显存=1.3B*2/4=0.65B=0.61GB,optimizer占显存=1.3B*12/4=3.9B=3.66GB。则每一片的可以支持的最大batch size<24GB-(0.61+0.61+3.66)=19.12GB。因此,有富裕的内存空间。如果是1片GPU,则可支持的最大batch size<24GB-19.52GB=4.48GB,也够。其中动态显存里还有激活函数、softmax、linear、add&norm等的计算占用。
按Zero-Stage 3的选择,是把weight & bias参数、一阶动量、二阶方差,都存储了起来,并且均匀分片到GPU的不同计算区域。前向传播feed forward时:分配了weight&bias,即参数分片。反向传播back propagation时:存储了梯度分片;optimizer states,是存储一阶动量和二阶方差。前向传播时,参数分片和梯度分片&optimizer states之间,单卡不通信,但多卡就涉及所有的GPU之间的全局通信。反向传播时,会从optimizer states计算出新的动量和方差后,向梯度分片修改梯度,再由梯度分片向参数分片修改参数。带宽的需求:如果上面举例的四片,则带宽*通信时间≥0.61GB;如果是1片,则没有通信问题。
6. 推导知识蒸馏中软标签损失项 对学生模型 logits
对学生模型 logits  的梯度,其中
的梯度,其中 ,并分析温度T如何影响梯度幅度和方向。
,并分析温度T如何影响梯度幅度和方向。
![]() (1)
(1)
因为![]() ,其中Z是logit的向量参数,则当i=k时,
,其中Z是logit的向量参数,则当i=k时,
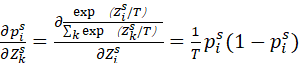 (2)
(2)
当i≠k时,
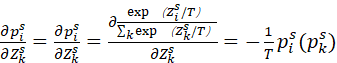 (3)
(3)
把(2)、(3)代入(1),有
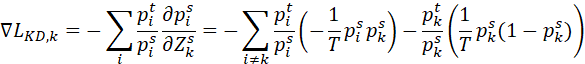
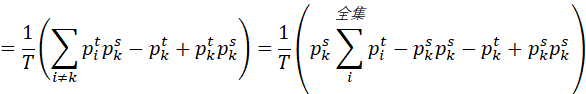
![]() )
)
由此可知,温度越高,则损失函数的梯度越小。当学生分布大于老师分布,梯度正向。
7. 在 MoE 架构的小模型(如 300M + 8 experts)中,若每个 token 仅激活 2 个专家,分析其 FLOPs 与 dense 模型的等效关系,并推导路由网络(router)的负载均衡损失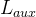 对总训练动态的影响。
对总训练动态的影响。
FLOPS是每个专家总的浮点计算数,dense模型就是所有的参数都参与计算。在300M小模型+8个专家下,每个专家需要接待的浮点数FLOPS=300M/8=37.5M。又因为每个token仅激活2个专家,相当于每个专家都double了接待的浮点数,则在MOE下,每个专家的flops=37.5×2=75M,相比dense模型的全部参数全部专家参与计算,计算量仅为dense的1/4。
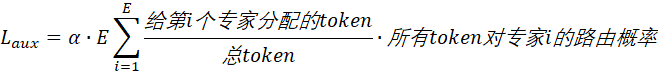
当每个专家的分配token是均匀的时候,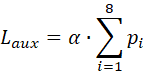
当路由概率pi也均匀的时候。Laux=α(学习因子)是最小值。如果负载均衡分布不均匀,则pi不均匀,Laux会变大。α如果太大,惩罚过强,会导致专家的学习无差别化,没有把最善于干x活的专家Ex提取出来;但α如果太小,就没有意义了,还是会发生专家坍缩。
8. 当使用 DPO 对小模型进行偏好对齐时,若参考模型(reference model)是大模型,分析其 log-ratio 项 中因模型容量差异导致的估计偏差,并提出一种基于置信度加权的修正策略。
中因模型容量差异导致的估计偏差,并提出一种基于置信度加权的修正策略。
由于πθ是小模型,则DPO训练时,会因为小模型不如大模型聚焦而变的更负,反之
会变的更正,导致估计偏差放大。
所以,要想办法把小模型的正样本概率抬高,而把负样本的概率拉低 。 考虑在正样本对数似然项后边,乘以一个基于置信度加权的权重因子,使得正样本变更正;在负样本对数似然项后边,乘以一个基于置信度加权的权重因子
,使得负样本变更负。
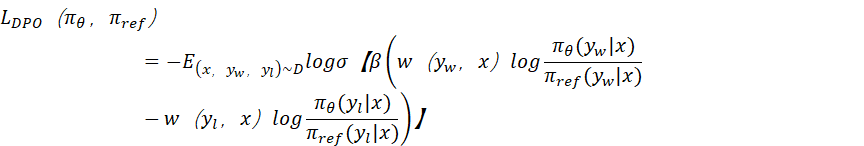
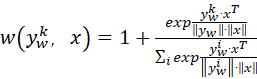 ,
,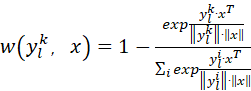
9. 在持续学习场景下,小模型微调新任务时极易发生灾难性遗忘。基于 Fisher 信息矩阵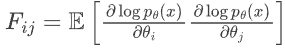 ,设计一个针对关键参数的 EWC 正则项。
,设计一个针对关键参数的 EWC 正则项。
continual learning里,旧的参数好不容易学会了,一旦引入新的知识,旧的参数就会被update,从而发生灾难性遗忘(catastrophic forgetting)。EWC(elastic weight consolidation)就是在损失函数里加入一个惩罚项,当fisher信息矩阵元变大、预示着训练偏移了旧参数的时候,施加很大的惩罚项,形成一个阻尼。设原先的损失函数为,施加了EWC的损失函数是
,则
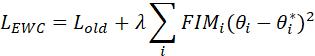 ,θ*是前次训练好的参数,λ是惩罚因子,FIMi是第i个参数的fisher对角矩阵元,满足
,θ*是前次训练好的参数,λ是惩罚因子,FIMi是第i个参数的fisher对角矩阵元,满足
![]() ,化简
,化简
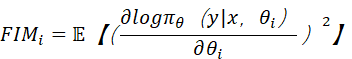
由此可见,FIM越大就说明旧参数越重要,从而当新老参数差值大的时候,就会施加更大的弹性惩罚。
10. 分析在小模型中使用 Grouped-Query Attention (GQA) 而非 Multi-Head Attention (MHA) 对 KV Cache 显存和推理延迟的影响。假设头数h=32 ,group 数g=8 ,计算显存节省比例。
Grouped-Query Attention(GQA)与MHA相比,GQA把MHA的头(h)各自独占KV,变为按照group数(g)把h个头分成g个group,每个group共享同一组KV。设T为context长度,d为维度,则MHA的显存占用是2*h*T*d,而GQA的显存占用是2*g*T*d。从而GQA显存只占MHA的8/32=1/4。显存节省了75%。显存占比节省了,吞吐量变大,带宽瓶颈得到很大的改善,但是推理的精度肯定是少许下降了。
(未完待续)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)